3149 Repositories
Python fast-data-pipeline Libraries
TIANCHI Purchase Redemption Forecast Challenge
TIANCHI Purchase Redemption Forecast Challenge
 4 Aug 26, 2022
4 Aug 26, 2022
WikiPron - a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary
WikiPron WikiPron is a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary, as well as a database of pronuncia
 213 Jan 1, 2023
213 Jan 1, 2023
Dead simple CSRF security middleware for Starlette ⭐ and Fast API ⚡
csrf-starlette-fastapi Dead simple CSRF security middleware for Starlette ⭐ and Fast API ⚡ Will work with either a input type="hidden" field or ajax
 9 Nov 20, 2022
9 Nov 20, 2022
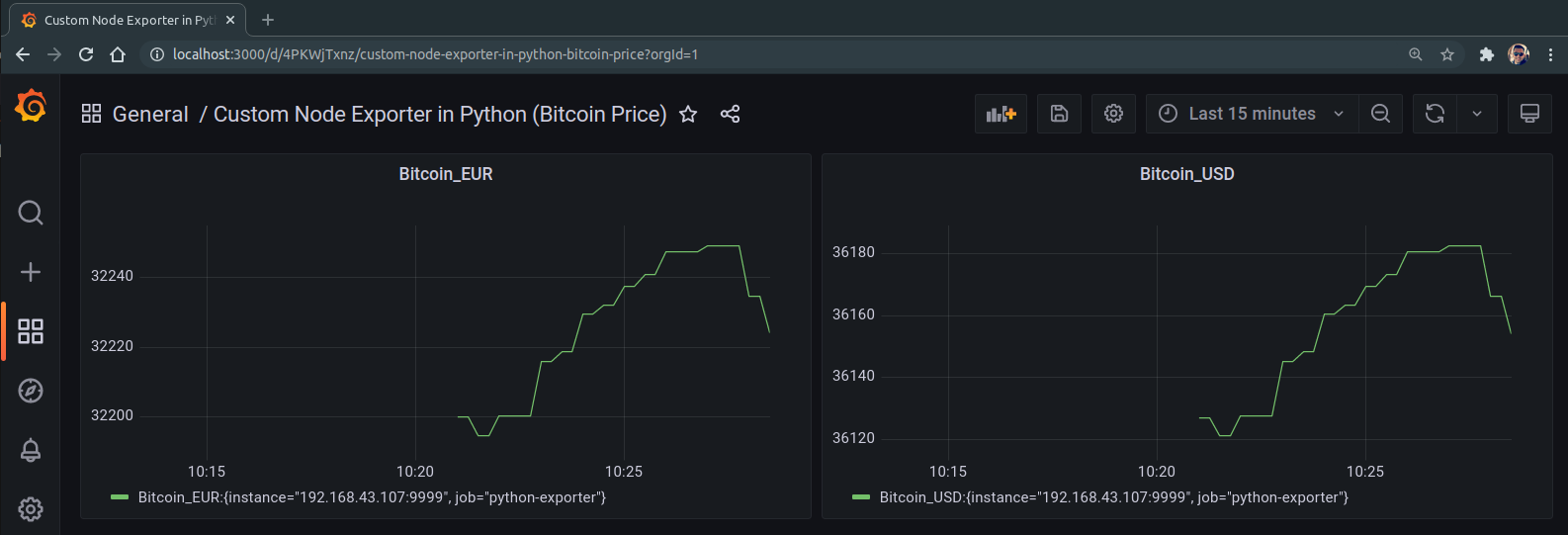
Import some key/value data to Prometheus custom-built Node Exporter in Python
About the app In one particilar project, i had to import some key/value data to Prometheus. So i have decided to create my custom-built Node Exporter
 1 May 19, 2022
1 May 19, 2022

Machine Learning e Data Science com Python
Machine Learning e Data Science com Python Arquivos do curso de Data Science e Machine Learning com Python na Udemy, cliqe aqui para acessá-lo. O prin
 1 Jan 27, 2022
1 Jan 27, 2022
Clean and reusable data-sciency notebooks.
KPACUBO KPACUBO is a set Jupyter notebooks focused on the best practices in both software development and data science, namely, code reuse, explicit d
 1 Jan 28, 2022
1 Jan 28, 2022

