697 Repositories
Python dataset-creation Libraries
Source codes for Improved Few-Shot Visual Classification (CVPR 2020), Enhancing Few-Shot Image Classification with Unlabelled Examples
Source codes for Improved Few-Shot Visual Classification (CVPR 2020), Enhancing Few-Shot Image Classification with Unlabelled Examples (WACV 2022) and Beyond Simple Meta-Learning: Multi-Purpose Models for Multi-Domain, Active and Continual Few-Shot Learning (TPAMI 2022 - in submission)
 42 Dec 6, 2022
42 Dec 6, 2022
A curated list of awesome game datasets, and tools to artificial intelligence in games
🎮 Awesome Game Datasets In computer science, Artificial Intelligence (AI) is intelligence demonstrated by machines. Its definition, AI research as th
 454 Jan 3, 2023
454 Jan 3, 2023
A Small and Easy approach to the BraTS2020 dataset (2D Segmentation)
BraTS2020 A Light & Scalable Solution to BraTS2020 | Medical Brain Tumor Segmentation (2D Segmentation) Developed the segmentation models for segregat
 0 Jan 19, 2022
0 Jan 19, 2022
Simple helper library to convert a collection of numpy data to tfrecord, and build a tensorflow dataset from the tfrecord.
numpy2tfrecord Simple helper library to convert a collection of numpy data to tfrecord, and build a tensorflow dataset from the tfrecord. Installation
 2 Jan 16, 2022
2 Jan 16, 2022

LEDNet: A Lightweight Encoder-Decoder Network for Real-time Semantic Segmentation
LEDNet: A Lightweight Encoder-Decoder Network for Real-time Semantic Segmentation Table of Contents: Introduction Project Structure Installation Datas
 492 Dec 2, 2022
492 Dec 2, 2022
Files for a tutorial to train SegNet for road scenes using the CamVid dataset
SegNet and Bayesian SegNet Tutorial This repository contains all the files for you to complete the 'Getting Started with SegNet' and the 'Bayesian Seg
 800 Dec 31, 2022
800 Dec 31, 2022
classify fashion-mnist dataset with pytorch
Fashion-Mnist Classifier with PyTorch Inference 1- clone this repository: git clone https://github.com/Jhamed7/Fashion-Mnist-Classifier.git 2- Instal
 1 Jan 14, 2022
1 Jan 14, 2022
Semantic Segmentation with SegFormer on Drone Dataset.
SegFormer_Segmentation Semantic Segmentation with SegFormer on Drone Dataset. You can check out the blog on Medium You can also try out the model with
 8 Oct 20, 2022
8 Oct 20, 2022

Using the provided dataset which includes various book features, in order to predict the price of books, using various proposed methods and models.
Using the provided dataset which includes various book features, in order to predict the price of books, using various proposed methods and models.
 1 Jan 13, 2022
1 Jan 13, 2022

Testing-crud-login-drf - Creation of an application in django on music albums
testing-crud-login-drf Creation of an application in django on music albums Befo
 1 Jan 11, 2022
1 Jan 11, 2022

Sentiment-Analysis and EDA on the IMDB Movie Review Dataset
Sentiment-Analysis and EDA on the IMDB Movie Review Dataset The main part of the work focuses on the exploration and study of different approaches whi
1 Jan 12, 2022
Exploratory Data Analysis of the 2019 Indian General Elections using a dataset from Kaggle.
2019-indian-election-eda Exploratory Data Analysis of the 2019 Indian General Elections using a dataset from Kaggle. This project is a part of the Cou
 5 Oct 10, 2022
5 Oct 10, 2022
I explore rock vs. mine prediction using a SONAR dataset
I explore rock vs. mine prediction using a SONAR dataset. Using a Logistic Regression Model for my prediction algorithm, I intend on predicting what an object is based on supervised learning.
 1 Jan 11, 2022
1 Jan 11, 2022

