1600 Repositories
Python basic-programming-language Libraries
tagls is a language server based on gtags.
tagls tagls is a language server based on gtags. Why I wrote it? Almost all modern editors have great support to LSP, but language servers based on se
 31 Dec 1, 2022
31 Dec 1, 2022
Description Basic Recon tool for beginners. Especially those who faces issue on how to recon or what all tools to use
Description Basic Recon tool for beginners. Especially those who faces issue on how to recon or what all tools to use. Will try to add atleast 10 more tools currently use 7 sources to gather domains.Currenlty uses below mentioned tools and also sort live domains using HttpX.
 7 Jan 3, 2022
7 Jan 3, 2022

🎴 LearnQuick is a flashcard application that you can study with decks and cards.
🎴 LearnQuick is a flashcard application that you can study with decks and cards. The main function of the application is to show the front sides of the created cards to the user and ask them to guess the back of the card. As a result of self-assessment of user's ability to guess the back sides of the displayed cards, the cards that user weak against are shown more often, and the cards that user strong against are shown less frequently.
 7 Aug 21, 2022
7 Aug 21, 2022
Creating low-level foundations and abstractions for asynchronous programming in Python.
DIY Async I/O Creating low-level foundations and abstractions for asynchronous programming in Python (i.e., implementing concurrency without using thr
 4 Dec 11, 2021
4 Dec 11, 2021

Application for shadowing Chinese.
chinese-shadowing Simple APP for shadowing chinese. With this application, it is very easy to record yourself, play the sound recorded and listen to s
 5 Sep 6, 2022
5 Sep 6, 2022

MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving.
MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving. It is a comprehensive framework for research purpose that integrates popular MWP benchmark datasets and typical deep learning-based MWP algorithms.
 119 Jan 4, 2023
119 Jan 4, 2023
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
Basic python tools to generate shellcode runner in vba
vba_bin_runner Basic python tools to generate shellcode runner in vba. The stub use ZwAllocateVirtualMemory to allocate memory, RtlMoveMemory to write
 4 Aug 24, 2021
4 Aug 24, 2021
EMNLP 2021 - Frustratingly Simple Pretraining Alternatives to Masked Language Modeling
Frustratingly Simple Pretraining Alternatives to Masked Language Modeling This is the official implementation for "Frustratingly Simple Pretraining Al
 31 Nov 18, 2022
31 Nov 18, 2022

Türkçe küfürlü içerikleri bulan bir yapay zeka kütüphanesi / An ML library for profanity detection in Turkish sentences
"Kötü söz sahibine aittir." -Anonim Nedir? sinkaf uygunsuz yorumların bulunmasını sağlayan bir python kütüphanesidir. Farkı nedir? Diğer algoritmalard
 4 Feb 18, 2022
4 Feb 18, 2022
Dataloader tools for language modelling
Installation: pip install lm_dataloader Design Philosophy A library to unify lm dataloading at large scale Simple interface, any tokenizer can be inte
 5 Mar 25, 2022
5 Mar 25, 2022

🌈 PyTorch Implementation for EMNLP'21 Findings "Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer"
SGLKT-VisDial Pytorch Implementation for the paper: Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer Gi-Cheon Kang, Junseok P
 9 Jul 5, 2022
9 Jul 5, 2022
EMNLP 2021 Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections
Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections Ruiqi Zhong, Kristy Lee*, Zheng Zhang*, Dan Klein EMN
 42 Nov 3, 2022
42 Nov 3, 2022

An original implementation of "Noisy Channel Language Model Prompting for Few-Shot Text Classification"
Channel LM Prompting (and beyond) This includes an original implementation of Sewon Min, Mike Lewis, Hannaneh Hajishirzi, Luke Zettlemoyer. "Noisy Cha
 92 Jan 7, 2023
92 Jan 7, 2023

Ongoing research training transformer language models at scale, including: BERT & GPT-2
Megatron (1 and 2) is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA.
 3.5k Dec 30, 2022
3.5k Dec 30, 2022