This repository contains the raw data and a python notebook to ingest historical A&E attendance data and then use a simple Prophet model to predict the number of A&E attendances in England if the COVID-19 pandemic had not happened
ae_attendances_modelling This repository contains the raw data and a python notebook to ingest historical A&E attendance data and then use a simple Pr
 2 Mar 29, 2022
2 Mar 29, 2022
FAIR Enough Metrics is an API for various FAIR Metrics Tests, written in python
☑️ FAIR Enough metrics for research FAIR Enough Metrics is an API for various FAIR Metrics Tests, written in python, conforming to the specifications
 3 Jul 6, 2022
3 Jul 6, 2022
This repository contains the implementation of the HealthGen model, a generative model to synthesize realistic EHR time series data with missingness
HealthGen: Conditional EHR Time Series Generation This repository contains the implementation of the HealthGen model, a generative model to synthesize
 0 Jan 20, 2022
0 Jan 20, 2022

A PyTorch implementation for our paper "Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation".
Dual-Contrastive-Learning A PyTorch implementation for our paper "Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation". Y
 85 Dec 26, 2022
85 Dec 26, 2022

PyTorch implementation for the paper Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime
Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime Created by Prarthana Bhattacharyya. Disclaimer: This is n
 5 Nov 8, 2022
5 Nov 8, 2022

coldcuts is an R package to automatically generate and plot segmentation drawings in R
coldcuts coldcuts is an R package that allows you to draw and plot automatically segmentations from 3D voxel arrays. The name is inspired by one of It
 2 Sep 3, 2022
2 Sep 3, 2022
Fast and exact ILP-based solvers for the Minimum Flow Decomposition (MFD) problem, and variants of it.
MFD-ILP Fast and exact ILP-based solvers for the Minimum Flow Decomposition (MFD) problem, and variants of it. The solvers are implemented using Pytho
 4 Oct 23, 2022
4 Oct 23, 2022
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques This repository is derived from the NMTGMinor
 1 Sep 7, 2022
1 Sep 7, 2022
Semantic code search implementation using Tensorflow framework and the source code data from the CodeSearchNet project
Semantic Code Search Semantic code search implementation using Tensorflow framework and the source code data from the CodeSearchNet project. The model
 24 Nov 29, 2022
24 Nov 29, 2022
Image super-resolution (SR) is a fast-moving field with novel architectures attracting the spotlight
Revisiting RCAN: Improved Training for Image Super-Resolution Introduction Image super-resolution (SR) is a fast-moving field with novel architectures
 76 Dec 1, 2022
76 Dec 1, 2022
Code for the paper titled "Prabhupadavani: A Code-mixed Speech Translation Data for 25 languages"
Prabhupadavani: A Code-mixed Speech Translation Data for 25 languages Code for the paper titled "Prabhupadavani: A Code-mixed Speech Translation Data
 12 Dec 1, 2022
12 Dec 1, 2022

Hyperparameters tuning and features selection are two common steps in every machine learning pipeline.
shap-hypetune A python package for simultaneous Hyperparameters Tuning and Features Selection for Gradient Boosting Models. Overview Hyperparameters t
 422 Jan 8, 2023
422 Jan 8, 2023
A classification model capable of accurately predicting the price of secondhand cars
The purpose of this project is create a classification model capable of accurately predicting the price of secondhand cars. The data used for model building is open source and has been added to this repository. Most packages used are usually pre-installed in most developed environments and tools like collab, jupyter, etc. This can be useful for people looking to enhance the way the code their predicitve models and efficient ways to deal with tabular data!
 2 Sep 13, 2022
2 Sep 13, 2022

Analyzing Earth Observation (EO) data is complex and solutions often require custom tailored algorithms.
eo-grow Earth observation framework for scaled-up processing in Python. Analyzing Earth Observation (EO) data is complex and solutions often require c
 18 Dec 23, 2022
18 Dec 23, 2022
Statistical & Probabilistic Analysis of Store Sales, University Survey, & Manufacturing data
Statistical_Modelling Statistical & Probabilistic Analysis of Store Sales, University Survey, & Manufacturing data Statistical Methods for Decision Ma
 1 Jan 27, 2022
1 Jan 27, 2022
Melanoma Skin Cancer Detection using Convolutional Neural Networks and Transfer Learning🕵🏻♂️
This is a Kaggle competition in which we have to identify if the given lesion image is malignant or not for Melanoma which is a type of skin cancer.
 1 Jan 27, 2022
1 Jan 27, 2022

