118 Repositories
Python chinese-fonts Libraries

🚀 RocketQA, dense retrieval for information retrieval and question answering, including both Chinese and English state-of-the-art models.
In recent years, the dense retrievers based on pre-trained language models have achieved remarkable progress. To facilitate more developers using cutt
 475 Jan 4, 2023
475 Jan 4, 2023

Gba-free-fonts - Free font resources for GBA game development
gba-free-fonts Free font resources for GBA game development This repo contains m
 28 Dec 30, 2022
28 Dec 30, 2022
This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transformer"
FlatTN This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transfor
 74 Nov 28, 2022
74 Nov 28, 2022
This repo provides a package to automatically select a random seed based on ancient Chinese Xuanxue
🤞 Random Luck Deep learning is acturally the alchemy. This repo provides a package to automatically select a random seed based on ancient Chinese Xua
 33 Jan 3, 2023
33 Jan 3, 2023

T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets
T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets (product titles, images, comments, etc.).
 55 Nov 22, 2022
55 Nov 22, 2022
[AI6122] Text Data Management & Processing
[AI6122] Text Data Management & Processing is an elective course of MSAI, SCSE, NTU, Singapore. The repository corresponds to the AI6122 of Semester 1, AY2021-2022, starting from 08/2021. The instructor of this course is Prof. Sun Aixin.
 1 Jan 17, 2022
1 Jan 17, 2022
A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
DeepKE is a knowledge extraction toolkit supporting low-resource and document-level scenarios for entity, relation and attribute extraction. We provide comprehensive documents, Google Colab tutorials, and online demo for beginners.
 1.6k Jan 5, 2023
1.6k Jan 5, 2023
Python-zhuyin - An open source Python library that provides a unified interface for converting between Chinese pinyin and Zhuyin (bopomofo)
Python-zhuyin - An open source Python library that provides a unified interface for converting between Chinese pinyin and Zhuyin (bopomofo)
 2 Dec 29, 2022
2 Dec 29, 2022
2021 AI CUP Competition on Traditional Chinese Scene Text Recognition - Intermediate Contest
繁體中文場景文字辨識 程式碼說明 組別:這就是我 成員:蔣明憲 唐碩謙 黃玥菱 林冠霆 蕭靖騰 目錄 環境套件 安裝方式 資料夾布局 前處理-製作偵測訓練註解檔 前處理-製作分類訓練樣本 part.py : 從 json 裁切出分類訓練樣本 Class.py : 將切出來的樣本按照文字分類到各資料夾
 3 Jan 14, 2022
3 Jan 14, 2022
Huawei firewall automatically updates Chinese ip to target IP group.
Huawei firewall automatically updates Chinese ip to target IP group.
 0 Jan 11, 2022
0 Jan 11, 2022
ASCEND Chinese-English code-switching dataset
ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong.
 11 Dec 9, 2022
11 Dec 9, 2022
A series of Jupyter notebooks with Chinese comment that walk you through the fundamentals of Machine Learning and Deep Learning in python using Scikit-Learn and TensorFlow.
Hands-on-Machine-Learning 目的 这份笔记旨在帮助中文学习者以一种较快较系统的方式入门机器学习, 是在学习Hands-on Machine Learning with Scikit-Learn and TensorFlow这本书的 时候做的个人笔记: 此项目的可取之处 原书的
 1.5k Dec 21, 2022
1.5k Dec 21, 2022

Anki Cards for the HSK vocabulary Chinese-German
Anki-HanyuShuipingKaoshi Anki Cards for the HSK vocabulary Chinese-German Das Deck baut auf folgenden Quellen auf: China Endecken Wortschatz von wohok
 1 Jan 7, 2022
1 Jan 7, 2022
Using BERT+Bi-LSTM+CRF
Chinese Medical Entity Recognition Based on BERT+Bi-LSTM+CRF Step 1 I share the dataset on my google drive, please download the whole 'CCKS_2019_Task1
 55 Dec 21, 2022
55 Dec 21, 2022

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023
YACLC - Yet Another Chinese Learner Corpus
汉语学习者文本多维标注数据集YACLC V1.0 中文 | English 汉语学习者文本多维标注数据集(Yet Another Chinese Learner
 47 Dec 15, 2022
47 Dec 15, 2022

