667 Repositories
Python sagemaker-training Libraries

Delve is a Python package for analyzing the inference dynamics of your PyTorch model.
Delve is a Python package for analyzing the inference dynamics of your PyTorch model.
 73 Dec 12, 2022
73 Dec 12, 2022
fastai ulmfit - Pretraining the Language Model, Fine-Tuning and training a Classifier
fast.ai ULMFiT with SentencePiece from pretraining to deployment Motivation: Why even bother with a non-BERT / Transformer language model? Short answe
 26 May 27, 2022
26 May 27, 2022
An easy to use Natural Language Processing library and framework for predicting, training, fine-tuning, and serving up state-of-the-art NLP models.
Welcome to AdaptNLP A high level framework and library for running, training, and deploying state-of-the-art Natural Language Processing (NLP) models
 407 Jan 3, 2023
407 Jan 3, 2023
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
An Agnostic Object Detection Framework IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-q
 790 Jan 5, 2023
790 Jan 5, 2023

Compare MLOps Platforms. Breakdowns of SageMaker, VertexAI, AzureML, Dataiku, Databricks, h2o, kubeflow, mlflow...
Compare MLOps Platforms. Breakdowns of SageMaker, VertexAI, AzureML, Dataiku, Databricks, h2o, kubeflow, mlflow...
 318 Jan 2, 2023
318 Jan 2, 2023

This is the official PyTorch implementation for "Mesa: A Memory-saving Training Framework for Transformers".
A Memory-saving Training Framework for Transformers This is the official PyTorch implementation for Mesa: A Memory-saving Training Framework for Trans
 105 Dec 6, 2022
105 Dec 6, 2022
Live training loss plot in Jupyter Notebook for Keras, PyTorch and others
livelossplot Don't train deep learning models blindfolded! Be impatient and look at each epoch of your training! (RECENT CHANGES, EXAMPLES IN COLAB, A
 1.2k Jan 8, 2023
1.2k Jan 8, 2023

 3 Nov 23, 2021
3 Nov 23, 2021

This is the official PyTorch implementation for "Mesa: A Memory-saving Training Framework for Transformers".
Mesa: A Memory-saving Training Framework for Transformers This is the official PyTorch implementation for Mesa: A Memory-saving Training Framework for
105 Dec 6, 2022
The pure and clear PyTorch Distributed Training Framework.
The pure and clear PyTorch Distributed Training Framework. Introduction Requirements and Usage Dependency Dataset Basic Usage Slurm Cluster Usage Base
 208 Dec 20, 2022
208 Dec 20, 2022
Scheme for training and applying a label propagation framework
Factorisation-based Image Labelling Overview This is a scheme for training and applying the factorisation-based image labelling (FIL) framework. Some
 2 Dec 17, 2021
2 Dec 17, 2021

A tutorial on training a DarkNet YOLOv4 model for the CrowdHuman dataset
YOLOv4 CrowdHuman Tutorial This is a tutorial demonstrating how to train a YOLOv4 people detector using Darknet and the CrowdHuman dataset. Table of c
 118 Nov 10, 2022
118 Nov 10, 2022
Code for "Training Neural Networks with Fixed Sparse Masks" (NeurIPS 2021).
Code for "Training Neural Networks with Fixed Sparse Masks" (NeurIPS 2021).
 7 Nov 22, 2021
7 Nov 22, 2021

