274 Repositories
Python chinese-ocr Libraries

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022

Automatic number plate recognition using tech: Yolo, OCR, Scene text detection, scene text recognation, flask, torch
Automatic Number Plate Recognition Automatic Number Plate Recognition (ANPR) is the process of reading the characters on the plate with various optica
 52 Dec 22, 2022
52 Dec 22, 2022

Optical Character Recognition + Instance Segmentation for russian and english languages
Распознавание рукописного текста в школьных тетрадях Соревнование, проводимое в рамках олимпиады НТО, разработанное Сбером. Платформа ODS. Результаты
 21 Dec 19, 2022
21 Dec 19, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
 327 Jan 1, 2023
327 Jan 1, 2023

🚀 RocketQA, dense retrieval for information retrieval and question answering, including both Chinese and English state-of-the-art models.
In recent years, the dense retrievers based on pre-trained language models have achieved remarkable progress. To facilitate more developers using cutt
 475 Jan 4, 2023
475 Jan 4, 2023
Read Japanese manga inside browser with selectable text.
mokuro Read Japanese manga with selectable text inside a browser. See demo: https://kha-white.github.io/manga-demo mokuro_demo.mp4 Demo contains excer
170 Dec 27, 2022

Comparison-of-OCR (KerasOCR, PyTesseract,EasyOCR)
Optical Character Recognition OCR (Optical Character Recognition) is a technology that enables the conversion of document types such as scanned paper
21 Dec 25, 2022
Digitalizing-Prescription-Image - PIRDS - Prescription Image Recognition and Digitalizing System is a OCR make with Tensorflow
Digitalizing-Prescription-Image PIRDS - Prescription Image Recognition and Digit
 2 May 11, 2022
2 May 11, 2022
Select range and every time the screen changes, OCR is activated.
ASOCR(Auto Screen OCR) Select range and every time you press Space key, OCR is activated. 範囲を選ぶと、あなたがスペースキーを押すたびに、画面が変わる度にOCRが起動します。 usage1: simple OC
 1 Feb 13, 2022
1 Feb 13, 2022

OCR, Object Detection, Number Plate, Real Time
README.md PrePareded anaconda env requirements.txt clova AI → deep text recognition → trained weights (ex, .pth) wpod-net weights (ex, .h5 , .json) ht
 7 Dec 6, 2022
7 Dec 6, 2022
Python tool that takes the OCR.space JSON output as input and draws a text overlay on top of the image.
OCR.space OCR Result Checker = Draw OCR overlay on top of image Python tool that takes the OCR.space JSON output as input, and draws an overlay on to
 4 Oct 18, 2022
4 Oct 18, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
327 Jan 1, 2023
This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transformer"
FlatTN This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transfor
 74 Nov 28, 2022
74 Nov 28, 2022
This pyhton script converts a pdf to Image then using tesseract as OCR engine converts Image to Text
Script_Convertir_PDF_IMG_TXT Este script de pyhton convierte un pdf en Imagen luego utilizando tesseract como motor OCR convierte la Imagen a Texto. p
 1 Jan 27, 2022
1 Jan 27, 2022
This repo provides a package to automatically select a random seed based on ancient Chinese Xuanxue
🤞 Random Luck Deep learning is acturally the alchemy. This repo provides a package to automatically select a random seed based on ancient Chinese Xua
 33 Jan 3, 2023
33 Jan 3, 2023
Simple and understandable swin-transformer OCR project
swin-transformer-ocr ocr with swin-transformer Overview Simple and understandable swin-transformer OCR project. The model in this repository heavily r
 67 Dec 31, 2022
67 Dec 31, 2022

OCR-ID-Card VietNamese (new id-card)
OCR-ID-Card VietNamese (new id-card) run project: download 2 file weights and pu
 12 Jun 15, 2022
12 Jun 15, 2022
OCR-D wrapper for detectron2 based segmentation models
ocrd_detectron2 OCR-D wrapper for detectron2 based segmentation models Introduction Installation Usage OCR-D processor interface ocrd-detectron2-segm
 13 Dec 6, 2022
13 Dec 6, 2022

