329 Repositories
Python document-understanding Libraries

VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training [Arxiv] VideoMAE: Masked Autoencoders are Data-Efficient Learne
 697 Jan 7, 2023
697 Jan 7, 2023

Temporally Efficient Vision Transformer for Video Instance Segmentation, CVPR 2022, Oral
Temporally Efficient Vision Transformer for Video Instance Segmentation Temporally Efficient Vision Transformer for Video Instance Segmentation (CVPR
 203 Dec 31, 2022
203 Dec 31, 2022
![[ACL 2022] LinkBERT: A Knowledgeable Language Model 😎 Pretrained with Document Links](https://github.com/michiyasunaga/LinkBERT/raw/main/figs/overview.png)
[ACL 2022] LinkBERT: A Knowledgeable Language Model 😎 Pretrained with Document Links
LinkBERT: A Knowledgeable Language Model Pretrained with Document Links This repo provides the model, code & data of our paper: LinkBERT: Pretraining
 264 Jan 1, 2023
264 Jan 1, 2023

Learn the basics of Python. These tutorials are for Python beginners. so even if you have no prior knowledge of Python, you won’t face any difficulty understanding these tutorials.
01_Python_Introduction Introduction 👋 Python is a modern, robust, high level programming language. It is very easy to pick up even if you are complet
 245 Dec 30, 2022
245 Dec 30, 2022

I've demonstrated the working of the decision tree-based ID3 algorithm. Use an appropriate data set for building the decision tree and apply this knowledge to classify a new sample. All the steps have been explained in detail with graphics for better understanding.
Python Decision Tree and Random Forest Decision Tree A Decision Tree is one of the popular and powerful machine learning algorithms that I have learne
185 Dec 31, 2022

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022
Official implementation of "CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding" (CVPR, 2022)
CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding (CVPR'22) Paper Link | Project Page Abstract : Manual an
 152 Dec 23, 2022
152 Dec 23, 2022
The SVO-Probes Dataset for Verb Understanding
The SVO-Probes Dataset for Verb Understanding This repository contains the SVO-Probes benchmark designed to probe for Subject, Verb, and Object unders
 20 Nov 30, 2022
20 Nov 30, 2022
A basic instruction for Kubernetes setup and understanding.
A basic instruction for Kubernetes setup and understanding Module ID Module Guide - Install Kubernetes Cluster k8s-install 3 Docker Core Technology mo
 648 Jan 2, 2023
648 Jan 2, 2023
[CVPR 2022 Oral] TubeDETR: Spatio-Temporal Video Grounding with Transformers
TubeDETR: Spatio-Temporal Video Grounding with Transformers Website • STVG Demo • Paper This repository provides the code for our paper. This includes
 108 Dec 27, 2022
108 Dec 27, 2022
![[ICLR 2022] Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators](https://github.com/microsoft/AMOS/raw/main/AMOS.png)
[ICLR 2022] Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
AMOS This repository contains the scripts for fine-tuning AMOS pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: Pretraining Text Encoders wi
 22 Sep 15, 2022
22 Sep 15, 2022

Code for our CVPR 2022 Paper "GEN-VLKT: Simplify Association and Enhance Interaction Understanding for HOI Detection"
GEN-VLKT Code for our CVPR 2022 paper "GEN-VLKT: Simplify Association and Enhance Interaction Understanding for HOI Detection". Contributed by Yue Lia
 47 Dec 4, 2022
47 Dec 4, 2022
![[CVPR2022] Bridge-Prompt: Towards Ordinal Action Understanding in Instructional Videos](https://github.com/ttlmh/Bridge-Prompt/raw/master/pipeline.gif)
[CVPR2022] Bridge-Prompt: Towards Ordinal Action Understanding in Instructional Videos
Bridge-Prompt: Towards Ordinal Action Understanding in Instructional Videos Created by Muheng Li, Lei Chen, Yueqi Duan, Zhilan Hu, Jianjiang Feng, Jie
 58 Dec 23, 2022
58 Dec 23, 2022
![[CVPR'22] Official PyTorch Implementation of Collaborative Transformers for Grounded Situation Recognition](https://user-images.githubusercontent.com/55849968/160762073-9a458795-03c1-4b2a-8945-2187b5a48aca.png)
[CVPR'22] Official PyTorch Implementation of Collaborative Transformers for Grounded Situation Recognition
[CVPR'22] Collaborative Transformers for Grounded Situation Recognition Paper | Model Checkpoint This is the official PyTorch implementation of Collab
 29 Dec 10, 2022
29 Dec 10, 2022

