263 Repositories
Python document-embedding Libraries
![[ACL 2022] LinkBERT: A Knowledgeable Language Model 😎 Pretrained with Document Links](https://github.com/michiyasunaga/LinkBERT/raw/main/figs/overview.png)
[ACL 2022] LinkBERT: A Knowledgeable Language Model 😎 Pretrained with Document Links
LinkBERT: A Knowledgeable Language Model Pretrained with Document Links This repo provides the model, code & data of our paper: LinkBERT: Pretraining
 264 Jan 1, 2023
264 Jan 1, 2023

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022
MGFN: Multi-Graph Fusion Networks for Urban Region Embedding was accepted by IJCAI-2022.
Multi-Graph Fusion Networks for Urban Region Embedding (IJCAI-22) This is the implementation of Multi-Graph Fusion Networks for Urban Region Embedding
 202 Nov 18, 2022
202 Nov 18, 2022
Anomaly Detection via Reverse Distillation from One-Class Embedding
Anomaly Detection via Reverse Distillation from One-Class Embedding Implementation (Official Code ⭐️ ⭐️ ⭐️ ) Environment pytorch == 1.91 torchvision =
 73 Dec 19, 2022
73 Dec 19, 2022
TigerLily: Finding drug interactions in silico with the Graph.
Drug Interaction Prediction with Tigerlily Documentation | Example Notebook | Youtube Video | Project Report Tigerlily is a TigerGraph based system de
 91 Dec 30, 2022
91 Dec 30, 2022
Boostcamp AI Tech 3rd / Basic Paper reading w.r.t Embedding
Boostcamp AI Tech 3rd : Basic Paper Reading w.r.t Embedding TL;DR 1992년부터 2018년도까지 이루어진 word/sentence embedding의 중요한 줄기를 이루는 기초 논문 스터디를 진행하고자 합니다. 논
 14 Nov 14, 2022
14 Nov 14, 2022
A library for end-to-end learning of embedding index and retrieval model
Poeem Poeem is a library for efficient approximate nearest neighbor (ANN) search, which has been widely adopted in industrial recommendation, advertis
 54 Dec 21, 2022
54 Dec 21, 2022

Picasso: a methods for embedding points in 2D in a way that respects distances while fitting a user-specified shape.
Picasso Code to generate Picasso embeddings of any input matrix. Picasso maps the points of an input matrix to user-defined, n-dimensional shape coord
 45 Dec 23, 2022
45 Dec 23, 2022

Source code for "A Two-Stream AMR-enhanced Model for Document-level Event Argument Extraction" @ NAACL 2022
TSAR Source code for NAACL 2022 paper: A Two-Stream AMR-enhanced Model for Document-level Event Argument Extraction. 🔥 Introduction We focus on extra
 21 Sep 24, 2022
21 Sep 24, 2022
Text classification is one of the popular tasks in NLP that allows a program to classify free-text documents based on pre-defined classes.
Deep-Learning-for-Text-Document-Classification Text classification is one of the popular tasks in NLP that allows a program to classify free-text docu
 2 Mar 17, 2022
2 Mar 17, 2022
Repo for WWW 2022 paper: Progressively Optimized Bi-Granular Document Representation for Scalable Embedding Based Retrieval
BiDR Repo for WWW 2022 paper: Progressively Optimized Bi-Granular Document Representation for Scalable Embedding Based Retrieval. Requirements torch==
 11 Oct 20, 2022
11 Oct 20, 2022
Tensorflow 1.13.X implementation for our NN paper: Wei Xia, Sen Wang, Ming Yang, Quanxue Gao, Jungong Han, Xinbo Gao: Multi-view graph embedding clustering network: Joint self-supervision and block diagonal representation. Neural Networks 145: 1-9 (2022)
Multi-view graph embedding clustering network: Joint self-supervision and block diagonal representation Simple implementation of our paper MVGC. The d
 13 Oct 26, 2022
13 Oct 26, 2022
SmallInitEmb - LayerNorm(SmallInit(Embedding)) in a Transformer to improve convergence
SmallInitEmb LayerNorm(SmallInit(Embedding)) in a Transformer I find that when t
 11 Dec 25, 2022
11 Dec 25, 2022
Pgn2tex - Scripts to convert pgn files to latex document. Useful to build books or pdf from pgn studies
Pgn2Latex (WIP) A simple script to make pdf from pgn files and studies. It's sti
 12 Jul 23, 2022
12 Jul 23, 2022
Searches a document for hash tags. Support multiple natural languages. Works in various contexts.
ht-getter Searches a document for hash tags. Supports multiple natural languages. Works in various contexts. This package uses a non-regex approach an
 1 Mar 1, 2022
1 Mar 1, 2022

