250 Repositories
Python word-embeddings Libraries
LUKE -- Language Understanding with Knowledge-based Embeddings
LUKE (Language Understanding with Knowledge-based Embeddings) is a new pre-trained contextualized representation of words and entities based on transf
 587 Dec 30, 2022
587 Dec 30, 2022
Phrase-BERT: Improved Phrase Embeddings from BERT with an Application to Corpus Exploration
Phrase-BERT: Improved Phrase Embeddings from BERT with an Application to Corpus Exploration This is the official repository for the EMNLP 2021 long pa
 70 Dec 11, 2022
70 Dec 11, 2022

Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks.
The Lottery Ticket Hypothesis for Pre-trained BERT Networks Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks. [NeurIPS
 122 Dec 14, 2022
122 Dec 14, 2022
Word and phrase lists in CSV
Word Lists Word and phrase lists in CSV, collected from different sources. Oxford Word Lists: oxford-5k.csv - Oxford 3000 and 5000 oxford-opal.csv - O
 14 Oct 14, 2022
14 Oct 14, 2022
Official Implementation of "Learning Disentangled Behavior Embeddings"
DBE: Disentangled-Behavior-Embedding Official implementation of Learning Disentangled Behavior Embeddings (NeurIPS 2021). Environment requirement The
 12 Sep 28, 2022
12 Sep 28, 2022
OpenL3: Open-source deep audio and image embeddings
OpenL3 OpenL3 is an open-source Python library for computing deep audio and image embeddings. Please refer to the documentation for detailed instructi
 326 Jan 2, 2023
326 Jan 2, 2023
Generate text captions for images from their CLIP embeddings. Includes PyTorch model code and example training script.
clip-text-decoder Generate text captions for images from their CLIP embeddings. Includes PyTorch model code and example training script. Example Predi
 36 Dec 21, 2022
36 Dec 21, 2022
Resources related to EMNLP 2021 paper "FAME: Feature-Based Adversarial Meta-Embeddings for Robust Input Representations"
FAME: Feature-based Adversarial Meta-Embeddings This is the companion code for the experiments reported in the paper "FAME: Feature-Based Adversarial
 11 Nov 27, 2022
11 Nov 27, 2022
Switch spaces for knowledge graph embeddings
SwisE Switch spaces for knowledge graph embeddings. Requirements: python3 pytorch numpy tqdm Reproduce the results To reproduce the reported results,
 4 Dec 1, 2021
4 Dec 1, 2021
Exploring dimension-reduced embeddings
sleepwalk Exploring dimension-reduced embeddings This is the code repository. See here for the Sleepwalk web page. License and disclaimer This program
 91 Nov 29, 2022
91 Nov 29, 2022
A fast, efficient universal vector embedding utility package.
Magnitude: a fast, simple vector embedding utility library A feature-packed Python package and vector storage file format for utilizing vector embeddi
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Repo for the paper "DiLBERT: Cheap Embeddings for Disease Related Medical NLP"
DiLBERT Repo for the paper "DiLBERT: Cheap Embeddings for Disease Related Medical NLP" Pretrained Model The pretrained model presented in the paper is
 2 Dec 15, 2022
2 Dec 15, 2022
Code for the paper "A Simple but Tough-to-Beat Baseline for Sentence Embeddings".
Code for the paper "A Simple but Tough-to-Beat Baseline for Sentence Embeddings".
 1.1k Dec 27, 2022
1.1k Dec 27, 2022

The best way to convert files on your computer, be it .pdf to .png, .pdf to .docx, .png to .ico, or anything you can imagine.
The best way to convert files on your computer, be it .pdf to .png, .pdf to .docx, .png to .ico, or anything you can imagine.
 2 Nov 20, 2021
2 Nov 20, 2021
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 A repository part of the MarIA project. Corpora 📃 Corpora Number of documents Number of tokens Size (GB) BNE 201,080,084
 203 Dec 20, 2022
203 Dec 20, 2022
Python script to generate Vale linting rules from word usage guidance in the Red Hat Supplementary Style Guide
ssg-vale-rules-gen Python script to generate Vale linting rules from word usage guidance in the Red Hat Supplementary Style Guide. These rules are use
 1 Jan 13, 2022
1 Jan 13, 2022

