199 Repositories
Python tts-chinese Libraries
This program uses trial auth token of Azure Cognitive Services to do speech synthesis for you.
🗣️ aspeak A simple text-to-speech client using azure TTS API(trial). 😆 TL;DR: This program uses trial auth token of Azure Cognitive Services to do s
 359 Jan 5, 2023
359 Jan 5, 2023
Rich Prosody Diversity Modelling with Phone-level Mixture Density Network
Phone Level Mixture Density Network for TTS This repo contains pytorch implementation of paper Rich Prosody Diversity Modelling with Phone-level Mixtu
 42 Dec 13, 2022
42 Dec 13, 2022
🐤 Nix-TTS: An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation
🐤 Nix-TTS An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation Rendi Chevi, Radityo Eko Prasojo, Alham Fikri Aji
 156 Jan 9, 2023
156 Jan 9, 2023

Comprehensive-E2E-TTS - PyTorch Implementation
A Non-Autoregressive End-to-End Text-to-Speech (text-to-wav), supporting a family of SOTA unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate E2E-TTS
 114 Nov 13, 2022
114 Nov 13, 2022
Finally, some decent sample sentences
tts-dataset-prompts This repository aims to be a decent set of sentences for people looking to clone their own voices (e.g. using Tacotron 2). Each se
 19 Dec 13, 2022
19 Dec 13, 2022
Repository for the paper: VoiceMe: Personalized voice generation in TTS
🗣 VoiceMe: Personalized voice generation in TTS Abstract Novel text-to-speech systems can generate entirely new voices that were not seen during trai
 80 Dec 29, 2022
80 Dec 29, 2022

🚀 RocketQA, dense retrieval for information retrieval and question answering, including both Chinese and English state-of-the-art models.
In recent years, the dense retrievers based on pre-trained language models have achieved remarkable progress. To facilitate more developers using cutt
 475 Jan 4, 2023
475 Jan 4, 2023

iSTFTNet : Fast and Lightweight Mel-spectrogram Vocoder Incorporating Inverse Short-time Fourier Transform
iSTFTNet : Fast and Lightweight Mel-spectrogram Vocoder Incorporating Inverse Short-time Fourier Transform This repo try to implement iSTFTNet : Fast
126 Jan 2, 2023
A multi-voice TTS system trained with an emphasis on quality
TorToiSe Tortoise is a text-to-speech program built with the following priorities: Strong multi-voice capabilities. Highly realistic prosody and inton
 2.1k Jan 1, 2023
2.1k Jan 1, 2023

PyTorch Implementation of DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
DiffGAN-TTS - PyTorch Implementation PyTorch implementation of DiffGAN-TTS: High
157 Jan 1, 2023

This repository contains code from the paper "TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network"
TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network This repository contains code from the paper "TTS-GAN: A Transformer-based Tim
 108 Dec 29, 2022
108 Dec 29, 2022
This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transformer"
FlatTN This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transfor
 74 Nov 28, 2022
74 Nov 28, 2022
Tensorflow Implementation of A Generative Flow for Text-to-Speech via Monotonic Alignment Search
Tensorflow Implementation of A Generative Flow for Text-to-Speech via Monotonic Alignment Search
 10 Oct 13, 2022
10 Oct 13, 2022
This repo provides a package to automatically select a random seed based on ancient Chinese Xuanxue
🤞 Random Luck Deep learning is acturally the alchemy. This repo provides a package to automatically select a random seed based on ancient Chinese Xua
 33 Jan 3, 2023
33 Jan 3, 2023
Simple Text-To-Speech Bot For Discord
Simple Text-To-Speech Bot For Discord This is a very simple TTS bot for discord made with python. For this bot you need FFMPEG, see installation to se
 1 Sep 26, 2022
1 Sep 26, 2022