An interactive document scanner built in Python using OpenCV
The scanner takes a poorly scanned image, finds the corners of the document, applies the perspective transformation to get a top-down view of the document, sharpens the image, and applies an adaptive color threshold to clean up the image.
 1 Feb 12, 2022
1 Feb 12, 2022
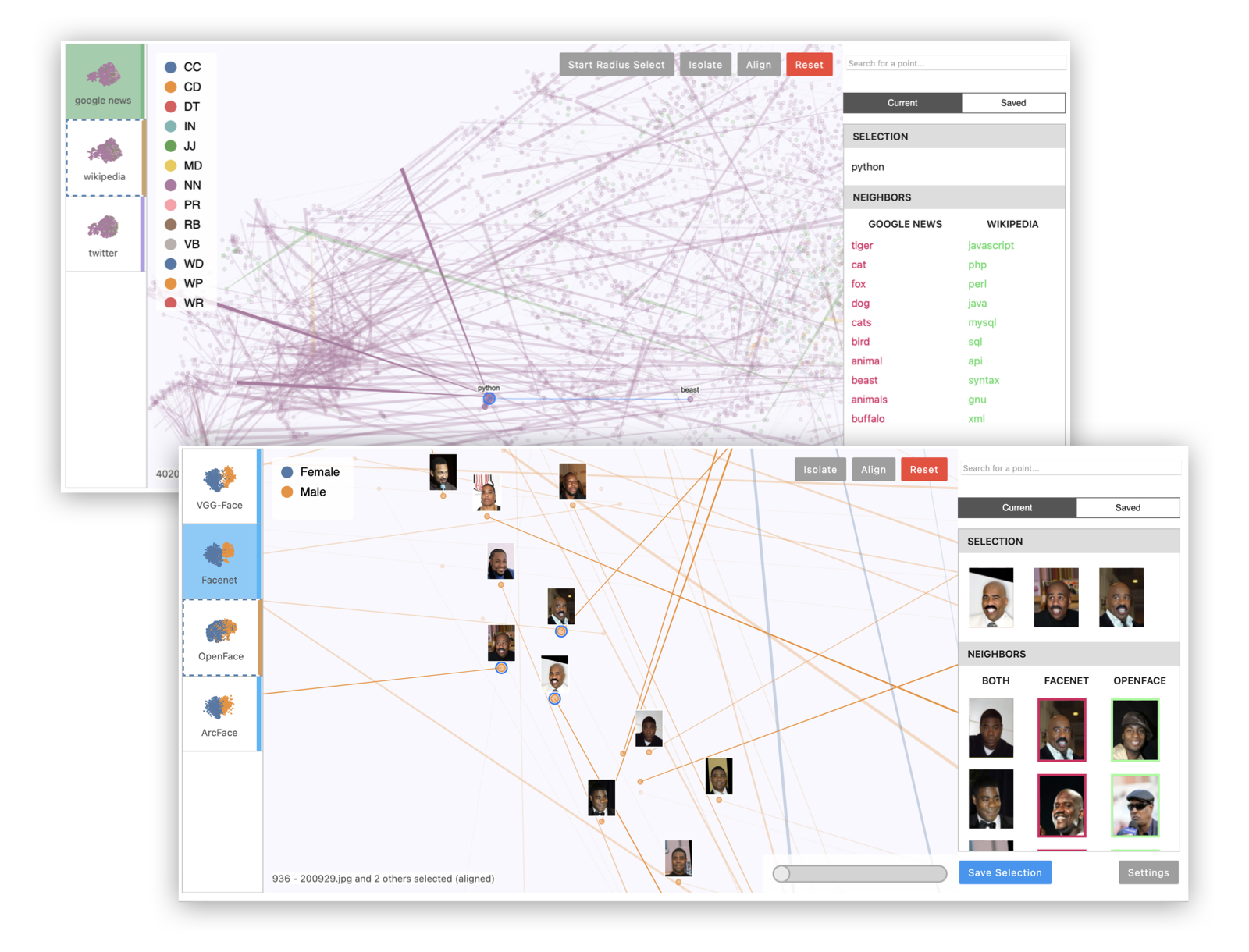
Emblaze - Interactive Embedding Comparison
Emblaze - Interactive Embedding Comparison Emblaze is a Jupyter notebook widget for visually comparing embeddings using animated scatter plots. It bun
 77 Nov 24, 2022
77 Nov 24, 2022
File-based TF-IDF: Calculates keywords in a document, using a word corpus.
File-based TF-IDF Calculates keywords in a document, using a word corpus. Why? Because I found myself with hundreds of plain text files, with no way t
 1 Feb 11, 2022
1 Feb 11, 2022
Split given PDF document into 4 page groups and convert them to booklet format
PUTO: PDF to Booklet converter Split given PDF document into 4 page groups and convert them to booklet format. It creates a PDF like shown below: Fir
 3 Mar 12, 2022
3 Mar 12, 2022

