648 Repositories
Python document-search Libraries
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
 224 Jan 4, 2023
224 Jan 4, 2023

AutoGiphyMovie lets you search giphy for gifs, converts them to videos, attach a soundtrack and stitches it all together into a movie!
AutoGiphyMovie lets you search giphy for gifs, converts them to videos, attach a soundtrack and stitches it all together into a movie!
 18 Nov 13, 2022
18 Nov 13, 2022
Disentangled Face Attribute Editing via Instance-Aware Latent Space Search, accepted by IJCAI 2021.
Instance-Aware Latent-Space Search This is a PyTorch implementation of the following paper: Disentangled Face Attribute Editing via Instance-Aware Lat
 67 Dec 21, 2022
67 Dec 21, 2022
Code for NAACL 2021 full paper "Efficient Attentions for Long Document Summarization"
LongDocSum Code for NAACL 2021 paper "Efficient Attentions for Long Document Summarization" This repository contains data and models needed to reprodu
 56 Jan 2, 2023
56 Jan 2, 2023

Recon is a script to perform a full recon on a target with the main tools to search for vulnerabilities.
👑 Recon 👑 The step of recognizing a target in both Bug Bounties and Pentest can be very time-consuming. Thinking about it, I decided to create my ow
 171 Dec 31, 2022
171 Dec 31, 2022
Deep Image Search is an AI-based image search engine that includes deep transfor learning features Extraction and tree-based vectorized search.
Deep Image Search - AI-Based Image Search Engine Deep Image Search is an AI-based image search engine that includes deep transfer learning features Ex
 139 Jan 1, 2023
139 Jan 1, 2023

search different Streaming Platforms for movie titles.
Install git clone and cd to directory install Selenium download chromedriver.exe to same directory First Run Use --setup True for the first run. Platf
 34 Dec 25, 2022
34 Dec 25, 2022

✖️ Unofficial API of 1337x.to
✖️ Unofficial Python API Wrapper of 1337x This is the unofficial API of 1337x. It supports all proxies of 1337x and almost all functions of 1337x. You
 71 Dec 26, 2022
71 Dec 26, 2022
Code for paper "Document-Level Argument Extraction by Conditional Generation". NAACL 21'
Argument Extraction by Generation Code for paper "Document-Level Argument Extraction by Conditional Generation". NAACL 21' Dependencies pytorch=1.6 tr
 87 Dec 26, 2022
87 Dec 26, 2022

Discord Bot that leverages the idea of nested containers using podman, runs untrusted user input, executes Quantum Circuits, allows users to refer to the Qiskit Documentation, and provides the ability to search questions on the Quantum Computing StackExchange.
Discord Bot that leverages the idea of nested containers using podman, runs untrusted user input, executes Quantum Circuits, allows users to refer to the Qiskit Documentation, and provides the ability to search questions on the Quantum Computing StackExchange.
 23 Oct 18, 2022
23 Oct 18, 2022
A Simple Telegram Inline Torrent Search Bot by @AbirHasan2005
A Simple Telegram Inline Torrent Search Bot by @AbirHasan2005
 61 Oct 28, 2022
61 Oct 28, 2022
Vowpal Wabbit is a machine learning system which pushes the frontier of machine learning with techniques
Vowpal Wabbit is a machine learning system which pushes the frontier of machine learning with techniques such as online, hashing, allreduce, reductions, learning2search, active, and interactive learning.
 8.1k Dec 30, 2022
8.1k Dec 30, 2022
Simple HTML and PDF document generator for Python - with built-in support for popular data analysis and plotting libraries.
Esparto is a simple HTML and PDF document generator for Python. Its primary use is for generating shareable single page reports with content from popular analytics and data science libraries.
 76 Dec 12, 2022
76 Dec 12, 2022
![[CVPR21] LightTrack: Finding Lightweight Neural Network for Object Tracking via One-Shot Architecture Search](https://github.com/researchmm/LightTrack/raw/main/Archs.gif)
[CVPR21] LightTrack: Finding Lightweight Neural Network for Object Tracking via One-Shot Architecture Search
LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search The official implementation of the paper LightTra
 290 Dec 24, 2022
290 Dec 24, 2022
Automatically create Faiss knn indices with the most optimal similarity search parameters.
It selects the best indexing parameters to achieve the highest recalls given memory and query speed constraints.
 419 Jan 1, 2023
419 Jan 1, 2023
Ray provides a simple, universal API for building distributed applications.
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
 23.5k Jan 5, 2023
23.5k Jan 5, 2023
An easier way to build neural search on the cloud
Jina is geared towards building search systems for any kind of data, including text, images, audio, video and many more. With the modular design & multi-layer abstraction, you can leverage the efficient patterns to build the system by parts, or chaining them into a Flow for an end-to-end experience.
 17k Jan 1, 2023
17k Jan 1, 2023
Beanie - is an Asynchronous Python object-document mapper (ODM) for MongoDB
Beanie - is an Asynchronous Python object-document mapper (ODM) for MongoDB, based on Motor and Pydantic.
 993 Jan 3, 2023
993 Jan 3, 2023
API spec validator and OpenAPI document generator for Python web frameworks.
API spec validator and OpenAPI document generator for Python web frameworks.
 249 Dec 22, 2022
249 Dec 22, 2022