Meta Self-learning for Multi-Source Domain Adaptation: A Benchmark
Meta Self-Learning for Multi-Source Domain Adaptation: A Benchmark Project | Arxiv | YouTube | | Abstract In recent years, deep learning-based methods
 188 Dec 12, 2022
188 Dec 12, 2022

T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets
T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets (product titles, images, comments, etc.).
 55 Nov 22, 2022
55 Nov 22, 2022
[AI6122] Text Data Management & Processing
[AI6122] Text Data Management & Processing is an elective course of MSAI, SCSE, NTU, Singapore. The repository corresponds to the AI6122 of Semester 1, AY2021-2022, starting from 08/2021. The instructor of this course is Prof. Sun Aixin.
 1 Jan 17, 2022
1 Jan 17, 2022
A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
DeepKE is a knowledge extraction toolkit supporting low-resource and document-level scenarios for entity, relation and attribute extraction. We provide comprehensive documents, Google Colab tutorials, and online demo for beginners.
 1.6k Jan 5, 2023
1.6k Jan 5, 2023
Python-zhuyin - An open source Python library that provides a unified interface for converting between Chinese pinyin and Zhuyin (bopomofo)
Python-zhuyin - An open source Python library that provides a unified interface for converting between Chinese pinyin and Zhuyin (bopomofo)
 2 Dec 29, 2022
2 Dec 29, 2022
2021 AI CUP Competition on Traditional Chinese Scene Text Recognition - Intermediate Contest
繁體中文場景文字辨識 程式碼說明 組別:這就是我 成員:蔣明憲 唐碩謙 黃玥菱 林冠霆 蕭靖騰 目錄 環境套件 安裝方式 資料夾布局 前處理-製作偵測訓練註解檔 前處理-製作分類訓練樣本 part.py : 從 json 裁切出分類訓練樣本 Class.py : 將切出來的樣本按照文字分類到各資料夾
 3 Jan 14, 2022
3 Jan 14, 2022
Huawei firewall automatically updates Chinese ip to target IP group.
Huawei firewall automatically updates Chinese ip to target IP group.
 0 Jan 11, 2022
0 Jan 11, 2022
ASCEND Chinese-English code-switching dataset
ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong.
 11 Dec 9, 2022
11 Dec 9, 2022
A series of Jupyter notebooks with Chinese comment that walk you through the fundamentals of Machine Learning and Deep Learning in python using Scikit-Learn and TensorFlow.
Hands-on-Machine-Learning 目的 这份笔记旨在帮助中文学习者以一种较快较系统的方式入门机器学习, 是在学习Hands-on Machine Learning with Scikit-Learn and TensorFlow这本书的 时候做的个人笔记: 此项目的可取之处 原书的
 1.5k Dec 21, 2022
1.5k Dec 21, 2022

Anki Cards for the HSK vocabulary Chinese-German
Anki-HanyuShuipingKaoshi Anki Cards for the HSK vocabulary Chinese-German Das Deck baut auf folgenden Quellen auf: China Endecken Wortschatz von wohok
 1 Jan 7, 2022
1 Jan 7, 2022
Using BERT+Bi-LSTM+CRF
Chinese Medical Entity Recognition Based on BERT+Bi-LSTM+CRF Step 1 I share the dataset on my google drive, please download the whole 'CCKS_2019_Task1
 55 Dec 21, 2022
55 Dec 21, 2022
Ddddocr - 通用验证码识别OCR pypi版
带带弟弟OCR通用验证码识别SDK免费开源版 今天ddddocr又更新啦! 当前版本为1.3.1 想必很多做验证码的新手,一定头疼碰到点选类型的图像,做样本费时
 4.4k Dec 31, 2022
4.4k Dec 31, 2022

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023
A bot that plays TFT using OCR. Keeps track of bench, board, items, and plays the user defined team comp.
NOTES: To ensure best results, make sure you are running this on a computer that has decent specs. 1920x1080 fullscreen is required in League, game mu
 125 Dec 30, 2022
125 Dec 30, 2022
Fine tuning keras-ocr python package with custom synthetic dataset from scratch
OCR-Pipeline-with-Keras The keras-ocr package generally consists of two parts: a Detector and a Recognizer: Detector is responsible for creating bound
 1 Jan 5, 2022
1 Jan 5, 2022
YACLC - Yet Another Chinese Learner Corpus
汉语学习者文本多维标注数据集YACLC V1.0 中文 | English 汉语学习者文本多维标注数据集(Yet Another Chinese Learner
 47 Dec 15, 2022
47 Dec 15, 2022

