89 Repositories
Python vertex-pipelines-kfp-chicago Libraries

Accelerated NLP pipelines for fast inference on CPU and GPU. Built with Transformers, Optimum and ONNX Runtime.
Optimum Transformers Accelerated NLP pipelines for fast inference 🚀 on CPU and GPU. Built with 🤗 Transformers, Optimum and ONNX runtime. Installatio
 115 Dec 16, 2022
115 Dec 16, 2022
Sample code and notebooks for Vertex AI, the end-to-end machine learning platform on Google Cloud
Google Cloud Vertex AI Samples Welcome to the Google Cloud Vertex AI sample repository. Overview The repository contains notebooks and community conte
 560 Dec 31, 2022
560 Dec 31, 2022
This is the course repository for the Spring 2022 iteration of MACS 30123 "Large-Scale Computing for the Social Sciences" at the University of Chicago.
Large-Scale Computing for the Social Sciences Spring 2022 - MACS 30123/MAPS 30123/PLSC 30123 Instructor Information TA Information TA Information Cour
 6 May 6, 2022
6 May 6, 2022

Open-source data observability for modern data teams
Use cases Monitor your data warehouse in minutes: Data anomalies monitoring as dbt tests Data lineage made simple, reliable, and automated dbt operati
 889 Jan 1, 2023
889 Jan 1, 2023

Repository for DCA0305, an undergraduate course about Machine Learning Workflows and Pipelines
Federal University of Rio Grande do Norte Technology Center Department of Computer Engineering and Automation Machine Learning Based Systems Design Re
 81 Oct 18, 2022
81 Oct 18, 2022
A simple guide to MLOps through ZenML and its various integrations.
ZenBytes Join our Slack Community and become part of the ZenML family Give the main ZenML repo a GitHub star to show your love ZenBytes is a series of
 127 Dec 27, 2022
127 Dec 27, 2022
🎡 Build Python wheels for all the platforms on CI with minimal configuration.
cibuildwheel Documentation Python wheels are great. Building them across Mac, Linux, Windows, on multiple versions of Python, is not. cibuildwheel is
 1.3k Jan 2, 2023
1.3k Jan 2, 2023

MLOps pipeline project using Amazon SageMaker Pipelines
This project shows steps to build an end to end MLOps architecture that covers data prep, model training, realtime and batch inference, build model registry, track lineage of artifacts and model drift detection. It utilizes SageMaker Pipelines that offers machine learning (ML) to orchestrate SageMaker jobs and author reproducible ML pipelines.
 3 Sep 16, 2022
3 Sep 16, 2022
Vertex AI: Serverless framework for MLOPs (ESP / ENG)
Vertex AI: Serverless framework for MLOPs (ESP / ENG) Español Qué es esto? Este repo contiene un pipeline end to end diseñado usando el SDK de Kubeflo
 2 Apr 28, 2022
2 Apr 28, 2022
Graph Coloring - Weighted Vertex Coloring Problem
Graph Coloring - Weighted Vertex Coloring Problem This project proposes several local searches and an MCTS algorithm for the weighted vertex coloring
 1 Jul 8, 2022
1 Jul 8, 2022
A solution designed to extract, transform and load Chicago crime data from an RDS instance to other services in AWS.
This project is intended to implement a solution designed to extract, transform and load Chicago crime data from an RDS instance to other services in AWS.
 1 Feb 4, 2022
1 Feb 4, 2022

Convert monolithic Jupyter notebooks into Ploomber pipelines.
Soorgeon Join our community | Newsletter | Contact us | Blog | Website | YouTube Convert monolithic Jupyter notebooks into Ploomber pipelines. soorgeo
 65 Dec 16, 2022
65 Dec 16, 2022

This example implements the end-to-end MLOps process using Vertex AI platform and Smart Analytics technology capabilities
MLOps with Vertex AI This example implements the end-to-end MLOps process using Vertex AI platform and Smart Analytics technology capabilities. The ex
238 Dec 21, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
 32 Dec 29, 2022
32 Dec 29, 2022

