1194 Repositories
Python video-search Libraries

Recon is a script to perform a full recon on a target with the main tools to search for vulnerabilities.
👑 Recon 👑 The step of recognizing a target in both Bug Bounties and Pentest can be very time-consuming. Thinking about it, I decided to create my ow
 171 Dec 31, 2022
171 Dec 31, 2022
Music and video downloader, Made with love by Bryan Herrera
Python-Mp3Mp4-Downloader Music and video downloader, Made with love by Bryan Herrera Requirements CHOCOLATELY windows command If your system does not
 104 Dec 27, 2022
104 Dec 27, 2022
Deep Image Search is an AI-based image search engine that includes deep transfor learning features Extraction and tree-based vectorized search.
Deep Image Search - AI-Based Image Search Engine Deep Image Search is an AI-based image search engine that includes deep transfer learning features Ex
 139 Jan 1, 2023
139 Jan 1, 2023

search different Streaming Platforms for movie titles.
Install git clone and cd to directory install Selenium download chromedriver.exe to same directory First Run Use --setup True for the first run. Platf
 34 Dec 25, 2022
34 Dec 25, 2022
Implementation of "Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification"
hypergraph_reid Implementation of "Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification" If you find this help your research,
 62 Dec 21, 2022
62 Dec 21, 2022
The implemention of Video Depth Estimation by Fusing Flow-to-Depth Proposals
Flow-to-depth (FDNet) video-depth-estimation This is the implementation of paper Video Depth Estimation by Fusing Flow-to-Depth Proposals Jiaxin Xie,
 32 Jun 14, 2022
32 Jun 14, 2022

A Joint Video and Image Encoder for End-to-End Retrieval
Frozen️ in Time ❄️ ️️️️ ⏳ A Joint Video and Image Encoder for End-to-End Retrieval (arXiv) Repository to contain the code, models, data for end-to-end
 225 Dec 25, 2022
225 Dec 25, 2022

Code for ECCV 2020 paper "Contacts and Human Dynamics from Monocular Video".
Contact and Human Dynamics from Monocular Video This is the official implementation for the ECCV 2020 spotlight paper by Davis Rempe, Leonidas J. Guib
 207 Jan 5, 2023
207 Jan 5, 2023
Inference code for "StylePeople: A Generative Model of Fullbody Human Avatars" paper. This code is for the part of the paper describing video-based avatars.
NeuralTextures This is repository with inference code for paper "StylePeople: A Generative Model of Fullbody Human Avatars" (CVPR21). This code is for
 18 Oct 6, 2022
18 Oct 6, 2022
A Telegram bot to convert videos into x265/x264 format via ffmpeg.
Video Encoder Bot A Telegram bot to convert videos into x265/x264 format via ffmpeg. Configuration Add values in environment variables or add them in
 82 Jan 3, 2023
82 Jan 3, 2023

✖️ Unofficial API of 1337x.to
✖️ Unofficial Python API Wrapper of 1337x This is the unofficial API of 1337x. It supports all proxies of 1337x and almost all functions of 1337x. You
 71 Dec 26, 2022
71 Dec 26, 2022
Deep learning (neural network) based remote photoplethysmography: how to extract pulse signal from video using deep learning tools
Deep-rPPG: Camera-based pulse estimation using deep learning tools Deep learning (neural network) based remote photoplethysmography: how to extract pu
 138 Dec 17, 2022
138 Dec 17, 2022

Discord Bot that leverages the idea of nested containers using podman, runs untrusted user input, executes Quantum Circuits, allows users to refer to the Qiskit Documentation, and provides the ability to search questions on the Quantum Computing StackExchange.
Discord Bot that leverages the idea of nested containers using podman, runs untrusted user input, executes Quantum Circuits, allows users to refer to the Qiskit Documentation, and provides the ability to search questions on the Quantum Computing StackExchange.
 23 Oct 18, 2022
23 Oct 18, 2022
A Simple Telegram Inline Torrent Search Bot by @AbirHasan2005
A Simple Telegram Inline Torrent Search Bot by @AbirHasan2005
 61 Oct 28, 2022
61 Oct 28, 2022
Implementation of Stochastic Image-to-Video Synthesis using cINNs.
Stochastic Image-to-Video Synthesis using cINNs Official PyTorch implementation of Stochastic Image-to-Video Synthesis using cINNs accepted to CVPR202
 135 Dec 28, 2022
135 Dec 28, 2022
Vowpal Wabbit is a machine learning system which pushes the frontier of machine learning with techniques
Vowpal Wabbit is a machine learning system which pushes the frontier of machine learning with techniques such as online, hashing, allreduce, reductions, learning2search, active, and interactive learning.
 8.1k Dec 30, 2022
8.1k Dec 30, 2022