Contains analysis of trends from Fitbit Dataset (source: Kaggle) to see how the trends can be applied to Bellabeat customers and Bellabeat products
Contains analysis of trends from Fitbit Dataset (source: Kaggle) to see how the trends can be applied to Bellabeat customers and Bellabeat products.
 2 Jan 12, 2022
2 Jan 12, 2022

FS2KToolbox FS2K Dataset Towards the translation between Face
FS2KToolbox FS2K Dataset Towards the translation between Face -- Sketch. Download (photo+sketch+annotation): Google-drive, Baidu-disk, pw: FS2K. For
 5 Jan 3, 2023
5 Jan 3, 2023
The dataset of tweets pulling from Twitters with keyword: Hydroxychloroquine, location: US, Time: 2020
HCQ_Tweet_Dataset: FREE to Download. Keywords: HCQ, hydroxychloroquine, tweet, twitter, COVID-19 This dataset is associated with the paper "Understand
 2 Mar 16, 2022
2 Mar 16, 2022

Using knowledge-informed machine learning on the PRONOSTIA (FEMTO) and IMS bearing data sets. Predict remaining-useful-life (RUL).
Knowledge Informed Machine Learning using a Weibull-based Loss Function Exploring the concept of knowledge-informed machine learning with the use of a
 43 Dec 14, 2022
43 Dec 14, 2022
This is the source code for generating the ASL-Skeleton3D and ASL-Phono datasets. Check out the README.md for more details.
ASL-Skeleton3D and ASL-Phono Datasets Generator The ASL-Skeleton3D contains a representation based on mapping into the three-dimensional space the coo
 5 Nov 20, 2022
5 Nov 20, 2022

UFPR-ADMR-v2 Dataset
UFPR-ADMR-v2 Dataset The UFPR-ADMRv2 dataset contains 5,000 dial meter images obtained on-site by employees of the Energy Company of Paraná (Copel), w
 8 Sep 29, 2022
8 Sep 29, 2022
ASCEND Chinese-English code-switching dataset
ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong.
 11 Dec 9, 2022
11 Dec 9, 2022
A music comments dataset, containing 39,051 comments for 27,384 songs.
Music Comments Dataset A music comments dataset, containing 39,051 comments for 27,384 songs. For academic research use only. Introduction This datase
 2 Jan 10, 2022
2 Jan 10, 2022

Text classification on IMDB dataset using Keras and Bi-LSTM network
Text classification on IMDB dataset using Keras and Bi-LSTM Text classification on IMDB dataset using Keras and Bi-LSTM network. Usage python3 main.py
 2 Sep 27, 2022
2 Sep 27, 2022
🎁 3,000,000+ Unsplash images made available for research and machine learning
The Unsplash Dataset The Unsplash Dataset is made up of over 250,000+ contributing global photographers and data sourced from hundreds of millions of
 2k Jan 3, 2023
2k Jan 3, 2023

DeepFashion2 is a comprehensive fashion dataset.
DeepFashion2 Dataset DeepFashion2 is a comprehensive fashion dataset. It contains 491K diverse images of 13 popular clothing categories from both comm
 1.8k Jan 7, 2023
1.8k Jan 7, 2023
FMA: A Dataset For Music Analysis
FMA: A Dataset For Music Analysis Michaël Defferrard, Kirell Benzi, Pierre Vandergheynst, Xavier Bresson. International Society for Music Information
 1.8k Dec 29, 2022
1.8k Dec 29, 2022
Full LAKH MIDI dataset converted to MuseNet MIDI output format (9 instruments + drums)
LAKH MuseNet MIDI Dataset Full LAKH MIDI dataset converted to MuseNet MIDI output format (9 instruments + drums) Bonus: Choir on Channel 10 Please CC
 6 Nov 20, 2022
6 Nov 20, 2022

Image based Human Fall Detection
Here I integrated the YOLOv5 object detection algorithm with my own created dataset which consists of human activity images to achieve low cost, high accuracy, and real-time computing requirements
 12 Dec 11, 2022
12 Dec 11, 2022

simple_pytorch_example project is a toy example of a python script that instantiates and trains a PyTorch neural network on the FashionMNIST dataset
simple_pytorch_example project is a toy example of a python script that instantiates and trains a PyTorch neural network on the FashionMNIST dataset
 1 Jan 7, 2022
1 Jan 7, 2022