Code for our ALiBi method for transformer language models.
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation This repository contains the code and models for our paper Tra
 211 Dec 31, 2022
211 Dec 31, 2022

CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
 100 Dec 28, 2022
100 Dec 28, 2022
CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
100 Dec 28, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 5, 2023
7.1k Jan 5, 2023
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022
Python library for the DeepL language translation API.
The DeepL API is a language translation API that allows other computer programs to send texts and documents to DeepL's servers and receive high-quality translations. This opens a whole universe of opportunities for developers: any translation product you can imagine can now be built on top of DeepL's best-in-class translation technology.
 535 Jan 4, 2023
535 Jan 4, 2023
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022

A Survey of Natural Language Generation in Task-Oriented Dialogue System (TOD): Recent Advances and New Frontiers
A Survey of Natural Language Generation in Task-Oriented Dialogue System (TOD): Recent Advances and New Frontiers
 132 Nov 25, 2022
132 Nov 25, 2022

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022

Empower Sequence Labeling with Task-Aware Language Model
LM-LSTM-CRF Check Our New NER Toolkit 🚀 🚀 🚀 Inference: LightNER: inference w. models pre-trained / trained w. any following tools, efficiently. Tra
 838 Jan 5, 2023
838 Jan 5, 2023

An almost fully customizable language made in python!
Whython is a project language, the idea of it is that anyone can download and edit the language to make it suitable to what they want.
 47 Nov 5, 2022
47 Nov 5, 2022
DEMix Layers for Modular Language Modeling
DEMix This repository contains modeling utilities for "DEMix Layers: Disentangling Domains for Modular Language Modeling" (Gururangan et. al, 2021). T
 43 Nov 11, 2022
43 Nov 11, 2022
Commodore 64 OS running on Atari 8-bit hardware
This is the Commodre 64 KERNAL, modified to run on the Atari 8-bit line of computers. They're practically the same machine; why didn't someone try this 30 years ago?
 133 Nov 12, 2022
133 Nov 12, 2022
Evaluation suite for large-scale language models.
This repo contains code for running the evaluations and reproducing the results from the Jurassic-1 Technical Paper (see blog post), with current support for running the tasks through both the AI21 Studio API and OpenAI's GPT3 API.
 71 Dec 17, 2022
71 Dec 17, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

Composed Image Retrieval using Pretrained LANguage Transformers (CIRPLANT)
CIRPLANT This repository contains the code and pre-trained models for Composed Image Retrieval using Pretrained LANguage Transformers (CIRPLANT) For d
 29 Nov 17, 2022
29 Nov 17, 2022

Guesslang detects the programming language of a given source code
Detect the programming language of a source code
 618 Dec 29, 2022
618 Dec 29, 2022
The official code for paper "R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Modeling".
R2D2 This is the official code for paper titled "R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Mode
 49 Dec 17, 2022
49 Dec 17, 2022

Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision. ICCV 2021.
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision Download links and PyTorch implementation of "Towers of Ba
 40 Dec 14, 2022
40 Dec 14, 2022
Vision-Language Transformer and Query Generation for Referring Segmentation (ICCV 2021)
Vision-Language Transformer and Query Generation for Referring Segmentation Please consider citing our paper in your publications if the project helps
 143 Dec 23, 2022
143 Dec 23, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022
😇A pyTorch implementation of the DeepMoji model: state-of-the-art deep learning model for analyzing sentiment, emotion, sarcasm etc
------ Update September 2018 ------ It's been a year since TorchMoji and DeepMoji were released. We're trying to understand how it's being used such t
 865 Dec 24, 2022
865 Dec 24, 2022
Ongoing research training transformer language models at scale, including: BERT & GPT-2
What is this fork of Megatron-LM and Megatron-DeepSpeed This is a detached fork of https://github.com/microsoft/Megatron-DeepSpeed, which in itself is
 316 Jan 3, 2023
316 Jan 3, 2023
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
 65 Sep 13, 2022
65 Sep 13, 2022
PyTorch implementation for Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuous Sign Language Recognition.
Stochastic CSLR This is the PyTorch implementation for the ECCV 2020 paper: Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuou
 28 Dec 19, 2022
28 Dec 19, 2022
Source code for "Progressive Transformers for End-to-End Sign Language Production" (ECCV 2020)
Progressive Transformers for End-to-End Sign Language Production Source code for "Progressive Transformers for End-to-End Sign Language Production" (B
 58 Dec 21, 2022
58 Dec 21, 2022
Sign Language Translation with Transformers (COLING'2020, ECCV'20 SLRTP Workshop)
transformer-slt This repository gathers data and code supporting the experiments in the paper Better Sign Language Translation with STMC-Transformer.
 107 Dec 27, 2022
107 Dec 27, 2022
Sign Language Transformers (CVPR'20)
Sign Language Transformers (CVPR'20) This repo contains the training and evaluation code for the paper Sign Language Transformers: Sign Language Trans
 164 Dec 30, 2022
164 Dec 30, 2022
Code for the paper "VisualBERT: A Simple and Performant Baseline for Vision and Language"
This repository contains code for the following two papers: VisualBERT: A Simple and Performant Baseline for Vision and Language (arxiv) with a short
 463 Dec 9, 2022
463 Dec 9, 2022
Multi Task Vision and Language
12-in-1: Multi-Task Vision and Language Representation Learning Please cite the following if you use this code. Code and pre-trained models for 12-in-
 712 Dec 19, 2022
712 Dec 19, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023

VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
VisualGPT Our Paper VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning Main Architecture of Our VisualGPT Downloa
 140 Dec 28, 2022
140 Dec 28, 2022

The RWKV Language Model
RWKV-LM We propose the RWKV language model, with alternating time-mix and channel-mix layers: The R, K, V are generated by linear transforms of input,
 877 Jan 5, 2023
877 Jan 5, 2023
Export solved codewars kata challenges to a text file.
Codewars Kata Exporter Note:this is not totally my work.i've edited the project to make more easier and faster for me.you can find the original work h
 4 Aug 13, 2021
4 Aug 13, 2021

Sum-Product Probabilistic Language
Sum-Product Probabilistic Language SPPL is a probabilistic programming language that delivers exact solutions to a broad range of probabilistic infere
 57 Nov 17, 2022
57 Nov 17, 2022
This tool ability to analyze software packages of different programming languages that are being or will be used in their codes, providing information that allows them to know in advance if this library complies with processes.
This tool gives developers, researchers and companies the ability to analyze software packages of different programming languages that are being or will be used in their codes, providing information that allows them to know in advance if this library complies with processes. secure development, if currently supported, possible backdoors (malicious embedded code), typosquatting analysis, the history of versions and reported vulnerabilities (CVEs) of the package.
 66 Nov 8, 2022
66 Nov 8, 2022
API for the GPT-J language model 🦜. Including a FastAPI backend and a streamlit frontend
gpt-j-api 🦜 An API to interact with the GPT-J language model. You can use and test the model in two different ways: Streamlit web app at http://api.v
 276 Dec 31, 2022
276 Dec 31, 2022
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022

Benchmark for evaluating open-ended generation
OpenMEVA Contributed by Jian Guan, Zhexin Zhang. Thank Jiaxin Wen for DeBugging. OpenMEVA is a benchmark for evaluating open-ended story generation me
 25 Nov 15, 2022
25 Nov 15, 2022

Data and Code for ACL 2021 Paper "Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning"
Introduction Code and data for ACL 2021 Paper "Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning". We cons
 81 Dec 27, 2022
81 Dec 27, 2022
Code Repo for the ACL21 paper "Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning"
Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning This is the Github repository of our paper, "Common S
 19 Nov 30, 2022
19 Nov 30, 2022
Versatile Generative Language Model
Versatile Generative Language Model This is the implementation of the paper: Exploring Versatile Generative Language Model Via Parameter-Efficient Tra
 17 Dec 2, 2022
17 Dec 2, 2022
Implementation of EMNLP 2017 Paper "Natural Language Does Not Emerge 'Naturally' in Multi-Agent Dialog" using PyTorch and ParlAI
Language Emergence in Multi Agent Dialog Code for the Paper Natural Language Does Not Emerge 'Naturally' in Multi-Agent Dialog Satwik Kottur, José M.
 105 Nov 25, 2022
105 Nov 25, 2022
KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark.
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022

basic tutorial on pytorch
Quick Tutorial on PyTorch PyTorch Basics Linear Regression Logistic Regression Artificial Neural Networks Convolutional Neural Networks Recurrent Neur
 7 Sep 15, 2022
7 Sep 15, 2022

