1689 Repositories
Python natural-language-generation Libraries
[EMNLP 2020] Keep CALM and Explore: Language Models for Action Generation in Text-based Games
Contextual Action Language Model (CALM) and the ClubFloyd Dataset Code and data for paper Keep CALM and Explore: Language Models for Action Generation
 43 Dec 16, 2022
43 Dec 16, 2022
Codes for our paper "SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge" (EMNLP 2020)
SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge Introduction SentiLARE is a sentiment-aware pre-trained language
 74 Dec 30, 2022
74 Dec 30, 2022
Meta Language-Specific Layers in Multilingual Language Models
Meta Language-Specific Layers in Multilingual Language Models This repo contains the source codes for our paper On Negative Interference in Multilingu
 20 Feb 13, 2022
20 Feb 13, 2022
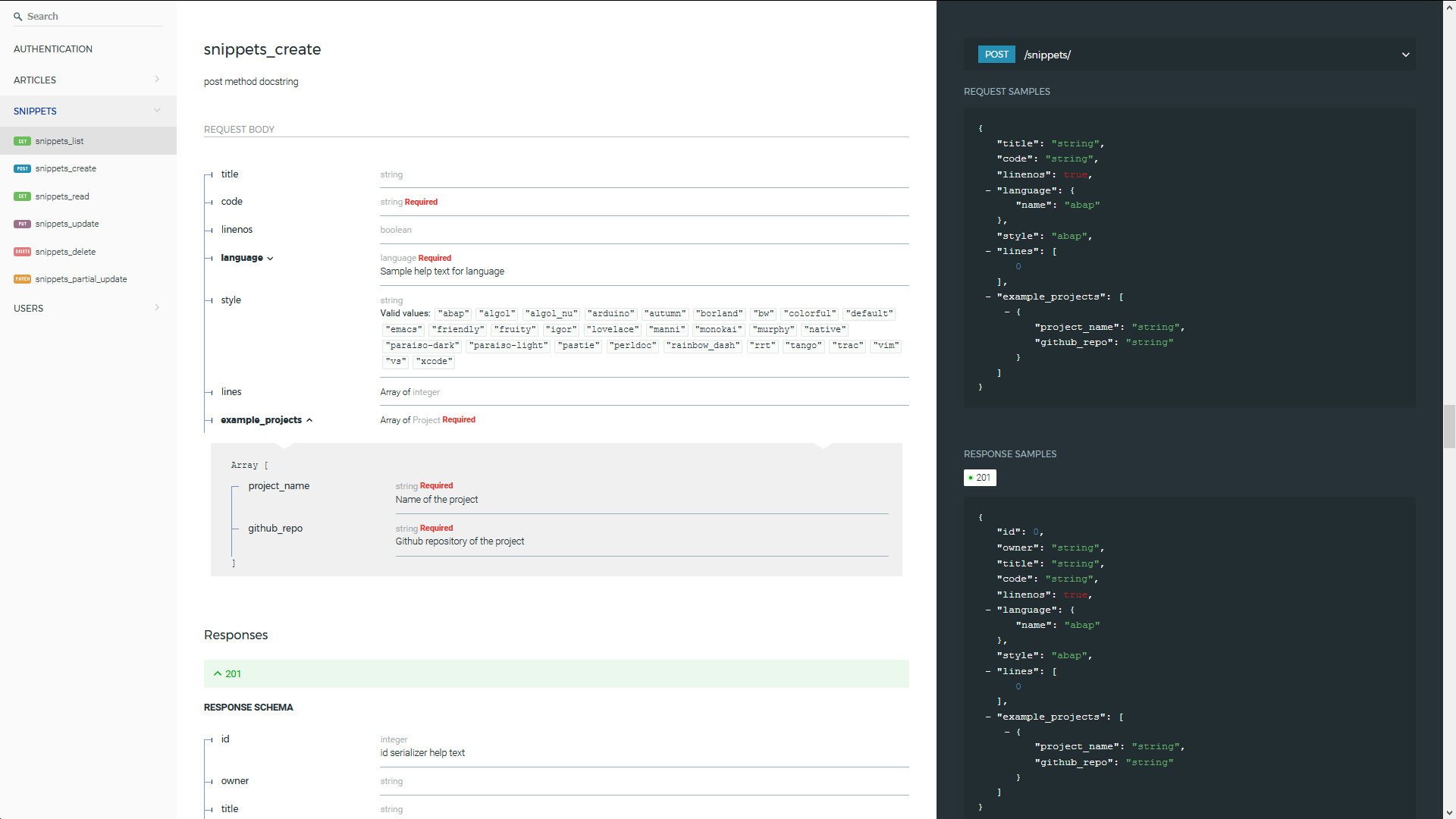
Automated generation of real Swagger/OpenAPI 2.0 schemas from Django REST Framework code.
drf-yasg - Yet another Swagger generator Generate real Swagger/OpenAPI 2.0 specifications from a Django Rest Framework API. Compatible with Django Res
 3k Jan 6, 2023
3k Jan 6, 2023

