85 Repositories
Python Flex-Modal-FAS Libraries

Code and pre-trained models for MultiMAE: Multi-modal Multi-task Masked Autoencoders
MultiMAE: Multi-modal Multi-task Masked Autoencoders Roman Bachmann*, David Mizrahi*, Andrei Atanov, Amir Zamir Website | arXiv | BibTeX Official PyTo
 385 Jan 6, 2023
385 Jan 6, 2023
![[CVPR 2022 Oral] Versatile Multi-Modal Pre-Training for Human-Centric Perception](https://github.com/hongfz16/HCMoCo/raw/main/assets/teaser.png)
[CVPR 2022 Oral] Versatile Multi-Modal Pre-Training for Human-Centric Perception
Versatile Multi-Modal Pre-Training for Human-Centric Perception Fangzhou Hong1 Liang Pan1 Zhongang Cai1,2,3 Ziwei Liu1* 1S-Lab, Nanyang Technologic
 96 Jan 3, 2023
96 Jan 3, 2023

RuDOLPH: One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP
[Paper] [Хабр] [Model Card] [Colab] [Kaggle] RuDOLPH 🦌 🎄 ☃️ One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP Russian Diffusio
 232 Jan 4, 2023
232 Jan 4, 2023
Unified API to facilitate usage of pre-trained "perceptor" models, a la CLIP
mmc installation git clone https://github.com/dmarx/Multi-Modal-Comparators cd 'Multi-Modal-Comparators' pip install poetry poetry build pip install d
 37 Nov 25, 2022
37 Nov 25, 2022
Official implementation of "CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding" (CVPR, 2022)
CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding (CVPR'22) Paper Link | Project Page Abstract : Manual an
 152 Dec 23, 2022
152 Dec 23, 2022
PyTorch code for the paper "Complementarity is the King: Multi-modal and Multi-grained Hierarchical Semantic Enhancement Network for Cross-modal Retrieval".
Complementarity is the King: Multi-modal and Multi-grained Hierarchical Semantic Enhancement Network for Cross-modal Retrieval (M2HSE) PyTorch code fo
 6 Dec 23, 2022
6 Dec 23, 2022
![[LREC] MMChat: Multi-Modal Chat Dataset on Social Media](https://github.com/silverriver/MMChat/raw/main/bin/sample.jpg)
[LREC] MMChat: Multi-Modal Chat Dataset on Social Media
MMChat This repo contains the code and data for the LREC2022 paper MMChat: Multi-Modal Chat Dataset on Social Media. Dataset MMChat is a large-scale d
 47 Jan 3, 2023
47 Jan 3, 2023

4st place solution for the PBVS 2022 Multi-modal Aerial View Object Classification Challenge - Track 1 (SAR) at PBVS2022
A Two-Stage Shake-Shake Network for Long-tailed Recognition of SAR Aerial View Objects 4st place solution for the PBVS 2022 Multi-modal Aerial View Ob
 5 Nov 9, 2022
5 Nov 9, 2022
Flexible-Modal Face Anti-Spoofing: A Benchmark
Flexible-Modal FAS This is the official repository of "Flexible-Modal Face Anti-
 22 Nov 10, 2022
22 Nov 10, 2022

Detecting Human-Object Interactions with Object-Guided Cross-Modal Calibrated Semantics
[AAAI2022] Detecting Human-Object Interactions with Object-Guided Cross-Modal Calibrated Semantics Overall pipeline of OCN. Paper Link: [arXiv] [AAAI
 13 Nov 21, 2022
13 Nov 21, 2022