Novel and high-performance medical image classification pipelines are heavily utilizing ensemble learning strategies
An Analysis on Ensemble Learning optimized Medical Image Classification with Deep Convolutional Neural Networks Novel and high-performance medical ima
 14 Dec 18, 2022
14 Dec 18, 2022
A beginner’s guide to train and deploy machine learning pipelines in Python using PyCaret
This model involves Insurance bill prediction, which was subsequently deployed on Heroku PaaS
 1 Jan 27, 2022
1 Jan 27, 2022
SynapseML - an open source library to simplify the creation of scalable machine learning pipelines
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
PHOTONAI is a high level python API for designing and optimizing machine learning pipelines.
PHOTONAI is a high level python API for designing and optimizing machine learning pipelines. We've created a system in which you can easily select and
 57 Nov 12, 2022
57 Nov 12, 2022

Advanced raster and geometry manipulations
buzzard In a nutshell, the buzzard library provides powerful abstractions to manipulate together images and geometries that come from different kind o
 30 Jun 20, 2022
30 Jun 20, 2022
The RAP community of practice includes all analysts and data scientists who are interested in adopting the working practices included in reproducible analytical pipelines (RAP) at NHS Digital.
The RAP community of practice includes all analysts and data scientists who are interested in adopting the working practices included in reproducible analytical pipelines (RAP) at NHS Digital.
 50 Dec 22, 2022
50 Dec 22, 2022
Medical appointments No-Show classifier
Medical Appointments No-shows Why do 20% of patients miss their scheduled appointments? A person makes a doctor appointment, receives all the instruct
 4 Apr 20, 2022
4 Apr 20, 2022
It is a Blender Tool which can convert the Object Data Attributes in face corner to the UVs or Vertex Color.
Blender_ObjectDataAttributesConvertTool It is a Blender Tool which can convert the Object Data Attributes in face corner to the UVs or Vertex Color. D
 2 Jan 8, 2022
2 Jan 8, 2022
Codeflare - Scale complex AI/ML pipelines anywhere
Scale complex AI/ML pipelines anywhere CodeFlare is a framework to simplify the integration, scaling and acceleration of complex multi-step analytics
 169 Nov 29, 2022
169 Nov 29, 2022
Cleaning-utils - a collection of small Python functions and classes which make cleaning pipelines shorter and easier
cleaning-utils [] [] [] cleaning-utils is a collection of small Python functions
 4 Aug 31, 2022
4 Aug 31, 2022
whylogs: A Data and Machine Learning Logging Standard
whylogs: A Data and Machine Learning Logging Standard whylogs is an open source standard for data and ML logging whylogs logging agent is the easiest
 2k Jan 6, 2023
2k Jan 6, 2023

PyTorch Implementation for Deep Metric Learning Pipelines
Easily Extendable Basic Deep Metric Learning Pipeline Karsten Roth ([email protected]), Biagio Brattoli ([email protected]) When using thi
 543 Jan 4, 2023
543 Jan 4, 2023
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size.
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size. The hub data layout enables rapid transformations and streaming of data while training models at scale. Hub is used by Google, Waymo, Red Cross, Oxford University, and Omdena.
 5.1k Jan 8, 2023
5.1k Jan 8, 2023
pypyr task-runner cli & api for automation pipelines.
pypyr task-runner cli & api for automation pipelines. Automate anything by combining commands, different scripts in different languages & applications into one pipeline process.
 471 Dec 15, 2022
471 Dec 15, 2022
The DL Streamer Pipeline Zoo is a catalog of optimized media and media analytics pipelines.
The DL Streamer Pipeline Zoo is a catalog of optimized media and media analytics pipelines. It includes tools for downloading pipelines and their dependencies and tools for measuring their performace.
 8 Dec 4, 2022
8 Dec 4, 2022
Spline is a tool that is capable of running locally as well as part of well known pipelines like Jenkins (Jenkinsfile), Travis CI (.travis.yml) or similar ones.
Welcome to spline - the pipeline tool Important note: Since change in my job I didn't had the chance to continue on this project. My main new project
 29 Aug 22, 2022
29 Aug 22, 2022
simple way to build the declarative and destributed data pipelines with python
unipipeline simple way to build the declarative and distributed data pipelines. Why you should use it Declarative strict config Scaffolding Fully type
 0 Jan 26, 2022
0 Jan 26, 2022
Python library for creating data pipelines with chain functional programming
PyFunctional Features PyFunctional makes creating data pipelines easy by using chained functional operators. Here are a few examples of what it can do
 2.1k Jan 5, 2023
2.1k Jan 5, 2023