This is the code used in the paper "Entity Embeddings of Categorical Variables".
This is the code used in the paper "Entity Embeddings of Categorical Variables". If you want to get the original version of the code used for the Kagg
 845 Nov 29, 2022
845 Nov 29, 2022
A socket script to obtain chinese phones-sequence for any english word
Foreign Pronunciation Generator (English-Chinese) We provide a simple socket script for acquiring Chinese pronunciation of English words (phones in ai
 5 Jul 25, 2022
5 Jul 25, 2022
Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings
Text2Music Emotion Embedding Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings Reference Emotion Embedding Spaces for Matching
 50 Dec 5, 2022
50 Dec 5, 2022
This Project is based on NLTK It generates a RANDOM WORD from a predefined list of words, From that random word it read out the word, its meaning with parts of speech , its antonyms, its synonyms
This Project is based on NLTK(Natural Language Toolkit) It generates a RANDOM WORD from a predefined list of words, From that random word it read out the word, its meaning with parts of speech , its antonyms, its synonyms
 2 Nov 17, 2021
2 Nov 17, 2021
This project uses word frequency and Term Frequency-Inverse Document Frequency to summarize a text.
Text Summarizer This project uses word frequency and Term Frequency-Inverse Document Frequency to summarize a text. Team Members This mini-project was
 1 Nov 16, 2021
1 Nov 16, 2021
This repo is the code release of EMNLP 2021 conference paper "Connect-the-Dots: Bridging Semantics between Words and Definitions via Aligning Word Sense Inventories".
Connect-the-Dots: Bridging Semantics between Words and Definitions via Aligning Word Sense Inventories This repo is the code release of EMNLP 2021 con
 12 Nov 22, 2022
12 Nov 22, 2022

An open-source online reverse dictionary.
An open-source online reverse dictionary.
 6.3k Jan 9, 2023
6.3k Jan 9, 2023
Rates how pog a word or user is. Not random and does have *some* kind of algorithm to it.
PogRater :D Rates how pogchamp a word is :D A fun project coded by JBYT27 using Python3 Have you ever wondered how pog a word is? Well, congrats, you
 2 Jun 25, 2022
2 Jun 25, 2022

Code repository for EMNLP 2021 paper 'Adversarial Attacks on Knowledge Graph Embeddings via Instance Attribution Methods'
Adversarial Attacks on Knowledge Graph Embeddings via Instance Attribution Methods This is the code repository to accompany the EMNLP 2021 paper on ad
 7 Sep 25, 2022
7 Sep 25, 2022
Simple Reddit bot that replies to comments containing a certain word.
reddit-replier-bot Small comment reply bot based on PRAW. This script will scan the comments of a subreddit as they come in and look for a trigger wor
 0 Jun 4, 2022
0 Jun 4, 2022
🌸 fastText + Bloom embeddings for compact, full-coverage vectors with spaCy
floret: fastText + Bloom embeddings for compact, full-coverage vectors with spaCy floret is an extended version of fastText that can produce word repr
 222 Dec 16, 2022
222 Dec 16, 2022

WORD: Revisiting Organs Segmentation in the Whole Abdominal Region
WORD: Revisiting Organs Segmentation in the Whole Abdominal Region. This repository provides the codebase and dataset for our work WORD: Revisiting Or
 71 Jan 7, 2023
71 Jan 7, 2023
Interpretable-contrastive-word-mover-s-embedding
Interpretable-contrastive-word-mover-s-embedding Paper Datasets Here is a Dropbox link to the datasets used in the paper: https://www.dropbox.com/sh/n
 0 Nov 2, 2021
0 Nov 2, 2021
gtfs2vec - Learning GTFS Embeddings for comparing PublicTransport Offer in Microregions
gtfs2vec This is a companion repository for a gtfs2vec - Learning GTFS Embeddings for comparing PublicTransport Offer in Microregions publication. Vis
 5 Oct 10, 2022
5 Oct 10, 2022