A simple flask application to collect annotations for the Turing Change Point Dataset, a benchmark dataset for change point detection algorithms
AnnotateChange Welcome to the repository of the "AnnotateChange" application. This application was created to collect annotations of time series data
 16 Jul 21, 2022
16 Jul 21, 2022
Código para trabalho com o dataset Wine em Python
Um perceptron multicamadas (MLP) é uma rede neural artificial feedforward que gera um conjunto de saídas a partir de um conjunto de entradas. Um MLP é
 1 Jan 8, 2022
1 Jan 8, 2022
A generator of point clouds dataset for PyPipes.
CloudPipesGenerator Documentation | Colab Notebooks | Video Tutorials | Master Degree website A generator of point clouds dataset for PyPipes. TODO Us
 1 Jan 13, 2022
1 Jan 13, 2022

Official re-implementation of the Calibrated Adversarial Refinement model described in the paper Calibrated Adversarial Refinement for Stochastic Semantic Segmentation
Official re-implementation of the Calibrated Adversarial Refinement model described in the paper Calibrated Adversarial Refinement for Stochastic Semantic Segmentation
 31 Nov 22, 2022
31 Nov 22, 2022

Customer Service Requests Analysis is one of the practical life problems that an analyst may face. This Project is one such take. The project is a beginner to intermediate level project. This repository has a Source Code, README file, Dataset, Image and License file.
Customer Service Requests Analysis Project 1 DESCRIPTION Background of Problem Statement : NYC 311's mission is to provide the public with quick and e
 7 Sep 19, 2022
7 Sep 19, 2022
deep learning model with only python and numpy with test accuracy 99 % on mnist dataset and different optimization choices
deep_nn_model_with_only_python_100%_test_accuracy deep learning model with only python and numpy with test accuracy 99 % on mnist dataset and differen
 0 Aug 28, 2022
0 Aug 28, 2022
Python module used to generate random facts
Randfacts is a python library that generates random facts. You can use randfacts.get_fact() to return a random fun fact. Disclaimer: Facts are not gua
 14 Dec 14, 2022
14 Dec 14, 2022

Bottom-up attention model for image captioning and VQA, based on Faster R-CNN and Visual Genome
bottom-up-attention This code implements a bottom-up attention model, based on multi-gpu training of Faster R-CNN with ResNet-101, using object and at
 1.3k Jan 9, 2023
1.3k Jan 9, 2023

TensorFlow implementation of AlexNet and its training and testing on ImageNet ILSVRC 2012 dataset
AlexNet training on ImageNet LSVRC 2012 This repository contains an implementation of AlexNet convolutional neural network and its training and testin
 161 Nov 25, 2022
161 Nov 25, 2022

U-Net Implementation: Convolutional Networks for Biomedical Image Segmentation" using the Carvana Image Masking Dataset in PyTorch
U-Net Implementation By Christopher Ley This is my interpretation and implementation of the famous paper "U-Net: Convolutional Networks for Biomedical
 1 Jan 6, 2022
1 Jan 6, 2022
NLP techniques such as named entity recognition, sentiment analysis, topic modeling, text classification with Python to predict sentiment and rating of drug from user reviews.
This file contains the following documents sumbited for Baruch CIS9665 group 9 fall 2021. 1. Dataset: drug_reviews.csv 2. python codes for text classi
 2 Jan 4, 2023
2 Jan 4, 2023
Fine tuning keras-ocr python package with custom synthetic dataset from scratch
OCR-Pipeline-with-Keras The keras-ocr package generally consists of two parts: a Detector and a Recognizer: Detector is responsible for creating bound
 1 Jan 5, 2022
1 Jan 5, 2022
Automated Exploration Data Analysis on a financial dataset
Automated EDA on financial dataset Just a simple way to get automated Exploration Data Analysis from financial dataset (OHLCV) using Streamlit and ta.
 28 Nov 27, 2022
28 Nov 27, 2022

