2531 Repositories
Python unstructured-data Libraries
GDSC UIET KUK 📍 , welcomes you all to this amazing event where you will be introduced to the world of coding 💻 .
GDSC UIET KUK 📍 , welcomes you all to this amazing event where you will be introduced to the world of coding 💻 .
 9 Mar 24, 2022
9 Mar 24, 2022

SentAugment is a data augmentation technique for semi-supervised learning in NLP.
SentAugment SentAugment is a data augmentation technique for semi-supervised learning in NLP. It uses state-of-the-art sentence embeddings to structur
 363 Dec 30, 2022
363 Dec 30, 2022
Creating predictive checklists from data using integer programming.
Learning Optimal Predictive Checklists A Python package to learn simple predictive checklists from data subject to customizable constraints. For more
 5 Apr 19, 2022
5 Apr 19, 2022
![Code and Data for the paper: Molecular Contrastive Learning with Chemical Element Knowledge Graph [AAAI 2022]](https://github.com/Fangyin1994/KCL/raw/main/fig/overview.png)
Code and Data for the paper: Molecular Contrastive Learning with Chemical Element Knowledge Graph [AAAI 2022]
Knowledge-enhanced Contrastive Learning (KCL) Molecular Contrastive Learning with Chemical Element Knowledge Graph [ AAAI 2022 ]. We construct a Chemi
 58 Dec 26, 2022
58 Dec 26, 2022
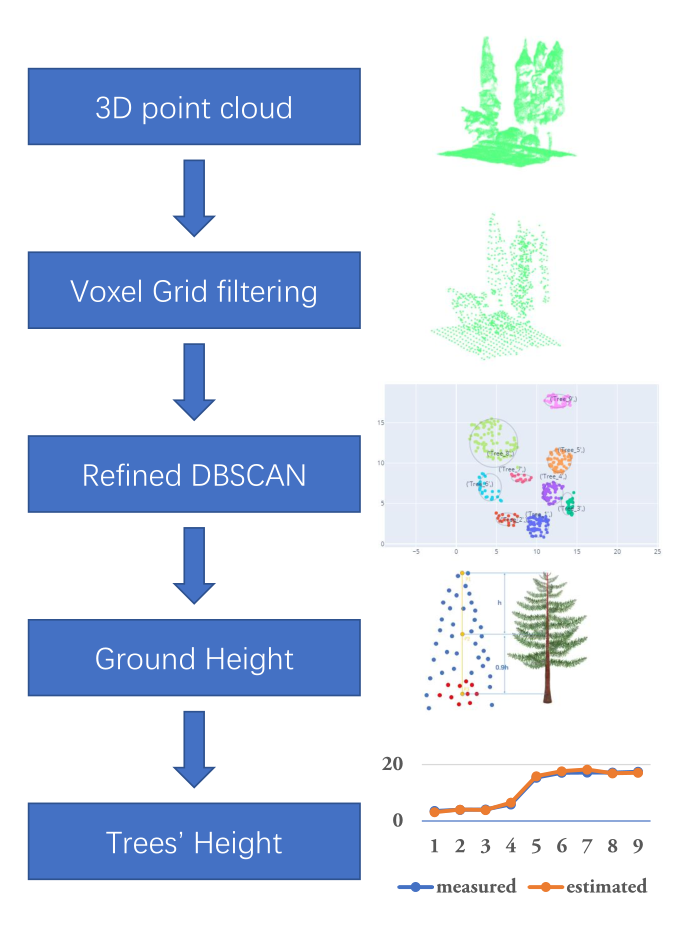
A simple algorithm for extracting tree height in sparse scene from point cloud data.
TREE HEIGHT EXTRACTION IN SPARSE SCENES BASED ON UAV REMOTE SENSING This is the offical python implementation of the paper "Tree Height Extraction in
 6 Oct 28, 2022
6 Oct 28, 2022

My notes on Data structure and Algos in golang implementation and python
My notes on DS and Algo Table of Contents Arrays LinkedList Trees Types of trees: Tree/Graph Traversal Algorithms Heap Priorty Queue Trie Graphs Graph
 0 Feb 13, 2022
0 Feb 13, 2022
Minimal pure Python library for working with little-endian list representation of bit strings.
bitlist Minimal Python library for working with bit vectors natively. Purpose This library allows programmers to work with a native representation of
 0 Jul 25, 2022
0 Jul 25, 2022