Neural network graphs and training metrics for PyTorch, Tensorflow, and Keras.
HiddenLayer A lightweight library for neural network graphs and training metrics for PyTorch, Tensorflow, and Keras. HiddenLayer is simple, easy to ex
 1.7k Dec 31, 2022
1.7k Dec 31, 2022
SageMaker Python SDK is an open source library for training and deploying machine learning models on Amazon SageMaker.
SageMaker Python SDK SageMaker Python SDK is an open source library for training and deploying machine learning models on Amazon SageMaker. With the S
 1.8k Jan 1, 2023
1.8k Jan 1, 2023
Code for the paper "SmoothMix: Training Confidence-calibrated Smoothed Classifiers for Certified Robustness" (NeurIPS 2021)
SmoothMix: Training Confidence-calibrated Smoothed Classifiers for Certified Robustness (NeurIPS2021) This repository contains code for the paper "Smo
 17 Dec 27, 2022
17 Dec 27, 2022
Official PyTorch implementation for "Low Precision Decentralized Distributed Training with Heterogenous Data"
Low Precision Decentralized Training with Heterogenous Data Official PyTorch implementation for "Low Precision Decentralized Distributed Training with
 0 Nov 23, 2021
0 Nov 23, 2021
Code for "Training Neural Networks with Fixed Sparse Masks" (NeurIPS 2021).
Fisher Induced Sparse uncHanging (FISH) Mask This repo contains the code for Fisher Induced Sparse uncHanging (FISH) Mask training, from "Training Neu
37 Dec 30, 2022
Simulation code and tutorial for BBHnet training data
Simulation Dataset for BBHnet NOTE: OLD README, UPDATE IN PROGRESS We generate simulation dataset to train BBHnet, our deep learning framework for det
 0 May 31, 2022
0 May 31, 2022
Multi-modal Content Creation Model Training Infrastructure including the FACT model (AI Choreographer) implementation.
AI Choreographer: Music Conditioned 3D Dance Generation with AIST++ [ICCV-2021]. Overview This package contains the model implementation and training
 365 Dec 30, 2022
365 Dec 30, 2022
PyTorch Kafka Dataset: A definition of a dataset to get training data from Kafka.
PyTorch Kafka Dataset: A definition of a dataset to get training data from Kafka.
 7 Aug 1, 2022
7 Aug 1, 2022
Experimental code for paper: Generative Adversarial Networks as Variational Training of Energy Based Models
Experimental code for paper: Generative Adversarial Networks as Variational Training of Energy Based Models, under review at ICLR 2017 requirements: T
 18 Mar 5, 2022
18 Mar 5, 2022

RP-GAN: Stable GAN Training with Random Projections
RP-GAN: Stable GAN Training with Random Projections This repository contains a reference implementation of the algorithm described in the paper: Behna
 20 Sep 18, 2021
20 Sep 18, 2021
Code for training and evaluation of the model from "Language Generation with Recurrent Generative Adversarial Networks without Pre-training"
Language Generation with Recurrent Generative Adversarial Networks without Pre-training Code for training and evaluation of the model from "Language G
 253 Sep 14, 2022
253 Sep 14, 2022
A stable algorithm for GAN training
DRAGAN (Deep Regret Analytic Generative Adversarial Networks) Link to our paper - https://arxiv.org/abs/1705.07215 Pytorch implementation (thanks!) -
 195 Oct 10, 2022
195 Oct 10, 2022
Code for ICLR2018 paper: Improving GAN Training via Binarized Representation Entropy (BRE) Regularization - Y. Cao · W Ding · Y.C. Lui · R. Huang
code for "Improving GAN Training via Binarized Representation Entropy (BRE) Regularization" (ICLR2018 paper) paper: https://arxiv.org/abs/1805.03644 G
 21 Oct 12, 2020
21 Oct 12, 2020
Training, generation, and analysis code for Learning Particle Physics by Example: Location-Aware Generative Adversarial Networks for Physics
Location-Aware Generative Adversarial Networks (LAGAN) for Physics Synthesis This repository contains all the code used in L. de Oliveira (@lukedeo),
 57 Oct 22, 2022
57 Oct 22, 2022

TensorFlow implementation of "Learning from Simulated and Unsupervised Images through Adversarial Training"
Simulated+Unsupervised (S+U) Learning in TensorFlow TensorFlow implementation of Learning from Simulated and Unsupervised Images through Adversarial T
 569 Dec 29, 2022
569 Dec 29, 2022
Code for the paper "Improved Techniques for Training GANs"
Status: Archive (code is provided as-is, no updates expected) improved-gan code for the paper "Improved Techniques for Training GANs" MNIST, SVHN, CIF
 2.2k Jan 1, 2023
2.2k Jan 1, 2023