Code for paper 'Audio-Driven Emotional Video Portraits'.
Audio-Driven Emotional Video Portraits [CVPR2021] Xinya Ji, Zhou Hang, Kaisiyuan Wang, Wayne Wu, Chen Change Loy, Xun Cao, Feng Xu [Project] [Paper] G
 197 Dec 31, 2022
197 Dec 31, 2022
![[CVPR21] LightTrack: Finding Lightweight Neural Network for Object Tracking via One-Shot Architecture Search](https://github.com/researchmm/LightTrack/raw/main/Archs.gif)
[CVPR21] LightTrack: Finding Lightweight Neural Network for Object Tracking via One-Shot Architecture Search
LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search The official implementation of the paper LightTra
 290 Dec 24, 2022
290 Dec 24, 2022

QueryInst: Parallelly Supervised Mask Query for Instance Segmentation
QueryInst is a simple and effective query based instance segmentation method driven by parallel supervision on dynamic mask heads, which outperforms previous arts in terms of both accuracy and speed.
 386 Jan 8, 2023
386 Jan 8, 2023

Code for "ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on", accepted at WACV 2021 Generation of Human Behavior Workshop.
ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on [ Paper ] [ Project Page ] This repository contains the code fo
 97 Dec 13, 2022
97 Dec 13, 2022
![[NeurIPS 2020] Blind Video Temporal Consistency via Deep Video Prior](https://github.com/yzxing87/pytorch-deep-video-prior/raw/main/example/example_in.gif)
[NeurIPS 2020] Blind Video Temporal Consistency via Deep Video Prior
pytorch-deep-video-prior (DVP) Official PyTorch implementation for NeurIPS 2020 paper: Blind Video Temporal Consistency via Deep Video Prior TensorFlo
 90 Oct 19, 2022
90 Oct 19, 2022
Awesome Video Datasets
Awesome Video Datasets
 462 Jan 2, 2023
462 Jan 2, 2023
Automatically create Faiss knn indices with the most optimal similarity search parameters.
It selects the best indexing parameters to achieve the highest recalls given memory and query speed constraints.
 419 Jan 1, 2023
419 Jan 1, 2023
Ray provides a simple, universal API for building distributed applications.
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
 23.5k Jan 5, 2023
23.5k Jan 5, 2023
An easier way to build neural search on the cloud
Jina is geared towards building search systems for any kind of data, including text, images, audio, video and many more. With the modular design & multi-layer abstraction, you can leverage the efficient patterns to build the system by parts, or chaining them into a Flow for an end-to-end experience.
 17k Jan 1, 2023
17k Jan 1, 2023

A simple image/video to Desmos graph converter run locally
Desmos Bezier Renderer A simple image/video to Desmos graph converter run locally Sample Result Setup Install dependencies apt update apt install git
 339 Dec 23, 2022
339 Dec 23, 2022

CLI utility to search and download torrents from major torrent sites
CLI Torrent Downloader About CLI Torrent Downloader provides convenient and quick way to search torrent magnet links (and to run associated torrent cl
 86 Dec 19, 2022
86 Dec 19, 2022

All in one Search Engine Scrapper for used by API or Python Module. It's Free!
All in one Search Engine Scrapper for used by API or Python Module. How to use: Video Documentation Senginta is All in one Search Engine Scrapper. Wit
 33 Nov 21, 2022
33 Nov 21, 2022
LightSeq: A High-Performance Inference Library for Sequence Processing and Generation
LightSeq is a high performance inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT2, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, and other related tasks using these models.
 2.5k Jan 3, 2023
2.5k Jan 3, 2023
Implementation of "Efficient Regional Memory Network for Video Object Segmentation" (Xie et al., CVPR 2021).
RMNet This repository contains the source code for the paper Efficient Regional Memory Network for Video Object Segmentation. Cite this work @inprocee
 76 Dec 14, 2022
76 Dec 14, 2022
[CVPR 2021] MiVOS - Mask Propagation module. Reproduced STM (and better) with training code :star2:. Semi-supervised video object segmentation evaluation.
MiVOS (CVPR 2021) - Mask Propagation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [arXiv] [Paper PDF] [Project Page] [Papers with Code] This repo impleme
 106 Jan 3, 2023
106 Jan 3, 2023

