2441 Repositories
Python video-to-image-converter Libraries

Fix Twitter video embeds in Discord
TwitFix very basic flask server that fixes twitter embeds in discord by using youtube-dl to grab the direct link to the MP4 file and embeds the link t
 682 Dec 28, 2022
682 Dec 28, 2022
Download images from forum threads
Forum Image Scraper Downloads images from forum threads Only works with forums which doesn't require a login to view and have an incremental paginatio
 9 Nov 16, 2022
9 Nov 16, 2022

Just playing with getting VQGAN+CLIP running locally, rather than having to use colab.
Just playing with getting VQGAN+CLIP running locally, rather than having to use colab.
 2.3k Jan 4, 2023
2.3k Jan 4, 2023
A curated list of papers, code and resources pertaining to image composition
A curated list of resources including papers, datasets, and relevant links pertaining to image composition.
 391 Dec 30, 2022
391 Dec 30, 2022
PyTorch implementation of Graph Convolutional Networks in Feature Space for Image Deblurring and Super-resolution, IJCNN 2021.
GCResNet PyTorch implementation of Graph Convolutional Networks in Feature Space for Image Deblurring and Super-resolution, IJCNN 2021. The code will
 11 May 19, 2022
11 May 19, 2022
I-SECRET: Importance-guided fundus image enhancement via semi-supervised contrastive constraining
I-SECRET This is the implementation of the MICCAI 2021 Paper "I-SECRET: Importance-guided fundus image enhancement via semi-supervised contrastive con
 13 Dec 2, 2022
13 Dec 2, 2022

SDL: Synthetic Document Layout dataset
SDL is the project that synthesizes document images. It facilitates multiple-level labeling on document images and can generate in multiple languages.
 0 Oct 7, 2021
0 Oct 7, 2021
Code for the CVPR 2021 paper "Triple-cooperative Video Shadow Detection"
Triple-cooperative Video Shadow Detection Code and dataset for the CVPR 2021 paper "Triple-cooperative Video Shadow Detection"[arXiv link] [official l
 24 Oct 4, 2022
24 Oct 4, 2022

Global Filter Networks for Image Classification
Global Filter Networks for Image Classification Created by Yongming Rao, Wenliang Zhao, Zheng Zhu, Jiwen Lu, Jie Zhou This repository contains PyTorch
 273 Dec 26, 2022
273 Dec 26, 2022

Code for "Learning Canonical Representations for Scene Graph to Image Generation", Herzig & Bar et al., ECCV2020
Learning Canonical Representations for Scene Graph to Image Generation (ECCV 2020) Roei Herzig*, Amir Bar*, Huijuan Xu, Gal Chechik, Trevor Darrell, A
 24 Jul 7, 2022
24 Jul 7, 2022
![Patch2Pix: Epipolar-Guided Pixel-Level Correspondences [CVPR2021]](https://github.com/GrumpyZhou/patch2pix/raw/main/patch2pix.png)
Patch2Pix: Epipolar-Guided Pixel-Level Correspondences [CVPR2021]
Patch2Pix for Accurate Image Correspondence Estimation This repository contains the Pytorch implementation of our paper accepted at CVPR2021: Patch2Pi
 199 Nov 29, 2022
199 Nov 29, 2022
Source code for models described in the paper "AudioCLIP: Extending CLIP to Image, Text and Audio" (https://arxiv.org/abs/2106.13043)
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
 458 Jan 2, 2023
458 Jan 2, 2023
Codes for paper "Towards Diverse Paragraph Captioning for Untrimmed Videos". CVPR 2021
Towards Diverse Paragraph Captioning for Untrimmed Videos This repository contains PyTorch implementation of our paper Towards Diverse Paragraph Capti
 61 Oct 11, 2022
61 Oct 11, 2022

This is the official repo for TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transformations at CVPR'21. According to some product reasons, we are not planning to release the training/testing codes and models. However, we will release the dataset and the scripts to prepare the dataset.
TransFill-Reference-Inpainting This is the official repo for TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transf
 80 Dec 8, 2022
80 Dec 8, 2022

