738 Repositories
Python weather-nlp Libraries
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 3, 2023
77.2k Jan 3, 2023

Implementation of character based convolutional neural network
Character Based CNN This repo contains a PyTorch implementation of a character-level convolutional neural network for text classification. The model a
 248 Nov 21, 2022
248 Nov 21, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
 203 Dec 20, 2022
203 Dec 20, 2022
DRIFT is a tool for Diachronic Analysis of Scientific Literature.
About DRIFT is a tool for Diachronic Analysis of Scientific Literature. The application offers user-friendly and customizable utilities for two modes:
 108 Dec 12, 2022
108 Dec 12, 2022
Universal Adversarial Triggers for Attacking and Analyzing NLP (EMNLP 2019)
Universal Adversarial Triggers for Attacking and Analyzing NLP This is the official code for the EMNLP 2019 paper, Universal Adversarial Triggers for
 248 Dec 17, 2022
248 Dec 17, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 286 Jan 2, 2023
286 Jan 2, 2023
🛠 All-in-one web-based IDE specialized for machine learning and data science.
All-in-one web-based development environment for machine learning Getting Started • Features & Screenshots • Support • Report a Bug • FAQ • Known Issu
 2.9k Jan 9, 2023
2.9k Jan 9, 2023
A repo for open resources & information for people to succeed in PhD in CS & career in AI / NLP
A repo for open resources & information for people to succeed in PhD in CS & career in AI / NLP
 420 Dec 28, 2022
420 Dec 28, 2022

🤗 Push your spaCy pipelines to the Hugging Face Hub
spacy-huggingface-hub: Push your spaCy pipelines to the Hugging Face Hub This package provides a CLI command for uploading any trained spaCy pipeline
 30 Oct 9, 2022
30 Oct 9, 2022
Use different orders of N-gram model to play Hangman game.
Hangman game The Hangman game is a game whereby one person thinks of a word, which is kept secret from another person, who tries to guess the word one
 4 Oct 11, 2022
4 Oct 11, 2022
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022

ACL'2021: Learning Dense Representations of Phrases at Scale
DensePhrases DensePhrases is an extractive phrase search tool based on your natural language inputs. From 5 million Wikipedia articles, it can search
 540 Dec 30, 2022
540 Dec 30, 2022
Huggingface Transformers + Adapters = ❤️
adapter-transformers A friendly fork of HuggingFace's Transformers, adding Adapters to PyTorch language models adapter-transformers is an extension of
 1.2k Jan 9, 2023
1.2k Jan 9, 2023
Graph4nlp is the library for the easy use of Graph Neural Networks for NLP
Graph4NLP Graph4NLP is an easy-to-use library for R&D at the intersection of Deep Learning on Graphs and Natural Language Processing (i.e., DLG4NLP).
 1.5k Dec 23, 2022
1.5k Dec 23, 2022

Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
SEDE SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description
 83 Nov 11, 2022
83 Nov 11, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
 99 Dec 23, 2022
99 Dec 23, 2022

Visual Weather api. Returns beautiful pictures with the current weather.
VWapi Visual Weather api. Returns beautiful pictures with the current weather. Installation: sudo apt update -y && sudo apt upgrade -y sudo apt instal
 33 Nov 13, 2022
33 Nov 13, 2022
Meta-learning for NLP
Self-Supervised Meta-Learning for Few-Shot Natural Language Classification Tasks Code for training the meta-learning models and fine-tuning on downstr
 43 Nov 8, 2022
43 Nov 8, 2022
CausaLM: Causal Model Explanation Through Counterfactual Language Models
CausaLM: Causal Model Explanation Through Counterfactual Language Models Authors: Amir Feder, Nadav Oved, Uri Shalit, Roi Reichart Abstract: Understan
 39 Jul 10, 2022
39 Jul 10, 2022