Streamlit app demonstrating an image browser for the Udacity self-driving-car dataset with realtime object detection using YOLO.
Streamlit Demo: The Udacity Self-driving Car Image Browser This project demonstrates the Udacity self-driving-car dataset and YOLO object detection in
 992 Jan 4, 2023
992 Jan 4, 2023
G-Research-Crypto-Competition - Project for passing the ML exam. Dataset took from the competition on the kaggle
G-Research-Crypto-Competition Project for passing the ML exam. Dataset took from
 5 Jan 9, 2022
5 Jan 9, 2022
KIND: an Italian Multi-Domain Dataset for Named Entity Recognition
KIND (Kessler Italian Named-entities Dataset) KIND is an Italian dataset for Named-Entity Recognition. It contains more than one million tokens with t
 5 Jun 21, 2022
5 Jun 21, 2022
The dataset of tweets pulling from Twitters with keyword: Hydroxychloroquine, location: US, Time: 2020
HCQ_Tweet_Dataset: FREE to Download. Keywords: HCQ, hydroxychloroquine, tweet, twitter, COVID-19 This dataset is associated with the paper "Understand
2 Mar 16, 2022

RodoSol-ALPR Dataset
RodoSol-ALPR Dataset This dataset, called RodoSol-ALPR dataset, contains 20,000 images captured by static cameras located at pay tolls owned by the Ro
 45 Dec 15, 2022
45 Dec 15, 2022
Generating synthetic mobility data for a realistic population with RNNs to improve utility and privacy
lbs-data Motivation Location data is collected from the public by private firms via mobile devices. Can this data also be used to serve the public goo
 11 Sep 22, 2022
11 Sep 22, 2022

Image Segmentation with U-Net Algorithm on Carvana Dataset using AWS Sagemaker
Image Segmentation with U-Net Algorithm on Carvana Dataset using AWS Sagemaker This is a full project of image segmentation using the model built with
 1 Jan 4, 2022
1 Jan 4, 2022
Implementations of LSTM: A Search Space Odyssey variants and their training results on the PTB dataset.
An LSTM Odyssey Code for training variants of "LSTM: A Search Space Odyssey" on Fomoro. Check out the blog post. Training Install TensorFlow. Clone th
 95 Apr 13, 2022
95 Apr 13, 2022

AsymmetricGAN - Dual Generator Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
AsymmetricGAN for Image-to-Image Translation AsymmetricGAN Framework for Multi-Domain Image-to-Image Translation AsymmetricGAN Framework for Hand Gest
 42 Jan 15, 2022
42 Jan 15, 2022

Code and dataset for AAAI 2021 paper FixMyPose: Pose Correctional Describing and Retrieval Hyounghun Kim, Abhay Zala, Graham Burri, Mohit Bansal.
FixMyPose / फिक्समाइपोज़ Code and dataset for AAAI 2021 paper "FixMyPose: Pose Correctional Describing and Retrieval" Hyounghun Kim*, Abhay Zala*, Grah
 4 Sep 19, 2022
4 Sep 19, 2022
This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detection', CVPR 2019.
Code-and-Dataset-for-CapSal This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detec
 48 Aug 19, 2022
48 Aug 19, 2022
Image segmentation with private İstanbul Dataset
Image Segmentation This repo was created for academic research and test result. Repo will update after academic article online. This repo contains wei
 9 Dec 11, 2022
9 Dec 11, 2022

Fashion Entity Classification
Fashion-Entity-Classification - Fashion-MNIST is a dataset of Zalando's article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes. Zalando intends Fashion-MNIST to serve as a direct drop-in replacement for the original MNIST dataset for benchmarking machine learning algorithms. It shares the same image size and structure of training and testing splits.
 1 Jan 4, 2022
1 Jan 4, 2022

