1214 Repositories
Python automatic-speech-recognition Libraries
Official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch.
Multi-speaker DGP This repository provides official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch. O
 24 Sep 7, 2022
24 Sep 7, 2022

AdaFocus (ICCV 2021) Adaptive Focus for Efficient Video Recognition
AdaFocus (ICCV 2021) This repo contains the official code and pre-trained models for AdaFocus. Adaptive Focus for Efficient Video Recognition Referenc
 115 Dec 21, 2022
115 Dec 21, 2022
Source Code For Template-Based Named Entity Recognition Using BART
Template-Based NER Source Code For Template-Based Named Entity Recognition Using BART Training Training train.py Inference inference.py Corpus ATIS (h
 174 Dec 19, 2022
174 Dec 19, 2022
Automatic ProxyShell Exploit
proxyshell-auto usage: proxyshell.py [-h] -t T Automatic Exploit ProxyShell optional arguments: -h, --help show this help message and exit -t T
 93 Jan 5, 2023
93 Jan 5, 2023
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion Yinghao Aaron Li, Ali Zare, Nima Mesgarani We pres
 282 Jan 1, 2023
282 Jan 1, 2023

GSoC'2021 | TensorFlow implementation of Wav2Vec2
GSoC'2021 | TensorFlow implementation of Wav2Vec2
 73 Nov 28, 2022
73 Nov 28, 2022
Temporal Segment Networks (TSN) in PyTorch
TSN-Pytorch We have released MMAction, a full-fledged action understanding toolbox based on PyTorch. It includes implementation for TSN as well as oth
 1k Jan 3, 2023
1k Jan 3, 2023
PyTorch implementation of Tacotron speech synthesis model.
tacotron_pytorch PyTorch implementation of Tacotron speech synthesis model. Inspired from keithito/tacotron. Currently not as much good speech quality
 279 Dec 9, 2022
279 Dec 9, 2022

This is the offical website for paper ''Category-consistent deep network learning for accurate vehicle logo recognition''
The Pytorch Implementation of Category-consistent deep network learning for accurate vehicle logo recognition This is the offical website for paper ''
 28 Oct 29, 2022
28 Oct 29, 2022
This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab.
Speech-Backbones This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab. Grad-TTS Official implementation of the Grad-
 295 Jan 7, 2023
295 Jan 7, 2023

Jittor Medical Segmentation Lib -- The assignment of Pattern Recognition course (2021 Spring) in Tsinghua University
THU模式识别2021春 -- Jittor 医学图像分割 模型列表 本仓库收录了课程作业中同学们采用jittor框架实现的如下模型: UNet SegNet DeepLab V2 DANet EANet HarDNet及其改动HarDNet_alter PSPNet OCNet OCRNet DL
 48 Dec 26, 2022
48 Dec 26, 2022

Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions
Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions To learn more about this project: medium blog post The goal of this proje
 60 Dec 17, 2022
60 Dec 17, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022
Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning
structshot Code and data for paper "Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning", Yi Yang and Arz
 47 Dec 27, 2022
47 Dec 27, 2022
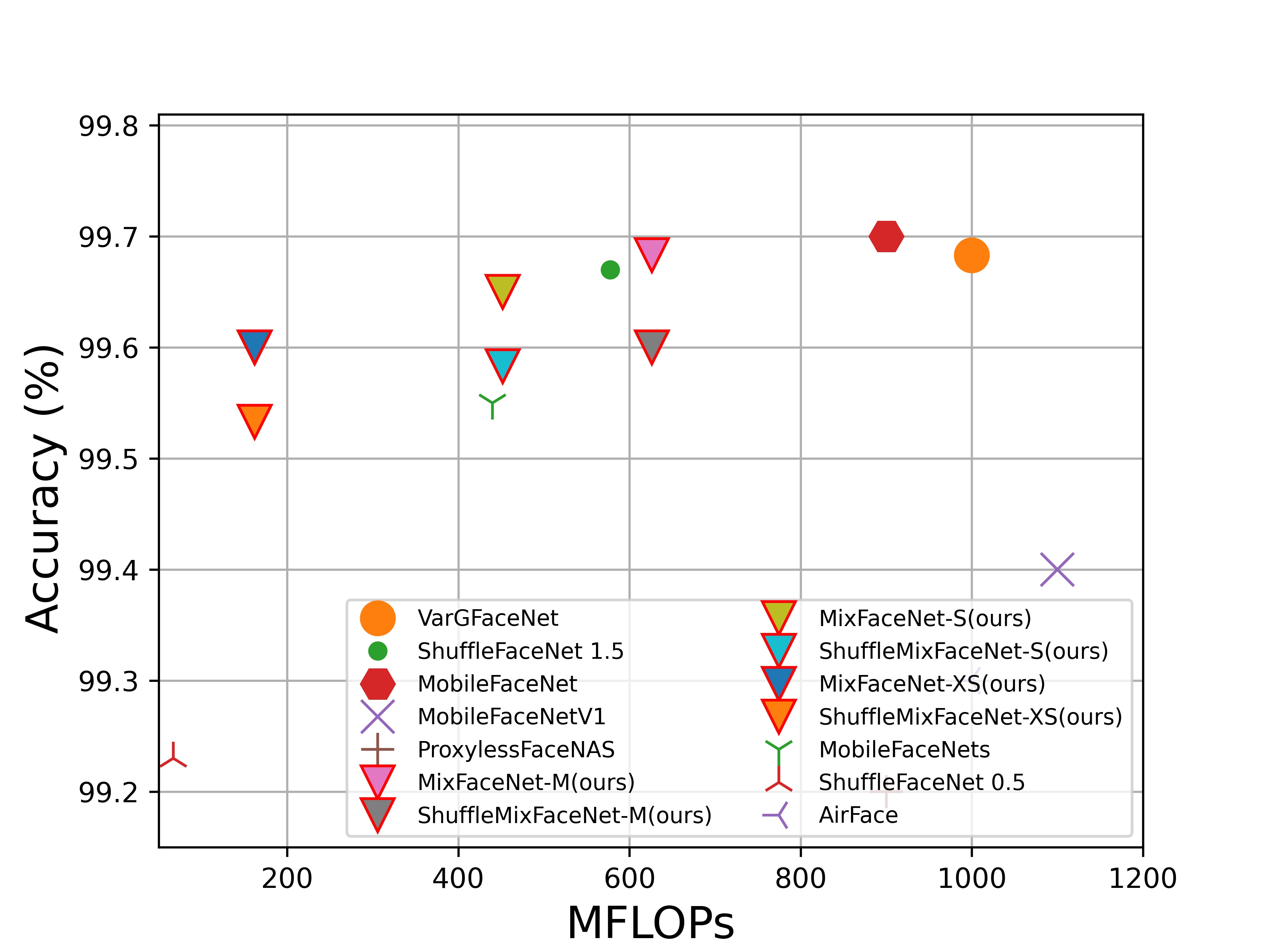
Official repository for MixFaceNets: Extremely Efficient Face Recognition Networks
MixFaceNets This is the official repository of the paper: MixFaceNets: Extremely Efficient Face Recognition Networks. (Accepted in IJCB2021) https://i
 51 Dec 13, 2022
51 Dec 13, 2022
3D ResNets for Action Recognition (CVPR 2018)
3D ResNets for Action Recognition Update (2020/4/13) We published a paper on arXiv. Hirokatsu Kataoka, Tenga Wakamiya, Kensho Hara, and Yutaka Satoh,
 3.5k Jan 6, 2023
3.5k Jan 6, 2023

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 5, 2023
247 Jan 5, 2023

A graphical Semi-automatic annotation tool based on labelImg and Yolov5
💕YOLOV5 semi-automatic annotation tool (Based on labelImg)
 247 Jan 5, 2023
247 Jan 5, 2023

Learning Compatible Embeddings, ICCV 2021
LCE Learning Compatible Embeddings, ICCV 2021 by Qiang Meng, Chixiang Zhang, Xiaoqiang Xu and Feng Zhou Paper: Arxiv We cannot release source codes pu
 25 Dec 17, 2022
25 Dec 17, 2022
Parametric Contrastive Learning (ICCV2021)
Parametric-Contrastive-Learning This repository contains the implementation code for ICCV2021 paper: Parametric Contrastive Learning (https://arxiv.or
 156 Dec 21, 2022
156 Dec 21, 2022
![[NeurIPS 2020] Official repository for the project](https://github.com/henryxrl/Listening-to-Sound-of-Silence-for-Speech-Denoising/raw/main/assets/network.png)
[NeurIPS 2020] Official repository for the project "Listening to Sound of Silence for Speech Denoising"
Listening to Sounds of Silence for Speech Denoising Introduction This is the repository of the "Listening to Sounds of Silence for Speech Denoising" p
 40 Dec 20, 2022
40 Dec 20, 2022
ExKaldi-RT: An Online Speech Recognition Extension Toolkit of Kaldi
ExKaldi-RT is an online ASR toolkit for Python language. It reads realtime streaming audio and do online feature extraction, probability computation, and online decoding.
 31 Aug 16, 2021
31 Aug 16, 2021
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 169 Jan 5, 2023
169 Jan 5, 2023
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023