Official Pytorch implementation of "Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video", CVPR 2021
TCMR: Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video Qualtitative result Paper teaser video Introduction This r
 215 Jan 6, 2023
215 Jan 6, 2023
"NAS-Bench-301 and the Case for Surrogate Benchmarks for Neural Architecture Search".
NAS-Bench-301 This repository containts code for the paper: "NAS-Bench-301 and the Case for Surrogate Benchmarks for Neural Architecture Search". The
 57 Nov 30, 2022
57 Nov 30, 2022
Semi-supervised Video Deraining with Dynamical Rain Generator (CVPR, 2021, Pytorch)
S2VD Semi-supervised Video Deraining with Dynamical Rain Generator (CVPR, 2021) Requirements and Dependencies Ubuntu 16.04, cuda 10.0 Python 3.6.10, P
 53 Nov 23, 2022
53 Nov 23, 2022
This is a simple collection of instructions and scripts to accompany the computerphile video about mininet and openflow.
How to get going. This project should work on Linux or MacOS. I used Ubuntu 20.04 and provide some notes here. Note, this is certainly not intended as
 70 Jan 2, 2023
70 Jan 2, 2023

An official implementation for "CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval"
The implementation of paper CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval. CLIP4Clip is a video-text retrieval model based
 456 Jan 6, 2023
456 Jan 6, 2023
[TIP2020] Adaptive Graph Representation Learning for Video Person Re-identification
Introduction This is the PyTorch implementation for Adaptive Graph Representation Learning for Video Person Re-identification. Get started git clone h
 41 Dec 12, 2022
41 Dec 12, 2022
The official pytorch implemention of the CVPR paper "Temporal Modulation Network for Controllable Space-Time Video Super-Resolution".
This is the official PyTorch implementation of TMNet in the CVPR 2021 paper "Temporal Modulation Network for Controllable Space-Time VideoSuper-Resolu
 95 Oct 24, 2022
95 Oct 24, 2022

TorchPQ is a python library for Approximate Nearest Neighbor Search (ANNS) and Maximum Inner Product Search (MIPS) on GPU using Product Quantization (PQ) algorithm.
Efficient implementations of Product Quantization and its variants using Pytorch and CUDA
 146 Dec 28, 2022
146 Dec 28, 2022

code for paper "Does Unsupervised Architecture Representation Learning Help Neural Architecture Search?"
Does Unsupervised Architecture Representation Learning Help Neural Architecture Search? Code for paper: Does Unsupervised Architecture Representation
 39 Dec 17, 2022
39 Dec 17, 2022

Training code of Spatial Time Memory Network. Semi-supervised video object segmentation.
Training-code-of-STM This repository fully reproduces Space-Time Memory Networks Performance on Davis17 val set&Weights backbone training stage traini
 128 Dec 11, 2022
128 Dec 11, 2022
Activity image-based video retrieval
Cross-modal-retrieval Our approach is focus on Activity Image-to-Video Retrieval (AIVR) task. The compared methods are state-of-the-art single modalit
 75 Oct 21, 2021
75 Oct 21, 2021
Syntax-Aware Action Targeting for Video Captioning
Syntax-Aware Action Targeting for Video Captioning Code for SAAT from "Syntax-Aware Action Targeting for Video Captioning" (Accepted to CVPR 2020). Th
 59 Oct 13, 2022
59 Oct 13, 2022
OCTIS: Comparing Topic Models is Simple! A python package to optimize and evaluate topic models (accepted at EACL2021 demo track)
OCTIS : Optimizing and Comparing Topic Models is Simple! OCTIS (Optimizing and Comparing Topic models Is Simple) aims at training, analyzing and compa
 478 Jan 1, 2023
478 Jan 1, 2023

TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks
TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks [Paper] [Project Website] This repository holds the source code, pretra
 83 Dec 21, 2022
83 Dec 21, 2022

VideoGPT: Video Generation using VQ-VAE and Transformers
VideoGPT: Video Generation using VQ-VAE and Transformers [Paper][Website][Colab][Gradio Demo] We present VideoGPT: a conceptually simple architecture
 470 Dec 30, 2022
470 Dec 30, 2022

