807 Repositories
Python audio-visual-applications Libraries

Code and data for "Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning" (EMNLP 2021).
GD-VCR Code for Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning (EMNLP 2021). Research Questions and Aims: How well can a model perform o
 24 Oct 13, 2022
24 Oct 13, 2022
Gateware for the Terasic/Arrow DECA board, to become a USB2 high speed audio interface
DECA USB Audio Interface DECA based USB 2.0 High Speed audio interface Status / current limitations enumerates as class compliant audio device on Linu
 16 Mar 21, 2022
16 Mar 21, 2022
Official Implementation of Few-shot Visual Relationship Co-localization
VRC Official implementation of the Few-shot Visual Relationship Co-localization (ICCV 2021) paper project page | paper Requirements Use python = 3.8.
 22 Oct 13, 2022
22 Oct 13, 2022
![[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification](https://github.com/raoyongming/CAL/raw/master/figs/intro.png)
[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Counterfactual Attention Learning Created by Yongming Rao*, Guangyi Chen*, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for ICCV
 89 Dec 18, 2022
89 Dec 18, 2022

The only purpose of a byte-sized application is to help you create .desktop entry files for downloaded applications.
Turtle 🐢 The only purpose of a byte-sized application is to help you create .desktop entry files for downloaded applications. As of usual with elemen
 14 Dec 29, 2022
14 Dec 29, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022
Code for Boundary-Aware Segmentation Network for Mobile and Web Applications
BASNet Boundary-Aware Segmentation Network for Mobile and Web Applications This repository contain implementation of BASNet in tensorflow/keras. comme
 8 Nov 24, 2022
8 Nov 24, 2022
A tool to fuck a video/audio quality using FFmpeg
Media quality fucker A tool to fuck a video/audio quality using FFmpeg How to use Download the source Download Python Extract FFmpeg Put what you want
 8 Jan 25, 2022
8 Jan 25, 2022
Sail is a free CLI tool to deploy, manage and scale WordPress applications in the DigitalOcean cloud.
Deploy WordPress to DigitalOcean with Sail Sail is a free CLI tool to deploy, manage and scale WordPress applications in the DigitalOcean cloud. Conte
 159 Dec 12, 2022
159 Dec 12, 2022
Reading list for research topics in sound event detection
Sound event detection aims at processing the continuous acoustic signal and converting it into symbolic descriptions of the corresponding sound events present at the auditory scene.
 64 Jan 5, 2023
64 Jan 5, 2023
pytest-django allows you to test your Django project/applications with the pytest testing tool.
pytest-django allows you to test your Django project/applications with the pytest testing tool.
 1.1k Dec 14, 2022
1.1k Dec 14, 2022
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
 1.7k Dec 28, 2022
1.7k Dec 28, 2022

pedalboard is a Python library for adding effects to audio.
pedalboard is a Python library for adding effects to audio. It supports a number of common audio effects out of the box, and also allows the use of VST3® and Audio Unit plugin formats for third-party effects.
 3.9k Jan 2, 2023
3.9k Jan 2, 2023

Cockpit is a visual and statistical debugger specifically designed for deep learning.
Cockpit: A Practical Debugging Tool for Training Deep Neural Networks
 421 Dec 29, 2022
421 Dec 29, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
[ICCV 2021] Released code for Causal Attention for Unbiased Visual Recognition
CaaM This repo contains the codes of training our CaaM on NICO/ImageNet9 dataset. Due to my recent limited bandwidth, this codebase is still messy, wh
 66 Dec 31, 2022
66 Dec 31, 2022
FreezeUI is a python package that creates applications using cx_freeze and GUI by converting .py to .exe .
FreezeUI is a python package use to create cx_Freeze setup files and run them to create applications and msi from python scripts (converts .py to .exe or .msi .
 4 Aug 25, 2022
4 Aug 25, 2022
praudio provides audio preprocessing framework for Deep Learning audio applications
praudio provides objects and a script for performing complex preprocessing operations on entire audio datasets with one command.
 105 Dec 26, 2022
105 Dec 26, 2022

This repo implements a Topological SLAM: Deep Visual Odometry with Long Term Place Recognition (Loop Closure Detection)
This repo implements a topological SLAM system. Deep Visual Odometry (DF-VO) and Visual Place Recognition are combined to form the topological SLAM system.
 32 Jun 23, 2022
32 Jun 23, 2022