Official Implementation of CoSMo: Content-Style Modulation for Image Retrieval with Text Feedback
CoSMo.pytorch Official Implementation of CoSMo: Content-Style Modulation for Image Retrieval with Text Feedback, Seungmin Lee*, Dongwan Kim*, Bohyung
 54 Dec 8, 2022
54 Dec 8, 2022
Robust Consistent Video Depth Estimation
[CVPR 2021] Robust Consistent Video Depth Estimation This repository contains Python and C++ implementation of Robust Consistent Video Depth, as descr
 213 Dec 17, 2022
213 Dec 17, 2022

Implementation of StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation in PyTorch
StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation Implementation of StyleSpace Analysis: Disentangled Controls for StyleGAN Ima
 86 Dec 7, 2022
86 Dec 7, 2022
Convert any image into greyscale ASCII art.
Image-to-ASCII Convert any image into greyscale ASCII art.
 12 Jan 15, 2022
12 Jan 15, 2022

Official PyTorch Implementation of Embedding Transfer with Label Relaxation for Improved Metric Learning, CVPR 2021
Embedding Transfer with Label Relaxation for Improved Metric Learning Official PyTorch implementation of CVPR 2021 paper Embedding Transfer with Label
 37 Dec 6, 2022
37 Dec 6, 2022
Python library to download bulk of images from Bing.com
Python library to download bulk of images form Bing.com. This package uses async url, which makes it very fast while downloading.
 105 Dec 14, 2022
105 Dec 14, 2022
Complete U-net Implementation with keras
U Net Lowered with Keras Complete U-net Implementation with keras Original Paper Link : https://arxiv.org/abs/1505.04597 Special Implementations : The
 14 Oct 10, 2022
14 Oct 10, 2022
The codes for the work "Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation"
Swin-Unet The codes for the work "Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation"(https://arxiv.org/abs/2105.05537). A validatio
 869 Jan 7, 2023
869 Jan 7, 2023
nnDetection is a self-configuring framework for 3D (volumetric) medical object detection which can be applied to new data sets without manual intervention. It includes guides for 12 data sets that were used to develop and evaluate the performance of the proposed method.
What is nnDetection? Simultaneous localisation and categorization of objects in medical images, also referred to as medical object detection, is of hi
 365 Jan 9, 2023
365 Jan 9, 2023
Semi-Autoregressive Transformer for Image Captioning
Semi-Autoregressive Transformer for Image Captioning Requirements Python 3.6 Pytorch 1.6 Prepare data Please use git clone --recurse-submodules to clo
 23 Dec 9, 2022
23 Dec 9, 2022

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023
Implementation of FitVid video prediction model in JAX/Flax.
FitVid Video Prediction Model Implementation of FitVid video prediction model in JAX/Flax. If you find this code useful, please cite it in your paper:
 62 Nov 25, 2022
62 Nov 25, 2022
Code for the Image similarity challenge.
ISC 2021 This repository contains code for the Image Similarity Challenge 2021. Getting started The docs subdirectory has step-by-step instructions on
173 Dec 12, 2022
Cross-Modal Contrastive Learning for Text-to-Image Generation
Cross-Modal Contrastive Learning for Text-to-Image Generation This repository hosts the open source JAX implementation of XMC-GAN. Setup instructions
94 Nov 12, 2022

Blender Python - Node-based multi-line text and image flowchart
MindMapper v0.8 Node-based text and image flowchart for Blender Mindmap with shortcuts visible: Mindmap with shortcuts hidden: Notes This was requeste
 58 Oct 8, 2022
58 Oct 8, 2022
Convert Image to ASCII Art
Convert Image to ASCII Art Persiapan aplikasi ini menggunakan bahasa python dan beberapa package python. oleh karena itu harus menginstall python dan
 48 Dec 20, 2022
48 Dec 20, 2022
AudioCLIP Extending CLIP to Image, Text and Audio
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
458 Jan 2, 2023