CLI utility to search and download torrents from major torrent sites
CLI Torrent Downloader About CLI Torrent Downloader provides convenient and quick way to search torrent magnet links (and to run associated torrent cl
 86 Dec 19, 2022
86 Dec 19, 2022

All in one Search Engine Scrapper for used by API or Python Module. It's Free!
All in one Search Engine Scrapper for used by API or Python Module. How to use: Video Documentation Senginta is All in one Search Engine Scrapper. Wit
 33 Nov 21, 2022
33 Nov 21, 2022
LightSeq: A High-Performance Inference Library for Sequence Processing and Generation
LightSeq is a high performance inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT2, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, and other related tasks using these models.
 2.5k Jan 3, 2023
2.5k Jan 3, 2023
"NAS-Bench-301 and the Case for Surrogate Benchmarks for Neural Architecture Search".
NAS-Bench-301 This repository containts code for the paper: "NAS-Bench-301 and the Case for Surrogate Benchmarks for Neural Architecture Search". The
 57 Nov 30, 2022
57 Nov 30, 2022

An official implementation for "CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval"
The implementation of paper CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval. CLIP4Clip is a video-text retrieval model based
 456 Jan 6, 2023
456 Jan 6, 2023

TorchPQ is a python library for Approximate Nearest Neighbor Search (ANNS) and Maximum Inner Product Search (MIPS) on GPU using Product Quantization (PQ) algorithm.
Efficient implementations of Product Quantization and its variants using Pytorch and CUDA
 146 Dec 28, 2022
146 Dec 28, 2022

code for paper "Does Unsupervised Architecture Representation Learning Help Neural Architecture Search?"
Does Unsupervised Architecture Representation Learning Help Neural Architecture Search? Code for paper: Does Unsupervised Architecture Representation
 39 Dec 17, 2022
39 Dec 17, 2022
OCTIS: Comparing Topic Models is Simple! A python package to optimize and evaluate topic models (accepted at EACL2021 demo track)
OCTIS : Optimizing and Comparing Topic Models is Simple! OCTIS (Optimizing and Comparing Topic models Is Simple) aims at training, analyzing and compa
 478 Jan 1, 2023
478 Jan 1, 2023
Pixel art search engine for opengameart
Pixel Art Reverse Image Search for OpenGameArt What does the final search look like? The final search with an example can be found here. It looks like
 92 Nov 6, 2022
92 Nov 6, 2022
A utility to search, download and process Landsat 8 satellite imagery
Landsat-util Landsat-util is a command line utility that makes it easy to search, download, and process Landsat imagery. Docs For full documentation v
 681 Dec 7, 2022
681 Dec 7, 2022