🌈 PyTorch Implementation for EMNLP'21 Findings "Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer"
SGLKT-VisDial Pytorch Implementation for the paper: Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer Gi-Cheon Kang, Junseok P
 9 Jul 5, 2022
9 Jul 5, 2022
Docker is an open platform for developing, shipping, and running applications OS-level virtualization to deliver software in packages called containers However, 'security' is a top request on Docker's public roadmap This project aims at vulnerability check for such docker containers. New contributions are accepted
Docker-Vulnerability-Check Docker is an open platform for developing, shipping, and running applications OS-level virtualization to deliver software i
 103 Aug 20, 2022
103 Aug 20, 2022

PaddleViT: State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 2.0+
PaddlePaddle Vision Transformers State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 🤖 PaddlePaddle Visual Transformers (PaddleViT or
 1k Dec 28, 2022
1k Dec 28, 2022

The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation
PointNav-VO The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation Project Page | Paper Table of Contents Setup
 41 Dec 15, 2022
41 Dec 15, 2022
The official implementation of the Interspeech 2021 paper WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution.
WSRGlow The official implementation of the Interspeech 2021 paper WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution. Audio sa
 96 Jan 3, 2023
96 Jan 3, 2023
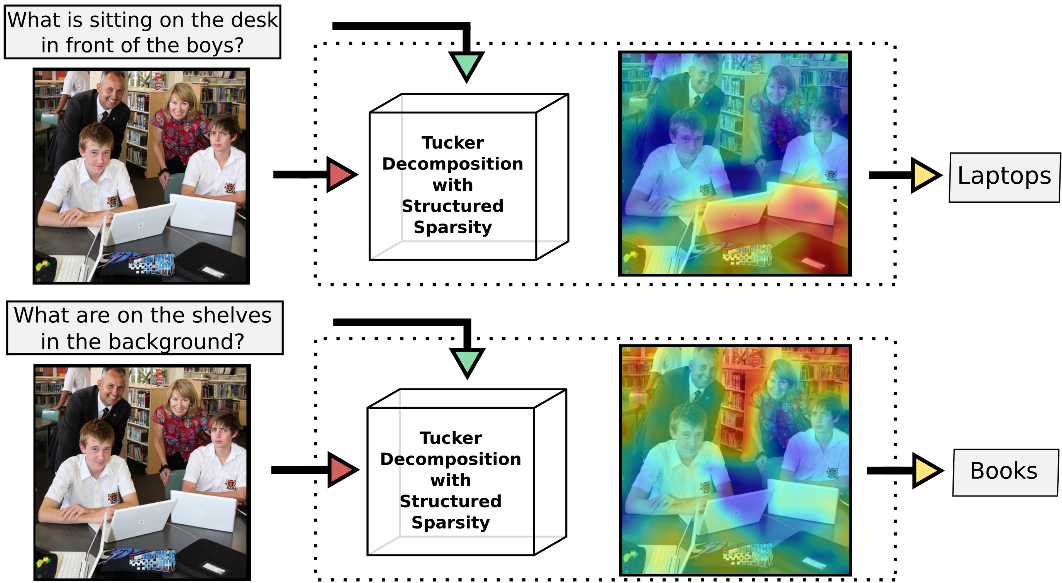
Visual Question Answering in Pytorch
Visual Question Answering in pytorch /!\ New version of pytorch for VQA available here: https://github.com/Cadene/block.bootstrap.pytorch This repo wa
 672 Jan 1, 2023
672 Jan 1, 2023
PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
samplernn-pytorch A PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model. It's based on the reference implem
 261 Dec 14, 2022
261 Dec 14, 2022
PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
Improving Visual-Semantic Embeddings with Hard Negatives Code for the image-caption retrieval methods from VSE++: Improving Visual-Semantic Embeddings
 441 Dec 5, 2022
441 Dec 5, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
 166 Dec 11, 2022
166 Dec 11, 2022

Simple torch.nn.module implementation of Alias-Free-GAN style filter and resample
Alias-Free-Torch Simple torch module implementation of Alias-Free GAN. This repository including Alias-Free GAN style lowpass sinc filter @filter.py A
 64 Dec 22, 2022
64 Dec 22, 2022
apkizer is a mass downloader for android applications for all available versions.
apkizer apkizer collects all available versions of an Android application from apkpure.com Purpose Sometimes mobile applications can be useful to dig
 41 Dec 16, 2022
41 Dec 16, 2022
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
 42 Dec 9, 2022
42 Dec 9, 2022