Show-attend-and-tell - TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
 902 Nov 29, 2022
902 Nov 29, 2022
March-madness - March Madness results 1985-2021
march-madness Results for all 2,268 NCAA Division I Men's Basketball Tournament games since the modern format was introduced in 1985. Includes years,
 2 Feb 26, 2022
2 Feb 26, 2022

Research - dataset and code for 2016 paper Learning a Driving Simulator
the people's comma the paper Learning a Driving Simulator the comma.ai driving dataset 7 and a quarter hours of largely highway driving. Enough to tra
 4.1k Jan 2, 2023
4.1k Jan 2, 2023
Spark-movie-lens - An on-line movie recommender using Spark, Python Flask, and the MovieLens dataset
A scalable on-line movie recommender using Spark and Flask This Apache Spark tutorial will guide you step-by-step into how to use the MovieLens datase
 794 Dec 23, 2022
794 Dec 23, 2022
Customer-Transaction-Analysis - This analysis is based on a synthesised transaction dataset containing 3 months worth of transactions for 100 hypothetical customers.
Customer-Transaction-Analysis - This analysis is based on a synthesised transaction dataset containing 3 months worth of transactions for 100 hypothetical customers. It contains purchases, recurring transactions, and salary transactions. The dataset is designed to simulate realistic transaction behaviours that are observed in ANZ’s real transaction data.
 1 Jan 1, 2022
1 Jan 1, 2022

Advanced_Data_Visualization_Tools - The present hands-on lab mainly uses Immigration to Canada dataset and employs advanced visualization tools such as word cloud, and waffle plot to display relations between features within the dataset.
Hands-on Practice Learning Lab for Data Science Overview This hands on practice lab is a part of Data Visualization with Python course offered by Cour
 1 Jan 5, 2022
1 Jan 5, 2022

Generating .npy dataset and labels out of given image, containing numbers from 0 to 9, using opencv
basic-dataset-generator-from-image-of-numbers generating .npy dataset and labels out of given image, containing numbers from 0 to 9, using opencv inpu
 1 Jan 1, 2022
1 Jan 1, 2022
CIFAR-10_train-test - training and testing codes for dataset CIFAR-10
CIFAR-10_train-test - training and testing codes for dataset CIFAR-10
 3 Apr 26, 2022
3 Apr 26, 2022

3D dataset of humans Manipulating Objects in-the-Wild (MOW)
MOW dataset [Website] This repository maintains our 3D dataset of humans Manipulating Objects in-the-Wild (MOW). The dataset contains 512 images in th
 28 Nov 6, 2022
28 Nov 6, 2022
GCRC: A Gaokao Chinese Reading Comprehension dataset for interpretable Evaluation
GCRC GCRC: A New Challenging MRC Dataset from Gaokao Chinese for Explainable Eva
 5 Nov 4, 2022
5 Nov 4, 2022
This repo tries to recognize faces in the dataset you created
YÜZ TANIMA SİSTEMİ Bu repo oluşturacağınız yüz verisetlerini tanımaya çalışan ma
 2 Dec 30, 2021
2 Dec 30, 2021