This repository contains datasets and baselines for benchmarking Chinese text recognition.
Benchmarking-Chinese-Text-Recognition This repository contains datasets and baselines for benchmarking Chinese text recognition. Please see the corres
 254 Dec 30, 2022
254 Dec 30, 2022
Chinese-specific configuration to improve your favorite DNS server
Dnsmasq-china-list - Chinese-specific configuration to improve your favorite DNS server. Best partner for chnroutes.
 4.6k Jan 3, 2023
4.6k Jan 3, 2023
GCRC: A Gaokao Chinese Reading Comprehension dataset for interpretable Evaluation
GCRC GCRC: A New Challenging MRC Dataset from Gaokao Chinese for Explainable Eva
 5 Nov 4, 2022
5 Nov 4, 2022
This is a telegram bot help you to get stylish fonts and text.
Stylish Font Bot 🐿 This is a telegram bot help you to get stylish fonts and text. Deploy to heroku 🗳 Press the button Deploy to heroku and give the
 0 Apr 8, 2022
0 Apr 8, 2022
EmoTag helps you train emotion detection model for Chinese audios
emoTag emoTag helps you train emotion detection model for Chinese audios. Environment pip install -r requirement.txt Data We used Emotional Speech Dat
 4 Sep 7, 2022
4 Sep 7, 2022
A unified tokenization tool for Images, Chinese and English.
ICE Tokenizer Token id [0, 20000) are image tokens. Token id [20000, 20100) are common tokens, mainly punctuations. E.g., icetk[20000] == 'unk', ice
 42 Dec 27, 2022
42 Dec 27, 2022
A 30000+ Chinese MRC dataset - Delta Reading Comprehension Dataset
Delta Reading Comprehension Dataset 台達閱讀理解資料集 Delta Reading Comprehension Dataset (DRCD) 屬於通用領域繁體中文機器閱讀理解資料集。 本資料集期望成為適用於遷移學習之標準中文閱讀理解資料集。 本資料集從2,108篇
 272 Dec 15, 2022
272 Dec 15, 2022
Noto fonts go universal! Download Noto fonts combined to suit your region (South Asia, SE Asia, Africa-MiddleEast, Europe-Americas).
Go Noto Universal Noto fonts go universal! Download Noto fonts combined to suit your region (South Asia, SE Asia, East Asia, Africa-MiddleEast, Europe
 67 Jan 6, 2023
67 Jan 6, 2023
A Telegram bot to index Chinese and Japanese group contents, works with @lilydjwg/luoxu.
luoxu-bot luoxu-bot 是类似于 luoxu-web 的 CJK 友好的 Telegram Bot,依赖于 luoxu 所创建的后端。 测试环境 Python 3.7.9 pip 21.1.2 开发中使用到的 Telethon 需要 Python 3+ 配置 前往 luoxu 根据相
 10 Nov 18, 2022
10 Nov 18, 2022
Chinese license plate recognition
AgentCLPR 简介 一个基于 ONNXRuntime、AgentOCR 和 License-Plate-Detector 项目开发的中国车牌检测识别系统。 车牌识别效果 支持多种车牌的检测和识别(其中单层车牌识别效果较好): 单层车牌: [[[[373, 282], [69, 284],
 26 Dec 25, 2022
26 Dec 25, 2022
Chinese named entity recognization with BiLSTM using Keras
Chinese named entity recognization (Bilstm with Keras) Project Structure ./ ├── README.md ├── data │ ├── README.md │ ├── data 数据集 │ │ ├─
 1 Dec 17, 2021
1 Dec 17, 2021
Chinese named entity recognization (bert/roberta/macbert/bert_wwm with Keras)
Chinese named entity recognization (bert/roberta/macbert/bert_wwm with Keras)
2 Jul 5, 2022
Chinese Named Entity Recognization (BiLSTM with PyTorch)
BiLSTM-CRF for Name Entity Recognition PyTorch version A PyTorch implemention of Bi-LSTM-CRF model for Chinese Named Entity Recognition. 使用 PyTorch 实现
5 Jun 1, 2022
Chinese NER with albert/electra or other bert descendable model (keras)
Chinese NLP (albert/electra with Keras) Named Entity Recognization Project Structure ./ ├── NER │ ├── __init__.py │ ├── log
2 Nov 20, 2022
Noto fonts go universal! Download Noto fonts combined to suit your region
noto-cjk Noto CJK fonts Noto Serif CJK update was released on 25 October 2021. We moved the release history and other notes into both Sans and Serif s
 2k Jan 2, 2023
2k Jan 2, 2023
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 342 Jan 5, 2023
342 Jan 5, 2023
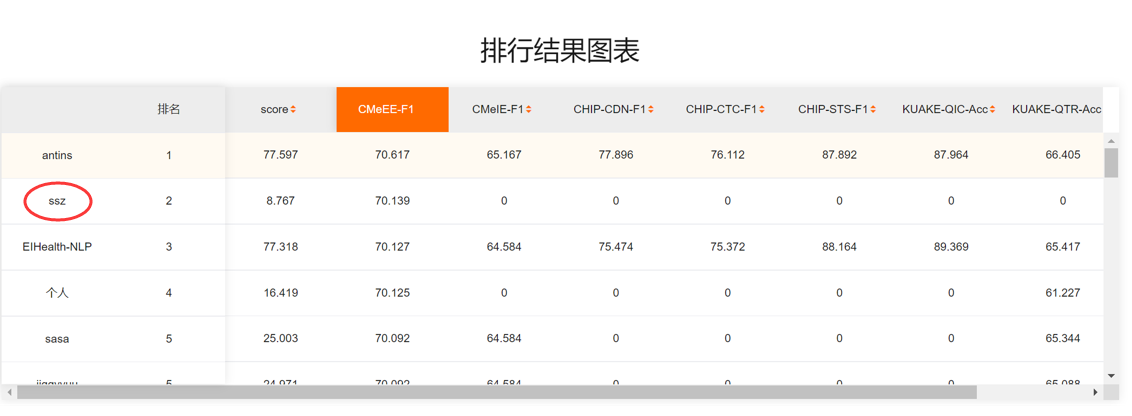
Nested Named Entity Recognition for Chinese Biomedical Text
CBio-NAMER CBioNAMER (Nested nAMed Entity Recognition for Chinese Biomedical Text) is our method used in CBLUE (Chinese Biomedical Language Understand
 8 Dec 25, 2022
8 Dec 25, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022
100+ Chinese Word Vectors 上百种预训练中文词向量
Chinese Word Vectors 中文词向量 中文 This project provides 100+ Chinese Word Vectors (embeddings) trained with different representations (dense and sparse),
 10.4k Jan 9, 2023
10.4k Jan 9, 2023