Some embedding layer implementation using ivy library
ivy-manual-embeddings Some embedding layer implementation using ivy library. Just for fun. It is based on NYCTaxiFare dataset from kaggle (cut down to
 2 Feb 10, 2022
2 Feb 10, 2022
nlabel is a library for generating, storing and retrieving tagging information and embedding vectors from various nlp libraries through a unified interface.
nlabel is a library for generating, storing and retrieving tagging information and embedding vectors from various nlp libraries through a unified interface.
 2 Jun 10, 2022
2 Jun 10, 2022
Word document generator with python
In this study, real world data is anonymized. The content is completely different, but the structure is the same. It was a script I prepared for the backend of a work using UiPath.
 3 Jan 30, 2022
3 Jan 30, 2022

DocEnTr: An end-to-end document image enhancement transformer
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
 19 Jan 29, 2022
19 Jan 29, 2022

SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples
SNCSE SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples This is the repository for SNCSE. SNCSE aims to allev
 59 Jan 2, 2023
59 Jan 2, 2023
This repository serves as a place to document a toy attempt on how to create a generative text model in Catalan, based on GPT-2
GPT-2 Catalan playground and scripts to train a GPT-2 model either from scrath or from another pretrained model.
 1 Jan 28, 2022
1 Jan 28, 2022
A deep learning framework for historical document image analysis
DIVA-DAF Description A deep learning framework for historical document image analysis. How to run Install dependencies # clone project git clone https
 9 Aug 4, 2022
9 Aug 4, 2022

OntoProtein: Protein Pretraining With Ontology Embedding
OntoProtein This is the implement of the paper "OntoProtein: Protein Pretraining With Ontology Embedding". OntoProtein is an effective method that mak
 80 Dec 14, 2022
80 Dec 14, 2022
Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer.
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
74 Jan 7, 2023
This repository is for Contrastive Embedding Distribution Refinement and Entropy-Aware Attention Network (CEDR)
CEDR This repository is for Contrastive Embedding Distribution Refinement and Entropy-Aware Attention Network (CEDR) introduced in the following paper
 3 Feb 27, 2022
3 Feb 27, 2022

This repository contains the database and code used in the paper Embedding Arithmetic for Text-driven Image Transformation
This repository contains the database and code used in the paper Embedding Arithmetic for Text-driven Image Transformation (Guillaume Couairon, Holger
 31 Oct 17, 2022
31 Oct 17, 2022
Keras Image Embeddings using Contrastive Loss
Image to Embedding projection in vector space. Implementation in keras and tensorflow of batch all triplet loss for one-shot/few-shot learning.
 5 Mar 21, 2022
5 Mar 21, 2022
A simple document management REST based API for collaboratively interacting with documents
documan_api A simple document management REST based API for collaboratively interacting with documents.
 1 Jan 22, 2022
1 Jan 22, 2022

