1204 Repositories
Python text-annotation Libraries
Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech
EdiTTS: Score-based Editing for Controllable Text-to-Speech Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech. Au
 98 Dec 25, 2022
98 Dec 25, 2022

PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
 279 Jan 4, 2023
279 Jan 4, 2023
Every Google, Azure & IBM text to speech voice for free
TTS-Grabber Quick thing i made about a year ago to download any text with any tts voice, over 630 voices to choose from currently. It will split the i
 16 Dec 7, 2022
16 Dec 7, 2022
Simple python code to fix your combo list by removing any text after a separator or removing duplicate combos
Combo List Fixer A simple python code to fix your combo list by removing any text after a separator or removing duplicate combos Removing any text aft
 3 Dec 5, 2022
3 Dec 5, 2022
Given a string or a text file with plain text , returns his encryption using SHA256 method
Encryption using SHA256 Given a string or a .txt file with plain text. Returns his encryption using SHA256 method Requirements : pip install pyperclip
 3 Jan 24, 2022
3 Jan 24, 2022

text to speech toolkit. 好用的中文语音合成工具箱,包含语音编码器、语音合成器、声码器和可视化模块。
ttskit Text To Speech Toolkit: 语音合成工具箱。 安装 pip install -U ttskit 注意 可能需另外安装的依赖包:torch,版本要求torch=1.6.0,=1.7.1,根据自己的实际环境安装合适cuda或cpu版本的torch。 ttskit的
 483 Jan 4, 2023
483 Jan 4, 2023
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
 37 Sep 5, 2022
37 Sep 5, 2022
Train 🤗-transformers model with Poutyne.
poutyne-transformers Train 🤗 -transformers models with Poutyne. Installation pip install poutyne-transformers Example import torch from transformers
 2 Dec 18, 2022
2 Dec 18, 2022
Repository containing the code for An-Gocair text normaliser
Scottish Gaelic Text Normaliser The following project contains the code and resources for the Scottish Gaelic text normalisation project. The repo can
 3 Jun 28, 2022
3 Jun 28, 2022
EdiTTS: Score-based Editing for Controllable Text-to-Speech
Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech
99 Jan 2, 2023
PortaSpeech - PyTorch Implementation
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
276 Dec 26, 2022

IJON is an annotation mechanism that analysts can use to guide fuzzers such as AFL.
IJON SPACE EXPLORER IJON is an annotation mechanism that analysts can use to guide fuzzers such as AFL. Using only a small (usually one line) annotati
 146 Dec 16, 2022
146 Dec 16, 2022

PyTorch implementation of Microsoft's text-to-speech system FastSpeech 2: Fast and High-Quality End-to-End Text to Speech.
An implementation of Microsoft's "FastSpeech 2: Fast and High-Quality End-to-End Text to Speech"
 1k Dec 30, 2022
1k Dec 30, 2022
Signature remover is a NLP based solution which removes email signatures from the rest of the text.
Signature Remover Signature remover is a NLP based solution which removes email signatures from the rest of the text. It helps to enchance data conten
 8 Jan 6, 2023
8 Jan 6, 2023
a python package that lets you add custom colors and text formatting to your scripts in a very easy way!
colormate Python script text formatting package What is colormate? colormate is a python library that lets you add text formatting to your scripts, it
 2 Dec 14, 2022
2 Dec 14, 2022
Write maintainable, production-ready pipelines using Jupyter or your favorite text editor. Develop locally, deploy to the cloud. ☁️
Write maintainable, production-ready pipelines using Jupyter or your favorite text editor. Develop locally, deploy to the cloud. ☁️
 2.9k Jan 6, 2023
2.9k Jan 6, 2023
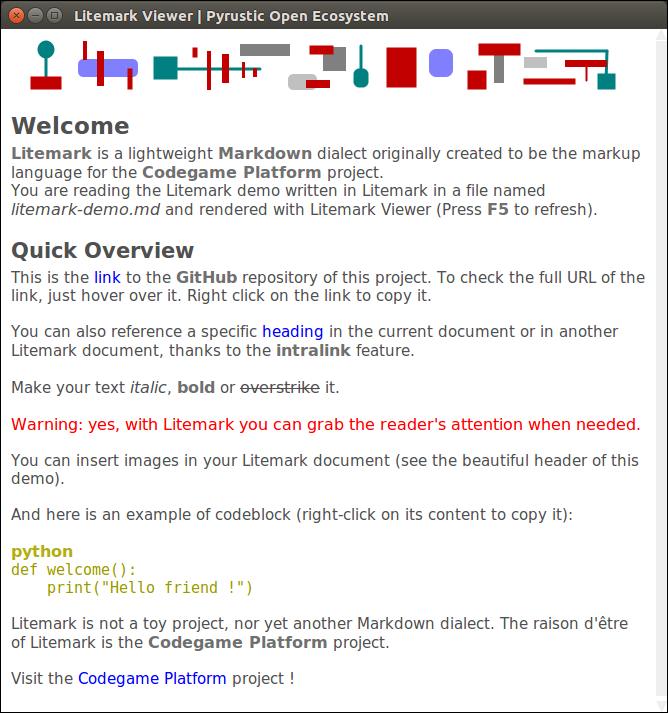
Lightweight Markdown dialect for Python desktop apps
Litemark is a lightweight Markdown dialect originally created to be the markup language for the Codegame Platform project. When you run litemark from the command line interface without any arguments, the Litemark Viewer opens and displays the rendered demo.
 10 Apr 23, 2022
10 Apr 23, 2022