This repository contains datasets and baselines for benchmarking Chinese text recognition.
Benchmarking-Chinese-Text-Recognition This repository contains datasets and baselines for benchmarking Chinese text recognition. Please see the corres
 254 Dec 30, 2022
254 Dec 30, 2022
Chinese-specific configuration to improve your favorite DNS server
Dnsmasq-china-list - Chinese-specific configuration to improve your favorite DNS server. Best partner for chnroutes.
 4.6k Jan 3, 2023
4.6k Jan 3, 2023

A supercharged version of paperless: scan, index and archive all your physical documents
Paperless-ng Paperless (click me) is an application by Daniel Quinn and contributors that indexes your scanned documents and allows you to easily sear
 5.3k Jan 9, 2023
5.3k Jan 9, 2023
Omdena-abuja-anpd - Automatic Number Plate Detection for the security of lives and properties using Computer Vision.
Omdena-abuja-anpd - Automatic Number Plate Detection for the security of lives and properties using Computer Vision.
 1 Jan 1, 2022
1 Jan 1, 2022

IDCARD-VERIFYING-SYSTEM - The "IDCARD VERIFYING SYSTEM" uses the Google's latest version of Tesseract OCR[Optical Character Recognition]
IDCARD VERIFYING SYSTEM The "IDCARD VERIFYING SYSTEM" uses the Google's latest v
 1 Dec 31, 2021
1 Dec 31, 2021
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. ocrmypdf
 8k Jan 8, 2023
8k Jan 8, 2023
GCRC: A Gaokao Chinese Reading Comprehension dataset for interpretable Evaluation
GCRC GCRC: A New Challenging MRC Dataset from Gaokao Chinese for Explainable Eva
 5 Nov 4, 2022
5 Nov 4, 2022

Highlight Translator can help you translate the words quickly and accurately.
Highlight Translator can help you translate the words quickly and accurately. By only highlighting, copying, or screenshoting the content you want to translate anywhere on your computer (ex. PDF, PPT, WORD etc.), the translated results will then be automatically displayed before you.
 48 Dec 21, 2022
48 Dec 21, 2022
This wrapper now has async support, its basically the same except it uses asyncio
This is a python wrapper for my api api_url = "https://api.dhravya.me/" This wrapper now has async support, its basically the same except it uses asyn
 5 Mar 10, 2022
5 Mar 10, 2022

