293 Repositories
Python pdf-parser Libraries

A data parser for the internal syncing data format used by Fog of World.
A data parser for the internal syncing data format used by Fog of World. The parser is not designed to be a well-coded library with good performance, it is more like a demo for showing the data structure.
 40 Dec 12, 2022
40 Dec 12, 2022

Fetch McDonald invoices from mailbox and merge them to one PDF file.
concatenate Fetch McDonald invoices from mailbox and merge them to one PDF file. Description This script will fetch all McDonald invoice pdfs from a p
 3 Oct 6, 2022
3 Oct 6, 2022
Python script that split PDF files.
Automatic PDF Splitter This script can create new single-page PDFs files from multipaged PDFs. Requirements Python 3.0+ # Debian distros sudo apt-get
 5 Apr 2, 2022
5 Apr 2, 2022
Merge multiple PDF files into one.
PDF Merger Merge multiple PDF files into one. Usage % python pdf_merger.py -h usage: pdf_merger.py [-h] [-o OUTPUT] [-f [FILES ...]] optional argumen
 6 Oct 3, 2022
6 Oct 3, 2022
Cobalt Strike Beacon configuration extractor and parser.
Cobalt Strike Configuration Extractor and Parser Overview Pure Python library and set of scripts to extract and parse configurations (configs) from Co
 102 Dec 18, 2022
102 Dec 18, 2022

Images to PDF Telegram Bot
ilovepdf Convert Images to PDF Bot This bot will helps you to create pdf's from your images [without leaving telegram] 😉 By Default: your pdf fil
 116 Dec 29, 2022
116 Dec 29, 2022
Generate a bunch of malicious pdf files with phone-home functionality. Can be used with Burp Collaborator
Malicious PDF Generator ☠️ Generate ten different malicious pdf files with phone-home functionality. Can be used with Burp Collaborator. Used for pene
 1.9k Jan 1, 2023
1.9k Jan 1, 2023
async parser for JET
This project is mainly aims to provide an async parsing option for NTDS.dit database file for obtaining user secrets.
 15 Mar 8, 2022
15 Mar 8, 2022
open-information-extraction-system, build open-knowledge-graph(SPO, subject-predicate-object) by pyltp(version==3.4.0)
中文开放信息抽取系统, open-information-extraction-system, build open-knowledge-graph(SPO, subject-predicate-object) by pyltp(version==3.4.0)
 7 Nov 2, 2022
7 Nov 2, 2022
BLE parser for passive BLE advertisements
This pypi package is parsing BLE advertisements to readable data for several sensors and can be used for device tracking, as long as the MAC address is static. The parser was originally developed as part of the BLE monitor custom component for Home Assistant, but can now be used for other implementations.
 19 Dec 26, 2022
19 Dec 26, 2022
This app converts an pdf file into the audio file.
PDF-to-Audio This app takes an pdf as an input and convert it into audio, and the library text-to-speech starts speaking the preffered page given in t
 3 Aug 4, 2021
3 Aug 4, 2021

Official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers
Visual Parser (ViP) This is the official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers. Key Feature
 117 Dec 11, 2022
117 Dec 11, 2022
Extract Thailand COVID-19 Cluster data from daily briefing pdf.
Thailand COVID-19 Cluster Data Extraction About Extract Clusters from Thailand Daily COVID-19 briefing PDF Download latest data Here. Data will be upd
 5 Sep 27, 2021
5 Sep 27, 2021

Set of utilities for exporting/controlling your robot in Blender
Blender Robotics Utils This repository contains utilities for exporting/controlling your robot in Blender Maintainers This repository is maintained by
 33 Nov 30, 2022
33 Nov 30, 2022

Performing the following operations using python on PDF.
Python PDF Handling Tutorial Python is a highly versatile language with a huge set of libraries. It is a high level language with simple syntax. Pytho
 131 Dec 16, 2022
131 Dec 16, 2022