Official code of Team Yao at Multi-Modal-Fact-Verification-2022
Official code of Team Yao at Multi-Modal-Fact-Verification-2022 A Multi-Modal Fact Verification dataset released as part of the De-Factify workshop in
 11 Nov 15, 2022
11 Nov 15, 2022
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques This repository is derived from the NMTGMinor
 1 Sep 7, 2022
1 Sep 7, 2022
Accelerated Multi-Modal MR Imaging with Transformers
Accelerated Multi-Modal MR Imaging with Transformers Dependencies numpy==1.18.5 scikit_image==0.16.2 torchvision==0.8.1 torch==1.7.0 runstats==1.8.0 p
 54 Dec 16, 2022
54 Dec 16, 2022
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features | paper | Official PyTorch implementation for Mul
 48 Dec 28, 2022
48 Dec 28, 2022
Transformer in Vision
Transformer-in-Vision Recent Transformer-based CV and related works. Welcome to comment/contribute! Keep updated. Resource SCENIC: A JAX Library for C
 1.1k Dec 30, 2022
1.1k Dec 30, 2022

Codes and scripts for "Explainable Semantic Space by Grounding Languageto Vision with Cross-Modal Contrastive Learning"
Visually Grounded Bert Language Model This repository is the official implementation of Explainable Semantic Space by Grounding Language to Vision wit
 17 Dec 17, 2022
17 Dec 17, 2022

Cross-modal Retrieval using Transformer Encoder Reasoning Networks (TERN). With use of Metric Learning and FAISS for fast similarity search on GPU
Cross-modal Retrieval using Transformer Encoder Reasoning Networks This project reimplements the idea from "Transformer Reasoning Network for Image-Te
 5 Nov 5, 2022
5 Nov 5, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022
A Comprehensive Empirical Study of Vision-Language Pre-trained Model for Supervised Cross-Modal Retrieval
CLIP4CMR A Comprehensive Empirical Study of Vision-Language Pre-trained Model for Supervised Cross-Modal Retrieval The original data and pre-calculate
 9 Jan 12, 2022
9 Jan 12, 2022
A Comprehensive Empirical Study of Vision-Language Pre-trained Model for Supervised Cross-Modal Retrieval
CLIP4CMR A Comprehensive Empirical Study of Vision-Language Pre-trained Model for Supervised Cross-Modal Retrieval The original data and pre-calculate
24 Dec 26, 2022
RuDOLPH: One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP
[Paper] [Хабр] [Model Card] [Colab] [Kaggle] RuDOLPH 🦌 🎄 ☃️ One Hyper-Modal Tr
 230 Dec 31, 2022
230 Dec 31, 2022

Multi-Modal Machine Learning toolkit based on PaddlePaddle.
简体中文 | English PaddleMM 简介 飞桨多模态学习工具包 PaddleMM 旨在于提供模态联合学习和跨模态学习算法模型库,为处理图片文本等多模态数据提供高效的解决方案,助力多模态学习应用落地。 近期更新 2022.1.5 发布 PaddleMM 初始版本 v1.0 特性 丰富的任务
 520 Dec 28, 2022
520 Dec 28, 2022

Multi-Modal Machine Learning toolkit based on PyTorch.
简体中文 | English TorchMM 简介 多模态学习工具包 TorchMM 旨在于提供模态联合学习和跨模态学习算法模型库,为处理图片文本等多模态数据提供高效的解决方案,助力多模态学习应用落地。 近期更新 2022.1.5 发布 TorchMM 初始版本 v1.0 特性 丰富的任务场景:工具
1 Jan 5, 2022

Audio-to-symbolic Arrangement via Cross-modal Music Representation Learning
Automatic Audio-to-symbolic Arrangement This is the repository of the project "Audio-to-symbolic Arrangement via Cross-modal Music Representation Lear
 6 Jan 5, 2022
6 Jan 5, 2022

BalaGAN: Image Translation Between Imbalanced Domains via Cross-Modal Transfer
BalaGAN: Image Translation Between Imbalanced Domains via Cross-Modal Transfer Project Page | Paper | Video State-of-the-art image-to-image translatio
 47 Dec 6, 2022
47 Dec 6, 2022

TSIT: A Simple and Versatile Framework for Image-to-Image Translation
TSIT: A Simple and Versatile Framework for Image-to-Image Translation This repository provides the official PyTorch implementation for the following p
 255 Nov 23, 2022
255 Nov 23, 2022

