1214 Repositories
Python automatic-speech-recognition Libraries
Some Boring Research About Products Recognition 、Duplicate Img Detection、Img Stitch、OCR
Products Recognition 介绍 商品识别,围绕在复杂的商场零售场景中,识别出货架图像中的商品信息。主要组成部分: 重复图像检测。【更新进度 4/10】 图像拼接。【更新进度 0/10】 目标检测。【更新进度 0/10】 商品识别。【更新进度 1/10】 OCR。【更新进度 1/10】
 18 Jan 27, 2022
18 Jan 27, 2022
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my thesis if you're curious or if you're looking for info I haven't documented. Mostly I would recommend giving a quick look to the figures beyond the introduction.
 38.5k Jan 3, 2023
38.5k Jan 3, 2023

Orthogonal Over-Parameterized Training
The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is of great importance. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. See our previous work -- MHE for an in-depth introduction.
 11 Apr 18, 2022
11 Apr 18, 2022

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
 59 Dec 6, 2022
59 Dec 6, 2022

MLP-Like Vision Permutator for Visual Recognition (PyTorch)
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition (arxiv) This is a Pytorch implementation of our paper. We present Vision
 162 Nov 28, 2022
162 Nov 28, 2022

VOLO: Vision Outlooker for Visual Recognition
VOLO: Vision Outlooker for Visual Recognition, arxiv This is a PyTorch implementation of our paper. We present Vision Outlooker (VOLO). We show that o
 876 Dec 9, 2022
876 Dec 9, 2022

This is an official implementation for "Video Swin Transformers".
Video Swin Transformer By Ze Liu*, Jia Ning*, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin and Han Hu. This repo is the official implementation of "V
 981 Jan 3, 2023
981 Jan 3, 2023

Code for the RA-L (ICRA) 2021 paper "SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition"
SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition [ArXiv+Supplementary] [IEEE Xplore RA-L 2021] [ICRA 2021 YouTube Video]
 63 Dec 12, 2022
63 Dec 12, 2022
PyTorch implementation of the paper The Lottery Ticket Hypothesis for Object Recognition
LTH-ObjectRecognition The Lottery Ticket Hypothesis for Object Recognition Sharath Girish*, Shishira R Maiya*, Kamal Gupta, Hao Chen, Larry Davis, Abh
 16 Feb 6, 2022
16 Feb 6, 2022

Code for the CVPR2021 paper "Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition"
Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition This repository contains code for the CVPR2021 paper "Patch-NetV
 368 Jan 6, 2023
368 Jan 6, 2023
Code for "Primitive Representation Learning for Scene Text Recognition" (CVPR 2021)
Primitive Representation Learning Network (PREN) This repository contains the code for our paper accepted by CVPR 2021 Primitive Representation Learni
 76 Jan 2, 2023
76 Jan 2, 2023
Speech Recognition for Uyghur using Speech transformer
Speech Recognition for Uyghur using Speech transformer Training: this model using CTC loss and Cross Entropy loss for training. Download pretrained mo
 11 Nov 17, 2022
11 Nov 17, 2022

PyTorch implementation of "ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context" (INTERSPEECH 2020)
ContextNet ContextNet has CNN-RNN-transducer architecture and features a fully convolutional encoder that incorporates global context information into
 24 Nov 24, 2022
24 Nov 24, 2022

Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models
Patch-Rotation(PatchRot) Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models Submitted to Neurips2021 To
 4 Jul 12, 2021
4 Jul 12, 2021

Isearch (OSINT) 🔎 Face recognition reverse image search on Instagram profile feed photos.
isearch is an OSINT tool on Instagram. Offers a face recognition reverse image search on Instagram profile feed photos.
 20 Oct 25, 2022
20 Oct 25, 2022
Automatic login utility of free Wi-Fi captive portals
wicafe Automatic login utility of free Wi-Fi captive portals Disclaimer: read and grant the Terms of Service of Wi-Fi services before using it! This u
 8 May 31, 2022
8 May 31, 2022
spafe: Simplified Python Audio-Features Extraction
spafe aims to simplify features extractions from mono audio files. The library can extract of the following features: BFCC, LFCC, LPC, LPCC, MFCC, IMFCC, MSRCC, NGCC, PNCC, PSRCC, PLP, RPLP, Frequency-stats etc. It also provides various filterbank modules (Mel, Bark and Gammatone filterbanks) and other spectral statistics.
 310 Jan 1, 2023
310 Jan 1, 2023