Slice a single image into multiple pieces and create a dataset from them
OpenCV Image to Dataset Converter Slice a single image of Persian digits into mu
 14 Dec 29, 2022
14 Dec 29, 2022
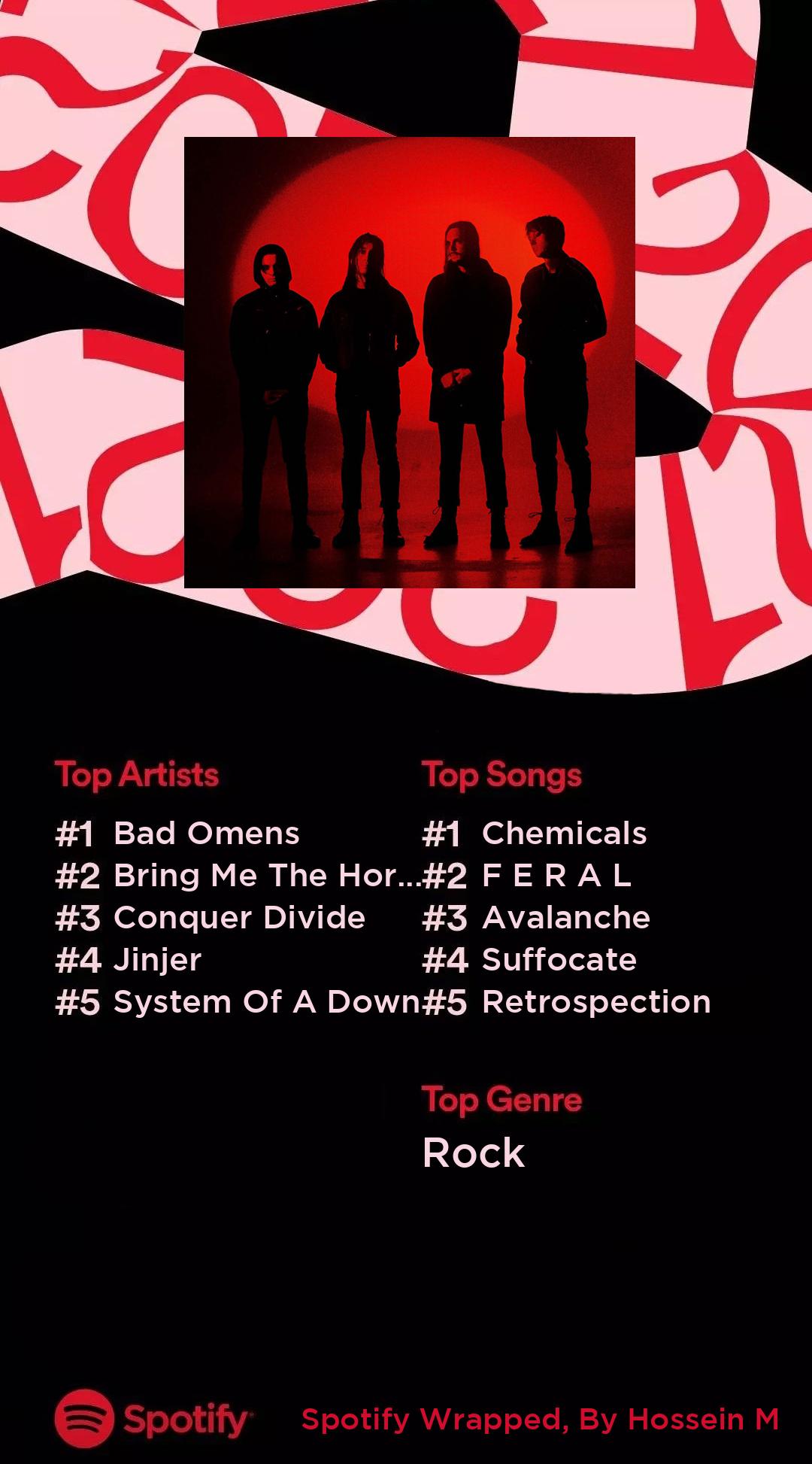
A project in order to analyze user's favorite musics, artists and genre
Spotify-Wrapped This is a project about Spotify Wrapped (which is an extra option for premium accounts, but you don't need to be premium here) This pr
 19 Jan 4, 2023
19 Jan 4, 2023
Quickly download, clean up, and install public datasets into a database management system
Finding data is one thing. Getting it ready for analysis is another. Acquiring, cleaning, standardizing and importing publicly available data is time
 274 Jan 4, 2023
274 Jan 4, 2023

N-Omniglot is a large neuromorphic few-shot learning dataset
N-Omniglot [Paper] || [Dataset] N-Omniglot is a large neuromorphic few-shot learning dataset. It reconstructs strokes of Omniglot as videos and uses D
 11 Dec 5, 2022
11 Dec 5, 2022

