1526 Repositories
Python vision-transformer-tf Libraries

Python scripts for performing road segemtnation and car detection using the HybridNets multitask model in ONNX.
ONNX-HybridNets-Multitask-Road-Detection Python scripts for performing road segemtnation and car detection using the HybridNets multitask model in ONN
 45 Jan 1, 2023
45 Jan 1, 2023

This is the first released system towards complex meters` detection and recognition, which is implemented by computer vision techniques.
A three-stage detection and recognition pipeline of complex meters in wild This is the first released system towards detection and recognition of comp
 19 Nov 28, 2022
19 Nov 28, 2022
![[CVPR 2022]](https://github.com/VITA-Group/Diverse-ViT/raw/main/Figs/Diversity_overview.png)
[CVPR 2022] "The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy" by Tianlong Chen, Zhenyu Zhang, Yu Cheng, Ahmed Awadallah, Zhangyang Wang
The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy Codes for this paper: [CVPR 2022] The Pr
 16 Nov 26, 2022
16 Nov 26, 2022
![[CVPR 2022] Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels](https://github.com/Haochen-Wang409/U2PL/raw/main/img/pipeline.png)
[CVPR 2022] Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
Using Unreliable Pseudo Labels Official PyTorch implementation of Semi-Supervised Semantic Segmentation Using Unreliable Pseudo Labels, CVPR 2022. Ple
 268 Dec 24, 2022
268 Dec 24, 2022

A simple, high level, easy-to-use open source Computer Vision library for Python.
ZoomVision : Slicing Aid Detection A simple, high level, easy-to-use open source Computer Vision library for Python. Installation Installing dependenc
 2 Mar 4, 2022
2 Mar 4, 2022
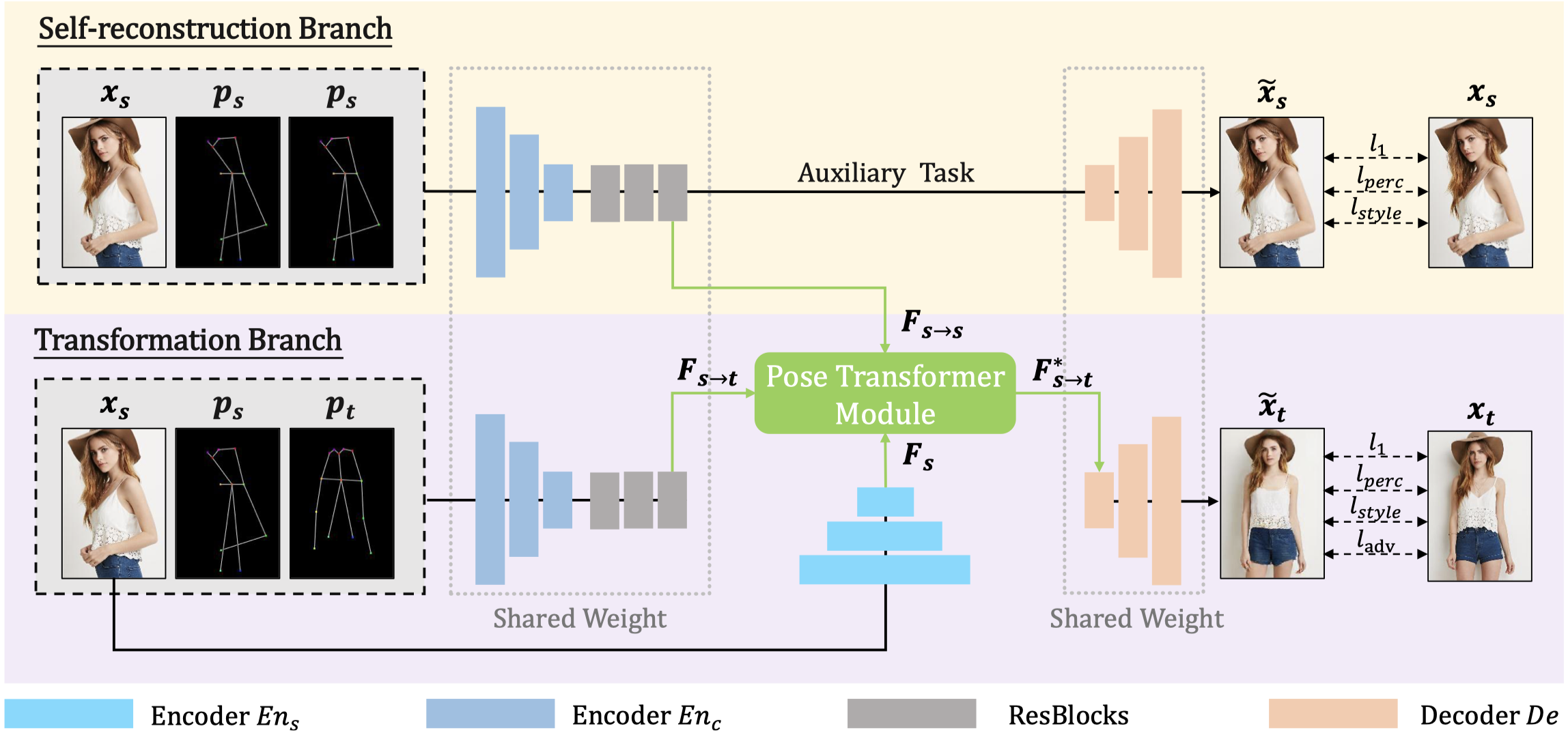
Exploring the Dual-task Correlation for Pose Guided Person Image Generation
Dual-task Pose Transformer Network The source code for our paper "Exploring Dual-task Correlation for Pose Guided Person Image Generation“ (CVPR2022)
 63 Dec 15, 2022
63 Dec 15, 2022