Pytorch implementation for Semantic Segmentation/Scene Parsing on MIT ADE20K dataset
Semantic Segmentation on MIT ADE20K dataset in PyTorch This is a PyTorch implementation of semantic segmentation models on MIT ADE20K scene parsing da
 4.5k Jan 8, 2023
4.5k Jan 8, 2023

Automatic Calibration for Non-repetitive Scanning Solid-State LiDAR and Camera Systems
ACSC Automatic extrinsic calibration for non-repetitive scanning solid-state LiDAR and camera systems. System Architecture 1. Dependency Tested with U
 192 Dec 13, 2022
192 Dec 13, 2022

Code release for The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification (TIP 2020)
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification Code release for The Devil is in the Channels: Mutual-Channel
 230 Dec 31, 2022
230 Dec 31, 2022

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
 47 Dec 18, 2022
47 Dec 18, 2022
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition (PyTorch) Paper: https://arxiv.org/abs/2105.01883 Citation: @
 260 Jan 3, 2023
260 Jan 3, 2023
Official implementation for ICDAR 2021 paper "Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer"
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer Description Convert offline handwritten mathematical expressi
 87 Dec 27, 2022
87 Dec 27, 2022
PyTorch implementation for Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuous Sign Language Recognition.
Stochastic CSLR This is the PyTorch implementation for the ECCV 2020 paper: Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuou
 28 Dec 19, 2022
28 Dec 19, 2022
StarGAN-ZSVC: Unofficial PyTorch Implementation
This repository is an unofficial PyTorch implementation of StarGAN-ZSVC by Matthew Baas and Herman Kamper. This repository provides both model architectures and the code to inference or train them.
 11 Aug 28, 2022
11 Aug 28, 2022
AutoVideo: An Automated Video Action Recognition System
AutoVideo is a system for automated video analysis. It is developed based on D3M infrastructure, which describes machine learning with generic pipeline languages. Currently, it focuses on video action recognition, supporting various state-of-the-art video action recognition algorithms. It also supports automated model selection and hyperparameter tuning. AutoVideo is developed by DATA Lab at Texas A&M University.
 267 Dec 17, 2022
267 Dec 17, 2022

End-to-end text to speech system using gruut and onnx. There are 40 voices available across 8 languages.
End to end text to speech system using gruut and onnx
 673 Dec 28, 2022
673 Dec 28, 2022

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
 235 Dec 22, 2022
235 Dec 22, 2022
neural network based speaker embedder
Content What is deepaudio-speaker? Installation Get Started Model Architecture How to contribute to deepaudio-speaker? Acknowledge What is deepaudio-s
 20 Dec 29, 2022
20 Dec 29, 2022
Unified unsupervised and semi-supervised domain adaptation network for cross-scenario face anti-spoofing, Pattern Recognition
USDAN The implementation of Unified unsupervised and semi-supervised domain adaptation network for cross-scenario face anti-spoofing, which is accepte
 11 Nov 3, 2022
11 Nov 3, 2022
Data from "HateCheck: Functional Tests for Hate Speech Detection Models" (Röttger et al., ACL 2021)
In this repo, you can find the data from our ACL 2021 paper "HateCheck: Functional Tests for Hate Speech Detection Models". "test_suite_cases.csv" con
 43 Nov 11, 2022
43 Nov 11, 2022
SelfAugment extends MoCo to include automatic unsupervised augmentation selection.
SelfAugment extends MoCo to include automatic unsupervised augmentation selection. In addition, we've included the ability to pretrain on several new datasets and included a wandb integration.
 24 Oct 26, 2022
24 Oct 26, 2022

Clone a voice in 5 seconds to generate arbitrary speech in real-time
This repository is forked from Real-Time-Voice-Cloning which only support English. English | 中文 Features 🌍 Chinese supported mandarin and tested with
 25.6k Jan 6, 2023
25.6k Jan 6, 2023