Code repo for EMNLP21 paper "Zero-Shot Information Extraction as a Unified Text-to-Triple Translation"
Zero-Shot Information Extraction as a Unified Text-to-Triple Translation Source code repo for paper Zero-Shot Information Extraction as a Unified Text
 88 Dec 31, 2022
88 Dec 31, 2022
Simple script to ban bots at Twitch chats using a text file as a source.
AUTOBAN 🇺🇸 English version Simple script to ban bots at Twitch chats using a text file as a source. How to use Windows Go to releases for further in
 5 Feb 6, 2022
5 Feb 6, 2022
A set of examples around pytorch in Vision, Text, Reinforcement Learning, etc.
PyTorch Examples WARNING: if you fork this repo, github actions will run daily on it. To disable this, go to /examples/settings/actions and Disable Ac
 19.4k Jan 1, 2023
19.4k Jan 1, 2023

Unofficial Implementation of Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration This repo contains only model Implementation of Zero-Shot Text-to-Speech for Text
 33 Sep 22, 2022
33 Sep 22, 2022

A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
237 Jan 2, 2023
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
 2.7k Jan 5, 2023
2.7k Jan 5, 2023
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
 1.5k Jan 1, 2023
1.5k Jan 1, 2023
Flexitext is a Python library that makes it easier to draw text with multiple styles in Matplotlib
Flexitext is a Python library that makes it easier to draw text with multiple styles in Matplotlib
 93 Dec 28, 2022
93 Dec 28, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 287 Dec 21, 2022
287 Dec 21, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023
A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis
WaveGlow A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis Quick Start: Install requirements: pip install
 204 Jul 14, 2022
204 Jul 14, 2022

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Jan 8, 2023
1.8k Jan 8, 2023

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Labelling platform for text using distant supervision
With DataQA, you can label unstructured text documents using rule-based distant supervision.
 245 Aug 5, 2022
245 Aug 5, 2022
text-to-speach bot - You really do NOT have time for read a newsletter? Now you can listen to it
NewsletterReader You really do NOT have time for read a newsletter? Now you can listen to it The Newsletter of Filipe Deschamps is a great place to re
 8 Sep 18, 2021
8 Sep 18, 2021

Just playing with getting CLIP Guided Diffusion running locally, rather than having to use colab.
CLIP-Guided-Diffusion Just playing with getting CLIP Guided Diffusion running locally, rather than having to use colab. Original colab notebooks by Ka
 336 Dec 9, 2022
336 Dec 9, 2022
Simple embedding based text classifier inspired by fastText, implemented in tensorflow
FastText in Tensorflow This project is based on the ideas in Facebook's FastText but implemented in Tensorflow. However, it is not an exact replica of
 306 Dec 2, 2022
306 Dec 2, 2022
Library for fast text representation and classification.
fastText fastText is a library for efficient learning of word representations and sentence classification. Table of contents Resources Models Suppleme
 24.1k Jan 1, 2023
24.1k Jan 1, 2023
A production-ready pipeline for text mining and subject indexing
A production-ready pipeline for text mining and subject indexing
 12 Nov 6, 2022
12 Nov 6, 2022