Django queries
Djaq Djaq - pronounced “Jack” - provides an instant remote API to your Django models data with a powerful query language. No server-side code beyond t
 53 Dec 12, 2022
53 Dec 12, 2022
LightSeq: A High-Performance Inference Library for Sequence Processing and Generation
LightSeq is a high performance inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT2, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, and other related tasks using these models.
 2.5k Jan 3, 2023
2.5k Jan 3, 2023
Pytorch implementation of CoCon: A Self-Supervised Approach for Controlled Text Generation
COCON_ICLR2021 This is our Pytorch implementation of COCON. CoCon: A Self-Supervised Approach for Controlled Text Generation (ICLR 2021) Alvin Chan, Y
 79 Dec 18, 2022
79 Dec 18, 2022
One Stop Anomaly Shop: Anomaly detection using two-phase approach: (a) pre-labeling using statistics, Natural Language Processing and static rules; (b) anomaly scoring using supervised and unsupervised machine learning.
One Stop Anomaly Shop (OSAS) Quick start guide Step 1: Get/build the docker image Option 1: Use precompiled image (might not reflect latest changes):
 148 Dec 26, 2022
148 Dec 26, 2022

TorchFlare is a simple, beginner-friendly, and easy-to-use PyTorch Framework train your models effortlessly.
TorchFlare TorchFlare is a simple, beginner-friendly and an easy-to-use PyTorch Framework train your models without much effort. It provides an almost
 85 Dec 26, 2022
85 Dec 26, 2022
Code for "Graph-Evolving Meta-Learning for Low-Resource Medical Dialogue Generation". [AAAI 2021]
Graph Evolving Meta-Learning for Low-resource Medical Dialogue Generation Code to be further cleaned... This repo contains the code of the following p
 29 Nov 1, 2022
29 Nov 1, 2022
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
 15k Jan 2, 2023
15k Jan 2, 2023

🏆 The 1st Place Submission to AICity Challenge 2021 Natural Language-Based Vehicle Retrieval Track (Alibaba-UTS submission)
🏆 The 1st Place Submission to AICity Challenge 2021 Natural Language-Based Vehicle Retrieval Track (Alibaba-UTS submission)
 26 Apr 29, 2021
26 Apr 29, 2021
🏆 The 1st Place Submission to AICity Challenge 2021 Natural Language-Based Vehicle Retrieval Track (Alibaba-UTS submission)
AI City 2021: Connecting Language and Vision for Natural Language-Based Vehicle Retrieval 🏆 The 1st Place Submission to AICity Challenge 2021 Natural
82 Dec 29, 2022
Contrastive Language-Audio Pretraining
CLAP Contrastive Language-Audio Pretraining In due time this repo will be full of lovely things, I hope. Feel free to check out the Issues if you're i
 83 Dec 1, 2022
83 Dec 1, 2022
Code and data of the Fine-Grained R2R Dataset proposed in paper Sub-Instruction Aware Vision-and-Language Navigation
Fine-Grained R2R Code and data of the Fine-Grained R2R Dataset proposed in the EMNLP2020 paper Sub-Instruction Aware Vision-and-Language Navigation. C
 34 Nov 15, 2022
34 Nov 15, 2022