A C-like hardware description language (HDL) adding high level synthesis(HLS)-like automatic pipelining as a language construct/compiler feature.
██████╗ ██╗██████╗ ███████╗██╗ ██╗███╗ ██╗███████╗ ██████╗ ██╔══██╗██║██╔══██╗██╔════╝██║ ██║████╗ ██║██╔════╝██╔════╝ ██████╔╝██║██████╔╝█
 391 Jan 1, 2023
391 Jan 1, 2023
Flexible HDF5 saving/loading and other data science tools from the University of Chicago
deepdish Flexible HDF5 saving/loading and other data science tools from the University of Chicago. This repository also host a Deep Learning blog: htt
 255 Dec 10, 2022
255 Dec 10, 2022
ZenML 🙏: MLOps framework to create reproducible ML pipelines for production machine learning.
ZenML is an extensible, open-source MLOps framework to create production-ready machine learning pipelines. It has a simple, flexible syntax, is cloud and tool agnostic, and has interfaces/abstractions that are catered towards ML workflows.
2.6k Dec 27, 2022
Data pipelines for both TensorFlow and PyTorch!
rapidnlp-datasets Data pipelines for both TensorFlow and PyTorch ! If you want to load public datasets, try: tensorflow/datasets huggingface/datasets
 1 Dec 8, 2021
1 Dec 8, 2021
Upgini : data search library for your machine learning pipelines
Automated data search library for your machine learning pipelines → find & deliver relevant external data & features to boost ML accuracy :chart_with_upwards_trend:
 175 Jan 8, 2023
175 Jan 8, 2023
Media Replay Engine (MRE) is a framework to build automated video clipping and replay (highlight) generation pipelines for live and video-on-demand content.
Media Replay Engine (MRE) is a framework for building automated video clipping and replay (highlight) generation pipelines using AWS services for live
 30 Nov 29, 2022
30 Nov 29, 2022
A kedro-plugin to serve Kedro Pipelines as API
General informations Software repository Latest release Total downloads Pypi Code health Branch Tests Coverage Links Documentation Deployment Activity
 12 Jul 15, 2022
12 Jul 15, 2022
Primitives for machine learning and data science.
An Open Source Project from the Data to AI Lab, at MIT MLPrimitives Pipelines and primitives for machine learning and data science. Documentation: htt
 65 Dec 29, 2022
65 Dec 29, 2022
Code for the ECIR'22 paper "Evaluating the Robustness of Retrieval Pipelines with Query Variation Generators"
Query Variation Generators This repository contains the code and annotation data for the ECIR'22 paper "Evaluating the Robustness of Retrieval Pipelin
 12 Nov 20, 2022
12 Nov 20, 2022
Data pipelines built with polars
valves Warning: the project is very much work in progress. Valves is a collection of functions for your data .pipe()-lines. This project aimes to host
 14 Jan 3, 2023
14 Jan 3, 2023
Scikit-Learn useful pre-defined Pipelines Hub
Scikit-Pipes Scikit-Learn useful pre-defined Pipelines Hub Usage: Install scikit-pipes It's advised to install sklearn-genetic using a virtual env, in
 1 Apr 26, 2022
1 Apr 26, 2022
Deep Learning Pipelines for Apache Spark
Deep Learning Pipelines for Apache Spark The repo only contains HorovodRunner code for local CI and API docs. To use HorovodRunner for distributed tra
 2k Jan 8, 2023
2k Jan 8, 2023