A Python tool to generate a static HTML file that represents the internal structure of a PDF file
PDFSyntax A Python tool to generate a static HTML file that represents the internal structure of a PDF file At some point the low-level functions deve
 394 Dec 30, 2022
394 Dec 30, 2022

PERIN is Permutation-Invariant Semantic Parser developed for MRP 2020
PERIN: Permutation-invariant Semantic Parsing David Samuel & Milan Straka Charles University Faculty of Mathematics and Physics Institute of Formal an
 40 Jan 4, 2023
40 Jan 4, 2023
pystitcher stitches your PDF files together, generating nice customizable bookmarks for you using a declarative markdown file as input
pystitcher pystitcher stitches your PDF files together, generating nice customizable bookmarks for you using a declarative input in the form of a mark
 387 Dec 10, 2022
387 Dec 10, 2022
A python library for extracting text from PDFs without losing the formatting of the PDF content.
Multilingual PDF to Text Install Package from Pypi Install it using pip. pip install multilingual-pdf2text The library uses Tesseract which can be ins
 49 Nov 7, 2022
49 Nov 7, 2022

Python parser for DTED data.
DTED Parser This is a package written in pure python (with help from numpy) to parse and investigate Digital Terrain Elevation Data (DTED) files. This
 12 Dec 18, 2022
12 Dec 18, 2022
Tomli is a Python library for parsing TOML
Tomli A lil' TOML parser Table of Contents generated with mdformat-toc Intro Installation Usage Parse a TOML string Parse a TOML file Handle invalid T
 315 Jan 4, 2023
315 Jan 4, 2023
Tomli is a Python library for parsing TOML. Tomli is fully compatible with TOML v1.0.0.
Tomli A lil' TOML parser Table of Contents generated with mdformat-toc Intro Installation Usage Parse a TOML string Parse a TOML file Handle invalid T
313 Dec 26, 2022

Parse discord tokens from any file, even if there is other shit in the file with them.
Discord-Token-Parser Parse discord tokens from any file, even if there is other shit in the file with them. Any. File. I glued together all html from
 4 May 7, 2022
4 May 7, 2022
A versatile token stream for handwritten parsers.
Writing recursive-descent parsers by hand can be quite elegant but it's often a bit more verbose than expected, especially when it comes to handling indentation and reporting proper syntax errors. This package provides a powerful general-purpose token stream that addresses these issues and more.
 8 Nov 30, 2022
8 Nov 30, 2022
Learning with Peter Norvig's lis.py interpreter
Learning with lis.py This repository contains variations of Peter Norvig's lis.py interpreter for a subset of Scheme, described in (How to Write a (Li
 170 Dec 15, 2022
170 Dec 15, 2022
An OData v4 query parser and transpiler for Python
odata-query is a library that parses OData v4 filter strings, and can convert them to other forms such as Django Queries, SQLAlchemy Queries, or just plain SQL.
 39 Jan 5, 2023
39 Jan 5, 2023
Using context-free grammar formalism to parse English sentences to determine their structure to help computer to better understand the meaning of the sentence.
Sentance Parser Executing the Program Make sure Python 3.6+ is installed. Install requirements $ pip install requirements.txt Run the program:
 12 Sep 28, 2022
12 Sep 28, 2022

