172 Repositories
Python gpu Libraries

Elevation Mapping on GPU.
Elevation Mapping cupy Overview This is a ros package of elevation mapping on GPU. Code are written in python and uses cupy for GPU calculation. * pla
 183 Dec 19, 2022
183 Dec 19, 2022

Accelerated NLP pipelines for fast inference on CPU and GPU. Built with Transformers, Optimum and ONNX Runtime.
Optimum Transformers Accelerated NLP pipelines for fast inference 🚀 on CPU and GPU. Built with 🤗 Transformers, Optimum and ONNX runtime. Installatio
 115 Dec 16, 2022
115 Dec 16, 2022
Sionna: An Open-Source Library for Next-Generation Physical Layer Research
Sionna: An Open-Source Library for Next-Generation Physical Layer Research Sionna™ is an open-source Python library for link-level simulations of digi
 313 Dec 22, 2022
313 Dec 22, 2022

GPU-accelerated Image Processing library using OpenCL
pyclesperanto pyclesperanto is a python package for clEsperanto - a multi-language framework for GPU-accelerated image processing. clEsperanto uses Op
 17 Dec 25, 2022
17 Dec 25, 2022
(Personalized) Page-Rank computation using PyTorch
torch-ppr This package allows calculating page-rank and personalized page-rank via power iteration with PyTorch, which also supports calculation on GP
 69 Dec 3, 2022
69 Dec 3, 2022

A fast poisson image editing implementation that can utilize multi-core CPU or GPU to handle a high-resolution image input.
Poisson Image Editing - A Parallel Implementation Jiayi Weng (jiayiwen), Zixu Chen (zixuc) Poisson Image Editing is a technique that can fuse two imag
 110 Dec 27, 2022
110 Dec 27, 2022

Use the state-of-the-art m2m100 to translate large data on CPU/GPU/TPU. Super Easy!
Easy-Translate is a script for translating large text files in your machine using the M2M100 models from Facebook/Meta AI. We also privide a script fo
 41 Dec 15, 2022
41 Dec 15, 2022

Easy Parallel Library (EPL) is a general and efficient deep learning framework for distributed model training.
English | 简体中文 Easy Parallel Library Overview Easy Parallel Library (EPL) is a general and efficient library for distributed model training. Usability
 185 Dec 21, 2022
185 Dec 21, 2022

GPU Programming with Julia - course at the Swiss National Supercomputing Centre (CSCS), ETH Zurich
Course Description The programming language Julia is being more and more adopted in High Performance Computing (HPC) due to its unique way to combine
 192 Jan 3, 2023
192 Jan 3, 2023
Numerical differential equation solvers in JAX. Autodifferentiable and GPU-capable.
Diffrax Numerical differential equation solvers in JAX. Autodifferentiable and GPU-capable. Diffrax is a JAX-based library providing numerical differe
 717 Jan 9, 2023
717 Jan 9, 2023
A framework for GPU based high-performance medical image processing and visualization
FAST is an open-source cross-platform framework with the main goal of making it easier to do high-performance processing and visualization of medical images on heterogeneous systems utilizing both multi-core CPUs and GPUs. To achieve this, FAST use modern C++, OpenCL and OpenGL.
 315 Dec 30, 2022
315 Dec 30, 2022
A Python function for Slurm, to monitor the GPU information
Gpu-Monitor A Python function for Slurm, where I couldn't use nvidia-smi to monitor the GPU information. whole repo is not finish Installation TODO Mo
 2 Feb 11, 2022
2 Feb 11, 2022
The unified machine learning framework, enabling framework-agnostic functions, layers and libraries.
The unified machine learning framework, enabling framework-agnostic functions, layers and libraries. Contents Overview In a Nutshell Where Next? Overv
 8.2k Dec 31, 2022
8.2k Dec 31, 2022
Pytorch Performace Tuning, WandB, AMP, Multi-GPU, TensorRT, Triton
Plant Pathology 2020 FGVC7 Introduction A deep learning model pipeline for training, experimentaiton and deployment for the Kaggle Competition, Plant
 0 Feb 25, 2022
0 Feb 25, 2022