The official code for “DocTr: Document Image Transformer for Geometric Unwarping and Illumination Correction”, ACM MM, Oral Paper, 2021.
Good news! Our new work exhibits state-of-the-art performances on DocUNet benchmark dataset: DocScanner: Robust Document Image Rectification with Prog
 231 Dec 26, 2022
231 Dec 26, 2022
RedisJSON - a JSON data type for Redis
RedisJSON is a Redis module that implements ECMA-404 The JSON Data Interchange Standard as a native data type. It allows storing, updating and fetching JSON values from Redis keys (documents).
 3.4k Dec 29, 2022
3.4k Dec 29, 2022
CKD - Collaborative Knowledge Distillation for Heterogeneous Information Network Embedding
Collaborative Knowledge Distillation for Heterogeneous Information Network Embed
 9 Dec 5, 2022
9 Dec 5, 2022
Document manipulation detection with python
image manipulation detection task: -- tianchi function image segmentation salie
 3 Aug 22, 2022
3 Aug 22, 2022
A very simple document database
DockieDb A simple in-memory document database. Installation Build the Wheel Fork or clone this repository and run python setup.py bdist_wheel in the r
 1 Jan 16, 2022
1 Jan 16, 2022

Language-Agnostic Website Embedding and Classification
Homepage2Vec Language-Agnostic Website Embedding and Classification based on Curlie labels https://arxiv.org/pdf/2201.03677.pdf Homepage2Vec is a pre-
 25 Dec 27, 2022
25 Dec 27, 2022
A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
DeepKE is a knowledge extraction toolkit supporting low-resource and document-level scenarios for entity, relation and attribute extraction. We provide comprehensive documents, Google Colab tutorials, and online demo for beginners.
1.6k Jan 5, 2023
PyTorch code for JEREX: Joint Entity-Level Relation Extractor
JEREX: "Joint Entity-Level Relation Extractor" PyTorch code for JEREX: "Joint Entity-Level Relation Extractor". For a description of the model and exp
 50 Dec 1, 2022
50 Dec 1, 2022

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
Mapping a variable-length sentence to a fixed-length vector using BERT model
Are you looking for X-as-service? Try the Cloud-Native Neural Search Framework for Any Kind of Data bert-as-service Using BERT model as a sentence enc
 11.1k Jan 1, 2023
11.1k Jan 1, 2023

Shelf DB is a tiny document database for Python to stores documents or JSON-like data
Shelf DB Introduction Shelf DB is a tiny document database for Python to stores documents or JSON-like data. Get it $ pip install shelfdb shelfquery S
 35 Nov 3, 2022
35 Nov 3, 2022

This repository contains the code for the paper 'PARM: Paragraph Aggregation Retrieval Model for Dense Document-to-Document Retrieval' published at ECIR'22.
Paragraph Aggregation Retrieval Model (PARM) for Dense Document-to-Document Retrieval This repository contains the code for the paper PARM: A Paragrap
 33 Aug 26, 2022
33 Aug 26, 2022
This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents".
Introduction This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents". If
 0 Jan 11, 2022
0 Jan 11, 2022
Import entity definition document into SQLie3. Manage the entity. Also, create a "Create Table SQL file".
EntityDocumentMaker Version 1.00 After importing the entity definition (Excel file), store the data in sqlite3. エンティティ定義(Excelファイル)をインポートした後、データをsqlit
 1 Jan 9, 2022
1 Jan 9, 2022
SphereFace: Deep Hypersphere Embedding for Face Recognition
SphereFace: Deep Hypersphere Embedding for Face Recognition By Weiyang Liu, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj and Le Song License SphereFa
 1.5k Dec 29, 2022
1.5k Dec 29, 2022
Python utility library for compositing PDF documents with reportlab.
pdfdoc-py Python utility library for compositing PDF documents with reportlab. Installation The pdfdoc-py package can be installed directly from the s
 1 Jan 6, 2022
1 Jan 6, 2022

Awesome Graph Classification - A collection of important graph embedding, classification and representation learning papers with implementations.
A collection of graph classification methods, covering embedding, deep learning, graph kernel and factorization papers
4.5k Jan 1, 2023