Google, Facebook, Amazon, Microsoft, Netflix tech interview questions
Algorithm and Data Structures Interview Questions HackerRank | Practice, Tutorials & Interview Preparation Solutions This repository consists of solut
 8 Oct 4, 2022
8 Oct 4, 2022
Learn to code in any language. If
Learn to Code It is an intiiative undertaken by Student Ambassadors Club, Jamshoro for students who are absolute begineers in programming and want to
 15 Oct 19, 2022
15 Oct 19, 2022
Multiple Imputation with Random Forests in Python
miceforest: Fast, Memory Efficient Imputation with lightgbm Fast, memory efficient Multiple Imputation by Chained Equations (MICE) with lightgbm. The
 202 Dec 31, 2022
202 Dec 31, 2022
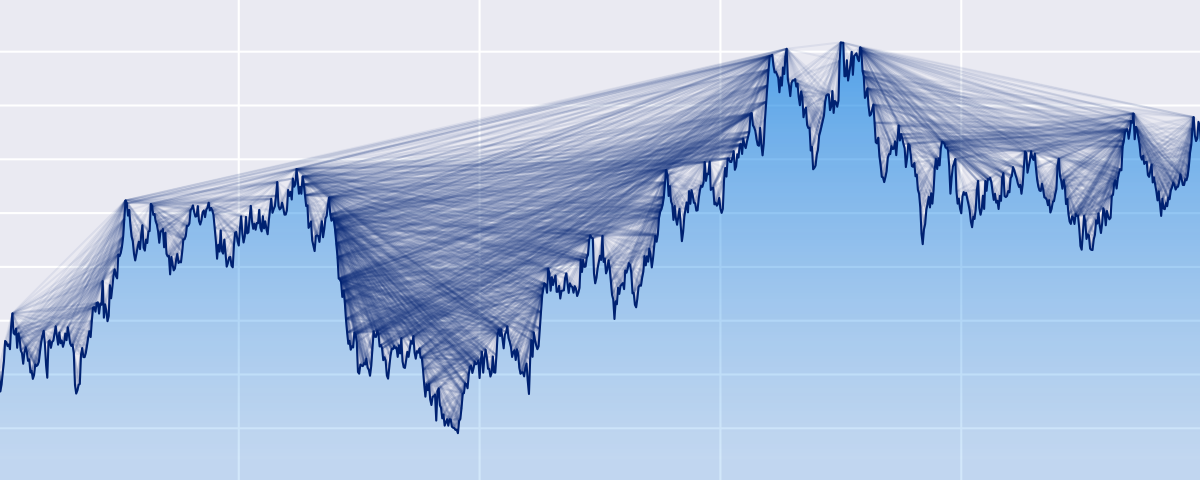
Python ts2vg package provides high-performance algorithm implementations to build visibility graphs from time series data.
ts2vg: Time series to visibility graphs The Python ts2vg package provides high-performance algorithm implementations to build visibility graphs from t
 26 Dec 17, 2022
26 Dec 17, 2022