Final Project for Practical Python Programming and Algorithms for Data Analysis
Final Project for Practical Python Programming and Algorithms for Data Analysis (PHW2781L, Summer 2020) Redlining, Race-Exclusive Deed Restriction Lan
 1 Jan 27, 2022
1 Jan 27, 2022
Fetch fund data from avanza.se using Python and some web scraping with bs4
Py(A)vanza Fetch fund data from avanza.se using Python and some web scraping with bs4. The default way is to display the data in the terminal, apply -
 1 Jan 27, 2022
1 Jan 27, 2022

The Dual Memory is build from a simple CNN for the deep memory and Linear Regression fro the fast Memory
Simple-DMA a simple Dual Memory Architecture for classifications. based on the paper Dual-Memory Deep Learning Architectures for Lifelong Learning of
 1 Jan 27, 2022
1 Jan 27, 2022
Storing, versioning, and downloading files from S3 made as easy as using open() in Python. Caching included.
open(LARGE) Storing, versioning, and downloading files from S3 made as easy as using open() in Python. Caching included. Motivation Oftentimes, especi
 2 Jan 30, 2022
2 Jan 30, 2022
This library provides an abstraction to perform Model Versioning using Weight & Biases.
Description This library provides an abstraction to perform Model Versioning using Weight & Biases. Features Version a new trained model Promote a mod
 2 Jan 28, 2022
2 Jan 28, 2022
Python-geoarrow - Storing geometry data in Apache Arrow format
geoarrow Storing geometry data in Apache Arrow format Installation $ pip install
 11 Mar 3, 2022
11 Mar 3, 2022
Django-fast-export - Utilities for quickly streaming CSV responses to the client
django-fast-export Utilities for quickly streaming CSV responses to the client T
 4 Aug 24, 2022
4 Aug 24, 2022
Scikit-event-correlation - Event Correlation and Forecasting over High Dimensional Streaming Sensor Data algorithms
scikit-event-correlation Event Correlation and Changing Detection Algorithm Theo
 5 Oct 30, 2022
5 Oct 30, 2022
Graviti-python-sdk - Graviti Data Platform Python SDK
Graviti Python SDK Graviti Python SDK is a python library to access Graviti Data
 13 Dec 15, 2022
13 Dec 15, 2022

DomainMonitor is a web project that has a RESTful API to get a domain's subdomains and whois data.
DomainMonitor is a web project that has a RESTful API to get a domain's subdomains and whois data.
 2 Feb 5, 2022
2 Feb 5, 2022
OptiPLANT is a cloud-based based system that empowers professional and non-professional data scientists to build high-quality predictive models
OptiPLANT OptiPLANT is a cloud-based based system that empowers professional and non-professional data scientists to build high-quality predictive mod
1 Jan 26, 2022
MGE-GraphQL is a Python library for building GraphQL mutations fast and easily
MGE-GraphQL Introduction MGE-GraphQL is a Python library for building GraphQL mutations fast and easily. Data Validations: A similar data validation w
 4 Apr 23, 2022
4 Apr 23, 2022

Dynamic vae - Dynamic VAE algorithm is used for anomaly detection of battery data
Dynamic VAE frame Automatic feature extraction can be achieved by probability di
 10 Oct 7, 2022
10 Oct 7, 2022

This repo provides the source code & data of our paper "GreaseLM: Graph REASoning Enhanced Language Models"
GreaseLM: Graph REASoning Enhanced Language Models This repo provides the source code & data of our paper "GreaseLM: Graph REASoning Enhanced Language
 137 Jan 2, 2023
137 Jan 2, 2023