Implementation of the state-of-the-art vision transformers with tensorflow
ViT Tensorflow This repository contains the tensorflow implementation of the state-of-the-art vision transformers (a category of computer vision model
 2 Mar 16, 2022
2 Mar 16, 2022
Transformer Huffman coding - Complete Huffman coding through transformer
Transformer_Huffman_coding Complete Huffman coding through transformer 2022/2/19
 3 May 19, 2022
3 May 19, 2022
SmallInitEmb - LayerNorm(SmallInit(Embedding)) in a Transformer to improve convergence
SmallInitEmb LayerNorm(SmallInit(Embedding)) in a Transformer I find that when t
 11 Dec 25, 2022
11 Dec 25, 2022

Python code for ICLR 2022 spotlight paper EViT: Expediting Vision Transformers via Token Reorganizations
Expediting Vision Transformers via Token Reorganizations This repository contain
 101 Dec 26, 2022
101 Dec 26, 2022

Breaching - Breaching privacy in federated learning scenarios for vision and text
Breaching - A Framework for Attacks against Privacy in Federated Learning This P
 139 Jan 3, 2023
139 Jan 3, 2023

HashNeRF-pytorch - Pure PyTorch Implementation of NVIDIA paper on Instant Training of Neural Graphics primitives
HashNeRF-pytorch Instant-NGP recently introduced a Multi-resolution Hash Encodin
 616 Jan 6, 2023
616 Jan 6, 2023

SafePicking: Learning Safe Object Extraction via Object-Level Mapping, ICRA 2022
SafePicking Learning Safe Object Extraction via Object-Level Mapping Kentaro Wad
 49 Oct 24, 2022
49 Oct 24, 2022

GeoTransformer - Geometric Transformer for Fast and Robust Point Cloud Registration
Geometric Transformer for Fast and Robust Point Cloud Registration PyTorch imple
 220 Jan 5, 2023
220 Jan 5, 2023
General Vision Benchmark, a project from OpenGVLab
Introduction We build GV-B(General Vision Benchmark) on Classification, Detection, Segmentation and Depth Estimation including 26 datasets for model e
 174 Dec 27, 2022
174 Dec 27, 2022

