224 Repositories
Python stt-benchmark Libraries
GNN-based Recommendation Benchmark
GRecX A Fair Benchmark for GNN-based Recommendation Homepage and Documentation Homepage: Documentation: Paper: GRecX: An Efficient and Unified Benchma
 73 Oct 17, 2022
73 Oct 17, 2022
Repository for the electrical and ICT benchmark model developed in the ERIGrid 2.0 project.
Benchmark Model Electrical and ICT System This repository contains the documentation, code, and models for the electrical and ICT benchmark model deve
 1 Nov 29, 2021
1 Nov 29, 2021

A benchmark of data-centric tasks from across the machine learning lifecycle.
A benchmark of data-centric tasks from across the machine learning lifecycle.
 61 Dec 28, 2022
61 Dec 28, 2022
Natural Intelligence is still a pretty good idea.
Human Learn Machine Learning models should play by the rules, literally. Project Goal Back in the old days, it was common to write rule-based systems.
 641 Dec 26, 2022
641 Dec 26, 2022

This is a tensorflow-based rotation detection benchmark, also called AlphaRotate.
AlphaRotate: A Rotation Detection Benchmark using TensorFlow Abstract AlphaRotate is maintained by Xue Yang with Shanghai Jiao Tong University supervi
 972 Jan 5, 2023
972 Jan 5, 2023

This repository contains the needed resources to build the HIRID-ICU-Benchmark dataset
HiRID-ICU-Benchmark This repository contains the needed resources to build the HIRID-ICU-Benchmark dataset for which the manuscript can be found here.
 30 Dec 16, 2022
30 Dec 16, 2022
Extracting knowledge graphs from language models as a diagnostic benchmark of model performance.
Interpreting Language Models Through Knowledge Graph Extraction Idea: How do we interpret what a language model learns at various stages of training?
 9 Oct 25, 2022
9 Oct 25, 2022
![[CoRL 2021] A robotics benchmark for cross-embodiment imitation.](https://github.com/kevinzakka/x-magical/raw/main/images/gripper-sweep.gif)
[CoRL 2021] A robotics benchmark for cross-embodiment imitation.
x-magical x-magical is a benchmark extension of MAGICAL specifically geared towards cross-embodiment imitation. The tasks still provide the Demo/Test
 36 Nov 26, 2022
36 Nov 26, 2022

AOT (Associating Objects with Transformers) in PyTorch
An efficient modular implementation of Associating Objects with Transformers for Video Object Segmentation in PyTorch
 162 Dec 14, 2022
162 Dec 14, 2022
PyAF is an Open Source Python library for Automatic Time Series Forecasting built on top of popular pydata modules.
PyAF (Python Automatic Forecasting) PyAF is an Open Source Python library for Automatic Forecasting built on top of popular data science python module
 405 Jan 2, 2023
405 Jan 2, 2023
A benchmark for the task of translation suggestion
WeTS: A Benchmark for Translation Suggestion Translation Suggestion (TS), which provides alternatives for specific words or phrases given the entire d
 55 Dec 24, 2022
55 Dec 24, 2022

Code and models for "Pano3D: A Holistic Benchmark and a Solid Baseline for 360 Depth Estimation", OmniCV Workshop @ CVPR21.
Pano3D A Holistic Benchmark and a Solid Baseline for 360o Depth Estimation Pano3D is a new benchmark for depth estimation from spherical panoramas. We
 50 Dec 29, 2022
50 Dec 29, 2022
EEGEyeNet is benchmark to evaluate ET prediction based on EEG measurements with an increasing level of difficulty
Introduction EEGEyeNet EEGEyeNet is a benchmark to evaluate ET prediction based on EEG measurements with an increasing level of difficulty. Overview T
 23 Dec 22, 2022
23 Dec 22, 2022
Graph Robustness Benchmark: A scalable, unified, modular, and reproducible benchmark for evaluating the adversarial robustness of Graph Machine Learning.
Homepage | Paper | Datasets | Leaderboard | Documentation Graph Robustness Benchmark (GRB) provides scalable, unified, modular, and reproducible evalu
 66 Dec 22, 2022
66 Dec 22, 2022
A map update dataset and benchmark
MUNO21 MUNO21 is a dataset and benchmark for machine learning methods that automatically update and maintain digital street map datasets. Previous dat
 16 Nov 30, 2022
16 Nov 30, 2022