Code for AAAI 2021 paper: Sequential End-to-end Network for Efficient Person Search
This repository hosts the source code of our paper: [AAAI 2021]Sequential End-to-end Network for Efficient Person Search. SeqNet achieves the state-of
 218 Dec 31, 2022
218 Dec 31, 2022

Layout Parser is a deep learning based tool for document image layout analysis tasks.
A Python Library for Document Layout Understanding
 3.4k Dec 30, 2022
3.4k Dec 30, 2022
xeuledoc - Fetch information about a public Google document.
xeuledoc - Fetch information about a public Google document.
 651 Dec 27, 2022
651 Dec 27, 2022
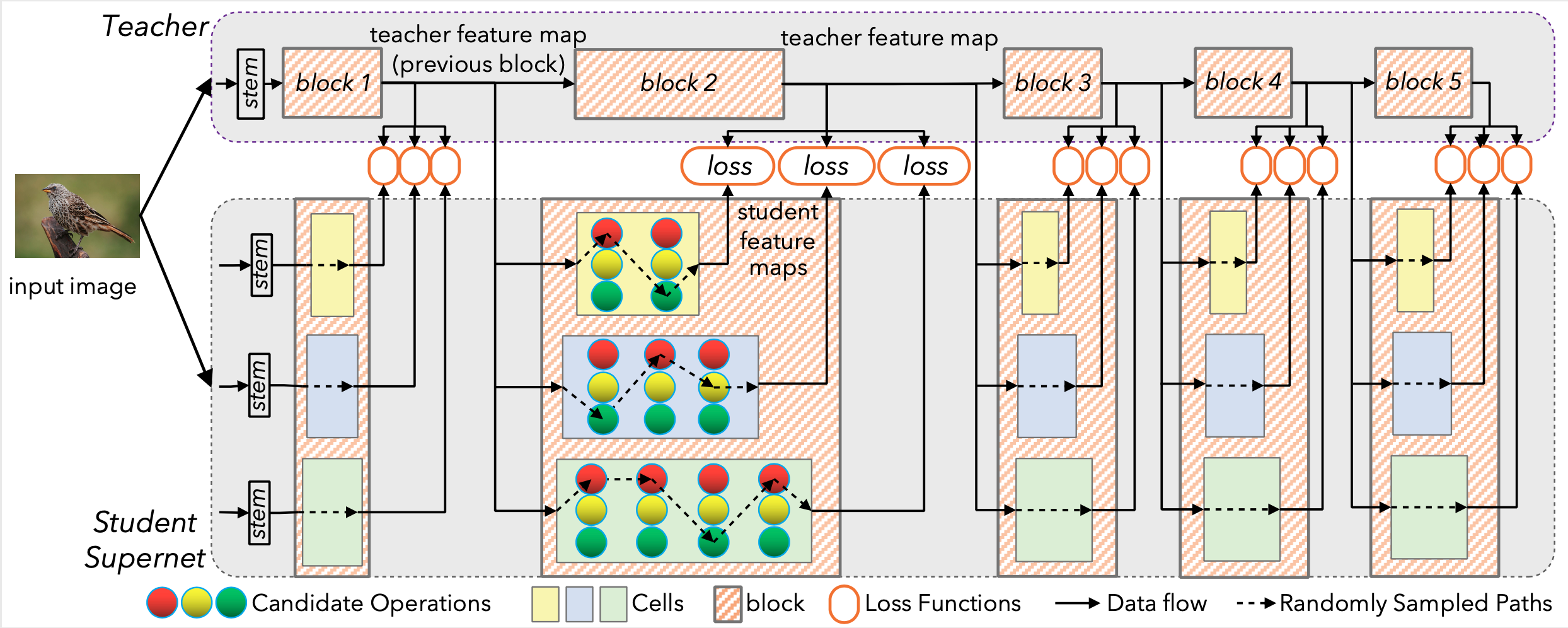
Block-wisely Supervised Neural Architecture Search with Knowledge Distillation (CVPR 2020)
DNA This repository provides the code of our paper: Blockwisely Supervised Neural Architecture Search with Knowledge Distillation. Illustration of DNA
 215 Dec 19, 2022
215 Dec 19, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023

