482 Repositories
Python benchmark-datasets Libraries
The first online catalogue for Arabic NLP datasets.
Masader The first online catalogue for Arabic NLP datasets. This catalogue contains 200 datasets with more than 25 metadata annotations for each datas
 94 Dec 26, 2022
94 Dec 26, 2022
Repository for the Bias Benchmark for QA dataset.
BBQ Repository for the Bias Benchmark for QA dataset. Authors: Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Tho
 18 Nov 18, 2022
18 Nov 18, 2022
Benchmark datasets, data loaders, and evaluators for graph machine learning
Overview The Open Graph Benchmark (OGB) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Datasets cover
 1.5k Jan 5, 2023
1.5k Jan 5, 2023

Repository for benchmarking graph neural networks
Benchmarking Graph Neural Networks Updates Nov 2, 2020 Project based on DGL 0.4.2. See the relevant dependencies defined in the environment yml files
 2k Jan 3, 2023
2k Jan 3, 2023

PyTorch implementation of paper “Unbiased Scene Graph Generation from Biased Training”
A new codebase for popular Scene Graph Generation methods (2020). Visualization & Scene Graph Extraction on custom images/datasets are provided. It's also a PyTorch implementation of paper “Unbiased Scene Graph Generation from Biased Training CVPR 2020”
 824 Jan 3, 2023
824 Jan 3, 2023
Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers.
ConditionalQA Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers. Disclaimer This dataset
 2 Oct 14, 2021
2 Oct 14, 2021
The self-supervised goal reaching benchmark introduced in Discovering and Achieving Goals via World Models
Lexa-Benchmark Codebase for the self-supervised goal reaching benchmark introduced in 'Discovering and Achieving Goals via World Models'. Setup Create
 1 Oct 14, 2021
1 Oct 14, 2021
Python Package for DataHerb: create, search, and load datasets.
The Python Package for DataHerb A DataHerb Core Service to Create and Load Datasets.
 4 Feb 11, 2022
4 Feb 11, 2022
HyperSpy is an open source Python library for the interactive analysis of multidimensional datasets
HyperSpy is an open source Python library for the interactive analysis of multidimensional datasets that can be described as multidimensional arrays o
 411 Dec 27, 2022
411 Dec 27, 2022
ImageNet-CoG is a benchmark for concept generalization. It provides a full evaluation framework for pre-trained visual representations which measure how well they generalize to unseen concepts.
The ImageNet-CoG Benchmark Project Website Paper (arXiv) Code repository for the ImageNet-CoG Benchmark introduced in the paper "Concept Generalizatio
 23 Oct 9, 2022
23 Oct 9, 2022
This repository contains all data used for writing a research paper Multiple Object Trackers in OpenCV: A Benchmark, presented in ISIE 2021 conference in Kyoto, Japan.
OpenCV-Multiple-Object-Tracking Python is version 3.6.7 to install opencv: pip uninstall opecv-python pip uninstall opencv-contrib-python pip install
 6 Dec 19, 2021
6 Dec 19, 2021
New approach to benchmark VQA models
VQA Benchmarking This repository contains the web application & the python interface to evaluate VQA models. Documentation Please see the documentatio
 4 Jul 25, 2022
4 Jul 25, 2022
Python suite to construct benchmark machine learning datasets from the MIMIC-III clinical database.
MIMIC-III Benchmarks Python suite to construct benchmark machine learning datasets from the MIMIC-III clinical database. Currently, the benchmark data
 6 Jan 2, 2023
6 Jan 2, 2023
Starter Code for VALUE benchmark
StarterCode for VALUE Benchmark This is the starter code for VALUE Benchmark [website], [paper]. This repository currently supports all baseline model
 73 Dec 9, 2022
73 Dec 9, 2022
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation (NeurIPS2021 Benchmark and Dataset Track)
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation by Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zh
 174 Dec 22, 2022
174 Dec 22, 2022
Official code of paper: MovingFashion: a Benchmark for the Video-to-Shop Challenge
SEAM Match-RCNN Official code of MovingFashion: a Benchmark for the Video-to-Shop Challenge paper Installation Requirements: Pytorch 1.5.1 or more rec
 31 Oct 10, 2022
31 Oct 10, 2022
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English ⚖️ 🏆 🧑🎓 👩⚖️ Dataset Summary Inspired by the recent widespread use of th
 95 Dec 8, 2022
95 Dec 8, 2022