Clustering is a popular approach to detect patterns in unlabeled data
Visual Clustering Clustering is a popular approach to detect patterns in unlabeled data. Existing clustering methods typically treat samples in a data
 24 Nov 11, 2022
24 Nov 11, 2022
SpyQL - SQL with Python in the middle
SpyQL SQL with Python in the middle Concept SpyQL is a query language that combines: the simplicity and structure of SQL with the power and readabilit
 853 Dec 30, 2022
853 Dec 30, 2022
Data-sets from the survey and analysis
bachelor-thesis "Umfragewerte.xlsx" contains the orginal survey results. "umfrage_alle.csv" contains the survey results but one participant is cancele
 1 Jan 26, 2022
1 Jan 26, 2022
Tools and Docker images to make a fast Ruby on Rails development environment
Tools and Docker images to make a fast Ruby on Rails development environment. With the production templates, moving from development to production will be seamless.
 1 Nov 13, 2022
1 Nov 13, 2022
Compute execution plan: A DAG representation of work that you want to get done. Individual nodes of the DAG could be simple python or shell tasks or complex deeply nested parallel branches or embedded DAGs themselves.
Hello from magnus Magnus provides four capabilities for data teams: Compute execution plan: A DAG representation of work that you want to get done. In
 12 Feb 8, 2022
12 Feb 8, 2022
Es-schema - Common Data Schemas for Elasticsearch
Common Data Schemas for Elasticsearch The Common Data Schema for Elasticsearch i
 2 Jan 25, 2022
2 Jan 25, 2022
E2EDNA2 - An automated pipeline for simulation of DNA aptamers complexed with small molecules and short peptides
E2EDNA2 - An automated pipeline for simulation of DNA aptamers complexed with small molecules and short peptides
 11 Nov 8, 2022
11 Nov 8, 2022
Data analysis and visualisation projects from a range of individual projects and applications
Python-Data-Analysis-and-Visualisation-Projects Data analysis and visualisation projects from a range of individual projects and applications. Python
 1 Jan 25, 2022
1 Jan 25, 2022

Predicting Auction Sale Price using the kaggle bulldozer auction sales data: Modeling with Ensembles vs Neural Network
Predicting Auction Sale Price using the kaggle bulldozer auction sales data: Modeling with Ensembles vs Neural Network The performances of tree ensemb
 2 Sep 13, 2022
2 Sep 13, 2022
A program made in PYTHON🐍 that automatically performs data insertions into a POSTGRES database 🐘 , using as base a .CSV file 📁 , useful in mass data insertions
A program made in PYTHON🐍 that automatically performs data insertions into a POSTGRES database 🐘 , using as base a .CSV file 📁 , useful in mass data insertions.
 1 Oct 17, 2022
1 Oct 17, 2022
Labelbox is the fastest way to annotate data to build and ship artificial intelligence applications
Labelbox Labelbox is the fastest way to annotate data to build and ship artificial intelligence applications. Use this github repository to help you s
 1.7k Dec 29, 2022
1.7k Dec 29, 2022
Doing fast searching of nearest neighbors in high dimensional spaces is an increasingly important problem
Benchmarking nearest neighbors Doing fast searching of nearest neighbors in high dimensional spaces is an increasingly important problem, but so far t
 3.2k Jan 3, 2023
3.2k Jan 3, 2023

FairLens is an open source Python library for automatically discovering bias and measuring fairness in data
FairLens FairLens is an open source Python library for automatically discovering bias and measuring fairness in data. The package can be used to quick
 69 Dec 15, 2022
69 Dec 15, 2022
This is a curated list of medical data for machine learning
Medical Data for Machine Learning This is a curated list of medical data for machine learning. This list is provided for informational purposes only,
 5.4k Dec 26, 2022
5.4k Dec 26, 2022
Segment axon and myelin from microscopy data using deep learning
Segment axon and myelin from microscopy data using deep learning. Written in Python. Using the TensorFlow framework. Based on a convolutional neural network architecture. Pixels are classified as either axon, myelin or background.
 103 Nov 29, 2022
103 Nov 29, 2022