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022
A management system designed for the employees of MIRAS (Art Gallery). It is used to sell/cancel tickets, book/cancel events and keeps track of all upcoming events.
Art-Galleria-Management-System Its a management system designed for the employees of MIRAS (Art Gallery). Backend : Python Frontend : Django Database
 8 Nov 30, 2022
8 Nov 30, 2022

Easy to use Audio Tagging in PyTorch
Audio Classification, Tagging & Sound Event Detection in PyTorch Progress: Fine-tune on audio classification Fine-tune on audio tagging Fine-tune on s
 15 Dec 22, 2022
15 Dec 22, 2022

A weakly-supervised scene graph generation codebase. The implementation of our CVPR2021 paper ``Linguistic Structures as Weak Supervision for Visual Scene Graph Generation''
README.md shall be finished soon. WSSGG 0 Overview 1 Installation 1.1 Faster-RCNN 1.2 Language Parser 1.3 GloVe Embeddings 2 Settings 2.1 VG-GT-Graph
 35 Nov 20, 2022
35 Nov 20, 2022
Nasdaq Cloud Data Service (NCDS) provides a modern and efficient method of delivery for realtime exchange data and other financial information. This repository provides an SDK for developing applications to access the NCDS.
Nasdaq Cloud Data Service (NCDS) Nasdaq Cloud Data Service (NCDS) provides a modern and efficient method of delivery for realtime exchange data and ot
 8 Dec 1, 2022
8 Dec 1, 2022
FPGA based USB 2.0 high speed audio interface featuring multiple optical ADAT inputs and outputs
ADAT USB Audio Interface FPGA based USB 2.0 High Speed audio interface featuring multiple optical ADAT inputs and outputs Status / current limitations
78 Dec 31, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
 41 Jan 3, 2023
41 Jan 3, 2023

A simple yet powerful TUI framework for your Python (3.7+) applications
A simple yet powerful TUI framework for your Python (3.7+) applications
 1.4k Jan 4, 2023
1.4k Jan 4, 2023

Code release for The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification (TIP 2020)
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification Code release for The Devil is in the Channels: Mutual-Channel
 230 Dec 31, 2022
230 Dec 31, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023
Video Visual Relation Detection (VidVRD) tracklets generation. also for ACM MM Visual Relation Understanding Grand Challenge
VidVRD-tracklets This repository contains codes for Video Visual Relation Detection (VidVRD) tracklets generation based on MEGA and deepSORT. These tr
 25 Dec 21, 2022
25 Dec 21, 2022
This app converts an pdf file into the audio file.
PDF-to-Audio This app takes an pdf as an input and convert it into audio, and the library text-to-speech starts speaking the preffered page given in t
 3 Aug 4, 2021
3 Aug 4, 2021

Drug design and development team HackBio internship is a virtual bioinformatics program that introduces students and professional to advanced practical bioinformatics and its applications globally.
-Nyokong. Drug design and development team HackBio internship is a virtual bioinformatics program that introduces students and professional to advance
 4 Aug 4, 2022
4 Aug 4, 2022

Official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers
Visual Parser (ViP) This is the official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers. Key Feature
 117 Dec 11, 2022
117 Dec 11, 2022
DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021)
DPT This repo is the official implementation of DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021). We provide code and model
 111 Dec 21, 2022
111 Dec 21, 2022

A generalized framework for prototyping full-stack cooperative driving automation applications under CARLA+SUMO.
OpenCDA OpenCDA is a SIMULATION tool integrated with a prototype cooperative driving automation (CDA; see SAE J3216) pipeline as well as regular autom
 726 Dec 29, 2022
726 Dec 29, 2022
This is the code for CVPR 2021 oral paper: Jigsaw Clustering for Unsupervised Visual Representation Learning
JigsawClustering Jigsaw Clustering for Unsupervised Visual Representation Learning Pengguang Chen, Shu Liu, Jiaya Jia Introduction This project provid
 73 Sep 18, 2022
73 Sep 18, 2022