PyMuPDF is a Python binding with support for MuPDF
PyMuPDF is a Python binding with support for MuPDF (current version 1.18.*), a lightweight PDF, XPS, and E-book viewer, renderer, and toolkit, which is maintained and developed by Artifex Software, Inc.
 1.9k Jan 3, 2023
1.9k Jan 3, 2023
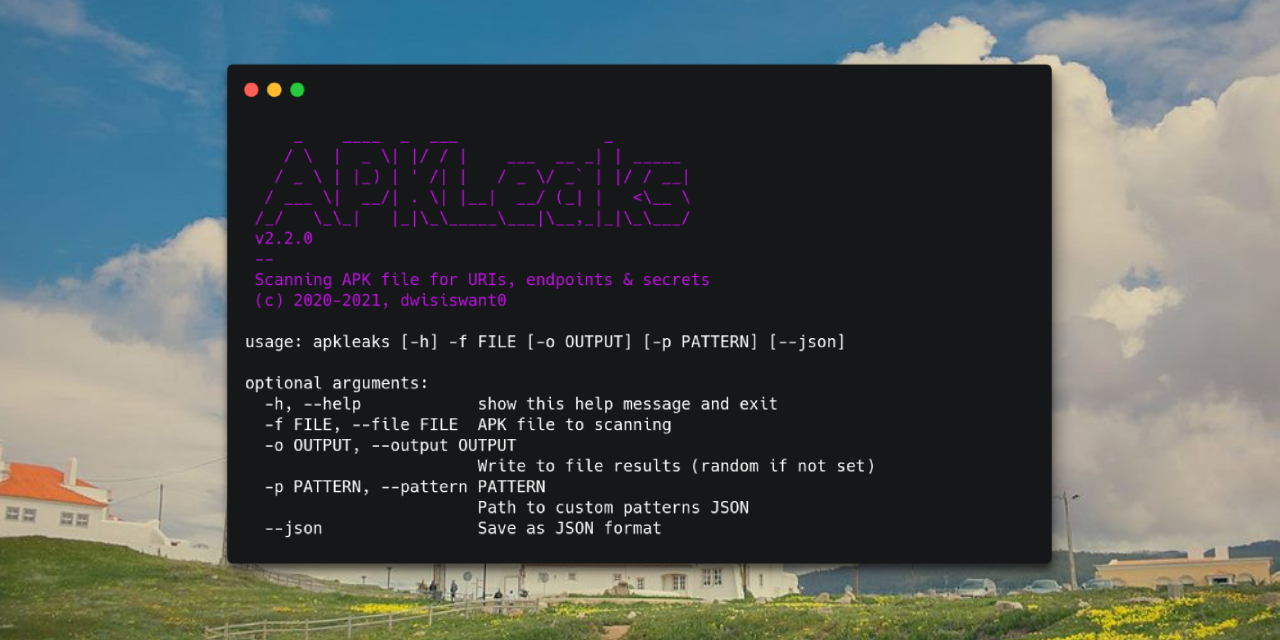
APKLeaks - Scanning APK file for URIs, endpoints & secrets.
APKLeaks - Scanning APK file for URIs, endpoints & secrets.
 3.5k Jan 9, 2023
3.5k Jan 9, 2023
A Gura parser implementation for Python
Gura parser This repository contains the implementation of a Gura format parser in Python. Installation pip install gura-parser Usage import gura gur
 19 Jan 25, 2022
19 Jan 25, 2022
simdjson : Parsing gigabytes of JSON per second
JSON is everywhere on the Internet. Servers spend a *lot* of time parsing it. We need a fresh approach. The simdjson library uses commonly available SIMD instructions and microparallel algorithms to parse JSON 4x faster than RapidJSON and 25x faster than JSON for Modern C++.
 16.3k Dec 29, 2022
16.3k Dec 29, 2022
A fast JSON parser/generator for C++ with both SAX/DOM style API
A fast JSON parser/generator for C++ with both SAX/DOM style API Tencent is pleased to support the open source community by making RapidJSON available
 12.6k Dec 30, 2022
12.6k Dec 30, 2022
Python PDF Parser (Not actively maintained). Check out pdfminer.six.
PDFMiner PDFMiner is a text extraction tool for PDF documents. Warning: As of 2020, PDFMiner is not actively maintained. The code still works, but thi
 4.9k Jan 4, 2023
4.9k Jan 4, 2023
PyPDF2 is a pure-python PDF library capable of splitting, merging together, cropping, and transforming the pages of PDF files.
PyPDF2 is a pure-python PDF library capable of splitting, merging together, cropping, and transforming the pages of PDF files. It can also add custom data, viewing options, and passwords to PDF files. It can retrieve text and metadata from PDFs as well as merge entire files together.
 5k Jan 4, 2023
5k Jan 4, 2023
Simple HTML and PDF document generator for Python - with built-in support for popular data analysis and plotting libraries.
Esparto is a simple HTML and PDF document generator for Python. Its primary use is for generating shareable single page reports with content from popular analytics and data science libraries.
 76 Dec 12, 2022
76 Dec 12, 2022
simplejson is a simple, fast, extensible JSON encoder/decoder for Python
simplejson simplejson is a simple, fast, complete, correct and extensible JSON http://json.org encoder and decoder for Python 3.3+ with legacy suppo
 1.5k Jan 5, 2023
1.5k Jan 5, 2023
Automatically detect changes made to the official Telegram sites.
🕷 Telegram Web Crawler This project is developed to automatically detect changes made to the official Telegram sites. This is necessary for anticipat
 115 Dec 31, 2022
115 Dec 31, 2022
PGPortfolio: Policy Gradient Portfolio, the source code of "A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem"(https://arxiv.org/pdf/1706.10059.pdf).
This is the original implementation of our paper, A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem (arXiv:1706.1
 1.5k Dec 29, 2022
1.5k Dec 29, 2022
Python bindings to libpostal for fast international address parsing/normalization
pypostal These are the official Python bindings to https://github.com/openvenues/libpostal, a fast statistical parser/normalizer for street addresses
 651 Dec 16, 2022
651 Dec 16, 2022