粉專/IG圖文加工器
粉專/IG圖文加工器 介紹 給PS智障(ex:我)使用,用於產生圖文 腳本省去每次重複步驟 可載入圖片(方形,請先處理過,歡迎PR) 圖片簡易套用濾鏡 可將圖片切片 要求 Python 版本 3.9 安裝 安裝最新 python pip3 install -r requirement.txt 效果
 7 Aug 10, 2022
7 Aug 10, 2022
Pretrained SOTA Deep Learning models, callbacks and more for research and production with PyTorch Lightning and PyTorch
Pretrained SOTA Deep Learning models, callbacks and more for research and production with PyTorch Lightning and PyTorch
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
Playing videos through S3 buckets (Wasabi, AWS, etc.) through client-side VideoJS player
Playing videos through S3 buckets (Wasabi, AWS, etc.) through client-side VideoJS player without incurring ingress/egree traffic on EC2 Instance.
 8 Mar 28, 2022
8 Mar 28, 2022

Official Pytorch Implementation of: "Semantic Diversity Learning for Zero-Shot Multi-label Classification"(2021) paper
Semantic Diversity Learning for Zero-Shot Multi-label Classification Paper Official PyTorch Implementation Avi Ben-Cohen, Nadav Zamir, Emanuel Ben Bar
 28 Aug 29, 2022
28 Aug 29, 2022
The repository for my video "Playing MINECRAFT with a WEBCAM"
This is the official repo for my video "Playing MINECRAFT with a WEBCAM" on YouTube Original video can be found here: https://youtu.be/701TPxL0Skg Red
 27 Jun 7, 2022
27 Jun 7, 2022

Pytorch implementation of few-shot semantic image synthesis
Few-shot Semantic Image Synthesis Using StyleGAN Prior Our method can synthesize photorealistic images from dense or sparse semantic annotations using
 40 Sep 26, 2022
40 Sep 26, 2022

This is an official implementation for "Video Swin Transformers".
Video Swin Transformer By Ze Liu*, Jia Ning*, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin and Han Hu. This repo is the official implementation of "V
 981 Jan 3, 2023
981 Jan 3, 2023

Learning to Reconstruct 3D Non-Cuboid Room Layout from a Single RGB Image
NonCuboidRoom Paper Learning to Reconstruct 3D Non-Cuboid Room Layout from a Single RGB Image Cheng Yang*, Jia Zheng*, Xili Dai, Rui Tang, Yi Ma, Xiao
 67 Dec 15, 2022
67 Dec 15, 2022
π-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
π-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis Project Page | Paper | Data Eric Ryan Chan*, Marco Monteiro*, Pe
 375 Dec 31, 2022
375 Dec 31, 2022
Spatially-Adaptive Pixelwise Networks for Fast Image Translation, CVPR 2021
Image Translation with ASAPNets Spatially-Adaptive Pixelwise Networks for Fast Image Translation, CVPR 2021 Webpage | Paper | Video Installation insta
 100 Dec 28, 2022
100 Dec 28, 2022
![[CVPR 2021] Region-aware Adaptive Instance Normalization for Image Harmonization](https://github.com/junleen/RainNet/raw/main/Doc/sample.png)
[CVPR 2021] Region-aware Adaptive Instance Normalization for Image Harmonization
RainNet — Official Pytorch Implementation Region-aware Adaptive Instance Normalization for Image Harmonization Jun Ling, Han Xue, Li Song*, Rong Xie,
 130 Dec 11, 2022
130 Dec 11, 2022

Implementation of Diverse Semantic Image Synthesis via Probability Distribution Modeling
Diverse Semantic Image Synthesis via Probability Distribution Modeling (CVPR 2021) Paper Zhentao Tan, Menglei Chai, Dongdong Chen, Jing Liao, Qi Chu,
 45 Nov 17, 2022
45 Nov 17, 2022

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022

The AugNet Python module contains functions for the fast computation of image similarity.
AugNet AugNet: End-to-End Unsupervised Visual Representation Learning with Image Augmentation arxiv link In our work, we propose AugNet, a new deep le
 74 Dec 28, 2022
74 Dec 28, 2022

Code for "LASR: Learning Articulated Shape Reconstruction from a Monocular Video". CVPR 2021.
LASR Installation Build with conda conda env create -f lasr.yml conda activate lasr # install softras cd third_party/softras; python setup.py install;
 157 Dec 26, 2022
157 Dec 26, 2022
The implementation of CVPR2021 paper Temporal Query Networks for Fine-grained Video Understanding, by Chuhan Zhang, Ankush Gupta and Andrew Zisserman.
Temporal Query Networks for Fine-grained Video Understanding 📋 This repository contains the implementation of CVPR2021 paper Temporal_Query_Networks
 55 Dec 21, 2022
55 Dec 21, 2022

