411 Repositories
Python Audio-driven-TalkingFace-HeadPose Libraries
This is a story bot, that will scrape stories from r/stories subreddit and convert it into an Audio File.
Introduction This is a story bot, that will scrape stories from r/stories subreddit and convert it into an Audio File. Installation pip install -r req
 11 Jun 30, 2022
11 Jun 30, 2022

digital audio workstation, instrument and effect plugins, wave editor
digital audio workstation, instrument and effect plugins, wave editor
 306 Jan 5, 2023
306 Jan 5, 2023
An 8D music player made to enjoy Halloween this year!🤘
HAPPY HALLOWEEN buddy! Split Player Hello There! Welcome to SplitPlayer... Supposed To Be A 8DPlayer.... You Decide.... It can play the ordinary audio
 1 Nov 4, 2021
1 Nov 4, 2021
[NeurIPS 2021] Official implementation of paper "Learning to Simulate Self-driven Particles System with Coordinated Policy Optimization".
Code for Coordinated Policy Optimization Webpage | Code | Paper | Talk (English) | Talk (Chinese) Hi there! This is the source code of the paper “Lear
 81 Dec 19, 2022
81 Dec 19, 2022
Using python to generate a bat script of repetitive lines of code that differ in some way but can sort out a group of audio files according to their common names
Batch Sorting Using python to generate a bat script of repetitive lines of code that differ in some way but can sort out a group of audio files accord
 1 Oct 29, 2021
1 Oct 29, 2021
Python script for extracting audio from video files and creating Mel spectrograms
video2spectrogram About This package is meant to automate the process of extracting audio files from videos and saving the plots computed from these a
 1 Oct 28, 2021
1 Oct 28, 2021
A Python 3 script for capturing and recording a SDR stream to a WAV file (or serving it to a HTTP audio stream).
rfsoapyfile A Python 3 script for capturing and recording a SDR stream to a WAV file (or serving it to a HTTP audio stream). The script is threaded fo
 4 Dec 19, 2022
4 Dec 19, 2022
Code Release for the paper "TriBERT: Full-body Human-centric Audio-visual Representation Learning for Visual Sound Separation"
TriBERT This repository contains the code for the NeurIPS 2021 paper titled "TriBERT: Full-body Human-centric Audio-visual Representation Learning for
 8 Aug 31, 2022
8 Aug 31, 2022
Audio Domain Adaptation for Acoustic Scene Classification using Disentanglement Learning
Audio Domain Adaptation for Acoustic Scene Classification using Disentanglement Learning Reference Abeßer, J. & Müller, M. Towards Audio Domain Adapt
 2 Jul 6, 2022
2 Jul 6, 2022
Audio Visual Emotion Recognition using TDA
Audio Visual Emotion Recognition using TDA RAVDESS database with two datasets analyzed: Video and Audio dataset: Audio-Dataset: https://www.kaggle.com
 3 May 11, 2022
3 May 11, 2022
SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch.
The SpeechBrain Toolkit SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch. The goal is to create a single, flexible, and us
 5.1k Jan 2, 2023
5.1k Jan 2, 2023
This repository contains code and data for "On the Multimodal Person Verification Using Audio-Visual-Thermal Data"
trimodal_person_verification This repository contains the code, and preprocessed dataset featured in "A Study of Multimodal Person Verification Using
 7 Aug 31, 2022
7 Aug 31, 2022
Official implementation of the paper WAV2CLIP: LEARNING ROBUST AUDIO REPRESENTATIONS FROM CLIP
Wav2CLIP 🚧 WIP 🚧 Official implementation of the paper WAV2CLIP: LEARNING ROBUST AUDIO REPRESENTATIONS FROM CLIP 📄 🔗 Ho-Hsiang Wu, Prem Seetharaman
 240 Dec 13, 2022
240 Dec 13, 2022
An app made in Python using the PyTube and Tkinter libraries to download videos and MP3 audio.
yt-dl (GUI Edition) An app made in Python using the PyTube and Tkinter libraries to download videos and MP3 audio. How do I download this? Windows: Fi
 1 Oct 23, 2021
1 Oct 23, 2021
Who calls the shots? Rethinking Few-Shot Learning for Audio (WASPAA 2021)
rethink-audio-fsl This repo contains the source code for the paper "Who calls the shots? Rethinking Few-Shot Learning for Audio." (WASPAA 2021) Table
 34 Dec 24, 2022
34 Dec 24, 2022