Source code for "A Two-Stream AMR-enhanced Model for Document-level Event Argument Extraction" @ NAACL 2022
TSAR Source code for NAACL 2022 paper: A Two-Stream AMR-enhanced Model for Document-level Event Argument Extraction. 🔥 Introduction We focus on extra
 21 Sep 24, 2022
21 Sep 24, 2022
Text classification is one of the popular tasks in NLP that allows a program to classify free-text documents based on pre-defined classes.
Deep-Learning-for-Text-Document-Classification Text classification is one of the popular tasks in NLP that allows a program to classify free-text docu
 2 Mar 17, 2022
2 Mar 17, 2022
Repo for WWW 2022 paper: Progressively Optimized Bi-Granular Document Representation for Scalable Embedding Based Retrieval
BiDR Repo for WWW 2022 paper: Progressively Optimized Bi-Granular Document Representation for Scalable Embedding Based Retrieval. Requirements torch==
11 Oct 20, 2022
Pgn2tex - Scripts to convert pgn files to latex document. Useful to build books or pdf from pgn studies
Pgn2Latex (WIP) A simple script to make pdf from pgn files and studies. It's sti
 12 Jul 23, 2022
12 Jul 23, 2022
Searches a document for hash tags. Support multiple natural languages. Works in various contexts.
ht-getter Searches a document for hash tags. Supports multiple natural languages. Works in various contexts. This package uses a non-regex approach an
 1 Mar 1, 2022
1 Mar 1, 2022

An interactive document scanner built in Python using OpenCV
The scanner takes a poorly scanned image, finds the corners of the document, applies the perspective transformation to get a top-down view of the document, sharpens the image, and applies an adaptive color threshold to clean up the image.
 1 Feb 12, 2022
1 Feb 12, 2022
File-based TF-IDF: Calculates keywords in a document, using a word corpus.
File-based TF-IDF Calculates keywords in a document, using a word corpus. Why? Because I found myself with hundreds of plain text files, with no way t
 1 Feb 11, 2022
1 Feb 11, 2022
Split given PDF document into 4 page groups and convert them to booklet format
PUTO: PDF to Booklet converter Split given PDF document into 4 page groups and convert them to booklet format. It creates a PDF like shown below: Fir
 3 Mar 12, 2022
3 Mar 12, 2022

The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding.
SuperGen The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. Requirements Before running, you
 38 Dec 12, 2022
38 Dec 12, 2022
Understanding Hyperdimensional Computing for Parallel Single-Pass Learning
Understanding Hyperdimensional Computing for Parallel Single-Pass Learning Authors: Tao Yu* Yichi Zhang* Zhiru Zhang Christopher De Sa *: Equal Contri
 4 Sep 8, 2022
4 Sep 8, 2022

Source code for "Understanding Knowledge Integration in Language Models with Graph Convolutions"
Graph Convolution Simulator (GCS) Source code for "Understanding Knowledge Integration in Language Models with Graph Convolutions" Requirements: PyTor
 10 Oct 18, 2022
10 Oct 18, 2022
Sequence-tagging using deep learning
Classification using Deep Learning Requirements PyTorch version = 1.9.1+cu111 Python version = 3.8.10 PyTorch-Lightning version = 1.4.9 Huggingface
 2 Dec 20, 2022
2 Dec 20, 2022
Wordle-player - An optimal player for Wordle. Based on a rough understanding of information theory
Wordle-player - An optimal player for Wordle. Based on a rough understanding of information theory
 3 Feb 26, 2022
3 Feb 26, 2022

PyTorch implementation of DirectCLR from paper Understanding Dimensional Collapse in Contrastive Self-supervised Learning
DirectCLR DirectCLR is a simple contrastive learning model for visual representation learning. It does not require a trainable projector as SimCLR. It
 49 Dec 21, 2022
49 Dec 21, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
Word document generator with python
In this study, real world data is anonymized. The content is completely different, but the structure is the same. It was a script I prepared for the backend of a work using UiPath.
 3 Jan 30, 2022
3 Jan 30, 2022