It is a simple python package to play videos in the terminal using characters as pixels
It is a simple python package to play videos in the terminal using characters as pixels
 1.4k Jan 7, 2023
1.4k Jan 7, 2023

This repository allows you to anonymize sensitive information in images/videos. The solution is fully compatible with the DL-based training/inference solutions that we already published/will publish for Object Detection and Semantic Segmentation.
BMW-Anonymization-Api Data privacy and individuals’ anonymity are and always have been a major concern for data-driven companies. Therefore, we design
 148 Dec 21, 2022
148 Dec 21, 2022

Diffgram - Supervised Learning Data Platform
Data Annotation, Data Labeling, Annotation Tooling, Training Data for Machine Learning
 1.6k Jan 7, 2023
1.6k Jan 7, 2023
The official pytorch implementation of our paper "Is Space-Time Attention All You Need for Video Understanding?"
TimeSformer This is an official pytorch implementation of Is Space-Time Attention All You Need for Video Understanding?. In this repository, we provid
 1k Dec 31, 2022
1k Dec 31, 2022

MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images
Main repo for ECCV 2020 paper MatryODShka: Real-time 6DoF Video View Synthesis using Multi-Sphere Images. visual.cs.brown.edu/matryodshka
 75 Dec 13, 2022
75 Dec 13, 2022
OpenMMLab's Next Generation Video Understanding Toolbox and Benchmark
Introduction English | 简体中文 MMAction2 is an open-source toolbox for video understanding based on PyTorch. It is a part of the OpenMMLab project. The m
 2.7k Jan 7, 2023
2.7k Jan 7, 2023
OpenMMLab Image and Video Editing Toolbox
Introduction MMEditing is an open source image and video editing toolbox based on PyTorch. It is a part of the OpenMMLab project. The master branch wo
3.9k Jan 4, 2023
An end-to-end PyTorch framework for image and video classification
What's New: March 2021: Added RegNetZ models November 2020: Vision Transformers now available, with training recipes! 2020-11-20: Classy Vision v0.5 R
1.5k Dec 31, 2022
PyTorchVideo is a deeplearning library with a focus on video understanding work
PyTorchVideo is a deeplearning library with a focus on video understanding work. PytorchVideo provides resusable, modular and efficient components needed to accelerate the video understanding research. PyTorchVideo is developed using PyTorch and supports different deeplearning video components like video models, video datasets, and video-specific transforms.
2.7k Jan 7, 2023

3D ResNet Video Classification accelerated by TensorRT
Activity Recognition TensorRT Perform video classification using 3D ResNets trained on Kinetics-400 dataset and accelerated with TensorRT P.S Click on
 39 Nov 21, 2022
39 Nov 21, 2022
Pixel art search engine for opengameart
Pixel Art Reverse Image Search for OpenGameArt What does the final search look like? The final search with an example can be found here. It looks like
 92 Nov 6, 2022
92 Nov 6, 2022

FireDM is a python open source (Internet Download Manager) with multi-connections, high speed engine, it downloads general files and videos from youtube and tons of other streaming websites .
python open source (Internet Download Manager) with multi-connections, high speed engine, based on python, LibCurl, and youtube_dl https://github.com/firedm/FireDM
 1.6k Apr 12, 2022
1.6k Apr 12, 2022
A utility to search, download and process Landsat 8 satellite imagery
Landsat-util Landsat-util is a command line utility that makes it easy to search, download, and process Landsat imagery. Docs For full documentation v
 681 Dec 7, 2022
681 Dec 7, 2022

Code for AAAI 2021 paper: Sequential End-to-end Network for Efficient Person Search
This repository hosts the source code of our paper: [AAAI 2021]Sequential End-to-end Network for Efficient Person Search. SeqNet achieves the state-of
 218 Dec 31, 2022
218 Dec 31, 2022
Bulk Downloader for Reddit
saveddit is a bulk media downloader for reddit pip3 install saveddit Setting up authorization Register an application with Reddit Write down your clie
 136 Jan 3, 2023
136 Jan 3, 2023