Datasets and source code for our paper Webly Supervised Fine-Grained Recognition: Benchmark Datasets and An Approach
Introduction Datasets and source code for our paper Webly Supervised Fine-Grained Recognition: Benchmark Datasets and An Approach Datasets: WebFG-496
 21 Sep 30, 2022
21 Sep 30, 2022

Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
 92 Jan 4, 2023
92 Jan 4, 2023
Repository for Multimodal AutoML Benchmark
Benchmarking Multimodal AutoML for Tabular Data with Text Fields Repository for the NeurIPS 2021 Dataset Track Submission "Benchmarking Multimodal Aut
 44 Nov 24, 2022
44 Nov 24, 2022
Benchmark library for high-dimensional HPO of black-box models based on Weighted Lasso regression
LassoBench LassoBench is a library for high-dimensional hyperparameter optimization benchmarks based on Weighted Lasso regression. Note: LassoBench is
 5 Mar 15, 2022
5 Mar 15, 2022
STS Benchmark comprises a selection of the English datasets used in the STS tasks organized in the context of SemEval between 2012 and 2017. The selection of datasets include text from image captions, news headlines and user forums.
stsb_multi_mt_en STS Benchmark comprises a selection of the English datasets used in the STS tasks organized in the context of SemEval between 2012 an
 2 Nov 5, 2021
2 Nov 5, 2021

SW components and demos for visual kinship recognition. An emphasis is put on the FIW dataset-- data loaders, benchmarks, results in summary.
FIW Data Development Kit Table of Contents Introduction Families In the Wild Database Publications Organization To Do License Getting Involved Introdu
 12 Jun 4, 2022
12 Jun 4, 2022
Installation, test and evaluation of Scribosermo speech-to-text engine
Scribosermo STT Setup Scribosermo is a LGPL licensed, open-source speech recognition engine to "Train fast Speech-to-Text networks in different langua
 3 Jun 20, 2022
3 Jun 20, 2022
[IROS2021] NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
NYU-VPR This repository provides the experiment code for the paper Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymiza
 22 Sep 28, 2022
22 Sep 28, 2022
![[v1 (ISBI'21) + v2] MedMNIST: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification](https://github.com/MedMNIST/MedMNIST/raw/main/assets/medmnistv2.jpg)
[v1 (ISBI'21) + v2] MedMNIST: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification
MedMNIST Project (Website) | Dataset (Zenodo) | Paper (arXiv) | MedMNIST v1 (ISBI'21) Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bili
 683 Dec 28, 2022
683 Dec 28, 2022
Simple Speech to Text, Text to Speech
Simple Speech to Text, Text to Speech 1. Download Repository Opsi 1 Download repository ini, extract di lokasi yang diinginkan Opsi 2 Jika sudah famil
 5 Dec 28, 2021
5 Dec 28, 2021
The Unsupervised Reinforcement Learning Benchmark (URLB)
The Unsupervised Reinforcement Learning Benchmark (URLB) URLB provides a set of leading algorithms for unsupervised reinforcement learning where agent
 259 Dec 26, 2022
259 Dec 26, 2022

A new benchmark for Icon Question Answering (IconQA) and a large-scale icon dataset Icon645.
IconQA About IconQA is a new diverse abstract visual question answering dataset that highlights the importance of abstract diagram understanding and c
 24 Dec 30, 2022
24 Dec 30, 2022
Codebase for the self-supervised goal reaching benchmark introduced in the LEXA paper
LEXA Benchmark Codebase for the self-supervised goal reaching benchmark introduced in the LEXA paper (Discovering and Achieving Goals via World Models
 36 Dec 22, 2022
36 Dec 22, 2022

NAS-HPO-Bench-II is the first benchmark dataset for joint optimization of CNN and training HPs.
NAS-HPO-Bench-II API Overview NAS-HPO-Bench-II is the first benchmark dataset for joint optimization of CNN and training HPs. It helps a fair and low-
 8 Nov 21, 2022
8 Nov 21, 2022
A MNIST-like fashion product database. Benchmark
Fashion-MNIST Table of Contents Why we made Fashion-MNIST Get the Data Usage Benchmark Visualization Contributing Contact Citing Fashion-MNIST License
 10.5k Jan 8, 2023
10.5k Jan 8, 2023