Deep learning based hand gesture recognition using LSTM and MediaPipie.
Hand Gesture Recognition Deep learning based hand gesture recognition using LSTM and MediaPipie. Demo video using PingPong Robot Files Pretrained mode
 24 Nov 11, 2022
24 Nov 11, 2022
This repository contains data used in the NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Proteno This is the data release associated with the corresponding NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deploymen
 37 Dec 4, 2022
37 Dec 4, 2022
[ACL-IJCNLP 2021] Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning
CLNER The code is for our ACL-IJCNLP 2021 paper: Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning CLNER is a
 71 Dec 8, 2022
71 Dec 8, 2022
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022
DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021)
DPT This repo is the official implementation of DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021). We provide code and model
 111 Dec 21, 2022
111 Dec 21, 2022

Unified learning approach for egocentric hand gesture recognition and fingertip detection
Unified Gesture Recognition and Fingertip Detection A unified convolutional neural network (CNN) algorithm for both hand gesture recognition and finge
 227 Dec 25, 2022
227 Dec 25, 2022
OpenGAN: Open-Set Recognition via Open Data Generation
OpenGAN: Open-Set Recognition via Open Data Generation ICCV 2021 (oral) Real-world machine learning systems need to analyze novel testing data that di
 90 Jan 6, 2023
90 Jan 6, 2023
![[IJCAI'21] Deep Automatic Natural Image Matting](https://github.com/JizhiziLi/AIM/raw/master/demo/network.png)
[IJCAI'21] Deep Automatic Natural Image Matting
Deep Automatic Natural Image Matting [IJCAI-21] This is the official repository of the paper Deep Automatic Natural Image Matting. Introduction | Netw
 316 Jan 6, 2023
316 Jan 6, 2023

Official implementation of SynthTIGER (Synthetic Text Image GEneratoR) ICDAR 2021
🐯 SynthTIGER: Synthetic Text Image GEneratoR Official implementation of SynthTIGER | Paper | Datasets Moonbin Yim1, Yoonsik Kim1, Han-cheol Cho1, Sun
 256 Jan 5, 2023
256 Jan 5, 2023

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 170 Jan 4, 2023
170 Jan 4, 2023

Chinese real time voice cloning (VC) and Chinese text to speech (TTS).
Chinese real time voice cloning (VC) and Chinese text to speech (TTS). 好用的中文语音克隆兼中文语音合成系统,包含语音编码器、语音合成器、声码器和可视化模块。
 6 Nov 8, 2022
6 Nov 8, 2022

IoT owl is light face detection and recognition system made for small IoT devices like raspberry pi.
IoT Owl IoT owl is light face detection and recognition system made for small IoT devices like raspberry pi. Versions Heavy with mask detection withou
 6 Jun 6, 2022
6 Jun 6, 2022

A tiny, friendly, strong baseline code for Person-reID (based on pytorch).
Pytorch ReID Strong, Small, Friendly A tiny, friendly, strong baseline code for Person-reID (based on pytorch). Strong. It is consistent with the new
 3.5k Jan 8, 2023
3.5k Jan 8, 2023

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
1.8k Dec 30, 2022
PyTorch implementation of the R2Plus1D convolution based ResNet architecture described in the paper "A Closer Look at Spatiotemporal Convolutions for Action Recognition"
R2Plus1D-PyTorch PyTorch implementation of the R2Plus1D convolution based ResNet architecture described in the paper "A Closer Look at Spatiotemporal
 342 Dec 16, 2022
342 Dec 16, 2022

This project is a re-implementation of MASTER: Multi-Aspect Non-local Network for Scene Text Recognition by MMOCR
This project is a re-implementation of MASTER: Multi-Aspect Non-local Network for Scene Text Recognition by MMOCR,which is an open-source toolbox based on PyTorch. The overall architecture will be shown below.
 82 Nov 17, 2022
82 Nov 17, 2022
organize - The file management automation tool
organize - The file management automation tool
 1.5k Jan 1, 2023
1.5k Jan 1, 2023

Compressed Video Action Recognition
Compressed Video Action Recognition Chao-Yuan Wu, Manzil Zaheer, Hexiang Hu, R. Manmatha, Alexander J. Smola, Philipp Krähenbühl. In CVPR, 2018. [Proj
 479 Dec 26, 2022
479 Dec 26, 2022
Open-Source Toolkit for End-to-End Speech Recognition leveraging PyTorch-Lightning and Hydra.
🤗 Contributing to OpenSpeech 🤗 OpenSpeech provides reference implementations of various ASR modeling papers and three languages recipe to perform ta
 513 Jan 3, 2023
513 Jan 3, 2023

