3574 Repositories
Python text-data Libraries
Deduplicating Training Data Makes Language Models Better
Deduplicating Training Data Makes Language Models Better This repository contains code to deduplicate language model datasets as descrbed in the paper
 431 Dec 27, 2022
431 Dec 27, 2022
Code release for our paper, "SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo"
SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo Thomas Kollar, Michael Laskey, Kevin Stone, Brijen Thananjeyan
 68 Dec 14, 2022
68 Dec 14, 2022
Utility functions for working with data from Nix in Python
Pynixutil - Utility functions for working with data from Nix in Python Examples Base32 encoding/decoding import pynixutil input = "v5sv61sszx301i0x6x
 11 Dec 16, 2022
11 Dec 16, 2022

A text augmentation tool for named entity recognition.
neraug This python library helps you with augmenting text data for named entity recognition. Augmentation Example Reference from An Analysis of Simple
 48 Oct 11, 2022
48 Oct 11, 2022
Python package for machine learning for healthcare using a OMOP common data model
This library was developed in order to facilitate rapid prototyping in Python of predictive machine-learning models using longitudinal medical data from an OMOP CDM-standard database.
 75 Jan 3, 2023
75 Jan 3, 2023
NeuralCompression is a Python repository dedicated to research of neural networks that compress data
NeuralCompression is a Python repository dedicated to research of neural networks that compress data. The repository includes tools such as JAX-based entropy coders, image compression models, video compression models, and metrics for image and video evaluation.
 297 Jan 6, 2023
297 Jan 6, 2023

Rubrix is a free and open-source tool for exploring and iterating on data for artificial intelligence projects.
Open-source tool for exploring, labeling, and monitoring data for AI projects
 1.5k Jan 7, 2023
1.5k Jan 7, 2023

A pytorch reproduction of { Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation }.
A PyTorch Reproduction of HCN Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation. Ch
 210 Dec 31, 2022
210 Dec 31, 2022
A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis
WaveGlow A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis Quick Start: Install requirements: pip install
 204 Jul 14, 2022
204 Jul 14, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023

Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
This is the official PyTorch implementation of the ALBEF paper [Blog]. This repository supports pre-training on custom datasets, as well as finetuning on VQA, SNLI-VE, NLVR2, Image-Text Retrieval on MSCOCO and Flickr30k, and visual grounding on RefCOCO+. Pre-trained and finetuned checkpoints are released.
 805 Jan 9, 2023
805 Jan 9, 2023
DrQ-v2: Improved Data-Augmented Reinforcement Learning
DrQ-v2: Improved Data-Augmented RL Agent Method DrQ-v2 is a model-free off-policy algorithm for image-based continuous control. DrQ-v2 builds on DrQ,
234 Jan 1, 2023
Data exploration done quick.
Pandas Tab Implementation of Stata's tabulate command in Pandas for extremely easy to type one-way and two-way tabulations. Support: Python 3.7 and 3.
 20 Aug 27, 2022
20 Aug 27, 2022

Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
 193 Dec 30, 2022
193 Dec 30, 2022
A library for generating fake data and populating database tables.
Knockoff Factory A library for generating mock data and creating database fixtures that can be used for unit testing. Table of content Installation Ch
 30 Sep 23, 2022
30 Sep 23, 2022

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
 67 Nov 14, 2022
67 Nov 14, 2022

Moving Object Segmentation in 3D LiDAR Data: A Learning-based Approach Exploiting Sequential Data
LiDAR-MOS: Moving Object Segmentation in 3D LiDAR Data This repo contains the code for our paper: Moving Object Segmentation in 3D LiDAR Data: A Learn
 394 Dec 29, 2022
394 Dec 29, 2022
code and data for paper "GIANT: Scalable Creation of a Web-scale Ontology"
GIANT Code and data for paper "GIANT: Scalable Creation of a Web-scale Ontology" https://arxiv.org/pdf/2004.02118.pdf Please cite our paper if this pr
 39 Dec 29, 2022
39 Dec 29, 2022

A new data augmentation method for extreme lighting conditions.
Random Shadows and Highlights This repo has the source code for the paper: Random Shadows and Highlights: A new data augmentation method for extreme l
 35 Nov 26, 2022
35 Nov 26, 2022

Exploit Camera Raw Data for Video Super-Resolution via Hidden Markov Model Inference
RawVSR This repo contains the official codes for our paper: Exploit Camera Raw Data for Video Super-Resolution via Hidden Markov Model Inference Xiaoh
 23 Oct 8, 2022
23 Oct 8, 2022

Unofficial Pytorch Implementation of WaveGrad2
WaveGrad 2 — Unofficial PyTorch Implementation WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis Unofficial PyTorch+Lightning Implementati
 104 Nov 29, 2022
104 Nov 29, 2022
MachineLearningStocks is designed to be an intuitive and highly extensible template project applying machine learning to making stock predictions.
Using python and scikit-learn to make stock predictions
 1.3k Jan 3, 2023
1.3k Jan 3, 2023
Pytorch implementation of "Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech"
GradTTS Unofficial Pytorch implementation of "Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech" (arxiv) About this repo This is an unoffic
 103 Dec 23, 2022
103 Dec 23, 2022

The MLOps platform for innovators 🚀
DS2.ai is an integrated AI operation solution that supports all stages from custom AI development to deployment. It is an AI-specialized platform service that collects data, builds a training dataset through data labeling, and enables automatic development of artificial intelligence and easy deployment and operation.
 9 Jan 3, 2023
9 Jan 3, 2023
Raganarok X: Next Generation Data Dump
Raganarok X Data Dump Raganarok X: Next Generation Data Dump More interesting Files File Name Contains en_langs All the variables you need in English
 14 Jul 15, 2022
14 Jul 15, 2022