Flickr-Faces-HQ (FFHQ) is a high-quality image dataset of human faces, originally created as a benchmark for generative adversarial networks (GAN)
Flickr-Faces-HQ Dataset (FFHQ) Flickr-Faces-HQ (FFHQ) is a high-quality image dataset of human faces, originally created as a benchmark for generative
 2.9k Dec 28, 2022
2.9k Dec 28, 2022

image scene graph generation benchmark
Scene Graph Benchmark in PyTorch 1.7 This project is based on maskrcnn-benchmark Highlights Upgrad to pytorch 1.7 Multi-GPU training and inference Bat
 303 Dec 27, 2022
303 Dec 27, 2022
BEAMetrics: Benchmark to Evaluate Automatic Metrics in Natural Language Generation
BEAMetrics: Benchmark to Evaluate Automatic Metrics in Natural Language Generation Installing The Dependencies $ conda create --name beametrics python
 7 Jul 4, 2022
7 Jul 4, 2022
Strawberry Benchmark With Python
Strawberry benchmarks these benchmarks have been made to compare the performance of dataloaders and joined database queries. How to use You can run th
 4 Feb 23, 2022
4 Feb 23, 2022
Repository for the Bias Benchmark for QA dataset.
BBQ Repository for the Bias Benchmark for QA dataset. Authors: Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Tho
 18 Nov 18, 2022
18 Nov 18, 2022
A Python library for adversarial machine learning focusing on benchmarking adversarial robustness.
ARES This repository contains the code for ARES (Adversarial Robustness Evaluation for Safety), a Python library for adversarial machine learning rese
 377 Dec 20, 2022
377 Dec 20, 2022

Benchmark tools for Compressive LiDAR-to-map registration
Benchmark tools for Compressive LiDAR-to-map registration This repo contains the released version of code and datasets used for our IROS 2021 paper: "
 9 Nov 24, 2022
9 Nov 24, 2022

LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation
LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation Tasks | Datasets | LongLM | Baselines | Paper Introduction LOT is a ben
 46 Dec 28, 2022
46 Dec 28, 2022
This repository contains a set of benchmarks of different implementations of Parquet (storage format) - Arrow (in-memory format).
Parquet benchmarks This repository contains a set of benchmarks of different implementations of Parquet (storage format) - Arrow (in-memory format).
 11 Dec 21, 2022
11 Dec 21, 2022
Repository for the Bias Benchmark for QA dataset.
BBQ Repository for the Bias Benchmark for QA dataset. Authors: Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Tho
18 Nov 18, 2022
Benchmark datasets, data loaders, and evaluators for graph machine learning
Overview The Open Graph Benchmark (OGB) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Datasets cover
 1.5k Jan 5, 2023
1.5k Jan 5, 2023

Repository for benchmarking graph neural networks
Benchmarking Graph Neural Networks Updates Nov 2, 2020 Project based on DGL 0.4.2. See the relevant dependencies defined in the environment yml files
 2k Jan 3, 2023
2k Jan 3, 2023

PyTorch implementation of paper “Unbiased Scene Graph Generation from Biased Training”
A new codebase for popular Scene Graph Generation methods (2020). Visualization & Scene Graph Extraction on custom images/datasets are provided. It's also a PyTorch implementation of paper “Unbiased Scene Graph Generation from Biased Training CVPR 2020”
 824 Jan 3, 2023
824 Jan 3, 2023
The self-supervised goal reaching benchmark introduced in Discovering and Achieving Goals via World Models
Lexa-Benchmark Codebase for the self-supervised goal reaching benchmark introduced in 'Discovering and Achieving Goals via World Models'. Setup Create
 1 Oct 14, 2021
1 Oct 14, 2021
ImageNet-CoG is a benchmark for concept generalization. It provides a full evaluation framework for pre-trained visual representations which measure how well they generalize to unseen concepts.
The ImageNet-CoG Benchmark Project Website Paper (arXiv) Code repository for the ImageNet-CoG Benchmark introduced in the paper "Concept Generalizatio
 23 Oct 9, 2022
23 Oct 9, 2022
This repository contains all data used for writing a research paper Multiple Object Trackers in OpenCV: A Benchmark, presented in ISIE 2021 conference in Kyoto, Japan.
OpenCV-Multiple-Object-Tracking Python is version 3.6.7 to install opencv: pip uninstall opecv-python pip uninstall opencv-contrib-python pip install
 6 Dec 19, 2021
6 Dec 19, 2021
New approach to benchmark VQA models
VQA Benchmarking This repository contains the web application & the python interface to evaluate VQA models. Documentation Please see the documentatio
 4 Jul 25, 2022
4 Jul 25, 2022
Python suite to construct benchmark machine learning datasets from the MIMIC-III clinical database.
MIMIC-III Benchmarks Python suite to construct benchmark machine learning datasets from the MIMIC-III clinical database. Currently, the benchmark data
 6 Jan 2, 2023
6 Jan 2, 2023
Starter Code for VALUE benchmark
StarterCode for VALUE Benchmark This is the starter code for VALUE Benchmark [website], [paper]. This repository currently supports all baseline model
 73 Dec 9, 2022
73 Dec 9, 2022
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation (NeurIPS2021 Benchmark and Dataset Track)
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation by Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zh
 174 Dec 22, 2022
174 Dec 22, 2022
Official code of paper: MovingFashion: a Benchmark for the Video-to-Shop Challenge
SEAM Match-RCNN Official code of MovingFashion: a Benchmark for the Video-to-Shop Challenge paper Installation Requirements: Pytorch 1.5.1 or more rec
 31 Oct 10, 2022
31 Oct 10, 2022
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English ⚖️ 🏆 🧑🎓 👩⚖️ Dataset Summary Inspired by the recent widespread use of th
 95 Dec 8, 2022
95 Dec 8, 2022