Keywords : Streamlit, BertTokenizer, BertForMaskedLM, Pytorch
Next Word Prediction Keywords : Streamlit, BertTokenizer, BertForMaskedLM, Pytorch 🎬 Project Demo ✔ Application is hosted on Streamlit. You can see t
 3 Aug 26, 2022
3 Aug 26, 2022
This code is for a bot which will find a Twitter user's most tweeted word and tweet that word, tagging said user
max_tweeted_word This code is for a bot which will find a Twitter user's most tweeted word and tweet that word, tagging said user The program uses twe
 1 Nov 29, 2021
1 Nov 29, 2021
Japanese Long-Unit-Word Tokenizer with RemBertTokenizerFast of Transformers
Japanese-LUW-Tokenizer Japanese Long-Unit-Word (国語研長単位) Tokenizer for Transformers based on 青空文庫 Basic Usage from transformers import RemBertToken
 3 Dec 22, 2021
3 Dec 22, 2021
The code of paper ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs. Zhanqiu Zhang, Jie Wang, Jiajun Chen, Shuiwang Ji, Feng Wu. NeurIPS 2021.
ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs This is the code of paper ConE: Cone Embeddings for Multi-Hop Reasoning over Knowl
 3 Oct 28, 2021
3 Oct 28, 2021
A PyTorch implementation of unsupervised SimCSE
A PyTorch implementation of unsupervised SimCSE
 99 Dec 23, 2022
99 Dec 23, 2022
ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs
ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs This is the code of paper ConE: Cone Embeddings for Multi-Hop Reasoning over Knowl
33 Dec 7, 2022
Towhee is a flexible machine learning framework currently focused on computing deep learning embeddings over unstructured data.
Towhee is a flexible machine learning framework currently focused on computing deep learning embeddings over unstructured data.
 1.7k Jan 8, 2023
1.7k Jan 8, 2023
Count the frequency of letters or words in a text file and show a graph.
Word Counter By EBUS Coding Club Count the frequency of letters or words in a text file and show a graph. Requirements Python 3.9 or higher matplotlib
 0 Apr 9, 2022
0 Apr 9, 2022
Language Models for the legal domain in Spanish done @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish legal domain Language Model ⚖️ This repository contains the page for two main resources for the Spanish legal domain: A RoBERTa model: https:/
12 Nov 14, 2022
Bootstrapped Unsupervised Sentence Representation Learning (ACL 2021)
Install first pip3 install -e . Training python3 training/unsupervised_tuning.py python3 training/supervised_tuning.py python3 training/multilingual_
 26 Jul 22, 2022
26 Jul 22, 2022

Code for reproducing our paper: LMSOC: An Approach for Socially Sensitive Pretraining
LMSOC: An Approach for Socially Sensitive Pretraining Code for reproducing the paper LMSOC: An Approach for Socially Sensitive Pretraining to appear a
 11 Dec 20, 2022
11 Dec 20, 2022
Recognition of 38 speech commands in russian. Based on Yandex Cup 2021 ML Challenge: ASR
Speech_38_ru_commands Recognition of 38 speech commands in russian. Based on Yandex Cup 2021 ML Challenge: ASR Программа умеет распознавать 38 ключевы
 9 May 5, 2022
9 May 5, 2022
A Word Level Transformer layer based on PyTorch and 🤗 Transformers.
Transformer Embedder A Word Level Transformer layer based on PyTorch and 🤗 Transformers. How to use Install the library from PyPI: pip install transf
 27 Nov 20, 2022
27 Nov 20, 2022
On-device wake word detection powered by deep learning.
Porcupine Made in Vancouver, Canada by Picovoice Porcupine is a highly-accurate and lightweight wake word engine. It enables building always-listening
 2.8k Dec 29, 2022
2.8k Dec 29, 2022

Finetuner allows one to tune the weights of any deep neural network for better embeddings on search tasks
Finetuner allows one to tune the weights of any deep neural network for better embeddings on search tasks
 794 Dec 31, 2022
794 Dec 31, 2022
Vector AI — A platform for building vector based applications. Encode, query and analyse data using vectors.
Vector AI is a framework designed to make the process of building production grade vector based applications as quickly and easily as possible. Create
 267 Dec 23, 2022
267 Dec 23, 2022

EMNLP'2021: SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings This repository contains the code and pre-trained models for our paper SimCSE: Simple Contr
 2.5k Dec 29, 2022
2.5k Dec 29, 2022
Code for ICML2019 Paper "Compositional Invariance Constraints for Graph Embeddings"
Dependencies NOTE: This code has been updated, if you were using this repo earlier and experienced issues that was due to an outaded codebase. Please
 43 Nov 25, 2022
43 Nov 25, 2022
 2 Jan 28, 2022
2 Jan 28, 2022
This repository contains the code for EMNLP-2021 paper "Word-Level Coreference Resolution"
Word-Level Coreference Resolution This is a repository with the code to reproduce the experiments described in the paper of the same name, which was a
 79 Dec 27, 2022
79 Dec 27, 2022