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022
An integration of several popular automatic augmentation methods, including OHL (Online Hyper-Parameter Learning for Auto-Augmentation Strategy) and AWS (Improving Auto Augment via Augmentation Wise Weight Sharing) by Sensetime Research.
An integration of several popular automatic augmentation methods, including OHL (Online Hyper-Parameter Learning for Auto-Augmentation Strategy) and AWS (Improving Auto Augment via Augmentation Wise Weight Sharing) by Sensetime Research.
 45 Dec 8, 2022
45 Dec 8, 2022

This repository is an open-source implementation of the ICRA 2021 paper: Locus: LiDAR-based Place Recognition using Spatiotemporal Higher-Order Pooling.
Locus This repository is an open-source implementation of the ICRA 2021 paper: Locus: LiDAR-based Place Recognition using Spatiotemporal Higher-Order
 96 Dec 15, 2022
96 Dec 15, 2022
This is the official pytorch implementation of AutoDebias, an automatic debiasing method for recommendation.
AutoDebias This is the official pytorch implementation of AutoDebias, a debiasing method for recommendation system. AutoDebias is proposed in the pape
 77 Nov 25, 2022
77 Nov 25, 2022

Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition The official code of ABINet (CVPR 2021, Oral).
 334 Dec 31, 2022
334 Dec 31, 2022
![[CVPR 21] Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting, IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2021.](https://github.com/AyanKumarBhunia/Self-Supervised-Learning-for-Sketch/raw/main/sample_images/outline.png)
[CVPR 21] Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting, IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2021.
Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting, CVPR 2021. Ayan Kumar Bhunia, Pinaki nath Chowdhury, Yongxin Yan
 44 Dec 12, 2022
44 Dec 12, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022

A gesture recognition system powered by OpenPose, k-nearest neighbours, and local outlier factor.
OpenHands OpenHands is a gesture recognition system powered by OpenPose, k-nearest neighbours, and local outlier factor. Currently the system can iden
 12 Jan 10, 2022
12 Jan 10, 2022
easySpeech is an open-source Python wrapper for google speech to text API that doesn't require PyAudio(So you especially windows user don't have to deal with the errors while installing PyAudio) and also works with hugging face transformers
easySpeech easySpeech is an open source python wrapper for google speech to text api that doesn't require PyAaudio(So you specially windows user don't
 14 May 24, 2022
14 May 24, 2022
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation. Training python train.py --c
 55 Dec 26, 2022
55 Dec 26, 2022

Official PyTorch code for CVPR 2020 paper "Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision"
Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision https://arxiv.org/abs/2003.00393 Abstract Active learning (AL) aims to min
 29 Nov 21, 2022
29 Nov 21, 2022

The coda and data for "Measuring Fine-Grained Domain Relevance of Terms: A Hierarchical Core-Fringe Approach" (ACL '21)
We propose a hierarchical core-fringe learning framework to measure fine-grained domain relevance of terms – the degree that a term is relevant to a broad (e.g., computer science) or narrow (e.g., deep learning) domain.
 14 Oct 21, 2022
14 Oct 21, 2022
Code for our paper "Transfer Learning for Sequence Generation: from Single-source to Multi-source" in ACL 2021.
TRICE: a task-agnostic transferring framework for multi-source sequence generation This is the source code of our work Transfer Learning for Sequence
 9 Jun 27, 2022
9 Jun 27, 2022
Hand gesture recognition based whiteboard that allows you to write on live webcam. This is the first version and has features like 4 different colors, eraser and a recording option that records your session and saves it in a "recordings" folder. Use index finger to draw and two or more fingers to move around and select items. Future version will contain more functionalities like changeable thickness, color palette, integration with zoom and google meet etc.
hand-write Hand gesture recognition based whiteboard that allows you to write on live webcam. This is the first version and has features like 4 differ
 27 Dec 16, 2022
27 Dec 16, 2022
learn how to use Gesture Control to change the volume of a computer
Volume-Control-using-gesture In this project we are going to learn how to use Gesture Control to change the volume of a computer. We first look into h
 49 Sep 22, 2022
49 Sep 22, 2022