Implementation of ViViT: A Video Vision Transformer
ViViT: A Video Vision Transformer Unofficial implementation of ViViT: A Video Vision Transformer. Notes: This is in WIP. Model 2 is implemented, Model
 297 Jan 6, 2023
297 Jan 6, 2023
![[AAAI 2021] MVFNet: Multi-View Fusion Network for Efficient Video Recognition](https://github.com/whwu95/MVFNet/raw/main/mvfnet.png)
[AAAI 2021] MVFNet: Multi-View Fusion Network for Efficient Video Recognition
MVFNet: Multi-View Fusion Network for Efficient Video Recognition (AAAI 2021) Overview We release the code of the MVFNet (Multi-View Fusion Network).
 114 Nov 27, 2022
114 Nov 27, 2022

Official implementation for NIPS'17 paper: PredRNN: Recurrent Neural Networks for Predictive Learning Using Spatiotemporal LSTMs.
PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning The predictive learning of spatiotemporal sequences aims to generate future
 243 Dec 26, 2022
243 Dec 26, 2022
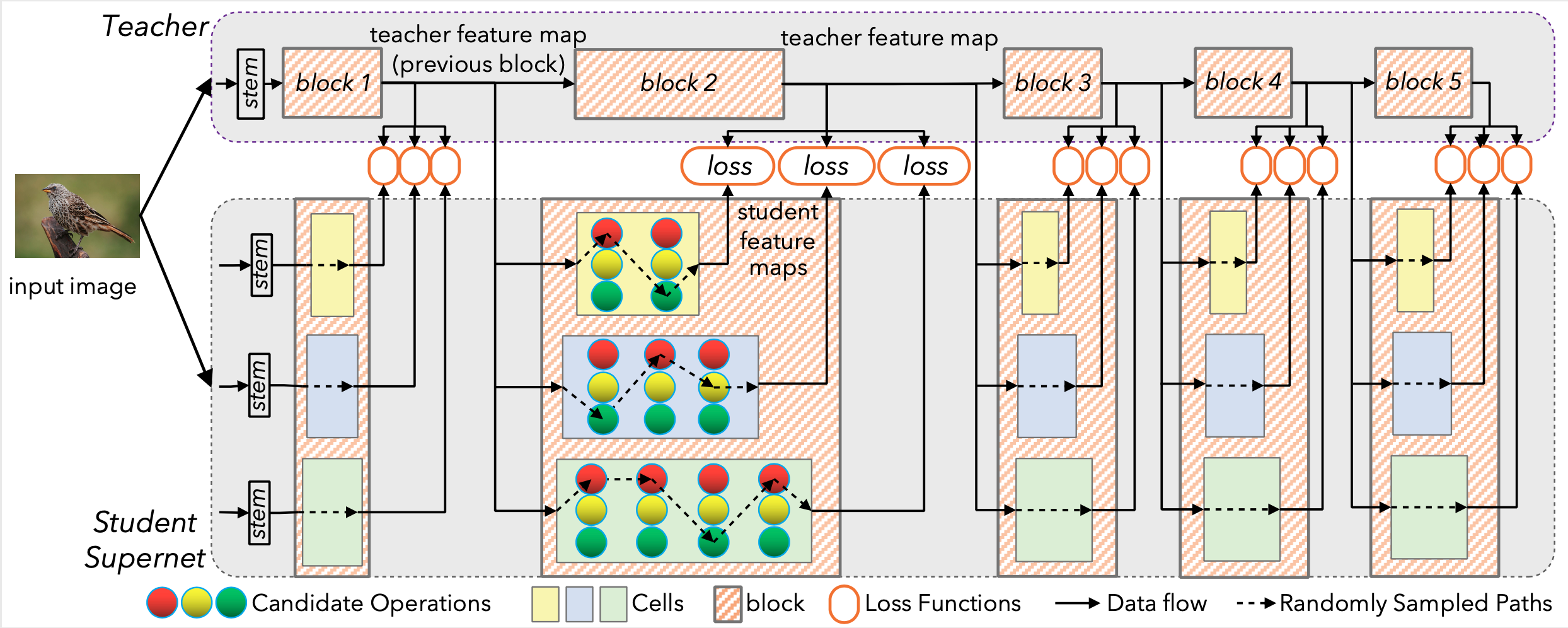
Block-wisely Supervised Neural Architecture Search with Knowledge Distillation (CVPR 2020)
DNA This repository provides the code of our paper: Blockwisely Supervised Neural Architecture Search with Knowledge Distillation. Illustration of DNA
 215 Dec 19, 2022
215 Dec 19, 2022

Code for "NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video", CVPR 2021 oral
NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video Project Page | Paper NeuralRecon: Real-Time Coherent 3D Reconstruction from Mon
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023