ProFuzzBench - A Benchmark for Stateful Protocol Fuzzing
ProFuzzBench - A Benchmark for Stateful Protocol Fuzzing ProFuzzBench is a benchmark for stateful fuzzing of network protocols. It includes a suite of
 155 Jan 8, 2023
155 Jan 8, 2023
A set of examples around hub for creating and processing datasets
Examples for Hub - Dataset Format for AI A repository showcasing examples of using Hub Uploading Dataset Places365 Colab Tutorials Notebook Link Getti
 11 Dec 14, 2022
11 Dec 14, 2022
TorchXRayVision: A library of chest X-ray datasets and models.
torchxrayvision A library for chest X-ray datasets and models. Including pre-trained models. ( 🎬 promo video about the project) Motivation: While the
 575 Jan 8, 2023
575 Jan 8, 2023

Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E. Evaluated on benchmark dataset Office31.
Deep-Unsupervised-Domain-Adaptation Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E.
 49 Dec 20, 2022
49 Dec 20, 2022

Benchmark a WebSocket server's message throughput ⌛
📻 WebSocket Benchmarker ⌚ Message throughput is how fast a WebSocket server can parse and respond to a message. Some people consider this to be a goo
 24 Nov 17, 2022
24 Nov 17, 2022

A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You can find two approaches for achieving this in this repo.
multitask-learning-transformers A simple recipe for training and inferencing Transformer architecture for Multi-Task Learning on custom datasets. You
 48 Jan 2, 2023
48 Jan 2, 2023

C++ Implementation of PyTorch Tutorials for Everyone
C++ Implementation of PyTorch Tutorials for Everyone OS (Compiler)\LibTorch 1.9.0 macOS (clang 10.0, 11.0, 12.0) Linux (gcc 8, 9, 10, 11) Windows (msv
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022
Create Fast and easy image datasets using reddit
Reddit-Image-Scraper Reddit Reddit is an American Social news aggregation, web content rating, and discussion website. Reddit has been devided by topi
 4 Apr 27, 2022
4 Apr 27, 2022

Benchmark for Answering Existential First Order Queries with Single Free Variable
EFO-1-QA Benchmark for First Order Query Estimation on Knowledge Graphs This repository contains an entire pipeline for the EFO-1-QA benchmark. EFO-1
 14 Oct 24, 2022
14 Oct 24, 2022

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Official code for 'Robust Siamese Object Tracking for Unmanned Aerial Manipulator' and offical introduction to UAMT100 benchmark
SiamSA: Robust Siamese Object Tracking for Unmanned Aerial Manipulator Demo video 📹 Our video on Youtube and bilibili demonstrates the evaluation of
 12 Dec 18, 2022
12 Dec 18, 2022
wireguard-config-benchmark is a python script that benchmarks the download speeds for the connections defined in one or more wireguard config files
wireguard-config-benchmark is a python script that benchmarks the download speeds for the connections defined in one or more wireguard config files. If multiple configs are benchmarked it will output a file ranking them from fastest to slowest.
 12 May 7, 2022
12 May 7, 2022

The tool to make NLP datasets ready to use
chazutsu photo from Kaikado, traditional Japanese chazutsu maker chazutsu is the dataset downloader for NLP. import chazutsu r = chazutsu.data
 243 Dec 29, 2022
243 Dec 29, 2022
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
 138 Jan 3, 2023
138 Jan 3, 2023

This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking".
SCT This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking" The spatial-channel Transformer (SCT) enhan
27 Nov 23, 2022

