449 Repositories
Python speech-annotation Libraries
This program uses trial auth token of Azure Cognitive Services to do speech synthesis for you.
🗣️ aspeak A simple text-to-speech client using azure TTS API(trial). 😆 TL;DR: This program uses trial auth token of Azure Cognitive Services to do s
 359 Jan 5, 2023
359 Jan 5, 2023

BDDM: Bilateral Denoising Diffusion Models for Fast and High-Quality Speech Synthesis
Bilateral Denoising Diffusion Models (BDDMs) This is the official PyTorch implementation of the following paper: BDDM: BILATERAL DENOISING DIFFUSION M
 172 Dec 23, 2022
172 Dec 23, 2022
🐤 Nix-TTS: An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation
🐤 Nix-TTS An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation Rendi Chevi, Radityo Eko Prasojo, Alham Fikri Aji
 156 Jan 9, 2023
156 Jan 9, 2023

HiFi++: a Unified Framework for Neural Vocoding, Bandwidth Extension and Speech Enhancement
HiFi++ : a Unified Framework for Neural Vocoding, Bandwidth Extension and Speech Enhancement This is the unofficial implementation of Vocoder part of
 118 Dec 29, 2022
118 Dec 29, 2022

A annotation of yolov5-5.0
代码版本:0714 commit #4000 $ git clone https://github.com/ultralytics/yolov5 $ cd yolov5 $ git checkout 720aaa65c8873c0d87df09e3c1c14f3581d4ea61 这个代码只是注释版
 229 Dec 17, 2022
229 Dec 17, 2022

Comprehensive-E2E-TTS - PyTorch Implementation
A Non-Autoregressive End-to-End Text-to-Speech (text-to-wav), supporting a family of SOTA unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate E2E-TTS
 114 Nov 13, 2022
114 Nov 13, 2022
Finally, some decent sample sentences
tts-dataset-prompts This repository aims to be a decent set of sentences for people looking to clone their own voices (e.g. using Tacotron 2). Each se
 19 Dec 13, 2022
19 Dec 13, 2022
Multi-Scale Temporal Frequency Convolutional Network With Axial Attention for Speech Enhancement
MTFAA-Net Unofficial PyTorch implementation of Baidu's MTFAA-Net: "Multi-Scale Temporal Frequency Convolutional Network With Axial Attention for Speec
 87 Dec 19, 2022
87 Dec 19, 2022
HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools
HuggingSound HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools. I have no intention of building a very complex tool here.
 247 Dec 26, 2022
247 Dec 26, 2022

Evaluation and Benchmarking of Speech Super-resolution Methods
Speech Super-resolution Evaluation and Benchmarking What this repo do: A toolbox for the evaluation of speech super-resolution algorithms. Unify the e
 84 Dec 20, 2022
84 Dec 20, 2022

PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI
data2vec-pytorch PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI (F
 105 Jan 4, 2023
105 Jan 4, 2023
HF's ML for Audio study group
Hugging Face Machine Learning for Audio Study Group Welcome to the ML for Audio Study Group. Through a series of presentations, paper reading and disc
 110 Jan 1, 2023
110 Jan 1, 2023

APEACH: Attacking Pejorative Expressions with Analysis on Crowd-generated Hate Speech Evaluation Datasets
APEACH - Korean Hate Speech Evaluation Datasets APEACH is the first crowd-generated Korean evaluation dataset for hate speech detection. Sentences of
 70 Dec 6, 2022
70 Dec 6, 2022

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
 87 Dec 21, 2022
87 Dec 21, 2022

iSTFTNet : Fast and Lightweight Mel-spectrogram Vocoder Incorporating Inverse Short-time Fourier Transform
iSTFTNet : Fast and Lightweight Mel-spectrogram Vocoder Incorporating Inverse Short-time Fourier Transform This repo try to implement iSTFTNet : Fast
126 Jan 2, 2023
SelfRemaster: SSL Speech Restoration
SelfRemaster: Self-Supervised Speech Restoration Official implementation of SelfRemaster: Self-Supervised Speech Restoration with Analysis-by-Synthesi
 46 Jan 7, 2023
46 Jan 7, 2023

LightHuBERT: Lightweight and Configurable Speech Representation Learning with Once-for-All Hidden-Unit BERT
LightHuBERT LightHuBERT: Lightweight and Configurable Speech Representation Learning with Once-for-All Hidden-Unit BERT | Github | Huggingface | SUPER
 46 Dec 29, 2022
46 Dec 29, 2022