An Official Repo of CVPR '20 "MSeg: A Composite Dataset for Multi-Domain Segmentation"
This is the code for the paper: MSeg: A Composite Dataset for Multi-domain Semantic Segmentation (CVPR 2020, Official Repo) [CVPR PDF] [Journal PDF] J
 226 Nov 5, 2022
226 Nov 5, 2022
Visualization of the World Religion Data dataset by Correlates of War Project.
World Religion Data Visualization Visualization of the World Religion Data dataset by Correlates of War Project. Mostly personal project to famirializ
 1 Oct 15, 2022
1 Oct 15, 2022
Seems Like Everyone Is Posting This, Thought I Should Too, Tokens Get Locked Upon Creation And Im Not Going To Fix For Several Reasons
Member-Booster Seems Like Everyone Is Posting This, Thought I Should Too, Tokens Get Locked Upon Creation And Im Not Going To Fix For Several Reasons
 1 Dec 28, 2021
1 Dec 28, 2021

TensorFlow implementation of "Attention is all you need (Transformer)"
[TensorFlow 2] Attention is all you need (Transformer) TensorFlow implementation of "Attention is all you need (Transformer)" Dataset The MNIST datase
 4 Jan 5, 2022
4 Jan 5, 2022
whylogs: A Data and Machine Learning Logging Standard
whylogs: A Data and Machine Learning Logging Standard whylogs is an open source standard for data and ML logging whylogs logging agent is the easiest
 2k Jan 6, 2023
2k Jan 6, 2023
Medical-Image-Triage-and-Classification-System-Based-on-COVID-19-CT-and-X-ray-Scan-Dataset
Medical-Image-Triage-and-Classification-System-Based-on-COVID-19-CT-and-X-ray-Sc
 2 Dec 26, 2021
2 Dec 26, 2021
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size.
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size. The hub data layout enables rapid transformations and streaming of data while training models at scale. Hub is used by Google, Waymo, Red Cross, Oxford University, and Omdena.
 5.1k Jan 8, 2023
5.1k Jan 8, 2023

Sequence lineage information extracted from RKI sequence data repo
Pango lineage information for German SARS-CoV-2 sequences This repository contains a join of the metadata and pango lineage tables of all German SARS-
 24 Oct 26, 2022
24 Oct 26, 2022
Rule based classification A hotel s customers dataset
Rule-based-classification-A-hotel-s-customers-dataset- Aim: Categorize new customers by segment and predict how much revenue they can generate This re
 4 Jan 2, 2022
4 Jan 2, 2022
Datasets with Softcatalà website content
softcatala-web-dataset This repository contains Sofcatalà web site content (articles and programs descriptions). Dataset are available in the dataset
 2 Dec 26, 2021
2 Dec 26, 2021
A Pytorch loader for MVTecAD dataset.
MVTecAD A Pytorch loader for MVTecAD dataset. It strictly follows the code style of common Pytorch datasets, such as torchvision.datasets.CIFAR10. The
 1 Dec 27, 2021
1 Dec 27, 2021

🛹 Turn an SVG into an STL for stencil creation purposes
svg2stl This repository provides a script which takes as input an SVG such as this one: It outputs an STL file like this one: You can also see an inte
 3 Dec 29, 2021
3 Dec 29, 2021
Django API creation with signed requests utilizing forms for validation.
django-formapi Create JSON API:s with HMAC authentication and Django form-validation. Version compatibility See Travis-CI page for actual test results
 34 Apr 4, 2022
34 Apr 4, 2022
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation by Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zh
 8 Nov 21, 2022
8 Nov 21, 2022
Utility for Google Text-To-Speech batch audio files generator. Ideal for prompt files creation with Google voices for application in offline IVRs
Google Text-To-Speech Batch Prompt File Maker Are you in the need of IVR prompts, but you have no voice actors? Let Google talk your prompts like a pr
 1 Aug 19, 2021
1 Aug 19, 2021
objectfactory is a python package to easily implement the factory design pattern for object creation, serialization, and polymorphism
py-object-factory objectfactory is a python package to easily implement the factory design pattern for object creation, serialization, and polymorphis
 6 Dec 14, 2022
6 Dec 14, 2022