Very useful and necessary functions that simplify working with data
Additional-function-for-pandas Very useful and necessary functions that simplify working with data random_fill_nan(module_name, nan) - Replaces all sp
 2 Dec 2, 2021
2 Dec 2, 2021
A tool to nowcast quarterly data with monthly indicators: US consumption example
MIDAS_Nowcaster A tool to nowcast quarterly data with monthly indicators: US consumption example Pulls data directly from FRED from a list of codes -
 3 Oct 6, 2022
3 Oct 6, 2022
Data Exfiltration without ever making a connection. Using TCP header space.
TCPwned PoC toy code to exfiltrate data without ever making a TCP connection. This will never show up in firewall logs, much less, actually be monitor
 2 Nov 21, 2022
2 Nov 21, 2022
Upgini : data search library for your machine learning pipelines
Automated data search library for your machine learning pipelines → find & deliver relevant external data & features to boost ML accuracy :chart_with_upwards_trend:
 175 Jan 8, 2023
175 Jan 8, 2023
A light weight data augmentation tool for training CNNs and Viola Jones detectors
hey-daug A light weight data augmentation tool for training CNNs and Viola Jones detectors (Haar Cascades). This tool inflates your data by up to six
 2 Nov 23, 2019
2 Nov 23, 2019
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
Tools for curating biomedical training data for large-scale language modeling
Tools for curating biomedical training data for large-scale language modeling
 242 Dec 25, 2022
242 Dec 25, 2022
The repository for the paper "When Do You Need Billions of Words of Pretraining Data?"
pretraining-learning-curves This is the repository for the paper When Do You Need Billions of Words of Pretraining Data? Edge Probing We use jiant1 fo
 19 Nov 25, 2022
19 Nov 25, 2022
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed+Megatron trained the world's most powerful language model: MT-530B DeepSpeed is hiring, come join us! DeepSpeed is a deep learning optimizat
 8.4k Dec 28, 2022
8.4k Dec 28, 2022
Information Gain Filtration (IGF) is a method for filtering domain-specific data during language model finetuning. IGF shows significant improvements over baseline fine-tuning without data filtration.
Information Gain Filtration Information Gain Filtration (IGF) is a method for filtering domain-specific data during language model finetuning. IGF sho
 4 Jul 28, 2022
4 Jul 28, 2022
The code is the training example of AAAI2022 Security AI Challenger Program Phase 8: Data Centric Robot Learning on ML models.
Example code of [Tianchi AAAI2022 Security AI Challenger Program Phase 8]
 22 Oct 14, 2022
22 Oct 14, 2022

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023
Data preprocessing rosetta parser for python
datapreprocessing_rosetta_parser I've never done any NLP or text data processing before, so I wanted to use this hackathon as a learning opportunity,
 2 Nov 28, 2021
2 Nov 28, 2021
Async boto3 with Autogenerated Data Classes
awspydk Async boto3 with Autogenerated JIT Data Classes Motivation This library is forked from an internal project that works with a lot of backend AW
 1 Dec 5, 2021
1 Dec 5, 2021
A command line tool that creates a super timeline from SentinelOne's Deep Visibility data
S1SuperTimeline A command line tool that creates a super timeline from SentinelOne's Deep Visibility data What does it do? The script accepts a S1QL q
 2 Feb 8, 2022
2 Feb 8, 2022
Visualize your pandas data with one-line code
PandasEcharts 简介 基于pandas和pyecharts的可视化工具 安装 pip 安装 $ pip install pandasecharts 源码安装 $ git clone https://github.com/gamersover/pandasecharts $ cd pand
 2 Apr 13, 2022
2 Apr 13, 2022

A Pythonic framework for threat modeling
pytm: A Pythonic framework for threat modeling Introduction Traditional threat modeling too often comes late to the party, or sometimes not at all. In
 644 Dec 20, 2022
644 Dec 20, 2022

ClearML - Auto-Magical Suite of tools to streamline your ML workflow. Experiment Manager, MLOps and Data-Management
ClearML - Auto-Magical Suite of tools to streamline your ML workflow Experiment Manager, MLOps and Data-Management ClearML Formerly known as Allegro T
 3.9k Jan 1, 2023
3.9k Jan 1, 2023
Official Repository for "Robust On-Policy Data Collection for Data Efficient Policy Evaluation" (NeurIPS 2021 Workshop on OfflineRL).
Robust On-Policy Data Collection for Data-Efficient Policy Evaluation Source code of Robust On-Policy Data Collection for Data-Efficient Policy Evalua
 2 Oct 9, 2022
2 Oct 9, 2022
Self-Supervised Image Denoising via Iterative Data Refinement
Self-Supervised Image Denoising via Iterative Data Refinement Yi Zhang1, Dasong Li1, Ka Lung Law2, Xiaogang Wang1, Hongwei Qin2, Hongsheng Li1 1CUHK-S
 72 Jan 1, 2023
72 Jan 1, 2023
Data Consistency for Magnetic Resonance Imaging
Data Consistency for Magnetic Resonance Imaging Data Consistency (DC) is crucial for generalization in multi-modal MRI data and robustness in detectin
 19 Dec 12, 2022
19 Dec 12, 2022

