147 Repositories
Python entity-linking Libraries

Entity Disambiguation as text extraction (ACL 2022)
ExtEnD: Extractive Entity Disambiguation This repository contains the code of ExtEnD: Extractive Entity Disambiguation, a novel approach to Entity Dis
 121 Jan 3, 2023
121 Jan 3, 2023

This repository consists of a complete guide on natural language processing (NLP) in Python where we'll learn various techniques for implementing NLP including parsing & text processing and understand how to use NLP for text feature engineering.
Python_Natural_Language_Processing This repository contains tutorials on important topics related to Natural Language Processing (NPL). No. Name 01 01
 170 Dec 13, 2022
170 Dec 13, 2022

Code for "Parallel Instance Query Network for Named Entity Recognition", accepted at ACL 2022.
README Code for Two-stage Identifier: "Parallel Instance Query Network for Named Entity Recognition", accepted at ACL 2022. For details of the model a
 45 Nov 29, 2022
45 Nov 29, 2022
Linking data between GBIF, Biodiverse, and Open Tree of Life
GBIF-biodiverse-OpenTree Linking data between GBIF, Biodiverse, and Open Tree of Life The python scripts will rely on opentree and Dendropy. To set up
 2 Oct 3, 2022
2 Oct 3, 2022

Spacy-ginza-ner-webapi - Named Entity Recognition API with spaCy and GiNZA
Named Entity Recognition API with spaCy and GiNZA I wrote a blog post about this
 3 Feb 27, 2022
3 Feb 27, 2022

A python package to fine-tune transformer-based models for named entity recognition (NER).
nerblackbox A python package to fine-tune transformer-based language models for named entity recognition (NER). Resources Source Code: https://github.
 13 Jul 30, 2022
13 Jul 30, 2022
Python command line tool and python engine to label table fields and fields in data files.
Python command line tool and python engine to label table fields and fields in data files. It could help to find meaningful data in your tables and data files or to find Personal identifable information (PII).
 22 Dec 5, 2022
22 Dec 5, 2022
TFPNER: Exploration on the Named Entity Recognition of Token Fused with Part-of-Speech
TFPNER TFPNER: Exploration on the Named Entity Recognition of Token Fused with Part-of-Speech Named entity recognition (NER), which aims at identifyin
 1 Feb 7, 2022
1 Feb 7, 2022