The implementation of "Optimizing Shoulder to Shoulder: A Coordinated Sub-Band Fusion Model for Real-Time Full-Band Speech Enhancement"
SF-Net for fullband SE This is the repo of the manuscript "Optimizing Shoulder to Shoulder: A Coordinated Sub-Band Fusion Model for Real-Time Full-Ban
 36 Dec 2, 2022
36 Dec 2, 2022

Repository for fine-tuning Transformers 🤗 based seq2seq speech models in JAX/Flax.
Seq2Seq Speech in JAX A JAX/Flax repository for combining a pre-trained speech encoder model (e.g. Wav2Vec2, HuBERT, WavLM) with a pre-trained text de
 21 Dec 14, 2022
21 Dec 14, 2022
"Video Moment Retrieval from Text Queries via Single Frame Annotation" in SIGIR 2022.
ViGA: Video moment retrieval via Glance Annotation This is the official repository of the paper "Video Moment Retrieval from Text Queries via Single F
 38 Dec 31, 2022
38 Dec 31, 2022
![[ICRA 2022] CaTGrasp: Learning Category-Level Task-Relevant Grasping in Clutter from Simulation](https://github.com/wenbowen123/catgrasp/raw/master/media/intro.jpg)
[ICRA 2022] CaTGrasp: Learning Category-Level Task-Relevant Grasping in Clutter from Simulation
This is the official implementation of our paper: Bowen Wen, Wenzhao Lian, Kostas Bekris, and Stefan Schaal. "CaTGrasp: Learning Category-Level Task-R
 199 Jan 4, 2023
199 Jan 4, 2023
Code for ACL 2022 main conference paper "STEMM: Self-learning with Speech-text Manifold Mixup for Speech Translation".
STEMM: Self-learning with Speech-Text Manifold Mixup for Speech Translation This is a PyTorch implementation for the ACL 2022 main conference paper ST
 29 Oct 16, 2022
29 Oct 16, 2022
3D Avatar Lip Syncronization from speech (JALI based face-rigging)
visemenet-inference Inference Demo of "VisemeNet-tensorflow" VisemeNet is an audio-driven animator centric speech animation driving a JALI or standard
 17 Dec 20, 2022
17 Dec 20, 2022

Vad-sli-asr - A Python scripts for a speech processing pipeline with Voice Activity Detection (VAD)
VAD-SLI-ASR Python scripts for a speech processing pipeline with Voice Activity
 14 Dec 9, 2022
14 Dec 9, 2022

PyTorch Implementation of DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
DiffGAN-TTS - PyTorch Implementation PyTorch implementation of DiffGAN-TTS: High
157 Jan 1, 2023