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022

Sequence model architectures from scratch in PyTorch
This repository implements a variety of sequence model architectures from scratch in PyTorch. Effort has been put to make the code well structured so that it can serve as learning material. The training loop implements the learner design pattern from fast.ai in pure PyTorch, with access to the loop provided through callbacks. Detailed logging and graphs are also provided with python logging and wandb. Additional implementations will be added.
 11 Mar 28, 2022
11 Mar 28, 2022
Deep Learning for Natural Language Processing - Lectures 2021
This repository contains slides for the course "20-00-0947: Deep Learning for Natural Language Processing" (Technical University of Darmstadt, Summer term 2021).
 0 Feb 21, 2022
0 Feb 21, 2022
Jina allows you to build deep learning-powered search-as-a-service in just minutes
Cloud-native neural search framework for any kind of data
 17k Dec 31, 2022
17k Dec 31, 2022

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022

This repository contains all the source code that is needed for the project : An Efficient Pipeline For Bloom’s Taxonomy Using Natural Language Processing and Deep Learning
Pipeline For NLP with Bloom's Taxonomy Using Improved Question Classification and Question Generation using Deep Learning This repository contains all
 9 Jul 17, 2021
9 Jul 17, 2021
This project checks the weather in the next 12 hours and sends an SMS to your phone number if it's going to rain to remind you to take your umbrella.
RainAlert-Request-Twilio This project checks the weather in the next 12 hours and sends an SMS to your phone number if it's going to rain to remind yo
 9 Apr 15, 2022
9 Apr 15, 2022
CausalNLP is a practical toolkit for causal inference with text as treatment, outcome, or "controlled-for" variable.
CausalNLP CausalNLP is a practical toolkit for causal inference with text as treatment, outcome, or "controlled-for" variable. Install pip install -U
 95 Jan 3, 2023
95 Jan 3, 2023
Unifying Cross-Lingual Semantic Role Labeling with Heterogeneous Linguistic Resources (NAACL-2021).
Unifying Cross-Lingual Semantic Role Labeling with Heterogeneous Linguistic Resources Description This is the repository for the paper Unifying Cross-
 16 Sep 9, 2022
16 Sep 9, 2022

A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/casual, active/passive, and many more. Created by Prithiviraj Damodaran. Open to pull requests and other forms of collaboration.
Styleformer A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/cas
 431 Dec 19, 2022
431 Dec 19, 2022
Load What You Need: Smaller Multilingual Transformers for Pytorch and TensorFlow 2.0.
Smaller Multilingual Transformers This repository shares smaller versions of multilingual transformers that keep the same representations offered by t
 79 Dec 28, 2022
79 Dec 28, 2022
Replacement for the default Dark Sky Home Assistant integration using Pirate Weather
Pirate Weather Integrations This integration is designed to replace the default Dark Sky integration in Home Assistant with a slightly modified, but f
 129 Jan 6, 2023
129 Jan 6, 2023
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022
Repository for the COLING 2020 paper "Explainable Automated Fact-Checking: A Survey."
Explainable Fact Checking: A Survey This repository and the accompanying webpage contain resources for the paper "Explainable Fact Checking: A Survey"
 42 Nov 17, 2022
42 Nov 17, 2022

pwy - A simple weather tool.
A simple weather tool. I made this as a way for me to learn Python, API, and PyPi packaging. Name changed from wwy to pwy.
 105 Dec 31, 2022
105 Dec 31, 2022
SparseML is a libraries for applying sparsification recipes to neural networks with a few lines of code, enabling faster and smaller models
SparseML is a toolkit that includes APIs, CLIs, scripts and libraries that apply state-of-the-art sparsification algorithms such as pruning and quantization to any neural network. General, recipe-driven approaches built around these algorithms enable the simplification of creating faster and smaller models for the ML performance community at large.
 1.5k Dec 30, 2022
1.5k Dec 30, 2022
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
 224 Jan 4, 2023
224 Jan 4, 2023
Home Assistant for Opendata CWB. Get the weather forecast of the city in Taiwan.
Home assistant support for Opendata CWB. The readme in Traditional Chinese. This integration is based on OpenWeatherMap (@csparpa, pyowm) to develop.
 11 Sep 30, 2022
11 Sep 30, 2022

An IVR Chatbot which can exponentially reduce the burden of companies as well as can improve the consumer/end user experience.
IVR-Chatbot Achievements 🏆 Team Uhtred won the Maverick 2.0 Bot-a-thon 2021 organized by AbInbev India. ❓ Problem Statement As we all know that, lot
 9 Dec 8, 2022
9 Dec 8, 2022