OpenClubhouse - A third-part web application based on flask to play Clubhouse audio.
OpenClubhouse - A third-part web application based on flask to play Clubhouse audio.
 1.1k Jan 5, 2023
1.1k Jan 5, 2023
Script simples para baixar vídeos/áudios/playlist do YouTube
🔗 VilelaTube ▶️ Script simples para baixar vídeos/áudios/playlist do YouTube Requisitos • Como usar • Melhorias futuras ⚠️ Atenção! ⚠️ Lembre-se de a
 2 Nov 3, 2021
2 Nov 3, 2021
A Telegram Userbot to play or streaming Audio and Video songs / files in Telegram Voice Chats.
Vcmusic-Userbot A Telegram Userbot to play or streaming Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram R
 3 Oct 23, 2021
3 Oct 23, 2021

Source code of our BMVC 2021 paper: AniFormer: Data-driven 3D Animation with Transformer
AniFormer This is the PyTorch implementation of our BMVC 2021 paper AniFormer: Data-driven 3D Animation with Transformer. Haoyu Chen, Hao Tang, Nicu S
 7 Oct 22, 2021
7 Oct 22, 2021
Source code of our BMVC 2021 paper: AniFormer: Data-driven 3D Animation with Transformer
AniFormer This is the PyTorch implementation of our BMVC 2021 paper AniFormer: Data-driven 3D Animation with Transformer. Haoyu Chen, Hao Tang, Nicu S
24 Nov 2, 2022
a dnn ai project to classify which food people are eating on audio recordings
Deep Learning - EAT Challenge About This project is part of an AI challenge of the DeepLearning course 2021 at the University of Augsburg. The objecti
 1 Oct 24, 2021
1 Oct 24, 2021
Retentioneering: product analytics, data-driven customer journey map optimization, marketing analytics, web analytics, transaction analytics, graph visualization, and behavioral segmentation with customer segments in Python.
What is Retentioneering? Retentioneering is a Python framework and library to assist product analysts and marketing analysts as it makes it easier to
 581 Jan 7, 2023
581 Jan 7, 2023
Official implementation of the paper Chunked Autoregressive GAN for Conditional Waveform Synthesis
Chunked Autoregressive GAN (CARGAN) Official implementation of the paper Chunked Autoregressive GAN for Conditional Waveform Synthesis [paper] [compan
150 Dec 6, 2022

PaSST: Efficient Training of Audio Transformers with Patchout
PaSST: Efficient Training of Audio Transformers with Patchout This is the implementation for Efficient Training of Audio Transformers with Patchout Pa
 165 Dec 26, 2022
165 Dec 26, 2022
Identify the emotion of multiple speakers in an Audio Segment
MevonAI - Speech Emotion Recognition Identify the emotion of multiple speakers in a Audio Segment Report Bug · Request Feature Try the Demo Here Table
 110 Dec 3, 2022
110 Dec 3, 2022
The description of FMFCC-A (audio track of FMFCC) dataset and Challenge resluts.
FMFCC-A This project is the description of FMFCC-A (audio track of FMFCC) dataset and Challenge resluts. The FMFCC-A dataset is shared through BaiduCl
 2 Oct 20, 2021
2 Oct 20, 2021
The description of FMFCC-A (audio track of FMFCC) dataset and Challenge resluts.
FMFCC-A This project is the description of FMFCC-A (audio track of FMFCC) dataset and Challenge resluts. The FMFCC-A dataset is shared through BaiduCl
18 Dec 24, 2022

Source code for "Taming Visually Guided Sound Generation" (Oral at the BMVC 2021)
Taming Visually Guided Sound Generation • [Project Page] • [ArXiv] • [Poster] • • Listen for the samples on our project page. Overview We propose to t
 226 Jan 3, 2023
226 Jan 3, 2023
Official implementation of A cappella: Audio-visual Singing VoiceSeparation, from BMVC21
Y-Net Official implementation of A cappella: Audio-visual Singing VoiceSeparation, British Machine Vision Conference 2021 Project page: ipcv.github.io
 12 Oct 22, 2022
12 Oct 22, 2022