Phy-Q: A Benchmark for Physical Reasoning
Phy-Q: A Benchmark for Physical Reasoning Cheng Xue*, Vimukthini Pinto*, Chathura Gamage* Ekaterina Nikonova, Peng Zhang, Jochen Renz School of Comput
 29 Dec 19, 2022
29 Dec 19, 2022
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless.
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless. This is the official Roboflow python package that interfaces with the Roboflow API.
 52 Dec 23, 2022
52 Dec 23, 2022

My published benchmark for a Kaggle Simulations Competition
Lux AI Working Title Bot Please refer to the Kaggle notebook for the comment section. The comment section contains my explanation on my code structure
 29 Aug 22, 2022
29 Aug 22, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation". It is intended to be used for normalizing / cleaning Bengali and English text.
normalizer This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch
23 Nov 30, 2022
An easy way to build PyTorch datasets. Modularly build datasets and automatically cache processed results
EasyDatas An easy way to build PyTorch datasets. Modularly build datasets and automatically cache processed results Installation pip install git+https
 4 Dec 14, 2021
4 Dec 14, 2021
Model Quantization Benchmark
MQBench Update V0.0.2 Fix academic prepare setting. More deployable prepare process. Fix setup.py. Fix deploy on SNPE. Fix convert_deploy bug. Add Qua
 500 Jan 6, 2023
500 Jan 6, 2023

TorchIO is a Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
 1.6k Jan 6, 2023
1.6k Jan 6, 2023

OpenCVのGrabCut()を利用したセマンティックセグメンテーション向けアノテーションツール(Annotation tool using GrabCut() of OpenCV. It can be used to create datasets for semantic segmentation.)
[Japanese/English] GrabCut-Annotation-Tool GrabCut-Annotation-Tool.mp4 OpenCVのGrabCut()を利用したアノテーションツールです。 セマンティックセグメンテーション向けのデータセット作成にご使用いただけます。 ※Grab
 30 Nov 18, 2022
30 Nov 18, 2022

Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
 91 Nov 22, 2022
91 Nov 22, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022

A novel benchmark dataset for Monocular Layout prediction
AutoLay AutoLay: Benchmarking Monocular Layout Estimation Kaustubh Mani, N. Sai Shankar, J. Krishna Murthy, and K. Madhava Krishna Abstract In this pa
 39 Apr 26, 2022
39 Apr 26, 2022
CPU benchmark by calculating Pi, powered by Python3
cpu-benchmark Info: CPU benchmark by calculating Pi, powered by Python 3. Algorithm The program calculates pi with an accuracy of 10,000 decimal place
 20 Jan 3, 2023
20 Jan 3, 2023
The official repository for our paper "The Devil is in the Detail: Simple Tricks Improve Systematic Generalization of Transformers". We significantly improve the systematic generalization of transformer models on a variety of datasets using simple tricks and careful considerations.
Codebase for training transformers on systematic generalization datasets. The official repository for our EMNLP 2021 paper The Devil is in the Detail:
 57 Nov 21, 2022
57 Nov 21, 2022
The CLRS Algorithmic Reasoning Benchmark
Learning representations of algorithms is an emerging area of machine learning, seeking to bridge concepts from neural networks with classical algorithms.
 251 Jan 5, 2023
251 Jan 5, 2023
CARLA: A Python Library to Benchmark Algorithmic Recourse and Counterfactual Explanation Algorithms
CARLA - Counterfactual And Recourse Library CARLA is a python library to benchmark counterfactual explanation and recourse models. It comes out-of-the
 200 Dec 28, 2022
200 Dec 28, 2022
GraphGT: Machine Learning Datasets for Graph Generation and Transformation
GraphGT: Machine Learning Datasets for Graph Generation and Transformation Dataset Website | Paper Installation Using pip To install the core environm
 50 Aug 18, 2022
50 Aug 18, 2022
Base pretrained models and datasets in pytorch (MNIST, SVHN, CIFAR10, CIFAR100, STL10, AlexNet, VGG16, VGG19, ResNet, Inception, SqueezeNet)
This is a playground for pytorch beginners, which contains predefined models on popular dataset. Currently we support mnist, svhn cifar10, cifar100 st
 2.4k Dec 28, 2022
2.4k Dec 28, 2022
Minimal But Practical Image Classifier Pipline Using Pytorch, Finetune on ResNet18, Got 99% Accuracy on Own Small Datasets.
PyTorch Image Classifier Updates As for many users request, I released a new version of standared pytorch immage classification example at here: http:
 106 Nov 6, 2022
106 Nov 6, 2022
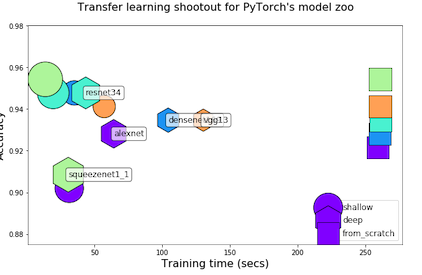
Transfer Learning Shootout for PyTorch's model zoo (torchvision)
pytorch-retraining Transfer Learning shootout for PyTorch's model zoo (torchvision). Load any pretrained model with custom final layer (num_classes) f
 169 Jun 29, 2022
169 Jun 29, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
176 Dec 28, 2022
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023
![[Preprint]](https://github.com/VITA-Group/Deep_GCN_Benchmarking/raw/main/figs/combo.png)
[Preprint] "Bag of Tricks for Training Deeper Graph Neural Networks A Comprehensive Benchmark Study" by Tianlong Chen*, Kaixiong Zhou*, Keyu Duan, Wenqing Zheng, Peihao Wang, Xia Hu, Zhangyang Wang
Bag of Tricks for Training Deeper Graph Neural Networks: A Comprehensive Benchmark Study Codes for [Preprint] Bag of Tricks for Training Deeper Graph
 101 Dec 29, 2022
101 Dec 29, 2022
Pip-package for trajectory benchmarking from "Be your own Benchmark: No-Reference Trajectory Metric on Registered Point Clouds", ECMR'21
Map Metrics for Trajectory Quality Map metrics toolkit provides a set of metrics to quantitatively evaluate trajectory quality via estimating consiste
 31 Oct 28, 2022
31 Oct 28, 2022

HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021)
Code for HDR Video Reconstruction HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021) Guanying Chen, Cha
 64 Nov 19, 2022
64 Nov 19, 2022

We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.
An Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering Papers with code | Paper Nikola Zubić Pietro Lio University
 213 Dec 27, 2022
213 Dec 27, 2022

FedScale: Benchmarking Model and System Performance of Federated Learning
FedScale: Benchmarking Model and System Performance of Federated Learning (Paper) This repository contains scripts and instructions of building FedSca
 268 Jan 1, 2023
268 Jan 1, 2023

ALFRED - A Benchmark for Interpreting Grounded Instructions for Everyday Tasks
ALFRED A Benchmark for Interpreting Grounded Instructions for Everyday Tasks Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han,
 204 Dec 15, 2022
204 Dec 15, 2022
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark We propose a benchmark to evaluate different quantization algorithms on vari
494 Dec 29, 2022

Codes for processing meeting summarization datasets AMI and ICSI.
Meeting Summarization Dataset Meeting plays an essential part in our daily life, which allows us to share information and collaborate with others. Wit
 39 Dec 14, 2022
39 Dec 14, 2022
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering
Disfl-QA is a targeted dataset for contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages. Disfl-QA builds upon the SQuAD-v2 (Rajpurkar et al., 2018) dataset, where each question in the dev set is annotated to add a contextual disfluency using the paragraph as a source of distractors.
 52 Jun 21, 2022
52 Jun 21, 2022
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022