Social Distancing Detector
Computer vision has opened up a lot of opportunities to explore into AI domain that were earlier highly limited. Here is an application of haarcascade classifier and OpenCV to develop a social distancing violation detector. I am passing the algo through a video feed where it first detects people using 'haarcascade_fullbody.xml' classifier algo. OpenCV and some mathematical operations then allow us to make code the social distancing violation logic
 2 Jul 18, 2022
2 Jul 18, 2022

RIFE - Real-Time Intermediate Flow Estimation for Video Frame Interpolation
RIFE - Real-Time Intermediate Flow Estimation for Video Frame Interpolation YouTube | BiliBili 16X interpolation results from two input images: Introd
 28 Dec 9, 2022
28 Dec 9, 2022
Object detection evaluation metrics using Python.
Object detection evaluation metrics using Python.
 2 Sep 6, 2022
2 Sep 6, 2022
The visual framework is designed on the idea of module and implemented by mixin method
Visual Framework The visual framework is designed on the idea of module and implemented by mixin method. Its biggest feature is the mixins module whic
 9 Sep 19, 2022
9 Sep 19, 2022

Accuracy Aligned. Concise Implementation of Swin Transformer
Accuracy Aligned. Concise Implementation of Swin Transformer This repository contains the implementation of Swin Transformer, and the training codes o
 77 Dec 16, 2022
77 Dec 16, 2022

DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
 36 Feb 13, 2022
36 Feb 13, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
 1.4k Jan 8, 2023
1.4k Jan 8, 2023

CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors In order to facilitate the res
 11 Dec 12, 2022
11 Dec 12, 2022

This repository contains code from the paper "TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network"
TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network This repository contains code from the paper "TTS-GAN: A Transformer-based Tim
 108 Dec 29, 2022
108 Dec 29, 2022

A python package to fine-tune transformer-based models for named entity recognition (NER).
nerblackbox A python package to fine-tune transformer-based language models for named entity recognition (NER). Resources Source Code: https://github.
 13 Jul 30, 2022
13 Jul 30, 2022

TorchMD-Net provides state-of-the-art graph neural networks and equivariant transformer neural networks potentials for learning molecular potentials
TorchMD-net TorchMD-Net provides state-of-the-art graph neural networks and equivariant transformer neural networks potentials for learning molecular
 104 Jan 3, 2023
104 Jan 3, 2023

Memory Defense: More Robust Classificationvia a Memory-Masking Autoencoder
Memory Defense: More Robust Classificationvia a Memory-Masking Autoencoder Authors: - Eashan Adhikarla - Dan Luo - Dr. Brian D. Davison Abstract Many
 4 Dec 25, 2022
4 Dec 25, 2022

A lane detection integrated Real-time Instance Segmentation based on YOLACT (You Only Look At CoefficienTs)
Real-time Instance Segmentation and Lane Detection This is a lane detection integrated Real-time Instance Segmentation based on YOLACT (You Only Look
 4 Dec 30, 2022
4 Dec 30, 2022

Clean and readable code for Decision Transformer: Reinforcement Learning via Sequence Modeling
Minimal implementation of Decision Transformer: Reinforcement Learning via Sequence Modeling in PyTorch for mujoco control tasks in OpenAI gym
 104 Jan 6, 2023
104 Jan 6, 2023

Non-Autoregressive Translation with Layer-Wise Prediction and Deep Supervision
Deeply Supervised, Layer-wise Prediction-aware (DSLP) Transformer for Non-autoregressive Neural Machine Translation
 37 Jan 4, 2023
37 Jan 4, 2023
PyTorch implementation of DD3D: Is Pseudo-Lidar needed for Monocular 3D Object detection?
PyTorch implementation of DD3D: Is Pseudo-Lidar needed for Monocular 3D Object detection? (ICCV 2021), Dennis Park*, Rares Ambrus*, Vitor Guizilini, Jie Li, and Adrien Gaidon.
 364 Dec 27, 2022
364 Dec 27, 2022
Awesome Monocular 3D detection
Awesome Monocular 3D detection Paper list of 3D detetction, keep updating! Contents Paper List 2022 2021 2020 2019 2018 2017 2016 KITTI Results Paper
 184 Jan 4, 2023
184 Jan 4, 2023
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
98 Dec 15, 2022