Automatic Data-Regularized Actor-Critic (Auto-DrAC)
Auto-DrAC: Automatic Data-Regularized Actor-Critic This is a PyTorch implementation of the methods proposed in Automatic Data Augmentation for General
 89 Dec 13, 2022
89 Dec 13, 2022
This repository is for the preprint "A generative nonparametric Bayesian model for whole genomes"
BEAR Overview This repository contains code associated with the preprint A generative nonparametric Bayesian model for whole genomes (2021), which pro
 10 Sep 18, 2022
10 Sep 18, 2022

Removing Inter-Experimental Variability from Functional Data in Systems Neuroscience
Removing Inter-Experimental Variability from Functional Data in Systems Neuroscience This repository is the official implementation of [https://www.bi
 6 Oct 9, 2022
6 Oct 9, 2022
Auditing Black-Box Prediction Models for Data Minimization Compliance
Data-Minimization-Auditor An auditing tool for model-instability based data minimization that is introduced in "Auditing Black-Box Prediction Models f
 2 Mar 24, 2022
2 Mar 24, 2022
[NeurIPS 2021] "G-PATE: Scalable Differentially Private Data Generator via Private Aggregation of Teacher Discriminators"
G-PATE This is the official code base for our NeurIPS 2021 paper: "G-PATE: Scalable Differentially Private Data Generator via Private Aggregation of T
 14 Oct 12, 2022
14 Oct 12, 2022
TAUFE: Task-Agnostic Undesirable Feature DeactivationUsing Out-of-Distribution Data
A deep neural network (DNN) has achieved great success in many machine learning tasks by virtue of its high expressive power. However, its prediction can be easily biased to undesirable features, which are not essential for solving the target task and are even imperceptible to a human, thereby resulting in poor generalization
 8 Dec 7, 2022
8 Dec 7, 2022
Equivariant layers for RC-complement symmetry in DNA sequence data
Equi-RC Equivariant layers for RC-complement symmetry in DNA sequence data This is a repository that implements the layers as described in "Reverse-Co
 7 May 19, 2022
7 May 19, 2022
Hide sensitive information in images
Data-Preserved Script allowing to blur the most sensitive information on images. Prerequisites Before you begin, ensure you have met the following req
 2 Dec 1, 2021
2 Dec 1, 2021