Benchmark for evaluating open-ended generation
OpenMEVA Contributed by Jian Guan, Zhexin Zhang. Thank Jiaxin Wen for DeBugging. OpenMEVA is a benchmark for evaluating open-ended story generation me
 25 Nov 15, 2022
25 Nov 15, 2022
ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge (ManiSkill Challenge), a large-scale learning-from-demonstrations benchmark for object manipulation.
ManiSkill-Learn ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge, a large-scale learning-from-dem
 48 Dec 30, 2022
48 Dec 30, 2022
Code Repo for the ACL21 paper "Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning"
Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning This is the Github repository of our paper, "Common S
 19 Nov 30, 2022
19 Nov 30, 2022
![[IJCAI'21] Deep Automatic Natural Image Matting](https://github.com/JizhiziLi/AIM/raw/master/demo/network.png)
[IJCAI'21] Deep Automatic Natural Image Matting
Deep Automatic Natural Image Matting [IJCAI-21] This is the official repository of the paper Deep Automatic Natural Image Matting. Introduction | Netw
 316 Jan 6, 2023
316 Jan 6, 2023
KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark.
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022

SAPIEN Manipulation Skill Benchmark
ManiSkill Benchmark SAPIEN Manipulation Skill Benchmark (abbreviated as ManiSkill, pronounced as "Many Skill") is a large-scale learning-from-demonstr
107 Jan 8, 2023
A curated list of amazingly awesome Cybersecurity datasets
A curated list of amazingly awesome Cybersecurity datasets
 758 Dec 28, 2022
758 Dec 28, 2022

PyTorch implementation of popular datasets and models in remote sensing
PyTorch Remote Sensing (torchrs) (WIP) PyTorch implementation of popular datasets and models in remote sensing tasks (Change Detection, Image Super Re
 222 Dec 28, 2022
222 Dec 28, 2022
Few-shot NLP benchmark for unified, rigorous eval
FLEX FLEX is a benchmark and framework for unified, rigorous few-shot NLP evaluation. FLEX enables: First-class NLP support Support for meta-training
 85 Dec 3, 2022
85 Dec 3, 2022
![[IJCAI-2021] A benchmark of data-free knowledge distillation from paper](https://github.com/zju-vipa/DataFree/raw/main/assets/cmi.png)
[IJCAI-2021] A benchmark of data-free knowledge distillation from paper "Contrastive Model Inversion for Data-Free Knowledge Distillation"
DataFree A benchmark of data-free knowledge distillation from paper "Contrastive Model Inversion for Data-Free Knowledge Distillation" Authors: Gongfa
 47 Jan 9, 2023
47 Jan 9, 2023
Deduplicating Training Data Makes Language Models Better
Deduplicating Training Data Makes Language Models Better This repository contains code to deduplicate language model datasets as descrbed in the paper
 431 Dec 27, 2022
431 Dec 27, 2022
An open-access benchmark and toolbox for electricity price forecasting
epftoolbox The epftoolbox is the first open-access library for driving research in electricity price forecasting. Its main goal is to make available a
 97 Dec 5, 2022
97 Dec 5, 2022
MVP Benchmark for Multi-View Partial Point Cloud Completion and Registration
MVP Benchmark: Multi-View Partial Point Clouds for Completion and Registration [NEWS] 2021-07-12 [NEW 🎉 ] The submission on Codalab starts! 2021-07-1
 93 Dec 21, 2022
93 Dec 21, 2022

Official PyTorch implementation of "Rapid Neural Architecture Search by Learning to Generate Graphs from Datasets" (ICLR 2021)
Rapid Neural Architecture Search by Learning to Generate Graphs from Datasets This is the official PyTorch implementation for the paper Rapid Neural A
 48 Dec 26, 2022
48 Dec 26, 2022

Project page for the paper Semi-Supervised Raw-to-Raw Mapping 2021.
Project page for the paper Semi-Supervised Raw-to-Raw Mapping 2021.
 22 Nov 8, 2022
22 Nov 8, 2022
A Pytorch implementation of CVPR 2021 paper "RSG: A Simple but Effective Module for Learning Imbalanced Datasets"
RSG: A Simple but Effective Module for Learning Imbalanced Datasets (CVPR 2021) A Pytorch implementation of our CVPR 2021 paper "RSG: A Simple but Eff
 120 Dec 12, 2022
120 Dec 12, 2022
Generic Event Boundary Detection: A Benchmark for Event Segmentation
Generic Event Boundary Detection: A Benchmark for Event Segmentation We release our data annotation & baseline codes for detecting generic event bound
 47 Nov 22, 2022
47 Nov 22, 2022