A supercharged version of paperless: scan, index and archive all your physical documents
Paperless-ng Paperless (click me) is an application by Daniel Quinn and contributors that indexes your scanned documents and allows you to easily sear
 5.3k Jan 9, 2023
5.3k Jan 9, 2023
An implementation of Deep Graph Infomax (DGI) in PyTorch
DGI Deep Graph Infomax (Veličković et al., ICLR 2019): https://arxiv.org/abs/1809.10341 Overview Here we provide an implementation of Deep Graph Infom
 491 Jan 3, 2023
491 Jan 3, 2023
Unsupervised Attributed Multiplex Network Embedding (AAAI 2020)
Unsupervised Attributed Multiplex Network Embedding (DMGI) Overview Nodes in a multiplex network are connected by multiple types of relations. However
 114 Dec 6, 2022
114 Dec 6, 2022
BiNE: Bipartite Network Embedding
BiNE: Bipartite Network Embedding This repository contains the demo code of the paper: BiNE: Bipartite Network Embedding. Ming Gao, Leihui Chen, Xiang
 214 Nov 24, 2022
214 Nov 24, 2022
Subgraph Based Learning of Contextual Embedding
SLiCE Self-Supervised Learning of Contextual Embeddings for Link Prediction in Heterogeneous Networks Dataset details: We use four public benchmark da
 27 Dec 1, 2022
27 Dec 1, 2022

The code for our paper "AutoSF: Searching Scoring Functions for Knowledge Graph Embedding"
AutoSF The code for our paper "AutoSF: Searching Scoring Functions for Knowledge Graph Embedding" and this paper has been accepted by ICDE2020. News:
 64 Dec 17, 2022
64 Dec 17, 2022
Korean Sentence Embedding Repository
Korean-Sentence-Embedding 🍭 Korean sentence embedding repository. You can download the pre-trained models and inference right away, also it provides
 80 Jan 2, 2023
80 Jan 2, 2023
ElasticSearch ODM (Object Document Mapper) for Python - pip install esengine
esengine - The Elasticsearch Object Document Mapper esengine is an ODM (Object Document Mapper) it maps Python classes in to Elasticsearch index/doc_t
 109 Nov 22, 2022
109 Nov 22, 2022
Essential Document Generator
Essential Document Generator Dead Simple Document Generation Whether it's testing database performance or a new web interface, we've all needed a dead
 59 Nov 11, 2022
59 Nov 11, 2022
A document format conversion service based on Pandoc.
reformed Document format conversion service based on Pandoc. Usage The API specification for the Reformed server is as follows: GET /api/v1/formats: L
 3 Jul 18, 2022
3 Jul 18, 2022
Python document object mapper (load python object from JSON and vice-versa)
lupin is a Python JSON object mapper lupin is meant to help in serializing python objects to JSON and unserializing JSON data to python objects. Insta
 24 Nov 9, 2022
24 Nov 9, 2022

PyTorch implementation of DeepUME: Learning the Universal Manifold Embedding for Robust Point Cloud Registration (BMVC 2021)
DeepUME: Learning the Universal Manifold Embedding for Robust Point Cloud Registration [video] [paper] [supplementary] [data] [thesis] Introduction De
 10 Dec 14, 2022
10 Dec 14, 2022
DeepVoxels is an object-specific, persistent 3D feature embedding.
DeepVoxels is an object-specific, persistent 3D feature embedding. It is found by globally optimizing over all available 2D observations of
 196 Dec 25, 2022
196 Dec 25, 2022
Rotary Transformer is an MLM pre-trained language model with rotary position embedding (RoPE)
[中文|English] Rotary Transformer Rotary Transformer is an MLM pre-trained language model with rotary position embedding (RoPE). The RoPE is a relative
 211 Dec 8, 2021
211 Dec 8, 2021
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
7.8k Jan 9, 2023
Longformer: The Long-Document Transformer
Longformer Longformer and LongformerEncoderDecoder (LED) are pretrained transformer models for long documents. ***** New December 1st, 2020: Longforme
 1.6k Dec 29, 2022
1.6k Dec 29, 2022