Wikipedia WordCloud App generate Wikipedia word cloud art created using python's streamlit, matplotlib, wikipedia and wordcloud packages
Wikipedia WordCloud App Wikipedia WordCloud App generate Wikipedia word cloud art created using python's streamlit, matplotlib, wikipedia and wordclou
 5 Jan 2, 2022
5 Jan 2, 2022
Using contrastive learning and OpenAI's CLIP to find good embeddings for images with lossy transformations
Creating Robust Representations from Pre-Trained Image Encoders using Contrastive Learning Sriram Ravula, Georgios Smyrnis This is the code for our pr
 26 Dec 10, 2022
26 Dec 10, 2022
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
 37 Sep 5, 2022
37 Sep 5, 2022
Telegram Group Management Bot based on phython !!!
How to setup/deploy. For easiest way to deploy this Bot click on the below button Mᴀᴅᴇ Bʏ Sᴜᴘᴘᴏʀᴛ Sᴏᴜʀᴄᴇ Find This Bot on Telegram A modular Telegram
 5 Nov 17, 2021
5 Nov 17, 2021
split Word file by chapter
split Word file by chapter we use the mircosoft word api to code this tool api url:https://docs.microsoft.com/zh-cn/dotnet/api/ if this tool is good f
 5 Nov 6, 2021
5 Nov 6, 2021

Implementation of Neural Distance Embeddings for Biological Sequences (NeuroSEED) in PyTorch
Neural Distance Embeddings for Biological Sequences Official implementation of Neural Distance Embeddings for Biological Sequences (NeuroSEED) in PyTo
 56 Dec 23, 2022
56 Dec 23, 2022
Code for ACL'2021 paper WARP 🌀 Word-level Adversarial ReProgramming
Code for ACL'2021 paper WARP 🌀 Word-level Adversarial ReProgramming. Outperforming `GPT-3` on SuperGLUE Few-Shot text classification.
 75 Nov 6, 2022
75 Nov 6, 2022

A Pytorch implementation of "Splitter: Learning Node Representations that Capture Multiple Social Contexts" (WWW 2019).
Splitter ⠀⠀ A PyTorch implementation of Splitter: Learning Node Representations that Capture Multiple Social Contexts (WWW 2019). Abstract Recent inte
 201 Nov 9, 2022
201 Nov 9, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022

A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
 488 Nov 28, 2022
488 Nov 28, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
 586 Dec 24, 2022
586 Dec 24, 2022

PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations"
Poincaré Embeddings for Learning Hierarchical Representations PyTorch implementation of Poincaré Embeddings for Learning Hierarchical Representations
 1.6k Dec 25, 2022
1.6k Dec 25, 2022
Original implementation of the pooling method introduced in "Speaker embeddings by modeling channel-wise correlations"
Speaker-Embeddings-Correlation-Pooling This is the original implementation of the pooling method introduced in "Speaker embeddings by modeling channel
 10 Apr 30, 2022
10 Apr 30, 2022
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022
Applying "Load What You Need: Smaller Versions of Multilingual BERT" to LaBSE
smaller-LaBSE LaBSE(Language-agnostic BERT Sentence Embedding) is a very good method to get sentence embeddings across languages. But it is hard to fi
 13 Sep 2, 2022
13 Sep 2, 2022

Embeddinghub is a database built for machine learning embeddings.
Embeddinghub is a database built for machine learning embeddings.
 1.2k Jan 1, 2023
1.2k Jan 1, 2023
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022
This repository contains the code for EMNLP-2021 paper "Word-Level Coreference Resolution"
Word-Level Coreference Resolution This is a repository with the code to reproduce the experiments described in the paper of the same name, which was a
79 Dec 27, 2022

MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving.
MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving. It is a comprehensive framework for research purpose that integrates popular MWP benchmark datasets and typical deep learning-based MWP algorithms.
 119 Jan 4, 2023
119 Jan 4, 2023
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
Improving Visual-Semantic Embeddings with Hard Negatives Code for the image-caption retrieval methods from VSE++: Improving Visual-Semantic Embeddings
 441 Dec 5, 2022
441 Dec 5, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022
从flomo导出的笔记中生成词云
flomo-word-cloud 从flomo导出的笔记中生成词云 如何使用? 将本项目克隆到你的电脑上,使用如下的命令,安装所需python库 pip install -r requirements.txt 在项目里新建一个file文件夹,把所有从flomo导出的html文件放入其中 运行main
 9 Dec 30, 2022
9 Dec 30, 2022

Learning Compatible Embeddings, ICCV 2021
LCE Learning Compatible Embeddings, ICCV 2021 by Qiang Meng, Chixiang Zhang, Xiaoqiang Xu and Feng Zhou Paper: Arxiv We cannot release source codes pu
 25 Dec 17, 2022
25 Dec 17, 2022
Large scale embeddings on a single machine.
Marius Marius is a system under active development for training embeddings for large-scale graphs on a single machine. Training on large scale graphs
 107 Jan 3, 2023
107 Jan 3, 2023
Versatile Generative Language Model
Versatile Generative Language Model This is the implementation of the paper: Exploring Versatile Generative Language Model Via Parameter-Efficient Tra
 17 Dec 2, 2022
17 Dec 2, 2022
PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations"
Poincaré Embeddings for Learning Hierarchical Representations PyTorch implementation of Poincaré Embeddings for Learning Hierarchical Representations
1.6k Dec 29, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
586 Dec 24, 2022
A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
488 Nov 28, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
 47 Sep 5, 2022
47 Sep 5, 2022
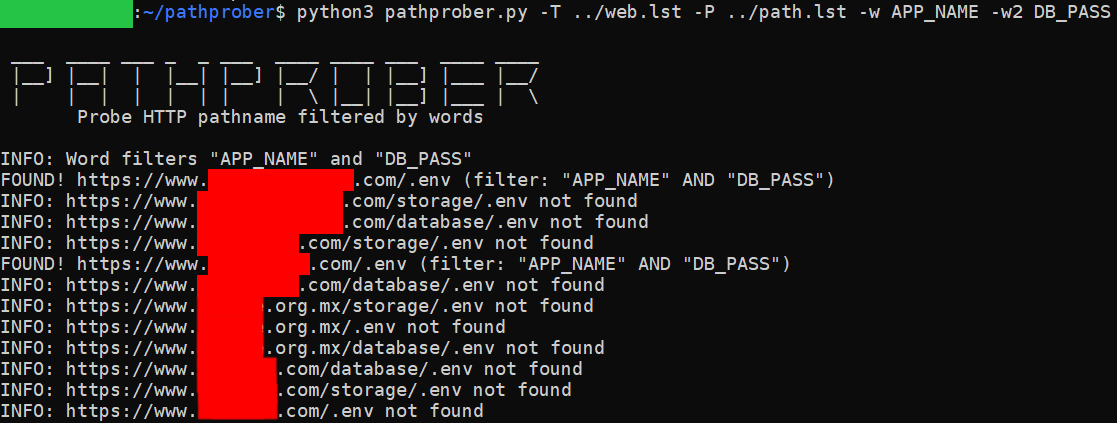
Probe and discover HTTP pathname using brute-force methodology and filtered by specific word or 2 words at once
pathprober Probe and discover HTTP pathname using brute-force methodology and filtered by specific word or 2 words at once. Purpose Brute-forcing webs
 41 Jul 6, 2022
41 Jul 6, 2022

An implementation of DeepMind's Relational Recurrent Neural Networks in PyTorch.
relational-rnn-pytorch An implementation of DeepMind's Relational Recurrent Neural Networks (Santoro et al. 2018) in PyTorch. Relational Memory Core (
 241 Nov 18, 2022
241 Nov 18, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
114 Nov 4, 2022