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
140 Dec 21, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
31 Dec 8, 2022

JAX code for the paper "Control-Oriented Model-Based Reinforcement Learning with Implicit Differentiation"
Optimal Model Design for Reinforcement Learning This repository contains JAX code for the paper Control-Oriented Model-Based Reinforcement Learning wi
 43 Sep 28, 2022
43 Sep 28, 2022

SpanNER: Named EntityRe-/Recognition as Span Prediction
SpanNER: Named EntityRe-/Recognition as Span Prediction Overview | Demo | Installation | Preprocessing | Prepare Models | Running | System Combination
 104 Dec 17, 2022
104 Dec 17, 2022
It's final year project of Diploma Engineering. This project is based on Computer Vision.
Face-Recognition-Based-Attendance-System It's final year project of Diploma Engineering. This project is based on Computer Vision. Brief idea about ou
 10 Nov 2, 2022
10 Nov 2, 2022

Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers.
Less is More: Pay Less Attention in Vision Transformers Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers. By
 73 Jan 1, 2023
73 Jan 1, 2023
Face recognition. Redefined.
FaceFinder Use a powerful CNN to identify faces in images! TABLE OF CONTENTS About The Project Built With Getting Started Prerequisites Installation U
 20 Jun 16, 2021
20 Jun 16, 2021

VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech Jaehyeon Kim, Jungil Kong, and Juhee Son In our rece
 1.7k Jan 8, 2023
1.7k Jan 8, 2023

deployment of a hybrid model for automatic weapon detection/ anomaly detection for surveillance applications
Automatic Weapon Detection Deployment of a hybrid model for automatic weapon detection/ anomaly detection for surveillance applications. Loved the pro
 4 Mar 4, 2022
4 Mar 4, 2022

InsightFace: 2D and 3D Face Analysis Project on MXNet and PyTorch
InsightFace: 2D and 3D Face Analysis Project on MXNet and PyTorch
 13.2k Jan 6, 2023
13.2k Jan 6, 2023

Automatic Attendance marker for LMS Practice School Division, BITS Pilani
LMS Attendance Marker Automatic script for lazy people to mark attendance on LMS for Practice School 1. Setup Add your LMS credentials and time slot t
 3 Jun 12, 2021
3 Jun 12, 2021

Open-Source Toolkit for End-to-End Speech Recognition leveraging PyTorch-Lightning and Hydra.
OpenSpeech provides reference implementations of various ASR modeling papers and three languages recipe to perform tasks on automatic speech recogniti
 86 Jun 11, 2021
86 Jun 11, 2021
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 6, 2023
Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. This Neural Network (NN) model recognizes the text contained in the images of segmented words.
Handwritten-Text-Recognition Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. T
 27 Jan 8, 2023
27 Jan 8, 2023
Open-Source Toolkit for End-to-End Speech Recognition leveraging PyTorch-Lightning and Hydra.
OpenSpeech provides reference implementations of various ASR modeling papers and three languages recipe to perform tasks on automatic speech recogniti
26 Dec 14, 2022
Automatic differentiation with weighted finite-state transducers.
GTN: Automatic Differentiation with WFSTs Quickstart | Installation | Documentation What is GTN? GTN is a framework for automatic differentiation with
 100 Dec 29, 2022
100 Dec 29, 2022