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
463 Dec 30, 2022

Bayesian inference for Permuton-induced Chinese Restaurant Process (NeurIPS2021).
Permuton-induced Chinese Restaurant Process Note: Currently only the Matlab version is available, but a Python version will be available soon! This is
 3 Dec 17, 2022
3 Dec 17, 2022
Source Code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chinese Question Matching
Description The source code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chin
 3 Jun 28, 2022
3 Jun 28, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
An Unsupervised Detection Framework for Chinese Jargons in the Darknet
An Unsupervised Detection Framework for Chinese Jargons in the Darknet This repo is the Python 3 implementation of 《An Unsupervised Detection Framewor
 7 Nov 8, 2022
7 Nov 8, 2022

Typesheet is a tiny Python script for creating transparent PNG spritesheets from TrueType (.ttf) fonts.
typesheet typesheet is a tiny Python script for creating transparent PNG spritesheets from TrueType (.ttf) fonts. I made it because I couldn't find an
 12 Dec 23, 2022
12 Dec 23, 2022

A demo of chinese asr
chinese_asr_demo 一个端到端的中文语音识别模型训练、测试框架 具备数据预处理、模型训练、解码、计算wer等等功能 训练数据 训练数据采用thchs_30,
 4 Dec 9, 2021
4 Dec 9, 2021
![[SIGGRAPH 2020] Attribute2Font: Creating Fonts You Want From Attributes](https://github.com/hologerry/Attr2Font/raw/master/img/teaser.png)
[SIGGRAPH 2020] Attribute2Font: Creating Fonts You Want From Attributes
Attr2Font Introduction This is the official PyTorch implementation of the Attribute2Font: Creating Fonts You Want From Attributes. Paper: arXiv | Rese
 200 Dec 15, 2022
200 Dec 15, 2022

Learning Chinese Character style with conditional GAN
zi2zi: Master Chinese Calligraphy with Conditional Adversarial Networks Introduction Learning eastern asian language typefaces with GAN. zi2zi(字到字, me
 2.2k Jan 2, 2023
2.2k Jan 2, 2023
A socket script to obtain chinese phones-sequence for any english word
Foreign Pronunciation Generator (English-Chinese) We provide a simple socket script for acquiring Chinese pronunciation of English words (phones in ai
 5 Jul 25, 2022
5 Jul 25, 2022

Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition
Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition | paper | dataset | pretrained detection model | Authors: Yi-Chang Che
1 Aug 23, 2022