A free Python source code editor and Notepad replacement for Windows
Website Download Features Toolbar Wide array of view options Syntax highlighting support for Python Usable accelerator keys for each function (Ctrl+N,
 7 Feb 16, 2022
7 Feb 16, 2022
This repo in the implementation of EMNLP'21 paper "SPARQLing Database Queries from Intermediate Question Decompositions" by Irina Saparina, Anton Osokin
SPARQLing Database Queries from Intermediate Question Decompositions This repo is the implementation of the following paper: SPARQLing Database Querie
 20 Dec 19, 2022
20 Dec 19, 2022
This project converts your human voice input to its text transcript and to an automated voice too.
Human Voice to Automated Voice & Text Introduction: In this project, whenever you'll speak, it will turn your voice into a robot voice and furthermore
 3 Oct 15, 2021
3 Oct 15, 2021
py-trans is a Free Python library for translate text into different languages.
Free Python library to translate text into different languages.
 13 Aug 27, 2022
13 Aug 27, 2022
AnnIE - Annotation Platform, tool for open information extraction annotations using text files.
AnnIE - Annotation Platform, tool for open information extraction annotations using text files.
 29 Dec 20, 2022
29 Dec 20, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 341 Dec 29, 2022
341 Dec 29, 2022
Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them"
Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them"
 19 Oct 28, 2022
19 Oct 28, 2022
`.](https://user-images.githubusercontent.com/4941909/132251464-0f6c48b2-f6ca-4ef7-9c76-39a78fbdd67c.png)
A Sublime Text plugin that displays inline images for single-line comments formatted like `// `.
Inline Images Sometimes ASCII art is not enough. Sometimes an image says more than a thousand words. This Sublime Text plugin can display images inlin
 8 Jul 1, 2022
8 Jul 1, 2022
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022
Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them"
ood-text-emnlp Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them" Files fine_tune.py is used to finetune the GPT-2 mo
19 Oct 28, 2022
Related resources for our EMNLP 2021 paper Plan-then-Generate: Controlled Data-to-Text Generation via Planning
Plan-then-Generate: Controlled Data-to-Text Generation via Planning Authors: Yixuan Su, David Vandyke, Sihui Wang, Yimai Fang, and Nigel Collier Code
 61 Jan 3, 2023
61 Jan 3, 2023

Feed forward VQGAN-CLIP model, where the goal is to eliminate the need for optimizing the latent space of VQGAN for each input prompt
Feed forward VQGAN-CLIP model, where the goal is to eliminate the need for optimizing the latent space of VQGAN for each input prompt. This is done by
 135 Dec 30, 2022
135 Dec 30, 2022
Finds snippets in iambic pentameter in English-language text and tries to combine them to a rhyming sonnet.
Sonnet finder Finds snippets in iambic pentameter in English-language text and tries to combine them to a rhyming sonnet. Usage This is a Python scrip
 11 Sep 25, 2022
11 Sep 25, 2022
Telegram bot to extract text from image
OCR Bot @Image_To_Text_OCR_Bot A star ⭐ from you means a lot to us! Telegram bot to extract text from image Usage Deploy to Heroku Tap on above button
 25 Nov 24, 2022
25 Nov 24, 2022

Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
 105 Jan 3, 2023
105 Jan 3, 2023
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Text-AutoAugment (TAA) This repository contains the code for our paper Text AutoAugment: Learning Compositional Augmentation Policy for Text Classific
105 Jan 3, 2023
This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation". It is intended to be used for normalizing / cleaning Bengali and English text.
normalizer This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch
 23 Nov 30, 2022
23 Nov 30, 2022
Tutorial to pretrain & fine-tune a 🤗 Flax T5 model on a TPUv3-8 with GCP
Pretrain and Fine-tune a T5 model with Flax on GCP This tutorial details how pretrain and fine-tune a FlaxT5 model from HuggingFace using a TPU VM ava
 41 Nov 18, 2022
41 Nov 18, 2022
Python lib for Simple PDF text extraction
Python lib for Simple PDF text extraction
 651 Jan 1, 2023
651 Jan 1, 2023