A simple weather tool. I made this as a way for me to learn Python, API, and PyPi packaging.
A simple weather tool. I made this as a way for me to learn Python, API, and PyPi packaging.
105 Dec 31, 2022
a weather application for the raspberry pi and the Pimorioni Inky pHAT.
raspi-weather a weather application for the raspberry pi and the Inky pHAT
 59 Oct 24, 2022
59 Oct 24, 2022
Sensor of Temperature Feels Like for Home Assistant.
Please ⭐ this repo if you find it useful Sensor of Temperature Feels Like for Home Assistant Installation Install from HACS (recommended) Have HACS in
 60 Dec 25, 2022
60 Dec 25, 2022
![[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.](https://github.com/cambridgeltl/sapbert/raw/main/sapbert_front_graphs_v6.png?raw=true)
[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.
SapBERT: Self-alignment pretraining for BERT This repo holds code for the SapBERT model presented in our NAACL 2021 paper: Self-Alignment Pretraining
 104 Dec 7, 2022
104 Dec 7, 2022

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022
:hot_pepper: R²SQL: "Dynamic Hybrid Relation Network for Cross-Domain Context-Dependent Semantic Parsing." (AAAI 2021)
R²SQL The PyTorch implementation of paper Dynamic Hybrid Relation Network for Cross-Domain Context-Dependent Semantic Parsing. (AAAI 2021) Requirement
 60 Dec 31, 2022
60 Dec 31, 2022
Google AI 2018 BERT pytorch implementation
BERT-pytorch Pytorch implementation of Google AI's 2018 BERT, with simple annotation BERT 2018 BERT: Pre-training of Deep Bidirectional Transformers f
 5.3k Jan 7, 2023
5.3k Jan 7, 2023
jiant is an NLP toolkit
jiant is an NLP toolkit The multitask and transfer learning toolkit for natural language processing research Why should I use jiant? jiant supports mu
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
Pytorch NLP library based on FastAI
Quick NLP Quick NLP is a deep learning nlp library inspired by the fast.ai library It follows the same api as fastai and extends it allowing for quick
 283 Nov 21, 2022
283 Nov 21, 2022
Interpretable Models for NLP using PyTorch
This repo is deprecated. Please find the updated package here. https://github.com/EdGENetworks/anuvada Anuvada: Interpretable Models for NLP using PyT
 19 Dec 17, 2022
19 Dec 17, 2022
An easier way to build neural search on the cloud
Jina is geared towards building search systems for any kind of data, including text, images, audio, video and many more. With the modular design & multi-layer abstraction, you can leverage the efficient patterns to build the system by parts, or chaining them into a Flow for an end-to-end experience.
17k Jan 1, 2023
[EMNLP 2020] Keep CALM and Explore: Language Models for Action Generation in Text-based Games
Contextual Action Language Model (CALM) and the ClubFloyd Dataset Code and data for paper Keep CALM and Explore: Language Models for Action Generation
43 Dec 16, 2022

QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
 152 Jan 2, 2023
152 Jan 2, 2023
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
152 Jan 2, 2023

COVID-19 Related NLP Papers
COVID-19 outbreak has become a global pandemic. NLP researchers are fighting the epidemic in their own way.
 28 Oct 30, 2022
28 Oct 30, 2022
![NAACL'2021: Factual Probing Is [MASK]: Learning vs. Learning to Recall](https://github.com/princeton-nlp/OptiPrompt/raw/main/figure/optiprompt.png)
NAACL'2021: Factual Probing Is [MASK]: Learning vs. Learning to Recall
OptiPrompt This is the PyTorch implementation of the paper Factual Probing Is [MASK]: Learning vs. Learning to Recall. We propose OptiPrompt, a simple
150 Dec 20, 2022
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
15k Jan 2, 2023
NLPretext packages in a unique library all the text preprocessing functions you need to ease your NLP project.
NLPretext packages in a unique library all the text preprocessing functions you need to ease your NLP project.
 114 Dec 15, 2022
114 Dec 15, 2022
An Explainable Leaderboard for NLP
ExplainaBoard: An Explainable Leaderboard for NLP Introduction | Website | Download | Backend | Paper | Video | Bib Introduction ExplainaBoard is an i
 319 Dec 20, 2022
319 Dec 20, 2022
PyTorch implementation of the end-to-end coreference resolution model with different higher-order inference methods.
End-to-End Coreference Resolution with Different Higher-Order Inference Methods This repository contains the implementation of the paper: Revealing th
 52 Jan 4, 2023
52 Jan 4, 2023

SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings This repository contains the code and pre-trained models for our paper SimCSE: Simple Contr
2.5k Jan 7, 2023
SpikeX - SpaCy Pipes for Knowledge Extraction
SpikeX is a collection of pipes ready to be plugged in a spaCy pipeline. It aims to help in building knowledge extraction tools with almost-zero effort.
 384 Dec 12, 2022
384 Dec 12, 2022
The repo contains the code of the ACL2020 paper `Dice Loss for Data-imbalanced NLP Tasks`
Dice Loss for NLP Tasks This repository contains code for Dice Loss for Data-imbalanced NLP Tasks at ACL2020. Setup Install Package Dependencies The c
 223 Dec 17, 2022
223 Dec 17, 2022
Official implementation of GraphMask as presented in our paper Interpreting Graph Neural Networks for NLP With Differentiable Edge Masking.
GraphMask This repository contains an implementation of GraphMask, the interpretability technique for graph neural networks presented in our ICLR 2021
 29 Sep 2, 2022
29 Sep 2, 2022
skweak: A software toolkit for weak supervision applied to NLP tasks
Labelled data remains a scarce resource in many practical NLP scenarios. This is especially the case when working with resource-poor languages (or text domains), or when using task-specific labels without pre-existing datasets. The only available option is often to collect and annotate texts by hand, which is expensive and time-consuming.
 850 Dec 28, 2022
850 Dec 28, 2022

Code for producing Japanese GPT-2 provided by rinna Co., Ltd.
japanese-gpt2 This repository provides the code for training Japanese GPT-2 models. This code has been used for producing japanese-gpt2-medium release
 491 Jan 7, 2023
491 Jan 7, 2023

FedNLP: A Benchmarking Framework for Federated Learning in Natural Language Processing
FedNLP is a research-oriented benchmarking framework for advancing federated learning (FL) in natural language processing (NLP). It uses FedML repository as the git submodule. In other words, FedNLP only focuses on adavanced models and dataset, while FedML supports various federated optimizers (e.g., FedAvg) and platforms (Distributed Computing, IoT/Mobile, Standalone).
 216 Nov 27, 2022
216 Nov 27, 2022

nlp基础任务
NLP算法 说明 此算法仓库包括文本分类、序列标注、关系抽取、文本匹配、文本相似度匹配这五个主流NLP任务,涉及到22个相关的模型算法。 框架结构 文件结构 all_models ├── Base_line │ ├── __init__.py │ ├── base_data_process.
 23 Sep 22, 2022
23 Sep 22, 2022

Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
 176 Nov 28, 2022
176 Nov 28, 2022
Awesome-NLP-Research (ANLP)
Awesome-NLP-Research (ANLP)
 72 Dec 19, 2022
72 Dec 19, 2022

Wetterdienst - Open weather data for humans
We are a group of like-minded people trying to make access to weather data in Python feel like a warm summer breeze, similar to other projects like rdwd for the R language, which originally drew our interest in this project.
 226 Jan 4, 2023
226 Jan 4, 2023
A fast and easy implementation of Transformer with PyTorch.
FasySeq FasySeq is a shorthand as a Fast and easy sequential modeling toolkit. It aims to provide a seq2seq model to researchers and developers, which
 7 Jul 18, 2022
7 Jul 18, 2022
中文空间语义理解评测
中文空间语义理解评测 最新消息 2021-04-10 🚩 排行榜发布: Leaderboard 2021-04-05 基线系统发布: SpaCE2021-Baseline 2021-04-05 开放数据提交: 提交结果 2021-04-01 开放报名: 我要报名 2021-04-01 数据集 pa
 40 Jan 4, 2023
40 Jan 4, 2023
Python bindings to libpostal for fast international address parsing/normalization
pypostal These are the official Python bindings to https://github.com/openvenues/libpostal, a fast statistical parser/normalizer for street addresses
 651 Dec 16, 2022
651 Dec 16, 2022

Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
 4.7k Jan 1, 2023
4.7k Jan 1, 2023
The source code for the Cutoff data augmentation approach proposed in this paper: "A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation".
Cutoff: A Simple Data Augmentation Approach for Natural Language This repository contains source code necessary to reproduce the results presented in
 49 Dec 22, 2022
49 Dec 22, 2022
Source code for the GPT-2 story generation models in the EMNLP 2020 paper "STORIUM: A Dataset and Evaluation Platform for Human-in-the-Loop Story Generation"
Storium GPT-2 Models This is the official repository for the GPT-2 models described in the EMNLP 2020 paper [STORIUM: A Dataset and Evaluation Platfor
 27 Dec 20, 2022
27 Dec 20, 2022
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language This repository contains UA-GEC data and an accompanying Python lib
 226 Dec 29, 2022
226 Dec 29, 2022
Learning Dense Representations of Phrases at Scale (Lee et al., 2020)
DensePhrases DensePhrases provides answers to your natural language questions from the entire Wikipedia in real-time. While it efficiently searches th
540 Dec 30, 2022

Tracking Progress in Natural Language Processing
Repository to track the progress in Natural Language Processing (NLP), including the datasets and the current state-of-the-art for the most common NLP tasks.
 21.2k Dec 30, 2022
21.2k Dec 30, 2022
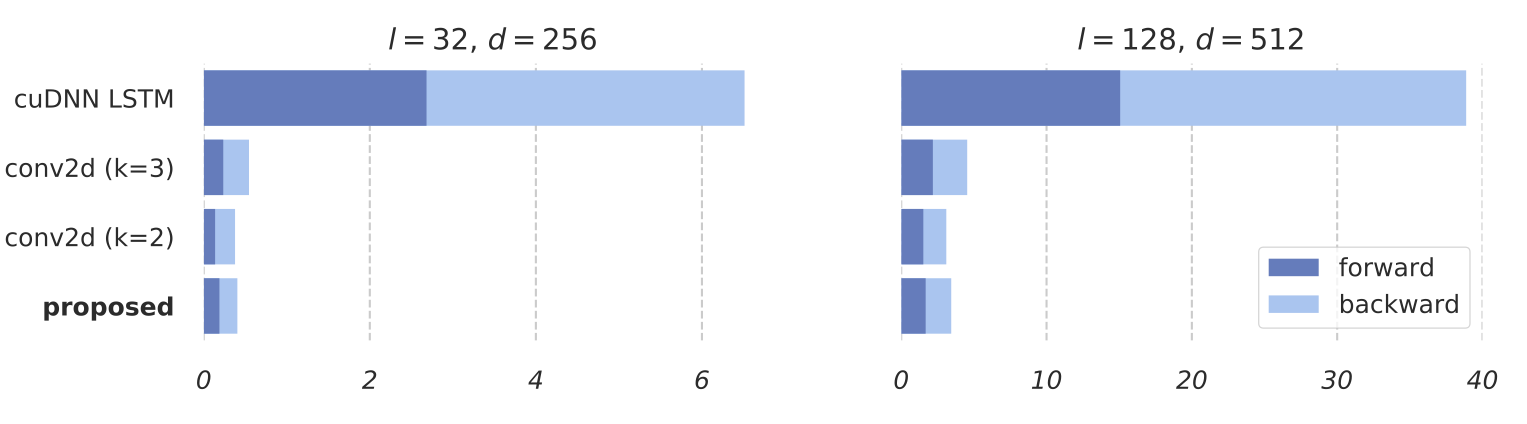
Training RNNs as Fast as CNNs (https://arxiv.org/abs/1709.02755)
News SRU++, a new SRU variant, is released. [tech report] [blog] The experimental code and SRU++ implementation are available on the dev branch which
 2.1k Jan 1, 2023
2.1k Jan 1, 2023
Library for faster pinned CPU - GPU transfer in Pytorch
SpeedTorch Faster pinned CPU tensor - GPU Pytorch variabe transfer and GPU tensor - GPU Pytorch variable transfer, in certain cases. Update 9-29-1
 657 Dec 19, 2022
657 Dec 19, 2022
Python package for earth-observing satellite data processing
Satpy The Satpy package is a python library for reading and manipulating meteorological remote sensing data and writing it to various image and data f
 882 Dec 27, 2022
882 Dec 27, 2022
An easier way to build neural search on the cloud
An easier way to build neural search on the cloud Jina is a deep learning-powered search framework for building cross-/multi-modal search systems (e.g
17k Jan 2, 2023