SimDeblur is a simple framework for image and video deblurring, implemented by PyTorch
SimDeblur (Simple Deblurring) is an open source framework for image and video deblurring toolbox based on PyTorch, which contains most deep-learning based state-of-the-art deblurring algorithms. It is easy to implement your own image or video deblurring or other restoration algorithms.
 220 Jan 7, 2023
220 Jan 7, 2023

Official implementation of Rethinking Graph Neural Architecture Search from Message-passing (CVPR2021)
Rethinking Graph Neural Architecture Search from Message-passing Intro The GNAS can automatically learn better architecture with the optimal depth of
 48 Sep 30, 2022
48 Sep 30, 2022
Search twitter by address.
Twitter Geolocate Twitter Geolocation is a console app that generates twitter search querries for a certain geolocation and opens them in your standar
 28 Dec 6, 2022
28 Dec 6, 2022
Official implementation of "An Image is Worth 16x16 Words, What is a Video Worth?" (2021 paper)
An Image is Worth 16x16 Words, What is a Video Worth? paper Official PyTorch Implementation Gilad Sharir, Asaf Noy, Lihi Zelnik-Manor DAMO Academy, Al
 213 Nov 12, 2022
213 Nov 12, 2022
Privacy enhanced BitTorrent client with P2P content discovery
Tribler Towards making Bittorrent anonymous and impossible to shut down. We use our own dedicated Tor-like network for anonymous torrent downloading.
 4.2k Dec 31, 2022
4.2k Dec 31, 2022
Command-line program to download videos from YouTube.com and other video sites
youtube-dl - download videos from youtube.com or other video platforms
 116.4k Jan 7, 2023
116.4k Jan 7, 2023

Deep Multimodal Neural Architecture Search
MMNas: Deep Multimodal Neural Architecture Search This repository corresponds to the PyTorch implementation of the MMnas for visual question answering
 23 Dec 21, 2022
23 Dec 21, 2022

Implementation of STAM (Space Time Attention Model), a pure and simple attention model that reaches SOTA for video classification
STAM - Pytorch Implementation of STAM (Space Time Attention Model), yet another pure and simple SOTA attention model that bests all previous models in
 109 Dec 28, 2022
109 Dec 28, 2022
A Telegram Video Watermark Adder Bot in Pyrogram by @AbirHasan2005
Watermark-Bot A Telegram Video Watermark Adder Bot by @AbirHasan2005 Features: Save Custom Watermark Image. Auto Resize Watermark According to Video q
95 Nov 20, 2022
Hybrid Neural Fusion for Full-frame Video Stabilization
FuSta: Hybrid Neural Fusion for Full-frame Video Stabilization Project Page | Video | Paper | Google Colab Setup Setup environment for [Yu and Ramamoo
 430 Jan 4, 2023
430 Jan 4, 2023

This code extends the neural style transfer image processing technique to video by generating smooth transitions between several reference style images
Neural Style Transfer Transition Video Processing By Brycen Westgarth and Tristan Jogminas Description This code extends the neural style transfer ima
 110 Jan 7, 2023
110 Jan 7, 2023
Streamlink is a CLI utility which pipes video streams from various services into a video player
Streamlink is a CLI utility which pipes video streams from various services into a video player
 8.2k Dec 26, 2022
8.2k Dec 26, 2022

Rembg Video Virtual Green Screen Edition
Rembg Virtual Greenscreen Edition is a tool to create a green screen matte for videos
 61 Mar 28, 2021
61 Mar 28, 2021
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
Ray provides a simple, universal API for building distributed applications. Ray is packaged with the following libraries for accelerating machine lear
23.3k Dec 31, 2022
Search and download Copernicus Sentinel satellite images
sentinelsat Sentinelsat makes searching, downloading and retrieving the metadata of Sentinel satellite images from the Copernicus Open Access Hub easy
 837 Dec 28, 2022
837 Dec 28, 2022
An easier way to build neural search on the cloud
An easier way to build neural search on the cloud Jina is a deep learning-powered search framework for building cross-/multi-modal search systems (e.g
17k Jan 2, 2023

BossNAS: Exploring Hybrid CNN-transformers with Block-wisely Self-supervised Neural Architecture Search
BossNAS This repository contains PyTorch evaluation code, retraining code and pretrained models of our paper: BossNAS: Exploring Hybrid CNN-transforme
127 Dec 26, 2022
Conversion of Image, video, text into ASCII format
asciju Python package that converts image to ascii Free software: MIT license
 11 Aug 22, 2022
11 Aug 22, 2022