ProFuzzBench - A Benchmark for Stateful Protocol Fuzzing
ProFuzzBench - A Benchmark for Stateful Protocol Fuzzing ProFuzzBench is a benchmark for stateful fuzzing of network protocols. It includes a suite of
 155 Jan 8, 2023
155 Jan 8, 2023

Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E. Evaluated on benchmark dataset Office31.
Deep-Unsupervised-Domain-Adaptation Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E.
 49 Dec 20, 2022
49 Dec 20, 2022

Benchmark a WebSocket server's message throughput ⌛
📻 WebSocket Benchmarker ⌚ Message throughput is how fast a WebSocket server can parse and respond to a message. Some people consider this to be a goo
 24 Nov 17, 2022
24 Nov 17, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022

Benchmark for Answering Existential First Order Queries with Single Free Variable
EFO-1-QA Benchmark for First Order Query Estimation on Knowledge Graphs This repository contains an entire pipeline for the EFO-1-QA benchmark. EFO-1
 14 Oct 24, 2022
14 Oct 24, 2022

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Official code for 'Robust Siamese Object Tracking for Unmanned Aerial Manipulator' and offical introduction to UAMT100 benchmark
SiamSA: Robust Siamese Object Tracking for Unmanned Aerial Manipulator Demo video 📹 Our video on Youtube and bilibili demonstrates the evaluation of
 12 Dec 18, 2022
12 Dec 18, 2022
wireguard-config-benchmark is a python script that benchmarks the download speeds for the connections defined in one or more wireguard config files
wireguard-config-benchmark is a python script that benchmarks the download speeds for the connections defined in one or more wireguard config files. If multiple configs are benchmarked it will output a file ranking them from fastest to slowest.
 12 May 7, 2022
12 May 7, 2022

This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking".
SCT This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking" The spatial-channel Transformer (SCT) enhan
27 Nov 23, 2022
STT for TorchScript is a port of Coqui STT based on DeepSpeech to PyTorch.
st3 STT for TorchScript is a port of Coqui STT based on DeepSpeech to PyTorch. Currently it supports converting pbmm models to pt scripts with integra
 8 Oct 18, 2021
8 Oct 18, 2021

Phy-Q: A Benchmark for Physical Reasoning
Phy-Q: A Benchmark for Physical Reasoning Cheng Xue*, Vimukthini Pinto*, Chathura Gamage* Ekaterina Nikonova, Peng Zhang, Jochen Renz School of Comput
 29 Dec 19, 2022
29 Dec 19, 2022

My published benchmark for a Kaggle Simulations Competition
Lux AI Working Title Bot Please refer to the Kaggle notebook for the comment section. The comment section contains my explanation on my code structure
 29 Aug 22, 2022
29 Aug 22, 2022
Model Quantization Benchmark
MQBench Update V0.0.2 Fix academic prepare setting. More deployable prepare process. Fix setup.py. Fix deploy on SNPE. Fix convert_deploy bug. Add Qua
 500 Jan 6, 2023
500 Jan 6, 2023
Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
91 Nov 22, 2022