Dataset used in "PlantDoc: A Dataset for Visual Plant Disease Detection" accepted in CODS-COMAD 2020
PlantDoc: A Dataset for Visual Plant Disease Detection This repository contains the Cropped-PlantDoc dataset used for benchmarking classification mode
 109 Dec 29, 2022
109 Dec 29, 2022

This's an implementation of deepmind Visual Interaction Networks paper using pytorch
Visual-Interaction-Networks An implementation of Deepmind visual interaction networks in Pytorch. Introduction For the purpose of understanding the ch
 166 Dec 6, 2022
166 Dec 6, 2022

PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs
PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs This code aims to reproduce results obtained in the paper "Visual F
 93 Aug 17, 2022
93 Aug 17, 2022

Bilinear attention networks for visual question answering
Bilinear Attention Networks This repository is the implementation of Bilinear Attention Networks for the visual question answering and Flickr30k Entit
 506 Nov 29, 2022
506 Nov 29, 2022

source code of “Visual Saliency Transformer” (ICCV2021)
Visual Saliency Transformer (VST) source code for our ICCV 2021 paper “Visual Saliency Transformer” by Nian Liu, Ni Zhang, Kaiyuan Wan, Junwei Han, an
 89 Dec 21, 2022
89 Dec 21, 2022
Easily turn single threaded command line applications into a fast, multi-threaded application with CIDR and glob support.
Easily turn single threaded command line applications into a fast, multi-threaded application with CIDR and glob support.
 1k Jan 7, 2023
1k Jan 7, 2023
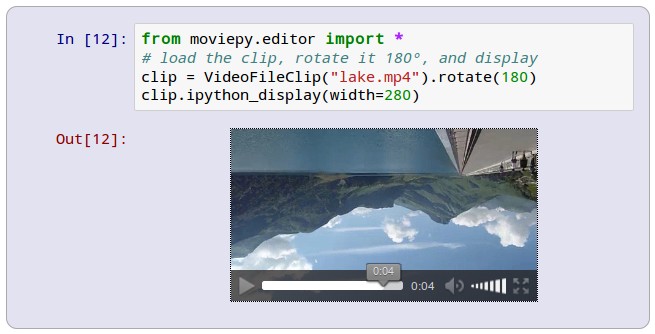
MoviePy is a Python library for video editing, can read and write all the most common audio and video formats
MoviePy is a Python library for video editing: cutting, concatenations, title insertions, video compositing (a.k.a. non-linear editing), video processing, and creation of custom effects. See the gallery for some examples of use.
 10k Jan 8, 2023
10k Jan 8, 2023

🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
 7.7k Jan 5, 2023
7.7k Jan 5, 2023
A Telegram Bot to Play Audio in Voice Chats With Youtube and Deezer support. Supports Live streaming from youtube Supports Mega Radio Fm Streamings
Bot To Stream Musics on PyTGcalls with Channel Support. A Telegram Bot to Play Audio in Voice Chats With Supports Live streaming from youtube and Mega
 37 Dec 15, 2022
37 Dec 15, 2022

PyTorch implementation of "Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning"
Transparency-by-Design networks (TbD-nets) This repository contains code for replicating the experiments and visualizations from the paper Transparenc
 351 Nov 18, 2022
351 Nov 18, 2022

Code for the Interspeech 2021 paper "AST: Audio Spectrogram Transformer".
AST: Audio Spectrogram Transformer Introduction Citing Getting Started ESC-50 Recipe Speechcommands Recipe AudioSet Recipe Pretrained Models Contact I
 603 Jan 7, 2023
603 Jan 7, 2023

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022

URIE: Universal Image Enhancementfor Visual Recognition in the Wild
URIE: Universal Image Enhancementfor Visual Recognition in the Wild This is the implementation of the paper "URIE: Universal Image Enhancement for Vis
 43 Sep 12, 2022
43 Sep 12, 2022
improvement of CLIP features over the traditional resnet features on the visual question answering, image captioning, navigation and visual entailment tasks.
CLIP-ViL In our paper "How Much Can CLIP Benefit Vision-and-Language Tasks?", we show the improvement of CLIP features over the traditional resnet fea
 310 Dec 28, 2022
310 Dec 28, 2022
STMTrack: Template-free Visual Tracking with Space-time Memory Networks
STMTrack This is the official implementation of the paper: STMTrack: Template-free Visual Tracking with Space-time Memory Networks. Setup Prepare Anac
 62 Dec 21, 2022
62 Dec 21, 2022
efficient neural audio synthesis in the waveform domain
neural waveshaping synthesis real-time neural audio synthesis in the waveform domain paper • website • colab • audio by Ben Hayes, Charalampos Saitis,
 169 Dec 23, 2022
169 Dec 23, 2022