A tool combining EasyOCR and LaMa to automatically detect text and replace it with an inpainted background.
EasyLaMa (WIP) This is a tool combining EasyOCR and LaMa to automatically detect text and replace it with an inpainted background. Installation For GP
 3 Sep 17, 2022
3 Sep 17, 2022
EmoTag helps you train emotion detection model for Chinese audios
emoTag emoTag helps you train emotion detection model for Chinese audios. Environment pip install -r requirement.txt Data We used Emotional Speech Dat
 4 Sep 7, 2022
4 Sep 7, 2022
轻量级公式 OCR 小工具:一键识别各类公式图片,并转换为 LaTeX 格式
QC-Formula | 青尘公式 OCR 介绍 轻量级开源公式 OCR 小工具:一键识别公式图片,并转换为 LaTeX 格式。 支持从 电脑本地 导入公式图片;(后续版本将支持直接从网页导入图片) 公式图片支持 .png / .jpg / .bmp,大小为 4M 以内均可; 支持印刷体及手写体,前
 26 Jan 7, 2023
26 Jan 7, 2023
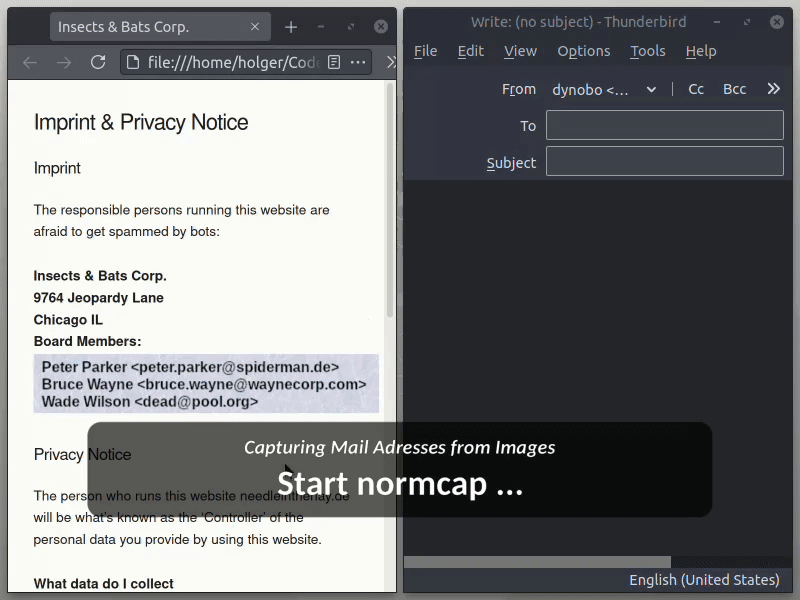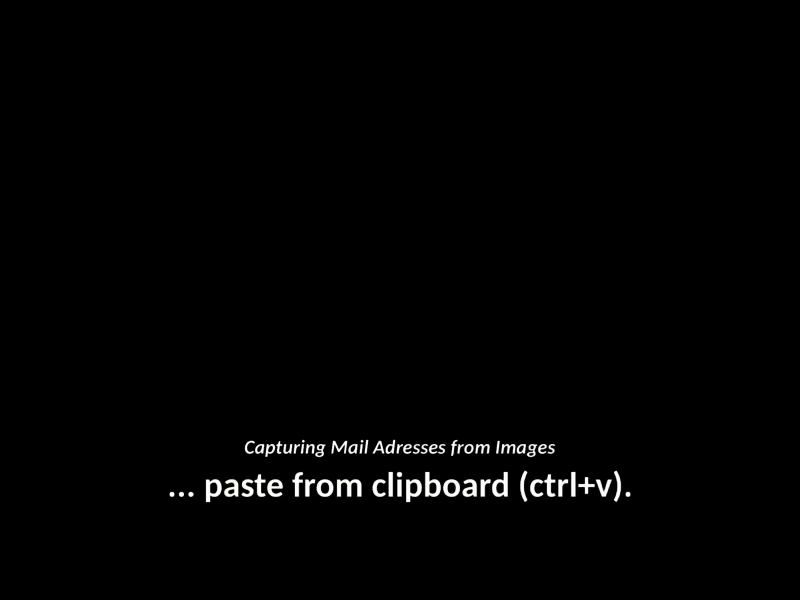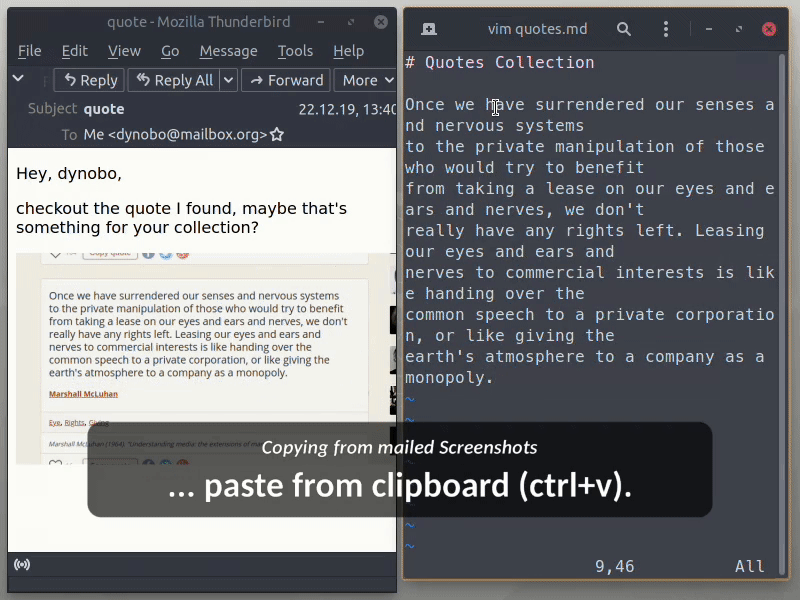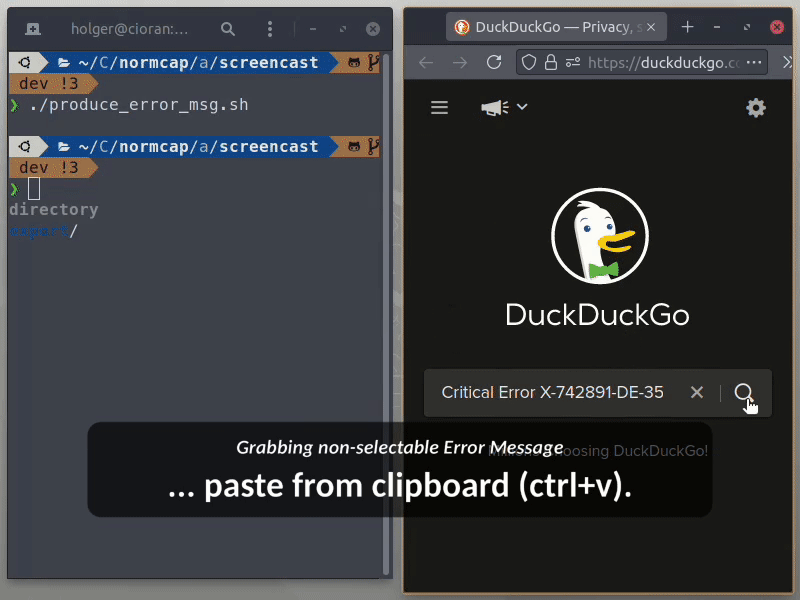
OCR powered screen-capture tool to capture information instead of images
NormCap OCR powered screen-capture tool to capture information instead of images. Links: Repo | PyPi | Releases | Changelog | FAQs Content: Quickstart
 575 Dec 31, 2022
575 Dec 31, 2022
A unified tokenization tool for Images, Chinese and English.
ICE Tokenizer Token id [0, 20000) are image tokens. Token id [20000, 20100) are common tokens, mainly punctuations. E.g., icetk[20000] == 'unk', ice
 42 Dec 27, 2022
42 Dec 27, 2022
A 30000+ Chinese MRC dataset - Delta Reading Comprehension Dataset
Delta Reading Comprehension Dataset 台達閱讀理解資料集 Delta Reading Comprehension Dataset (DRCD) 屬於通用領域繁體中文機器閱讀理解資料集。 本資料集期望成為適用於遷移學習之標準中文閱讀理解資料集。 本資料集從2,108篇
 272 Dec 15, 2022
272 Dec 15, 2022
A Telegram bot to index Chinese and Japanese group contents, works with @lilydjwg/luoxu.
luoxu-bot luoxu-bot 是类似于 luoxu-web 的 CJK 友好的 Telegram Bot,依赖于 luoxu 所创建的后端。 测试环境 Python 3.7.9 pip 21.1.2 开发中使用到的 Telethon 需要 Python 3+ 配置 前往 luoxu 根据相
 10 Nov 18, 2022