This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Technique for Text Classification
The baseline code is for EDA: Easy Data Augmentation techniques for boosting performance on text classification tasks
 81 Dec 9, 2022
81 Dec 9, 2022
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
CLabel is a terminal-based cluster labeling tool that allows you to explore text data interactively and label clusters based on reviewing that data.
CLabel is a terminal-based cluster labeling tool that allows you to explore text data interactively and label clusters based on reviewing that
 29 Aug 9, 2022
29 Aug 9, 2022

Generate text line images for training deep learning OCR model (e.g. CRNN)
Generate text line images for training deep learning OCR model (e.g. CRNN)
 532 Jan 6, 2023
532 Jan 6, 2023
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
 30 Dec 12, 2022
30 Dec 12, 2022

Python 3 patcher for Sublime Text v4107-4114 Windows x64
sublime-text-4-patcher Python 3 patcher for Sublime Text v4107-4114 Windows x64 Credits for signatures and patching logic goes to https://github.com/l
 187 Dec 27, 2022
187 Dec 27, 2022

OpenCVのGrabCut()を利用したセマンティックセグメンテーション向けアノテーションツール(Annotation tool using GrabCut() of OpenCV. It can be used to create datasets for semantic segmentation.)
[Japanese/English] GrabCut-Annotation-Tool GrabCut-Annotation-Tool.mp4 OpenCVのGrabCut()を利用したアノテーションツールです。 セマンティックセグメンテーション向けのデータセット作成にご使用いただけます。 ※Grab
 30 Nov 18, 2022
30 Nov 18, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
A bot can be used to broadcast your messages ( Text & Media ) to the Subscribers
Broadcast Bot A Telegram bot to send messages and medias to the subscribers directly through bot. Authorized users of the bot can send messages (Texts
 8 Oct 21, 2022
8 Oct 21, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
Mail classification with tensorflow and MS Exchange Server (ham or spam).
Mail classification with tensorflow and MS Exchange Server (ham or spam).
 1 Sep 11, 2021
1 Sep 11, 2021
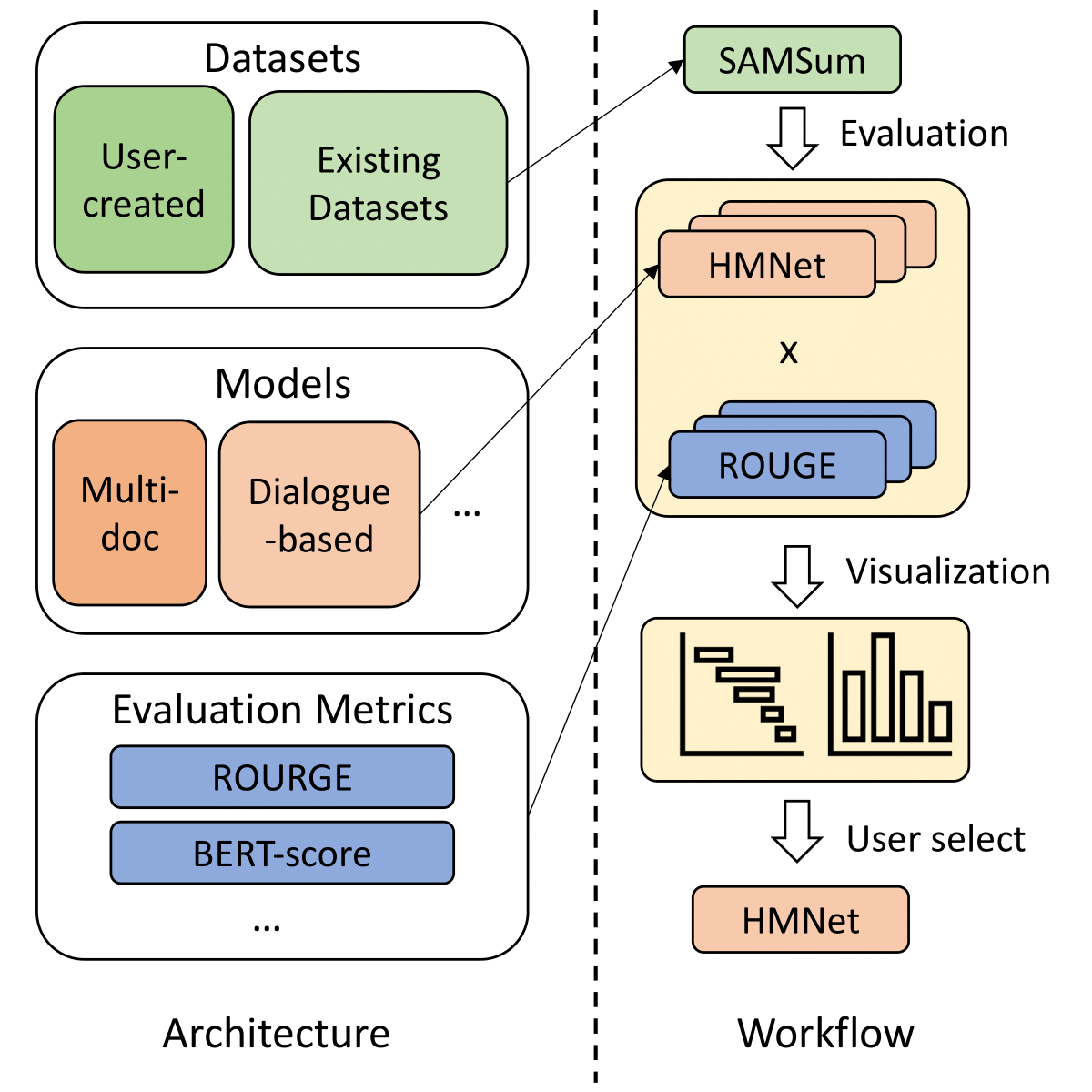
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023