Layout Parser is a deep learning based tool for document image layout analysis tasks.
A Python Library for Document Layout Understanding
 3.4k Dec 30, 2022
3.4k Dec 30, 2022
Source Code for DialogBERT: Discourse-Aware Response Generation via Learning to Recover and Rank Utterances (https://arxiv.org/pdf/2012.01775.pdf)
DialogBERT This is a PyTorch implementation of the DialogBERT model described in DialogBERT: Neural Response Generation via Hierarchical BERT with Dis
 67 Jan 6, 2023
67 Jan 6, 2023
PyTorch implementation of TabNet paper : https://arxiv.org/pdf/1908.07442.pdf
README TabNet : Attentive Interpretable Tabular Learning This is a pyTorch implementation of Tabnet (Arik, S. O., & Pfister, T. (2019). TabNet: Attent
 2k Dec 27, 2022
2k Dec 27, 2022
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. ocrmypdf # it's a scriptable c
 7.9k Jan 3, 2023
7.9k Jan 3, 2023
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023
A machine learning software for extracting information from scholarly documents
GROBID GROBID documentation Visit the GROBID documentation for more detailed information. Summary GROBID (or Grobid, but not GroBid nor GroBiD) means
 1.9k Jan 8, 2023
1.9k Jan 8, 2023
Python library to extract tabular data from images and scanned PDFs
Overview ExtractTable - API to extract tabular data from images and scanned PDFs The motivation is to make it easy for developers to extract tabular d
 165 Dec 31, 2022
165 Dec 31, 2022

Camelot: PDF Table Extraction for Humans
Camelot: PDF Table Extraction for Humans Camelot is a Python library that makes it easy for anyone to extract tables from PDF files! Note: You can als
 3.3k Dec 31, 2022
3.3k Dec 31, 2022
📔️ Generate a text-based journal from a template file.
JGen 📔️ Generate a text-based journal from a template file. Contents Getting Started Example Overview Usage Details Reserved Keywords Gotchas Getting
 21 Sep 25, 2022
21 Sep 25, 2022

Parse Robinhood 1099 Tax Document from PDF into CSV
Robinhood 1099 Parser This project converts Robinhood Securities 1099 tax document from PDF to CSV file. This tool will be helpful for those who need
 52 Jun 10, 2022
52 Jun 10, 2022