10 Nov 18, 2022
Chinese license plate recognition
AgentCLPR 简介 一个基于 ONNXRuntime、AgentOCR 和 License-Plate-Detector 项目开发的中国车牌检测识别系统。 车牌识别效果 支持多种车牌的检测和识别(其中单层车牌识别效果较好): 单层车牌: [[[[373, 282], [69, 284],
 26 Dec 25, 2022
26 Dec 25, 2022
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
 3k Jan 2, 2023
3k Jan 2, 2023
Chinese named entity recognization with BiLSTM using Keras
Chinese named entity recognization (Bilstm with Keras) Project Structure ./ ├── README.md ├── data │ ├── README.md │ ├── data 数据集 │ │ ├─
 1 Dec 17, 2021
1 Dec 17, 2021
Chinese named entity recognization (bert/roberta/macbert/bert_wwm with Keras)
Chinese named entity recognization (bert/roberta/macbert/bert_wwm with Keras)
2 Jul 5, 2022
Chinese Named Entity Recognization (BiLSTM with PyTorch)
BiLSTM-CRF for Name Entity Recognition PyTorch version A PyTorch implemention of Bi-LSTM-CRF model for Chinese Named Entity Recognition. 使用 PyTorch 实现
5 Jun 1, 2022
Chinese NER with albert/electra or other bert descendable model (keras)
Chinese NLP (albert/electra with Keras) Named Entity Recognization Project Structure ./ ├── NER │ ├── __init__.py │ ├── log
2 Nov 20, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 342 Jan 5, 2023
342 Jan 5, 2023
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
Demo processor to illustrate OCR-D Python API
ocrd_vandalize/ Demo processor to illustrate the OCR-D/core Python API Description :TODO: write docs :) Installation From PyPI pip3 install ocrd_vanda
 5 May 5, 2022
5 May 5, 2022
Educational application aimed at automating user-defined workflows for the mobile game, "Granblue Fantasy", using a variety of CV technologies in the backend such as OpenCV, PyAutoGUI and EasyOCR and a frontend coded in Typescript.
Granblue Automation using Template Matching (It is like Full Auto, but with Full Customization!) Discord here: https://discord.gg/5Yv4kqjAbm Android v
 71 Dec 30, 2022
71 Dec 30, 2022