SHAS: Approaching optimal Segmentation for End-to-End Speech Translation
SHAS: Approaching optimal Segmentation for End-to-End Speech Translation In this repo you can find the code of the Supervised Hybrid Audio Segmentatio
 21 Dec 20, 2022
21 Dec 20, 2022
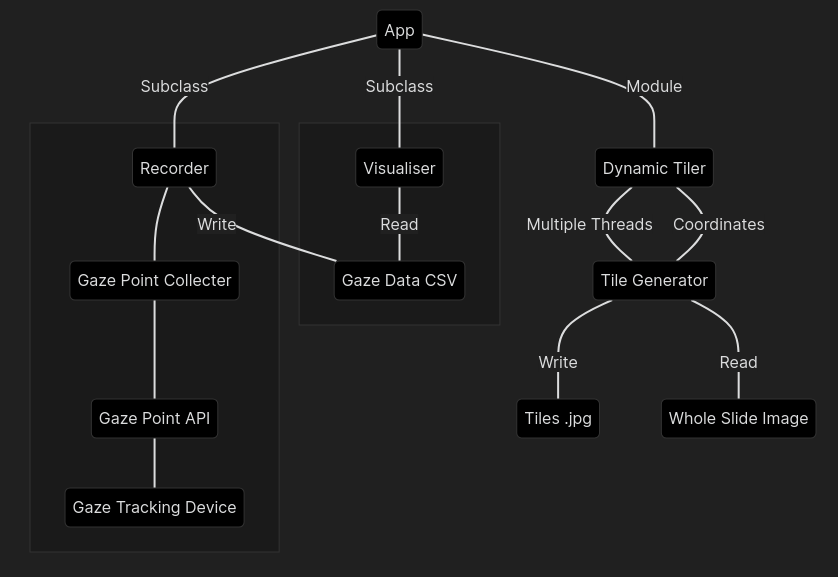
VISNOTATE: An Opensource tool for Gaze-based Annotation of WSI Data
VISNOTATE: An Opensource tool for Gaze-based Annotation of WSI Data Introduction Requirements Installation and Setup Supported Hardware and Software R
 1 Jun 14, 2022
1 Jun 14, 2022
PyTorch implementation of NATSpeech: A Non-Autoregressive Text-to-Speech Framework
A Non-Autoregressive Text-to-Speech (NAR-TTS) framework, including official PyTorch implementation of PortaSpeech (NeurIPS 2021) and DiffSpeech (AAAI 2022)
 760 Jan 3, 2023
760 Jan 3, 2023
Convert PDF to AudioBook and Audio Speech to PDF
In this Python project, we will build a GUI-based PDF to Audio and Audio to PDF converter using the Tkinter, OS, path, pyttsx3, SpeechRecognition, PyPDF4, and Pydub libraries and the messagebox module of the Tkinter library.
 1 Feb 13, 2022
1 Feb 13, 2022
Speech Recognition is an important feature in several applications used such as home automation, artificial intelligence
Speech Recognition is an important feature in several applications used such as home automation, artificial intelligence, etc. This article aims to provide an introduction on how to make use of the SpeechRecognition and pyttsx3 library of Python.
1 Feb 13, 2022
A pure PyTorch batched computation implementation of "CIF: Continuous Integrate-and-Fire for End-to-End Speech Recognition"
A pure PyTorch batched computation implementation of "CIF: Continuous Integrate-and-Fire for End-to-End Speech Recognition"
 14 Dec 2, 2022
14 Dec 2, 2022
Crowd-Kit is a powerful Python library that implements commonly-used aggregation methods for crowdsourced annotation and offers the relevant metrics and datasets
Crowd-Kit: Computational Quality Control for Crowdsourcing Documentation Crowd-Kit is a powerful Python library that implements commonly-used aggregat
 125 Dec 30, 2022
125 Dec 30, 2022
HGCN: Harmonic Gated Compensation Network For Speech Enhancement
HGCN The official repo of "HGCN: Harmonic Gated Compensation Network For Speech Enhancement", which was accepted at ICASSP2022. How to use step1: Calc
 33 Nov 14, 2022
33 Nov 14, 2022
An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright.
Playwright nonoCAPTCHA An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright. Disclaimer This project is for educational
 69 Dec 28, 2022
69 Dec 28, 2022
Speech Emotion Recognition with Fusion of Acoustic- and Linguistic-Feature-Based Decisions
APSIPA-SER-with-A-and-T This code is the implementation of Speech Emotion Recognition (SER) with acoustic and linguistic features. The network model i
 3 Jan 4, 2023
3 Jan 4, 2023
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
 0 Feb 8, 2022
0 Feb 8, 2022