ICML 21 - Voice2Series: Reprogramming Acoustic Models for Time Series Classification
Voice2Series-Reprogramming Voice2Series: Reprogramming Acoustic Models for Time Series Classification International Conference on Machine Learning (IC
 49 Jan 3, 2023
49 Jan 3, 2023

Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
 193 Dec 30, 2022
193 Dec 30, 2022

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022

A text augmentation tool for named entity recognition.
neraug This python library helps you with augmenting text data for named entity recognition. Augmentation Example Reference from An Analysis of Simple
 48 Oct 11, 2022
48 Oct 11, 2022

A pytorch reproduction of { Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation }.
A PyTorch Reproduction of HCN Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation. Ch
 210 Dec 31, 2022
210 Dec 31, 2022
A Flow-based Generative Network for Speech Synthesis
WaveGlow: a Flow-based Generative Network for Speech Synthesis Ryan Prenger, Rafael Valle, and Bryan Catanzaro In our recent paper, we propose WaveGlo
 2k Dec 26, 2022
2k Dec 26, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 3, 2023
77.2k Jan 3, 2023
A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis
WaveGlow A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis Quick Start: Install requirements: pip install
 204 Jul 14, 2022
204 Jul 14, 2022
Athena is an open-source implementation of end-to-end speech processing engine.
Athena is an open-source implementation of end-to-end speech processing engine. Our vision is to empower both industrial application and academic research on end-to-end models for speech processing. To make speech processing available to everyone, we're also releasing example implementation and recipe on some opensource dataset for various tasks (Automatic Speech Recognition, Speech Synthesis, Voice Conversion, Speaker Recognition, etc).
 34 Sep 8, 2022
34 Sep 8, 2022
Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
193 Dec 30, 2022

Implementation of: "Exploring Randomly Wired Neural Networks for Image Recognition"
RandWireNN Unofficial PyTorch Implementation of: Exploring Randomly Wired Neural Networks for Image Recognition. Results Validation result on Imagenet
 684 Nov 2, 2022
684 Nov 2, 2022

Implementation of QuickDraw - an online game developed by Google, combined with AirGesture - a simple gesture recognition application
QuickDraw - AirGesture Introduction Here is my python source code for QuickDraw - an online game developed by google, combined with AirGesture - a sim
 89 Dec 18, 2022
89 Dec 18, 2022
PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022
Deep RGB-D Saliency Detection with Depth-Sensitive Attention and Automatic Multi-Modal Fusion (CVPR'2021, Oral)
DSA^2 F: Deep RGB-D Saliency Detection with Depth-Sensitive Attention and Automatic Multi-Modal Fusion (CVPR'2021, Oral) This repo is the official imp
 46 Dec 21, 2022
46 Dec 21, 2022

URIE: Universal Image Enhancementfor Visual Recognition in the Wild
URIE: Universal Image Enhancementfor Visual Recognition in the Wild This is the implementation of the paper "URIE: Universal Image Enhancement for Vis
 43 Sep 12, 2022
43 Sep 12, 2022

MicRank is a Learning to Rank neural channel selection framework where a DNN is trained to rank microphone channels.
MicRank: Learning to Rank Microphones for Distant Speech Recognition Application Scenario Many applications nowadays envision the presence of multiple
 20 Nov 10, 2022
20 Nov 10, 2022
A pytorch implementation of MBNET: MOS PREDICTION FOR SYNTHESIZED SPEECH WITH MEAN-BIAS NETWORK
Pytorch-MBNet A pytorch implementation of MBNET: MOS PREDICTION FOR SYNTHESIZED SPEECH WITH MEAN-BIAS NETWORK Training To train a new model, please ru
 46 Dec 28, 2022
46 Dec 28, 2022

Unofficial Pytorch Implementation of WaveGrad2
WaveGrad 2 — Unofficial PyTorch Implementation WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis Unofficial PyTorch+Lightning Implementati
104 Nov 29, 2022
Pytorch implementation of "Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech"
GradTTS Unofficial Pytorch implementation of "Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech" (arxiv) About this repo This is an unoffic
 103 Dec 23, 2022
103 Dec 23, 2022
Script for automatic dump and brute-force passwords using Volatility Framework
Volatility-auto-hashdump Script for automatic dump and brute-force passwords using Volatility Framework
 11 Apr 11, 2022
11 Apr 11, 2022