Code for Dual Contrastive Learning for Unsupervised Image-to-Image Translation, NTIRE, CVPRW 2021.
arXiv Dual Contrastive Learning Adversarial Generative Networks (DCLGAN) We provide our PyTorch implementation of DCLGAN, which is a simple yet powerf
 119 Dec 4, 2022
119 Dec 4, 2022
Code for the paper "Improving Vision-and-Language Navigation with Image-Text Pairs from the Web" (ECCV 2020)
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web Arjun Majumdar, Ayush Shrivastava, Stefan Lee, Peter Anderson, Devi Parikh
 44 Dec 14, 2022
44 Dec 14, 2022
Reimplementation of the paper `Human Attention Maps for Text Classification: Do Humans and Neural Networks Focus on the Same Words? (ACL2020)`
Human Attention for Text Classification Re-implementation of the paper Human Attention Maps for Text Classification: Do Humans and Neural Networks Foc
 15 Dec 13, 2021
15 Dec 13, 2021

This repo contains the official code of our work SAM-SLR which won the CVPR 2021 Challenge on Large Scale Signer Independent Isolated Sign Language Recognition.
Skeleton Aware Multi-modal Sign Language Recognition By Songyao Jiang, Bin Sun, Lichen Wang, Yue Bai, Kunpeng Li and Yun Fu. Smile Lab @ Northeastern
 128 Dec 8, 2022
128 Dec 8, 2022
Code for "Learning the Best Pooling Strategy for Visual Semantic Embedding", CVPR 2021
Learning the Best Pooling Strategy for Visual Semantic Embedding Official PyTorch implementation of the paper Learning the Best Pooling Strategy for V
 106 Jan 6, 2023
106 Jan 6, 2023

FID calculation with proper image resizing and quantization steps
clean-fid: Fixing Inconsistencies in FID Project | Paper The FID calculation involves many steps that can produce inconsistencies in the final metric.
 606 Jan 6, 2023
606 Jan 6, 2023
OCTIS: Comparing Topic Models is Simple! A python package to optimize and evaluate topic models (accepted at EACL2021 demo track)
OCTIS : Optimizing and Comparing Topic Models is Simple! OCTIS (Optimizing and Comparing Topic models Is Simple) aims at training, analyzing and compa
 478 Jan 1, 2023
478 Jan 1, 2023

VideoGPT: Video Generation using VQ-VAE and Transformers
VideoGPT: Video Generation using VQ-VAE and Transformers [Paper][Website][Colab][Gradio Demo] We present VideoGPT: a conceptually simple architecture
 470 Dec 30, 2022
470 Dec 30, 2022
DVG-Face: Dual Variational Generation for Heterogeneous Face Recognition, TPAMI 2021
DVG-Face: Dual Variational Generation for HFR This repo is a PyTorch implementation of DVG-Face: Dual Variational Generation for Heterogeneous Face Re
 52 Dec 30, 2022
52 Dec 30, 2022

Code for Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021)
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021) Hang Zhou, Yasheng Sun, Wayne Wu, Chen Cha
 628 Dec 28, 2022
628 Dec 28, 2022
skweak: A software toolkit for weak supervision applied to NLP tasks
Labelled data remains a scarce resource in many practical NLP scenarios. This is especially the case when working with resource-poor languages (or text domains), or when using task-specific labels without pre-existing datasets. The only available option is often to collect and annotate texts by hand, which is expensive and time-consuming.
 850 Dec 28, 2022
850 Dec 28, 2022
This repository contains the code for "Generating Datasets with Pretrained Language Models".
Datasets from Instructions (DINO 🦕 ) This repository contains the code for Generating Datasets with Pretrained Language Models. The paper introduces
 154 Jan 1, 2023
154 Jan 1, 2023