Segmentation Training Pipeline
Segmentation Training Pipeline This package is a part of Musket ML framework. Reasons to use Segmentation Pipeline Segmentation Pipeline was developed
 52 Dec 12, 2022
52 Dec 12, 2022
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline. The pipeline accepts english text as input and returns the French translation.
 1 Jan 24, 2022
1 Jan 24, 2022
Equipped customers with insights about their EVs Hourly energy consumption and helped predict future charging behavior using LSTM model
Equipped customers with insights about their EVs Hourly energy consumption and helped predict future charging behavior using LSTM model. Designed sample dashboard with insights and recommendation for customers.
 2 Apr 7, 2022
2 Apr 7, 2022
A Celery application to collect data, download media and extract information from social media APIs
Project IBEX A Celery application to collect data, download media and extract information from social media APIs. Requirements You must have a Redis D
 4 Dec 15, 2022
4 Dec 15, 2022
Data processing with Pandas.
Processing-data-with-python This is a simple example showing how to use Pandas to create a dataframe and the processing data with python. The jupyter
 1 Jan 23, 2022
1 Jan 23, 2022
Nobel Data Analysis
Nobel_Data_Analysis This project is for analyzing a set of data about people who have won the Nobel Prize in different fields and different countries
 1 Jan 24, 2022
1 Jan 24, 2022
Investigating EV charging data
Investigating EV charging data Introduction: Got an opportunity to work with a home monitoring technology company over the last 6 months whose goal wa
2 Apr 7, 2022
Analyze the Gravitational wave data stored at LIGO/VIRGO observatories
Gravitational-Wave-Analysis This project showcases how to analyze the Gravitational wave data stored at LIGO/VIRGO observatories, using Python program
 1 Jan 23, 2022
1 Jan 23, 2022
Ingestinator is my personal VFX pipeline tool for ingesting folders containing frame sequences that have been pulled and downloaded to a local folder
Ingestinator Ingestinator is my personal VFX pipeline tool for ingesting folders containing frame sequences that have been pulled and downloaded to a
 2 Nov 18, 2022
2 Nov 18, 2022
This python script allows you to manipulate the audience data from Sl.ido surveys
Slido-Automated-VoteBot This python script allows you to manipulate the audience data from Sl.ido surveys Since Slido blocks interference from automat
 1 Jan 24, 2022
1 Jan 24, 2022
Cormen-Lib - An academic tool for data structures and algorithms courses
The Cormen-lib module is an insular data structures and algorithms library based on the Thomas H. Cormen's Introduction to Algorithms Third Edition. This library was made specifically for administering and grading assignments related to data structure and algorithms in computer science.
 12 Aug 18, 2022
12 Aug 18, 2022

Collapse by Conditioning: Training Class-conditional GANs with Limited Data
Collapse by Conditioning: Training Class-conditional GANs with Limited Data Moha
 33 Dec 6, 2022
33 Dec 6, 2022
Mmdb-server - An open source fast API server to lookup IP addresses for their geographic location
mmdb-server mmdb-server is an open source fast API server to lookup IP addresses
 67 Nov 25, 2022
67 Nov 25, 2022
GoogleFormSpammer - A simple CLI script to spam Google Forms used by Crypto Wallet scammers to collect stolen data
GoogleFormSpammer - A simple CLI script to spam Google Forms used by Crypto Wallet scammers to collect stolen data
 14 Dec 17, 2022
14 Dec 17, 2022
Implement the Perspective open source code in preparation for data visualization
Task Overview | Installation Instructions | Link to Module 2 Introduction Experience Technology at JP Morgan Chase Try out what real work is like in t
 1 Jan 23, 2022
1 Jan 23, 2022
PostQF is a user-friendly Postfix queue data filter which operates on data produced by postqueue -j.
PostQF Copyright © 2022 Ralph Seichter PostQF is a user-friendly Postfix queue data filter which operates on data produced by postqueue -j. See the ma
 11 Nov 24, 2022
11 Nov 24, 2022
Synthetic data need to preserve the statistical properties of real data in terms of their individual behavior and (inter-)dependences
Synthetic data need to preserve the statistical properties of real data in terms of their individual behavior and (inter-)dependences. Copula and functional Principle Component Analysis (fPCA) are statistical models that allow these properties to be simulated (Joe 2014). As such, copula generated data have shown potential to improve the generalization of machine learning (ML) emulators (Meyer et al. 2021) or anonymize real-data datasets (Patki et al. 2016).
 32 Dec 20, 2022
32 Dec 20, 2022
An easy-to-use feature store
A feature store is a data storage system for data science and machine-learning. It can store raw data and also transformed features, which can be fed straight into an ML model or training script.
 48 Dec 9, 2022
48 Dec 9, 2022
Learn Basic to advanced level Data visualisation techniques from this Repository
Data visualisation Hey, You can learn Basic to advanced level Data visualisation techniques from this Repository. Data visualization is the graphic re
 16 Jan 3, 2023
16 Jan 3, 2023