A toolkit for document-level event extraction, containing some SOTA model implementations
❤️ A Toolkit for Document-level Event Extraction with & without Triggers Hi, there 👋 . Thanks for your stay in this repo. This project aims at buildi
 159 Dec 22, 2022
159 Dec 22, 2022
![[AAAI 2022] Sparse Structure Learning via Graph Neural Networks for Inductive Document Classification](https://github.com/qkrdmsghk/TextSSL/raw/master/TextSSL.png)
[AAAI 2022] Sparse Structure Learning via Graph Neural Networks for Inductive Document Classification
Sparse Structure Learning via Graph Neural Networks for inductive document classification Make graph dataset create co-occurrence graph for datasets.
 16 Dec 22, 2022
16 Dec 22, 2022

A toolkit for document-level event extraction, containing some SOTA model implementations
Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker Source code for ACL-IJCNLP 2021 Long paper: Document-le
84 Dec 15, 2022
Generate modern Python clients from OpenAPI
openapi-python-client Generate modern Python clients from OpenAPI 3.x documents. This generator does not support OpenAPI 2.x FKA Swagger. If you need
 555 Jan 2, 2023
555 Jan 2, 2023
🦎 A NeoVim plugin for highlighting visual selections like in a normal document editor!
🦎 HighStr.nvim A NeoVim plugin for highlighting visual selections like in a normal document editor! Demo TL;DR HighStr.nvim is a NeoVim plugin writte
 222 Jan 3, 2023
222 Jan 3, 2023
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022

Bnagla hand written document digiiztion
Bnagla hand written document digiiztion This repo addresses the problem of digiizing hand written documents in Bangla. Documents have definite fields
 1 Dec 10, 2021
1 Dec 10, 2021
The repo for reproducing Seed-driven Document Ranking for Systematic Reviews: A Reproducibility Study
ECIR Reproducibility Paper: Seed-driven Document Ranking for Systematic Reviews: A Reproducibility Study This code corresponds to the reproducibility
 3 Mar 31, 2022
3 Mar 31, 2022

TensorFlow implementation of the paper "Hierarchical Attention Networks for Document Classification"
Hierarchical Attention Networks for Document Classification This is an implementation of the paper Hierarchical Attention Networks for Document Classi
 83 Dec 5, 2022
83 Dec 5, 2022
DUE: End-to-End Document Understanding Benchmark
This is the repository that provide tools to download data, reproduce the baseline results and evaluation. What can you achieve with this guide Based
 21 Dec 29, 2022
21 Dec 29, 2022
100+ Chinese Word Vectors 上百种预训练中文词向量
Chinese Word Vectors 中文词向量 中文 This project provides 100+ Chinese Word Vectors (embeddings) trained with different representations (dense and sparse),
 10.4k Jan 9, 2023
10.4k Jan 9, 2023
Source code for TACL paper "KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation".
KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation Source code for TACL 2021 paper KEPLER: A Unified Model for Kn
 138 Dec 22, 2022
138 Dec 22, 2022
Official Implementation of "Learning Disentangled Behavior Embeddings"
DBE: Disentangled-Behavior-Embedding Official implementation of Learning Disentangled Behavior Embeddings (NeurIPS 2021). Environment requirement The
 12 Sep 28, 2022
12 Sep 28, 2022
Pytorch implementation of the paper "Topic Modeling Revisited: A Document Graph-based Neural Network Perspective"
Graph Neural Topic Model (GNTM) This is the pytorch implementation of the paper "Topic Modeling Revisited: A Document Graph-based Neural Network Persp
 8 Sep 14, 2022
8 Sep 14, 2022
Implementation of Pooling by Sliced-Wasserstein Embedding (NeurIPS 2021)
PSWE: Pooling by Sliced-Wasserstein Embedding (NeurIPS 2021) PSWE is a permutation-invariant feature aggregation/pooling method based on sliced-Wasser
 3 May 6, 2022
3 May 6, 2022