A simple python library for fast image generation of people who do not exist.
Random Face A simple python library for fast image generation of people who do not exist. For more details, please refer to the [paper](https://arxiv.
 170 Dec 15, 2022
170 Dec 15, 2022
Source code for AAAI20 "Generating Persona Consistent Dialogues by Exploiting Natural Language Inference".
Generating Persona Consistent Dialogues by Exploiting Natural Language Inference Source code for RCDG model in AAAI20 Generating Persona Consistent Di
 16 Oct 8, 2022
16 Oct 8, 2022

FedNLP: A Benchmarking Framework for Federated Learning in Natural Language Processing
FedNLP is a research-oriented benchmarking framework for advancing federated learning (FL) in natural language processing (NLP). It uses FedML repository as the git submodule. In other words, FedNLP only focuses on adavanced models and dataset, while FedML supports various federated optimizers (e.g., FedAvg) and platforms (Distributed Computing, IoT/Mobile, Standalone).
 216 Nov 27, 2022
216 Nov 27, 2022
Official code of our work, Unified Pre-training for Program Understanding and Generation [NAACL 2021].
PLBART Code pre-release of our work, Unified Pre-training for Program Understanding and Generation accepted at NAACL 2021. Note. A detailed documentat
 138 Dec 30, 2022
138 Dec 30, 2022

GrammarTagger — A Neural Multilingual Grammar Profiler for Language Learning
GrammarTagger — A Neural Multilingual Grammar Profiler for Language Learning GrammarTagger is an open-source toolkit for grammatical profiling for lan
 27 Jan 5, 2023
27 Jan 5, 2023
GLM (General Language Model)
GLM GLM is a General Language Model pretrained with an autoregressive blank-filling objective and can be finetuned on various natural language underst
 421 Jan 4, 2023
421 Jan 4, 2023
Code related to "Have Your Text and Use It Too! End-to-End Neural Data-to-Text Generation with Semantic Fidelity" paper
DataTuner You have just found the DataTuner. This repository provides tools for fine-tuning language models for a task. See LICENSE.txt for license de
 81 Jan 1, 2023
81 Jan 1, 2023
OpenMMLab's Next Generation Video Understanding Toolbox and Benchmark
Introduction English | 简体中文 MMAction2 is an open-source toolbox for video understanding based on PyTorch. It is a part of the OpenMMLab project. The m
 2.7k Jan 7, 2023
2.7k Jan 7, 2023
OpenMMLab Image and Video Editing Toolbox
Introduction MMEditing is an open source image and video editing toolbox based on PyTorch. It is a part of the OpenMMLab project. The master branch wo
3.9k Jan 4, 2023
Awesome-NLP-Research (ANLP)
Awesome-NLP-Research (ANLP)
 72 Dec 19, 2022
72 Dec 19, 2022

Python library containing BART query generation and BERT-based Siamese models for neural retrieval.
Neural Retrieval Embedding-based Zero-shot Retrieval through Query Generation leverages query synthesis over large corpuses of unlabeled text (such as
 35 Apr 14, 2022
35 Apr 14, 2022
Changing the Mind of Transformers for Topically-Controllable Language Generation
We will first introduce the how to run the IPython notebook demo by downloading our pretrained models. Then, we will introduce how to run our training and evaluation code.
 20 Dec 6, 2022
20 Dec 6, 2022

QA-GNN: Question Answering using Language Models and Knowledge Graphs
QA-GNN: Question Answering using Language Models and Knowledge Graphs This repo provides the source code & data of our paper: QA-GNN: Reasoning with L
 434 Jan 4, 2023
434 Jan 4, 2023