Official implementation of the paper DeFlow: Learning Complex Image Degradations from Unpaired Data with Conditional Flows
DeFlow: Learning Complex Image Degradations from Unpaired Data with Conditional Flows Official implementation of the paper DeFlow: Learning Complex Im
 86 Nov 16, 2022
86 Nov 16, 2022

Towards Long-Form Video Understanding
Towards Long-Form Video Understanding Chao-Yuan Wu, Philipp Krähenbühl, CVPR 2021 [Paper] [Project Page] [Dataset] Citation @inproceedings{lvu2021,
 69 Dec 26, 2022
69 Dec 26, 2022

Senginta is All in one Search Engine Scrapper for used by API or Python Module. It's Free!
Senginta is All in one Search Engine Scrapper. With traditional scrapping, Senginta can be powerful to get result from any Search Engine, and convert to Json. Now support only for Google Product Search Engine (GShop, GVideo and many too) and Baidu Search Engine.
 33 Nov 21, 2022
33 Nov 21, 2022

Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models
Patch-Rotation(PatchRot) Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models Submitted to Neurips2021 To
 4 Jul 12, 2021
4 Jul 12, 2021
Unbalanced Feature Transport for Exemplar-based Image Translation (CVPR 2021)
UNITE and UNITE+ Unbalanced Feature Transport for Exemplar-based Image Translation (CVPR 2021) Unbalanced Intrinsic Feature Transport for Exemplar-bas
 183 Nov 9, 2022
183 Nov 9, 2022
VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning
This is a release of our VIMPAC paper to illustrate the implementations. The pretrained checkpoints and scripts will be soon open-sourced in HuggingFace transformers.
 74 Dec 3, 2022
74 Dec 3, 2022

Isearch (OSINT) 🔎 Face recognition reverse image search on Instagram profile feed photos.
isearch is an OSINT tool on Instagram. Offers a face recognition reverse image search on Instagram profile feed photos.
 20 Oct 25, 2022
20 Oct 25, 2022
pygamevideo module helps developer to embed videos into their Pygame display
pygamevideo module helps developer to embed videos into their Pygame display. Audio playback doesn't use pygame.mixer.
 10 Dec 28, 2022
10 Dec 28, 2022
Jina allows you to build deep learning-powered search-as-a-service in just minutes
Cloud-native neural search framework for any kind of data
 17k Dec 31, 2022
17k Dec 31, 2022

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
 544 Dec 19, 2022
544 Dec 19, 2022