UMPNet: Universal Manipulation Policy Network for Articulated Objects
UMPNet: Universal Manipulation Policy Network for Articulated Objects Zhenjia Xu, Zhanpeng He, Shuran Song Columbia University Robotics and Automation
 33 Dec 3, 2022
33 Dec 3, 2022
Building Ellee — A GPT-3 and Computer Vision Powered Talking Robotic Teddy Bear With Human Level Conversation Intelligence
Using an object detection and facial recognition system built on MobileNetSSDV2 and Dlib and running on an NVIDIA Jetson Nano, a GPT-3 model, Google Speech Recognition, Amazon Polly and servo motors, I built Ellee - a robotic teddy bear who can move her head and converse naturally.
 24 Oct 26, 2022
24 Oct 26, 2022

Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
 58 Dec 24, 2022
58 Dec 24, 2022

This project uses ViT to perform image classification tasks on DATA set CIFAR10.
Vision-Transformer-Multiprocess-DistributedDataParallel-Apex Introduction This project uses ViT to perform image classification tasks on DATA set CIFA
 3 Jun 3, 2022
3 Jun 3, 2022

Deep Surface Reconstruction from Point Clouds with Visibility Information
Data, code and pretrained models for the paper Deep Surface Reconstruction from Point Clouds with Visibility Information.
 23 Jan 4, 2023
23 Jan 4, 2023

Python code to fuse multiple RGB-D images into a TSDF voxel volume.
Volumetric TSDF Fusion of RGB-D Images in Python This is a lightweight python script that fuses multiple registered color and depth images into a proj
 845 Jan 3, 2023
845 Jan 3, 2023

A Novel Plug-in Module for Fine-grained Visual Classification
Pytorch implementation for A Novel Plug-in Module for Fine-Grained Visual Classification. fine-grained visual classification task.
 109 Dec 20, 2022
109 Dec 20, 2022
Pytorch implementation of MaskGIT: Masked Generative Image Transformer
Pytorch implementation of MaskGIT: Masked Generative Image Transformer
 247 Dec 16, 2022
247 Dec 16, 2022

Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
 13 Feb 8, 2022
13 Feb 8, 2022
Transformers provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 50 Nov 12, 2022
50 Nov 12, 2022

Codebase to experiment with a hybrid Transformer that combines conditional sequence generation with regression
Regression Transformer Codebase to experiment with a hybrid Transformer that combines conditional sequence generation with regression . Development se
 27 Jan 5, 2023
27 Jan 5, 2023

Pytorch implementation of TailCalibX : Feature Generation for Long-tail Classification
TailCalibX : Feature Generation for Long-tail Classification by Rahul Vigneswaran, Marc T. Law, Vineeth N. Balasubramanian, Makarand Tapaswi [arXiv] [
 34 Jan 2, 2023
34 Jan 2, 2023

MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition Paper: MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition accepted fo
 64 Dec 18, 2022
64 Dec 18, 2022
NeuralForecast is a Python library for time series forecasting with deep learning models
NeuralForecast is a Python library for time series forecasting with deep learning models. It includes benchmark datasets, data-loading utilities, evaluation functions, statistical tests, univariate model benchmarks and SOTA models implemented in PyTorch and PyTorchLightning.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023

A transformer which can randomly augment VOC format dataset (both image and bbox) online.
VocAug It is difficult to find a script which can augment VOC-format dataset, especially the bbox. Or find a script needs complex requirements so it i
 1 Mar 5, 2022
1 Mar 5, 2022