T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets
T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets (product titles, images, comments, etc.).
 55 Nov 22, 2022
55 Nov 22, 2022
[AI6122] Text Data Management & Processing
[AI6122] Text Data Management & Processing is an elective course of MSAI, SCSE, NTU, Singapore. The repository corresponds to the AI6122 of Semester 1, AY2021-2022, starting from 08/2021. The instructor of this course is Prof. Sun Aixin.
 1 Jan 17, 2022
1 Jan 17, 2022
A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
DeepKE is a knowledge extraction toolkit supporting low-resource and document-level scenarios for entity, relation and attribute extraction. We provide comprehensive documents, Google Colab tutorials, and online demo for beginners.
 1.6k Jan 5, 2023
1.6k Jan 5, 2023
Python-zhuyin - An open source Python library that provides a unified interface for converting between Chinese pinyin and Zhuyin (bopomofo)
Python-zhuyin - An open source Python library that provides a unified interface for converting between Chinese pinyin and Zhuyin (bopomofo)
 2 Dec 29, 2022
2 Dec 29, 2022
2021 AI CUP Competition on Traditional Chinese Scene Text Recognition - Intermediate Contest
繁體中文場景文字辨識 程式碼說明 組別:這就是我 成員:蔣明憲 唐碩謙 黃玥菱 林冠霆 蕭靖騰 目錄 環境套件 安裝方式 資料夾布局 前處理-製作偵測訓練註解檔 前處理-製作分類訓練樣本 part.py : 從 json 裁切出分類訓練樣本 Class.py : 將切出來的樣本按照文字分類到各資料夾
 3 Jan 14, 2022
3 Jan 14, 2022
Huawei firewall automatically updates Chinese ip to target IP group.
Huawei firewall automatically updates Chinese ip to target IP group.
 0 Jan 11, 2022
0 Jan 11, 2022
ASCEND Chinese-English code-switching dataset
ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong.
 11 Dec 9, 2022
11 Dec 9, 2022
A series of Jupyter notebooks with Chinese comment that walk you through the fundamentals of Machine Learning and Deep Learning in python using Scikit-Learn and TensorFlow.
Hands-on-Machine-Learning 目的 这份笔记旨在帮助中文学习者以一种较快较系统的方式入门机器学习, 是在学习Hands-on Machine Learning with Scikit-Learn and TensorFlow这本书的 时候做的个人笔记: 此项目的可取之处 原书的
 1.5k Dec 21, 2022
1.5k Dec 21, 2022

Anki Cards for the HSK vocabulary Chinese-German
Anki-HanyuShuipingKaoshi Anki Cards for the HSK vocabulary Chinese-German Das Deck baut auf folgenden Quellen auf: China Endecken Wortschatz von wohok
 1 Jan 7, 2022
1 Jan 7, 2022
Using BERT+Bi-LSTM+CRF
Chinese Medical Entity Recognition Based on BERT+Bi-LSTM+CRF Step 1 I share the dataset on my google drive, please download the whole 'CCKS_2019_Task1
 55 Dec 21, 2022
55 Dec 21, 2022

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023
YACLC - Yet Another Chinese Learner Corpus
汉语学习者文本多维标注数据集YACLC V1.0 中文 | English 汉语学习者文本多维标注数据集(Yet Another Chinese Learner
 47 Dec 15, 2022
47 Dec 15, 2022

This repository contains datasets and baselines for benchmarking Chinese text recognition.
Benchmarking-Chinese-Text-Recognition This repository contains datasets and baselines for benchmarking Chinese text recognition. Please see the corres
 254 Dec 30, 2022
254 Dec 30, 2022
DeepSpeech - Easy-to-use Speech Toolkit including SOTA ASR pipeline, influential TTS with text frontend and End-to-End Speech Simultaneous Translation.
(简体中文|English) Quick Start | Documents | Models List PaddleSpeech is an open-source toolkit on PaddlePaddle platform for a variety of critical tasks i
5.6k Jan 3, 2023
Chinese-specific configuration to improve your favorite DNS server
Dnsmasq-china-list - Chinese-specific configuration to improve your favorite DNS server. Best partner for chnroutes.
 4.6k Jan 3, 2023
4.6k Jan 3, 2023