Turn any live video stream or locally stored video into a dataset of interesting samples for ML training, or any other type of analysis.
Sieve Video Data Collection Example Find samples that are interesting within hours of raw video, for free and completely automatically using Sieve API
 72 Aug 1, 2022
72 Aug 1, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
Keras implementation of PersonLab for Multi-Person Pose Estimation and Instance Segmentation.
PersonLab This is a Keras implementation of PersonLab for Multi-Person Pose Estimation and Instance Segmentation. The model predicts heatmaps and vari
 160 Dec 21, 2022
160 Dec 21, 2022
A 30000+ Chinese MRC dataset - Delta Reading Comprehension Dataset
Delta Reading Comprehension Dataset 台達閱讀理解資料集 Delta Reading Comprehension Dataset (DRCD) 屬於通用領域繁體中文機器閱讀理解資料集。 本資料集期望成為適用於遷移學習之標準中文閱讀理解資料集。 本資料集從2,108篇
 272 Dec 15, 2022
272 Dec 15, 2022
Open clone of OpenAI's unreleased WebText dataset scraper.
Open clone of OpenAI's unreleased WebText dataset scraper. This version uses pushshift.io files instead of the API for speed.
 471 Dec 30, 2022
471 Dec 30, 2022

Codes for “A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection”
DSAMNet The pytorch implementation for "A Deeply-supervised Attention Metric-based Network and an Open Aerial Image Dataset for Remote Sensing Change
 41 Dec 14, 2022
41 Dec 14, 2022

This repository provides data for the VAW dataset as described in the CVPR 2021 paper titled "Learning to Predict Visual Attributes in the Wild"
Visual Attributes in the Wild (VAW) This repository provides data for the VAW dataset as described in the CVPR 2021 Paper: Learning to Predict Visual
 36 Dec 30, 2022
36 Dec 30, 2022
This project consists of a collaborative filtering algorithm to predict movie reviews ratings from a dataset of Netflix ratings.
Collaborative Filtering - Netflix movie reviews Description This project consists of a collaborative filtering algorithm to predict movie reviews rati
 1 Dec 21, 2021
1 Dec 21, 2021
MAVE: : A Product Dataset for Multi-source Attribute Value Extraction
MAVE: : A Product Dataset for Multi-source Attribute Value Extraction The dataset contains 3 million attribute-value annotations across 1257 unique ca
 89 Jan 8, 2023
89 Jan 8, 2023

LSTM model trained on a small dataset of 3000 names written in PyTorch
LSTM model trained on a small dataset of 3000 names. Model generates names from model by selecting one out of top 3 letters suggested by model at a time until an EOS (End Of Sentence) character is not encountered.
 1 Dec 20, 2021
1 Dec 20, 2021
Le dataset des images du projet d'IA de 2021
face-mask-dataset-ilc-2021 Le dataset des images du projet d'IA de 2021, Indiquez vos id git dans la issue pour les droits TL;DR: Choisir 200 images J
 7 Nov 15, 2021
7 Nov 15, 2021
Human Activity Recognition example using TensorFlow on smartphone sensors dataset and an LSTM RNN. Classifying the type of movement amongst six activity categories - Guillaume Chevalier
LSTMs for Human Activity Recognition Human Activity Recognition (HAR) using smartphones dataset and an LSTM RNN. Classifying the type of movement amon
 3.1k Dec 30, 2022
3.1k Dec 30, 2022
TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
902 Nov 29, 2022

CPPE - 5 (Medical Personal Protective Equipment) is a new challenging object detection dataset
CPPE - 5 CPPE - 5 (Medical Personal Protective Equipment) is a new challenging dataset with the goal to allow the study of subordinate categorization
 53 Dec 17, 2022
53 Dec 17, 2022
🏆 • 5050 most frequent words in 109 languages
🏆 Most Common Words Multilingual 5000 most frequent words in 109 languages. Uses wordfrequency.info as a source. 🔗 License source code license data
 14 Nov 24, 2022
14 Nov 24, 2022