This repository provides the official code for GeNER (an automated dataset Generation framework for NER).
GeNER This repository provides the official code for GeNER (an automated dataset Generation framework for NER). Overview of GeNER GeNER allows you to
 50 Nov 30, 2022
50 Nov 30, 2022
This repository contains (not all) code from my project on Named Entity Recognition in philosophical text
NERphilosophy 👋 Welcome to the github repository of my BsC thesis. This repository contains (not all) code from my project on Named Entity Recognitio
 1 Jan 27, 2022
1 Jan 27, 2022
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
TweebankNLP This repo contains the new Tweebank-NER dataset and off-the-shelf Twitter-Stanza pipeline for state-of-the-art Tweet NLP, as described in
 42 Jan 26, 2022
42 Jan 26, 2022
RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2
RoNER RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2. It is meant to be an easy to use, hi
 9 Nov 7, 2022
9 Nov 7, 2022
Stanford CoreNLP provides a set of natural language analysis tools written in Java
Stanford CoreNLP Stanford CoreNLP provides a set of natural language analysis tools written in Java. It can take raw human language text input and giv
 8.8k Jan 7, 2023
8.8k Jan 7, 2023
Code for the paper BERT might be Overkill: A Tiny but Effective Biomedical Entity Linker based on Residual Convolutional Neural Networks
Biomedical Entity Linking This repo provides the code for the paper BERT might be Overkill: A Tiny but Effective Biomedical Entity Linker based on Res
 24 Oct 24, 2022
24 Oct 24, 2022
TweebankNLP - Pre-trained Tweet NLP Pipeline (NER, tokenization, lemmatization, POS tagging, dependency parsing) + Models + Tweebank-NER
TweebankNLP This repo contains the new Tweebank-NER dataset and Twitter-Stanza p
84 Dec 20, 2022
Effective Use of Transformer Networks for Entity Tracking
Effective Use of Transformer Networks for Entity Tracking (EMNLP19) This is a PyTorch implementation of our EMNLP paper on the effectiveness of pre-tr
 5 Nov 6, 2021
5 Nov 6, 2021
A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
DeepKE is a knowledge extraction toolkit supporting low-resource and document-level scenarios for entity, relation and attribute extraction. We provide comprehensive documents, Google Colab tutorials, and online demo for beginners.
 1.6k Jan 5, 2023
1.6k Jan 5, 2023
PyTorch code for JEREX: Joint Entity-Level Relation Extractor
JEREX: "Joint Entity-Level Relation Extractor" PyTorch code for JEREX: "Joint Entity-Level Relation Extractor". For a description of the model and exp
 50 Dec 1, 2022
50 Dec 1, 2022
HuSpaCy: industrial-strength Hungarian natural language processing
HuSpaCy: Industrial-strength Hungarian NLP HuSpaCy is a spaCy model and a library providing industrial-strength Hungarian language processing faciliti
 120 Dec 14, 2022
120 Dec 14, 2022
Import entity definition document into SQLie3. Manage the entity. Also, create a "Create Table SQL file".
EntityDocumentMaker Version 1.00 After importing the entity definition (Excel file), store the data in sqlite3. エンティティ定義(Excelファイル)をインポートした後、データをsqlit
 1 Jan 9, 2022
1 Jan 9, 2022
Using BERT+Bi-LSTM+CRF
Chinese Medical Entity Recognition Based on BERT+Bi-LSTM+CRF Step 1 I share the dataset on my google drive, please download the whole 'CCKS_2019_Task1
 55 Dec 21, 2022
55 Dec 21, 2022
DeepMusic is an easy to use Spotify like app to manage and listen to your favorites musics.
DeepMusic is an easy to use Spotify like app to manage and listen to your favorites musics. Technically, this project is an Android Client and its ent
 1 Jul 12, 2021
1 Jul 12, 2021
NLP techniques such as named entity recognition, sentiment analysis, topic modeling, text classification with Python to predict sentiment and rating of drug from user reviews.
This file contains the following documents sumbited for Baruch CIS9665 group 9 fall 2021. 1. Dataset: drug_reviews.csv 2. python codes for text classi
 2 Jan 4, 2023
2 Jan 4, 2023

👑 spaCy building blocks and visualizers for Streamlit apps
spacy-streamlit: spaCy building blocks for Streamlit apps This package contains utilities for visualizing spaCy models and building interactive spaCy-
 620 Dec 29, 2022
620 Dec 29, 2022
KIND: an Italian Multi-Domain Dataset for Named Entity Recognition
KIND (Kessler Italian Named-entities Dataset) KIND is an Italian dataset for Named-Entity Recognition. It contains more than one million tokens with t
 5 Jun 21, 2022
5 Jun 21, 2022
![[CVPR 2020] Transform and Tell: Entity-Aware News Image Captioning](https://github.com/alasdairtran/transform-and-tell/raw/master/figures/teaser.png)
[CVPR 2020] Transform and Tell: Entity-Aware News Image Captioning
Transform and Tell: Entity-Aware News Image Captioning This repository contains the code to reproduce the results in our CVPR 2020 paper Transform and
 85 Dec 13, 2022
85 Dec 13, 2022

GoodNews Everyone! Context driven entity aware captioning for news images
This is the code for a CVPR 2019 paper, called GoodNews Everyone! Context driven entity aware captioning for news images. Enjoy! Model preview: Huge T
 117 Dec 19, 2022
117 Dec 19, 2022