Official implementation of Rethinking Graph Neural Architecture Search from Message-passing (CVPR2021)
Rethinking Graph Neural Architecture Search from Message-passing Intro The GNAS can automatically learn better architecture with the optimal depth of
 48 Sep 30, 2022
48 Sep 30, 2022
Search twitter by address.
Twitter Geolocate Twitter Geolocation is a console app that generates twitter search querries for a certain geolocation and opens them in your standar
 28 Dec 6, 2022
28 Dec 6, 2022
Privacy enhanced BitTorrent client with P2P content discovery
Tribler Towards making Bittorrent anonymous and impossible to shut down. We use our own dedicated Tor-like network for anonymous torrent downloading.
 4.2k Dec 31, 2022
4.2k Dec 31, 2022

Deep Multimodal Neural Architecture Search
MMNas: Deep Multimodal Neural Architecture Search This repository corresponds to the PyTorch implementation of the MMnas for visual question answering
 23 Dec 21, 2022
23 Dec 21, 2022
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
Ray provides a simple, universal API for building distributed applications. Ray is packaged with the following libraries for accelerating machine lear
23.3k Dec 31, 2022
Search and download Copernicus Sentinel satellite images
sentinelsat Sentinelsat makes searching, downloading and retrieving the metadata of Sentinel satellite images from the Copernicus Open Access Hub easy
 837 Dec 28, 2022
837 Dec 28, 2022
An easier way to build neural search on the cloud
An easier way to build neural search on the cloud Jina is a deep learning-powered search framework for building cross-/multi-modal search systems (e.g
17k Jan 2, 2023

BossNAS: Exploring Hybrid CNN-transformers with Block-wisely Self-supervised Neural Architecture Search
BossNAS This repository contains PyTorch evaluation code, retraining code and pretrained models of our paper: BossNAS: Exploring Hybrid CNN-transforme
127 Dec 26, 2022
Fetch information about a public Google document.
xeuledoc Fetch information about any public Google document. It's working on : Google Docs Google Spreadsheets Google Slides Google Drawning Google My
655 Jan 3, 2023

Code for CVPR 2021 paper: Anchor-Free Person Search
Introduction This is the implementationn for Anchor-Free Person Search in CVPR2021 License This project is released under the Apache 2.0 license. Inst
 158 Jan 4, 2023
158 Jan 4, 2023
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023

document image degradation
ocrodeg The ocrodeg package is a small Python library implementing document image degradation for data augmentation for handwriting recognition and OC
 134 Nov 18, 2022
134 Nov 18, 2022

Binarize document images
Binarization Binarization for document images Examples Introduction This tool performs document image binarization (i.e. transform colour/grayscale to
 48 Jan 2, 2023
48 Jan 2, 2023
A selectional auto-encoder approach for document image binarization
The code of this repository was used for the following publication. If you find this code useful please cite our paper: @article{Gallego2019, title =
 89 Nov 18, 2022
89 Nov 18, 2022
PAGE XML format collection for document image page content and more
PAGE-XML PAGE XML format collection for document image page content and more For an introduction, please see the following publication: http://www.pri
 46 Nov 14, 2022
46 Nov 14, 2022
Python-based tools for document analysis and OCR
ocropy OCRopus is a collection of document analysis programs, not a turn-key OCR system. In order to apply it to your documents, you may need to do so
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Packaged, Pytorch-based, easy to use, cross-platform version of the CRAFT text detector
CRAFT: Character-Region Awareness For Text detection Packaged, Pytorch-based, easy to use, cross-platform version of the CRAFT text detector | Paper |
 188 Dec 28, 2022
188 Dec 28, 2022
This repository provides train&test code, dataset, det.&rec. annotation, evaluation script, annotation tool, and ranking.
SCUT-CTW1500 Datasets We have updated annotations for both train and test set. Train: 1000 images [images][annos] Additional point annotation for each
 600 Dec 18, 2022
600 Dec 18, 2022