Official Implementation for "StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery" (ICCV 2021 Oral)
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery (ICCV 2021 Oral) Run this model on Replicate Optimization: Global directions: Mapper: Check ou
 3.3k Jan 5, 2023
3.3k Jan 5, 2023
Audio Steganography is a technique used to transmit hidden information by modifying an audio signal in an imperceptible manner.
Audio Steganography Audio Steganography is a technique used to transmit hidden information by modifying an audio signal in an imperceptible manner. Ab
 1 Oct 17, 2021
1 Oct 17, 2021
Acoustic mosquito detection code with Bayesian Neural Networks
HumBugDB Acoustic mosquito detection with Bayesian Neural Networks. Extract audio or features from our large-scale dataset on Zenodo. This repository
 31 Nov 28, 2022
31 Nov 28, 2022
Official implementation of A cappella: Audio-visual Singing VoiceSeparation, from BMVC21
Y-Net Official implementation of A cappella: Audio-visual Singing VoiceSeparation, British Machine Vision Conference 2021 Project page: ipcv.github.io
12 Oct 22, 2022
MONAI Deploy App SDK offers a framework and associated tools to design, develop and verify AI-driven applications in the healthcare imaging domain.
MONAI Deploy App SDK offers a framework and associated tools to design, develop and verify AI-driven applications in the healthcare imaging domain.
 49 Dec 23, 2022
49 Dec 23, 2022
Download videos and audio with a graphical interface in python
Youtube-Downloader Download videos and audio with a graphical interface in python Windows To run windows using Command Prompt python main.py linux To
 2 Jan 7, 2022
2 Jan 7, 2022

GUI for a Vocal Remover that uses Deep Neural Networks.
GUI for a Vocal Remover that uses Deep Neural Networks.
 4.4k Jan 7, 2023
4.4k Jan 7, 2023
Telegram bot to download tiktok video/audio
TikTokDL (Bot) Telegram RoBot to Download Tiktok video/audio. Features: 👉 Download TikTok Video without Watermark 👉 Download TikTok Video with Water
 23 Nov 21, 2022
23 Nov 21, 2022
This bot can stream audio or video files and urls in telegram voice chats :)
Voice Chat Streamer This bot can stream audio or video files and urls in telegram voice chats :) 🎯 Follow me and star this repo for more telegram bot
 63 Dec 25, 2022
63 Dec 25, 2022

Youtube Downloader is a Graphic User Interface(GUI) that lets users download a Youtube Video or Audio through a URL
Youtube Downloader This Python and Tkinter based GUI allows users to directly download the Best Resolution Videos and Audios from Youtube. Pa-fy Insta
 2 Jun 25, 2022
2 Jun 25, 2022

A fast implementation of bss_eval metrics for blind source separation
fast_bss_eval Do you have a zillion BSS audio files to process and it is taking days ? Is your simulation never ending ? Fear no more! fast_bss_eval i
 99 Dec 13, 2022
99 Dec 13, 2022

Audio media crawler for lbry.
Audio media crawler for lbry. Requirements Python 3.8 Poetry 1.1.7 Elasticsearch 7.14.0 Lbry-sdk 0.99.0 Development This project uses poetry as a depe
 4 Dec 3, 2022
4 Dec 3, 2022
African language Speech Recognition - Speech-to-Text
Swahili-Speech-To-Text Table of Contents Swahili-Speech-To-Text Overview Scenario Approach Project Structure data: models: notebooks: scripts tests: l
 2 Jan 5, 2023
2 Jan 5, 2023
DaDRA (day-druh) is a Python library for Data-Driven Reachability Analysis.
DaDRA (day-druh) is a Python library for Data-Driven Reachability Analysis. The main goal of the package is to accelerate the process of computing estimates of forward reachable sets for nonlinear dynamical systems.
 2 Nov 8, 2021
2 Nov 8, 2021
GWpy is a collaboration-driven Python package providing tools for studying data from ground-based gravitational-wave detectors
GWpy is a collaboration-driven Python package providing tools for studying data from ground-based gravitational-wave detectors. GWpy provides a user-f
 342 Jan 7, 2023
342 Jan 7, 2023
RL-driven agent playing tic-tac-toe on starknet against challengers.
tictactoe-on-starknet RL-driven agent playing tic-tac-toe on starknet against challengers. GUI reference: https://pythonguides.com/create-a-game-using
 21 Jul 30, 2022
21 Jul 30, 2022
Official repository of PanoAVQA: Grounded Audio-Visual Question Answering in 360° Videos (ICCV 2021)
Pano-AVQA Official repository of PanoAVQA: Grounded Audio-Visual Question Answering in 360° Videos (ICCV 2021) [Paper] [Poster] [Video] Getting Starte
 9 Dec 23, 2022
9 Dec 23, 2022