Unet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning
Unet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning English | 中文 ❗ Now we provide inferencing code and pre-training models
 164 Jan 2, 2023
164 Jan 2, 2023
GCRC: A Gaokao Chinese Reading Comprehension dataset for interpretable Evaluation
GCRC GCRC: A New Challenging MRC Dataset from Gaokao Chinese for Explainable Eva
 5 Nov 4, 2022
5 Nov 4, 2022
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 1.1k Jan 2, 2023
1.1k Jan 2, 2023
EmoTag helps you train emotion detection model for Chinese audios
emoTag emoTag helps you train emotion detection model for Chinese audios. Environment pip install -r requirement.txt Data We used Emotional Speech Dat
 4 Sep 7, 2022
4 Sep 7, 2022

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022
Utility for Google Text-To-Speech batch audio files generator. Ideal for prompt files creation with Google voices for application in offline IVRs
Google Text-To-Speech Batch Prompt File Maker Are you in the need of IVR prompts, but you have no voice actors? Let Google talk your prompts like a pr
 1 Aug 19, 2021
1 Aug 19, 2021

ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python)
ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python) 日本語は以下に続きます (Japanese follows) English: This book is written in Japanese and primaril
 189 Dec 29, 2022
189 Dec 29, 2022
A unified tokenization tool for Images, Chinese and English.
ICE Tokenizer Token id [0, 20000) are image tokens. Token id [20000, 20100) are common tokens, mainly punctuations. E.g., icetk[20000] == 'unk', ice
 42 Dec 27, 2022
42 Dec 27, 2022
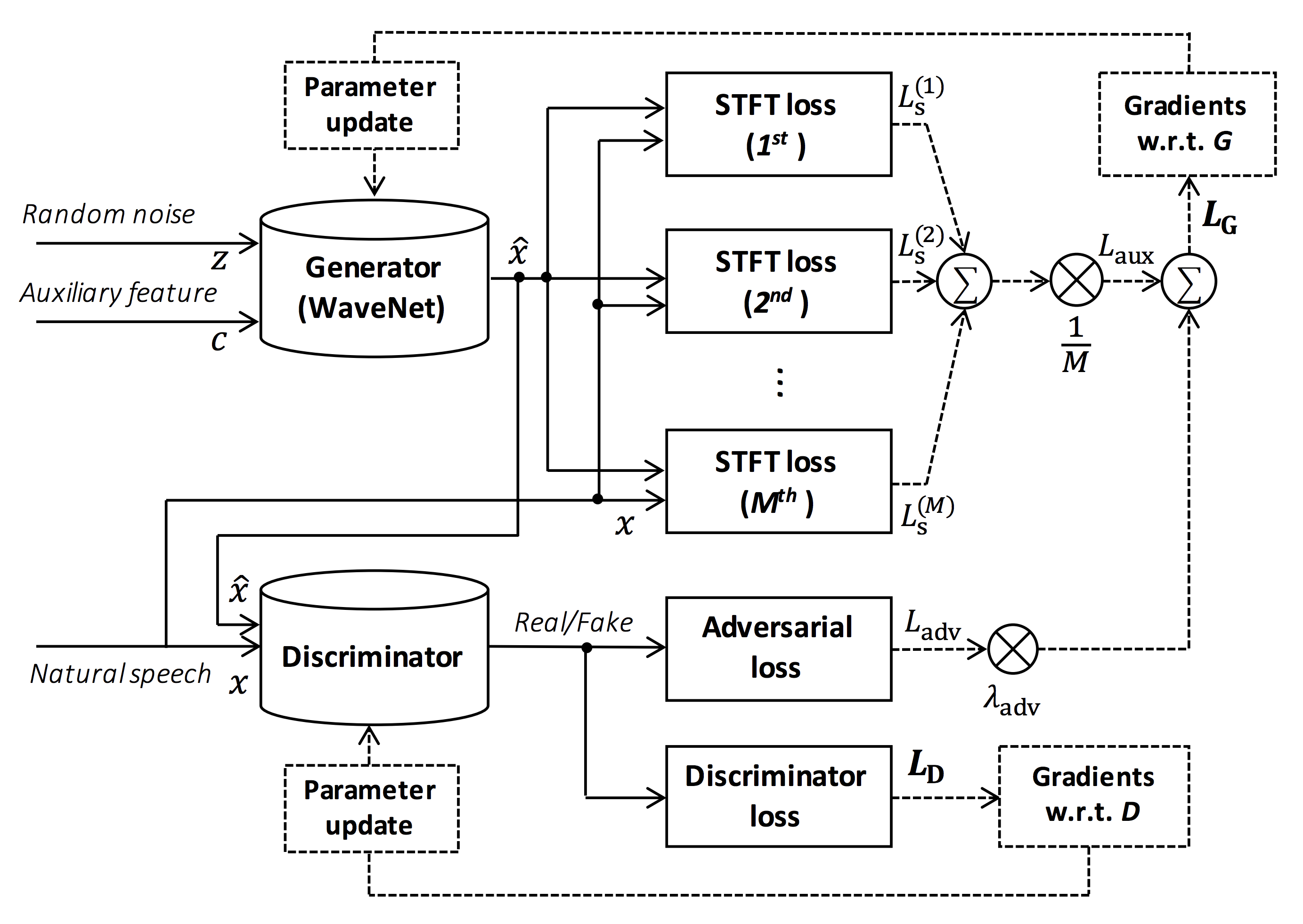
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN & HiFi-GAN & StyleMelGAN) with Pytorch