DocEnTr: An end-to-end document image enhancement transformer
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
 19 Jan 29, 2022
19 Jan 29, 2022
This repository serves as a place to document a toy attempt on how to create a generative text model in Catalan, based on GPT-2
GPT-2 Catalan playground and scripts to train a GPT-2 model either from scrath or from another pretrained model.
 1 Jan 28, 2022
1 Jan 28, 2022
A deep learning framework for historical document image analysis
DIVA-DAF Description A deep learning framework for historical document image analysis. How to run Install dependencies # clone project git clone https
 9 Aug 4, 2022
9 Aug 4, 2022
Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer.
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
74 Jan 7, 2023
A simple document management REST based API for collaboratively interacting with documents
documan_api A simple document management REST based API for collaboratively interacting with documents.
 1 Jan 22, 2022
1 Jan 22, 2022

The official code for “DocTr: Document Image Transformer for Geometric Unwarping and Illumination Correction”, ACM MM, Oral Paper, 2021.
Good news! Our new work exhibits state-of-the-art performances on DocUNet benchmark dataset: DocScanner: Robust Document Image Rectification with Prog
 231 Dec 26, 2022
231 Dec 26, 2022
RedisJSON - a JSON data type for Redis
RedisJSON is a Redis module that implements ECMA-404 The JSON Data Interchange Standard as a native data type. It allows storing, updating and fetching JSON values from Redis keys (documents).
 3.4k Dec 29, 2022
3.4k Dec 29, 2022
Pyramid Pooling Transformer for Scene Understanding
Pyramid Pooling Transformer for Scene Understanding Requirements: torch 1.6+ torchvision 0.7.0 timm==0.3.2 Validated on torch 1.6.0, torchvision 0.7.0
 119 Dec 29, 2022
119 Dec 29, 2022
Document manipulation detection with python
image manipulation detection task: -- tianchi function image segmentation salie
 3 Aug 22, 2022
3 Aug 22, 2022
Assginment for UofT CSC420: Intro to Image Understanding
Run the code Open edge_detection.ipynb in google colab. Upload image1.jpg,image2.jpg and my_image.jpg to '/content/drive/My Drive'. chooose 'Run all'
 1 Feb 24, 2022
1 Feb 24, 2022
A very simple document database
DockieDb A simple in-memory document database. Installation Build the Wheel Fork or clone this repository and run python setup.py bdist_wheel in the r
 1 Jan 16, 2022
1 Jan 16, 2022
A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
DeepKE is a knowledge extraction toolkit supporting low-resource and document-level scenarios for entity, relation and attribute extraction. We provide comprehensive documents, Google Colab tutorials, and online demo for beginners.
 1.6k Jan 5, 2023
1.6k Jan 5, 2023
PyTorch code for JEREX: Joint Entity-Level Relation Extractor
JEREX: "Joint Entity-Level Relation Extractor" PyTorch code for JEREX: "Joint Entity-Level Relation Extractor". For a description of the model and exp
 50 Dec 1, 2022
50 Dec 1, 2022

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
Mapping a variable-length sentence to a fixed-length vector using BERT model
Are you looking for X-as-service? Try the Cloud-Native Neural Search Framework for Any Kind of Data bert-as-service Using BERT model as a sentence enc
 11.1k Jan 1, 2023
11.1k Jan 1, 2023

Shelf DB is a tiny document database for Python to stores documents or JSON-like data
Shelf DB Introduction Shelf DB is a tiny document database for Python to stores documents or JSON-like data. Get it $ pip install shelfdb shelfquery S
 35 Nov 3, 2022
35 Nov 3, 2022
Towards Understanding Quality Challenges of the Federated Learning: A First Look from the Lens of Robustness
FL Analysis This repository contains the code and results for the paper "Towards Understanding Quality Challenges of the Federated Learning: A First L
 3 Oct 17, 2022
3 Oct 17, 2022
Code examples and benchmarks from the paper "Understanding Entropy Coding With Asymmetric Numeral Systems (ANS): a Statistician's Perspective"
Code For the Paper "Understanding Entropy Coding With Asymmetric Numeral Systems (ANS): a Statistician's Perspective" Author: Robert Bamler Date: 22 D
 4 Nov 2, 2022
4 Nov 2, 2022