High performance distributed framework for training deep learning recommendation models based on PyTorch.
High performance distributed framework for training deep learning recommendation models based on PyTorch.
 340 Dec 30, 2022
340 Dec 30, 2022
CCQA A New Web-Scale Question Answering Dataset for Model Pre-Training
CCQA: A New Web-Scale Question Answering Dataset for Model Pre-Training This is the official repository for the code and models of the paper CCQA: A N
 29 Nov 30, 2022
29 Nov 30, 2022
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository will provide the official PyTorch implementa
 238 Nov 25, 2022
238 Nov 25, 2022
Iterative Training: Finding Binary Weight Deep Neural Networks with Layer Binarization
Iterative Training: Finding Binary Weight Deep Neural Networks with Layer Binarization This repository contains the source code for the paper (link wi
 0 Nov 19, 2021
0 Nov 19, 2021
Improving the robustness and performance of biomedical NLP models through adversarial training
RobustBioNLP Improving the robustness and performance of biomedical NLP models through adversarial training In this repository you can find suppliment
 3 Sep 20, 2022
3 Sep 20, 2022

TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning
TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning Authors: Yixuan Su, Fangyu Liu, Zaiqiao Meng, Lei Shu, Ehsan Shareghi, and Nig
 21 Nov 17, 2021
21 Nov 17, 2021
AdaNet is a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention
AdaNet is a lightweight TensorFlow-based framework for automatically learning high-quality models with minimal expert intervention. AdaNet buil
 3.4k Jan 7, 2023
3.4k Jan 7, 2023

BentoML is a flexible, high-performance framework for serving, managing, and deploying machine learning models.
Model Serving Made Easy BentoML is a flexible, high-performance framework for serving, managing, and deploying machine learning models. Supports multi
 4.4k Jan 4, 2023
4.4k Jan 4, 2023
🚪✊Knock Knock: Get notified when your training ends with only two additional lines of code
Knock Knock A small library to get a notification when your training is complete or when it crashes during the process with two additional lines of co
 2.5k Jan 7, 2023
2.5k Jan 7, 2023

Fast, modular reference implementation and easy training of Semantic Segmentation algorithms in PyTorch.
TorchSeg This project aims at providing a fast, modular reference implementation for semantic segmentation models using PyTorch. Highlights Modular De
 1.4k Jan 2, 2023
1.4k Jan 2, 2023

Training PSPNet in Tensorflow. Reproduce the performance from the paper.
Training Reproduce of PSPNet. (Updated 2021/04/09. Authors of PSPNet have provided a Pytorch implementation for PSPNet and their new work with support
 126 Jul 13, 2022
126 Jul 13, 2022

This code is a toolbox that uses Torch library for training and evaluating the ERFNet architecture for semantic segmentation.
ERFNet This code is a toolbox that uses Torch library for training and evaluating the ERFNet architecture for semantic segmentation. NEW!! New PyTorch
 104 Jan 5, 2023
104 Jan 5, 2023
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation.
ENet This work has been published in arXiv: ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. Packages: train contains too
 344 Nov 21, 2022
344 Nov 21, 2022

Chainer Implementation of Fully Convolutional Networks. (Training code to reproduce the original result is available.)
fcn - Fully Convolutional Networks Chainer implementation of Fully Convolutional Networks. Installation pip install fcn Inference Inference is done as
 218 Oct 27, 2022
218 Oct 27, 2022

Training BERT with Compute/Time (Academic) Budget
Training BERT with Compute/Time (Academic) Budget This repository contains scripts for pre-training and finetuning BERT-like models with limited time
 263 Jan 7, 2023
263 Jan 7, 2023

A Pytorch implementation of MoveNet from Google. Include training code and pre-train model.
Movenet.Pytorch Intro MoveNet is an ultra fast and accurate model that detects 17 keypoints of a body. This is A Pytorch implementation of MoveNet fro
 241 Dec 26, 2022
241 Dec 26, 2022
Single machine, multiple cards training; mix-precision training; DALI data loader.
Template Script Category Description Category script comparison script train.py, loader.py for single-machine-multiple-cards training train_DP.py, tra
 2 Jun 27, 2022
2 Jun 27, 2022
SAT: 2D Semantics Assisted Training for 3D Visual Grounding, ICCV 2021 (Oral)
SAT: 2D Semantics Assisted Training for 3D Visual Grounding SAT: 2D Semantics Assisted Training for 3D Visual Grounding by Zhengyuan Yang, Songyang Zh
 22 Nov 30, 2022
22 Nov 30, 2022