Official PyTorch implementation of Data-free Knowledge Distillation for Object Detection, WACV 2021.
Introduction This repository is the official PyTorch implementation of Data-free Knowledge Distillation for Object Detection, WACV 2021. Data-free Kno
 50 Jan 5, 2023
50 Jan 5, 2023
Sign data using symmetric-key algorithm encryption.
Sign data using symmetric-key algorithm encryption. Validate signed data and identify possible validation errors. Uses sha-(1, 224, 256, 385 and 512)/hmac for signature encryption. Custom hash algorithms are allowed. Useful shortcut functions for signing (and validating) dictionaries and URLs.
 39 Jun 10, 2022
39 Jun 10, 2022
A Python 3 library making time series data mining tasks, utilizing matrix profile algorithms
MatrixProfile MatrixProfile is a Python 3 library, brought to you by the Matrix Profile Foundation, for mining time series data. The Matrix Profile is
 302 Dec 29, 2022
302 Dec 29, 2022
Primitives for machine learning and data science.
An Open Source Project from the Data to AI Lab, at MIT MLPrimitives Pipelines and primitives for machine learning and data science. Documentation: htt
 65 Dec 29, 2022
65 Dec 29, 2022
An helper library to scrape data from Instagram effortlessly, using the Influencer Hunters APIs.
Instagram Scraper An utility library to scrape data from Instagram hassle-free Go to the website » View Demo · Report Bug · Request Feature About The
 2 Jul 6, 2022
2 Jul 6, 2022
tradingview socket api for fetching real time prices.
tradingView-API tradingview socket api for fetching real time prices. How to run git clone https://github.com/mohamadkhalaj/tradingView-API.git cd tra
 35 Dec 31, 2022
35 Dec 31, 2022
This repository is used to provide data to zzhack,
This repository is used to provide data to zzhack, but you don't have to care about anything, just write your thinking down, and you can see your thinking is rendered in zzhack perfectly
 5 Apr 29, 2022
5 Apr 29, 2022
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository provides the official PyTorch implementation
 155 Nov 30, 2021
155 Nov 30, 2021
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
 1 Nov 30, 2021
1 Nov 30, 2021
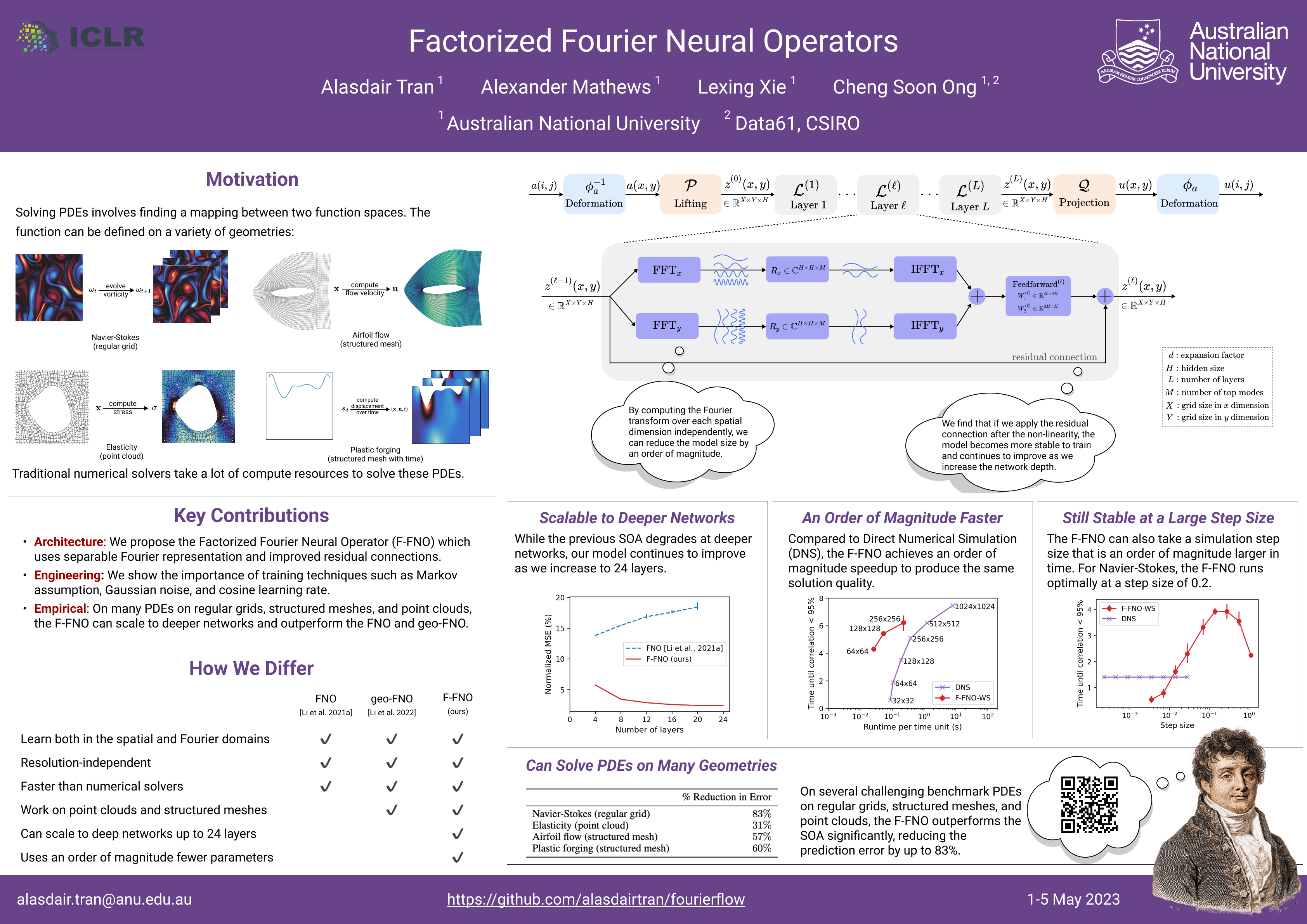
Experiments with Fourier layers on simulation data.
Factorized Fourier Neural Operators This repository contains the code to reproduce the results in our NeurIPS 2021 ML4PS workshop paper, Factorized Fo
 57 Dec 25, 2022
57 Dec 25, 2022
The first GANs-based omics-to-omics translation framework
OmiTrans Please also have a look at our multi-omics multi-task DL freamwork 👀 : OmiEmbed The FIRST GANs-based omics-to-omics translation framework Xi
 1 Nov 30, 2021
1 Nov 30, 2021
Auxiliary data to the CHIIR paper Searching to Learn with Instructional Scaffolding
Searching to Learn with Instructional Scaffolding This is the data and analysis code for the paper "Searching to Learn with Instructional Scaffolding"
 2 Mar 2, 2022
2 Mar 2, 2022
Source Code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chinese Question Matching
Description The source code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chin
 3 Jun 28, 2022
3 Jun 28, 2022