Release of SPLASH: Dataset for semantic parse correction with natural language feedback in the context of text-to-SQL parsing
SPLASH: Semantic Parsing with Language Assistance from Humans SPLASH is dataset for the task of semantic parse correction with natural language feedba
 35 Oct 31, 2022
35 Oct 31, 2022

⚡ boost inference speed of T5 models by 5x & reduce the model size by 3x using fastT5.
Reduce T5 model size by 3X and increase the inference speed up to 5X. Install Usage Details Functionalities Benchmarks Onnx model Quantized onnx model
 399 Jan 5, 2023
399 Jan 5, 2023

Repository to hold code for the cap-bot varient that is being presented at the SIIC Defence Hackathon 2021.
capbot-siic Repository to hold code for the cap-bot varient that is being presented at the SIIC Defence Hackathon 2021. Problem Inspiration A plethora
 19 Feb 17, 2022
19 Feb 17, 2022
Package for controllable summarization
summarizers summarizers is package for controllable summarization based CTRLsum. currently, we only supports English. It doesn't work in other languag
 72 Dec 7, 2022
72 Dec 7, 2022
a Deep Learning Framework for Text
DeLFT DeLFT (Deep Learning Framework for Text) is a Keras and TensorFlow framework for text processing, focusing on sequence labelling (e.g. named ent
 350 Dec 19, 2022
350 Dec 19, 2022
Natural language detection
Detect the language of text. What’s so cool about franc? franc can support more languages(†) than any other library franc is packaged with support for
 3.8k Jan 2, 2023
3.8k Jan 2, 2023
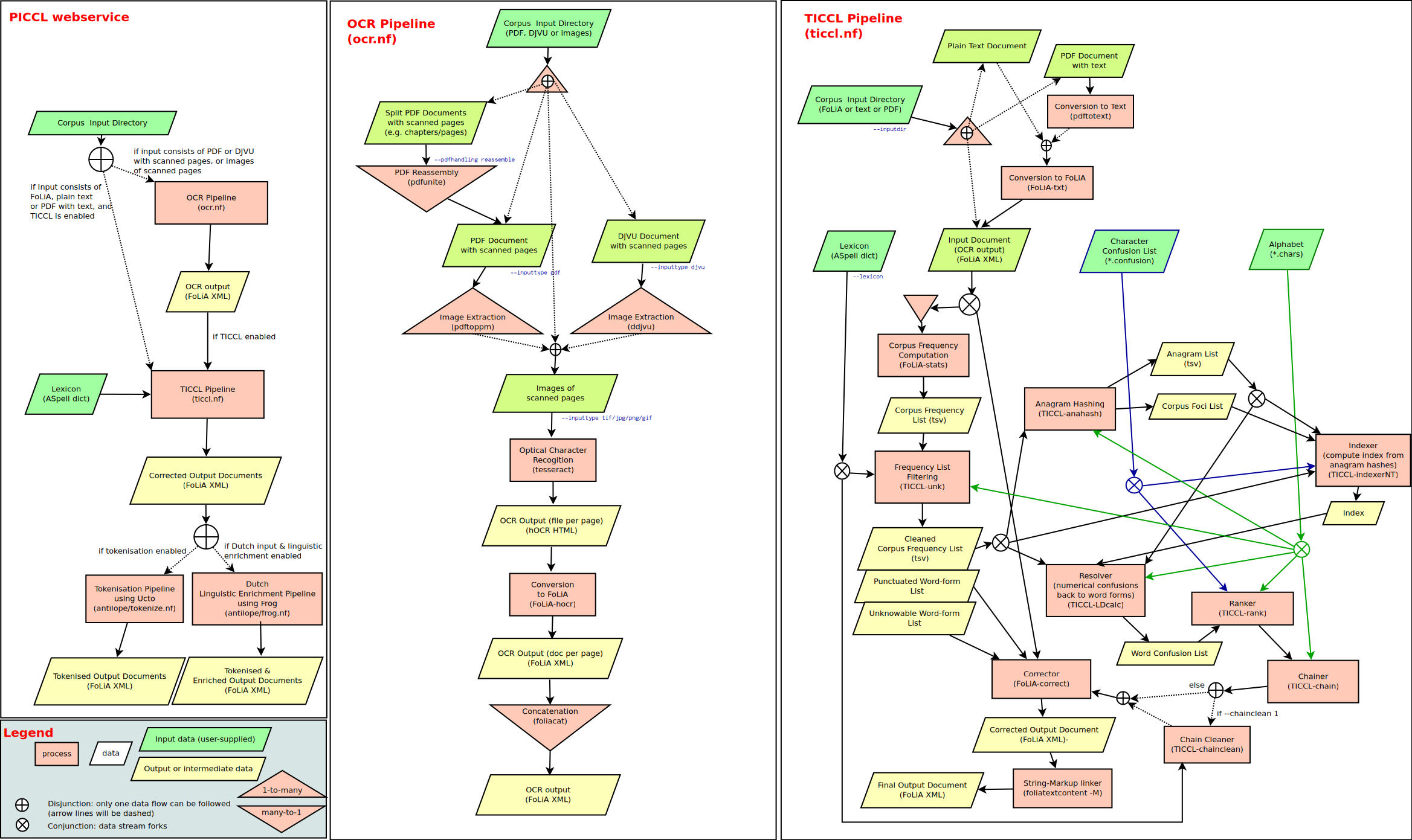
A set of workflows for corpus building through OCR, post-correction and normalisation
PICCL: Philosophical Integrator of Computational and Corpus Libraries PICCL offers a workflow for corpus building and builds on a variety of tools. Th
 41 Dec 27, 2022
41 Dec 27, 2022
Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
176 Nov 28, 2022
Lightning Fast Language Prediction 🚀
whatthelang Lightning Fast Language Prediction 🚀 Dependencies The dependencies can be installed using the requirements.txt file: $ pip install -r req
 152 Oct 16, 2022
152 Oct 16, 2022
👄 The most accurate natural language detection library for Java and the JVM, suitable for long and short text alike
Quick Info this library tries to solve language detection of very short words and phrases, even shorter than tweets makes use of both statistical and
 532 Dec 28, 2022
532 Dec 28, 2022