Official repository for Few-shot Image Generation via Cross-domain Correspondence (CVPR '21)
Few-shot Image Generation via Cross-domain Correspondence Utkarsh Ojha, Yijun Li, Jingwan Lu, Alexei A. Efros, Yong Jae Lee, Eli Shechtman, Richard Zh
 251 Dec 11, 2022
251 Dec 11, 2022

I-BERT: Integer-only BERT Quantization
I-BERT: Integer-only BERT Quantization HuggingFace Implementation I-BERT is also available in the master branch of HuggingFace! Visit the following li
 139 Dec 27, 2022
139 Dec 27, 2022

TTS is a library for advanced Text-to-Speech generation.
TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality. TTS comes with pretrained models, tools for measuring dataset quality and already used in 20+ languages for products and research projects.
 6.5k Jan 8, 2023
6.5k Jan 8, 2023
PClean: A Domain-Specific Probabilistic Programming Language for Bayesian Data Cleaning
PClean: A Domain-Specific Probabilistic Programming Language for Bayesian Data Cleaning Warning: This is a rapidly evolving research prototype.
 190 Dec 27, 2022
190 Dec 27, 2022
A fast and easy implementation of Transformer with PyTorch.
FasySeq FasySeq is a shorthand as a Fast and easy sequential modeling toolkit. It aims to provide a seq2seq model to researchers and developers, which
 7 Jul 18, 2022
7 Jul 18, 2022

Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
 4.7k Jan 1, 2023
4.7k Jan 1, 2023
CLASP - Contrastive Language-Aminoacid Sequence Pretraining
CLASP - Contrastive Language-Aminoacid Sequence Pretraining Repository for creating models pretrained on language and aminoacid sequences similar to C
 133 Dec 29, 2022
133 Dec 29, 2022
Official PyTorch implementation of MX-Font (Multiple Heads are Better than One: Few-shot Font Generation with Multiple Localized Experts)
Introduction Pytorch implementation of Multiple Heads are Better than One: Few-shot Font Generation with Multiple Localized Expert. | paper Song Park1
 97 Dec 23, 2022
97 Dec 23, 2022
A collection of scripts to preprocess ASR datasets and finetune language-specific Wav2Vec2 XLSR models
wav2vec-toolkit A collection of scripts to preprocess ASR datasets and finetune language-specific Wav2Vec2 XLSR models This repository accompanies the
 29 Oct 23, 2022
29 Oct 23, 2022

⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
 11.2k Jan 9, 2023
11.2k Jan 9, 2023
The source code for the Cutoff data augmentation approach proposed in this paper: "A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation".
Cutoff: A Simple Data Augmentation Approach for Natural Language This repository contains source code necessary to reproduce the results presented in
 49 Dec 22, 2022
49 Dec 22, 2022
Source code for the GPT-2 story generation models in the EMNLP 2020 paper "STORIUM: A Dataset and Evaluation Platform for Human-in-the-Loop Story Generation"
Storium GPT-2 Models This is the official repository for the GPT-2 models described in the EMNLP 2020 paper [STORIUM: A Dataset and Evaluation Platfor
 27 Dec 20, 2022
27 Dec 20, 2022
Official repository for "PAIR: Planning and Iterative Refinement in Pre-trained Transformers for Long Text Generation"
pair-emnlp2020 Official repository for the paper: Xinyu Hua and Lu Wang: PAIR: Planning and Iterative Refinement in Pre-trained Transformers for Long
 31 Oct 13, 2022
31 Oct 13, 2022

Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT CheXbert is an accurate, automated dee
 51 Dec 8, 2022
51 Dec 8, 2022
Code, Data and Demo for Paper: Controllable Generation from Pre-trained Language Models via Inverse Prompting
InversePrompting Paper: Controllable Generation from Pre-trained Language Models via Inverse Prompting Code: The code is provided in the "chinese_ip"
101 Dec 16, 2022
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language This repository contains UA-GEC data and an accompanying Python lib
 226 Dec 29, 2022
226 Dec 29, 2022

StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation
StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation Demo video: CVPR 2021 Oral: Single Channel Manipulation: Localized or attribu
 267 Dec 30, 2022
267 Dec 30, 2022
TextFlint is a multilingual robustness evaluation platform for natural language processing tasks,
TextFlint is a multilingual robustness evaluation platform for natural language processing tasks, which unifies general text transformation, task-specific transformation, adversarial attack, sub-population, and their combinations to provide a comprehensive robustness analysis.
 587 Dec 20, 2022
587 Dec 20, 2022
NetworkX is a Python package for the creation, manipulation, and study of the structure, dynamics, and functions of complex networks.
NetworkX is a Python package for the creation, manipulation, and study of the structure, dynamics, and functions of complex networks.
 12k Jan 2, 2023
12k Jan 2, 2023

Codes for NAACL 2021 Paper "Unsupervised Multi-hop Question Answering by Question Generation"
Unsupervised-Multi-hop-QA This repository contains code and models for the paper: Unsupervised Multi-hop Question Answering by Question Generation (NA
 70 Nov 27, 2022
70 Nov 27, 2022

Regularizing Generative Adversarial Networks under Limited Data (CVPR 2021)
Regularizing Generative Adversarial Networks under Limited Data [Project Page][Paper] Implementation for our GAN regularization method. The proposed r
 148 Nov 18, 2022
148 Nov 18, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
This project is part of Eleuther AI's quest to create a massive repository of high quality text data for training language models.
This project is part of Eleuther AI's quest to create a massive repository of high quality text data for training language models.
 42 Dec 13, 2022
42 Dec 13, 2022

A novel method to tune language models. Codes and datasets for paper ``GPT understands, too''.
P-tuning A novel method to tune language models. Codes and datasets for paper ``GPT understands, too''. How to use our code We have released the code
562 Dec 27, 2022

source code and pre-trained/fine-tuned checkpoint for NAACL 2021 paper LightningDOT
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval This repository contains source code and pre-trained/fine-tun
 65 Dec 26, 2022
65 Dec 26, 2022
The next generation Canto RSS daemon
Canto Daemon This is the RSS backend for Canto clients. Canto-curses is the default client at: http://github.com/themoken/canto-curses Requirements De
 155 Dec 28, 2022
155 Dec 28, 2022

Implementation of the paper "Language-agnostic representation learning of source code from structure and context".
Code Transformer This is an official PyTorch implementation of the CodeTransformer model proposed in: D. Zügner, T. Kirschstein, M. Catasta, J. Leskov
 131 Dec 13, 2022
131 Dec 13, 2022

The guide to tackle with the Text Summarization
The guide to tackle with the Text Summarization
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
Source Code for DialogBERT: Discourse-Aware Response Generation via Learning to Recover and Rank Utterances (https://arxiv.org/pdf/2012.01775.pdf)
DialogBERT This is a PyTorch implementation of the DialogBERT model described in DialogBERT: Neural Response Generation via Hierarchical BERT with Dis
 67 Jan 6, 2023
67 Jan 6, 2023
JMESPath is a query language for JSON.
JMESPath JMESPath (pronounced "james path") allows you to declaratively specify how to extract elements from a JSON document. For example, given this
 1.7k Dec 31, 2022
1.7k Dec 31, 2022
Simple yet flexible natural sorting in Python.
natsort Simple yet flexible natural sorting in Python. Source Code: https://github.com/SethMMorton/natsort Downloads: https://pypi.org/project/natsort
 712 Dec 23, 2022
712 Dec 23, 2022
MashaRobot : New Generation Telegram Group Manager Bot (🔸Fast 🔸Python🔸Pyrogram 🔸Telethon 🔸Mongo db )
MashaRobot Me On Telegram ✨ MASHA ✨ This is just a demo bot.. Don't try to add to your group.. Create your own bot How To Host The easiest way to depl
 40 Oct 9, 2022
40 Oct 9, 2022