Fashion Entity Classification
Fashion-Entity-Classification - Fashion-MNIST is a dataset of Zalando's article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes. Zalando intends Fashion-MNIST to serve as a direct drop-in replacement for the original MNIST dataset for benchmarking machine learning algorithms. It shares the same image size and structure of training and testing splits.
 1 Jan 4, 2022
1 Jan 4, 2022

Automatically generates a TypeQL script for doing entity and relationship insertions from a .csv file, so you don't have to mess with writing TypeQL.
Automatically generates a TypeQL script for doing entity and relationship insertions from a .csv file, so you don't have to mess with writing TypeQL.
 3 Feb 9, 2022
3 Feb 9, 2022

Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning And private Server services
Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning
 4.2k Dec 29, 2022
4.2k Dec 29, 2022
Pytorch implementation of the paper "COAD: Contrastive Pre-training with Adversarial Fine-tuning for Zero-shot Expert Linking."
Expert-Linking Pytorch implementation of the paper "COAD: Contrastive Pre-training with Adversarial Fine-tuning for Zero-shot Expert Linking." This is
 12 Jan 1, 2023
12 Jan 1, 2023

Align and Prompt: Video-and-Language Pre-training with Entity Prompts
ALPRO Align and Prompt: Video-and-Language Pre-training with Entity Prompts [Paper] Dongxu Li, Junnan Li, Hongdong Li, Juan Carlos Niebles, Steven C.H
 127 Dec 21, 2022
127 Dec 21, 2022
Extract city and country mentions from Text like GeoText without regex, but FlashText, a Aho-Corasick implementation.
flashgeotext ⚡ 🌍 Extract and count countries and cities (+their synonyms) from text, like GeoText on steroids using FlashText, a Aho-Corasick impleme
 57 Dec 16, 2022
57 Dec 16, 2022
Artificial Conversational Entity for queries in Eulogio "Amang" Rodriguez Institute of Science and Technology (EARIST)
🤖 Coeus - EARIST A.C.E 💬 Coeus is an Artificial Conversational Entity for queries in Eulogio "Amang" Rodriguez Institute of Science and Technology,
 3 Oct 14, 2022
3 Oct 14, 2022

Fast and robust date extraction from web pages, with Python or on the command-line
Find original and updated publication dates of any web page. From the command-line or within Python, all the steps needed from web page download to HTML parsing, scraping, and text analysis are included.
 60 Dec 14, 2022
60 Dec 14, 2022
Flexible constructor to create dynamic list of heterogeneous properties for some kind of entity
Flexible constructor to create dynamic list of heterogeneous properties for some kind of entity. This set of helpers useful to create properties like contacts or attributes for describe car/computer/etc.
 24 Jul 21, 2022
24 Jul 21, 2022
An elaborate and exhaustive paper list for Named Entity Recognition (NER)
Named-Entity-Recognition-NER-Papers by Pengfei Liu, Jinlan Fu and other contributors. An elaborate and exhaustive paper list for Named Entity Recognit
 388 Dec 18, 2022
388 Dec 18, 2022

Healthsea is a spaCy pipeline for analyzing user reviews of supplementary products for their effects on health.
Welcome to Healthsea ✨ Create better access to health with spaCy. Healthsea is a pipeline for analyzing user reviews to supplement products by extract
75 Dec 19, 2022
Chinese named entity recognization with BiLSTM using Keras
Chinese named entity recognization (Bilstm with Keras) Project Structure ./ ├── README.md ├── data │ ├── README.md │ ├── data 数据集 │ │ ├─
 1 Dec 17, 2021
1 Dec 17, 2021
Chinese named entity recognization (bert/roberta/macbert/bert_wwm with Keras)
Chinese named entity recognization (bert/roberta/macbert/bert_wwm with Keras)
2 Jul 5, 2022
Chinese Named Entity Recognization (BiLSTM with PyTorch)
BiLSTM-CRF for Name Entity Recognition PyTorch version A PyTorch implemention of Bi-LSTM-CRF model for Chinese Named Entity Recognition. 使用 PyTorch 实现
5 Jun 1, 2022
Transcribing audio files using Hugging Face's implementation of Wav2Vec2 + "chain-linking" NLP tasks to combine speech-to-text with downstream tasks like translation and summarisation.
PART 2: CHAIN LINKING AUDIO-TO-TEXT NLP TASKS 2A: TRANSCRIBE-TRANSLATE-SENTIMENT-ANALYSIS In notebook3.0, I demo a simple workflow to: transcribe a lo
 30 Jul 13, 2022
30 Jul 13, 2022