PyTorchMemTracer - Depict GPU memory footprint during DNN training of PyTorch
A Memory Tracer For PyTorch OOM is a nightmare for PyTorch users. However, most
 9 Nov 14, 2022
9 Nov 14, 2022
GPU implementation of $k$-Nearest Neighbors and Shared-Nearest Neighbors
GPU implementation of kNN and SNN GPU implementation of $k$-Nearest Neighbors and Shared-Nearest Neighbors Supported by numba cuda and faiss library E
 7 Nov 23, 2022
7 Nov 23, 2022

TResNet: High Performance GPU-Dedicated Architecture
TResNet: High Performance GPU-Dedicated Architecture paperV2 | pretrained models Official PyTorch Implementation Tal Ridnik, Hussam Lawen, Asaf Noy, I
 426 Dec 28, 2022
426 Dec 28, 2022
![[内测中]前向式Python环境快捷封装工具,快速将Python打包为EXE并添加CUDA、NoAVX等支持。](https://github.com/QPT-Family/QPT/raw/%E5%BC%80%E5%8F%91%E5%88%86%E6%94%AF/ext/img/jetbrains.png)
[内测中]前向式Python环境快捷封装工具,快速将Python打包为EXE并添加CUDA、NoAVX等支持。
QPT - Quick packaging tool 快捷封装工具 GitHub主页 | Gitee主页 QPT是一款可以“模拟”开发环境的多功能封装工具,最短只需一行命令即可将普通的Python脚本打包成EXE可执行程序,并选择性添加CUDA和NoAVX的支持,尽可能兼容更多的用户环境。 感觉还可
 545 Dec 28, 2022
545 Dec 28, 2022

Colab notebook for openai/glide-text2im.
GLIDE text2im on Colab This repository provides a Colab notebook to produce images conditioned on text prompts with GLIDE [1]. Usage Run text2im.ipynb
 19 Oct 19, 2022
19 Oct 19, 2022

Cross-modal Retrieval using Transformer Encoder Reasoning Networks (TERN). With use of Metric Learning and FAISS for fast similarity search on GPU
Cross-modal Retrieval using Transformer Encoder Reasoning Networks This project reimplements the idea from "Transformer Reasoning Network for Image-Te
 5 Nov 5, 2022
5 Nov 5, 2022
Collection of machine learning related notebooks to share.
ML_Notebooks Collection of machine learning related notebooks to share. Notebooks GAN_distributed_training.ipynb In this Notebook, TensorFlow's tutori
 14 Dec 22, 2022
14 Dec 22, 2022
GrabGpu_py: a scripts for grab gpu when gpu is free
GrabGpu_py a scripts for grab gpu when gpu is free. WaitCondition: gpu_memory
 3 Jun 18, 2022
3 Jun 18, 2022

FDTD simulator that generates s-parameters from OFF geometry files using a GPU
Emport Overview This repo provides a FDTD (Finite Differences Time Domain) simulator called emport for solving RF circuits. Emport outputs its simulat
 4 Dec 15, 2022
4 Dec 15, 2022
GPOEO is a micro-intrusive GPU online energy optimization framework for iterative applications
GPOEO GPOEO is a micro-intrusive GPU online energy optimization framework for iterative applications. We also implement ODPP [1] as a comparison. [1]
 8 Sep 10, 2022
8 Sep 10, 2022

PyTorch/GPU re-implementation of the paper Masked Autoencoders Are Scalable Vision Learners
Masked Autoencoders: A PyTorch Implementation This is a PyTorch/GPU re-implementation of the paper Masked Autoencoders Are Scalable Vision Learners: @
 4.8k Jan 4, 2023
4.8k Jan 4, 2023
PyTorch GPU implementation of the ES-RNN model for time series forecasting
Fast ES-RNN: A GPU Implementation of the ES-RNN Algorithm A GPU-enabled version of the hybrid ES-RNN model by Slawek et al that won the M4 time-series
 305 Jan 3, 2023
305 Jan 3, 2023
Python binding for Khiva library.
Khiva-Python Build Documentation Build Linux and Mac OS Build Windows Code Coverage README This is the Khiva Python binding, it allows the usage of Kh
 46 Oct 16, 2022
46 Oct 16, 2022
AXI Combat is a networked multiplayer game built on the AXI Visualizer 3D engine.
AXI_Combat AXI Combat is a networked multiplayer game built on the AXI Visualizer 3D engine. https://axi.x10.mx/Combat AXI Combat is released under th
 0 Aug 2, 2022
0 Aug 2, 2022
A Demo server serving Bert through ONNX with GPU written in Rust with 3
Demo BERT ONNX server written in rust This demo showcase the use of onnxruntime-rs on BERT with a GPU on CUDA 11 served by actix-web and tokenized wit
 28 Jan 1, 2023
28 Jan 1, 2023