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE: A Benchmark Suite for Data-centric NLP You can get the english version of README. 以数据为中心的AI测评(DataCLUE) 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE
 135 Dec 22, 2022
135 Dec 22, 2022
ChirpText is a collection of text processing tools for Python 3.
ChirpText is a collection of text processing tools for Python 3. It is not meant to be a powerful tank like the popular NTLK but a small package which
 5 Nov 30, 2022
5 Nov 30, 2022
A telegram bot help you to get stylish fonts and text
Stylish Font Bot 🐿 This is a telegram bot help you to get stylish fonts and text. Config Vars 🤖 API_HASH: Get this value from my.telegram.org. API_K
 1 Nov 8, 2021
1 Nov 8, 2021

Chinese Advertisement Board Identification(Pytorch)
Chinese-Advertisement-Board-Identification. We use YoloV5 to extract the ROI of the location of the chinese word. Next, we sort the bounding box and recognize every chinese words which we extracted. The methods which we use are Yolov5, ArgMargin and Focal loss.
 12 Jul 21, 2022
12 Jul 21, 2022
Chinese Pre-Trained Language Models (CPM-LM) Version-I
CPM-Generate 为了促进中文自然语言处理研究的发展,本项目提供了 CPM-LM (2.6B) 模型的文本生成代码,可用于文本生成的本地测试,并以此为基础进一步研究零次学习/少次学习等场景。[项目首页] [模型下载] [技术报告] 若您想使用CPM-1进行推理,我们建议使用高效推理工具BMI
 1.4k Jan 3, 2023
1.4k Jan 3, 2023
Fonts used to be an install-and-forget thing, but many of are now updated regularly.
Your font manager. Fonts used to be an install-and-forget thing, but many of are now updated regularly. fontman helps you keep track of the fonts you
 20 Feb 7, 2022
20 Feb 7, 2022
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
 1.6k Jan 3, 2023
1.6k Jan 3, 2023
A PyTorch implementation of unsupervised SimCSE
A PyTorch implementation of unsupervised SimCSE
 99 Dec 23, 2022
99 Dec 23, 2022
Chinese Grammatical Error Diagnosis
nlp-CGED Chinese Grammatical Error Diagnosis 中文语法纠错研究 基于序列标注的方法 所需环境 Python==3.6 tensorflow==1.14.0 keras==2.3.1 bert4keras==0.10.6 笔者使用了开源的bert4keras
 12 Nov 25, 2022
12 Nov 25, 2022
[SIGGRAPH Asia 2021] DeepVecFont: Synthesizing High-quality Vector Fonts via Dual-modality Learning.
DeepVecFont This is the homepage for "DeepVecFont: Synthesizing High-quality Vector Fonts via Dual-modality Learning". Yizhi Wang and Zhouhui Lian. WI
 5 Oct 22, 2021
5 Oct 22, 2021
[SIGGRAPH Asia 2021] DeepVecFont: Synthesizing High-quality Vector Fonts via Dual-modality Learning.
DeepVecFont This is the homepage for "DeepVecFont: Synthesizing High-quality Vector Fonts via Dual-modality Learning". Yizhi Wang and Zhouhui Lian. WI
17 Dec 22, 2022
NLP-based analysis of poor Chinese movie reviews on Douban
douban_embedding 豆瓣中文影评差评分析 1. NLP NLP(Natural Language Processing)是指自然语言处理,他的目的是让计算机可以听懂人话。 下面是我将2万条豆瓣影评训练之后,随意输入一段新影评交给神经网络,最终AI推断出的结果。 "很好,演技不错
 3 Apr 15, 2022
3 Apr 15, 2022
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
 197 Nov 26, 2022
197 Nov 26, 2022

Mengzi Pretrained Models
中文 | English Mengzi 尽管预训练语言模型在 NLP 的各个领域里得到了广泛的应用,但是其高昂的时间和算力成本依然是一个亟需解决的问题。这要求我们在一定的算力约束下,研发出各项指标更优的模型。 我们的目标不是追求更大的模型规模,而是轻量级但更强大,同时对部署和工业落地更友好的模型。
 424 Jan 4, 2023
424 Jan 4, 2023

LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation
LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation Tasks | Datasets | LongLM | Baselines | Paper Introduction LOT is a ben
 46 Dec 28, 2022
46 Dec 28, 2022
[SIGGRAPH 2021 Asia] DeepVecFont: Synthesizing High-quality Vector Fonts via Dual-modality Learning
DeepVecFont This is the official Pytorch implementation of the paper: Yizhi Wang and Zhouhui Lian. DeepVecFont: Synthesizing High-quality Vector Fonts
146 Dec 18, 2022