Convert PDF/Image to TXT using EasyOcr - the best OCR engine available!
PDFImage2TXT - DOWNLOAD INSTALLER HERE What can you do with it? Convert scanned PDFs to TXT. Convert scanned Documents to TXT. No coding required!! In
 2 Feb 22, 2022
2 Feb 22, 2022
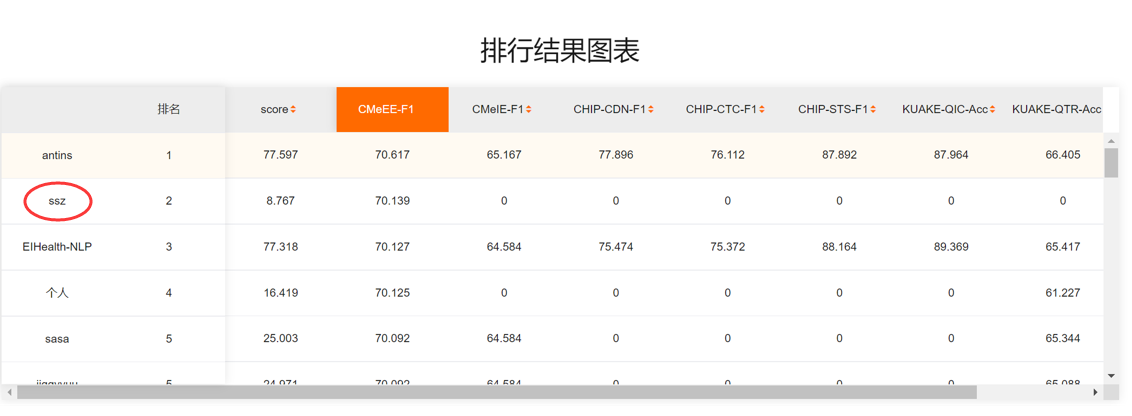
Nested Named Entity Recognition for Chinese Biomedical Text
CBio-NAMER CBioNAMER (Nested nAMed Entity Recognition for Chinese Biomedical Text) is our method used in CBLUE (Chinese Biomedical Language Understand
 8 Dec 25, 2022
8 Dec 25, 2022