Natural language processing summarizer using 3 state of the art Transformer models: BERT, GPT2, and T5
NLP-Summarizer Natural language processing summarizer using 3 state of the art Transformer models: BERT, GPT2, and T5 This project aimed to provide in
 1 Feb 7, 2022
1 Feb 7, 2022

Open source simulator for autonomous vehicles built on Unreal Engine / Unity, from Microsoft AI & Research
Welcome to AirSim AirSim is a simulator for drones, cars and more, built on Unreal Engine (we now also have an experimental Unity release). It is open
 13.8k Jan 3, 2023
13.8k Jan 3, 2023

Face recognition project by matching the features extracted using SIFT.
MV_FaceDetectionWithSIFT Face recognition project by matching the features extracted using SIFT. By : Aria Radmehr Professor : Ali Amiri Dependencies
 4 May 31, 2022
4 May 31, 2022

An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to art and design.
Awesome AI for Art & Design An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to a
 20 Dec 21, 2022
20 Dec 21, 2022
Python Computer Vision Aim Bot for Roblox's Phantom Forces
Python-Phantom-Forces-Aim-Bot Python Computer Vision Aim Bot for Roblox's Phanto
 2 Jul 11, 2022
2 Jul 11, 2022

Semantic Segmentation Suite in TensorFlow
Semantic Segmentation Suite in TensorFlow. Implement, train, and test new Semantic Segmentation models easily!
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
LabelMe annotation tool source code
LabelMe annotation tool source code Here you will find the source code to install the LabelMe annotation tool on your server. LabelMe is an annotation
 1.3k Jan 3, 2023
1.3k Jan 3, 2023
This project proposes a camera vision based cursor control system, using hand moment captured from a webcam through a landmarks of hand by using Mideapipe module
This project proposes a camera vision based cursor control system, using hand moment captured from a webcam through a landmarks of hand by using Mideapipe module
 2 Feb 20, 2022
2 Feb 20, 2022
Mae segmentation - Reproduction of semantic segmentation using masked autoencoder (mae)
ADE20k Semantic segmentation with MAE Getting started Install the mmsegmentation
 97 Dec 17, 2022
97 Dec 17, 2022
Real-time domain adaptation for semantic segmentation
Advanced-Machine-Learning This repository contains the code for the project Real
 1 Jan 30, 2022
1 Jan 30, 2022
The official code repo of "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
134 Jan 1, 2023
The 7th edition of NTIRE: New Trends in Image Restoration and Enhancement workshop will be held on June 2022 in conjunction with CVPR 2022.
NTIRE 2022 - Image Inpainting Challenge Important dates 2022.02.01: Release of train data (input and output images) and validation data (only input) 2
 37 Nov 27, 2022
37 Nov 27, 2022
This repo contains the code required to train the multivariate time-series Transformer.
Multi-Variate Time-Series Transformer This repo contains the code required to train the multivariate time-series Transformer. Download the data The No
 4 Nov 24, 2022
4 Nov 24, 2022
MoRecon - A tool for reconstructing missing frames in motion capture data.
MoRecon - A tool for reconstructing missing frames in motion capture data.
 38 Dec 3, 2022
38 Dec 3, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022

Code for You Only Cut Once: Boosting Data Augmentation with a Single Cut
You Only Cut Once (YOCO) YOCO is a simple method/strategy of performing augmenta
 88 Dec 28, 2022
88 Dec 28, 2022

An implementation of the "Attention is all you need" paper without extra bells and whistles, or difficult syntax
Simple Transformer An implementation of the "Attention is all you need" paper without extra bells and whistles, or difficult syntax. Note: The only ex
 29 Jun 16, 2022
29 Jun 16, 2022
Image processing is one of the most common term in computer vision
Image processing is one of the most common term in computer vision. Computer vision is the process by which computers can understand images and videos, and how they are stored, manipulated, and retrieve details from them. OpenCV is an open source computer vision image processing library for machine learning, deep leaning and AI application which plays a major role in real-time operation which is very important in today’s systems.
 3 Feb 15, 2022
3 Feb 15, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
 327 Jan 1, 2023
327 Jan 1, 2023