A 10000+ hours dataset for Chinese speech recognition
WenetSpeech Official website | Paper A 10000+ Hours Multi-domain Chinese Corpus for Speech Recognition Download Please visit the official website, rea
 310 Jan 3, 2023
310 Jan 3, 2023

text to speech toolkit. 好用的中文语音合成工具箱,包含语音编码器、语音合成器、声码器和可视化模块。
ttskit Text To Speech Toolkit: 语音合成工具箱。 安装 pip install -U ttskit 注意 可能需另外安装的依赖包:torch,版本要求torch=1.6.0,=1.7.1,根据自己的实际环境安装合适cuda或cpu版本的torch。 ttskit的
 483 Jan 4, 2023
483 Jan 4, 2023

Google and Stanford University released a new pre-trained model called ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants. For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA. ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
1.2k Dec 30, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
29 Nov 26, 2022
This is a tool to automate the icons generation from sets of svg files into fonts and atlases.
SVG Icon processing tool for C++
 66 Dec 14, 2022
66 Dec 14, 2022
vits chinese, tts chinese, tts mandarin
vits chinese, tts chinese, tts mandarin 史上训练最简单,音质最好的语音合成系统
 12 Dec 14, 2022
12 Dec 14, 2022
A 10000+ hours dataset for Chinese speech recognition
A 10000+ hours dataset for Chinese speech recognition
309 Dec 16, 2022

CDLA: A Chinese document layout analysis (CDLA) dataset
CDLA: A Chinese document layout analysis (CDLA) dataset 介绍 CDLA是一个中文文档版面分析数据集,面向中文文献类(论文)场景。包含以下10个label: 正文 标题 图片 图片标题 表格 表格标题 页眉 页脚 注释 公式 Text Title
 84 Dec 28, 2022
84 Dec 28, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
341 Dec 29, 2022

An experimental Fang Song style Chinese font generated with skeleton-tracing and pix2pix
An experimental Fang Song style Chinese font generated with skeleton-tracing and pix2pix, with glyphs based on cwTeXFangSong. The font is optimised fo
 98 Jan 7, 2023
98 Jan 7, 2023
DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE 以数据为中心的AI测评(DataCLUE) DataCLUE: A Chinese Data-centric Language Evaluation Benchmark 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE)的背景 任务描述 任务描述 实验结果
135 Dec 22, 2022

Application for shadowing Chinese.
chinese-shadowing Simple APP for shadowing chinese. With this application, it is very easy to record yourself, play the sound recorded and listen to s
 5 Sep 6, 2022
5 Sep 6, 2022

A Tool that provides automatic kerning for ligature based OpenType fonts in Microsoft Volt
Kerning A Tool that provides automatic kerning for ligature based OpenType fonts in Microsoft Volt There are three stages of the algorithm. The first
 6 Aug 1, 2022
6 Aug 1, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task。涵盖68个领域、共计916万词的专业词典知识库,可用于文本分类、知识增强、领域词汇库扩充等自然语言处理应用。
 357 Dec 24, 2022
357 Dec 24, 2022

A demo for end-to-end English and Chinese text spotting using ABCNet.
ABCNet_Chinese A demo for end-to-end English and Chinese text spotting using ABCNet. This is an old model that was trained a long ago, which serves as
 45 Oct 4, 2022
45 Oct 4, 2022

A Multi-modal Model Chinese Spell Checker Released on ACL2021.
ReaLiSe ReaLiSe is a multi-modal Chinese spell checking model. This the office code for the paper Read, Listen, and See: Leveraging Multimodal Informa
 106 Dec 29, 2022
106 Dec 29, 2022

Chinese real time voice cloning (VC) and Chinese text to speech (TTS).
Chinese real time voice cloning (VC) and Chinese text to speech (TTS). 好用的中文语音克隆兼中文语音合成系统,包含语音编码器、语音合成器、声码器和可视化模块。
 6 Nov 8, 2022
6 Nov 8, 2022

ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information This repository contains code, model, dataset for ChineseBERT at ACL2021. Ch
 413 Dec 1, 2022
413 Dec 1, 2022

Translation for Trilium Notes. Trilium Notes 中文版.
Trilium Translation 中文说明 This repo provides a translation for the awesome Trilium Notes. Currently, I have translated Trilium Notes into Chinese. Test
 743 Jan 8, 2023
743 Jan 8, 2023
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
197 Nov 26, 2022
A Multi-modal Model Chinese Spell Checker Released on ACL2021.
ReaLiSe ReaLiSe is a multi-modal Chinese spell checking model. This the office code for the paper Read, Listen, and See: Leveraging Multimodal Informa
106 Dec 29, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
99 Dec 23, 2022