Self-supervised Deep LiDAR Odometry for Robotic Applications
DeLORA: Self-supervised Deep LiDAR Odometry for Robotic Applications Overview Paper: link Video: link ICRA Presentation: link This is the correspondin
 181 Dec 29, 2022
181 Dec 29, 2022
![[CVPR 2021] A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts](https://github.com/gyhandy/Visual-Reasoning-eXplanation/raw/main/docs/Fig-1.png)
[CVPR 2021] A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts
Visual-Reasoning-eXplanation [CVPR 2021 A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts] Project Page | Vid
 54 Dec 21, 2022
54 Dec 21, 2022
Telegram Radio - A User-bot who continuously play random audio files (from the famous telegram music channel @mveargasm) in the intended voice chat.
MvEargasmDJ: This is my submission for the Telegram Radio Project of Baivaru. Which required a userbot to continiously play random audio files from th
 24 Nov 12, 2022
24 Nov 12, 2022
HyperPose is a library for building high-performance custom pose estimation applications.
HyperPose is a library for building high-performance custom pose estimation applications.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling @ INTERSPEECH 2021 Accepted
NU-Wave — Official PyTorch Implementation NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling Junhyeok Lee, Seungu Han @ MINDsLab Inc
 242 Dec 23, 2022
242 Dec 23, 2022

box is a text-based visual programming language inspired by Unreal Engine Blueprint function graphs.
Box is a text-based visual programming language inspired by Unreal Engine blueprint function graphs. $ cat factorial.box ┌─ƒ(Factorial)───┐
 104 Dec 24, 2022
104 Dec 24, 2022

Classify bird species based on their songs using SIamese Networks and 1D dilated convolutions.
The goal is to classify different birds species based on their songs/calls. Spectrograms have been extracted from the audio samples and used as features for classification.
9 Dec 27, 2022
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
 564 Jan 3, 2023
564 Jan 3, 2023

Code for "Learning Canonical Representations for Scene Graph to Image Generation", Herzig & Bar et al., ECCV2020
Learning Canonical Representations for Scene Graph to Image Generation (ECCV 2020) Roei Herzig*, Amir Bar*, Huijuan Xu, Gal Chechik, Trevor Darrell, A
 24 Jul 7, 2022
24 Jul 7, 2022
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
 93 Dec 17, 2022
93 Dec 17, 2022
![[CVPR2021] Look before you leap: learning landmark features for one-stage visual grounding.](https://github.com/svip-lab/LBYLNet/raw/main/imgs/landmarks.png)
[CVPR2021] Look before you leap: learning landmark features for one-stage visual grounding.
LBYL-Net This repo implements paper Look Before You Leap: Learning Landmark Features For One-Stage Visual Grounding CVPR 2021. Getting Started Prerequ
 45 Dec 12, 2022
45 Dec 12, 2022
Source code for models described in the paper "AudioCLIP: Extending CLIP to Image, Text and Audio" (https://arxiv.org/abs/2106.13043)
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
 458 Jan 2, 2023
458 Jan 2, 2023

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022

VID-Fusion: Robust Visual-Inertial-Dynamics Odometry for Accurate External Force Estimation
VID-Fusion VID-Fusion: Robust Visual-Inertial-Dynamics Odometry for Accurate External Force Estimation Authors: Ziming Ding , Tiankai Yang, Kunyi Zhan
 86 Nov 18, 2022
86 Nov 18, 2022
Localizing Visual Sounds the Hard Way
Localizing-Visual-Sounds-the-Hard-Way Code and Dataset for "Localizing Visual Sounds the Hard Way". The repo contains code and our pre-trained model.
 58 Dec 7, 2022
58 Dec 7, 2022