University of Rochester 2021 Summer REU focusing on music sentiment transfer using CycleGAN
Music-Sentiment-Transfer University of Rochester 2021 Summer REU focusing on music sentiment transfer using CycleGAN Poster: Music Sentiment Transfer
 2 Jan 24, 2022
2 Jan 24, 2022
A Low Complexity Speech Enhancement Framework for Full-Band Audio (48kHz) based on Deep Filtering.
DeepFilterNet A Low Complexity Speech Enhancement Framework for Full-Band Audio (48kHz) based on Deep Filtering. libDF contains Rust code used for dat
 292 Dec 25, 2022
292 Dec 25, 2022

Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation
Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation The code repository for "Audio-Visual Generalized Few-Shot Learning with
 3 Jun 27, 2022
3 Jun 27, 2022
Official PyTorch implementation of "AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks"
AASIST This repository provides the overall framework for training and evaluating audio anti-spoofing systems proposed in 'AASIST: Audio Anti-Spoofing
 56 Jan 2, 2023
56 Jan 2, 2023
An audio-solving python funcaptcha solving module
funcapsolver funcapsolver is a funcaptcha audio-solving module, which allows captchas to be interacted with and solved with the use of google's speech
 8 Nov 21, 2022
8 Nov 21, 2022
Time-stretch audio clips quickly with PyTorch (CUDA supported)! Additional utilities for searching efficient transformations are included.
Time-stretch audio clips quickly with PyTorch (CUDA supported)! Additional utilities for searching efficient transformations are included.
 22 Jul 7, 2022
22 Jul 7, 2022

text to speech toolkit. 好用的中文语音合成工具箱,包含语音编码器、语音合成器、声码器和可视化模块。
ttskit Text To Speech Toolkit: 语音合成工具箱。 安装 pip install -U ttskit 注意 可能需另外安装的依赖包:torch,版本要求torch=1.6.0,=1.7.1,根据自己的实际环境安装合适cuda或cpu版本的torch。 ttskit的
 483 Jan 4, 2023
483 Jan 4, 2023
Zappa makes it super easy to build and deploy server-less, event-driven Python applications on AWS Lambda + API Gateway.
Zappa makes it super easy to build and deploy server-less, event-driven Python applications (including, but not limited to, WSGI web apps) on AWS Lambda + API Gateway. Think of it as "serverless" web hosting for your Python apps. That means infinite scaling, zero downtime, zero maintenance - and at a fraction of the cost of your current deployments!
 2.2k Jan 9, 2023
2.2k Jan 9, 2023
Rhythm-Finder is a unsupervised ML driven python powered web-application that can find the songs that suits you.
ML-powered Music Recommendation Engine
 23 Oct 9, 2022
23 Oct 9, 2022

Unofficial Implementation of Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration This repo contains only model Implementation of Zero-Shot Text-to-Speech for Text
 33 Sep 22, 2022
33 Sep 22, 2022

Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
 883 Jan 7, 2023
883 Jan 7, 2023

Django-Audiofield is a simple app that allows Audio files upload, management and conversion to different audio format (mp3, wav & ogg), which also makes it easy to play audio files into your Django application.
Django-Audiofield Description: Django Audio Management Tools Maintainer: Areski Contributors: list of contributors Django-Audiofield is a simple app t
 167 Nov 10, 2022
167 Nov 10, 2022
Music source separation is a task to separate audio recordings into individual sources
Music Source Separation Music source separation is a task to separate audio recordings into individual sources. This repository is an PyTorch implmeme
 958 Jan 3, 2023
958 Jan 3, 2023
Stor is a community-driven green cryptocurrency based on a proof of space and time consensus algorithm.
Stor Blockchain Stor is a community-driven green cryptocurrency based on a proof of space and time consensus algorithm. For more information, see our
 15 May 18, 2022
15 May 18, 2022
Gateware for the Terasic/Arrow DECA board, to become a USB2 high speed audio interface
DECA USB Audio Interface DECA based USB 2.0 High Speed audio interface Status / current limitations enumerates as class compliant audio device on Linu
 16 Mar 21, 2022
16 Mar 21, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022
A tool to fuck a video/audio quality using FFmpeg
Media quality fucker A tool to fuck a video/audio quality using FFmpeg How to use Download the source Download Python Extract FFmpeg Put what you want
 8 Jan 25, 2022
8 Jan 25, 2022
Reading list for research topics in sound event detection
Sound event detection aims at processing the continuous acoustic signal and converting it into symbolic descriptions of the corresponding sound events present at the auditory scene.
 64 Jan 5, 2023
64 Jan 5, 2023