SMIS - Semantically Multi-modal Image Synthesis(CVPR 2020)
Semantically Multi-modal Image Synthesis Project page / Paper / Demo Semantically Multi-modal Image Synthesis(CVPR2020). Zhen Zhu, Zhiliang Xu, Anshen
 316 Dec 1, 2022
316 Dec 1, 2022

PyTorch Implementation of SSTNs for hyperspectral image classifications from the IEEE T-GRS paper "Spectral-Spatial Transformer Network for Hyperspectral Image Classification: A FAS Framework."
PyTorch Implementation of SSTN for Hyperspectral Image Classification Paper links: SSTN published on IEEE T-GRS. Also, you can directly find the imple
 54 Dec 19, 2022
54 Dec 19, 2022
This repo provides code for QB-Norm (Cross Modal Retrieval with Querybank Normalisation)
This repo provides code for QB-Norm (Cross Modal Retrieval with Querybank Normalisation) Usage example python dynamic_inverted_softmax.py --sims_train
 36 Dec 29, 2022
36 Dec 29, 2022

This repository contains the code used in the paper "Prompt-Based Multi-Modal Image Segmentation".
Prompt-Based Multi-Modal Image Segmentation This repository contains the code used in the paper "Prompt-Based Multi-Modal Image Segmentation". The sys
 305 Dec 30, 2022
305 Dec 30, 2022
Code of paper Interact, Embed, and EnlargE (IEEE): Boosting Modality-specific Representations for Multi-Modal Person Re-identification.
Interact, Embed, and EnlargE (IEEE): Boosting Modality-specific Representations for Multi-Modal Person Re-identification We provide the codes for repr
 12 Dec 12, 2022
12 Dec 12, 2022

Hierarchical Cross-modal Talking Face Generation with Dynamic Pixel-wise Loss (ATVGnet)
Hierarchical Cross-modal Talking Face Generation with Dynamic Pixel-wise Loss (ATVGnet) By Lele Chen , Ross K Maddox, Zhiyao Duan, Chenliang Xu. Unive
 218 Dec 27, 2022
218 Dec 27, 2022
A Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities
MPT A Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities. Implementation for our AAAI 2022 paper: Multi-
 4 May 8, 2022
4 May 8, 2022

A concise but complete implementation of CLIP with various experimental improvements from recent papers
x-clip (wip) A concise but complete implementation of CLIP with various experimental improvements from recent papers Install $ pip install x-clip Usag
 115 Dec 9, 2021
115 Dec 9, 2021
A concise but complete implementation of CLIP with various experimental improvements from recent papers
x-clip (wip) A concise but complete implementation of CLIP with various experimental improvements from recent papers Install $ pip install x-clip Usag
515 Dec 26, 2022
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
 124 Jan 2, 2023
124 Jan 2, 2023
Multi-modal co-attention for drug-target interaction annotation and Its Application to SARS-CoV-2
CoaDTI Multi-modal co-attention for drug-target interaction annotation and Its Application to SARS-CoV-2 Abstract Environment The test was conducted i
 7 Nov 14, 2022
7 Nov 14, 2022

EvDistill: Asynchronous Events to End-task Learning via Bidirectional Reconstruction-guided Cross-modal Knowledge Distillation (CVPR'21)
EvDistill: Asynchronous Events to End-task Learning via Bidirectional Reconstruction-guided Cross-modal Knowledge Distillation (CVPR'21) Citation If y
 18 Nov 11, 2022
18 Nov 11, 2022

Multi-modal Vision Transformers Excel at Class-agnostic Object Detection
Multi-modal Vision Transformers Excel at Class-agnostic Object Detection
 206 Jan 4, 2023
206 Jan 4, 2023