A DSL for data-driven computational pipelines
"Dataflow variables are spectacularly expressive in concurrent programming" Henri E. Bal , Jennifer G. Steiner , Andrew S. Tanenbaum Quick overview Ne
 1.9k Jan 3, 2023
1.9k Jan 3, 2023

Pypeln is a simple yet powerful Python library for creating concurrent data pipelines.
Pypeln Pypeln (pronounced as "pypeline") is a simple yet powerful Python library for creating concurrent data pipelines. Main Features Simple: Pypeln
 1.4k Dec 31, 2022
1.4k Dec 31, 2022
Building house price data pipelines with Apache Beam and Spark on GCP
This project contains the process from building a web crawler to extract the raw data of house price to create ETL pipelines using Google Could Platform services.
 1 Nov 22, 2021
1 Nov 22, 2021
An orchestration platform for the development, production, and observation of data assets.
Dagster An orchestration platform for the development, production, and observation of data assets. Dagster lets you define jobs in terms of the data f
 6.2k Jan 8, 2023
6.2k Jan 8, 2023
OCR of Chicago 1909 Renumbering Plan
Requirements: Python 3 (probably at least 3.4) pipenv (pip3 install pipenv) tesseract (brew install tesseract, at least if you have a mac and homebrew
 2 Nov 21, 2021
2 Nov 21, 2021
ZenML 🙏: MLOps framework to create reproducible ML pipelines for production machine learning.
ZenML is an extensible, open-source MLOps framework to create production-ready machine learning pipelines. It has a simple, flexible syntax, is cloud and tool agnostic, and has interfaces/abstractions that are catered towards ML workflows.
2.6k Jan 8, 2023
This tool parses log data and allows to define analysis pipelines for anomaly detection.
logdata-anomaly-miner This tool parses log data and allows to define analysis pipelines for anomaly detection. It was designed to run the analysis wit
 32 Nov 27, 2022
32 Nov 27, 2022
Streamz helps you build pipelines to manage continuous streams of data
Streamz helps you build pipelines to manage continuous streams of data. It is simple to use in simple cases, but also supports complex pipelines that involve branching, joining, flow control, feedback, back pressure, and so on.
 1.1k Dec 28, 2022
1.1k Dec 28, 2022
Kubeflow is a machine learning (ML) toolkit that is dedicated to making deployments of ML workflows on Kubernetes simple, portable, and scalable.
SDK: Overview of the Kubeflow pipelines service Kubeflow is a machine learning (ML) toolkit that is dedicated to making deployments of ML workflows on
 3.1k Jan 6, 2023
3.1k Jan 6, 2023
AI pipelines for Nvidia Jetson Platform
Jetson Multicamera Pipelines Easy-to-use realtime CV/AI pipelines for Nvidia Jetson Platform. This project: Builds a typical multi-camera pipeline, i.
 96 Dec 23, 2022
96 Dec 23, 2022
PipeChain is a utility library for creating functional pipelines.
PipeChain Motivation PipeChain is a utility library for creating functional pipelines. Let's start with a motivating example. We have a list of Austra
 2 Aug 7, 2022
2 Aug 7, 2022
🎵 A repository for manually annotating files to create labeled acoustic datasets for machine learning.
🎵 A repository for manually annotating files to create labeled acoustic datasets for machine learning.
 28 Dec 22, 2022
28 Dec 22, 2022

Using machine learning to predict and analyze high and low reader engagement for New York Times articles posted to Facebook.
How The New York Times can increase Engagement on Facebook Using machine learning to understand characteristics of news content that garners "high" Fa
 0 Sep 16, 2021
0 Sep 16, 2021

QSIprep: Preprocessing and analysis of q-space images
QSIprep: Preprocessing and analysis of q-space images Full documentation at https://qsiprep.readthedocs.io About qsiprep configures pipelines for proc
 88 Dec 15, 2022
88 Dec 15, 2022