Use FOFA automatic vulnerability scanning tool
AutoSRC Use FOFA automatic vulnerability scanning tool Usage python3 autosrc.py -e FOFA EMAIL -k TOKEN Screenshots License MIT Dev 6613GitHub6613
 48 Oct 25, 2022
48 Oct 25, 2022

RetinaFace: Deep Face Detection Library in TensorFlow for Python
RetinaFace is a deep learning based cutting-edge facial detector for Python coming with facial landmarks.
 512 Dec 29, 2022
512 Dec 29, 2022

Spherical Confidence Learning for Face Recognition, accepted to CVPR2021.
Sphere Confidence Face (SCF) This repository contains the PyTorch implementation of Sphere Confidence Face (SCF) proposed in the CVPR2021 paper: Shen
 70 Dec 9, 2022
70 Dec 9, 2022

PyTorch implementation of Densely Connected Time Delay Neural Network
Densely Connected Time Delay Neural Network PyTorch implementation of Densely Connected Time Delay Neural Network (D-TDNN) in our paper "Densely Conne
 64 Oct 11, 2022
64 Oct 11, 2022

NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling @ INTERSPEECH 2021 Accepted
NU-Wave — Official PyTorch Implementation NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling Junhyeok Lee, Seungu Han @ MINDsLab Inc
242 Dec 23, 2022

A fast and lightweight python-based CTC beam search decoder for speech recognition.
pyctcdecode A fast and feature-rich CTC beam search decoder for speech recognition written in Python, providing n-gram (kenlm) language model support
 315 Dec 21, 2022
315 Dec 21, 2022
Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis
MLP Singer Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis. Audio samples are available on our demo page.
 103 Dec 23, 2022
103 Dec 23, 2022
Recognize Handwritten Digits using Deep Learning on the browser itself.
MNIST on the Web An attempt to predict MNIST handwritten digits from my PyTorch model from the browser (client-side) and not from the server, with the
 7 May 28, 2022
7 May 28, 2022

Command Line Text-To-Speech using Google TTS
cli-tts Thanks to gTTS by @pndurette! This is an interactive command line text-to-speech tool using Google TTS. Just type text and the voice will be p
 3 Nov 11, 2022
3 Nov 11, 2022
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022

Official implementation of FCL-taco2: Fast, Controllable and Lightweight version of Tacotron2 @ ICASSP 2021
FCL-Taco2: Towards Fast, Controllable and Lightweight Text-to-Speech synthesis (ICASSP 2021) Paper | Demo Block diagram of FCL-taco2, where the decode
 39 Sep 28, 2022
39 Sep 28, 2022
A toolbox of scene text detection and recognition
FudanOCR This toolbox contains the implementations of the following papers: Scene Text Telescope: Text-Focused Scene Image Super-Resolution [Chen et a
 170 Dec 26, 2022
170 Dec 26, 2022
A trusty face recognition research platform developed by Tencent Youtu Lab
Introduction TFace: A trusty face recognition research platform developed by Tencent Youtu Lab. It provides a high-performance distributed training fr
 956 Jan 1, 2023
956 Jan 1, 2023

Global Filter Networks for Image Classification
Global Filter Networks for Image Classification Created by Yongming Rao, Wenliang Zhao, Zheng Zhu, Jiwen Lu, Jie Zhou This repository contains PyTorch
 273 Dec 26, 2022
273 Dec 26, 2022
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
 93 Dec 17, 2022
93 Dec 17, 2022

PyTorch Implementation of NCSOFT's FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
FastPitchFormant - PyTorch Implementation PyTorch Implementation of FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis. Qu
63 Jan 2, 2023

Code for Two-stage Identifier: "Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition"
Code for Two-stage Identifier: "Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition", accepted at ACL 2021. For details of the model and experiments, please see our paper.
 87 Dec 16, 2022
87 Dec 16, 2022

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
This is a template for the Non-autoregressive Deep Learning-Based TTS model (in PyTorch).
Non-autoregressive Deep Learning-Based TTS Template This is a template for the Non-autoregressive TTS model. It contains Data Preprocessing Pipeline D
13 Dec 5, 2022