An original implementation of "Noisy Channel Language Model Prompting for Few-Shot Text Classification"
Channel LM Prompting (and beyond) This includes an original implementation of Sewon Min, Mike Lewis, Hannaneh Hajishirzi, Luke Zettlemoyer. "Noisy Cha
 92 Jan 7, 2023
92 Jan 7, 2023
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 54 Aug 30, 2021
54 Aug 30, 2021

GSoC'2021 | TensorFlow implementation of Wav2Vec2
GSoC'2021 | TensorFlow implementation of Wav2Vec2
 73 Nov 28, 2022
73 Nov 28, 2022
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task。涵盖68个领域、共计916万词的专业词典知识库,可用于文本分类、知识增强、领域词汇库扩充等自然语言处理应用。
 357 Dec 24, 2022
357 Dec 24, 2022

Generate vibrant and detailed images using only text.
CLIP Guided Diffusion From RiversHaveWings. Generate vibrant and detailed images using only text. See captions and more generations in the Gallery See
 401 Dec 28, 2022
401 Dec 28, 2022
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 5, 2023
247 Jan 5, 2023

A graphical Semi-automatic annotation tool based on labelImg and Yolov5
💕YOLOV5 semi-automatic annotation tool (Based on labelImg)
 247 Jan 5, 2023
247 Jan 5, 2023
Extract knowledge from raw text
Extract knowledge from raw text This repository is a nearly copy-paste of "From Text to Knowledge: The Information Extraction Pipeline" with some cosm
 10 Dec 3, 2022
10 Dec 3, 2022

Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer Summary Explorer is a tool to visually inspect the summaries from several state-of-the-art neural summarization models across multipl
 42 Aug 14, 2022
42 Aug 14, 2022
This Telegram bot allows you to create direct links with pre-filled text to WhatsApp Chats
WhatsApp API Bot Telegram bot to create direct links with pre-filled text for WhatsApp Chats You can check our bot here. The bot is based on the API p
 17 Aug 20, 2022
17 Aug 20, 2022
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
42 Aug 14, 2022
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 169 Jan 5, 2023
169 Jan 5, 2023
Text based command line webcam photobooth app
Skunkbooth Why See it in action Usage Installation Run Media location Contributing Install Poetry Clone the repo Activate poetry shell Install dev dep
 45 Dec 26, 2022
45 Dec 26, 2022