MASS: Masked Sequence to Sequence Pre-training for Language Generation
MASS: Masked Sequence to Sequence Pre-training for Language Generation
 1.1k Dec 17, 2022
1.1k Dec 17, 2022
Active learning for text classification in Python
Active Learning allows you to efficiently label training data in a small-data scenario.
 375 Dec 28, 2022
375 Dec 28, 2022
GlokyPortScannar is a really fast tool to scan TCP ports implemented in Python.
GlokyPortScannar is a really fast tool to scan TCP ports implemented in Python. Installation: This program requires Python 3.9. Linux
 5 Jun 25, 2022
5 Jun 25, 2022

meProp: Sparsified Back Propagation for Accelerated Deep Learning
meProp The codes were used for the paper meProp: Sparsified Back Propagation for Accelerated Deep Learning with Reduced Overfitting (ICML 2017) [pdf]
 107 Nov 18, 2022
107 Nov 18, 2022

Train an RL agent to execute natural language instructions in a 3D Environment (PyTorch)
Gated-Attention Architectures for Task-Oriented Language Grounding This is a PyTorch implementation of the AAAI-18 paper: Gated-Attention Architecture
 234 Nov 5, 2022
234 Nov 5, 2022

🐥A PyTorch implementation of OpenAI's finetuned transformer language model with a script to import the weights pre-trained by OpenAI
PyTorch implementation of OpenAI's Finetuned Transformer Language Model This is a PyTorch implementation of the TensorFlow code provided with OpenAI's
1.4k Jan 5, 2023
UdemyBot - A Simple Udemy Free Courses Scrapper
UdemyBot - A Simple Udemy Free Courses Scrapper
 112 Nov 12, 2022
112 Nov 12, 2022