Attention mechanism with MNIST dataset
[TensorFlow] Attention mechanism with MNIST dataset Usage $ python run.py Result Training Loss graph. Test Each figure shows input digit, attention ma
 12 Jun 10, 2022
12 Jun 10, 2022
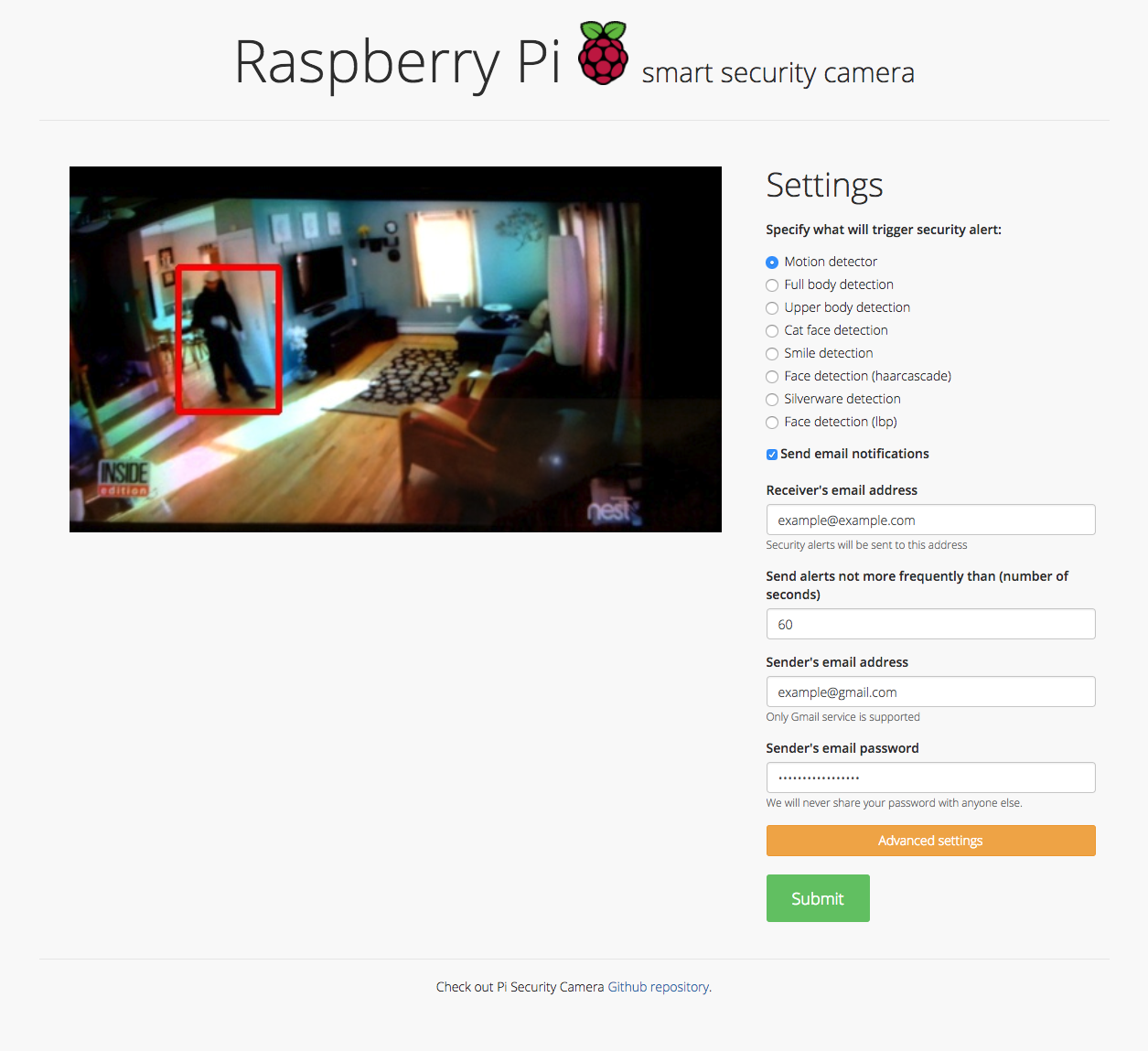
Motion detector, Full body detection, Upper body detection, Cat face detection, Smile detection, Face detection (haar cascade), Silverware detection, Face detection (lbp), and Sending email notifications
Security camera running OpenCV for object and motion detection. The camera will send email with image of any objects it detects. It also runs a server that provides web interface with live stream video.
 10 Jun 30, 2021
10 Jun 30, 2021