Official code for "Parser-Free Virtual Try-on via Distilling Appearance Flows", CVPR 2021
Parser-Free Virtual Try-on via Distilling Appearance Flows, CVPR 2021 Official code for CVPR 2021 paper 'Parser-Free Virtual Try-on via Distilling App
 395 Jan 3, 2023
395 Jan 3, 2023

This repo provides the official code for TransBTS: Multimodal Brain Tumor Segmentation Using Transformer (https://arxiv.org/pdf/2103.04430.pdf).
TransBTS: Multimodal Brain Tumor Segmentation Using Transformer This repo is the official implementation for TransBTS: Multimodal Brain Tumor Segmenta
 247 Dec 28, 2022
247 Dec 28, 2022

Render reMarkable documents to PDF
rmrl: reMarkable Rendering Library rmrl is a Python library for rendering reMarkable documents to PDF files. It takes the original PDF document and th
 95 Dec 25, 2022
95 Dec 25, 2022
:mag: Ambar: Document Search Engine
🔍 Ambar: Document Search Engine Ambar is an open-source document search engine with automated crawling, OCR, tagging and instant full-text search. Am
 1.9k Jan 9, 2023
1.9k Jan 9, 2023
Python library for creating PEG parsers
PyParsing -- A Python Parsing Module Introduction The pyparsing module is an alternative approach to creating and executing simple grammars, vs. the t
 1.7k Jan 3, 2023
1.7k Jan 3, 2023
:snake: Complete C99 parser in pure Python
pycparser v2.20 Contents 1 Introduction 1.1 What is pycparser? 1.2 What is it good for? 1.3 Which version of C does pycparser support? 1.4 What gramma
 2.8k Dec 29, 2022
2.8k Dec 29, 2022
Stand-alone parser for User Access Logging from Server 2012 and newer systems
KStrike Stand-alone parser for User Access Logging from Server 2012 and newer systems BriMor Labs KStrike This script will parse data from the User Ac
 69 Nov 1, 2022
69 Nov 1, 2022
Knowledge Management for Humans using Machine Learning & Tags
HyperTag HyperTag helps humans intuitively express how they think about their files using tags and machine learning.
 165 Nov 4, 2022
165 Nov 4, 2022
Knowledge Management for Humans using Machine Learning & Tags
HyperTag helps humans intuitively express how they think about their files using tags and machine learning. Represent how you think using tags. Find what you look for using semantic search for your text documents (yes, even PDF's) and images.
166 Jan 7, 2023