NLPShala , the best IDE for all Natural language processing tasks.
The revolutionary IDE for all NLP (Natural language processing) stuffs on the internet.
 3 Aug 8, 2021
3 Aug 8, 2021
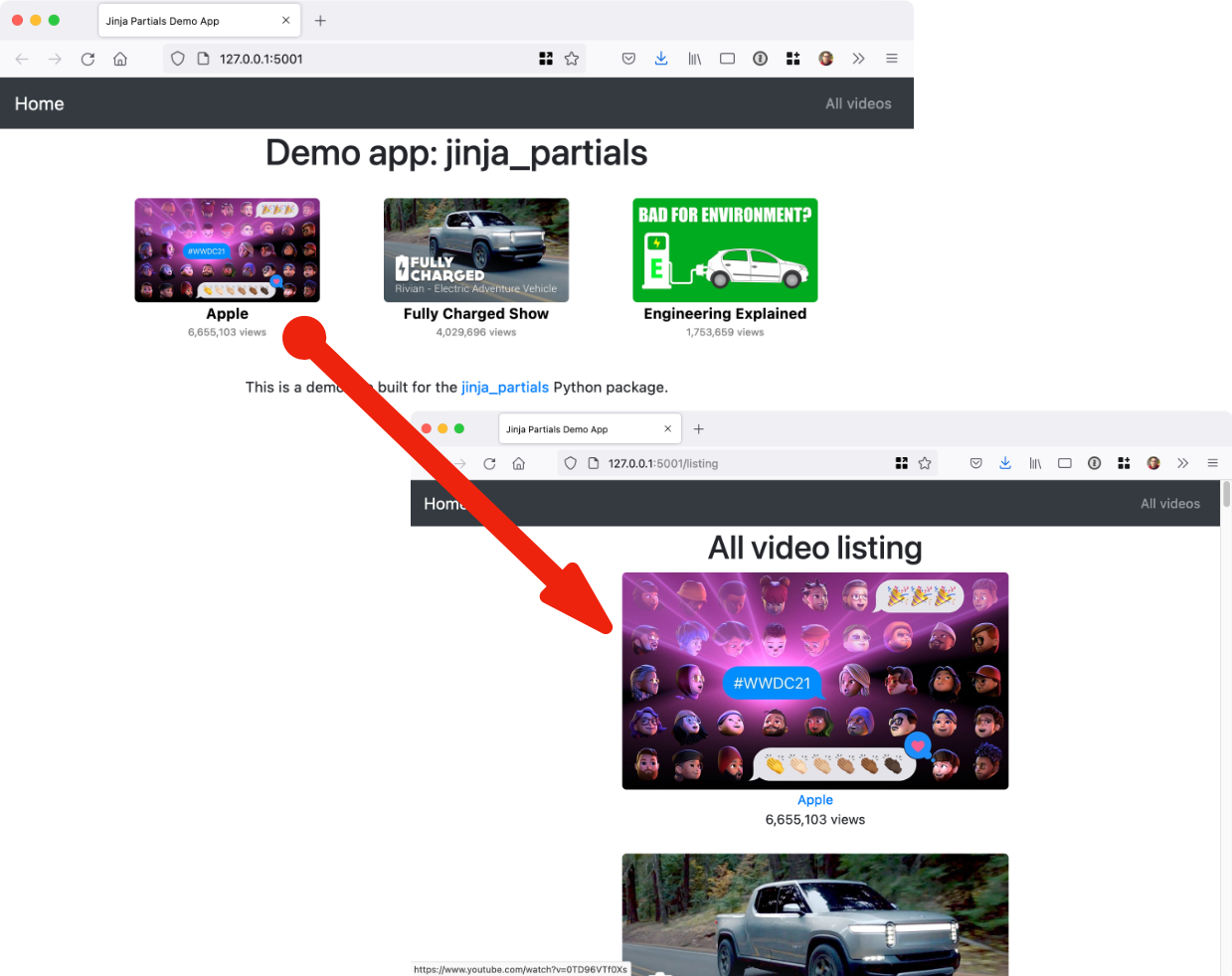
Simple reuse of partial HTML page templates in the Jinja template language for Python web frameworks.
Jinja Partials Simple reuse of partial HTML page templates in the Jinja template language for Python web frameworks. (There is also a Pyramid/Chameleo
 106 Dec 28, 2022
106 Dec 28, 2022
GPT-Code-Clippy (GPT-CC) is an open source version of GitHub Copilot, a language model
GPT-Code-Clippy (GPT-CC) is an open source version of GitHub Copilot, a language model -- based on GPT-3, called GPT-Codex -- that is fine-tuned on publicly available code from GitHub.
 2.3k Jan 1, 2023
2.3k Jan 1, 2023

Learned Token Pruning for Transformers
LTP: Learned Token Pruning for Transformers Check our paper for more details. Installation We follow the same installation procedure as the original H
 52 Dec 29, 2022
52 Dec 29, 2022
Deduplicating Training Data Makes Language Models Better
Deduplicating Training Data Makes Language Models Better This repository contains code to deduplicate language model datasets as descrbed in the paper
 431 Dec 27, 2022
431 Dec 27, 2022
[ICML 2021] Towards Understanding and Mitigating Social Biases in Language Models
Towards Understanding and Mitigating Social Biases in Language Models This repo contains code and data for evaluating and mitigating bias from generat
 42 Jan 3, 2023
42 Jan 3, 2023
QVHighlights: Detecting Moments and Highlights in Videos via Natural Language Queries
Moment-DETR QVHighlights: Detecting Moments and Highlights in Videos via Natural Language Queries Jie Lei, Tamara L. Berg, Mohit Bansal For dataset de
 133 Dec 22, 2022
133 Dec 22, 2022

A text augmentation tool for named entity recognition.
neraug This python library helps you with augmenting text data for named entity recognition. Augmentation Example Reference from An Analysis of Simple
 48 Oct 11, 2022
48 Oct 11, 2022