This repository contains the code for the paper 'PARM: Paragraph Aggregation Retrieval Model for Dense Document-to-Document Retrieval' published at ECIR'22.
Paragraph Aggregation Retrieval Model (PARM) for Dense Document-to-Document Retrieval This repository contains the code for the paper PARM: A Paragrap
 33 Aug 26, 2022
33 Aug 26, 2022
This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents".
Introduction This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents". If
 0 Jan 11, 2022
0 Jan 11, 2022
The official code of "SCROLLS: Standardized CompaRison Over Long Language Sequences".
SCROLLS This repository contains the official code of the paper: "SCROLLS: Standardized CompaRison Over Long Language Sequences". Links Official Websi
 39 Dec 23, 2022
39 Dec 23, 2022
Some shitty programs just to brush up on my understanding of binary conversions.
Binary Converters Some shitty programs just to brush up on my understanding of binary conversions. Supported conversions formats = "unsigned-binary" |
 2 Jan 9, 2022
2 Jan 9, 2022
Natural Language Processing Best Practices & Examples
NLP Best Practices In recent years, natural language processing (NLP) has seen quick growth in quality and usability, and this has helped to drive bus
6.1k Dec 31, 2022
Official Implementation of "DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization."
DialogLM Code for AAAI 2022 paper: DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization. Pre-trained Models We release two ve
92 Dec 19, 2022
Import entity definition document into SQLie3. Manage the entity. Also, create a "Create Table SQL file".
EntityDocumentMaker Version 1.00 After importing the entity definition (Excel file), store the data in sqlite3. エンティティ定義(Excelファイル)をインポートした後、データをsqlit
 1 Jan 9, 2022
1 Jan 9, 2022
A new codebase for Group Activity Recognition. It contains codes for ICCV 2021 paper: Spatio-Temporal Dynamic Inference Network for Group Activity Recognition and some other methods.
Spatio-Temporal Dynamic Inference Network for Group Activity Recognition The source codes for ICCV2021 Paper: Spatio-Temporal Dynamic Inference Networ
 40 Dec 12, 2022
40 Dec 12, 2022
Python utility library for compositing PDF documents with reportlab.
pdfdoc-py Python utility library for compositing PDF documents with reportlab. Installation The pdfdoc-py package can be installed directly from the s
 1 Jan 6, 2022
1 Jan 6, 2022
Understanding and Overcoming the Challenges of Efficient Transformer Quantization
Transformer Quantization This repository contains the implementation and experiments for the paper presented in Yelysei Bondarenko1, Markus Nagel1, Ti
 83 Dec 30, 2022
83 Dec 30, 2022

Iowa Project - My second project done at General Assembly, focused on feature engineering and understanding Linear Regression as a concept
Project 2 - Ames Housing Data and Kaggle Challenge PROBLEM STATEMENT Inferring or Predicting? What's more valuable for a housing model? When creating
 1 Jan 3, 2022
1 Jan 3, 2022

Flask-vs-FastAPI - Understanding Flask vs FastAPI Web Framework. A comparison of two different RestAPI frameworks.
Flask-vs-FastAPI Understanding Flask vs FastAPI Web Framework. A comparison of two different RestAPI frameworks. IntroductionIn Flask is a popular mic
 1 Jan 1, 2022
1 Jan 1, 2022

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

Keras Realtime Multi-Person Pose Estimation - Keras version of Realtime Multi-Person Pose Estimation project
This repository has become incompatible with the latest and recommended version of Tensorflow 2.0 Instead of refactoring this code painfully, I create
 769 Dec 8, 2022
769 Dec 8, 2022

A supercharged version of paperless: scan, index and archive all your physical documents
Paperless-ng Paperless (click me) is an application by Daniel Quinn and contributors that indexes your scanned documents and allows you to easily sear
 5.3k Jan 9, 2023
5.3k Jan 9, 2023
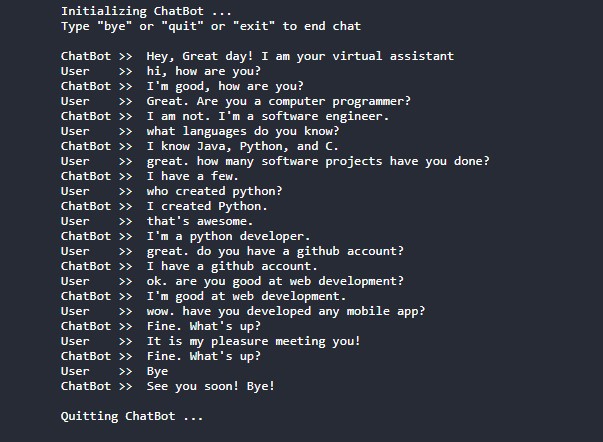
Conversational-AI-ChatBot - Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users!
Conversational AI ChatBot Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users! In this project? Thi
 6 Nov 30, 2022
6 Nov 30, 2022