Unofficial implementation of "TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images"
TableNet Unofficial implementation of ICDAR 2019 paper : TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from
 243 Dec 30, 2022
243 Dec 30, 2022
Detect textlines in document images
Textline Detection Detect textlines in document images Introduction This tool performs border, region and textline detection from document image data
70 Jun 30, 2022

Document Layout Analysis
Eynollah Document Layout Analysis Introduction This tool performs document layout analysis (segmentation) from image data and returns the results as P
198 Dec 29, 2022
Page to PAGE Layout Analysis Tool
P2PaLA Page to PAGE Layout Analysis (P2PaLA) is a toolkit for Document Layout Analysis based on Neural Networks. 💥 Try our new DEMO for online baseli
 180 Nov 24, 2022
180 Nov 24, 2022
A simple document layout analysis using Python-OpenCV
Run the application: python main.py *Note: For first time running the application, create a folder named "output". The application is a simple documen
 109 Dec 12, 2022
109 Dec 12, 2022
Document Layout Analysis Projects
Layout_Analysis Introduction This is an implementation of RLSA and X-Y Cut with OpenCV Dependencies OpenCV 3.0+ How to use Compile with g++ : g++ -std
 22 Dec 8, 2022
22 Dec 8, 2022
Generic framework for historical document processing
dhSegment dhSegment is a tool for Historical Document Processing. Its generic approach allows to segment regions and extract content from different ty
 343 Dec 24, 2022
343 Dec 24, 2022
Detect textlines in document images
Textline Detection Detect textlines in document images Introduction This tool performs border, region and textline detection from document image data
70 Jun 30, 2022

Code for the paper "DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regression Networks" (ICCV '19)
DewarpNet This repository contains the codes for DewarpNet training. Recent Updates [May, 2020] Added evaluation images and an important note about Ma
 354 Jan 1, 2023
354 Jan 1, 2023

Document Image Dewarping
Document image dewarping using text-lines and line Segments Abstract Conventional text-line based document dewarping methods have problems when handli
 268 Dec 23, 2022
268 Dec 23, 2022

Library used to deskew a scanned document
Deskew //Note: Skew is measured in degrees. Deskewing is a process whereby skew is removed by rotating an image by the same amount as its skew but in
 273 Jan 6, 2023
273 Jan 6, 2023
An application of high resolution GANs to dewarp images of perturbed documents
Docuwarp This project is focused on dewarping document images through the usage of pix2pixHD, a GAN that is useful for general image to image translat
 97 Dec 25, 2022
97 Dec 25, 2022
code for "AttentiveNAS Improving Neural Architecture Search via Attentive Sampling"
AttentiveNAS: Improving Neural Architecture Search via Attentive Sampling This repository contains PyTorch evaluation code, training code and pretrain
 94 Oct 26, 2022
94 Oct 26, 2022
![[ICLR 2021] HW-NAS-Bench: Hardware-Aware Neural Architecture Search Benchmark](https://github.com/RICE-EIC/HW-NAS-Bench/raw/main/devices.jpg?raw=true)
[ICLR 2021] HW-NAS-Bench: Hardware-Aware Neural Architecture Search Benchmark
HW-NAS-Bench: Hardware-Aware Neural Architecture Search Benchmark Accepted as a spotlight paper at ICLR 2021. Table of content File structure Prerequi
 72 Jan 3, 2023
72 Jan 3, 2023

Automatically search Stack Overflow for the command you want to run
stackshell Automatically search Stack Overflow (and other Stack Exchange sites) for the command you want to ru Use the up and down arrows to change be
 22 Oct 27, 2021
22 Oct 27, 2021
Privacy-respecting metasearch engine
Privacy-respecting, hackable metasearch engine / pronunciation səːks. If you are looking for running instances, ready to use, then visit searx.space.
 12.4k Jan 8, 2023
12.4k Jan 8, 2023
A generic JSON document store with sharing and synchronisation capabilities.
Kinto Kinto is a minimalist JSON storage service with synchronisation and sharing abilities. Online documentation Tutorial Issue tracker Contributing
 4.2k Dec 26, 2022
4.2k Dec 26, 2022