Rubrix is a free and open-source tool for exploring and iterating on data for artificial intelligence projects.
Open-source tool for exploring, labeling, and monitoring data for AI projects
1.5k Jan 7, 2023

An implementation of DeepMind's Relational Recurrent Neural Networks in PyTorch.
relational-rnn-pytorch An implementation of DeepMind's Relational Recurrent Neural Networks (Santoro et al. 2018) in PyTorch. Relational Memory Core (
 241 Nov 18, 2022
241 Nov 18, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022

The Noise Contrastive Estimation for softmax output written in Pytorch
An NCE implementation in pytorch About NCE Noise Contrastive Estimation (NCE) is an approximation method that is used to work around the huge computat
 287 Nov 25, 2022
287 Nov 25, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
77.2k Jan 3, 2023
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context This repository contains the code in both PyTorch and TensorFlow for our paper
 3.3k Dec 28, 2022
3.3k Dec 28, 2022

Implementation of character based convolutional neural network
Character Based CNN This repo contains a PyTorch implementation of a character-level convolutional neural network for text classification. The model a
 248 Nov 21, 2022
248 Nov 21, 2022
PyTorch original implementation of Cross-lingual Language Model Pretraining.
XLM NEW: Added XLM-R model. PyTorch original implementation of Cross-lingual Language Model Pretraining. Includes: Monolingual language model pretrain
2.7k Dec 27, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023
Pyomo is an object-oriented algebraic modeling language in Python for structured optimization problems.
Pyomo is a Python-based open-source software package that supports a diverse set of optimization capabilities for formulating and analyzing optimization models. Pyomo can be used to define symbolic problems, create concrete problem instances, and solve these instances with standard solvers.
 1.4k Dec 28, 2022
1.4k Dec 28, 2022

Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
This is the official PyTorch implementation of the ALBEF paper [Blog]. This repository supports pre-training on custom datasets, as well as finetuning on VQA, SNLI-VE, NLVR2, Image-Text Retrieval on MSCOCO and Flickr30k, and visual grounding on RefCOCO+. Pre-trained and finetuned checkpoints are released.
 805 Jan 9, 2023
805 Jan 9, 2023

RoBERTa Marathi Language model trained from scratch during huggingface 🤗 x flax community week
RoBERTa base model for Marathi Language (मराठी भाषा) Pretrained model on Marathi language using a masked language modeling (MLM) objective. RoBERTa wa
 23 Oct 19, 2022
23 Oct 19, 2022
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
 203 Dec 20, 2022
203 Dec 20, 2022

Analyzing basic network responses to novel classes
novelty-detection Analyzing how AlexNet responds to novel classes with varying degrees of similarity to pretrained classes from ImageNet. If you find
 34 Oct 2, 2022
34 Oct 2, 2022

A heterogeneous entity-augmented academic language model based on Open Academic Graph (OAG)
Library | Paper | Slack We released two versions of OAG-BERT in CogDL package. OAG-BERT is a heterogeneous entity-augmented academic language model wh
 58 Dec 17, 2022
58 Dec 17, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 43 Nov 21, 2022
43 Nov 21, 2022
Measuring and Improving Consistency in Pretrained Language Models
ParaRel 🤘 This repository contains the code and data for the paper: Measuring and Improving Consistency in Pretrained Language Models as well as the
 26 Dec 2, 2022
26 Dec 2, 2022
A very basic esp32-based logic analyzer capable of sampling digital signals at up to ~3.2MHz.
A very basic esp32-based logic analyzer capable of sampling digital signals at up to ~3.2MHz.
 43 Dec 27, 2022
43 Dec 27, 2022
Write Python in Urdu - اردو میں کوڈ لکھیں
UrduPython Write simple Python in Urdu. How to Use Write Urdu code in سامپل۔پے The mappings are as following: "۔": ".", "،":
 26 Nov 27, 2022
26 Nov 27, 2022
 17 Jan 9, 2022
17 Jan 9, 2022