pedalboard is a Python library for adding effects to audio.
pedalboard is a Python library for adding effects to audio. It supports a number of common audio effects out of the box, and also allows the use of VST3® and Audio Unit plugin formats for third-party effects.
 3.9k Jan 2, 2023
3.9k Jan 2, 2023

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022

Sync2Gen Code for ICCV 2021 paper: Scene Synthesis via Uncertainty-Driven Attribute Synchronization
Sync2Gen Code for ICCV 2021 paper: Scene Synthesis via Uncertainty-Driven Attribute Synchronization 0. Environment Environment: python 3.6 and cuda 10
 62 Dec 30, 2022
62 Dec 30, 2022
praudio provides audio preprocessing framework for Deep Learning audio applications
praudio provides objects and a script for performing complex preprocessing operations on entire audio datasets with one command.
 105 Dec 26, 2022
105 Dec 26, 2022
The official implementation of the Interspeech 2021 paper WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution.
WSRGlow The official implementation of the Interspeech 2021 paper WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution. Audio sa
 96 Jan 3, 2023
96 Jan 3, 2023
PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
samplernn-pytorch A PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model. It's based on the reference implem
 261 Dec 14, 2022
261 Dec 14, 2022

Simple torch.nn.module implementation of Alias-Free-GAN style filter and resample
Alias-Free-Torch Simple torch module implementation of Alias-Free GAN. This repository including Alias-Free GAN style lowpass sinc filter @filter.py A
 64 Dec 22, 2022
64 Dec 22, 2022
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
 42 Dec 9, 2022
42 Dec 9, 2022

Easy to use Audio Tagging in PyTorch
Audio Classification, Tagging & Sound Event Detection in PyTorch Progress: Fine-tune on audio classification Fine-tune on audio tagging Fine-tune on s
 15 Dec 22, 2022
15 Dec 22, 2022
FPGA based USB 2.0 high speed audio interface featuring multiple optical ADAT inputs and outputs
ADAT USB Audio Interface FPGA based USB 2.0 High Speed audio interface featuring multiple optical ADAT inputs and outputs Status / current limitations
78 Dec 31, 2022
This app converts an pdf file into the audio file.
PDF-to-Audio This app takes an pdf as an input and convert it into audio, and the library text-to-speech starts speaking the preffered page given in t
 3 Aug 4, 2021
3 Aug 4, 2021
A Repository of Community-Driven Natural Instructions
A Repository of Community-Driven Natural Instructions TLDR; this repository maintains a community effort to create a large collection of tasks and the
 244 Jan 4, 2023
244 Jan 4, 2023

Pytorch implementation of CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generation"
MUST-GAN Code | paper The Pytorch implementation of our CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generat
 46 Dec 26, 2022
46 Dec 26, 2022

Mventory is an API-driven solution for Makerspaces, Tinkerers, and Hackers.
Mventory is an API-driven inventory solution for Makers, Makerspaces, Hackspaces, and just about anyone else who needs to keep track of "stuff".
 107 Dec 21, 2022
107 Dec 21, 2022
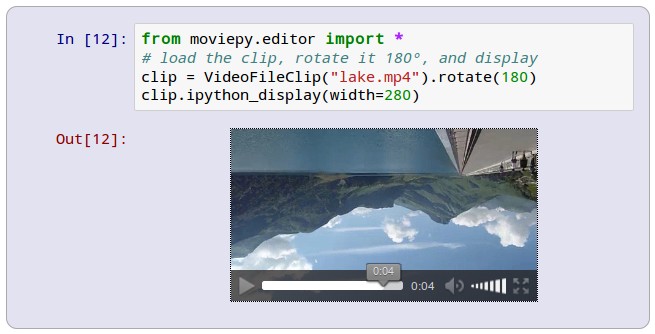
MoviePy is a Python library for video editing, can read and write all the most common audio and video formats
MoviePy is a Python library for video editing: cutting, concatenations, title insertions, video compositing (a.k.a. non-linear editing), video processing, and creation of custom effects. See the gallery for some examples of use.
 10k Jan 8, 2023
10k Jan 8, 2023
IDRLnet, a Python toolbox for modeling and solving problems through Physics-Informed Neural Network (PINN) systematically.
IDRLnet IDRLnet is a machine learning library on top of PyTorch. Use IDRLnet if you need a machine learning library that solves both forward and inver
 105 Dec 17, 2022
105 Dec 17, 2022
A Telegram Bot to Play Audio in Voice Chats With Youtube and Deezer support. Supports Live streaming from youtube Supports Mega Radio Fm Streamings
Bot To Stream Musics on PyTGcalls with Channel Support. A Telegram Bot to Play Audio in Voice Chats With Supports Live streaming from youtube and Mega
 37 Dec 15, 2022
37 Dec 15, 2022