PyTorch implementation and pretrained models for XCiT models. See XCiT: Cross-Covariance Image Transformer
Official code Cross-Covariance Image Transformer (XCiT)
605 Jan 2, 2023
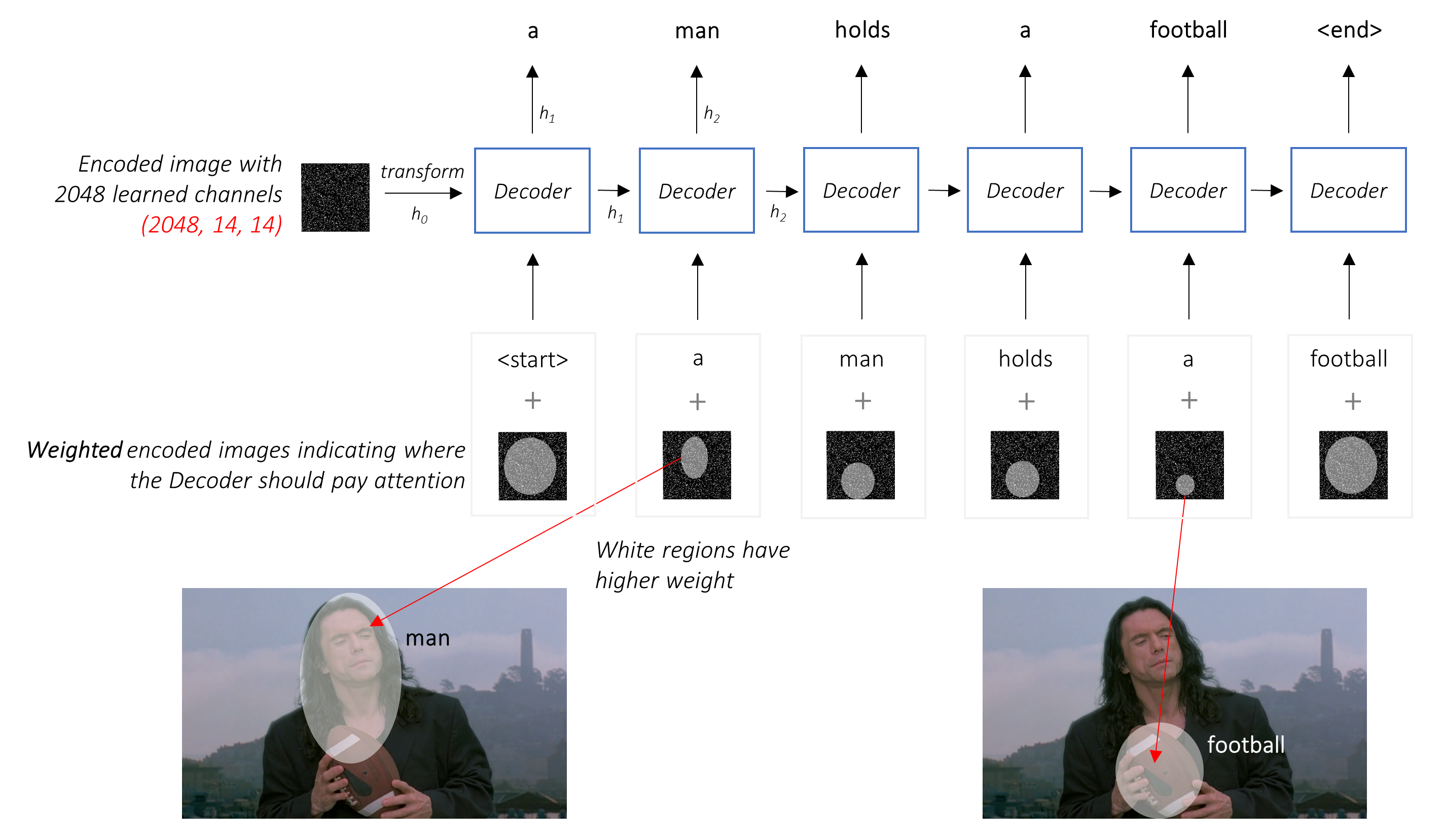
Pipeline for chemical image-to-text competition
BMS-Molecular-Translation Introduction This is a pipeline for Bristol-Myers Squibb – Molecular Translation by Vadim Timakin and Maksim Zhdanov. We got
 7 Sep 20, 2022
7 Sep 20, 2022

CT-Net: Channel Tensorization Network for Video Classification
[ICLR2021] CT-Net: Channel Tensorization Network for Video Classification @inproceedings{ li2021ctnet, title={{\{}CT{\}}-Net: Channel Tensorization Ne
 33 Nov 15, 2022
33 Nov 15, 2022

AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations
AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations. Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
4.6k Jan 9, 2023
PyTorch implementation and pretrained models for XCiT models. See XCiT: Cross-Covariance Image Transformer
Cross-Covariance Image Transformer (XCiT) PyTorch implementation and pretrained models for XCiT models. See XCiT: Cross-Covariance Image Transformer L
605 Jan 2, 2023

Implementation of Uformer, Attention-based Unet, in Pytorch
Uformer - Pytorch Implementation of Uformer, Attention-based Unet, in Pytorch. It will only offer the concat-cross-skip connection. This repository wi
 72 Dec 19, 2022
72 Dec 19, 2022

This is the PyTorch implementation of GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation
Official PyTorch repo for GAN's N' Roses. Diverse im2im and vid2vid selfie to anime translation.
 1.1k Jan 1, 2023
1.1k Jan 1, 2023