Official PyTorch implementation of "Adversarial Reciprocal Points Learning for Open Set Recognition"
Adversarial Reciprocal Points Learning for Open Set Recognition Official PyTorch implementation of "Adversarial Reciprocal Points Learning for Open Se
 78 Dec 28, 2022
78 Dec 28, 2022
Synthetic Humans for Action Recognition, IJCV 2021
SURREACT: Synthetic Humans for Action Recognition from Unseen Viewpoints Gül Varol, Ivan Laptev and Cordelia Schmid, Andrew Zisserman, Synthetic Human
 59 Dec 14, 2022
59 Dec 14, 2022
Ecommerce product title recognition package
revizor This package solves task of splitting product title string into components, like type, brand, model and article (or SKU or product code or you
 16 Mar 3, 2022
16 Mar 3, 2022

automatic mails sender with attachments
أزعجني لين تدربني Automatic mails sender with attachments. Note: You need to have gmail account & and you need to turn on "Less secure app access" set
 6 Dec 30, 2022
6 Dec 30, 2022
Automatic voice-synthetised summaries of latest research papers on arXiv
PaperWhisperer PaperWhisperer is a Python application that keeps you up-to-date with research papers. How? It retrieves the latest articles from arXiv
 124 Dec 20, 2022
124 Dec 20, 2022

Pytorch Implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension)
DiffSinger - PyTorch Implementation PyTorch implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension). Status
152 Jan 2, 2023

An Efficient Training Approach for Very Large Scale Face Recognition or F²C for simplicity.
Fast Face Classification (F²C) This is the code of our paper An Efficient Training Approach for Very Large Scale Face Recognition or F²C for simplicit
 33 Jun 27, 2021
33 Jun 27, 2021
Chinese clinical named entity recognition using pre-trained BERT model
Chinese clinical named entity recognition (CNER) using pre-trained BERT model Introduction Code for paper Chinese clinical named entity recognition wi
 109 Dec 14, 2022
109 Dec 14, 2022

This is the research repository for Vid2Doppler: Synthesizing Doppler Radar Data from Videos for Training Privacy-Preserving Activity Recognition.
Vid2Doppler: Synthesizing Doppler Radar Data from Videos for Training Privacy-Preserving Activity Recognition This is the research repository for Vid2
 26 Dec 24, 2022
26 Dec 24, 2022

Anonymize BLM Protest Images
Anonymize BLM Protest Images This repository automates @BLMPrivacyBot, a Twitter bot that shows the anonymized images to help keep protesters safe. Us
 40 Oct 13, 2022
40 Oct 13, 2022
This is an official implementation for "ResT: An Efficient Transformer for Visual Recognition".
ResT By Qing-Long Zhang and Yu-Bin Yang [State Key Laboratory for Novel Software Technology at Nanjing University] This repo is the official implement
 222 Dec 13, 2022
222 Dec 13, 2022

Official repo for AutoInt: Automatic Integration for Fast Neural Volume Rendering in CVPR 2021
AutoInt: Automatic Integration for Fast Neural Volume Rendering CVPR 2021 Project Page | Video | Paper PyTorch implementation of automatic integration
 149 Dec 22, 2022
149 Dec 22, 2022
Automatic generator of readmes for git repositories (Includes file' listing)
Readme Generator We are bored of write the same things once and once again. We trust in the comments made inside of our files, and we decided to autom
 6 Jul 20, 2021
6 Jul 20, 2021
A PyTorch implementation of paper "Learning Shared Semantic Space for Speech-to-Text Translation", ACL (Findings) 2021
Chimera: Learning Shared Semantic Space for Speech-to-Text Translation This is a Pytorch implementation for the "Chimera" paper Learning Shared Semant
 43 Dec 28, 2022
43 Dec 28, 2022
Rest API Written In Python To Classify NSFW Images.
✨ NSFW Classifier API ✨ Rest API Written In Python To Classify NSFW Images. Fastest Solution If you don't want to selfhost it, there's already an inst
 23 Dec 30, 2022
23 Dec 30, 2022
Simple, hackable offline speech to text - using the VOSK-API.
Nerd Dictation Offline Speech to Text for Desktop Linux. This is a utility that provides simple access speech to text for using in Linux without being
 844 Jan 7, 2023
844 Jan 7, 2023