A project based example of Data pipelines, ML workflow management, API endpoints and Monitoring.
MLOps template with examples for Data pipelines, ML workflow management, API development and Monitoring.
 33 Dec 3, 2022
33 Dec 3, 2022

Multi-Branch CI/CD Pipeline using CDK Pipelines.
Using AWS CDK Pipelines and AWS Lambda for multi-branch pipeline management and infrastructure deployment. This project shows how to use the AWS CDK P
36 Dec 23, 2022
Write maintainable, production-ready pipelines using Jupyter or your favorite text editor. Develop locally, deploy to the cloud. ☁️
Write maintainable, production-ready pipelines using Jupyter or your favorite text editor. Develop locally, deploy to the cloud. ☁️
2.9k Jan 6, 2023

Pipelines de datos, 2021.
Este repo ilustra un proceso sencillo de automatización de transformación y modelado de datos, a través de un pipeline utilizando Luigi. Stack princip
 8 May 19, 2022
8 May 19, 2022

Elementary is an open-source data reliability framework for modern data teams. The first module of the framework is data lineage.
Data lineage made simple, reliable, and automated. Effortlessly track the flow of data, understand dependencies and analyze impact. Features Visualiza
898 Jan 9, 2023
A machine learning library for spiking neural networks. Supports training with both torch and jax pipelines, and deployment to neuromorphic hardware.
Rockpool Rockpool is a Python package for developing signal processing applications with spiking neural networks. Rockpool allows you to build network
 21 Dec 14, 2022
21 Dec 14, 2022

Kedro is an open-source Python framework for creating reproducible, maintainable and modular data science code
A Python framework for creating reproducible, maintainable and modular data science code.
 7.9k Jan 1, 2023
7.9k Jan 1, 2023
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022

Demonstration of the Model Training as a CI/CD System in Vertex AI
Model Training as a CI/CD System This project demonstrates the machine model training as a CI/CD system in GCP platform. You will see more detailed wo
 19 Dec 28, 2022
19 Dec 28, 2022
Framework for creating efficient data processing pipelines
Aqueduct Framework for creating efficient data processing pipelines. Contact Feel free to ask questions in telegram t.me/avito-ml Key Features Increas
 137 Dec 29, 2022
137 Dec 29, 2022

CPOST is a CLI tool to assist with the proper sizing of Clara Deploy pipelines
CPOST (Clara Pipeline Operator Sizing Tool) Tool to measure resource usage of Clara Platform pipeline operators Cpost is a tool that will help you run
 5 Sep 27, 2021
5 Sep 27, 2021

This solution helps you deploy Data Lake Infrastructure on AWS using CDK Pipelines.
CDK Pipelines for Data Lake Infrastructure Deployment This solution helps you deploy data lake infrastructure on AWS using CDK Pipelines. This is base
66 Nov 23, 2022

🤗 Push your spaCy pipelines to the Hugging Face Hub
spacy-huggingface-hub: Push your spaCy pipelines to the Hugging Face Hub This package provides a CLI command for uploading any trained spaCy pipeline
 30 Oct 9, 2022
30 Oct 9, 2022
Tuplex is a parallel big data processing framework that runs data science pipelines written in Python at the speed of compiled code
Tuplex is a parallel big data processing framework that runs data science pipelines written in Python at the speed of compiled code. Tuplex has similar Python APIs to Apache Spark or Dask, but rather than invoking the Python interpreter, Tuplex generates optimized LLVM bytecode for the given pipeline and input data set.
 791 Jan 4, 2023
791 Jan 4, 2023
Build tensorflow keras model pipelines in a single line of code. Created by Ram Seshadri. Collaborators welcome. Permission granted upon request.
deep_autoviml Build keras pipelines and models in a single line of code! Table of Contents Motivation How it works Technology Install Usage API Image
 102 Dec 17, 2022
102 Dec 17, 2022
Orchest is a browser based IDE for Data Science.
Orchest is a browser based IDE for Data Science. It integrates your favorite Data Science tools out of the box, so you don’t have to. The application is easy to use and can run on your laptop as well as on a large scale cloud cluster.
 3.6k Jan 9, 2023
3.6k Jan 9, 2023