Deep Learning Chinese Word Segment
引用 本项目模型BiLSTM+CRF参考论文:http://www.aclweb.org/anthology/N16-1030 ,IDCNN+CRF参考论文:https://arxiv.org/abs/1702.02098 构建 安装好bazel代码构建工具,安装好tensorflow(目前本项目需
 2.1k Dec 23, 2022
2.1k Dec 23, 2022

A spherical CNN for weather forecasting
DeepSphere-Weather - Deep Learning on the sphere for weather/climate applications. The code in this repository provides a scalable and flexible framew
 47 Dec 25, 2022
47 Dec 25, 2022

CUAD
Contract Understanding Atticus Dataset This repository contains code for the Contract Understanding Atticus Dataset (CUAD), a dataset for legal contra
 273 Dec 17, 2022
273 Dec 17, 2022
☀️ Measuring the accuracy of BBC weather forecasts in Honolulu, USA
Accuracy of BBC Weather forecasts for Honolulu This repository records the forecasts made by BBC Weather for the city of Honolulu, USA. Essentially, t
 12 Oct 15, 2022
12 Oct 15, 2022
Contract Understanding Atticus Dataset
Contract Understanding Atticus Dataset This repository contains code for the Contract Understanding Atticus Dataset (CUAD), a dataset for legal contra
273 Dec 17, 2022