Scale-aware Automatic Augmentation for Object Detection (CVPR 2021)
SA-AutoAug Scale-aware Automatic Augmentation for Object Detection Yukang Chen, Yanwei Li, Tao Kong, Lu Qi, Ruihang Chu, Lei Li, Jiaya Jia [Paper] [Bi
 182 Dec 29, 2022
182 Dec 29, 2022
Datasets of Automatic Keyphrase Extraction
This repository contains 20 annotated datasets of Automatic Keyphrase Extraction made available by the research community. Following are the datasets and the original papers that proposed them. If you know more datasets, and want to contribute, please, notify me.
 163 Dec 23, 2022
163 Dec 23, 2022
Conformer: Local Features Coupling Global Representations for Visual Recognition
Conformer: Local Features Coupling Global Representations for Visual Recognition (arxiv) This repository is built upon DeiT and timm Usage First, inst
 378 Jan 8, 2023
378 Jan 8, 2023

Official codes for the paper "Learning Hierarchical Discrete Linguistic Units from Visually-Grounded Speech"
ResDAVEnet-VQ Official PyTorch implementation of Learning Hierarchical Discrete Linguistic Units from Visually-Grounded Speech What is in this repo? M
 21 Aug 23, 2022
21 Aug 23, 2022

PyTorch code of my ICDAR 2021 paper Vision Transformer for Fast and Efficient Scene Text Recognition (ViTSTR)
Vision Transformer for Fast and Efficient Scene Text Recognition (ICDAR 2021) ViTSTR is a simple single-stage model that uses a pre-trained Vision Tra
 198 Dec 27, 2022
198 Dec 27, 2022

ERISHA is a mulitilingual multispeaker expressive speech synthesis framework. It can transfer the expressivity to the speaker's voice for which no expressive speech corpus is available.
ERISHA: Multilingual Multispeaker Expressive Text-to-Speech Library ERISHA is a multilingual multispeaker expressive speech synthesis framework. It ca
 43 Nov 27, 2022
43 Nov 27, 2022

Face Transformer for Recognition
Face-Transformer This is the code of Face Transformer for Recognition (https://arxiv.org/abs/2103.14803v2). Recently there has been great interests of
 153 Nov 30, 2022
153 Nov 30, 2022

voice2json is a collection of command-line tools for offline speech/intent recognition on Linux
Command-line tools for speech and intent recognition on Linux
 988 Jan 4, 2023
988 Jan 4, 2023

Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Parallel Tacotron2 Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
170 Dec 27, 2022
Automatic certificate unpinning for Android apps
What is this? Script used to perform automatic certificate unpinning of an APK by adding a custom network security configuration that permits user-add
 5 Jul 28, 2021
5 Jul 28, 2021
Python codes for Lite Audio-Visual Speech Enhancement.
Lite Audio-Visual Speech Enhancement (Interspeech 2020) Introduction This is the PyTorch implementation of Lite Audio-Visual Speech Enhancement (LAVSE
 85 Dec 1, 2022
85 Dec 1, 2022

Keeping it safe - AI Based COVID-19 Tracker using Deep Learning and facial recognition
Keeping it safe - AI Based COVID-19 Tracker using Deep Learning and facial recognition
 15 Jun 17, 2021
15 Jun 17, 2021

EQFace: An implementation of EQFace: A Simple Explicit Quality Network for Face Recognition
EQFace: A Simple Explicit Quality Network for Face Recognition The first face recognition network that generates explicit face quality online.
 141 Dec 31, 2022
141 Dec 31, 2022
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
RepMLP RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition Released the code of RepMLP together with an example o
 260 Jan 3, 2023
260 Jan 3, 2023
TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition.
TraND This is the code for the paper "Jinkai Zheng, Xinchen Liu, Chenggang Yan, Jiyong Zhang, Wu Liu, Xiaoping Zhang and Tao Mei: TraND: Transferable
 32 Apr 4, 2022
32 Apr 4, 2022