Cloud-native, data onboarding architecture for the Google Cloud Public Datasets program
Public Datasets Pipelines Cloud-native, data pipeline architecture for onboarding datasets to the Google Cloud Public Datasets Program. Overview Requi
109 Dec 30, 2022
geobeam - adds GIS capabilities to your Apache Beam and Dataflow pipelines.
geobeam adds GIS capabilities to your Apache Beam pipelines. What does geobeam do? geobeam enables you to ingest and analyze massive amounts of geospa
61 Nov 8, 2022
Extra blocks for scikit-learn pipelines.
scikit-lego We love scikit learn but very often we find ourselves writing custom transformers, metrics and models. The goal of this project is to atte
 941 Dec 30, 2022
941 Dec 30, 2022
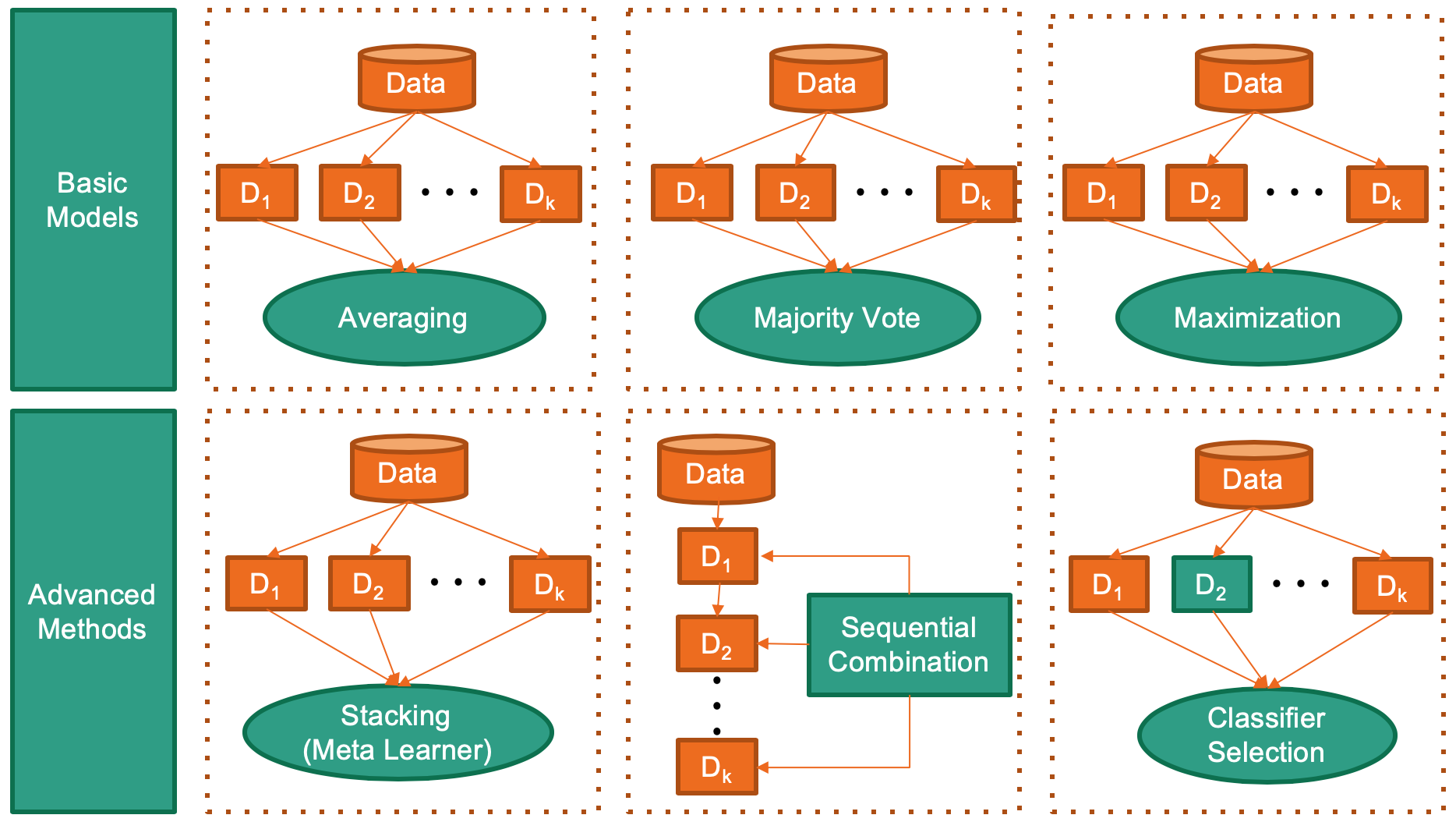
(AAAI' 20) A Python Toolbox for Machine Learning Model Combination
combo: A Python Toolbox for Machine Learning Model Combination Deployment & Documentation & Stats Build Status & Coverage & Maintainability & License
 606 Dec 21, 2022
606 Dec 21, 2022
Build, test, deploy, iterate - Dev and prod tool for data science pipelines
Prodmodel is a build system for data science pipelines. Users, testers, contributors are welcome! Motivation · Concepts · Installation · Usage · Contr
 53 Nov 29, 2022
53 Nov 29, 2022
Easy pipelines for pandas DataFrames.
pdpipe ˨ Easy pipelines for pandas DataFrames (learn how!). Website: https://pdpipe.github.io/pdpipe/ Documentation: https://pdpipe.github.io/pdpipe/d
 694 Jan 5, 2023
694 Jan 5, 2023
Machine Learning Platform for Kubernetes
Reproduce, Automate, Scale your data science. Welcome to Polyaxon, a platform for building, training, and monitoring large scale deep learning applica
 3.2k Dec 23, 2022
3.2k Dec 23, 2022
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
Master status: Development status: Package information: TPOT stands for Tree-based Pipeline Optimization Tool. Consider TPOT your Data Science Assista
 8.9k Jan 9, 2023
8.9k Jan 9, 2023