A little but useful tool to explore OCR data extracted with `pytesseract` and `opencv`
Screenshot OCR Tool Extracting data from screen time screenshots in iOS and Android. We are exploring 3 options: Simple OCR with no text position usin
 1 Dec 7, 2021
1 Dec 7, 2021
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022
100+ Chinese Word Vectors 上百种预训练中文词向量
Chinese Word Vectors 中文词向量 中文 This project provides 100+ Chinese Word Vectors (embeddings) trained with different representations (dense and sparse),
 10.4k Jan 9, 2023
10.4k Jan 9, 2023

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
463 Dec 30, 2022
FOTS Pytorch Implementation
News!!! Recognition branch now is added into model. The whole project has beed optimized and refactored. ICDAR Dataset SynthText 800K Dataset detectio
 599 Dec 19, 2022
599 Dec 19, 2022

Bayesian inference for Permuton-induced Chinese Restaurant Process (NeurIPS2021).
Permuton-induced Chinese Restaurant Process Note: Currently only the Matlab version is available, but a Python version will be available soon! This is
 3 Dec 17, 2022
3 Dec 17, 2022
Indonesian ID Card OCR using tesseract OCR
KTP OCR Indonesian ID Card OCR using tesseract OCR KTP OCR is python-flask with tesseract web application to convert Indonesian ID Card to text / JSON
 5 Dec 6, 2021
5 Dec 6, 2021

The open source extract transaction infomation by using OCR.
Transaction OCR Mã nguồn trích xuất thông tin transaction từ file scaned pdf, ở đây tôi lựa chọn tài liệu sao kê công khai của Thuy Tien. Mã nguồn có
 18 Jun 2, 2022
18 Jun 2, 2022
Source Code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chinese Question Matching
Description The source code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chin
 3 Jun 28, 2022
3 Jun 28, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
OpenMMLab Text Detection, Recognition and Understanding Toolbox
Introduction English | 简体中文 MMOCR is an open-source toolbox based on PyTorch and mmdetection for text detection, text recognition, and the correspondi
 3k Jan 7, 2023
3k Jan 7, 2023

OCR Streamlit App is used to extract text from images using python's easyocr, pytorch and streamlit packages
OCR-Streamlit-App OCR Streamlit App is used to extract text from images using python's easyocr, pytorch and streamlit packages OCR app gets an image a
 5 Apr 5, 2022
5 Apr 5, 2022
An Unsupervised Detection Framework for Chinese Jargons in the Darknet
An Unsupervised Detection Framework for Chinese Jargons in the Darknet This repo is the Python 3 implementation of 《An Unsupervised Detection Framewor
 7 Nov 8, 2022
7 Nov 8, 2022

Apply different text recognition services to images of handwritten documents.
Handprint The Handwritten Page Recognition Test is a command-line program that invokes HTR (handwritten text recognition) services on images of docume
 117 Jan 2, 2023
117 Jan 2, 2023

A demo of chinese asr
chinese_asr_demo 一个端到端的中文语音识别模型训练、测试框架 具备数据预处理、模型训练、解码、计算wer等等功能 训练数据 训练数据采用thchs_30,
 4 Dec 9, 2021
4 Dec 9, 2021

Learning Chinese Character style with conditional GAN
zi2zi: Master Chinese Calligraphy with Conditional Adversarial Networks Introduction Learning eastern asian language typefaces with GAN. zi2zi(字到字, me
 2.2k Jan 2, 2023
2.2k Jan 2, 2023
A socket script to obtain chinese phones-sequence for any english word
Foreign Pronunciation Generator (English-Chinese) We provide a simple socket script for acquiring Chinese pronunciation of English words (phones in ai
 5 Jul 25, 2022
5 Jul 25, 2022

Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition
Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition | paper | dataset | pretrained detection model | Authors: Yi-Chang Che
1 Aug 23, 2022

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE: A Benchmark Suite for Data-centric NLP You can get the english version of README. 以数据为中心的AI测评(DataCLUE) 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE
 135 Dec 22, 2022
135 Dec 22, 2022
ChirpText is a collection of text processing tools for Python 3.
ChirpText is a collection of text processing tools for Python 3. It is not meant to be a powerful tank like the popular NTLK but a small package which
 5 Nov 30, 2022
5 Nov 30, 2022
OCR of Chicago 1909 Renumbering Plan
Requirements: Python 3 (probably at least 3.4) pipenv (pip3 install pipenv) tesseract (brew install tesseract, at least if you have a mac and homebrew
 2 Nov 21, 2021
2 Nov 21, 2021