A program that analyzes data from inertia measurement units installed in aircraft and generates g-exceedance curves.
A program that analyzes data from inertia measurement units installed in aircraft and generates g-exceedance curves.
 1 Dec 2, 2021
1 Dec 2, 2021
My Discord Bot that I used to learn Python. Please disregard the unstructured code!
Botsche My personal Discord Bot. To run this bot, change TOKEN in config.ini to your Discord Bot Token, which can be retrieved from your Discord Dev
 1 Nov 29, 2021
1 Nov 29, 2021
Data wrangling & common calculations for results from qMem measurement software
qMem Datawrangler This script processes output of qMem measurement software into an Origin ® compatible *.csv files and matplotlib graphs to quickly v
 1 Nov 30, 2021
1 Nov 30, 2021
Django based webapp pulling in crypto news and price data via api
Deploy Django in Production FTA project implementing containerization of Django Web Framework into Docker to be placed into Azure Container Services a
 0 Sep 21, 2022
0 Sep 21, 2022

Code for generating synthetic text images as described in "Synthetic Data for Text Localisation in Natural Images", Ankush Gupta, Andrea Vedaldi, Andrew Zisserman, CVPR 2016.
SynthText Code for generating synthetic text images as described in "Synthetic Data for Text Localisation in Natural Images", Ankush Gupta, Andrea Ved
 1.8k Dec 28, 2022
1.8k Dec 28, 2022

🛰️ Scripts démontrant l'utilisation de l'imagerie RADARSAT-1 à partir d'un seau AWS | 🛰️ Scripts demonstrating the use of RADARSAT-1 imagery from an AWS bucket
🛰️ Scripts démontrant l'utilisation de l'imagerie RADARSAT-1 à partir d'un seau AWS | 🛰️ Scripts demonstrating the use of RADARSAT-1 imagery from an AWS bucket
 4 May 18, 2022
4 May 18, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

This is a python script to grab data from Zyxel NSA310 NAS and display in Home Asisstant as sensors.
Home-Assistant Python Scripts Python Scripts for Home-Assistant (http://www.home-assistant.io) Zyxel-NSA310-Home-Assistant Monitoring This is a python
 6 Oct 31, 2022
6 Oct 31, 2022

A real world application of a Recurrent Neural Network on a binary classification of time series data
What is this This is a real world application of a Recurrent Neural Network on a binary classification of time series data. This project includes data
 2 Jan 30, 2022
2 Jan 30, 2022

APIlocal_dbAWS_RDS - Disclaimer! All data used is for educational purposes only.
APIlocal_dbAWS_RDS Disclaimer! All data used is for educational purposes only. ETL pipeline diagram. Aim of project By creating a fully working pipe
 0 Apr 25, 2022
0 Apr 25, 2022
Flexible time series feature extraction & processing
tsflex is a toolkit for flexible time series processing & feature extraction, that is efficient and makes few assumptions about sequence data. Useful
 206 Dec 28, 2022
206 Dec 28, 2022