Implementation of the method described in the Speech Resynthesis from Discrete Disentangled Self-Supervised Representations.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations Implementation of the method described in the Speech Resynthesis from Di
 4 Mar 11, 2022
4 Mar 11, 2022
TFPNER: Exploration on the Named Entity Recognition of Token Fused with Part-of-Speech
TFPNER TFPNER: Exploration on the Named Entity Recognition of Token Fused with Part-of-Speech Named entity recognition (NER), which aims at identifyin
 1 Feb 7, 2022
1 Feb 7, 2022
Application to help find best train itinerary, uses speech to text, has a spam filter to segregate invalid inputs, NLP and Pathfinding algos.
T-IAI-901-MSC2022 - GROUP 18 Gestion de projet Notre travail a été organisé et réparti dans un Trello. https://trello.com/b/X3s2fpPJ/ia-projet Install
 1 Feb 5, 2022
1 Feb 5, 2022
Extract longest transcript or longest CDS transcript from GTF annotation file or gencode transcripts fasta file.
Extract longest transcript or longest CDS transcript from GTF annotation file or gencode transcripts fasta file.
 13 Nov 23, 2022
13 Nov 23, 2022
Javascript image annotation tool based on image segmentation.
JS Segment Annotator Javascript image annotation tool based on image segmentation. Label image regions with mouse. Written in vanilla Javascript, with
 513 Nov 15, 2022
513 Nov 15, 2022
LabelMe annotation tool source code
LabelMe annotation tool source code Here you will find the source code to install the LabelMe annotation tool on your server. LabelMe is an annotation
 1.3k Jan 3, 2023
1.3k Jan 3, 2023
A voice control utility for Spotify
Spotify Voice Control A voice control utility for Spotify · Report Bug · Request
 27 Jan 1, 2023
27 Jan 1, 2023
Creating an Audiobook (mp3 file) using a Ebook (epub) using BeautifulSoup and Google Text to Speech
epub2audiobook Creating an Audiobook (mp3 file) using a Ebook (epub) using BeautifulSoup and Google Text to Speech Input examples qual a pasta do seu
 7 Aug 25, 2022
7 Aug 25, 2022
Pytorch Implementation of Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
NANSY: Unofficial Pytorch Implementation of Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations Notice Papers' D
 104 Dec 23, 2022
104 Dec 23, 2022
Tensorflow Implementation of A Generative Flow for Text-to-Speech via Monotonic Alignment Search
Tensorflow Implementation of A Generative Flow for Text-to-Speech via Monotonic Alignment Search
 10 Oct 13, 2022
10 Oct 13, 2022
WikiPron - a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary
WikiPron WikiPron is a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary, as well as a database of pronuncia
 213 Jan 1, 2023
213 Jan 1, 2023
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques This repository is derived from the NMTGMinor
 1 Sep 7, 2022
1 Sep 7, 2022
Code for the paper titled "Prabhupadavani: A Code-mixed Speech Translation Data for 25 languages"
Prabhupadavani: A Code-mixed Speech Translation Data for 25 languages Code for the paper titled "Prabhupadavani: A Code-mixed Speech Translation Data
 12 Dec 1, 2022
12 Dec 1, 2022

LabelImg is a graphical image annotation tool.
LabelImgPlus LabelImg is a graphical image annotation tool. This project is not updated with new functions now. More functions are supported with Labe
 200 Dec 20, 2022
200 Dec 20, 2022

Labelme is a graphical image annotation tool, It is written in Python and uses Qt for its graphical interface
Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).
 9.6k Jan 9, 2023
9.6k Jan 9, 2023
Election Exit Poll Prediction and U.S.A Presidential Speech Analysis using Machine Learning
Machine_Learning Election Exit Poll Prediction and U.S.A Presidential Speech Analysis using Machine Learning This project is based on 2 case-studies:
 1 Jan 27, 2022
1 Jan 27, 2022
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
TweebankNLP This repo contains the new Tweebank-NER dataset and off-the-shelf Twitter-Stanza pipeline for state-of-the-art Tweet NLP, as described in
 42 Jan 26, 2022
42 Jan 26, 2022

This is the repo of the manuscript "Dual-branch Attention-In-Attention Transformer for speech enhancement"
DB-AIAT: A Dual-branch attention-in-attention transformer for single-channel SE
68 Dec 16, 2022
Labelbox is the fastest way to annotate data to build and ship artificial intelligence applications
Labelbox Labelbox is the fastest way to annotate data to build and ship artificial intelligence applications. Use this github repository to help you s
 1.7k Dec 29, 2022
1.7k Dec 29, 2022

CVAT is free, online, interactive video and image annotation tool for computer vision
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 4, 2023
8.6k Jan 4, 2023
Some utils for auto speech recognition
About Some utils for auto speech recognition. Utils Util Description Script Reset audio Reset sample rate, sample width, etc of audios.
 1 Jan 24, 2022
1 Jan 24, 2022
Simple Text-To-Speech Bot For Discord
Simple Text-To-Speech Bot For Discord This is a very simple TTS bot for discord made with python. For this bot you need FFMPEG, see installation to se
 1 Sep 26, 2022
1 Sep 26, 2022

A real-time speech emotion recognition application using Scikit-learn and gradio
Speech-Emotion-Recognition-App A real-time speech emotion recognition application using Scikit-learn and gradio. Requirements librosa==0.6.3 numpy sou
 6 Oct 4, 2022
6 Oct 4, 2022
A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk.
Simple-Vosk A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk. Check out the official Vosk G
 2 Jun 19, 2022
2 Jun 19, 2022
TweebankNLP - Pre-trained Tweet NLP Pipeline (NER, tokenization, lemmatization, POS tagging, dependency parsing) + Models + Tweebank-NER
TweebankNLP This repo contains the new Tweebank-NER dataset and Twitter-Stanza p
84 Dec 20, 2022