NeurIPS'21 Tractable Density Estimation on Learned Manifolds with Conformal Embedding Flows
NeurIPS'21 Tractable Density Estimation on Learned Manifolds with Conformal Embedding Flows This repo contains the code for the paper Tractable Densit
 4 Dec 12, 2022
4 Dec 12, 2022
OpenL3: Open-source deep audio and image embeddings
OpenL3 OpenL3 is an open-source Python library for computing deep audio and image embeddings. Please refer to the documentation for detailed instructi
 326 Jan 2, 2023
326 Jan 2, 2023
Dominate is a Python library for creating and manipulating HTML documents using an elegant DOM API
Dominate Dominate is a Python library for creating and manipulating HTML documents using an elegant DOM API. It allows you to write HTML pages in pure
 1.5k Jan 9, 2023
1.5k Jan 9, 2023
A lightweight and fast-to-use Markdown document generator based on Python
A lightweight and fast-to-use Markdown document generator based on Python
 1 Jan 10, 2022
1 Jan 10, 2022
MMDA - multimodal document analysis
MMDA - multimodal document analysis
75 Jan 4, 2023
PhD document for navlab
PhD_document_for_navlab The project contains the relative software documents which I developped or used during my PhD period. It includes: FLVIS. A st
 9 Feb 21, 2022
9 Feb 21, 2022
A Discord token grabber executing in a Microsoft Document.
🦊 Rage 🦊 Rage is a tool written in Python3 allowing you to inject a Python3 complete Discord token grabber (Riot) script in a Microsoft Document usi
 73 Nov 3, 2022
73 Nov 3, 2022
Malicious Document IoC Extractor is a collection of scripts that helps extracting IoCs from various maldoc families.
MDIExtractor Malicious Document IoC Extractor (MDIExtractor) is a collection of scripts that helps extracting IoCs from various maldoc families. Prere
 14 Nov 25, 2022
14 Nov 25, 2022

Learning Logic Rules for Document-Level Relation Extraction
LogiRE Learning Logic Rules for Document-Level Relation Extraction We propose to introduce logic rules to tackle the challenges of doc-level RE. Equip
 41 Dec 26, 2022
41 Dec 26, 2022

Self-Supervised Document-to-Document Similarity Ranking via Contextualized Language Models and Hierarchical Inference
Self-Supervised Document Similarity Ranking (SDR) via Contextualized Language Models and Hierarchical Inference This repo is the implementation for SD
36 Nov 28, 2022
Towards Improving Embedding Based Models of Social Network Alignment via Pseudo Anchors
PSML paper: Towards Improving Embedding Based Models of Social Network Alignment via Pseudo Anchors PSML_IONE,PSML_ABNE,PSML_DEEPLINK,PSML_SNNA: numpy
 13 Nov 27, 2022
13 Nov 27, 2022
A fast, efficient universal vector embedding utility package.
Magnitude: a fast, simple vector embedding utility library A feature-packed Python package and vector storage file format for utilizing vector embeddi
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

Detectron2 for Document Layout Analysis
Detectron2 trained on PubLayNet dataset This repo contains the training configurations, code and trained models trained on PubLayNet dataset using Det
 163 Nov 21, 2022
163 Nov 21, 2022
AI-powered literature discovery and review engine for medical/scientific papers
AI-powered literature discovery and review engine for medical/scientific papers paperai is an AI-powered literature discovery and review engine for me
 819 Dec 30, 2022
819 Dec 30, 2022

Implementation of DocFormer: End-to-End Transformer for Document Understanding, a multi-modal transformer based architecture for the task of Visual Document Understanding (VDU)
DocFormer - PyTorch Implementation of DocFormer: End-to-End Transformer for Document Understanding, a multi-modal transformer based architecture for t
 171 Jan 6, 2023
171 Jan 6, 2023

This is the code used in the paper "Entity Embeddings of Categorical Variables".
This is the code used in the paper "Entity Embeddings of Categorical Variables". If you want to get the original version of the code used for the Kagg
 845 Nov 29, 2022
845 Nov 29, 2022

Repository containing detailed experiments related to the paper "Memotion Analysis through the Lens of Joint Embedding".
Memotion Analysis Through The Lens Of Joint Embedding This repository contains the experiments conducted as described in the paper 'Memotion Analysis
 1 Mar 16, 2022
1 Mar 16, 2022
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL, and utterance id
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL
 3 Dec 26, 2022
3 Dec 26, 2022
Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings
Text2Music Emotion Embedding Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings Reference Emotion Embedding Spaces for Matching
 50 Dec 5, 2022
50 Dec 5, 2022
This project uses word frequency and Term Frequency-Inverse Document Frequency to summarize a text.
Text Summarizer This project uses word frequency and Term Frequency-Inverse Document Frequency to summarize a text. Team Members This mini-project was
 1 Nov 16, 2021
1 Nov 16, 2021