DuBE: Duple-balanced Ensemble Learning from Skewed Data
DuBE: Duple-balanced Ensemble Learning from Skewed Data "Towards Inter-class and Intra-class Imbalance in Class-imbalanced Learning" (IEEE ICDE 2022 S
 6 Nov 12, 2022
6 Nov 12, 2022

Fast mesh denoising with data driven normal filtering using deep variational autoencoders
Fast mesh denoising with data driven normal filtering using deep variational autoencoders This is an implementation for the paper entitled "Fast mesh
 9 Dec 2, 2022
9 Dec 2, 2022

IMBENS: class-imbalanced ensemble learning in Python.
IMBENS: class-imbalanced ensemble learning in Python. Links: [Documentation] [Gallery] [PyPI] [Changelog] [Source] [Download] [知乎/Zhihu] [中文README] [a
 176 Jan 4, 2023
176 Jan 4, 2023
Research code for the paper "Variational Gibbs inference for statistical estimation from incomplete data".
Variational Gibbs inference (VGI) This repository contains the research code for Simkus, V., Rhodes, B., Gutmann, M. U., 2021. Variational Gibbs infer
 1 Apr 8, 2022
1 Apr 8, 2022

Deep Learning Emotion decoding using EEG data from Autism individuals
Deep Learning Emotion decoding using EEG data from Autism individuals This repository includes the python and matlab codes using for processing EEG 2D
 12 Dec 8, 2022
12 Dec 8, 2022

This repository contains all code and data for the Inside Out Visual Place Recognition task
Inside Out Visual Place Recognition This repository contains code and instructions to reproduce the results for the Inside Out Visual Place Recognitio
 15 May 21, 2022
15 May 21, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
Tool for running a high throughput data ingestion/transformation workload with MongoDB
Mongo Mangler The mongo-mangler tool is a lightweight Python utility, which you can run from a low-powered machine to execute a high throughput data i
 9 Jan 2, 2023
9 Jan 2, 2023
Gathering data of likes on Tinder within the past 7 days
tinder_likes_data Gathering data of Likes Sent on Tinder within the past 7 days. Versions November 25th, 2021 - Functionality to get the name and age
 12 Jan 5, 2023
12 Jan 5, 2023
Empresas do Brasil (CNPJs)
Biblioteca em Python que coleta informações cadastrais de empresas do Brasil (CNPJ) obtidas de fontes oficiais (Receita Federal) e exporta para um formato legível por humanos (CSV ou JSON).
 8 Aug 17, 2022
8 Aug 17, 2022
E-Commerce recommender demo with real-time data and a graph database
🔍 E-Commerce recommender demo 🔍 This is a simple stream setup that uses Memgraph to ingest real-time data from a simulated online store. Data is str
 3 Feb 23, 2022
3 Feb 23, 2022
Redis OM Python makes it easy to model Redis data in your Python applications.
Object mapping, and more, for Redis and Python Redis OM Python makes it easy to model Redis data in your Python applications. Redis OM Python | Redis
 568 Jan 2, 2023
568 Jan 2, 2023

A procedural Blender pipeline for photorealistic training image generation
BlenderProc2 A procedural Blender pipeline for photorealistic rendering. Documentation | Tutorials | Examples | ArXiv paper | Workshop paper Features
 1.8k Jan 2, 2023
1.8k Jan 2, 2023
Open source platform for Data Science Management automation
Hydrosphere examples This repo contains demo scenarios and pre-trained models to show Hydrosphere capabilities. Data and artifacts management Some mod
 6 Aug 10, 2021
6 Aug 10, 2021
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate.
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate. Website • Key Features • How To Use • Docs •
 21.1k Jan 8, 2023
21.1k Jan 8, 2023
Learning from graph data using Keras
Steps to run = Download the cora dataset from this link : https://linqs.soe.ucsc.edu/data unzip the files in the folder input/cora cd code python eda
 64 Nov 16, 2022
64 Nov 16, 2022
Data pipelines built with polars
valves Warning: the project is very much work in progress. Valves is a collection of functions for your data .pipe()-lines. This project aimes to host
 14 Jan 3, 2023
14 Jan 3, 2023