PyTorch implementation for the ICLR 2020 paper "Understanding the Limitations of Variational Mutual Information Estimators"
Smoothed Mutual Information ``Lower Bound'' Estimator PyTorch implementation for the ICLR 2020 paper Understanding the Limitations of Variational Mutu
 50 Nov 9, 2022
50 Nov 9, 2022
ElasticSearch ODM (Object Document Mapper) for Python - pip install esengine
esengine - The Elasticsearch Object Document Mapper esengine is an ODM (Object Document Mapper) it maps Python classes in to Elasticsearch index/doc_t
 109 Nov 22, 2022
109 Nov 22, 2022

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022
Artificial Conversational Entity for queries in Eulogio "Amang" Rodriguez Institute of Science and Technology (EARIST)
🤖 Coeus - EARIST A.C.E 💬 Coeus is an Artificial Conversational Entity for queries in Eulogio "Amang" Rodriguez Institute of Science and Technology,
 3 Oct 14, 2022
3 Oct 14, 2022
Essential Document Generator
Essential Document Generator Dead Simple Document Generation Whether it's testing database performance or a new web interface, we've all needed a dead
 59 Nov 11, 2022
59 Nov 11, 2022
A document format conversion service based on Pandoc.
reformed Document format conversion service based on Pandoc. Usage The API specification for the Reformed server is as follows: GET /api/v1/formats: L
 3 Jul 18, 2022
3 Jul 18, 2022

PyTorch implementation of the paper: Text is no more Enough! A Benchmark for Profile-based Spoken Language Understanding
Text is no more Enough! A Benchmark for Profile-based Spoken Language Understanding This repository contains the official PyTorch implementation of th
 26 Dec 14, 2022
26 Dec 14, 2022
Python document object mapper (load python object from JSON and vice-versa)
lupin is a Python JSON object mapper lupin is meant to help in serializing python objects to JSON and unserializing JSON data to python objects. Insta
 24 Nov 9, 2022
24 Nov 9, 2022
Understanding the Properties of Minimum Bayes Risk Decoding in Neural Machine Translation.
Understanding Minimum Bayes Risk Decoding This repo provides code and documentation for the following paper: Müller and Sennrich (2021): Understanding
 13 May 1, 2022
13 May 1, 2022
[AAAI 2022] Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding
[AAAI 2022] Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding Official Pytorch implementation of Negative Sample Matter
69 Dec 26, 2022

ARKitScenes - A Diverse Real-World Dataset for 3D Indoor Scene Understanding Using Mobile RGB-D Data
ARKitScenes This repo accompanies the research paper, ARKitScenes - A Diverse Real-World Dataset for 3D Indoor Scene Understanding Using Mobile RGB-D
 371 Jan 5, 2023
371 Jan 5, 2023

Label data using HuggingFace's transformers and automatically get a prediction service
Label Studio for Hugging Face's Transformers Website • Docs • Twitter • Join Slack Community Transfer learning for NLP models by annotating your textu
 135 Dec 29, 2022
135 Dec 29, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 342 Jan 5, 2023
342 Jan 5, 2023
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022
LUKE -- Language Understanding with Knowledge-based Embeddings
LUKE (Language Understanding with Knowledge-based Embeddings) is a new pre-trained contextualized representation of words and entities based on transf
 587 Dec 30, 2022
587 Dec 30, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
7.8k Jan 9, 2023
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
DeBERTa: Decoding-enhanced BERT with Disentangled Attention This repository is the official implementation of DeBERTa: Decoding-enhanced BERT with Dis
1.2k Jan 3, 2023
Longformer: The Long-Document Transformer
Longformer Longformer and LongformerEncoderDecoder (LED) are pretrained transformer models for long documents. ***** New December 1st, 2020: Longforme
 1.6k Dec 29, 2022
1.6k Dec 29, 2022