Pythonic particle-based (super-droplet) warm-rain/aqueous-chemistry cloud microphysics package with box, parcel & 1D/2D prescribed-flow examples in Python, Julia and Matlab
PySDM PySDM is a package for simulating the dynamics of population of particles. It is intended to serve as a building block for simulation systems mo
 32 Oct 18, 2022
32 Oct 18, 2022

Scalene: a high-performance, high-precision CPU, GPU, and memory profiler for Python
Scalene: a high-performance CPU, GPU and memory profiler for Python by Emery Berger, Sam Stern, and Juan Altmayer Pizzorno. Scalene community Slack Ab
 7k Dec 30, 2022
7k Dec 30, 2022
It is a simple library to speed up CLIP inference up to 3x (K80 GPU)
CLIP-ONNX It is a simple library to speed up CLIP inference up to 3x (K80 GPU) Usage Install clip-onnx module and requirements first. Use this trick !
 93 Dec 20, 2022
93 Dec 20, 2022
Tf alloc - Simplication of GPU allocation for Tensorflow2
tf_alloc Simpliying GPU allocation for Tensorflow Developer: korkite (Junseo Ko)
 3 Feb 10, 2022
3 Feb 10, 2022

Hyperopt for solving CIFAR-100 with a convolutional neural network (CNN) built with Keras and TensorFlow, GPU backend
Hyperopt for solving CIFAR-100 with a convolutional neural network (CNN) built with Keras and TensorFlow, GPU backend This project acts as both a tuto
 103 Jul 22, 2022
103 Jul 22, 2022
Memory-efficient optimum einsum using opt_einsum planning and PyTorch kernels.
opt-einsum-torch There have been many implementations of Einstein's summation. numpy's numpy.einsum is the least efficient one as it only runs in sing
 9 Nov 18, 2022
9 Nov 18, 2022
A simplistic and efficient pure-python neural network library from Phys Whiz with CPU and GPU support.
A simplistic and efficient pure-python neural network library from Phys Whiz with CPU and GPU support.
 19 Feb 28, 2022
19 Feb 28, 2022
Scalable and Elastic Deep Reinforcement Learning Using PyTorch. Please star. 🔥
ElegantRL “小雅”: Scalable and Elastic Deep Reinforcement Learning ElegantRL is developed for researchers and practitioners with the following advantage
 2.5k Jan 5, 2023
2.5k Jan 5, 2023

Stochastic Tensor Optimization for Robot Motion - A GPU Robot Motion Toolkit
STORM Stochastic Tensor Optimization for Robot Motion - A GPU Robot Motion Toolkit [Install Instructions] [Paper] [Website] This package contains code
101 Dec 12, 2022

Real-Time and Accurate Full-Body Multi-Person Pose Estimation&Tracking System
News! Aug 2020: v0.4.0 version of AlphaPose is released! Stronger tracking! Include whole body(face,hand,foot) keypoints! Colab now available. Dec 201
 6.7k Dec 28, 2022
6.7k Dec 28, 2022
Robotics with GPU computing
Robotics with GPU computing Cupoch is a library that implements rapid 3D data processing for robotics using CUDA. The goal of this library is to imple
 625 Jan 7, 2023
625 Jan 7, 2023

Efficient and Scalable Physics-Informed Deep Learning and Scientific Machine Learning on top of Tensorflow for multi-worker distributed computing
Notice: Support for Python 3.6 will be dropped in v.0.2.1, please plan accordingly! Efficient and Scalable Physics-Informed Deep Learning Collocation-
 74 Dec 9, 2022
74 Dec 9, 2022
The versatile ocean simulator, in pure Python, powered by JAX.
Veros is the versatile ocean simulator -- it aims to be a powerful tool that makes high-performance ocean modeling approachable and fun. Because Veros
 245 Dec 20, 2022
245 Dec 20, 2022