DocEnTr: An end-to-end document image enhancement transformer
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
 19 Jan 29, 2022
19 Jan 29, 2022

RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and rearranging captions and pictures. Unlike other versions of the model we use BERT for text encoder and SWIN transformer for image encoder.
ruCLIP-SB RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and re
 5 Apr 13, 2022
5 Apr 13, 2022
Computer Vision Paper Reviews with Key Summary of paper, End to End Code Practice and Jupyter Notebook converted papers
Computer-Vision-Paper-Reviews Computer Vision Paper Reviews with Key Summary along Papers & Codes. Jonathan Choi 2021 The repository provides 100+ Pap
 2 Mar 17, 2022
2 Mar 17, 2022
![[ECE NTUA] 👁 Computer Vision - Lab Projects & Theoretical Problem Sets (2020-2021)](https://github.com/d-dimos/computer_vision_ntua/raw/master/labs/lab1/README_imgs/edge_in.jpg?raw=true)
[ECE NTUA] 👁 Computer Vision - Lab Projects & Theoretical Problem Sets (2020-2021)
Computer Vision - NTUA (2020-2021) This repository hosts the lab projects and theoretical problem sets of the Computer Vision course held by ECE NTUA
 6 Jul 21, 2022
6 Jul 21, 2022
🤖 Project template for your next awesome AI project. 🦾
🤖 AI Awesome Project Template 👋 Template author You may want to adjust badge links in a README.md file. 💎 Installation with pip Installation is as
 18 Nov 23, 2022
18 Nov 23, 2022

Deep ViT Features as Dense Visual Descriptors
dino-vit-features [paper] [project page] Official implementation of the paper "Deep ViT Features as Dense Visual Descriptors". We demonstrate the effe
 113 Dec 24, 2022
113 Dec 24, 2022

PyTorch implementation of "VRT: A Video Restoration Transformer"
VRT: A Video Restoration Transformer Jingyun Liang, Jiezhang Cao, Yuchen Fan, Kai Zhang, Rakesh Ranjan, Yawei Li, Radu Timofte, Luc Van Gool Computer
 837 Jan 9, 2023
837 Jan 9, 2023
This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transformer"
FlatTN This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transfor
 74 Nov 28, 2022
74 Nov 28, 2022
This is the code repository for the paper A hierarchical semantic segmentation framework for computer-vision-based bridge column damage detection
Bridge-damage-segmentation This is the code repository for the paper A hierarchical semantic segmentation framework for computer-vision-based bridge c
 5 Dec 7, 2022
5 Dec 7, 2022
Annotate datasets with a semi-trained or fully trained YOLOv5 model
YOLOv5 Auto Annotator Annotate datasets with a semi-trained or fully trained YOLOv5 model Prerequisites Ubuntu =20.04 Python =3.7 System dependencie
 3 May 14, 2022
3 May 14, 2022

Decision Transformer: A brand new Offline RL Pattern
DecisionTransformer_StepbyStep Intro Decision Transformer: A brand new Offline RL Pattern. 这是关于NeurIPS 2021 热门论文Decision Transformer的复现。 👍 原文地址: Deci
 14 Nov 22, 2022
14 Nov 22, 2022

This repository contains a toolkit for collecting, labeling and tracking object keypoints
This repository contains a toolkit for collecting, labeling and tracking object keypoints. Object keypoints are semantic points in an object's coordinate frame.
 13 Dec 12, 2022
13 Dec 12, 2022

Geometric Interpretation of Matrix Square Root and Inverse Square Root
Fast Differentiable Matrix Sqrt Root Geometric Interpretation of Matrix Square Root and Inverse Square Root This repository constains the official Pyt
 5 Jan 24, 2022
5 Jan 24, 2022

This repository contains the code for TABS, a 3D CNN-Transformer hybrid automated brain tissue segmentation algorithm using T1w structural MRI scans
This repository contains the code for TABS, a 3D CNN-Transformer hybrid automated brain tissue segmentation algorithm using T1w structural MRI scans. TABS relies on a Res-Unet backbone, with a Vision Transformer embedded between the encoder and decoder layers.
 6 Nov 7, 2022
6 Nov 7, 2022