Snips Python library to extract meaning from text
Snips NLU Snips NLU (Natural Language Understanding) is a Python library that allows to extract structured information from sentences written in natur
 3.5k Feb 17, 2021
3.5k Feb 17, 2021
Snips Python library to extract meaning from text
Snips NLU Snips NLU (Natural Language Understanding) is a Python library that allows to extract structured information from sentences written in natur
3.5k Feb 12, 2021
MkDocs Plugin allowing your visitors to *File Print Save as PDF* the entire site.
mkdocs-print-site-plugin MkDocs plugin that adds a page to your site combining all pages, allowing your site visitors to File Print Save as PDF th
 67 Jan 4, 2023
67 Jan 4, 2023
Generate a single PDF file from MkDocs repository.
PDF Generate Plugin for MkDocs This plugin will generate a single PDF file from your MkDocs repository. This plugin is inspired by MkDocs PDF Export P
 198 Jan 3, 2023
198 Jan 3, 2023
An MkDocs plugin to export content pages as PDF files
MkDocs PDF Export Plugin An MkDocs plugin to export content pages as PDF files The pdf-export plugin will export all markdown pages in your MkDocs rep
 266 Dec 13, 2022
266 Dec 13, 2022
A Python Parser
parso - A Python Parser Parso is a Python parser that supports error recovery and round-trip parsing for different Python versions (in multiple Python
 520 Dec 26, 2022
520 Dec 26, 2022
Pythonic command line arguments parser, that will make you smile
docopt creates beautiful command-line interfaces Video introduction to docopt: PyCon UK 2012: Create *beautiful* command-line interfaces with Python N
 7.7k Dec 30, 2022
7.7k Dec 30, 2022
ISO 8601 date/time parser
ISO 8601 date/time parser This module implements ISO 8601 date, time and duration parsing. The implementation follows ISO8601:2004 standard, and imple
 118 Dec 20, 2022
118 Dec 20, 2022
python parser for human readable dates
Python parser for human readable dates Key Features • How To Use • Installation • Common use cases • You may also like... • License Key Features Suppo
 2.2k Jan 8, 2023
2.2k Jan 8, 2023
Type-safe YAML parser and validator.
StrictYAML StrictYAML is a type-safe YAML parser that parses and validates a restricted subset of the YAML specification. Priorities: Beautiful API Re
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
Python wrapper around rapidjson
python-rapidjson Python wrapper around RapidJSON Authors: Ken Robbins [email protected] Lele Gaifax [email protected] License: MIT License Sta
 469 Jan 4, 2023
469 Jan 4, 2023
simplejson is a simple, fast, extensible JSON encoder/decoder for Python
simplejson simplejson is a simple, fast, complete, correct and extensible JSON http://json.org encoder and decoder for Python 3.3+ with legacy suppo
1.5k Dec 31, 2022
FlatBuffers: Memory Efficient Serialization Library
FlatBuffers FlatBuffers is a cross platform serialization library architected for maximum memory efficiency. It allows you to directly access serializ
 19.6k Jan 1, 2023
19.6k Jan 1, 2023
IMDbPY is a Python package useful to retrieve and manage the data of the IMDb movie database about movies, people, characters and companies
IMDbPY is a Python package for retrieving and managing the data of the IMDb movie database about movies, people and companies. Revamp notice Starting
 1.1k Jan 2, 2023
1.1k Jan 2, 2023
A fast, extensible and spec-compliant Markdown parser in pure Python.
mistletoe mistletoe is a Markdown parser in pure Python, designed to be fast, spec-compliant and fully customizable. Apart from being the fastest Comm
 546 Jan 1, 2023
546 Jan 1, 2023
Markdown parser, done right. 100% CommonMark support, extensions, syntax plugins & high speed. Now in Python!
markdown-it-py Markdown parser done right. Follows the CommonMark spec for baseline parsing Configurable syntax: you can add new rules and even replac
 398 Dec 24, 2022
398 Dec 24, 2022
Convert HTML to Markdown-formatted text.
html2text html2text is a Python script that converts a page of HTML into clean, easy-to-read plain ASCII text. Better yet, that ASCII also happens to
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
A Python implementation of John Gruber’s Markdown with Extension support.
Python-Markdown This is a Python implementation of John Gruber's Markdown. It is almost completely compliant with the reference implementation, though
 3.1k Dec 31, 2022
3.1k Dec 31, 2022
Python binding to Modest engine (fast HTML5 parser with CSS selectors).
A fast HTML5 parser with CSS selectors using Modest engine. Installation From PyPI using pip: pip install selectolax Development version from github:
 710 Jan 4, 2023
710 Jan 4, 2023
The awesome document factory
The Awesome Document Factory WeasyPrint is a smart solution helping web developers to create PDF documents. It turns simple HTML pages into gorgeous s
 5.4k Jan 7, 2023
5.4k Jan 7, 2023
HTTP request/response parser for python in C
http-parser HTTP request/response parser for Python compatible with Python 2.x (=2.7), Python 3 and Pypy. If possible a C parser based on http-parser
 334 Dec 24, 2022
334 Dec 24, 2022
Fast HTTP parser
httptools is a Python binding for the nodejs HTTP parser. The package is available on PyPI: pip install httptools. APIs httptools contains two classes
 1.1k Jan 7, 2023
1.1k Jan 7, 2023