A high-performance distributed deep learning system targeting large-scale and automated distributed training.
HETU Documentation | Examples Hetu is a high-performance distributed deep learning system targeting trillions of parameters DL model training, develop
 150 Dec 21, 2022
150 Dec 21, 2022
A python package simulating the quasi-2D pseudospin-1/2 Gross-Pitaevskii equation with NVIDIA GPU acceleration.
A python package simulating the quasi-2D pseudospin-1/2 Gross-Pitaevskii equation with NVIDIA GPU acceleration. Introduction spinor-gpe is high-level,
 2 Sep 20, 2022
2 Sep 20, 2022
GTK and Python based, system performance and usage monitoring tool
System Monitoring Center GTK3 and Python 3 based, system performance and usage monitoring tool. Features: Detailed system performance and usage usage
 649 Jan 3, 2023
649 Jan 3, 2023

Hardware-accelerated DNN model inference ROS2 packages using NVIDIA Triton/TensorRT for both Jetson and x86_64 with CUDA-capable GPU
Isaac ROS DNN Inference Overview This repository provides two NVIDIA GPU-accelerated ROS2 nodes that perform deep learning inference using custom mode
 62 Dec 14, 2022
62 Dec 14, 2022
Massively parallel Monte Carlo diffusion MR simulator written in Python.
Disimpy Disimpy is a Python package for generating simulated diffusion-weighted MR signals that can be useful in the development and validation of dat
 16 Nov 11, 2022
16 Nov 11, 2022

Run Keras models in the browser, with GPU support using WebGL
**This project is no longer active. Please check out TensorFlow.js.** The Keras.js demos still work but is no longer updated. Run Keras models in the
 4.9k Dec 29, 2022
4.9k Dec 29, 2022

Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU
GPU Docker NLP Application Deployment Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU, to setup the enviroment on
 9 Oct 14, 2022
9 Oct 14, 2022
Train Dense Passage Retriever (DPR) with a single GPU
Gradient Cached Dense Passage Retrieval Gradient Cached Dense Passage Retrieval (GC-DPR) - is an extension of the original DPR library. We introduce G
 92 Jan 2, 2023
92 Jan 2, 2023
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed+Megatron trained the world's most powerful language model: MT-530B DeepSpeed is hiring, come join us! DeepSpeed is a deep learning optimizat
 8.4k Dec 28, 2022
8.4k Dec 28, 2022

Efficient training of deep recommenders on cloud.
HybridBackend Introduction HybridBackend is a training framework for deep recommenders which bridges the gap between evolving cloud infrastructure and
111 Dec 23, 2022
⚡️Optimizing einsum functions in NumPy, Tensorflow, Dask, and more with contraction order optimization.
Optimized Einsum Optimized Einsum: A tensor contraction order optimizer Optimized einsum can significantly reduce the overall execution time of einsum
 653 Dec 30, 2022
653 Dec 30, 2022
High performance Cross-platform Inference-engine, you could run Anakin on x86-cpu,arm, nv-gpu, amd-gpu,bitmain and cambricon devices.
Anakin2.0 Welcome to the Anakin GitHub. Anakin is a cross-platform, high-performance inference engine, which is originally developed by Baidu engineer
 514 Dec 28, 2022
514 Dec 28, 2022

Publish GPU miner info to MQTT
Miner2MQTT Доступ к вашему GPU майнеру через MQTT. Изменения 1.0 EXE файл для Windows 1.1 Управление вентиляторами видеокарт (Linux) Упраление power l
 5 Aug 21, 2022
5 Aug 21, 2022
Our implementation used for the MICCAI 2021 FLARE Challenge titled 'Efficient Multi-Organ Segmentation Using SpatialConfiguartion-Net with Low GPU Memory Requirements'.
Efficient Multi-Organ Segmentation Using SpatialConfiguartion-Net with Low GPU Memory Requirements Our implementation used for the MICCAI 2021 FLARE C
 3 Sep 27, 2022
3 Sep 27, 2022
Fast and simple implementation of RL algorithms, designed to run fully on GPU.
RSL RL Fast and simple implementation of RL algorithms, designed to run fully on GPU. This code is an evolution of rl-pytorch provided with NVIDIA's I
68 Dec 29, 2022

Build and run Docker containers leveraging NVIDIA GPUs
NVIDIA Container Toolkit Introduction The NVIDIA Container Toolkit allows users to build and run GPU accelerated Docker containers. The toolkit includ
 15.6k Jan 1, 2023
15.6k Jan 1, 2023
Optimized primitives for collective multi-GPU communication
NCCL Optimized primitives for inter-GPU communication. Introduction NCCL (pronounced "Nickel") is a stand-alone library of standard communication rout
2k Jan 9, 2023