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023

This repository contains a PyTorch implementation of "AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis".
AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis | Project Page | Paper | PyTorch implementation for the paper "AD-NeRF: Audio
 551 Dec 29, 2022
551 Dec 29, 2022
AudioCLIP Extending CLIP to Image, Text and Audio
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
458 Jan 2, 2023
Use android as mic/speaker for ubuntu
Pulse Audio Control Panel Platforms Requirements sudo apt install ffmpeg pactl (already installed) Download Download the AppImage from release page ch
 19 Dec 1, 2022
19 Dec 1, 2022

Among AIs is a (prototype of) PC Game we developed as part of the Smart Applications course @ University of Pisa.
Among AIs is a PC Game we developed as part of the Smart Applications course @ Department of Computer Science of University of Pisa, under t
 5 Dec 5, 2021
5 Dec 5, 2021

Orthogonal Over-Parameterized Training
The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is of great importance. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. See our previous work -- MHE for an in-depth introduction.
 11 Apr 18, 2022
11 Apr 18, 2022

Visual Weather api. Returns beautiful pictures with the current weather.
VWapi Visual Weather api. Returns beautiful pictures with the current weather. Installation: sudo apt update -y && sudo apt upgrade -y sudo apt instal
 33 Nov 13, 2022
33 Nov 13, 2022
Python tool to check a web applications compliance with OWASP HTTP response headers best practices
Check Your Head A quick and easy way to check a web applications response headers!
 6 Nov 9, 2021
6 Nov 9, 2021
This is a multi-app executor that it used when we have some different task in a our applications and want to run them at the same time
This is a multi-app executor that it used when we have some different task in a our applications and want to run them at the same time. It uses SQLAlchemy for ORM and Alembic for database migrations.
 5 Apr 16, 2022
5 Apr 16, 2022

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
 59 Dec 6, 2022
59 Dec 6, 2022

MLP-Like Vision Permutator for Visual Recognition (PyTorch)
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition (arxiv) This is a Pytorch implementation of our paper. We present Vision
 162 Nov 28, 2022
162 Nov 28, 2022
PyTorch implementation code for the paper MixCo: Mix-up Contrastive Learning for Visual Representation
How to Reproduce our Results This repository contains PyTorch implementation code for the paper MixCo: Mix-up Contrastive Learning for Visual Represen
 46 Dec 15, 2022
46 Dec 15, 2022

VOLO: Vision Outlooker for Visual Recognition
VOLO: Vision Outlooker for Visual Recognition, arxiv This is a PyTorch implementation of our paper. We present Vision Outlooker (VOLO). We show that o
 876 Dec 9, 2022
876 Dec 9, 2022

Code for the RA-L (ICRA) 2021 paper "SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition"
SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition [ArXiv+Supplementary] [IEEE Xplore RA-L 2021] [ICRA 2021 YouTube Video]
 63 Dec 12, 2022
63 Dec 12, 2022

JittorVis - Visual understanding of deep learning model.
JittorVis is a deep neural network computational graph visualization library based on Jittor.
 182 Jan 6, 2023
182 Jan 6, 2023
Sierra is a lightweight Python framework for building and integrating web applications
A lightweight Python framework for building and Integrating Web Applications. Sierra is a Python3 library for building and integrating web applications with HTML and CSS using simple enough syntax. You can develop your web applications with Python, taking advantage of its functionalities and integrating them to the fullest.
 83 Sep 23, 2022
83 Sep 23, 2022
Role Based Access Control for Slack-Bolt Applications
Role Based Access Control for Slack-Bolt Apps Role Based Access Control (RBAC) is a term applied to limiting the authorization for a specific operatio
 7 Jan 6, 2022
7 Jan 6, 2022
spafe: Simplified Python Audio-Features Extraction
spafe aims to simplify features extractions from mono audio files. The library can extract of the following features: BFCC, LFCC, LPC, LPCC, MFCC, IMFCC, MSRCC, NGCC, PNCC, PSRCC, PLP, RPLP, Frequency-stats etc. It also provides various filterbank modules (Mel, Bark and Gammatone filterbanks) and other spectral statistics.
 310 Jan 1, 2023
310 Jan 1, 2023

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022

Episodic Transformer (E.T.) is a novel attention-based architecture for vision-and-language navigation. E.T. is based on a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions.
Episodic Transformers (E.T.) Episodic Transformer for Vision-and-Language Navigation Alexander Pashevich, Cordelia Schmid, Chen Sun Episodic Transform
 62 Dec 24, 2022
62 Dec 24, 2022