CinnaMon is a Python library which offers a number of tools to detect, explain, and correct data drift in a machine learning system
CinnaMon is a Python library which offers a number of tools to detect, explain, and correct data drift in a machine learning system
 67 Dec 28, 2022
67 Dec 28, 2022
🗂️ 🔍 Geospatial Data Management and Search API - Django Apps
Geospatial Data API in Django Resonant GeoData (RGD) is a series of Django applications well suited for cataloging and searching annotated geospatial
 53 Nov 1, 2022
53 Nov 1, 2022
A package designed to scrape data from Yahoo Finance.
yahoostock A package designed to scrape data from Yahoo Finance. Installation The most simple installation method is through PIP. pip install yahoosto
 2 May 28, 2022
2 May 28, 2022
An index of algorithms for learning causality with data
awesome-causality-algorithms An index of algorithms for learning causality with data. Please cite our survey paper if this index is helpful. @article{
 2.3k Jan 8, 2023
2.3k Jan 8, 2023
Simple and Distributed Machine Learning
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
3.9k Dec 30, 2022
Qlib is an AI-oriented quantitative investment platform
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment.
10.1k Dec 30, 2022
Automatically download the cwru data set, and then divide it into training data set and test data set
Automatically download the cwru data set, and then divide it into training data set and test data set.自动下载cwru数据集,然后分训练数据集和测试数据集
 6 Jun 27, 2022
6 Jun 27, 2022

Improve current data preprocessing for FTM's WOB data to analyze Shell and Dutch Governmental contacts.
We're the hackathon leftovers, but we are Too Good To Go ;-). A repo by Lukas Schubotz and Raymon van Dinter. We aim to improve current data preprocessing for FTM's WOB data to analyze Shell and Dutch Governmental contacts.
5 Dec 9, 2021
Project under the certification "Data Analysis with Python" on FreeCodeCamp
Sea Level Predictor Assignment You will anaylize a dataset of the global average sea level change since 1880. You will use the data to predict the sea
 3 Jan 31, 2022
3 Jan 31, 2022
Tools for the analysis, simulation, and presentation of Lorentz TEM data.
ltempy ltempy is a set of tools for Lorentz TEM data analysis, simulation, and presentation. Features Single Image Transport of Intensity Equation (SI
 1 Dec 26, 2022
1 Dec 26, 2022
The FIRST GANs-based omics-to-omics translation framework
OmiTrans Please also have a look at our multi-omics multi-task DL freamwork 👀 : OmiEmbed The FIRST GANs-based omics-to-omics translation framework Xi
6 Dec 14, 2022
Finds, downloads, parses, and standardizes public bikeshare data into a standard pandas dataframe format
Finds, downloads, parses, and standardizes public bikeshare data into a standard pandas dataframe format.
 2 Dec 1, 2021
2 Dec 1, 2021
NYCT-GTFS - Real-time NYC subway data parsing for humans
NYCT-GTFS - Real-time NYC subway data parsing for humans This python library provides a human-friendly, native python interface for dealing with the N
 37 Dec 27, 2022
37 Dec 27, 2022
Data and codes for ACL 2021 paper: Towards Emotional Support Dialog Systems
Emotional-Support-Conversation Copyright © 2021 CoAI Group, Tsinghua University. All rights reserved. Data and codes are for academic research use onl
 126 Dec 21, 2022
126 Dec 21, 2022
Gathers data and displays metrics related to climate change and resource depletion on a PowerBI report.
Apocalypse Status Dashboard Purpose Climate change and resource depletion are grave long-term dangers. The code in this repository will pull data from
 1 Nov 12, 2021
1 Nov 12, 2021
Compilation of resources and insights that helped me on my journey to data scientist
Compilation of resources and insights that helped me on my journey to data scientist
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

A collection of online resources to help you on your Tech journey.
Everything Tech Resources & Projects About The Project Coming from an engineering background and looking to up skill yourself on a new field can be di
 396 Dec 31, 2022
396 Dec 31, 2022

This is Assignment1 code for the Web Data Processing System.
This is a Python program to Entity Linking by processing WARC files. We recognize entities from web pages and link them to a Knowledge Base(Wikidata).
 3 Dec 4, 2022
3 Dec 4, 2022