Parallel WaveGAN implementation with Pytorch This repository provides UNOFFICIAL pytorch implementations of the following models: Parallel WaveGAN Mel
 1.2k Dec 23, 2022
1.2k Dec 23, 2022
A 30000+ Chinese MRC dataset - Delta Reading Comprehension Dataset
Delta Reading Comprehension Dataset 台達閱讀理解資料集 Delta Reading Comprehension Dataset (DRCD) 屬於通用領域繁體中文機器閱讀理解資料集。 本資料集期望成為適用於遷移學習之標準中文閱讀理解資料集。 本資料集從2,108篇
 272 Dec 15, 2022
272 Dec 15, 2022
A Telegram bot to index Chinese and Japanese group contents, works with @lilydjwg/luoxu.
luoxu-bot luoxu-bot 是类似于 luoxu-web 的 CJK 友好的 Telegram Bot,依赖于 luoxu 所创建的后端。 测试环境 Python 3.7.9 pip 21.1.2 开发中使用到的 Telethon 需要 Python 3+ 配置 前往 luoxu 根据相
 10 Nov 18, 2022
10 Nov 18, 2022
A Python module made to simplify the usage of Text To Speech and Speech Recognition.
Nav Module The solution for voice related stuff in Python Nav is a Python module which simplifies voice related stuff in Python. Just import the Modul
 1 Dec 20, 2021
1 Dec 20, 2021

DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022; Official code
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
 803 Dec 28, 2022
803 Dec 28, 2022
Chinese license plate recognition
AgentCLPR 简介 一个基于 ONNXRuntime、AgentOCR 和 License-Plate-Detector 项目开发的中国车牌检测识别系统。 车牌识别效果 支持多种车牌的检测和识别(其中单层车牌识别效果较好): 单层车牌: [[[[373, 282], [69, 284],
 26 Dec 25, 2022
26 Dec 25, 2022
Arabic speech recognition, classification and text-to-speech.
klaam Arabic speech recognition, classification and text-to-speech using many advanced models like wave2vec and fastspeech2. This repository allows tr
 177 Dec 27, 2022
177 Dec 27, 2022
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
829 Jan 7, 2023
Chinese named entity recognization with BiLSTM using Keras
Chinese named entity recognization (Bilstm with Keras) Project Structure ./ ├── README.md ├── data │ ├── README.md │ ├── data 数据集 │ │ ├─
 1 Dec 17, 2021
1 Dec 17, 2021