TCNN Temporal convolutional neural network for real-time speech enhancement in the time domain
TCNN Pandey A, Wang D L. TCNN: Temporal convolutional neural network for real-time speech enhancement in the time domain[C]//ICASSP 2019-2019 IEEE Int
 16 Dec 30, 2022
16 Dec 30, 2022
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus CVSS is a massively multilingual-to-English speech-to-speech translation corpus, co
 26 Jan 16, 2022
26 Jan 16, 2022

ObjectDrawer-ToolBox: a graphical image annotation tool to generate ground plane masks for a 3D object reconstruction system
ObjectDrawer-ToolBox is a graphical image annotation tool to generate ground plane masks for a 3D object reconstruction system, Object Drawer.
 77 Jan 5, 2023
77 Jan 5, 2023
A python package to perform same transformation to coco-annotation as performed on the image.
coco-transform-util A python package to perform same transformation to coco-annotation as performed on the image. Installation Way 1 $ git clone https
 1 Jan 14, 2022
1 Jan 14, 2022
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus CVSS is a massively multilingual-to-English speech-to-speech translation corpus, co
118 Jan 6, 2023

I-Spy is a discord and twitter bot 🤖 that keeps a check on usage foul language, hate-speech and NSFW contents
I-Spy is a discord and twitter bot 🤖 that keeps a check on usage foul language, hate-speech and NSFW contents. It is the one stop solution to monitor your discord servers and twitter handles against community demons by offering content moderation.
 5 Nov 16, 2022
5 Nov 16, 2022

PyTorch implementation of Lip to Speech Synthesis with Visual Context Attentional GAN (NeurIPS2021)
Lip to Speech Synthesis with Visual Context Attentional GAN This repository contains the PyTorch implementation of the following paper: Lip to Speech
 6 Nov 2, 2022
6 Nov 2, 2022

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022

Fancy console logger and wise assistant within your python projects
Fancy console logger and wise assistant within your python projects. Made to save tons of hours for common routines.
 5 Apr 1, 2022
5 Apr 1, 2022
Implementation of paper "DCS-Net: Deep Complex Subtractive Neural Network for Monaural Speech Enhancement"
DCS-Net This is the implementation of "DCS-Net: Deep Complex Subtractive Neural Network for Monaural Speech Enhancement" Steps to run the model Edit V
 10 Apr 4, 2022
10 Apr 4, 2022
End-to-end speech secognition toolkit
End-to-end speech secognition toolkit This is an E2E ASR toolkit modified from Espnet1 (version 0.9.9). This is the official implementation of paper:
 147 Dec 28, 2022
147 Dec 28, 2022

Speech Recognition Database Management with python
Speech Recognition Database Management The main aim of this project is to recogn
 2 Feb 2, 2022
2 Feb 2, 2022
Time series annotation library.
CrowdCurio Time Series Annotator Library The CrowdCurio Time Series Annotation Library implements classification tasks for time series. Features Suppo
 51 Sep 15, 2022
51 Sep 15, 2022

The Wearables Development Toolkit - a development environment for activity recognition applications with sensor signals
Wearables Development Toolkit (WDK) The Wearables Development Toolkit (WDK) is a framework and set of tools to facilitate the iterative development of
 114 Nov 27, 2022
114 Nov 27, 2022

Speech to text streamlit app
Speech to text Streamlit-app! 👄 This speech to text recognition is powered by t
 9 Jan 1, 2023
9 Jan 1, 2023
Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi.
Spchcat Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi. Description spchcat is a command-line tool that read
 279 Jan 3, 2023
279 Jan 3, 2023

A self-supervised learning framework for audio-visual speech
AV-HuBERT (Audio-Visual Hidden Unit BERT) Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction Robust Self-Supervised A
431 Jan 7, 2023

The official code for the ICCV-2021 paper "Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates".
SpeechDrivesTemplates The official repo for the ICCV-2021 paper "Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates". [arxiv
 53 Dec 23, 2022
53 Dec 23, 2022

Graphical Password Authentication System.
Graphical Password Authentication System. This is used to increase the protection/security of a website. Our system is divided into further 4 layers of protection. Each layer is totally different and diverse than the others. This not only increases protection, but also makes sure that no non-human can log in to your account using different activities such as Brute Force Algorithm and so on.
 12 Dec 16, 2022
12 Dec 16, 2022
ConferencingSpeech2022; Non-intrusive Objective Speech Quality Assessment (NISQA) Challenge
ConferencingSpeech 2022 challenge This repository contains the datasets list and scripts required for the ConferencingSpeech 2022 challenge. For more
 21 Dec 2, 2022
21 Dec 2, 2022