A novel benchmark dataset for Monocular Layout prediction
AutoLay AutoLay: Benchmarking Monocular Layout Estimation Kaustubh Mani, N. Sai Shankar, J. Krishna Murthy, and K. Madhava Krishna Abstract In this pa
 39 Apr 26, 2022
39 Apr 26, 2022
CPU benchmark by calculating Pi, powered by Python3
cpu-benchmark Info: CPU benchmark by calculating Pi, powered by Python 3. Algorithm The program calculates pi with an accuracy of 10,000 decimal place
 20 Jan 3, 2023
20 Jan 3, 2023
The CLRS Algorithmic Reasoning Benchmark
Learning representations of algorithms is an emerging area of machine learning, seeking to bridge concepts from neural networks with classical algorithms.
 251 Jan 5, 2023
251 Jan 5, 2023
CARLA: A Python Library to Benchmark Algorithmic Recourse and Counterfactual Explanation Algorithms
CARLA - Counterfactual And Recourse Library CARLA is a python library to benchmark counterfactual explanation and recourse models. It comes out-of-the
 200 Dec 28, 2022
200 Dec 28, 2022
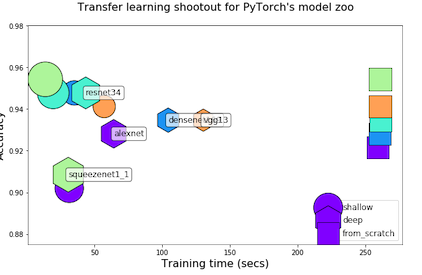
Transfer Learning Shootout for PyTorch's model zoo (torchvision)
pytorch-retraining Transfer Learning shootout for PyTorch's model zoo (torchvision). Load any pretrained model with custom final layer (num_classes) f
 169 Jun 29, 2022
169 Jun 29, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
176 Dec 28, 2022
![[Preprint]](https://github.com/VITA-Group/Deep_GCN_Benchmarking/raw/main/figs/combo.png)
[Preprint] "Bag of Tricks for Training Deeper Graph Neural Networks A Comprehensive Benchmark Study" by Tianlong Chen*, Kaixiong Zhou*, Keyu Duan, Wenqing Zheng, Peihao Wang, Xia Hu, Zhangyang Wang
Bag of Tricks for Training Deeper Graph Neural Networks: A Comprehensive Benchmark Study Codes for [Preprint] Bag of Tricks for Training Deeper Graph
 101 Dec 29, 2022
101 Dec 29, 2022
Pip-package for trajectory benchmarking from "Be your own Benchmark: No-Reference Trajectory Metric on Registered Point Clouds", ECMR'21
Map Metrics for Trajectory Quality Map metrics toolkit provides a set of metrics to quantitatively evaluate trajectory quality via estimating consiste
 31 Oct 28, 2022
31 Oct 28, 2022

HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021)
Code for HDR Video Reconstruction HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021) Guanying Chen, Cha
 64 Nov 19, 2022
64 Nov 19, 2022

FedScale: Benchmarking Model and System Performance of Federated Learning
FedScale: Benchmarking Model and System Performance of Federated Learning (Paper) This repository contains scripts and instructions of building FedSca
 268 Jan 1, 2023
268 Jan 1, 2023

ALFRED - A Benchmark for Interpreting Grounded Instructions for Everyday Tasks
ALFRED A Benchmark for Interpreting Grounded Instructions for Everyday Tasks Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han,
 204 Dec 15, 2022
204 Dec 15, 2022
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark We propose a benchmark to evaluate different quantization algorithms on vari
494 Dec 29, 2022
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering
Disfl-QA is a targeted dataset for contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages. Disfl-QA builds upon the SQuAD-v2 (Rajpurkar et al., 2018) dataset, where each question in the dev set is annotated to add a contextual disfluency using the paragraph as a source of distractors.
 52 Jun 21, 2022
52 Jun 21, 2022
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022

Benchmark for evaluating open-ended generation
OpenMEVA Contributed by Jian Guan, Zhexin Zhang. Thank Jiaxin Wen for DeBugging. OpenMEVA is a benchmark for evaluating open-ended story generation me
25 Nov 15, 2022
ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge (ManiSkill Challenge), a large-scale learning-from-demonstrations benchmark for object manipulation.
ManiSkill-Learn ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge, a large-scale learning-from-dem
 48 Dec 30, 2022
48 Dec 30, 2022
KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark.
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022