SegTransVAE: Hybrid CNN - Transformer with Regularization for medical image segmentation
SegTransVAE: Hybrid CNN - Transformer with Regularization for medical image segmentation This repo is the official implementation for SegTransVAE. Seg
 4 Aug 4, 2022
4 Aug 4, 2022

PyTorch implementation for the paper Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime
Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime Created by Prarthana Bhattacharyya. Disclaimer: This is n
 5 Nov 8, 2022
5 Nov 8, 2022

Explore the Expression: Facial Expression Generation using Auxiliary Classifier Generative Adversarial Network
Explore the Expression: Facial Expression Generation using Auxiliary Classifier Generative Adversarial Network This is the official implementation of
 2 Jul 9, 2022
2 Jul 9, 2022
Transformer based SAR image despeckling
Transformer based SAR image despeckling Using the code: The code is stable while using Python 3.6.13, CUDA =10.1 Clone this repository: git clone htt
 27 Nov 13, 2022
27 Nov 13, 2022
Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer.
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
74 Jan 7, 2023
Vision transformers (ViTs) have found only limited practical use in processing images
CXV Convolutional Xformers for Vision Vision transformers (ViTs) have found only limited practical use in processing images, in spite of their state-o
 23 Sep 10, 2022
23 Sep 10, 2022

Labelme is a graphical image annotation tool, It is written in Python and uses Qt for its graphical interface
Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).
9.6k Jan 9, 2023

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023

Object classification with basic computer vision techniques
naive-image-classification Object classification with basic computer vision techniques. Final assignment for the computer vision course I took at univ
 2 Jul 1, 2022
2 Jul 1, 2022
Computer vision applications project (Flask and OpenCV)
Computer Vision Applications Project This project is at it's initial phase. This is all about the implementation of different computer vision techniqu
 1 Jan 26, 2022
1 Jan 26, 2022
Code for our paper A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization,
FSRA This repository contains the dataset link and the code for our paper A Transformer-Based Feature Segmentation and Region Alignment Method For UAV
 32 Dec 18, 2022
32 Dec 18, 2022

EdiBERT is a generative model based on a bi-directional transformer, suited for image manipulation
EdiBERT, a generative model for image editing EdiBERT is a generative model based on a bi-directional transformer, suited for image manipulation. The
 16 Dec 7, 2022
16 Dec 7, 2022

On the Adversarial Robustness of Visual Transformer
On the Adversarial Robustness of Visual Transformer Code for our paper "On the Adversarial Robustness of Visual Transformers"
 35 Dec 14, 2022
35 Dec 14, 2022

This is the repo of the manuscript "Dual-branch Attention-In-Attention Transformer for speech enhancement"
DB-AIAT: A Dual-branch attention-in-attention transformer for single-channel SE
 68 Dec 16, 2022
68 Dec 16, 2022
RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2
RoNER RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2. It is meant to be an easy to use, hi
 9 Nov 7, 2022
9 Nov 7, 2022

Eye-Blink-Counter - Python based Computer Vision project which counts how many time a person blinks
Eye Blink Counter OpenCV and Mediapipe No Blink Blink
 2 Mar 24, 2022
2 Mar 24, 2022
Vit-ImageClassification - Pytorch ViT for Image classification on the CIFAR10 dataset
Vit-ImageClassification Introduction This project uses ViT to perform image clas
4 Jun 1, 2022
Labelbox is the fastest way to annotate data to build and ship artificial intelligence applications
Labelbox Labelbox is the fastest way to annotate data to build and ship artificial intelligence applications. Use this github repository to help you s
 1.7k Dec 29, 2022
1.7k Dec 29, 2022

CVAT is free, online, interactive video and image annotation tool for computer vision
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 4, 2023
8.6k Jan 4, 2023