Automagically synchronize subtitles with video.
FFsubsync Language-agnostic automatic synchronization of subtitles with video, so that subtitles are aligned to the correct starting point within the
 5.7k Jan 6, 2023
5.7k Jan 6, 2023

👑 spaCy building blocks and visualizers for Streamlit apps
spacy-streamlit: spaCy building blocks for Streamlit apps This package contains utilities for visualizing spaCy models and building interactive spaCy-
 620 Dec 29, 2022
620 Dec 29, 2022
Do you like Quick, Draw? Well what if you could train/predict doodles drawn inside Streamlit? Also draws lines, circles and boxes over background images for annotation.
Streamlit - Drawable Canvas Streamlit component which provides a sketching canvas using Fabric.js. Features Draw freely, lines, circles, boxes and pol
 325 Dec 28, 2022
325 Dec 28, 2022
Asr abc - Automatic speech recognition(ASR),中文语音识别
语音识别的简单示例,主要在课堂演示使用 创建python虚拟环境 在linux 和macos 上验证通过 # 如果已经有pyhon3.6 环境,跳过该步骤,使用
 8 Nov 11, 2022
8 Nov 11, 2022
DeepSpeech - Easy-to-use Speech Toolkit including SOTA ASR pipeline, influential TTS with text frontend and End-to-End Speech Simultaneous Translation.
(简体中文|English) Quick Start | Documents | Models List PaddleSpeech is an open-source toolkit on PaddlePaddle platform for a variety of critical tasks i
 5.6k Jan 3, 2023
5.6k Jan 3, 2023

Amazing-Python-Scripts - 🚀 Curated collection of Amazing Python scripts from Basics to Advance with automation task scripts.
📑 Introduction A curated collection of Amazing Python scripts from Basics to Advance with automation task scripts. This is your Personal space to fin
 1.1k Dec 29, 2022
1.1k Dec 29, 2022

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

VQMIVC - Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion (Interspeech
 262 Dec 31, 2022
262 Dec 31, 2022

SpecAugmentPyTorch - A Pytorch (support batch and channel) implementation of GoogleBrain's SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
SpecAugment An implementation of SpecAugment for Pytorch How to use Install pytorch, version=1.9.0 (new feature (torch.Tensor.take_along_dim) is used
 3 Oct 11, 2022
3 Oct 11, 2022

The codebase for Data-driven general-purpose voice activity detection.
Data driven GPVAD Repository for the work in TASLP 2021 Voice activity detection in the wild: A data-driven approach using teacher-student training. S
 75 Nov 27, 2022
75 Nov 27, 2022
基于百度的语音识别,用python实现,pyaudio+pyqt
Speech-recognition 基于百度的语音识别,python3.8(conda)+pyaudio+pyqt+baidu-aip 百度有面向python
 1 Jan 3, 2022
1 Jan 3, 2022

This project aim to create multi-label classification annotation tool to boost annotation speed and make it more easier.
This project aim to create multi-label classification annotation tool to boost annotation speed and make it more easier.
 4 Aug 2, 2022
4 Aug 2, 2022
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022
Autoregressive Predictive Coding: An unsupervised autoregressive model for speech representation learning
Autoregressive Predictive Coding This repository contains the official implementation (in PyTorch) of Autoregressive Predictive Coding (APC) proposed
 173 Dec 18, 2022
173 Dec 18, 2022
Robust, highly tunable and easy-to-integrate in-memory cache solution written in pure Python, with no dependencies.
Omoide Cache Caching doesn't need to be hard anymore. With just a few lines of code Omoide Cache will instantly bring your Python services to the next
 2 Aug 14, 2022
2 Aug 14, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 1.1k Jan 2, 2023
1.1k Jan 2, 2023

🚀Clone a voice in 5 seconds to generate arbitrary speech in real-time
English | 中文 Features 🌍 Chinese supported mandarin and tested with multiple datasets: aidatatang_200zh, magicdata, aishell3, data_aishell, and etc. ?
 25.6k Dec 31, 2022
25.6k Dec 31, 2022

Retrieve annotated intron sequences and classify them as minor (U12-type) or major (U2-type)
(intron I nterrogator and C lassifier) intronIC is a program that can be used to classify intron sequences as minor (U12-type) or major (U2-type), usi
 4 Jul 26, 2022
4 Jul 26, 2022
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger In this project, our aim is to tune, compare, and contrast the perf
 0 Dec 25, 2021
0 Dec 25, 2021