Code for CVPR 2021 paper: Anchor-Free Person Search
Introduction This is the implementationn for Anchor-Free Person Search in CVPR2021 License This project is released under the Apache 2.0 license. Inst
158 Jan 4, 2023

Source code of our TPAMI'21 paper Dual Encoding for Video Retrieval by Text and CVPR'19 paper Dual Encoding for Zero-Example Video Retrieval.
Dual Encoding for Video Retrieval by Text Source code of our TPAMI'21 paper Dual Encoding for Video Retrieval by Text and CVPR'19 paper Dual Encoding
 81 Dec 1, 2022
81 Dec 1, 2022
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023
A collection of resources (including the papers and datasets) of OCR (Optical Character Recognition).
OCR Resources This repository contains a collection of resources (including the papers and datasets) of OCR (Optical Character Recognition). Contents
 363 Jan 3, 2023
363 Jan 3, 2023
About A python based Apple Quicktime protocol,you can record audio and video from real iOS devices
介绍 本应用程序使用 python 实现,可以通过 USB 连接 iOS 设备进行屏幕共享 高帧率(30〜60fps) 高画质 低延迟(200ms) 非侵入性 支持多设备并行 Mac OSX 安装 python =3.7 brew install libusb pkg-config 如需使用 g
 124 Nov 30, 2022
124 Nov 30, 2022
code for "AttentiveNAS Improving Neural Architecture Search via Attentive Sampling"
AttentiveNAS: Improving Neural Architecture Search via Attentive Sampling This repository contains PyTorch evaluation code, training code and pretrain
94 Oct 26, 2022
[CVPR 2021] Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
[CVPR 2021] Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
364 Jan 3, 2023

Unofficial implementation of "TTNet: Real-time temporal and spatial video analysis of table tennis" (CVPR 2020)
TTNet-Pytorch The implementation for the paper "TTNet: Real-time temporal and spatial video analysis of table tennis" An introduction of the project c
 438 Dec 29, 2022
438 Dec 29, 2022
![[ICLR 2021] HW-NAS-Bench: Hardware-Aware Neural Architecture Search Benchmark](https://github.com/RICE-EIC/HW-NAS-Bench/raw/main/devices.jpg?raw=true)
[ICLR 2021] HW-NAS-Bench: Hardware-Aware Neural Architecture Search Benchmark
HW-NAS-Bench: Hardware-Aware Neural Architecture Search Benchmark Accepted as a spotlight paper at ICLR 2021. Table of content File structure Prerequi
 72 Jan 3, 2023
72 Jan 3, 2023
Simple screen recorder
Kooha Simple screen recorder Description Kooha is a simple screen recorder built with GTK. It allows you to record your screen and also audio from you
 1.2k Jan 3, 2023
1.2k Jan 3, 2023

Automatically search Stack Overflow for the command you want to run
stackshell Automatically search Stack Overflow (and other Stack Exchange sites) for the command you want to ru Use the up and down arrows to change be
 22 Oct 27, 2021
22 Oct 27, 2021

FLAVR is a fast, flow-free frame interpolation method capable of single shot multi-frame prediction
FLAVR is a fast, flow-free frame interpolation method capable of single shot multi-frame prediction. It uses a customized encoder decoder architecture with spatio-temporal convolutions and channel gating to capture and interpolate complex motion trajectories between frames to generate realistic high frame rate videos. This repository contains original source code for the paper accepted to CVPR 2021.
 280 Dec 23, 2022
280 Dec 23, 2022
Privacy-respecting metasearch engine
Privacy-respecting, hackable metasearch engine / pronunciation səːks. If you are looking for running instances, ready to use, then visit searx.space.
 12.4k Jan 8, 2023
12.4k Jan 8, 2023
![[CVPR2021 Oral] End-to-End Video Instance Segmentation with Transformers](https://user-images.githubusercontent.com/16319629/110786946-b99aa080-82a7-11eb-98e4-85478ca4eeac.png)
[CVPR2021 Oral] End-to-End Video Instance Segmentation with Transformers
VisTR: End-to-End Video Instance Segmentation with Transformers This is the official implementation of the VisTR paper: Installation We provide instru
 687 Jan 7, 2023
687 Jan 7, 2023