Official PyTorch code for CVPR 2020 paper "Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision"
Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision https://arxiv.org/abs/2003.00393 Abstract Active learning (AL) aims to min
 29 Nov 21, 2022
29 Nov 21, 2022
Official implementation of "SinIR: Efficient General Image Manipulation with Single Image Reconstruction" (ICML 2021)
SinIR (Official Implementation) Requirements To install requirements: pip install -r requirements.txt We used Python 3.7.4 and f-strings which are in
 47 Oct 11, 2022
47 Oct 11, 2022

This is the official repository of XVFI (eXtreme Video Frame Interpolation)
XVFI This is the official repository of XVFI (eXtreme Video Frame Interpolation), https://arxiv.org/abs/2103.16206 Last Update: 20210607 We provide th
 195 Dec 29, 2022
195 Dec 29, 2022

Official PyTorch implementation of "Proxy Synthesis: Learning with Synthetic Classes for Deep Metric Learning" (AAAI 2021)
Proxy Synthesis: Learning with Synthetic Classes for Deep Metric Learning Official PyTorch implementation of "Proxy Synthesis: Learning with Synthetic
 30 Dec 6, 2022
30 Dec 6, 2022

Pytorch implementation of the paper SPICE: Semantic Pseudo-labeling for Image Clustering
SPICE: Semantic Pseudo-labeling for Image Clustering By Chuang Niu and Ge Wang This is a Pytorch implementation of the paper. (In updating) SOTA on 5
 154 Dec 15, 2022
154 Dec 15, 2022

Polyfoto - Create image mosaics.
Polyfoto Create image mosaics. Showcase "Before and After Science" by Brian Eno "Scott 3" by Scott Walker Installation Clone this repository to your l
 149 Dec 25, 2022
149 Dec 25, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
544 Dec 19, 2022

IMGUR5K handwriting set. It is a handwritten in-the-wild dataset, which contains challenging real world handwritten samples from different writers.The dataset is shared as a set of image urls with annotations. This code downloads the images and verifies the hash to the image to avoid data contamination.
IMGUR5K Handwriting Dataset To run the code for downloading the urls and generate corresponding annotations : Usage: python download_imgur5k.py --data
213 Dec 26, 2022
A Telegram Video Merge Bot by @AbirHasan2005
VideoMerge-Bot This is very simple Telegram Videos Merge Bot by @AbirHasan2005. Using FFmpeg for Merging Videos. Features: Merge Multiple Videos. User
 57 Nov 12, 2022
57 Nov 12, 2022
Text-to-Image generation
Generate vivid Images for Any (Chinese) text CogView is a pretrained (4B-param) transformer for text-to-image generation in general domain. Read our p
 1.3k Jan 5, 2023
1.3k Jan 5, 2023
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
192 Dec 23, 2022

Tensorflow implementation of MIRNet for Low-light image enhancement
MIRNet Tensorflow implementation of the MIRNet architecture as proposed by Learning Enriched Features for Real Image Restoration and Enhancement. Lanu
 91 Jan 6, 2023
91 Jan 6, 2023

Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals
LapDepth-release This repository is a Pytorch implementation of the paper "Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals" M
 205 Dec 30, 2022
205 Dec 30, 2022

A lightweight deep network for fast and accurate optical flow estimation.
FastFlowNet: A Lightweight Network for Fast Optical Flow Estimation The official PyTorch implementation of FastFlowNet (ICRA 2021). Authors: Lingtong
 161 Jan 3, 2023
161 Jan 3, 2023
Aerial Single-View Depth Completion with Image-Guided Uncertainty Estimation (RA-L/ICRA 2020)
Aerial Depth Completion This work is described in the letter "Aerial Single-View Depth Completion with Image-Guided Uncertainty Estimation", by Lucas
 70 Dec 22, 2022
70 Dec 22, 2022
Towards End-to-end Video-based Eye Tracking
Towards End-to-end Video-based Eye Tracking The code accompanying our ECCV 2020 publication and dataset, EVE. Authors: Seonwook Park, Emre Aksan, Xuco
 76 Dec 12, 2022
76 Dec 12, 2022
![[CVPR 2021] Teachers Do More Than Teach: Compressing Image-to-Image Models (CAT)](https://github.com/snap-research/CAT/raw/main/images/comparison.png)
[CVPR 2021] Teachers Do More Than Teach: Compressing Image-to-Image Models (CAT)
CAT arXiv Pytorch implementation of our method for compressing image-to-image models. Teachers Do More Than Teach: Compressing Image-to-Image Models Q
 160 Dec 9, 2022
160 Dec 9, 2022

CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation
CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation (CVPR 2021, oral presentation) CoCosNet v2: Full-Resolution Correspondence
 308 Dec 7, 2022
308 Dec 7, 2022

Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch
Segformer - Pytorch Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch. Install $ pip install segformer-pytorch
208 Dec 25, 2022
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
STCN Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [a
 456 Dec 12, 2022
456 Dec 12, 2022

Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers.
Less is More: Pay Less Attention in Vision Transformers Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers. By
 73 Jan 1, 2023
73 Jan 1, 2023

Vehicle Identification Speed Detection (VISD) extracts vehicle information like License Plate number, Manufacturer and colour from a video and provides this data in the form of a CSV file
Vehicle Identification Speed Detection (VISD) extracts vehicle information like License Plate number, Manufacturer and colour from a video and provides this data in the form of a CSV file. VISD can also perform vehicle speed detection on a video. All these features of VSID are provided to the user using a Web Application which is created using Flask
 6 Feb 22, 2022
6 Feb 22, 2022
This is a GUI based text and image messenger. Other functionalities will be added soon.
Pigeon-Messenger (Requires Python and Kivy) Pigeon is a GUI based text and image messenger using Kivy and Python. Currently the layout is built. Funct
 4 Jan 21, 2022
4 Jan 21, 2022
A Icon Maker GUI Made - Convert your image into icon ( .ico format ).
Icon-Maker-GUI A Icon Maker GUI Made Using Python 3.9.0 . It will take any image and convert it to ICO file, for web site favicon or Windows applicati
 12 Dec 15, 2021
12 Dec 15, 2021

PyTorch implementation of Pay Attention to MLPs
gMLP PyTorch implementation of Pay Attention to MLPs. Quickstart Clone this repository. git clone https://github.com/jaketae/g-mlp.git Navigate to th
 34 Dec 13, 2022
34 Dec 13, 2022

ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection
ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection This repository contains implementation of the
 190 Dec 30, 2022
190 Dec 30, 2022
EDPN: Enhanced Deep Pyramid Network for Blurry Image Restoration
EDPN: Enhanced Deep Pyramid Network for Blurry Image Restoration Ruikang Xu, Zeyu Xiao, Jie Huang, Yueyi Zhang, Zhiwei Xiong. EDPN: Enhanced Deep Pyra
 69 Dec 15, 2022
69 Dec 15, 2022

DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification Created by Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, Ch
414 Jan 1, 2023

This is an implementation for the CVPR2020 paper "Learning Invariant Representation for Unsupervised Image Restoration"
Learning Invariant Representation for Unsupervised Image Restoration (CVPR 2020) Introduction This is an implementation for the paper "Learning Invari
 88 Nov 7, 2022
88 Nov 7, 2022

An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C.
vizh An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C. Overview Her
 228 Dec 17, 2022
228 Dec 17, 2022
A simple programming language for manipulating images.
f-stop A simple programming language for manipulating images. Examples OPEN "image.png" AS image RESIZE image (300, 300) SAVE image "out.jpg" CLOSE im
 6 Oct 27, 2022
6 Oct 27, 2022

Rubik's cube assistant on Flask webapp
webcube Rubik's cube assistant on Flask webapp. This webapp accepts the six faces of your cube and gives you the voice instructions as a response. Req
 56 Nov 22, 2022
56 Nov 22, 2022

This is an incredibly powerful calculator that is capable of many useful day-to-day functions.
Description 💻 This is an incredibly powerful calculator that is capable of many useful day-to-day functions. Such functions include solving basic ari
 37 Nov 19, 2022
37 Nov 19, 2022
SparseML is a libraries for applying sparsification recipes to neural networks with a few lines of code, enabling faster and smaller models
SparseML is a toolkit that includes APIs, CLIs, scripts and libraries that apply state-of-the-art sparsification algorithms such as pruning and quantization to any neural network. General, recipe-driven approaches built around these algorithms enable the simplification of creating faster and smaller models for the ML performance community at large.
 1.5k Dec 30, 2022
1.5k Dec 30, 2022