R interface to fast.ai
R interface to fastai The fastai package provides R wrappers to fastai. The fastai library simplifies training fast and accurate neural nets using mod
 113 Dec 20, 2022
113 Dec 20, 2022
🔊 Audio and fastai v2
Fastaudio An audio module for fastai v2. We want to help you build audio machine learning applications while minimizing the need for audio domain expe
 152 Dec 28, 2022
152 Dec 28, 2022
An easy to use Natural Language Processing library and framework for predicting, training, fine-tuning, and serving up state-of-the-art NLP models.
Welcome to AdaptNLP A high level framework and library for running, training, and deploying state-of-the-art Natural Language Processing (NLP) models
 407 Jan 3, 2023
407 Jan 3, 2023
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows.
An open-source, low-code machine learning library in Python 🚀 Version 2.3.5 out now! Check out the release notes here. Official • Docs • Install • Tu
 6.7k Jan 8, 2023
6.7k Jan 8, 2023

Multiple types of NN model optimization environments. It is possible to directly access the host PC GUI and the camera to verify the operation. Intel iHD GPU (iGPU) support. NVIDIA GPU (dGPU) support.
mtomo Multiple types of NN model optimization environments. It is possible to directly access the host PC GUI and the camera to verify the operation.
 24 Mar 2, 2022
24 Mar 2, 2022
A GPU-optional modular synthesizer in pytorch, 16200x faster than realtime, for audio ML researchers.
torchsynth The fastest synth in the universe. Introduction torchsynth is based upon traditional modular synthesis written in pytorch. It is GPU-option
 229 Jan 2, 2023
229 Jan 2, 2023
Management of exclusive GPU access for distributed machine learning workloads
TensorHive is an open source tool for managing computing resources used by multiple users across distributed hosts. It focuses on granting
 131 Dec 12, 2022
131 Dec 12, 2022
Taichi is a parallel programming language for high-performance numerical computations.
Taichi is a parallel programming language for high-performance numerical computations.
 22k Jan 4, 2023
22k Jan 4, 2023
Computations and statistics on manifolds with geometric structures.
Geomstats Code Continuous Integration Code coverage (numpy) Code coverage (autograd, tensorflow, pytorch) Documentation Community NEWS: Geomstats is r
 875 Dec 31, 2022
875 Dec 31, 2022
kitty - the fast, feature-rich, cross-platform, GPU based terminal
kitty - the fast, feature-rich, cross-platform, GPU based terminal
 17.3k Jan 4, 2023
17.3k Jan 4, 2023
AdaNet is a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention
AdaNet is a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention. AdaNet buil
 3.4k Jan 7, 2023
3.4k Jan 7, 2023

「PyTorch Implementation of AnimeGANv2」を用いて、生成した顔画像を元の画像に上書きするデモ
AnimeGANv2-Face-Overlay-Demo PyTorch Implementation of AnimeGANv2を用いて、生成した顔画像を元の画像に上書きするデモです。
 21 Oct 18, 2022
21 Oct 18, 2022

clesperanto is a graphical user interface for GPU-accelerated image processing.
clesperanto is a graphical user interface for a multi-platform multi-language framework for GPU-accelerated image processing. It is based on napari and the pyclesperanto-prototype.
1 Jan 2, 2022
⚡️ Get notified as soon as your next CPU, GPU, or game console is in stock
Inventory Hunter This bot helped me snag an RTX 3070... hopefully it will help you get your hands on your next CPU, GPU, or game console. Requirements
 1.1k Dec 26, 2022
1.1k Dec 26, 2022

It is a program that displays the current temperature of the GPU and CPU in real time and stores the temperature history.
HWLogger It is a program that displays the current temperature of the GPU and CPU in real time and stores the temperature history. Sample Usage Run HW
 0 Apr 5, 2022
0 Apr 5, 2022