Cookiecutter template for FastAPI projects using: Machine Learning, Poetry, Azure Pipelines and Pytests
cookiecutter-fastapi In order to create a template to FastAPI projects. 🚀 Important To use this project you don't need fork it. Just run cookiecutter
 225 Dec 28, 2022
225 Dec 28, 2022
Run your jupyter notebooks as a REST API endpoint. This isn't a jupyter server but rather just a way to run your notebooks as a REST API Endpoint.
Jupter Notebook REST API Run your jupyter notebooks as a REST API endpoint. This isn't a jupyter server but rather just a way to run your notebooks as
 54 Nov 4, 2022
54 Nov 4, 2022

Command line driven CI frontend and development task automation tool.
tox automation project Command line driven CI frontend and development task automation tool At its core tox provides a convenient way to run arbitrary
 3.1k Jan 4, 2023
3.1k Jan 4, 2023
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
Master status: Development status: Package information: TPOT stands for Tree-based Pipeline Optimization Tool. Consider TPOT your Data Science Assista
8.9k Dec 30, 2022
[UNMAINTAINED] Automated machine learning for analytics & production
auto_ml Automated machine learning for production and analytics Installation pip install auto_ml Getting started from auto_ml import Predictor from au
 1.6k Jan 2, 2023
1.6k Jan 2, 2023
Unified Interface for Constructing and Managing Workflows on different workflow engines, such as Argo Workflows, Tekton Pipelines, and Apache Airflow.
Couler What is Couler? Couler aims to provide a unified interface for constructing and managing workflows on different workflow engines, such as Argo
 781 Jan 3, 2023
781 Jan 3, 2023

Luigi is a Python module that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization etc. It also comes with Hadoop support built in.
Luigi is a Python (3.6, 3.7 tested) package that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow managemen
 16.2k Jan 1, 2023
16.2k Jan 1, 2023