A PyTorch Implementation of "Watch Your Step: Learning Node Embeddings via Graph Attention" (NeurIPS 2018).
Attention Walk ⠀⠀ A PyTorch Implementation of Watch Your Step: Learning Node Embeddings via Graph Attention (NIPS 2018). Abstract Graph embedding meth
303 Dec 9, 2022
A Pytorch implementation of "Splitter: Learning Node Representations that Capture Multiple Social Contexts" (WWW 2019).
Splitter ⠀⠀ A PyTorch implementation of Splitter: Learning Node Representations that Capture Multiple Social Contexts (WWW 2019). Abstract Recent inte
201 Nov 9, 2022
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
203 Dec 20, 2022
DRIFT is a tool for Diachronic Analysis of Scientific Literature.
About DRIFT is a tool for Diachronic Analysis of Scientific Literature. The application offers user-friendly and customizable utilities for two modes:
 108 Dec 12, 2022
108 Dec 12, 2022
Implementation of Rotary Embeddings, from the Roformer paper, in Pytorch
Rotary Embeddings - Pytorch A standalone library for adding rotary embeddings to transformers in Pytorch, following its success as relative positional
 110 Dec 30, 2022
110 Dec 30, 2022
🤖 A Python library for learning and evaluating knowledge graph embeddings
PyKEEN PyKEEN (Python KnowlEdge EmbeddiNgs) is a Python package designed to train and evaluate knowledge graph embedding models (incorporating multi-m
 1.1k Jan 9, 2023
1.1k Jan 9, 2023
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022
Shared code for training sentence embeddings with Flax / JAX
flax-sentence-embeddings This repository will be used to share code for the Flax / JAX community event to train sentence embeddings on 1B+ training pa
 23 Dec 30, 2022
23 Dec 30, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
99 Dec 23, 2022

UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus
UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus General info This is
 71 Oct 25, 2022
71 Oct 25, 2022