A Python training and inference implementation of Yolov5 helmet detection in Jetson Xavier nx and Jetson nano
yolov5-helmet-detection-python A Python implementation of Yolov5 to detect head or helmet in the wild in Jetson Xavier nx and Jetson nano. In Jetson X
 12 Dec 5, 2022
12 Dec 5, 2022
QAT(quantize aware training) for classification with MQBench
MQBench Quantization Aware Training with PyTorch I am using MQBench(Model Quantization Benchmark)(http://mqbench.tech/) to quantize the model for depl
 29 Nov 18, 2022
29 Nov 18, 2022
MQBench Quantization Aware Training with PyTorch
MQBench Quantization Aware Training with PyTorch I am using MQBench(Model Quantization Benchmark)(http://mqbench.tech/) to quantize the model for depl
29 Nov 18, 2022

Official Code Release for "TIP-Adapter: Training-free clIP-Adapter for Better Vision-Language Modeling"
Official Code Release for "TIP-Adapter: Training-free clIP-Adapter for Better Vision-Language Modeling" Pipeline of Tip-Adapter Tip-Adapter can provid
 187 Dec 28, 2022
187 Dec 28, 2022
TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning
TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning Authors: Yixuan Su, Fangyu Liu, Zaiqiao Meng, Lei Shu, Ehsan Shareghi, and Nig
79 Nov 4, 2022
TaCL: Improve BERT Pre-training with Token-aware Contrastive Learning
TaCL: Improve BERT Pre-training with Token-aware Contrastive Learning
26 Oct 17, 2022

Visualize the training curve from the *.csv file (tensorboard format).
Training-Curve-Vis Visualize the training curve from the *.csv file (tensorboard format). Feature Custom labels Curve smoothing Support for multiple c
 7 Feb 23, 2022
7 Feb 23, 2022
[ICCV 2021 Oral] Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Just Ask: Learning to Answer Questions from Millions of Narrated Videos Webpage • Demo • Paper This repository provides the code for our paper, includ
 87 Jan 5, 2023
87 Jan 5, 2023
![[ICCV' 21]](https://github.com/hansen7/OcCo/raw/master/assets/teaser.png)
[ICCV' 21] "Unsupervised Point Cloud Pre-training via Occlusion Completion"
OcCo: Unsupervised Point Cloud Pre-training via Occlusion Completion This repository is the official implementation of paper: "Unsupervised Point Clou
 204 Dec 24, 2022
204 Dec 24, 2022

Dataset and Code for the paper "DepthTrack: Unveiling the Power of RGBD Tracking" (ICCV2021), and "Depth-only Object Tracking" (BMVC2021)
DeT and DOT Code and datasets for "DepthTrack: Unveiling the Power of RGBD Tracking" (ICCV2021) "Depth-only Object Tracking" (BMVC2021) @InProceedings
 55 Dec 15, 2022
55 Dec 15, 2022

ICCV2021, Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet, ICCV 2021 Update: 2021/03/11: update our new results. Now our T2T-ViT-14 w
 1k Dec 31, 2022
1k Dec 31, 2022
A customisable game where you have to quickly click on black tiles in order of appearance while avoiding clicking on white squares.
W.I.P-Aim-Memory-Game A customisable game where you have to quickly click on black tiles in order of appearance while avoiding clicking on white squar
 1 Dec 8, 2021
1 Dec 8, 2021

Efficient Training of Audio Transformers with Patchout
PaSST: Efficient Training of Audio Transformers with Patchout This is the implementation for Efficient Training of Audio Transformers with Patchout Pa
 165 Dec 26, 2022
165 Dec 26, 2022