聚合空间测绘搜索(Fofa,Zoomeye,Quake,Shodan,Censys,BinaryEdge)
#Search-Tools Search-Tools集合比较常见的网络空间探测引擎 Fofa,Zoomeye,Quake,Shodan,Censys,BinaryEdge 简单说明 ICO搜索目前只有Fofa,Shodan,Quake支持 代理设置是防止在API请求过于频繁,或者在实战中,好多红队打
 311 Dec 16, 2022
311 Dec 16, 2022

Parse Robinhood 1099 Tax Document from PDF into CSV
Robinhood 1099 Parser This project converts Robinhood Securities 1099 tax document from PDF to CSV file. This tool will be helpful for those who need
 52 Jun 10, 2022
52 Jun 10, 2022
Official pytorch implementation of paper "Inception Convolution with Efficient Dilation Search" (CVPR 2021 Oral).
IC-Conv This repository is an official implementation of the paper Inception Convolution with Efficient Dilation Search. Getting Started Download Imag
 111 Dec 31, 2022
111 Dec 31, 2022
Bot simply search for the files from provided channel according to given query and gives link to those files as buttons!
Auto Filter Bot ㅤㅤㅤㅤㅤㅤㅤ ㅤㅤㅤㅤㅤㅤㅤ You can call this as an Auto Filter Bot if you like :D Bot simply search for the files from provided channel according
 89 Nov 23, 2022
89 Nov 23, 2022
🎯 A comprehensive gradient-free optimization framework written in Python
Solid is a Python framework for gradient-free optimization. It contains basic versions of many of the most common optimization algorithms that do not
 565 Dec 26, 2022
565 Dec 26, 2022
Sequential Model-based Algorithm Configuration
SMAC v3 Project Copyright (C) 2016-2018 AutoML Group Attention: This package is a reimplementation of the original SMAC tool (see reference below). Ho
778 Jan 5, 2023
Automated Machine Learning with scikit-learn
auto-sklearn auto-sklearn is an automated machine learning toolkit and a drop-in replacement for a scikit-learn estimator. Find the documentation here
6.7k Jan 7, 2023
mlpack: a scalable C++ machine learning library --
a fast, flexible machine learning library Home | Documentation | Doxygen | Community | Help | IRC Chat Download: current stable version (3.4.2) mlpack
 4.2k Jan 1, 2023
4.2k Jan 1, 2023
一款高性能敏感词(非法词/脏字)检测过滤组件,附带繁体简体互换,支持全角半角互换,汉字转拼音,模糊搜索等功能。
一款高性能非法词(敏感词)检测组件,附带繁体简体互换,支持全角半角互换,获取拼音首字母,获取拼音字母,拼音模糊搜索等功能。
 3.6k Jan 7, 2023
3.6k Jan 7, 2023
LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search
LightSpeech UnOfficial PyTorch implementation of LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search.
 54 Dec 3, 2022
54 Dec 3, 2022

dirmaker is a simple, opinionated static site generator for quickly publishing directory websites.
dirmaker is a simple, opinionated static site generator for publishing directory websites (eg: Indic.page, env.wiki It takes entries from a YAML file and generates a categorised, paginated directory website.
 40 Nov 20, 2022
40 Nov 20, 2022
A free & open modern, fast email client with user-friendly encryption and privacy features
Welcome to Mailpile! Introduction Mailpile (https://www.mailpile.is/) is a modern, fast web-mail client with user-friendly encryption and privacy feat
 8.7k Jan 4, 2023
8.7k Jan 4, 2023
Scan, index, and archive all of your paper documents
[ en | de | el ] Important news about the future of this project It's been more than 5 years since I started this project on a whim as an effort to tr
 7.8k Jan 6, 2023
7.8k Jan 6, 2023
:bookmark: Browser-independent bookmark manager
buku buku in action! Introduction buku is a powerful bookmark manager written in Python3 and SQLite3. When I started writing it, I couldn't find a fle
 5.4k Jan 2, 2023
5.4k Jan 2, 2023
:mag: Ambar: Document Search Engine
🔍 Ambar: Document Search Engine Ambar is an open-source document search engine with automated crawling, OCR, tagging and instant full-text search. Am
 1.9k Jan 9, 2023
1.9k Jan 9, 2023