Reliable probability face embeddings
ProbFace, arxiv This is a demo code of training and testing [ProbFace] using Tensorflow. ProbFace is a reliable Probabilistic Face Embeddging (PFE) me
 34 Dec 31, 2022
34 Dec 31, 2022
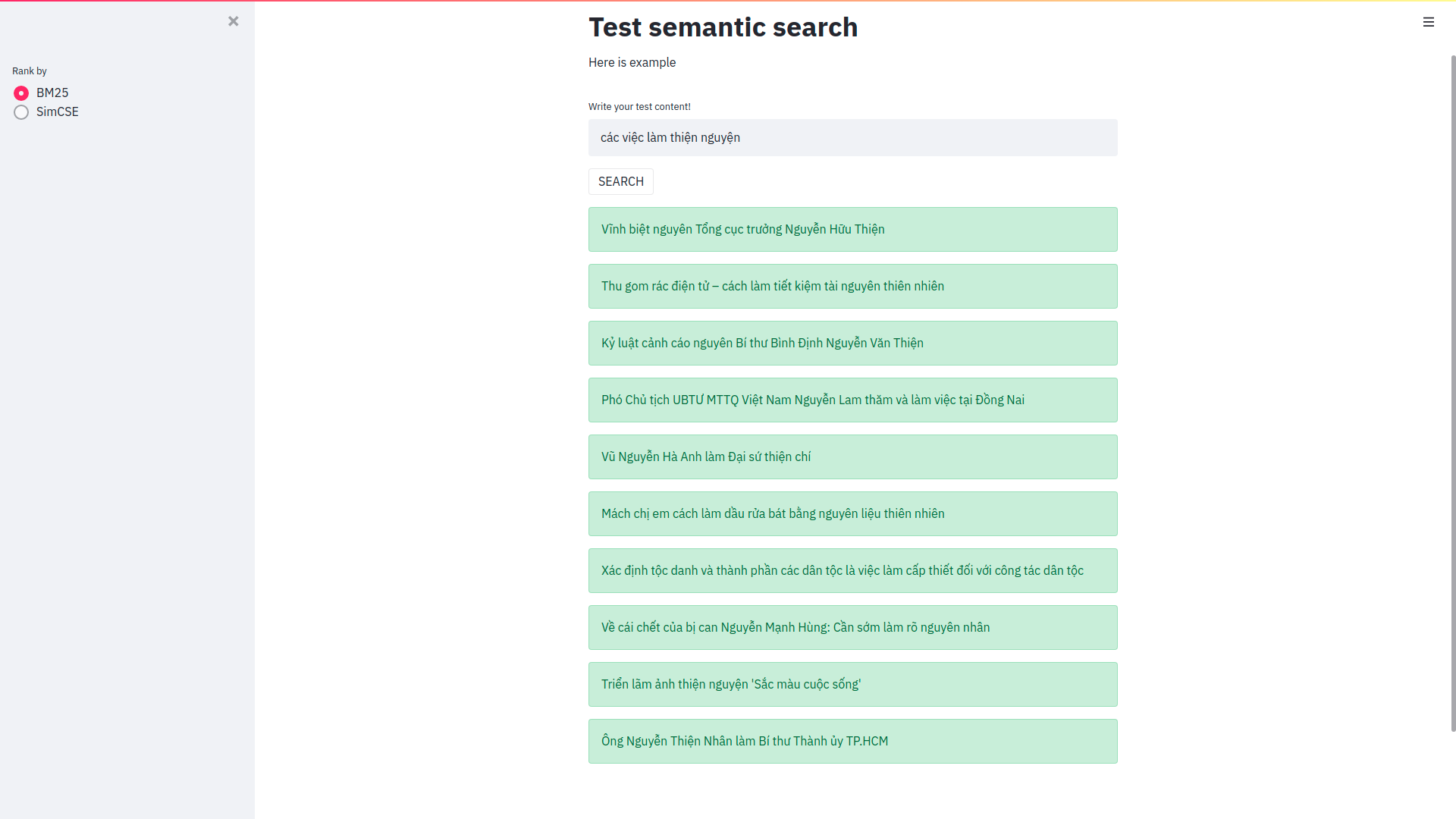
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings Trong bài viết này mình sẽ sử dụng pretrain model SimCS
 18 Nov 25, 2022
18 Nov 25, 2022
Code for the ACL2021 paper "Combining Static Word Embedding and Contextual Representations for Bilingual Lexicon Induction"
CSCBLI Code for our ACL Findings 2021 paper, "Combining Static Word Embedding and Contextual Representations for Bilingual Lexicon Induction". Require
 12 Oct 8, 2022
12 Oct 8, 2022
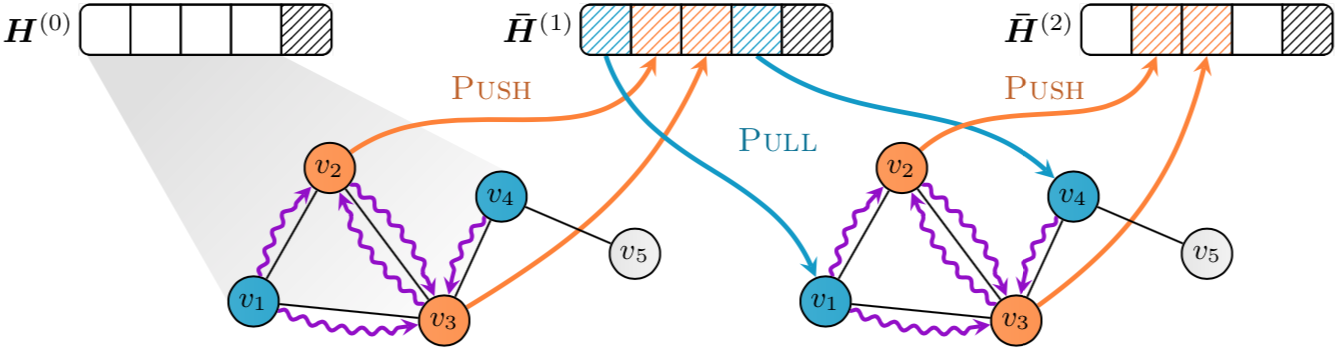
Implementation of "GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings" in PyTorch
PyGAS: Auto-Scaling GNNs in PyG PyGAS is the practical realization of our G NN A uto S cale (GAS) framework, which scales arbitrary message-passing GN
 139 Dec 25, 2022
139 Dec 25, 2022
Code for Graph-to-Tree Learning for Solving Math Word Problems (ACL 2020)
Graph-to-Tree Learning for Solving Math Word Problems PyTorch implementation of Graph based Math Word Problem solver described in our ACL 2020 paper G
 66 Nov 23, 2022
66 Nov 23, 2022
Paddle implementation for "Cross-Lingual Word Embedding Refinement by ℓ1 Norm Optimisation" (NAACL 2021)
L1-Refinement Paddle implementation for "Cross-Lingual Word Embedding Refinement by ℓ1 Norm Optimisation" (NAACL 2021) 🙈 A more detailed readme is co
 4 Jun 9, 2021
4 Jun 9, 2021