A suite of benchmarks for CPU and GPU performance of the most popular high-performance libraries for Python :rocket:
A suite of benchmarks for CPU and GPU performance of the most popular high-performance libraries for Python :rocket:
 255 Jan 4, 2023
255 Jan 4, 2023
GPU Accelerated Non-rigid ICP for surface registration
GPU Accelerated Non-rigid ICP for surface registration Introduction Preivous Non-rigid ICP algorithm is usually implemented on CPU, and needs to solve
 144 Jan 4, 2023
144 Jan 4, 2023
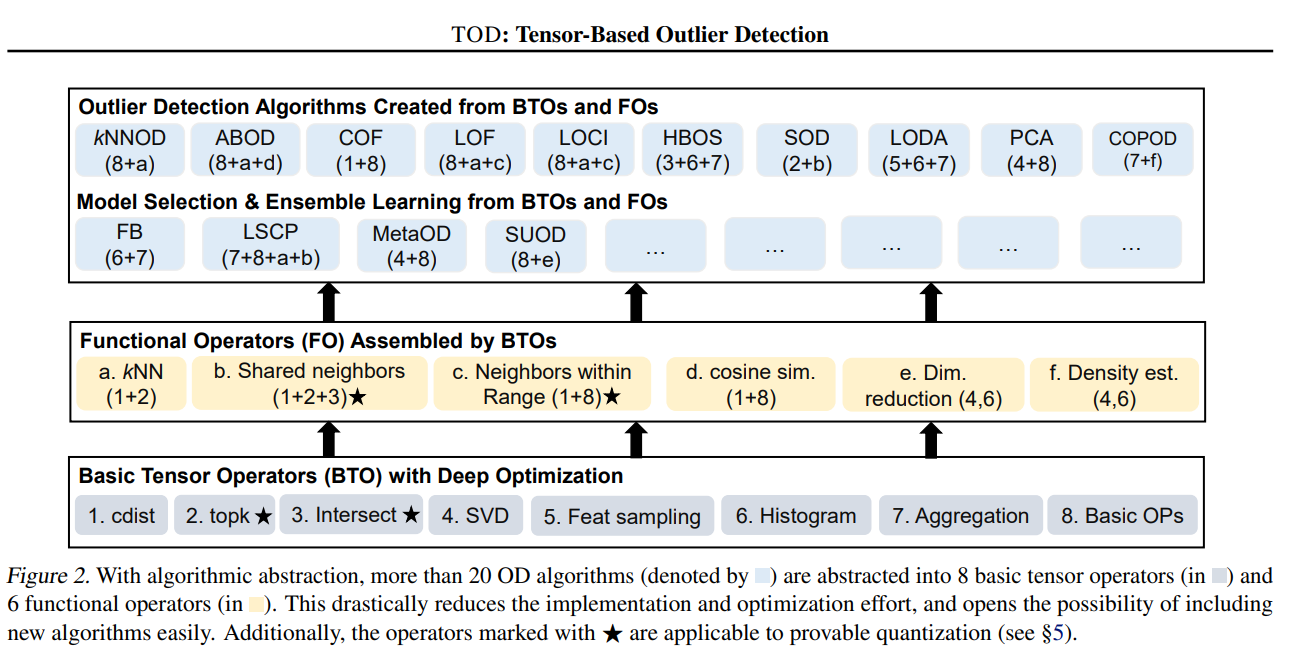
(Py)TOD: Tensor-based Outlier Detection, A General GPU-Accelerated Framework
(Py)TOD: Tensor-based Outlier Detection, A General GPU-Accelerated Framework Background: Outlier detection (OD) is a key data mining task for identify
 127 Jan 5, 2023
127 Jan 5, 2023
An example showing how to use jax to train resnet50 on multi-node multi-GPU
jax-multi-gpu-resnet50-example This repo shows how to use jax for multi-node multi-GPU training. The example is adapted from the resnet50 example in d
 20 Jul 4, 2022
20 Jul 4, 2022

NCNN implementation of Real-ESRGAN. Real-ESRGAN aims at developing Practical Algorithms for General Image Restoration.
NCNN implementation of Real-ESRGAN. Real-ESRGAN aims at developing Practical Algorithms for General Image Restoration.
 593 Jan 3, 2023
593 Jan 3, 2023

GPU-accelerated image processing using cupy and CUDA
napari-cupy-image-processing GPU-accelerated image processing using cupy and CUDA This napari plugin was generated with Cookiecutter using with @napar
 16 Oct 26, 2022
16 Oct 26, 2022

General purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends)
General purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabled, asynchronous and optimized for advanced GPU data processing usecases. Backed by the Linux Foundation.
 1k Jan 6, 2023
1k Jan 6, 2023