Radar-to-Lidar: Heterogeneous Place Recognition via Joint Learning
radar-to-lidar-place-recognition This page is the coder of a pre-print, implemented by PyTorch. If you have some questions on this project, please fee
 37 Oct 9, 2022
37 Oct 9, 2022
A list of papers about point cloud based place recognition, also known as loop closure detection in SLAM (processing)
A list of papers about point cloud based place recognition, also known as loop closure detection in SLAM (processing)
 17 May 16, 2021
17 May 16, 2021

Text to speech is a process to convert any text into voice. Text to speech project takes words on digital devices and convert them into audio. Here I have used Google-text-to-speech library popularly known as gTTS library to convert text file to .mp3 file. Hope you like my project!
Text to speech (using Python) Text to speech is a process to convert any text into voice. Text to speech project takes words on digital devices and co
 19 Jun 30, 2022
19 Jun 30, 2022

Face Detection & Age Gender & Expression & Recognition
Face Detection & Age Gender & Expression & Recognition
 188 Dec 28, 2022
188 Dec 28, 2022
framework providing automatic constructions of vulnerable infrastructures
中文 | English 1 Introduction Metarget = meta- + target, a framework providing automatic constructions of vulnerable infrastructures, used to deploy sim
 685 Dec 28, 2022
685 Dec 28, 2022
A fast Text-to-Speech (TTS) model. Work well for English, Mandarin/Chinese, Japanese, Korean, Russian and Tibetan (so far). 快速语音合成模型,适用于英语、普通话/中文、日语、韩语、俄语和藏语(当前已测试)。
简体中文 | English 并行语音合成 [TOC] 新进展 2021/04/20 合并 wavegan 分支到 main 主分支,删除 wavegan 分支! 2021/04/13 创建 encoder 分支用于开发语音风格迁移模块! 2021/04/13 softdtw 分支 支持使用 Sof
 161 Dec 19, 2022
161 Dec 19, 2022
This repository describes our reproducible framework for assessing self-supervised representation learning from speech
LeBenchmark: a reproducible framework for assessing SSL from speech Self-Supervised Learning (SSL) using huge unlabeled data has been successfully exp
 49 Aug 24, 2022
49 Aug 24, 2022
Modular and extensible speech recognition library leveraging pytorch-lightning and hydra.
Lightning ASR Modular and extensible speech recognition library leveraging pytorch-lightning and hydra What is Lightning ASR • Installation • Get Star
40 Sep 19, 2022
Identify the emotion of multiple speakers in an Audio Segment
MevonAI - Speech Emotion Recognition
 111 Jan 7, 2023
111 Jan 7, 2023
Espresso: A Fast End-to-End Neural Speech Recognition Toolkit
Espresso Espresso is an open-source, modular, extensible end-to-end neural automatic speech recognition (ASR) toolkit based on the deep learning libra
 919 Jan 3, 2023
919 Jan 3, 2023
pytorch-kaldi is a project for developing state-of-the-art DNN/RNN hybrid speech recognition systems. The DNN part is managed by pytorch, while feature extraction, label computation, and decoding are performed with the kaldi toolkit.
The PyTorch-Kaldi Speech Recognition Toolkit PyTorch-Kaldi is an open-source repository for developing state-of-the-art DNN/HMM speech recognition sys
 2.3k Dec 27, 2022
2.3k Dec 27, 2022

Pytorch-Named-Entity-Recognition-with-BERT
BERT NER Use google BERT to do CoNLL-2003 NER ! Train model using Python and Inference using C++ ALBERT-TF2.0 BERT-NER-TENSORFLOW-2.0 BERT-SQuAD Requi
 1.1k Dec 25, 2022
1.1k Dec 25, 2022

Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
 881 Jan 3, 2023
881 Jan 3, 2023
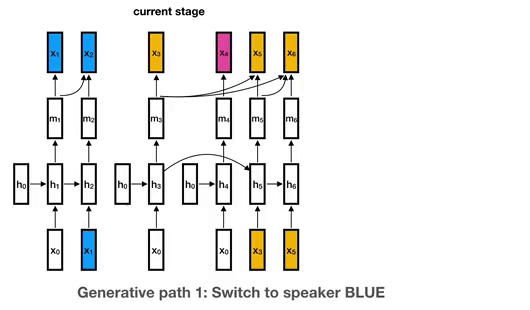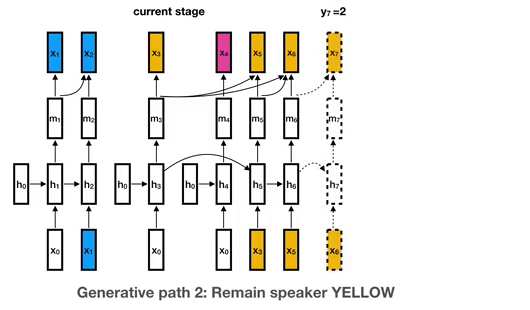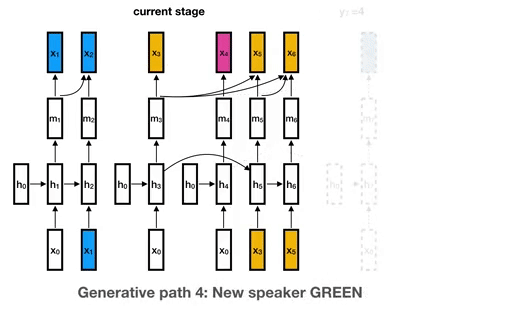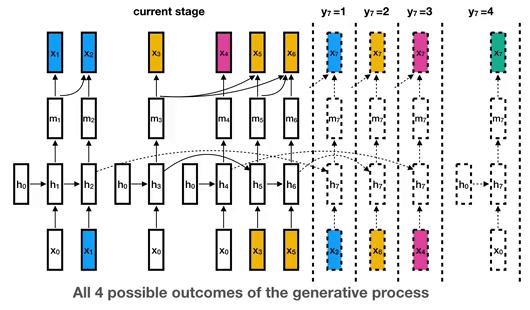
This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm, corresponding to the paper Fully Supervised Speaker Diarization.
UIS-RNN Overview This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm. UIS-RNN solves the problem of s
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
End-to-End Speech Processing Toolkit
ESPnet: end-to-end speech processing toolkit system/pytorch ver. 1.0.1 1.1.0 1.2.0 1.3.1 1.4.0 1.5.1 1.6.0 1.7.1 1.8.1 ubuntu18/python3.8/pip ubuntu18
 5.9k Jan 3, 2023
5.9k Jan 3, 2023
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
 2.2k Jan 9, 2023
2.2k Jan 9, 2023

Pytorch implementation of Tacotron
Tacotron-pytorch A pytorch implementation of Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model. Requirements Install python 3 Install pytorc
 203 Dec 2, 2022
203 Dec 2, 2022
Sequence-to-Sequence Framework in PyTorch
nmtpytorch allows training of various end-to-end neural architectures including but not limited to neural machine translation, image captioning and au
 395 Nov 21, 2022
395 Nov 21, 2022
A PyTorch Implementation of End-to-End Models for Speech-to-Text
speech Speech is an open-source package to build end-to-end models for automatic speech recognition. Sequence-to-sequence models with attention, Conne
 647 Dec 25, 2022
647 Dec 25, 2022

A method to generate speech across multiple speakers
VoiceLoop PyTorch implementation of the method described in the paper VoiceLoop: Voice Fitting and Synthesis via a Phonological Loop. VoiceLoop is a n
 873 Dec 15, 2022
873 Dec 15, 2022
Data manipulation and transformation for audio signal processing, powered by PyTorch
torchaudio: an audio library for PyTorch The aim of torchaudio is to apply PyTorch to the audio domain. By supporting PyTorch, torchaudio follows the
 1.9k Jan 8, 2023
1.9k Jan 8, 2023