Chinese Advertisement Board Identification(Pytorch)
Chinese-Advertisement-Board-Identification. We use YoloV5 to extract the ROI of the location of the chinese word. Next, we sort the bounding box and recognize every chinese words which we extracted. The methods which we use are Yolov5, ArgMargin and Focal loss.
 12 Jul 21, 2022
12 Jul 21, 2022

This is a GUI for scrapping PDFs with the help of optical character recognition making easier than ever to scrape PDFs.
pdf-scraper-with-ocr With this tool I am aiming to facilitate the work of those who need to scrape PDFs either by hand or using tools that doesn't imp
 75 Oct 21, 2022
75 Oct 21, 2022
Chinese Pre-Trained Language Models (CPM-LM) Version-I
CPM-Generate 为了促进中文自然语言处理研究的发展,本项目提供了 CPM-LM (2.6B) 模型的文本生成代码,可用于文本生成的本地测试,并以此为基础进一步研究零次学习/少次学习等场景。[项目首页] [模型下载] [技术报告] 若您想使用CPM-1进行推理,我们建议使用高效推理工具BMI
 1.4k Jan 3, 2023
1.4k Jan 3, 2023

OCR Post Correction for Endangered Language Texts
📌 Coming soon: an update to the software including features from our paper on semi-supervised OCR post-correction, to be published in the Transaction
 96 Dec 31, 2022
96 Dec 31, 2022
Python-based tools for document analysis and OCR
ocropy OCRopus is a collection of document analysis programs, not a turn-key OCR system. In order to apply it to your documents, you may need to do so
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
 176 Nov 28, 2022
176 Nov 28, 2022
Tools for manipulating and evaluating the hOCR format for representing multi-lingual OCR results by embedding them into HTML.
hocr-tools About About the code Installation System-wide with pip System-wide from source virtualenv Available Programs hocr-check -- check the hOCR f
285 Dec 8, 2022
Classical OCR DCNN reproduction based on PaddlePaddle framework.
Paddle-SVHN Classical OCR DCNN reproduction based on PaddlePaddle framework. This project reproduces Multi-digit Number Recognition from Street View I
 1 Nov 12, 2021
1 Nov 12, 2021
This is a implementation of CRAFT OCR method
This is a implementation of CRAFT OCR method
 0 Nov 1, 2021
0 Nov 1, 2021
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
 1.6k Jan 3, 2023
1.6k Jan 3, 2023
A PyTorch implementation of unsupervised SimCSE
A PyTorch implementation of unsupervised SimCSE
 99 Dec 23, 2022
99 Dec 23, 2022
This is a GUI for scrapping PDFs with the help of optical character recognition making easier than ever to scrape PDFs.
pdf-scraper-with-ocr With this tool I am aiming to facilitate the work of those who need to scrape PDFs either by hand or using tools that doesn't imp
75 Oct 21, 2022
Dirty, ugly, and hopefully useful OCR of Facebook Papers docs released by Gizmodo
Quick and Dirty OCR of Facebook Papers Gizmodo has been working through the Facebook Papers and releasing the docs that they process and review. As lu
 2 Oct 28, 2021
2 Oct 28, 2021
Generate custom detailed survey paper with topic clustered sections and proper citations, from just a single query in just under 30 mins !!
Auto-Research A no-code utility to generate a detailed well-cited survey with topic clustered sections (draft paper format) and other interesting arti
 20 Dec 14, 2022
20 Dec 14, 2022
Chinese Grammatical Error Diagnosis
nlp-CGED Chinese Grammatical Error Diagnosis 中文语法纠错研究 基于序列标注的方法 所需环境 Python==3.6 tensorflow==1.14.0 keras==2.3.1 bert4keras==0.10.6 笔者使用了开源的bert4keras
 12 Nov 25, 2022
12 Nov 25, 2022
A Vietnamese personal card OCR website built with Django.
Django VietCardOCR Installation Creation of virtual environments is done by executing the command venv: python -m venv venv That will create a new fol
 4 Sep 4, 2021
4 Sep 4, 2021