Implementation of DocFormer: End-to-End Transformer for Document Understanding, a multi-modal transformer based architecture for the task of Visual Document Understanding (VDU)
DocFormer - PyTorch Implementation of DocFormer: End-to-End Transformer for Document Understanding, a multi-modal transformer based architecture for t
 171 Jan 6, 2023
171 Jan 6, 2023
Multi-modal Content Creation Model Training Infrastructure including the FACT model (AI Choreographer) implementation.
AI Choreographer: Music Conditioned 3D Dance Generation with AIST++ [ICCV-2021]. Overview This package contains the model implementation and training
 365 Dec 30, 2022
365 Dec 30, 2022
Self-supervised Multi-modal Hybrid Fusion Network for Brain Tumor Segmentation
JBHI-Pytorch This repository contains a reference implementation of the algorithms described in our paper "Self-supervised Multi-modal Hybrid Fusion N
 5 Dec 13, 2021
5 Dec 13, 2021

Pytorch implementation of our paper LIMUSE: LIGHTWEIGHT MULTI-MODAL SPEAKER EXTRACTION.
LiMuSE Overview Pytorch implementation of our paper LIMUSE: LIGHTWEIGHT MULTI-MODAL SPEAKER EXTRACTION. LiMuSE explores group communication on a multi
 17 Oct 26, 2022
17 Oct 26, 2022
Multi-Modal Fingerprint Presentation Attack Detection: Evaluation On A New Dataset
PADISI USC Dataset This repository analyzes the PADISI-Finger dataset introduced in Multi-Modal Fingerprint Presentation Attack Detection: Evaluation
 6 Feb 6, 2022
6 Feb 6, 2022
Template for a Dataflow Flex Template in Python
Dataflow Flex Template in Python This repository contains a template for a Dataflow Flex Template written in Python that can easily be used to build D
 5 Apr 28, 2022
5 Apr 28, 2022

This is the code related to "Sparse-to-dense Feature Matching: Intra and Inter domain Cross-modal Learning in Domain Adaptation for 3D Semantic Segmentation" (ICCV 2021).
Sparse-to-dense Feature Matching: Intra and Inter domain Cross-modal Learning in Domain Adaptation for 3D Semantic Segmentation This is the code relat
 39 Sep 23, 2022
39 Sep 23, 2022

MDETR: Modulated Detection for End-to-End Multi-Modal Understanding
MDETR: Modulated Detection for End-to-End Multi-Modal Understanding Website • Colab • Paper This repository contains code and links to pre-trained mod
 770 Dec 28, 2022
770 Dec 28, 2022

A CROSS-MODAL FUSION NETWORK BASED ON SELF-ATTENTION AND RESIDUAL STRUCTURE FOR MULTIMODAL EMOTION RECOGNITION
CFN-SR A CROSS-MODAL FUSION NETWORK BASED ON SELF-ATTENTION AND RESIDUAL STRUCTURE FOR MULTIMODAL EMOTION RECOGNITION The audio-video based multimodal
 15 Sep 26, 2022
15 Sep 26, 2022
![[v1 (ISBI'21) + v2] MedMNIST: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification](https://github.com/MedMNIST/MedMNIST/raw/main/assets/medmnistv2.jpg)
[v1 (ISBI'21) + v2] MedMNIST: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification
MedMNIST Project (Website) | Dataset (Zenodo) | Paper (arXiv) | MedMNIST v1 (ISBI'21) Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bili
 683 Dec 28, 2022
683 Dec 28, 2022

SEJE is a prototype for the paper Learning Text-Image Joint Embedding for Efficient Cross-Modal Retrieval with Deep Feature Engineering.
SEJE is a prototype for the paper Learning Text-Image Joint Embedding for Efficient Cross-Modal Retrieval with Deep Feature Engineering. Contents Inst
 0 Oct 21, 2021
0 Oct 21, 2021

Source code for "Taming Visually Guided Sound Generation" (Oral at the BMVC 2021)
Taming Visually Guided Sound Generation • [Project Page] • [ArXiv] • [Poster] • • Listen for the samples on our project page. Overview We propose to t
 226 Jan 3, 2023
226 Jan 3, 2023

Official implementation for Multi-Modal Interaction Graph Convolutional Network for Temporal Language Localization in Videos
Multi-modal Interaction Graph Convolutioal Network for Temporal Language Localization in Videos Official implementation for Multi-Modal Interaction Gr
 15 Oct 18, 2022
15 Oct 18, 2022