API & Webapp to answer questions about COVID-19. Using NLP (Question Answering) and trusted data sources.
This open source project serves two purposes. Collection and evaluation of a Question Answering dataset to improve existing QA/search methods - COVID-
 329 Nov 10, 2022
329 Nov 10, 2022

Sandwich Batch Normalization
Sandwich Batch Normalization Code for Sandwich Batch Normalization. Introduction We present Sandwich Batch Normalization (SaBN), an extremely easy imp
 48 Dec 15, 2022
48 Dec 15, 2022
Model search is a framework that implements AutoML algorithms for model architecture search at scale
Model search (MS) is a framework that implements AutoML algorithms for model architecture search at scale. It aims to help researchers speed up their exploration process for finding the right model architecture for their classification problems (i.e., DNNs with different types of layers).
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
Python-based tools for document analysis and OCR
ocropy OCRopus is a collection of document analysis programs, not a turn-key OCR system. In order to apply it to your documents, you may need to do so
3.2k Jan 4, 2023
Full text search for flask.
flask-msearch Installation To install flask-msearch: pip install flask-msearch # when MSEARCH_BACKEND = "whoosh" pip install whoosh blinker # when MSE
 197 Dec 29, 2022
197 Dec 29, 2022
rewise is an unofficial wrapper for google search's auto-complete feature
rewise is an unofficial wrapper for google search's auto-complete feature
 71 Jul 19, 2022
71 Jul 19, 2022
Knowledge Management for Humans using Machine Learning & Tags
HyperTag HyperTag helps humans intuitively express how they think about their files using tags and machine learning.
 165 Nov 4, 2022
165 Nov 4, 2022
Seach Losses of our paper 'Loss Function Discovery for Object Detection via Convergence-Simulation Driven Search', accepted by ICLR 2021.
CSE-Autoloss Designing proper loss functions for vision tasks has been a long-standing research direction to advance the capability of existing models
 54 Dec 17, 2022
54 Dec 17, 2022
Dockerized iCloud drive
iCloud-drive-docker is a simple iCloud drive client in Docker environment. It uses pyiCloud python library to interact with iCloud
 376 Jan 1, 2023
376 Jan 1, 2023
Knowledge Management for Humans using Machine Learning & Tags
HyperTag helps humans intuitively express how they think about their files using tags and machine learning. Represent how you think using tags. Find what you look for using semantic search for your text documents (yes, even PDF's) and images.
166 Jan 7, 2023
Generate modern Python clients from OpenAPI
openapi-python-client Generate modern Python clients from OpenAPI 3.x documents. This generator does not support OpenAPI 2.x FKA Swagger. If you need
 558 Jan 7, 2023
558 Jan 7, 2023
Cookiecutter API for creating Custom Skills for Azure Search using Python and Docker
cookiecutter-spacy-fastapi Python cookiecutter API for quick deployments of spaCy models with FastAPI Azure Search The API interface is compatible wit
 379 Jan 3, 2023
379 Jan 3, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 11.7k Feb 18, 2021
11.7k Feb 18, 2021

NeuralQA: A Usable Library for Question Answering on Large Datasets with BERT
NeuralQA: A Usable Library for (Extractive) Question Answering on Large Datasets with BERT Still in alpha, lots of changes anticipated. View demo on n
 184 Feb 10, 2021
184 Feb 10, 2021

Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
 1.5k Feb 17, 2021
1.5k Feb 17, 2021

Extract Keywords from sentence or Replace keywords in sentences.
FlashText This module can be used to replace keywords in sentences or extract keywords from sentences. It is based on the FlashText algorithm. Install
 4.7k Feb 17, 2021
4.7k Feb 17, 2021