This is the implementation of the paper LiST: Lite Self-training Makes Efficient Few-shot Learners.
LiST (Lite Self-Training) This is the implementation of the paper LiST: Lite Self-training Makes Efficient Few-shot Learners. LiST is short for Lite S
 28 Dec 7, 2022
28 Dec 7, 2022
A Simple Framwork for CV Pre-training Model (SOCO, VirTex, BEiT)
A Simple Framwork for CV Pre-training Model (SOCO, VirTex, BEiT)
 14 Jul 7, 2022
14 Jul 7, 2022
Efficient Sharpness-aware Minimization for Improved Training of Neural Networks
Efficient Sharpness-aware Minimization for Improved Training of Neural Networks Code for “Efficient Sharpness-aware Minimization for Improved Training
 32 Oct 18, 2022
32 Oct 18, 2022
Code for EMNLP2021 paper "Allocating Large Vocabulary Capacity for Cross-lingual Language Model Pre-training"
VoCapXLM Code for EMNLP2021 paper Allocating Large Vocabulary Capacity for Cross-lingual Language Model Pre-training Environment DockerFile: dancingso
 15 Jul 28, 2022
15 Jul 28, 2022
The spiritual successor to knockknock for PyTorch Lightning, get notified when your training ends
Who's there? The spiritual successor to knockknock for PyTorch Lightning, to get a notification when your training is complete or when it crashes duri
 70 Oct 6, 2022
70 Oct 6, 2022
Revealing and Protecting Labels in Distributed Training
Revealing and Protecting Labels in Distributed Training
 0 Nov 9, 2022
0 Nov 9, 2022

training script for space time memory network
Trainig Script for Space Time Memory Network This codebase implemented training code for Space Time Memory Network with some cyclic features. Requirem
 100 Dec 20, 2022
100 Dec 20, 2022

Training Certifiably Robust Neural Networks with Efficient Local Lipschitz Bounds (Local-Lip)
Training Certifiably Robust Neural Networks with Efficient Local Lipschitz Bounds (Local-Lip) Introduction TL;DR: We propose an efficient and trainabl
 17 Dec 1, 2022
17 Dec 1, 2022

This codebase facilitates fast experimentation of differentially private training of Hugging Face transformers.
private-transformers This codebase facilitates fast experimentation of differentially private training of Hugging Face transformers. What is this? Why
 73 Dec 28, 2022
73 Dec 28, 2022
Enhancing Knowledge Tracing via Adversarial Training
Enhancing Knowledge Tracing via Adversarial Training This repository contains source code for the paper "Enhancing Knowledge Tracing via Adversarial T
 14 Oct 24, 2022
14 Oct 24, 2022

SEC'21: Sparse Bitmap Compression for Memory-Efficient Training onthe Edge
Training Deep Learning Models on The Edge Training on the Edge enables continuous learning from new data for deployed neural networks on memory-constr
 4 Nov 18, 2022
4 Nov 18, 2022

Implementation of average- and worst-case robust flatness measures for adversarial training.
Relating Adversarially Robust Generalization to Flat Minima This repository contains code corresponding to the MLSys'21 paper: D. Stutz, M. Hein, B. S
 13 Nov 27, 2022
13 Nov 27, 2022

A complete end-to-end machine learning portal that covers processes starting from model training to the model predicting results using FastAPI.
Machine Learning Portal Goal Application Workflow Process Design Live Project Goal A complete end-to-end machine learning portal that covers processes
 39 Nov 24, 2022
39 Nov 24, 2022
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
 1.6k Jan 3, 2023
1.6k Jan 3, 2023

Open source single image super-resolution toolbox containing various functionality for training a diverse number of state-of-the-art super-resolution models. Also acts as the companion code for the IEEE signal processing letters paper titled 'Improving Super-Resolution Performance using Meta-Attention Layers’.
Deep-FIR Codebase - Super Resolution Meta Attention Networks About This repository contains the main coding framework accompanying our work on meta-at
 17 Jun 17, 2022
17 Jun 17, 2022
Implementation for On Provable Benefits of Depth in Training Graph Convolutional Networks
Implementation for On Provable Benefits of Depth in Training Graph Convolutional Networks Setup This implementation is based on PyTorch = 1.0.0. Smal
 8 Oct 28, 2022
8 Oct 28, 2022
Colossal-AI: A Unified Deep Learning System for Large-Scale Parallel Training
ColossalAI An integrated large-scale model training system with efficient parallelization techniques. arXiv: Colossal-AI: A Unified Deep Learning Syst
 7.9k Jan 8, 2023
7.9k Jan 8, 2023
Data, model training, and evaluation code for "PubTables-1M: Towards a universal dataset and metrics for training and evaluating table extraction models".
PubTables-1M This repository contains training and evaluation code for the paper "PubTables-1M: Towards a universal dataset and metrics for training a
365 Jan 4, 2023
Predicting lncRNA–protein interactions based on graph autoencoders and collaborative training
Predicting lncRNA–protein interactions based on graph autoencoders and collaborative training Code for our paper "Predicting lncRNA–protein interactio
 1 Nov 29, 2022
1 Nov 29, 2022
Colossal-AI: A Unified Deep Learning System for Large-Scale Parallel Training
ColossalAI An integrated large-scale model training system with efficient parallelization techniques Installation PyPI pip install colossalai Install
7.1k Jan 3, 2023