FactSeg: Foreground Activation Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery (TGRS)
FactSeg: Foreground Activation Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery by Ailong Ma, Junjue Wang*, Yanfei Zhon
 43 Jan 5, 2023
43 Jan 5, 2023

Code for the Interspeech 2021 paper "AST: Audio Spectrogram Transformer".
AST: Audio Spectrogram Transformer Introduction Citing Getting Started ESC-50 Recipe Speechcommands Recipe AudioSet Recipe Pretrained Models Contact I
 603 Jan 7, 2023
603 Jan 7, 2023

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022
efficient neural audio synthesis in the waveform domain
neural waveshaping synthesis real-time neural audio synthesis in the waveform domain paper • website • colab • audio by Ben Hayes, Charalampos Saitis,
 169 Dec 23, 2022
169 Dec 23, 2022
Telegram Radio - A User-bot who continuously play random audio files (from the famous telegram music channel @mveargasm) in the intended voice chat.
MvEargasmDJ: This is my submission for the Telegram Radio Project of Baivaru. Which required a userbot to continiously play random audio files from th
 24 Nov 12, 2022
24 Nov 12, 2022

NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling @ INTERSPEECH 2021 Accepted
NU-Wave — Official PyTorch Implementation NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling Junhyeok Lee, Seungu Han @ MINDsLab Inc
242 Dec 23, 2022

Classify bird species based on their songs using SIamese Networks and 1D dilated convolutions.
The goal is to classify different birds species based on their songs/calls. Spectrograms have been extracted from the audio samples and used as features for classification.
9 Dec 27, 2022
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
93 Dec 17, 2022
Source code for models described in the paper "AudioCLIP: Extending CLIP to Image, Text and Audio" (https://arxiv.org/abs/2106.13043)
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
 458 Jan 2, 2023
458 Jan 2, 2023

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022

This repository contains a PyTorch implementation of "AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis".
AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis | Project Page | Paper | PyTorch implementation for the paper "AD-NeRF: Audio
 551 Dec 29, 2022
551 Dec 29, 2022
AudioCLIP Extending CLIP to Image, Text and Audio
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
458 Jan 2, 2023
Use android as mic/speaker for ubuntu
Pulse Audio Control Panel Platforms Requirements sudo apt install ffmpeg pactl (already installed) Download Download the AppImage from release page ch
 19 Dec 1, 2022
19 Dec 1, 2022
Social Media Network Focuses On Data Security And Being Community Driven Web App
privalise Social Media Network Focuses On Data Security And Being Community Driven Web App The Main Idea: We`ve seen social media web apps that focuse
 8 Jun 25, 2021
8 Jun 25, 2021

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
 59 Dec 6, 2022
59 Dec 6, 2022

An API-driven solution for Makerspaces, Tinkerers, and Hackers.
Mventory is an API-driven inventory solution for Makers, Makerspaces, Hackspaces, and just about anyone else who needs to keep track of "stuff".
 107 Dec 21, 2022
107 Dec 21, 2022
spafe: Simplified Python Audio-Features Extraction
spafe aims to simplify features extractions from mono audio files. The library can extract of the following features: BFCC, LFCC, LPC, LPCC, MFCC, IMFCC, MSRCC, NGCC, PNCC, PSRCC, PLP, RPLP, Frequency-stats etc. It also provides various filterbank modules (Mel, Bark and Gammatone filterbanks) and other spectral statistics.
 310 Jan 1, 2023
310 Jan 1, 2023

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022