Tracking Progress in Natural Language Processing
Repository to track the progress in Natural Language Processing (NLP), including the datasets and the current state-of-the-art for the most common NLP tasks.
 21.2k Dec 30, 2022
21.2k Dec 30, 2022
A probabilistic programming language in TensorFlow. Deep generative models, variational inference.
Edward is a Python library for probabilistic modeling, inference, and criticism. It is a testbed for fast experimentation and research with probabilis
 4.7k Jan 9, 2023
4.7k Jan 9, 2023
Library for faster pinned CPU - GPU transfer in Pytorch
SpeedTorch Faster pinned CPU tensor - GPU Pytorch variabe transfer and GPU tensor - GPU Pytorch variable transfer, in certain cases. Update 9-29-1
 657 Dec 19, 2022
657 Dec 19, 2022

Release of SPLASH: Dataset for semantic parse correction with natural language feedback in the context of text-to-SQL parsing
SPLASH: Semantic Parsing with Language Assistance from Humans SPLASH is dataset for the task of semantic parse correction with natural language feedba
 35 Oct 31, 2022
35 Oct 31, 2022
NaturalProofs: Mathematical Theorem Proving in Natural Language
NaturalProofs: Mathematical Theorem Proving in Natural Language NaturalProofs: Mathematical Theorem Proving in Natural Language Sean Welleck, Jiacheng
 83 Jan 5, 2023
83 Jan 5, 2023
UNION: An Unreferenced Metric for Evaluating Open-ended Story Generation
UNION Automatic Evaluation Metric described in the paper UNION: An UNreferenced MetrIc for Evaluating Open-eNded Story Generation (EMNLP 2020). Please
50 Dec 30, 2022
![[CVPR 2021] Counterfactual VQA: A Cause-Effect Look at Language Bias](https://github.com/yuleiniu/cfvqa/raw/main/assets/cfvqa.png)
[CVPR 2021] Counterfactual VQA: A Cause-Effect Look at Language Bias
Counterfactual VQA (CF-VQA) This repository is the Pytorch implementation of our paper "Counterfactual VQA: A Cause-Effect Look at Language Bias" in C
 94 Dec 3, 2022
94 Dec 3, 2022
A curated list of resources dedicated to scene text localization and recognition
Scene Text Localization & Recognition Resources A curated list of resources dedicated to scene text localization and recognition. Any suggestions and
 1.6k Dec 22, 2022
1.6k Dec 22, 2022

OCR system for Arabic language that converts images of typed text to machine-encoded text.
Arabic OCR OCR system for Arabic language that converts images of typed text to machine-encoded text. The system currently supports only letters (29 l
 144 Jan 5, 2023
144 Jan 5, 2023
Natural language detection
Detect the language of text. What’s so cool about franc? franc can support more languages(†) than any other library franc is packaged with support for
 3.8k Jan 2, 2023
3.8k Jan 2, 2023
Detecting Text in Natural Image with Connectionist Text Proposal Network (ECCV'16)
Detecting Text in Natural Image with Connectionist Text Proposal Network The codes are used for implementing CTPN for scene text detection, described
 1.3k Dec 22, 2022
1.3k Dec 22, 2022

keras复现场景文本检测网络CPTN: 《Detecting Text in Natural Image with Connectionist Text Proposal Network》;欢迎试用,关注,并反馈问题...
keras-ctpn [TOC] 说明 预测 训练 例子 4.1 ICDAR2015 4.1.1 带侧边细化 4.1.2 不带带侧边细化 4.1.3 做数据增广-水平翻转 4.2 ICDAR2017 4.3 其它数据集 toDoList 总结 说明 本工程是keras实现的CPTN: Detecti
 107 Jan 9, 2023
107 Jan 9, 2023

Recognizing cropped text in natural images.
ASTER: Attentional Scene Text Recognizer with Flexible Rectification ASTER is an accurate scene text recognizer with flexible rectification mechanism.
 681 Jan 2, 2023
681 Jan 2, 2023