User-friendly Voice Cloning Application
Multi-Language-RTVC stands for Multi-Language Real Time Voice Cloning and is a Voice Cloning Tool capable of transfering speaker-specific audio featur
 19 Dec 30, 2022
19 Dec 30, 2022
Chinese named entity recognization (bert/roberta/macbert/bert_wwm with Keras)
Chinese named entity recognization (bert/roberta/macbert/bert_wwm with Keras)
2 Jul 5, 2022
Chinese Named Entity Recognization (BiLSTM with PyTorch)
BiLSTM-CRF for Name Entity Recognition PyTorch version A PyTorch implemention of Bi-LSTM-CRF model for Chinese Named Entity Recognition. 使用 PyTorch 实现
5 Jun 1, 2022
Chinese NER with albert/electra or other bert descendable model (keras)
Chinese NLP (albert/electra with Keras) Named Entity Recognization Project Structure ./ ├── NER │ ├── __init__.py │ ├── log
2 Nov 20, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 342 Jan 5, 2023
342 Jan 5, 2023
Parallel TTS web demo based on Flask + Vue (Vuetify).
Parallel TTS web demo based on Flask + Vue (Vuetify).
 34 Dec 16, 2022
34 Dec 16, 2022
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone In our recent paper we propose the YourTTS model. YourTTS bri
 390 Dec 29, 2022
390 Dec 29, 2022
Nested Named Entity Recognition for Chinese Biomedical Text
CBio-NAMER CBioNAMER (Nested nAMed Entity Recognition for Chinese Biomedical Text) is our method used in CBLUE (Chinese Biomedical Language Understand
 8 Dec 25, 2022
8 Dec 25, 2022
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
 76 Dec 30, 2022
76 Dec 30, 2022
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022

Implementation of Google Brain's WaveGrad high-fidelity vocoder
WaveGrad Implementation (PyTorch) of Google Brain's high-fidelity WaveGrad vocoder (paper). First implementation on GitHub with high-quality generatio
 363 Dec 27, 2022
363 Dec 27, 2022
Neural HMMs are all you need (for high-quality attention-free TTS)
Neural HMMs are all you need (for high-quality attention-free TTS) Shivam Mehta, Éva Székely, Jonas Beskow, and Gustav Eje Henter This is the official
 0 Oct 28, 2022
0 Oct 28, 2022
100+ Chinese Word Vectors 上百种预训练中文词向量
Chinese Word Vectors 中文词向量 中文 This project provides 100+ Chinese Word Vectors (embeddings) trained with different representations (dense and sparse),
 10.4k Jan 9, 2023
10.4k Jan 9, 2023

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
463 Dec 30, 2022

Bayesian inference for Permuton-induced Chinese Restaurant Process (NeurIPS2021).
Permuton-induced Chinese Restaurant Process Note: Currently only the Matlab version is available, but a Python version will be available soon! This is
 3 Dec 17, 2022
3 Dec 17, 2022
Source Code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chinese Question Matching
Description The source code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chin
 3 Jun 28, 2022
3 Jun 28, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
Text-to-Speech for Belarusian language
title emoji colorFrom colorTo sdk app_file pinned Belarusian TTS 🐸 green green gradio app.py false Belarusian TTS 📢 🤖 Belarusian TTS (text-to-speec
 1 Nov 27, 2021
1 Nov 27, 2021

A python gui program to generate reddit text to speech videos from the id of any post.
Reddit text to speech generator A python gui program to generate reddit text to speech videos from the id of any post. Current functionality Generate
 17 Dec 19, 2022
17 Dec 19, 2022
An Unsupervised Detection Framework for Chinese Jargons in the Darknet
An Unsupervised Detection Framework for Chinese Jargons in the Darknet This repo is the Python 3 implementation of 《An Unsupervised Detection Framewor
 7 Nov 8, 2022
7 Nov 8, 2022