Autoregressive Entity Retrieval
The GENRE (Generative ENtity REtrieval) system as presented in Autoregressive Entity Retrieval implemented in pytorch. @inproceedings{decao2020autoreg
 611 Dec 16, 2022
611 Dec 16, 2022
A computational block to solve entity alignment over textual attributes in a knowledge graph creation pipeline.
How to apply? Create your config.ini file following the example provided in config.ini Choose one of the options below to run: Run with Python3 pip in
 3 Jun 23, 2022
3 Jun 23, 2022
ANEA: Automated (Named) Entity Annotation for German Domain-Specific Texts
ANEA The goal of Automatic (Named) Entity Annotation is to create a small annotated dataset for NER extracted from German domain-specific texts. Insta
 2 Oct 7, 2022
2 Oct 7, 2022
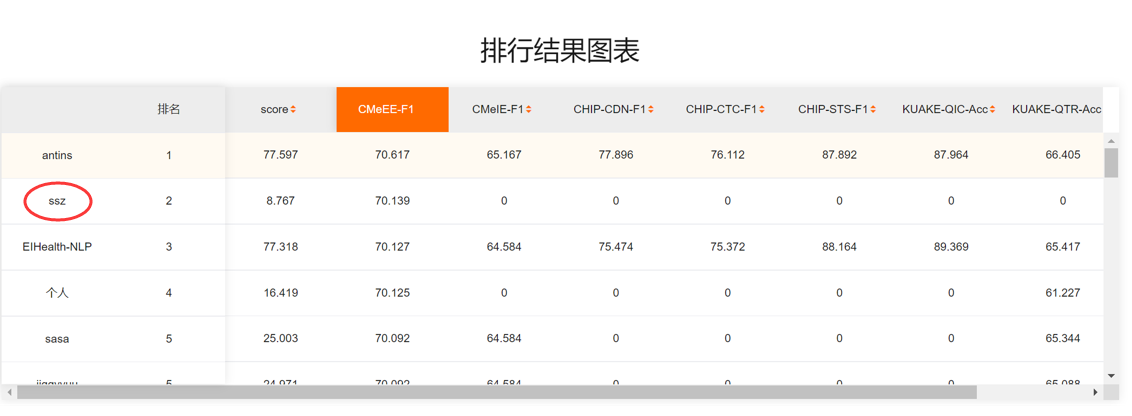
Nested Named Entity Recognition for Chinese Biomedical Text
CBio-NAMER CBioNAMER (Nested nAMed Entity Recognition for Chinese Biomedical Text) is our method used in CBLUE (Chinese Biomedical Language Understand
 8 Dec 25, 2022
8 Dec 25, 2022
Simple bots or Simbots is a library designed to create simple bots using the power of python. This library utilises Intent, Entity, Relation and Context model to create bots .
Simple bots or Simbots is a library designed to create simple chat bots using the power of python. This library utilises Intent, Entity, Relation and
 14 Dec 15, 2021
14 Dec 15, 2021
Multi-Task Deep Neural Networks for Natural Language Understanding
New Release We released Adversarial training for both LM pre-training/finetuning and f-divergence. Large-scale Adversarial training for LMs: ALUM code
 2.1k Dec 30, 2022
2.1k Dec 30, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022
Code repository for the paper Computer Vision User Entity Behavior Analytics
Computer Vision User Entity Behavior Analytics Code repository for "Computer Vision User Entity Behavior Analytics" Code Description dataset.csv As di
 2 Aug 20, 2022
2 Aug 20, 2022
An open-source Kazakh named entity recognition dataset (KazNERD), annotation guidelines, and baseline NER models.
Kazakh Named Entity Recognition This repository contains an open-source Kazakh named entity recognition dataset (KazNERD), named entity annotation gui
 9 Dec 23, 2022
9 Dec 23, 2022
Nested Named Entity Recognition
Nested Named Entity Recognition Training Dataset: CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark url: https://tianchi.aliyun.
8 Dec 25, 2022
Collection of in-progress libraries for entity neural networks.
ENN Incubator Collection of in-progress libraries for entity neural networks: Neural Network Architectures for Structured State Entity Gym: Abstractio
 25 Dec 1, 2022
25 Dec 1, 2022
Stanza: A Python NLP Library for Many Human Languages
Official Stanford NLP Python Library for Many Human Languages
5.8k Nov 22, 2021