Pytorch implementation for our ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visual Question Answering".
TRAnsformer Routing Networks (TRAR) This is an official implementation for ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visu
 49 Nov 10, 2022
49 Nov 10, 2022
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition [ArXiv] [Project Page] This repository is the official implementation of AdaMML:
 43 Dec 26, 2022
43 Dec 26, 2022

Code for 'Single Image 3D Shape Retrieval via Cross-Modal Instance and Category Contrastive Learning', ICCV 2021
CMIC-Retrieval Code for Single Image 3D Shape Retrieval via Cross-Modal Instance and Category Contrastive Learning. ICCV 2021. Introduction In this wo
 42 Nov 17, 2022
42 Nov 17, 2022
A pytorch-based deep learning framework for multi-modal 2D/3D medical image segmentation
A 3D multi-modal medical image segmentation library in PyTorch We strongly believe in open and reproducible deep learning research. Our goal is to imp
 1.2k Dec 27, 2022
1.2k Dec 27, 2022
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022
An official PyTorch implementation of the paper "Learning by Aligning: Visible-Infrared Person Re-identification using Cross-Modal Correspondences", ICCV 2021.
PyTorch implementation of Learning by Aligning (ICCV 2021) This is an official PyTorch implementation of the paper "Learning by Aligning: Visible-Infr
 30 Nov 5, 2022
30 Nov 5, 2022
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
 42 Dec 9, 2022
42 Dec 9, 2022

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022

A Multi-modal Model Chinese Spell Checker Released on ACL2021.
ReaLiSe ReaLiSe is a multi-modal Chinese spell checking model. This the office code for the paper Read, Listen, and See: Leveraging Multimodal Informa
 106 Dec 29, 2022
106 Dec 29, 2022
Few-shot NLP benchmark for unified, rigorous eval
FLEX FLEX is a benchmark and framework for unified, rigorous few-shot NLP evaluation. FLEX enables: First-class NLP support Support for meta-training
 85 Dec 3, 2022
85 Dec 3, 2022
Deep RGB-D Saliency Detection with Depth-Sensitive Attention and Automatic Multi-Modal Fusion (CVPR'2021, Oral)
DSA^2 F: Deep RGB-D Saliency Detection with Depth-Sensitive Attention and Automatic Multi-Modal Fusion (CVPR'2021, Oral) This repo is the official imp
 46 Dec 21, 2022
46 Dec 21, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 43 Nov 21, 2022
43 Nov 21, 2022
A Multi-modal Model Chinese Spell Checker Released on ACL2021.
ReaLiSe ReaLiSe is a multi-modal Chinese spell checking model. This the office code for the paper Read, Listen, and See: Leveraging Multimodal Informa
106 Dec 29, 2022

Official Implement of CVPR 2021 paper “Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting”
RGBT Crowd Counting Lingbo Liu, Jiaqi Chen, Hefeng Wu, Guanbin Li, Chenglong Li, Liang Lin. "Cross-Modal Collaborative Representation Learning and a L
 37 Dec 8, 2022
37 Dec 8, 2022
Cross-Modal Contrastive Learning for Text-to-Image Generation
Cross-Modal Contrastive Learning for Text-to-Image Generation This repository hosts the open source JAX implementation of XMC-GAN. Setup instructions
94 Nov 12, 2022
Probabilistic Cross-Modal Embedding (PCME) CVPR 2021
Probabilistic Cross-Modal Embedding (PCME) CVPR 2021 Official Pytorch implementation of PCME | Paper Sanghyuk Chun1 Seong Joon Oh1 Rafael Sampaio de R
 87 Dec 21, 2022
87 Dec 21, 2022
CVPR 2021 Official Pytorch Code for UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training
UC2 UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training Mingyang Zhou, Luowei Zhou, Shuohang Wang, Yu Cheng, Linjie Li, Zhou Yu,
 28 Dec 30, 2022
28 Dec 30, 2022
Code of U2Fusion: a unified unsupervised image fusion network for multiple image fusion tasks, including multi-modal, multi-exposure and multi-focus image fusion.
U2Fusion Code of U2Fusion: a unified unsupervised image fusion network for multiple image fusion tasks, including multi-modal (VIS-IR, medical), multi
 129 Dec 11, 2022
129 Dec 11, 2022