Create charts with Python in a very similar way to creating charts using Chart.js
Create charts with Python in a very similar way to creating charts using Chart.js. The charts created are fully configurable, interactive and modular and are displayed directly in the output of the the cells of your jupyter notebook environment.
 68 Dec 8, 2022
68 Dec 8, 2022

visualize_ML is a python package made to visualize some of the steps involved while dealing with a Machine Learning problem
visualize_ML visualize_ML is a python package made to visualize some of the steps involved while dealing with a Machine Learning problem. It is build
 164 Dec 12, 2022
164 Dec 12, 2022
Equibles Stocks API for Python
Equibles Stocks API for Python Requirements. Python 2.7 and 3.4+ Installation & Usage pip install If the python package is hosted on Github, you can i
 3 Apr 15, 2022
3 Apr 15, 2022
A server and client for passing data between computercraft computers/turtles across dimensions or even servers.
ccserver A server and client for passing data between computercraft computers/turtles across dimensions or even servers. pastebin get zUnE5N0v client
 1 Jan 22, 2022
1 Jan 22, 2022
Feature engineering and machine learning: together at last
Feature engineering and machine learning: together at last! Lambdo is a workflow engine which significantly simplifies data analysis by unifying featu
 14 Sep 15, 2022
14 Sep 15, 2022
INFO-H515 - Big Data Scalable Analytics
INFO-H515 - Big Data Scalable Analytics Jacopo De Stefani, Giovanni Buroni, Théo Verhelst and Gianluca Bontempi - Machine Learning Group Exercise clas
 58 Dec 11, 2022
58 Dec 11, 2022
This module is used to create Convolutional AutoEncoders for Variational Data Assimilation
VarDACAE This module is used to create Convolutional AutoEncoders for Variational Data Assimilation. A user can define, create and train an AE for Dat
 23 Dec 16, 2022
23 Dec 16, 2022
Tutorials, examples, collections, and everything else that falls into the categories: pattern classification, machine learning, and data mining
**Tutorials, examples, collections, and everything else that falls into the categories: pattern classification, machine learning, and data mining.** S
 4k Dec 30, 2022
4k Dec 30, 2022
Perform sentiment analysis on textual data that people generally post on websites like social networks and movie review sites.
Sentiment Analyzer The goal of this project is to perform sentiment analysis on textual data that people generally post on websites like social networ
 53 Mar 1, 2022
53 Mar 1, 2022

Dive into Machine Learning
Dive into Machine Learning Hi there! You might find this guide helpful if: You know Python or you're learning it 🐍 You're new to Machine Learning You
 11.1k Jan 3, 2023
11.1k Jan 3, 2023
TensorDebugger (TDB) is a visual debugger for deep learning. It extends TensorFlow with breakpoints + real-time visualization of the data flowing through the computational graph
TensorDebugger (TDB) is a visual debugger for deep learning. It extends TensorFlow (Google's Deep Learning framework) with breakpoints + real-time visualization of the data flowing through the computational graph.
 1.4k Dec 15, 2022
1.4k Dec 15, 2022
Python for Data Analysis, 2nd Edition
Python for Data Analysis, 2nd Edition Materials and IPython notebooks for "Python for Data Analysis" by Wes McKinney, published by O'Reilly Media Buy
 18.6k Jan 8, 2023
18.6k Jan 8, 2023
INF42 - Topological Data Analysis
TDA INF421(Conception et analyse d'algorithmes) Projet : Topological Data Analysis SphereMin Etant donné un nuage des points, ce programme contient de
 2 Jan 7, 2022
2 Jan 7, 2022

Demonstrate the breadth and depth of your data science skills by earning all of the Databricks Data Scientist credentials
Data Scientist Learning Plan Demonstrate the breadth and depth of your data science skills by earning all of the Databricks Data Scientist credentials
 27 Nov 1, 2022
27 Nov 1, 2022

sequitur is a library that lets you create and train an autoencoder for sequential data in just two lines of code
sequitur sequitur is a library that lets you create and train an autoencoder for sequential data in just two lines of code. It implements three differ
 305 Dec 21, 2022
305 Dec 21, 2022

This is an open solution to the Home Credit Default Risk challenge 🏡
Home Credit Default Risk: Open Solution This is an open solution to the Home Credit Default Risk challenge 🏡 . More competitions 🎇 Check collection
 427 Dec 27, 2022
427 Dec 27, 2022
A fast, efficiency python package for searching and getting search results with many different search engines
search A fast, efficiency python package for searching and getting search results with many different search engines. Installation To install the pack
 0 Oct 6, 2022
0 Oct 6, 2022

Google AI Open Images - Object Detection Track: Open Solution
Google AI Open Images - Object Detection Track: Open Solution This is an open solution to the Google AI Open Images - Object Detection Track 😃 More c
46 Jun 22, 2022