This is the code used in the paper "Entity Embeddings of Categorical Variables".
This is the code used in the paper "Entity Embeddings of Categorical Variables". If you want to get the original version of the code used for the Kagg
 845 Nov 29, 2022
845 Nov 29, 2022

Solving Zero-Shot Learning in Named Entity Recognition with Common Sense Knowledge
Zero-Shot Learning in Named Entity Recognition with Common Sense Knowledge Associated code for the paper Zero-Shot Learning in Named Entity Recognitio
 13 Dec 25, 2022
13 Dec 25, 2022
Entity-Based Knowledge Conflicts in Question Answering.
Entity-Based Knowledge Conflicts in Question Answering Run Instructions | Paper | Citation | License This repository provides the Substitution Framewo
 35 Oct 19, 2022
35 Oct 19, 2022
ANEA: Distant Supervision for Low-Resource Named Entity Recognition
ANEA: Distant Supervision for Low-Resource Named Entity Recognition ANEA is a tool to automatically annotate named entities in unlabeled text based on
 15 Mar 30, 2022
15 Mar 30, 2022
Named Entity Recognition API used by TEI Publisher
TEI Publisher Named Entity Recognition API This repository contains the API used by TEI Publisher's web-annotation editor to detect entities in the in
 14 Nov 15, 2022
14 Nov 15, 2022
Use Google's BERT for named entity recognition (CoNLL-2003 as the dataset).
For better performance, you can try NLPGNN, see NLPGNN for more details. BERT-NER Version 2 Use Google's BERT for named entity recognition (CoNLL-2003
 1.2k Dec 26, 2022
1.2k Dec 26, 2022
Implemented shortest-circuit disambiguation, maximum probability disambiguation, HMM-based lexical annotation and BiLSTM+CRF-based named entity recognition
Implemented shortest-circuit disambiguation, maximum probability disambiguation, HMM-based lexical annotation and BiLSTM+CRF-based named entity recognition
 0 Feb 13, 2022
0 Feb 13, 2022
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
 1.6k Jan 3, 2023
1.6k Jan 3, 2023
Probabilistic Entity Representation Model for Reasoning over Knowledge Graphs
Implementation for the paper: Probabilistic Entity Representation Model for Reasoning over Knowledge Graphs, Nurendra Choudhary, Nikhil Rao, Sumeet Ka
 8 Nov 15, 2022
8 Nov 15, 2022
jel - Japanese Entity Linker - is Bi-encoder based entity linker for japanese.
jel: Japanese Entity Linker jel - Japanese Entity Linker - is Bi-encoder based entity linker for japanese. Usage Currently, link and question methods
 10 Jan 6, 2023
10 Jan 6, 2023