AugMax: Adversarial Composition of Random Augmentations for Robust Training
[NeurIPS'21] "AugMax: Adversarial Composition of Random Augmentations for Robust Training" by Haotao Wang, Chaowei Xiao, Jean Kossaifi, Zhiding Yu, Animashree Anandkumar, and Zhangyang Wang.
 31 Oct 28, 2021
31 Oct 28, 2021
Exponential Graph is Provably Efficient for Decentralized Deep Training
Exponential Graph is Provably Efficient for Decentralized Deep Training This code repository is for the paper Exponential Graph is Provably Efficient
 3 Apr 20, 2022
3 Apr 20, 2022
[NeurIPS'21] "AugMax: Adversarial Composition of Random Augmentations for Robust Training" by Haotao Wang, Chaowei Xiao, Jean Kossaifi, Zhiding Yu, Animashree Anandkumar, and Zhangyang Wang.
AugMax: Adversarial Composition of Random Augmentations for Robust Training Haotao Wang, Chaowei Xiao, Jean Kossaifi, Zhiding Yu, Anima Anandkumar, an
112 Nov 7, 2022

In this project I played with mlflow, streamlit and fastapi to create a training and prediction app on digits
Fastapi + MLflow + streamlit Setup env. I hope I covered all. pip install -r requirements.txt Start app Go in the root dir and run these Streamlit str
 76 Nov 23, 2022
76 Nov 23, 2022

Asterisk is a framework to generate high-quality training datasets at scale
Asterisk is a framework to generate high-quality training datasets at scale
 44 Apr 25, 2022
44 Apr 25, 2022
![[NeurIPS 2021] Better Safe Than Sorry: Preventing Delusive Adversaries with Adversarial Training](https://github.com/TLMichael/Delusive-Adversary/raw/main/fig/Thumbnail.png)
[NeurIPS 2021] Better Safe Than Sorry: Preventing Delusive Adversaries with Adversarial Training
Better Safe Than Sorry: Preventing Delusive Adversaries with Adversarial Training Code for NeurIPS 2021 paper "Better Safe Than Sorry: Preventing Delu
 29 Sep 20, 2022
29 Sep 20, 2022

code for generating data set ES-ImageNet with corresponding training code
es-imagenet-master code for generating data set ES-ImageNet with corresponding training code dataset generator some codes of ODG algorithm The variabl
 18 Dec 25, 2022
18 Dec 25, 2022

A Context-aware Visual Attention-based training pipeline for Object Detection from a Webpage screenshot!
CoVA: Context-aware Visual Attention for Webpage Information Extraction Abstract Webpage information extraction (WIE) is an important step to create k
 41 Jan 1, 2023
41 Jan 1, 2023
Code for the prototype tool in our paper "CoProtector: Protect Open-Source Code against Unauthorized Training Usage with Data Poisoning".
CoProtector Code for the prototype tool in our paper "CoProtector: Protect Open-Source Code against Unauthorized Training Usage with Data Poisoning".
 1 Oct 26, 2021
1 Oct 26, 2021
Code for the prototype tool in our paper "CoProtector: Protect Open-Source Code against Unauthorized Training Usage with Data Poisoning".
CoProtector Code for the prototype tool in our paper "CoProtector: Protect Open-Source Code against Unauthorized Training Usage with Data Poisoning".
1 Oct 26, 2021
This is the official source code for SLATE. We provide the code for the model, the training code, and a dataset loader for the 3D Shapes dataset. This code is implemented in Pytorch.
SLATE This is the official source code for SLATE. We provide the code for the model, the training code and a dataset loader for the 3D Shapes dataset.
 66 Dec 26, 2022
66 Dec 26, 2022

PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Cross-Speaker-Emotion-Transfer - PyTorch Implementation PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Conditio
 114 Jan 8, 2023
114 Jan 8, 2023
PyTorch Code for NeurIPS 2021 paper Anti-Backdoor Learning: Training Clean Models on Poisoned Data.
Anti-Backdoor Learning PyTorch Code for NeurIPS 2021 paper Anti-Backdoor Learning: Training Clean Models on Poisoned Data. Check the unlearning effect
 51 Dec 7, 2022
51 Dec 7, 2022