TGS Salt Identification Challenge
TGS Salt Identification Challenge This is an open solution to the TGS Salt Identification Challenge. Note Unfortunately, we can no longer provide supp
 123 Nov 4, 2022
123 Nov 4, 2022

Airbus Ship Detection Challenge
Airbus Ship Detection Challenge This is an open solution to the Airbus Ship Detection Challenge. Our goals We are building entirely open solution to t
55 Nov 29, 2022
This is an analysis and prediction project for house prices in King County, USA based on certain features of the house
This is a project for analysis and estimation of House Prices in King County USA The .csv file contains the data of the house and the .ipynb file con
 1 Jan 21, 2022
1 Jan 21, 2022
Python Sreamlit Duplicate Records Finder Remover
Python-Sreamlit-Duplicate-Records-Finder-Remover Streamlit is an open-source Python library that makes it easy to create and share beautiful, custom w
 1 Jan 21, 2022
1 Jan 21, 2022
Program that predicts the NBA mvp based on data from previous years.
NBA MVP Predictor A machine learning model using RandomForest Regression that predicts NBA MVP's using player data. Explore the docs » View Demo · Rep
 1 Jan 21, 2022
1 Jan 21, 2022
Simple Translator in Python
Simple Translator in Python Project Description: In this project, we'll be making a very simple translator in Python using some libraries. Requirement
 3 Jan 23, 2022
3 Jan 23, 2022

Fast Differentiable Matrix Sqrt Root
Official Pytorch implementation of ICLR 22 paper Fast Differentiable Matrix Square Root
 42 Dec 30, 2022
42 Dec 30, 2022

Open solution to the Toxic Comment Classification Challenge
Starter code: Kaggle Toxic Comment Classification Challenge More competitions 🎇 Check collection of public projects 🎁 , where you can find multiple
153 Jun 22, 2022
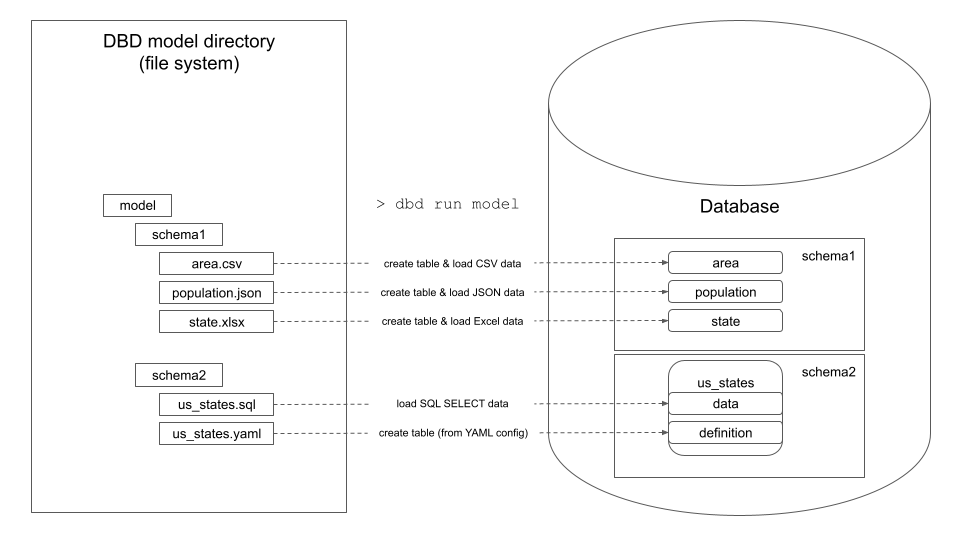
dbd is a database prototyping tool that enables data analysts and engineers to quickly load and transform data in SQL databases.
dbd: database prototyping tool dbd is a database prototyping tool that enables data analysts and engineers to quickly load and transform data in SQL d
 47 Dec 7, 2022
47 Dec 7, 2022
Data-driven Computer Science UoB
COMS20011_2021 Data-driven Computer Science UoB Staff Laurence Aitchison [[email protected]] (unit director) Majid Mirmehdi [m.mirmehdi
 6 May 16, 2022
6 May 16, 2022
Colab notebook and additional materials for Python-driven analysis of redlining data in Philadelphia
RedliningExploration The Google Colaboratory file contained in this repository contains work inspired by a project on educational inequality in the Ph
 1 Jan 20, 2022
1 Jan 20, 2022
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
 3 Jan 24, 2022
3 Jan 24, 2022