A demo of chinese asr
chinese_asr_demo 一个端到端的中文语音识别模型训练、测试框架 具备数据预处理、模型训练、解码、计算wer等等功能 训练数据 训练数据采用thchs_30,
 4 Dec 9, 2021
4 Dec 9, 2021

Learning Chinese Character style with conditional GAN
zi2zi: Master Chinese Calligraphy with Conditional Adversarial Networks Introduction Learning eastern asian language typefaces with GAN. zi2zi(字到字, me
 2.2k Jan 2, 2023
2.2k Jan 2, 2023
A socket script to obtain chinese phones-sequence for any english word
Foreign Pronunciation Generator (English-Chinese) We provide a simple socket script for acquiring Chinese pronunciation of English words (phones in ai
 5 Jul 25, 2022
5 Jul 25, 2022

Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition
Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition | paper | dataset | pretrained detection model | Authors: Yi-Chang Che
1 Aug 23, 2022

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE: A Benchmark Suite for Data-centric NLP You can get the english version of README. 以数据为中心的AI测评(DataCLUE) 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE
 135 Dec 22, 2022
135 Dec 22, 2022
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 168 Dec 28, 2022
168 Dec 28, 2022
A relatively simple python program to generate one of those reddit text to speech videos dominating youtube.
Reddit text to speech generator A basic reddit tts video generator Current functionality Generate videos for subs based on comments,(askreddit) so rea
17 Dec 19, 2022
ChirpText is a collection of text processing tools for Python 3.
ChirpText is a collection of text processing tools for Python 3. It is not meant to be a powerful tank like the popular NTLK but a small package which
 5 Nov 30, 2022
5 Nov 30, 2022
Implementation of TTS with combination of Tacotron2 and HiFi-GAN
Tacotron2-HiFiGAN-master Implementation of TTS with combination of Tacotron2 and HiFi-GAN for Mandarin TTS. Inference In order to inference, we need t
 7 Nov 11, 2022
7 Nov 11, 2022

Meta-TTS: Meta-Learning for Few-shot SpeakerAdaptive Text-to-Speech
Meta-TTS: Meta-Learning for Few-shot SpeakerAdaptive Text-to-Speech This repository is the official implementation of "Meta-TTS: Meta-Learning for Few
 128 Dec 25, 2022
128 Dec 25, 2022
Azure Neural Speech Service TTS
Written in Python using the Azure Speech SDK. App.py provides an easy way to create an Text-To-Speech request to Azure Speech and download the wav file. Azure Neural Voices Text-To-Speech enables fluid, natural-sounding text to speech that matches the patterns and intonation of human voices.
 4 Dec 14, 2022
4 Dec 14, 2022

Chinese Advertisement Board Identification(Pytorch)
Chinese-Advertisement-Board-Identification. We use YoloV5 to extract the ROI of the location of the chinese word. Next, we sort the bounding box and recognize every chinese words which we extracted. The methods which we use are Yolov5, ArgMargin and Focal loss.
 12 Jul 21, 2022
12 Jul 21, 2022
Ukrainian TTS (text-to-speech) using Coqui TTS
title emoji colorFrom colorTo sdk app_file pinned Ukrainian TTS 🐸 green green gradio app.py false Ukrainian TTS 📢 🤖 Ukrainian TTS (text-to-speech)
85 Dec 26, 2022
Chinese Pre-Trained Language Models (CPM-LM) Version-I
CPM-Generate 为了促进中文自然语言处理研究的发展,本项目提供了 CPM-LM (2.6B) 模型的文本生成代码,可用于文本生成的本地测试,并以此为基础进一步研究零次学习/少次学习等场景。[项目首页] [模型下载] [技术报告] 若您想使用CPM-1进行推理,我们建议使用高效推理工具BMI
 1.4k Jan 3, 2023
1.4k Jan 3, 2023
Azure Text-to-speech service for Home Assistant
Azure Text-to-speech service for Home Assistant The Azure text-to-speech platform uses online Azure Text-to-Speech cognitive service to read a text wi
 2 Aug 6, 2022
2 Aug 6, 2022
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
 1.6k Jan 3, 2023
1.6k Jan 3, 2023
A PyTorch implementation of unsupervised SimCSE
A PyTorch implementation of unsupervised SimCSE
 99 Dec 23, 2022
99 Dec 23, 2022
Simple Speech to Text, Text to Speech
Simple Speech to Text, Text to Speech 1. Download Repository Opsi 1 Download repository ini, extract di lokasi yang diinginkan Opsi 2 Jika sudah famil
 5 Dec 28, 2021
5 Dec 28, 2021
Chinese Grammatical Error Diagnosis
nlp-CGED Chinese Grammatical Error Diagnosis 中文语法纠错研究 基于序列标注的方法 所需环境 Python==3.6 tensorflow==1.14.0 keras==2.3.1 bert4keras==0.10.6 笔者使用了开源的bert4keras
 12 Nov 25, 2022
12 Nov 25, 2022

PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Cross-Speaker-Emotion-Transfer - PyTorch Implementation PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Conditio
114 Jan 8, 2023
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge This is an implementation of the paper,
 19 Oct 14, 2022
19 Oct 14, 2022
NLP-based analysis of poor Chinese movie reviews on Douban
douban_embedding 豆瓣中文影评差评分析 1. NLP NLP(Natural Language Processing)是指自然语言处理,他的目的是让计算机可以听懂人话。 下面是我将2万条豆瓣影评训练之后,随意输入一段新影评交给神经网络,最终AI推断出的结果。 "很好,演技不错
 3 Apr 15, 2022
3 Apr 15, 2022

A Python/Pytorch app for easily synthesising human voices
Voice Cloning App A Python/Pytorch app for easily synthesising human voices Documentation Discord Server Video guide Voice Sharing Hub FAQ's System Re
 840 Jan 4, 2023
840 Jan 4, 2023
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
 197 Nov 26, 2022
197 Nov 26, 2022

Mengzi Pretrained Models
中文 | English Mengzi 尽管预训练语言模型在 NLP 的各个领域里得到了广泛的应用,但是其高昂的时间和算力成本依然是一个亟需解决的问题。这要求我们在一定的算力约束下,研发出各项指标更优的模型。 我们的目标不是追求更大的模型规模,而是轻量级但更强大,同时对部署和工业落地更友好的模型。
 424 Jan 4, 2023
424 Jan 4, 2023
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge This is an implementation of the paper,
19 Oct 14, 2022

LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation
LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation Tasks | Datasets | LongLM | Baselines | Paper Introduction LOT is a ben
 46 Dec 28, 2022
46 Dec 28, 2022
Maix Speech AI lib, including ASR, chat, TTS etc.
Maix-Speech 中文 | English Brief Now only support Chinese, See 中文 Build Clone code by: git clone https://github.com/sipeed/Maix-Speech Compile x86x64 c
 267 Dec 25, 2022
267 Dec 25, 2022
Updated for TTS(CE) = Also Known as TTN V3. The code requires the first server to be 'ttn' protocol.
Updated Updated for TTS(CE) = Also Known as TTN V3. The code requires the first server to be 'ttn' protocol. Introduction This balenaCloud (previously
 1 Oct 17, 2021
1 Oct 17, 2021
FG-transformer-TTS Fine-grained style control in transformer-based text-to-speech synthesis
LST-TTS Official implementation for the paper Fine-grained style control in transformer-based text-to-speech synthesis. Submitted to ICASSP 2022. Audi
 64 Dec 30, 2022
64 Dec 30, 2022
Azure Neural Speech Service TTS
Written in Python using the Azure Speech SDK. App.py provides an easy way to create an Text-To-Speech request to Azure Speech and download the wav file.
1 Oct 11, 2021