Meerkat provides fast and flexible data structures for working with complex machine learning datasets.
Meerkat makes it easier for ML practitioners to interact with high-dimensional, multi-modal data. It provides simple abstractions for data inspection, model evaluation and model training supported by efficient and robust IO under the hood.
 115 Dec 12, 2022
115 Dec 12, 2022

Official Implement of CVPR 2021 paper “Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting”
RGBT Crowd Counting Lingbo Liu, Jiaqi Chen, Hefeng Wu, Guanbin Li, Chenglong Li, Liang Lin. "Cross-Modal Collaborative Representation Learning and a L
 37 Dec 8, 2022
37 Dec 8, 2022

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022
Preprocessed Datasets for our Multimodal NER paper
Unified Multimodal Transformer (UMT) for Multimodal Named Entity Recognition (MNER) Two MNER Datasets and Codes for our ACL'2020 paper: Improving Mult
 76 Dec 21, 2022
76 Dec 21, 2022

Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020)
GraspNet Baseline Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020). [paper] [dataset] [API] [do
 209 Dec 29, 2022
209 Dec 29, 2022

NAS Benchmark in "Prioritized Architecture Sampling with Monto-Carlo Tree Search", CVPR2021
NAS-Bench-Macro This repository includes the benchmark and code for NAS-Bench-Macro in paper "Prioritized Architecture Sampling with Monto-Carlo Tree
 35 Jan 3, 2023
35 Jan 3, 2023
Code and datasets for our paper "PTR: Prompt Tuning with Rules for Text Classification"
PTR Code and datasets for our paper "PTR: Prompt Tuning with Rules for Text Classification" If you use the code, please cite the following paper: @art
 118 Dec 30, 2022
118 Dec 30, 2022

Official PyTorch code for CVPR 2020 paper "Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision"
Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision https://arxiv.org/abs/2003.00393 Abstract Active learning (AL) aims to min
 29 Nov 21, 2022
29 Nov 21, 2022

A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/casual, active/passive, and many more. Created by Prithiviraj Damodaran. Open to pull requests and other forms of collaboration.
Styleformer A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/cas
 431 Dec 19, 2022
431 Dec 19, 2022

modelvshuman is a Python library to benchmark the gap between human and machine vision
modelvshuman is a Python library to benchmark the gap between human and machine vision. Using this library, both PyTorch and TensorFlow models can be evaluated on 17 out-of-distribution datasets with high-quality human comparison data.
 244 Jan 3, 2023
244 Jan 3, 2023
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022

3D AffordanceNet is a 3D point cloud benchmark consisting of 23k shapes from 23 semantic object categories, annotated with 56k affordance annotations and covering 18 visual affordance categories.
3D AffordanceNet This repository is the official experiment implementation of 3D AffordanceNet benchmark. 3D AffordanceNet is a 3D point cloud benchma
 49 Dec 1, 2022
49 Dec 1, 2022

The toolkit to generate auto labeled datasets
Ozeu Ozeu is the toolkit to autolabal dataset for instance segmentation. You can generate datasets labaled with segmentation mask and bounding box fro
 28 Mar 28, 2022
28 Mar 28, 2022
Datasets of Automatic Keyphrase Extraction
This repository contains 20 annotated datasets of Automatic Keyphrase Extraction made available by the research community. Following are the datasets and the original papers that proposed them. If you know more datasets, and want to contribute, please, notify me.
 163 Dec 23, 2022
163 Dec 23, 2022
A list of hyperspectral image super-solution resources collected by Junjun Jiang
A list of hyperspectral image super-resolution resources collected by Junjun Jiang. If you find that important resources are not included, please feel free to contact me.
 301 Jan 5, 2023
301 Jan 5, 2023
This repository contains the implementations related to the experiments of a set of publicly available datasets that are used in the time series forecasting research space.
TSForecasting This repository contains the implementations related to the experiments of a set of publicly available datasets that are used in the tim
 80 Dec 30, 2022
80 Dec 30, 2022