Cross-modal Deep Face Normals with Deactivable Skip Connections
Cross-modal Deep Face Normals with Deactivable Skip Connections Victoria Fernández Abrevaya*, Adnane Boukhayma*, Philip H. S. Torr, Edmond Boyer (*Equ
 72 Nov 27, 2022
72 Nov 27, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
44 Jan 6, 2023

Code for Referring Image Segmentation via Cross-Modal Progressive Comprehension, CVPR2020.
CMPC-Refseg Code of our CVPR 2020 paper Referring Image Segmentation via Cross-Modal Progressive Comprehension. Shaofei Huang*, Tianrui Hui*, Si Liu,
 55 Dec 1, 2022
55 Dec 1, 2022
![The code of “Similarity Reasoning and Filtration for Image-Text Matching” [AAAI2021]](https://github.com/Paranioar/SGRAF/raw/main/fig/model.png)
The code of “Similarity Reasoning and Filtration for Image-Text Matching” [AAAI2021]
SGRAF PyTorch implementation for AAAI2021 paper of “Similarity Reasoning and Filtration for Image-Text Matching”. It is built on top of the SCAN and C
 149 Dec 22, 2022
149 Dec 22, 2022
Code for "Learning the Best Pooling Strategy for Visual Semantic Embedding", CVPR 2021
Learning the Best Pooling Strategy for Visual Semantic Embedding Official PyTorch implementation of the paper Learning the Best Pooling Strategy for V
 106 Jan 6, 2023
106 Jan 6, 2023
Activity image-based video retrieval
Cross-modal-retrieval Our approach is focus on Activity Image-to-Video Retrieval (AIVR) task. The compared methods are state-of-the-art single modalit
 75 Oct 21, 2021
75 Oct 21, 2021
![[CVPR'21] Multi-Modal Fusion Transformer for End-to-End Autonomous Driving](https://github.com/autonomousvision/transfuser/raw/main/transfuser/assets/teaser.png)
[CVPR'21] Multi-Modal Fusion Transformer for End-to-End Autonomous Driving
TransFuser This repository contains the code for the CVPR 2021 paper Multi-Modal Fusion Transformer for End-to-End Autonomous Driving. If you find our
 695 Jan 5, 2023
695 Jan 5, 2023
《Image2Reverb: Cross-Modal Reverb Impulse Response Synthesis》(2021)
Image2Reverb Image2Reverb is an end-to-end neural network that generates plausible audio impulse responses from single images of acoustic environments
 48 Nov 27, 2022
48 Nov 27, 2022
Code for CVPR 2021 paper: Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning
Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning This is the PyTorch companion code for the paper: A
 69 Jan 3, 2023
69 Jan 3, 2023

Official PyTorch implementation for Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers, a novel method to visualize any Transformer-based network. Including examples for DETR, VQA.
PyTorch Implementation of Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers 1 Using Colab Please notic
 489 Jan 7, 2023
489 Jan 7, 2023

Implementation / replication of DALL-E, OpenAI's Text to Image Transformer, in Pytorch
Implementation / replication of DALL-E, OpenAI's Text to Image Transformer, in Pytorch
5k Jan 2, 2023