Converts text into a PDF of handwritten notes
Text To Handwritten Notes Converts text into a PDF of handwritten notes Explore the docs » · Report Bug · Request Feature · Steps: $ git clone https:/
 63 Oct 9, 2022
63 Oct 9, 2022
![The official implementation of NeMo: Neural Mesh Models of Contrastive Features for Robust 3D Pose Estimation [ICLR-2021]. https://arxiv.org/pdf/2101.12378.pdf](https://github.com/Angtian/NeMo/raw/main/example.gif)
The official implementation of NeMo: Neural Mesh Models of Contrastive Features for Robust 3D Pose Estimation [ICLR-2021]. https://arxiv.org/pdf/2101.12378.pdf
NeMo: Neural Mesh Models of Contrastive Features for Robust 3D Pose Estimation [ICLR-2021] Release Notes The offical PyTorch implementation of NeMo, p
 76 Nov 23, 2022
76 Nov 23, 2022
A non-validating SQL parser module for Python
python-sqlparse - Parse SQL statements sqlparse is a non-validating SQL parser for Python. It provides support for parsing, splitting and formatting S
 3.1k Jan 4, 2023
3.1k Jan 4, 2023
A simple Python module for parsing human names into their individual components
Name Parser A simple Python (3.2+ & 2.6+) module for parsing human names into their individual components. hn.title hn.first hn.middle hn.last hn.suff
 574 Dec 20, 2022
574 Dec 20, 2022
Python library for creating PEG parsers
PyParsing -- A Python Parsing Module Introduction The pyparsing module is an alternative approach to creating and executing simple grammars, vs. the t
1.7k Dec 27, 2022
Convert HTML to Markdown-formatted text.
html2text html2text is a Python script that converts a page of HTML into clean, easy-to-read plain ASCII text. Better yet, that ASCII also happens to
1.3k Dec 31, 2022
A Python implementation of John Gruber’s Markdown with Extension support.
Python-Markdown This is a Python implementation of John Gruber's Markdown. It is almost completely compliant with the reference implementation, though
3.1k Dec 30, 2022
A fast yet powerful Python Markdown parser with renderers and plugins.
Mistune v2 A fast yet powerful Python Markdown parser with renderers and plugins. NOTE: This is the re-designed v2 of mistune. Check v1 branch for ear
 2.2k Jan 4, 2023
2.2k Jan 4, 2023
Python wrapper around rapidjson
python-rapidjson Python wrapper around RapidJSON Authors: Ken Robbins [email protected] Lele Gaifax [email protected] License: MIT License Sta
469 Jan 4, 2023
Snips Python library to extract meaning from text
Snips NLU Snips NLU (Natural Language Understanding) is a Python library that allows to extract structured information from sentences written in natur
3.7k Dec 30, 2022
A python wrapper around the ZPar parser for English.
NOTE This project is no longer under active development since there are now really nice pure Python parsers such as Stanza and Spacy. The repository w
 49 Sep 12, 2022
49 Sep 12, 2022
Python bindings to the dutch NLP tool Frog (pos tagger, lemmatiser, NER tagger, morphological analysis, shallow parser, dependency parser)
Frog for Python This is a Python binding to the Natural Language Processing suite Frog. Frog is intended for Dutch and performs part-of-speech tagging
 46 Dec 14, 2022
46 Dec 14, 2022

Launched in 2018 Actively developed and supported. Supports tkinter, Qt, WxPython, Remi (in browser). Create custom layout GUI's simply. Python 2.7 & 3 Support. 200+ Demo programs & Cookbook for rapid start. Extensive documentation. Examples using Machine Learning(GUI, OpenCV Integration, Chatterbot), Floating Desktop Widgets, Matplotlib + Pyplot integration, add GUI to command line scripts, PDF & Image Viewer. For both beginning and advanced programmers .
Python GUIs for Humans Transforms the tkinter, Qt, WxPython, and Remi (browser-based) GUI frameworks into a simpler interface. The window definition i
 11k Dec 30, 2022
11k Dec 30, 2022