Efficient Training of Visual Transformers with Small Datasets
Official codes for "Efficient Training of Visual Transformers with Small Datasets", NerIPS 2021.
 112 Dec 25, 2022
112 Dec 25, 2022
Training Very Deep Neural Networks Without Skip-Connections
DiracNets v2 update (January 2018): The code was updated for DiracNets-v2 in which we removed NCReLU by adding per-channel a and b multipliers without
 585 Oct 12, 2022
585 Oct 12, 2022
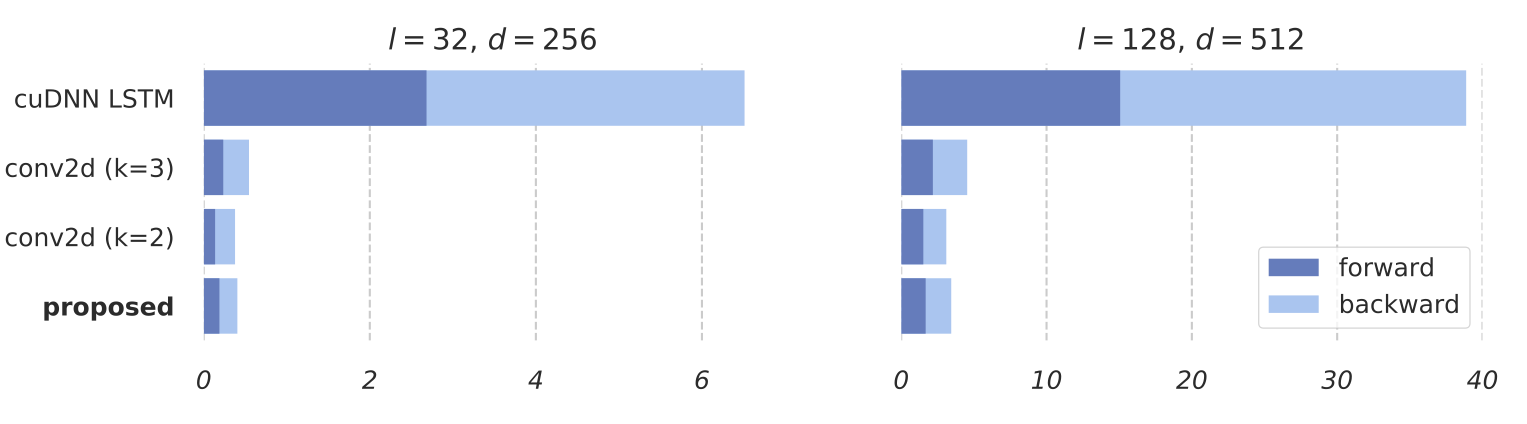
Training RNNs as Fast as CNNs
News SRU++, a new SRU variant, is released. [tech report] [blog] The experimental code and SRU++ implementation are available on the dev branch which
 14 Dec 12, 2022
14 Dec 12, 2022
CVNets: A library for training computer vision networks
CVNets: A library for training computer vision networks This repository contains the source code for training computer vision models. Specifically, it
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
BERT model training impelmentation using 1024 A100 GPUs for MLPerf Training v1.1
Pre-trained checkpoint and bert config json file Location of checkpoint and bert config json file This MLCommons members Google Drive location contain
 12 Apr 27, 2022
12 Apr 27, 2022

A SageMaker Projects template to deploy a model from Model Registry, choosing your preferred method of deployment among async (Asynchronous Inference), batch (Batch Transform), realtime (Real-time Inference Endpoint). More to be added soon!
SageMaker Projects: Multiple Choice Deployment A SageMaker Projects template to deploy a model from Model Registry, choosing your preferred method of
 3 Dec 21, 2021
3 Dec 21, 2021
For auto aligning, cropping, and scaling HR and LR images for training image based neural networks
ImgAlign For auto aligning, cropping, and scaling HR and LR images for training image based neural networks Usage Make sure OpenCV is installed, 'pip
 15 Dec 4, 2022
15 Dec 4, 2022