A collection of Classical Chinese natural language processing models, including Classical Chinese related models and resources on the Internet.
GuwenModels: 古文自然语言处理模型合集, 收录互联网上的古文相关模型及资源. A collection of Classical Chinese natural language processing models, including Classical Chinese related models and resources on the Internet.
 66 Dec 26, 2022
66 Dec 26, 2022
A Django chatbot that is capable of doing math and searching Chinese poet online. Developed with django, channels, celery and redis.
Django Channels Websocket Chatbot A Django chatbot that is capable of doing math and searching Chinese poet online. Developed with django, channels, c
 8 Oct 28, 2022
8 Oct 28, 2022
Easy-to-use CPM for Chinese text generation
CPM 项目描述 CPM(Chinese Pretrained Models)模型是北京智源人工智能研究院和清华大学发布的中文大规模预训练模型。官方发布了三种规模的模型,参数量分别为109M、334M、2.6B,用户需申请与通过审核,方可下载。 由于原项目需要考虑大模型的训练和使用,需要安装较为复杂
 382 Jan 7, 2023
382 Jan 7, 2023
2021海华AI挑战赛·中文阅读理解·技术组·第三名
文字是人类用以记录和表达的最基本工具,也是信息传播的重要媒介。透过文字与符号,我们可以追寻人类文明的起源,可以传播知识与经验,读懂文字是认识与了解的第一步。对于人工智能而言,它的核心问题之一就是认知,而认知的核心则是语义理解。
 21 Dec 26, 2022
21 Dec 26, 2022
多语言降噪预训练模型MBart的中文生成任务
mbart-chinese 基于mbart-large-cc25 的中文生成任务 Input source input: text + /s + lang_code target input: lang_code + text + /s Usage token_ids_mapping.jso
 11 Sep 19, 2022
11 Sep 19, 2022
Port Hitsuboku Kumi Chinese CVVC voicebank to deepvocal. / 筆墨クミDeepvocal中文音源
Hitsuboku Kumi (筆墨クミ) is a UTAU virtual singer developed by Cubialpha. This project ports Hitsuboku Kumi Chinese CVVC voicebank to deepvocal. This is the first open-source deepvocal voicebank on Github.
 8 Apr 26, 2022
8 Apr 26, 2022
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022
Chinese clinical named entity recognition using pre-trained BERT model
Chinese clinical named entity recognition (CNER) using pre-trained BERT model Introduction Code for paper Chinese clinical named entity recognition wi
 109 Dec 14, 2022
109 Dec 14, 2022

Code for the ACL2021 paper "Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter"
Lexicon Enhanced Chinese Sequence Labeling Using BERT Adapter Code and checkpoints for the ACL2021 paper "Lexicon Enhanced Chinese Sequence Labelling
 274 Dec 6, 2022
274 Dec 6, 2022

TPlinker for NER 中文/英文命名实体识别
本项目是参考 TPLinker 中HandshakingTagging思想,将TPLinker由原来的关系抽取(RE)模型修改为命名实体识别(NER)模型。
 113 Dec 28, 2022
113 Dec 28, 2022
A framework for cleaning Chinese dialog data
A framework for cleaning Chinese dialog data
 136 Dec 20, 2022
136 Dec 20, 2022
A fast Text-to-Speech (TTS) model. Work well for English, Mandarin/Chinese, Japanese, Korean, Russian and Tibetan (so far). 快速语音合成模型,适用于英语、普通话/中文、日语、韩语、俄语和藏语(当前已测试)。
简体中文 | English 并行语音合成 [TOC] 新进展 2021/04/20 合并 wavegan 分支到 main 主分支,删除 wavegan 分支! 2021/04/13 创建 encoder 分支用于开发语音风格迁移模块! 2021/04/13 softdtw 分支 支持使用 Sof
 161 Dec 19, 2022
161 Dec 19, 2022


Chinese Mandarin tts text-to-speech 中文 (普通话) 语音 合成 , by fastspeech 2 , implemented in pytorch, using waveglow as vocoder,
Chinese mandarin text to speech based on Fastspeech2 and Unet This is a modification and adpation of fastspeech2 to mandrin(普通话). Many modifications t
 291 Jan 2, 2023
291 Jan 2, 2023