Official implementation of the ICLR 2021 paper
You Only Need Adversarial Supervision for Semantic Image Synthesis Official PyTorch implementation of the ICLR 2021 paper "You Only Need Adversarial S
 272 Dec 28, 2022
272 Dec 28, 2022
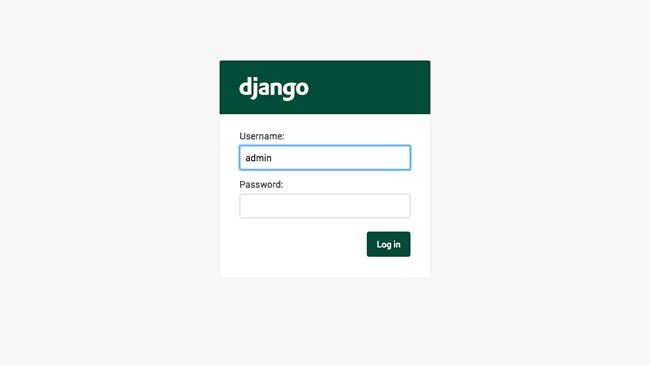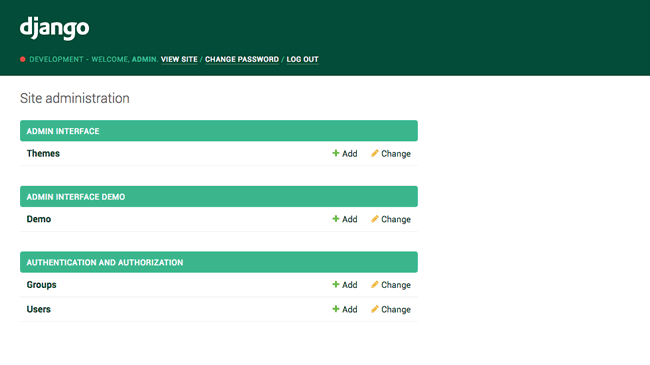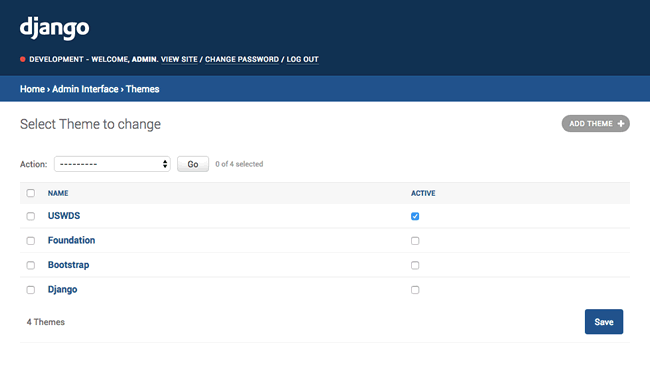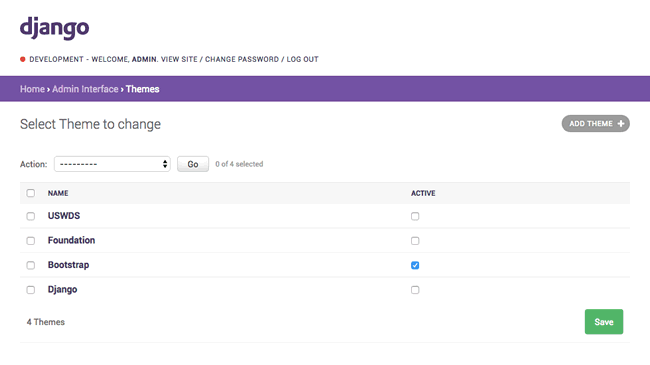
django's default admin interface made customizable. popup windows replaced by modals. :mage: :zap:
django-admin-interface django-admin-interface is a modern responsive flat admin interface customizable by the admin itself. Features Beautiful default
 1.3k Dec 31, 2022
1.3k Dec 31, 2022

Implementation / replication of DALL-E, OpenAI's Text to Image Transformer, in Pytorch
DALL-E in Pytorch Implementation / replication of DALL-E, OpenAI's Text to Image Transformer, in Pytorch. It will also contain CLIP for ranking the ge
5k Jan 4, 2023
FLEX (Federated Learning EXchange,FLEX) protocol is a set of standardized federal learning agreements designed by Tongdun AI Research Group。
Click to view Chinese version FLEX (Federated Learning Exchange) protocol is a set of standardized federal learning agreements designed by Tongdun AI
 50 Nov 29, 2022
50 Nov 29, 2022