Train a state-of-the-art yolov3 object detector from scratch!
TrainYourOwnYOLO: Building a Custom Object Detector from Scratch This repo let's you train a custom image detector using the state-of-the-art YOLOv3 c
 616 Jan 8, 2023
616 Jan 8, 2023
NVIDIA Merlin is an open source library providing end-to-end GPU-accelerated recommender systems, from feature engineering and preprocessing to training deep learning models and running inference in production.
NVIDIA Merlin NVIDIA Merlin is an open source library designed to accelerate recommender systems on NVIDIA’s GPUs. It enables data scientists, machine
 419 Jan 3, 2023
419 Jan 3, 2023
MG-GCN: Scalable Multi-GPU GCN Training Framework
MG-GCN MG-GCN: multi-GPU GCN training framework. For more information, please read our paper. After cloning our repository, run git submodule update -
 6 Oct 24, 2022
6 Oct 24, 2022

impy is an all-in-one image analysis library, equipped with parallel processing, GPU support, GUI based tools and so on.
impy is All You Need in Image Analysis impy is an all-in-one image analysis library, equipped with parallel processing, GPU support, GUI based tools a
 24 Dec 20, 2022
24 Dec 20, 2022
Huggingface inference with GPU Docker on AWS
This repository contains code to containerize and deploy a GPU docker on AWS for summarization task. Find a detailed blogpost here Youtube Video Versi
 21 Dec 30, 2022
21 Dec 30, 2022

Blue noise image stippling in Processing (requires GPU)
Blue noise image stippling in Processing (requires GPU)
 141 Oct 9, 2022
141 Oct 9, 2022
A GUI for Face Recognition, based upon Docker, Tkinter, GPU and a camera device.
Face Recognition GUI This repository is a GUI version of Face Recognition by Adam Geitgey, where e.g. Docker and Tkinter are utilized. All the materia
 6 Dec 5, 2022
6 Dec 5, 2022
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
2.7k Jan 5, 2023

BMInf (Big Model Inference) is a low-resource inference package for large-scale pretrained language models (PLMs).
BMInf (Big Model Inference) is a low-resource inference package for large-scale pretrained language models (PLMs).
 377 Jan 2, 2023
377 Jan 2, 2023
GPU-accelerated PyTorch implementation of Zero-shot User Intent Detection via Capsule Neural Networks
GPU-accelerated PyTorch implementation of Zero-shot User Intent Detection via Capsule Neural Networks This repository implements a capsule model Inten
 15 Dec 24, 2022
15 Dec 24, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
Implementation of a Transformer, but completely in Triton
Transformer in Triton (wip) Implementation of a Transformer, but completely in Triton. I'm completely new to lower-level neural net code, so this repo
 152 Dec 22, 2022
152 Dec 22, 2022
WarpDrive: Extremely Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU
WarpDrive is a flexible, lightweight, and easy-to-use open-source reinforcement learning (RL) framework that implements end-to-end multi-agent RL on a single GPU (Graphics Processing Unit).
 334 Jan 6, 2023
334 Jan 6, 2023

A3C LSTM Atari with Pytorch plus A3G design
NEWLY ADDED A3G A NEW GPU/CPU ARCHITECTURE OF A3C FOR SUBSTANTIALLY ACCELERATED TRAINING!! RL A3C Pytorch NEWLY ADDED A3G!! New implementation of A3C
 532 Jan 2, 2023
532 Jan 2, 2023
Run Effective Large Batch Contrastive Learning on Limited Memory GPU
Gradient Cache Gradient Cache is a simple technique for unlimitedly scaling contrastive learning batch far beyond GPU memory constraint. This means tr
198 Dec 29, 2022
A modified version of DeepMind's Alphafold2 to divide CPU part (MSA and template searching) and GPU part (prediction model)
ParallelFold Author: Bozitao Zhong This is a modified version of DeepMind's Alphafold2 to divide CPU part (MSA and template searching) and GPU part (p
 77 Dec 22, 2022
77 Dec 22, 2022
This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust.
Demo BERT ONNX pipeline written in rust This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust. R
14 Dec 17, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
114 Nov 4, 2022
GPU-accelerated PyTorch implementation of Zero-shot User Intent Detection via Capsule Neural Networks
GPU-accelerated PyTorch implementation of Zero-shot User Intent Detection via Capsule Neural Networks This repository implements a capsule model Inten
15 Dec 24, 2022