Example Of Fine-Tuning BERT For Named-Entity Recognition Task And Preparing For Cloud Deployment Using Flask, React, And Docker
Example Of Fine-Tuning BERT For Named-Entity Recognition Task And Preparing For Cloud Deployment Using Flask, React, And Docker This repository contai
 12 Dec 14, 2022
12 Dec 14, 2022

A Partition Filter Network for Joint Entity and Relation Extraction EMNLP 2021
EMNLP 2021 - A Partition Filter Network for Joint Entity and Relation Extraction
 127 Jan 4, 2023
127 Jan 4, 2023
A cross-document event and entity coreference resolution system, trained and evaluated on the ECB+ corpus.
A Comprehensive Comparison of Word Embeddings in Event & Entity Coreference Resolution. Introduction This repo contains experimental code derived from
 2 May 9, 2022
2 May 9, 2022
EMNLP'2021: Simple Entity-centric Questions Challenge Dense Retrievers
EntityQuestions This repository contains the EntityQuestions dataset as well as code to evaluate retrieval results from the the paper Simple Entity-ce
 50 Sep 24, 2021
50 Sep 24, 2021

GLaRA: Graph-based Labeling Rule Augmentation for Weakly Supervised Named Entity Recognition
GLaRA: Graph-based Labeling Rule Augmentation for Weakly Supervised Named Entity Recognition
 29 Dec 26, 2022
29 Dec 26, 2022
This is the source code for: Context-aware Entity Typing in Knowledge Graphs.
This is the source code for: Context-aware Entity Typing in Knowledge Graphs.
 9 Sep 1, 2022
9 Sep 1, 2022
EMNLP'2021: Simple Entity-centric Questions Challenge Dense Retrievers
EntityQuestions This repository contains the EntityQuestions dataset as well as code to evaluate retrieval results from the the paper Simple Entity-ce
119 Sep 28, 2022

Source code for "Pack Together: Entity and Relation Extraction with Levitated Marker"
PL-Marker Source code for Pack Together: Entity and Relation Extraction with Levitated Marker. Quick links Overview Setup Install Dependencies Data Pr
 173 Dec 30, 2022
173 Dec 30, 2022
A spaCy wrapper of OpenTapioca for named entity linking on Wikidata
spaCyOpenTapioca A spaCy wrapper of OpenTapioca for named entity linking on Wikidata. Table of contents Installation How to use Local OpenTapioca Vizu
 80 Jan 3, 2023
80 Jan 3, 2023
[EMNLP 2021] MuVER: Improving First-Stage Entity Retrieval with Multi-View Entity Representations
MuVER This repo contains the code and pre-trained model for our EMNLP 2021 paper: MuVER: Improving First-Stage Entity Retrieval with Multi-View Entity
 24 May 30, 2022
24 May 30, 2022

Tool to add main subject to items on Wikidata using a WMFs CirrusSearch for named entity recognition or a manually supplied list of QIDs
ItemSubjector Tool made to add main subject statements to items based on the title using a home-brewed CirrusSearch-based Named Entity Recognition alg
 9 Nov 17, 2022
9 Nov 17, 2022

“Data Augmentation for Cross-Domain Named Entity Recognition” (EMNLP 2021)
Data Augmentation for Cross-Domain Named Entity Recognition Authors: Shuguang Chen, Gustavo Aguilar, Leonardo Neves and Thamar Solorio This repository
 18 Sep 10, 2022
18 Sep 10, 2022
[EMNLP 2021] Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training
RoSTER The source code used for Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training, p
 60 Dec 30, 2022
60 Dec 30, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
Source Code For Template-Based Named Entity Recognition Using BART
Template-Based NER Source Code For Template-Based Named Entity Recognition Using BART Training Training train.py Inference inference.py Corpus ATIS (h
 174 Dec 19, 2022
174 Dec 19, 2022

Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions
Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions To learn more about this project: medium blog post The goal of this proje
 60 Dec 17, 2022
60 Dec 17, 2022
Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning
structshot Code and data for paper "Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning", Yi Yang and Arz
 47 Dec 27, 2022
47 Dec 27, 2022
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023
Collective Multi-type Entity Alignment Between Knowledge Graphs (WWW'20)
CG-MuAlign A reference implementation for "Collective Multi-type Entity Alignment Between Knowledge Graphs", published in WWW 2020. If you find our pa
 28 Dec 11, 2022
28 Dec 11, 2022
[ACL-IJCNLP 2021] Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning
CLNER The code is for our ACL-IJCNLP 2021 paper: Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning CLNER is a
71 Dec 8, 2022

Open-World Entity Segmentation
Open-World Entity Segmentation Project Website Lu Qi*, Jason Kuen*, Yi Wang, Jiuxiang Gu, Hengshuang Zhao, Zhe Lin, Philip Torr, Jiaya Jia This projec
 410 Jan 3, 2023
410 Jan 3, 2023

"Inductive Entity Representations from Text via Link Prediction" @ The Web Conference 2021
Inductive entity representations from text via link prediction This repository contains the code used for the experiments in the paper "Inductive enti
 45 Jan 9, 2023
45 Jan 9, 2023
Open-World Entity Segmentation
Open-World Entity Segmentation Project Website Lu Qi*, Jason Kuen*, Yi Wang, Jiuxiang Gu, Hengshuang Zhao, Zhe Lin, Philip Torr, Jiaya Jia This projec
408 Dec 29, 2022

A text augmentation tool for named entity recognition.
neraug This python library helps you with augmenting text data for named entity recognition. Augmentation Example Reference from An Analysis of Simple
 48 Oct 11, 2022
48 Oct 11, 2022

A heterogeneous entity-augmented academic language model based on Open Academic Graph (OAG)
Library | Paper | Slack We released two versions of OAG-BERT in CogDL package. OAG-BERT is a heterogeneous entity-augmented academic language model wh
 58 Dec 17, 2022
58 Dec 17, 2022
Source code for "UniRE: A Unified Label Space for Entity Relation Extraction.", ACL2021.
UniRE Source code for "UniRE: A Unified Label Space for Entity Relation Extraction.", ACL2021. Requirements python: 3.7.6 pytorch: 1.8.1 transformers:
 109 Nov 29, 2022
109 Nov 29, 2022

Implementation for our AAAI2021 paper (Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction).
SSAN Introduction This is the pytorch implementation of the SSAN model (see our AAAI2021 paper: Entity Structure Within and Throughout: Modeling Menti
 69 Nov 15, 2022
69 Nov 15, 2022

Code for Two-stage Identifier: "Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition"
Code for Two-stage Identifier: "Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition", accepted at ACL 2021. For details of the model and experiments, please see our paper.
87 Dec 16, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022
Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning".
ERICA Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive L
75 Nov 2, 2022
Ecommerce product title recognition package
revizor This package solves task of splitting product title string into components, like type, brand, model and article (or SKU or product code or you
 16 Mar 3, 2022
16 Mar 3, 2022
Chinese clinical named entity recognition using pre-trained BERT model
Chinese clinical named entity recognition (CNER) using pre-trained BERT model Introduction Code for paper Chinese clinical named entity recognition wi
 109 Dec 14, 2022
109 Dec 14, 2022

A look-ahead multi-entity Transformer for modeling coordinated agents.
baller2vec++ This is the repository for the paper: Michael A. Alcorn and Anh Nguyen. baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling
 30 Dec 16, 2022
30 Dec 16, 2022
Deduplication is the task to combine different representations of the same real world entity.
Deduplication is the task to combine different representations of the same real world entity. This package implements deduplication using active learning. Active learning allows for rapid training without having to provide a large, manually labelled dataset.
 63 Nov 17, 2022
63 Nov 17, 2022