An Implementation of the seglink alogrithm in paper Detecting Oriented Text in Natural Images by Linking Segments
Tips: A more recent scene text detection algorithm: PixelLink, has been implemented here: https://github.com/ZJULearning/pixel_link Contents: Introduc
 484 Dec 7, 2022
484 Dec 7, 2022

This is a c++ project deploying a deep scene text reading pipeline with tensorflow. It reads text from natural scene images. It uses frozen tensorflow graphs. The detector detect scene text locations. The recognizer reads word from each detected bounding box.
DeepSceneTextReader This is a c++ project deploying a deep scene text reading pipeline. It reads text from natural scene images. Prerequsites The proj
 49 Sep 10, 2022
49 Sep 10, 2022
Text language identification using Wikipedia data
Text language identification using Wikipedia data The aim of this project is to provide high-quality language detection over all the web's languages.
 28 Jul 9, 2022
28 Jul 9, 2022
Lightning Fast Language Prediction 🚀
whatthelang Lightning Fast Language Prediction 🚀 Dependencies The dependencies can be installed using the requirements.txt file: $ pip install -r req
 152 Oct 16, 2022
152 Oct 16, 2022
👄 The most accurate natural language detection library for Java and the JVM, suitable for long and short text alike
Quick Info this library tries to solve language detection of very short words and phrases, even shorter than tweets makes use of both statistical and
 532 Dec 28, 2022
532 Dec 28, 2022

TensorFlow code for the neural network presented in the paper: "Structural Language Models of Code" (ICML'2020)
SLM: Structural Language Models of Code This is an official implementation of the model described in: "Structural Language Models of Code" [PDF] To ap
 73 Nov 6, 2022
73 Nov 6, 2022
Python generation script for BitBirds
BitBirds generation script Intro This is published under MIT license, which means you can do whatever you want with it - entirely at your own risk. Pl
 286 Dec 6, 2022
286 Dec 6, 2022
Uncertain natural language inference
Uncertain Natural Language Inference This repository hosts the code for the following paper: Tongfei Chen*, Zhengping Jiang*, Adam Poliak, Keisuke Sak
 14 Sep 1, 2022
14 Sep 1, 2022

Code for the paper Language as a Cognitive Tool to Imagine Goals in Curiosity Driven Exploration
IMAGINE: Language as a Cognitive Tool to Imagine Goals in Curiosity Driven Exploration This repo contains the code base of the paper Language as a Cog
 26 Dec 22, 2022
26 Dec 22, 2022

ReText: Simple but powerful editor for Markdown and reStructuredText
Welcome to ReText! ReText is a simple but powerful editor for Markdown and reStructuredText markup languages. One can also add support for custom mark
 1.6k Dec 23, 2022
1.6k Dec 23, 2022

Komodo Edit is a fast and free multi-language code editor. Written in JS, Python, C++ and based on the Mozilla platform.
Komodo Edit This readme explains how to get started building, using and developing with the Komodo Edit source base. Whilst the main Komodo Edit sourc
 2k Dec 28, 2022
2k Dec 28, 2022

A collection of full-stack resources for programmers.
A collection of full-stack resources for programmers.
 22.3k Dec 30, 2022
22.3k Dec 30, 2022

Simple command line tool for text to image generation using OpenAI's CLIP and Siren (Implicit neural representation network)
Simple command line tool for text to image generation using OpenAI's CLIP and Siren (Implicit neural representation network)
 4.4k Jan 9, 2023
4.4k Jan 9, 2023
To be a next-generation DL-based phenotype prediction from genome mutations.
Sequence -----------+-- 3D_structure -- 3D_module --+ +-- ? | |
 18 Jan 11, 2022
18 Jan 11, 2022
Official code of our work, Unified Pre-training for Program Understanding and Generation [NAACL 2021].
PLBART Code pre-release of our work, Unified Pre-training for Program Understanding and Generation accepted at NAACL 2021. Note. A detailed documentat
138 Dec 30, 2022