The pytorch implementation of the paper "text-guided neural image inpainting" at MM'2020
TDANet: Text-Guided Neural Image Inpainting, MM'2020 (Oral) MM | ArXiv This repository implements the paper "Text-Guided Neural Image Inpainting" by L
 75 Dec 22, 2022
75 Dec 22, 2022

Database Reasoning Over Text project for ACL paper
Database Reasoning over Text This repository contains the code for the Database Reasoning Over Text paper, to appear at ACL2021. Work is performed in
320 Dec 12, 2022

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
47 Dec 18, 2022
Official implementation for ICDAR 2021 paper "Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer"
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer Description Convert offline handwritten mathematical expressi
 87 Dec 27, 2022
87 Dec 27, 2022
Text-to-Image generation
Generate vivid Images for Any (Chinese) text CogView is a pretrained (4B-param) transformer for text-to-image generation in general domain. Read our p
 1.3k Dec 29, 2022
1.3k Dec 29, 2022
Full-text multi-table search application for Django. Easy to install and use, with good performance.
django-watson django-watson is a fast multi-model full-text search plugin for Django. It is easy to install and use, and provides high quality search
 1.1k Jan 3, 2023
1.1k Jan 3, 2023

End-to-end text to speech system using gruut and onnx. There are 40 voices available across 8 languages.
End to end text to speech system using gruut and onnx
 673 Dec 28, 2022
673 Dec 28, 2022

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
 235 Dec 22, 2022
235 Dec 22, 2022
Export solved codewars kata challenges to a text file.
Codewars Kata Exporter Note:this is not totally my work.i've edited the project to make more easier and faster for me.you can find the original work h
 4 Aug 13, 2021
4 Aug 13, 2021

A demo for end-to-end English and Chinese text spotting using ABCNet.
ABCNet_Chinese A demo for end-to-end English and Chinese text spotting using ABCNet. This is an old model that was trained a long ago, which serves as
 45 Oct 4, 2022
45 Oct 4, 2022
Text-Based Ideal Points
Text-Based Ideal Points Source code for the paper: Text-Based Ideal Points by Keyon Vafa, Suresh Naidu, and David Blei (ACL 2020). Update (June 29, 20
 37 Oct 9, 2022
37 Oct 9, 2022

Textual is a TUI (Text User Interface) framework for Python inspired by modern web development.
Textual is a TUI (Text User Interface) framework for Python inspired by modern web development.
 17.1k Jan 8, 2023
17.1k Jan 8, 2023

A Data Annotation Tool for Semantic Segmentation, Object Detection and Lane Line Detection.(In Development Stage)
Data-Annotation-Tool How to Run this Tool? To run this software, follow the steps: git clone https://github.com/Autonomous-Car-Project/Data-Annotation
 13 Aug 18, 2022
13 Aug 18, 2022
Code for "Finetuning Pretrained Transformers into Variational Autoencoders"
transformers-into-vaes Code for Finetuning Pretrained Transformers into Variational Autoencoders (our submission to NLP Insights Workshop 2021). Gathe
 22 Nov 26, 2022
22 Nov 26, 2022
ThinkTwice: A Two-Stage Method for Long-Text Machine Reading Comprehension
ThinkTwice ThinkTwice is a retriever-reader architecture for solving long-text machine reading comprehension. It is based on the paper: ThinkTwice: A
 4 Aug 6, 2021
4 Aug 6, 2021
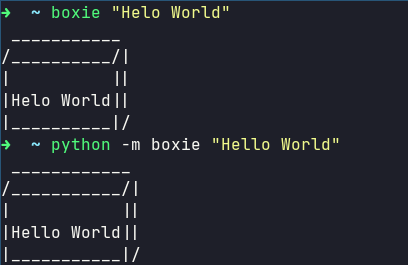
📦 A command line utility to put text in a box.
boxie A command line utility to put text in a box. Installation pip install boxie If you are on Linux you may need to use sudo to access this globally
 10 Jun 30, 2022
10 Jun 30, 2022