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023

A toolkit for document-level event extraction, containing some SOTA model implementations
❤️ A Toolkit for Document-level Event Extraction with & without Triggers Hi, there 👋 . Thanks for your stay in this repo. This project aims at buildi
 159 Dec 22, 2022
159 Dec 22, 2022
Understanding the field usage of any object in Salesforce
Understanding the field usage of any object in Salesforce One of the biggest problems that I have addressed while working with Salesforce is to unders
 1 Dec 14, 2021
1 Dec 14, 2021
![[AAAI 2022] Sparse Structure Learning via Graph Neural Networks for Inductive Document Classification](https://github.com/qkrdmsghk/TextSSL/raw/master/TextSSL.png)
[AAAI 2022] Sparse Structure Learning via Graph Neural Networks for Inductive Document Classification
Sparse Structure Learning via Graph Neural Networks for inductive document classification Make graph dataset create co-occurrence graph for datasets.
 16 Dec 22, 2022
16 Dec 22, 2022

A toolkit for document-level event extraction, containing some SOTA model implementations
Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker Source code for ACL-IJCNLP 2021 Long paper: Document-le
84 Dec 15, 2022
Generate modern Python clients from OpenAPI
openapi-python-client Generate modern Python clients from OpenAPI 3.x documents. This generator does not support OpenAPI 2.x FKA Swagger. If you need
 555 Jan 2, 2023
555 Jan 2, 2023
🦎 A NeoVim plugin for highlighting visual selections like in a normal document editor!
🦎 HighStr.nvim A NeoVim plugin for highlighting visual selections like in a normal document editor! Demo TL;DR HighStr.nvim is a NeoVim plugin writte
 222 Jan 3, 2023
222 Jan 3, 2023
A framework for the elicitation, specification, formalization and understanding of requirements.
A framework for the elicitation, specification, formalization and understanding of requirements.
 161 Jan 3, 2023
161 Jan 3, 2023

This repository accompanies the ACM TOIS paper "What can I cook with these ingredients?" - Understanding cooking-related information needs in conversational search
In this repository you find data that has been gathered when conducting in-situ experiments in a conversational cooking setting. These data include tr
 6 Sep 22, 2022
6 Sep 22, 2022

Bnagla hand written document digiiztion
Bnagla hand written document digiiztion This repo addresses the problem of digiizing hand written documents in Bangla. Documents have definite fields
 1 Dec 10, 2021
1 Dec 10, 2021
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce (EMNLP Founding 2021)
Introduction K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce. Installation PyTor
 21 Nov 16, 2022
21 Nov 16, 2022

Fuzz introspector is a tool to help fuzzer developers to get an understanding of their fuzzer’s performance and identify any potential blockers.
Fuzz introspector Fuzz introspector is a tool to help fuzzer developers to get an understanding of their fuzzer’s performance and identify any potenti
 221 Jan 1, 2023
221 Jan 1, 2023

S-attack library. Official implementation of two papers "Are socially-aware trajectory prediction models really socially-aware?" and "Vehicle trajectory prediction works, but not everywhere".
S-attack library: A library for evaluating trajectory prediction models This library contains two research projects to assess the trajectory predictio
 71 Jan 4, 2023
71 Jan 4, 2023
The repo for reproducing Seed-driven Document Ranking for Systematic Reviews: A Reproducibility Study
ECIR Reproducibility Paper: Seed-driven Document Ranking for Systematic Reviews: A Reproducibility Study This code corresponds to the reproducibility
 3 Mar 31, 2022
3 Mar 31, 2022
![[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining](https://github.com/microsoft/COCO-LM/raw/main/coco-lm.png)
[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
COCO-LM This repository contains the scripts for fine-tuning COCO-LM pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: COCO-LM: Correcting an
106 Dec 12, 2022

TensorFlow implementation of the paper "Hierarchical Attention Networks for Document Classification"
Hierarchical Attention Networks for Document Classification This is an implementation of the paper Hierarchical Attention Networks for Document Classi
 83 Dec 5, 2022
83 Dec 5, 2022

Official Pytorch Implementation of Relational Self-Attention: What's Missing in Attention for Video Understanding
Relational Self-Attention: What's Missing in Attention for Video Understanding This repository is the official implementation of "Relational Self-Atte
 43 Dec 7, 2022
43 Dec 7, 2022
DUE: End-to-End Document Understanding Benchmark
This is the repository that provide tools to download data, reproduce the baseline results and evaluation. What can you achieve with this guide Based
 21 Dec 29, 2022
21 Dec 29, 2022