SAPIEN Manipulation Skill Benchmark
ManiSkill Benchmark SAPIEN Manipulation Skill Benchmark (abbreviated as ManiSkill, pronounced as "Many Skill") is a large-scale learning-from-demonstr
107 Jan 8, 2023
Few-shot NLP benchmark for unified, rigorous eval
FLEX FLEX is a benchmark and framework for unified, rigorous few-shot NLP evaluation. FLEX enables: First-class NLP support Support for meta-training
 85 Dec 3, 2022
85 Dec 3, 2022
![[IJCAI-2021] A benchmark of data-free knowledge distillation from paper](https://github.com/zju-vipa/DataFree/raw/main/assets/cmi.png)
[IJCAI-2021] A benchmark of data-free knowledge distillation from paper "Contrastive Model Inversion for Data-Free Knowledge Distillation"
DataFree A benchmark of data-free knowledge distillation from paper "Contrastive Model Inversion for Data-Free Knowledge Distillation" Authors: Gongfa
 47 Jan 9, 2023
47 Jan 9, 2023
An open-access benchmark and toolbox for electricity price forecasting
epftoolbox The epftoolbox is the first open-access library for driving research in electricity price forecasting. Its main goal is to make available a
 97 Dec 5, 2022
97 Dec 5, 2022
MVP Benchmark for Multi-View Partial Point Cloud Completion and Registration
MVP Benchmark: Multi-View Partial Point Clouds for Completion and Registration [NEWS] 2021-07-12 [NEW 🎉 ] The submission on Codalab starts! 2021-07-1
 93 Dec 21, 2022
93 Dec 21, 2022
Generic Event Boundary Detection: A Benchmark for Event Segmentation
Generic Event Boundary Detection: A Benchmark for Event Segmentation We release our data annotation & baseline codes for detecting generic event bound
 47 Nov 22, 2022
47 Nov 22, 2022

Official Implement of CVPR 2021 paper “Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting”
RGBT Crowd Counting Lingbo Liu, Jiaqi Chen, Hefeng Wu, Guanbin Li, Chenglong Li, Liang Lin. "Cross-Modal Collaborative Representation Learning and a L
 37 Dec 8, 2022
37 Dec 8, 2022

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022

Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020)
GraspNet Baseline Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020). [paper] [dataset] [API] [do
 209 Dec 29, 2022
209 Dec 29, 2022

NAS Benchmark in "Prioritized Architecture Sampling with Monto-Carlo Tree Search", CVPR2021
NAS-Bench-Macro This repository includes the benchmark and code for NAS-Bench-Macro in paper "Prioritized Architecture Sampling with Monto-Carlo Tree
 35 Jan 3, 2023
35 Jan 3, 2023

A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/casual, active/passive, and many more. Created by Prithiviraj Damodaran. Open to pull requests and other forms of collaboration.
Styleformer A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/cas
 431 Dec 19, 2022
431 Dec 19, 2022

modelvshuman is a Python library to benchmark the gap between human and machine vision
modelvshuman is a Python library to benchmark the gap between human and machine vision. Using this library, both PyTorch and TensorFlow models can be evaluated on 17 out-of-distribution datasets with high-quality human comparison data.
 244 Jan 3, 2023
244 Jan 3, 2023
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022

3D AffordanceNet is a 3D point cloud benchmark consisting of 23k shapes from 23 semantic object categories, annotated with 56k affordance annotations and covering 18 visual affordance categories.
3D AffordanceNet This repository is the official experiment implementation of 3D AffordanceNet benchmark. 3D AffordanceNet is a 3D point cloud benchma
 49 Dec 1, 2022
49 Dec 1, 2022
A list of hyperspectral image super-solution resources collected by Junjun Jiang
A list of hyperspectral image super-resolution resources collected by Junjun Jiang. If you find that important resources are not included, please feel free to contact me.
 301 Jan 5, 2023
301 Jan 5, 2023
[CVPR2021] UAV-Human: A Large Benchmark for Human Behavior Understanding with Unmanned Aerial Vehicles
UAV-Human Official repository for CVPR2021: UAV-Human: A Large Benchmark for Human Behavior Understanding with Unmanned Aerial Vehicle Paper arXiv Res
 129 Jan 4, 2023
129 Jan 4, 2023
RoboDesk A Multi-Task Reinforcement Learning Benchmark
RoboDesk A Multi-Task Reinforcement Learning Benchmark If you find this open source release useful, please reference in your paper: @misc{kannan2021ro
 66 Oct 7, 2022
66 Oct 7, 2022