A Python library for reading, writing and visualizing the OMEGA Format
A Python library for reading, writing and visualizing the OMEGA Format, targeted towards storing reference and perception data in the automotive context on an object list basis with a focus on an urban use case.
 12 Sep 1, 2022
12 Sep 1, 2022

Squidpy is a tool for the analysis and visualization of spatial molecular data.
Squidpy is a tool for the analysis and visualization of spatial molecular data. It builds on top of scanpy and anndata, from which it inherits modularity and scalability. It provides analysis tools that leverages the spatial coordinates of the data, as well as tissue images if available.
 251 Dec 19, 2022
251 Dec 19, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 286 Jan 2, 2023
286 Jan 2, 2023

A community run, 5-day PyTorch Deep Learning Bootcamp
Deep Learning Winter School, November 2107. Tel Aviv Deep Learning Bootcamp : http://deep-ml.com. About Tel-Aviv Deep Learning Bootcamp is an intensiv
 1.3k Sep 4, 2021
1.3k Sep 4, 2021

Amazon Forest Computer Vision: Satellite Image tagging code using PyTorch / Keras with lots of PyTorch tricks
Amazon Forest Computer Vision Satellite Image tagging code using PyTorch / Keras Here is a sample of images we had to work with Source: https://www.ka
 360 Dec 10, 2022
360 Dec 10, 2022
🛠 All-in-one web-based IDE specialized for machine learning and data science.
All-in-one web-based development environment for machine learning Getting Started • Features & Screenshots • Support • Report a Bug • FAQ • Known Issu
 2.9k Jan 9, 2023
2.9k Jan 9, 2023
Wrapper to display a script output or a text file content on the desktop in sway or other wlroots-based compositors
nwg-wrapper This program is a part of the nwg-shell project. This program is a GTK3-based wrapper to display a script output, or a text file content o
 94 Dec 27, 2022
94 Dec 27, 2022
XGBoost-Ray is a distributed backend for XGBoost, built on top of distributed computing framework Ray.
XGBoost-Ray is a distributed backend for XGBoost, built on top of distributed computing framework Ray.
 92 Dec 14, 2022
92 Dec 14, 2022

A mindmap summarising Machine Learning concepts, from Data Analysis to Deep Learning.
A mindmap summarising Machine Learning concepts, from Data Analysis to Deep Learning.
 5.7k Dec 30, 2022
5.7k Dec 30, 2022

This is the unofficial code of Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes. which achieve state-of-the-art trade-off between accuracy and speed on cityscapes and camvid, without using inference acceleration and extra data
Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes Introduction This is the unofficial code of Deep Dual-re
 113 Dec 23, 2022
113 Dec 23, 2022

Deep Learning and Logical Reasoning from Data and Knowledge
Logic Tensor Networks (LTN) Logic Tensor Network (LTN) is a neurosymbolic framework that supports querying, learning and reasoning with both rich data
 171 Dec 29, 2022
171 Dec 29, 2022

graph-theoretic framework for robust pairwise data association
CLIPPER: A Graph-Theoretic Framework for Robust Data Association Data association is a fundamental problem in robotics and autonomy. CLIPPER provides
 118 Dec 28, 2022
118 Dec 28, 2022

Official Pytorch Implementation of Adversarial Instance Augmentation for Building Change Detection in Remote Sensing Images.
IAug_CDNet Official Implementation of Adversarial Instance Augmentation for Building Change Detection in Remote Sensing Images. Overview We propose a
 53 Dec 2, 2022
53 Dec 2, 2022
A PyTorch-based open-source framework that provides methods for improving the weakly annotated data and allows researchers to efficiently develop and compare their own methods.
Knodle (Knowledge-supervised Deep Learning Framework) - a new framework for weak supervision with neural networks. It provides a modularization for se
 93 Nov 6, 2022
93 Nov 6, 2022
PyTorch wrapper for Taichi data-oriented class
Stannum PyTorch wrapper for Taichi data-oriented class PRs are welcomed, please see TODOs. Usage from stannum import Tin import torch data_oriented =
 86 Dec 23, 2022
86 Dec 23, 2022

Build a better understanding of your data in PostgreSQL.
Data Fluent for PostgreSQL Build a better understanding of your data in PostgreSQL. The following shows an example report generated by this tool. It g
 28 Aug 30, 2022
28 Aug 30, 2022

box is a text-based visual programming language inspired by Unreal Engine Blueprint function graphs.
Box is a text-based visual programming language inspired by Unreal Engine blueprint function graphs. $ cat factorial.box ┌─ƒ(Factorial)───┐
 104 Dec 24, 2022
104 Dec 24, 2022
Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis
MLP Singer Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis. Audio samples are available on our demo page.
 103 Dec 23, 2022
103 Dec 23, 2022
A python library for extracting text from PDFs without losing the formatting of the PDF content.
Multilingual PDF to Text Install Package from Pypi Install it using pip. pip install multilingual-pdf2text The library uses Tesseract which can be ins
 49 Nov 7, 2022
49 Nov 7, 2022

Python parser for DTED data.
DTED Parser This is a package written in pure python (with help from numpy) to parse and investigate Digital Terrain Elevation Data (DTED) files. This
 12 Dec 18, 2022
12 Dec 18, 2022
A discord bot consuming Notion API to add, retrieve data to Notion databases.
Notion-DiscordBot A discord bot consuming Notion API to add and retrieve data from Notion databases. Instructions to use the bot: Pre-Requisites: a)In
 57 Dec 29, 2022
57 Dec 29, 2022

Just playing with getting VQGAN+CLIP running locally, rather than having to use colab.
Just playing with getting VQGAN+CLIP running locally, rather than having to use colab.
 2.3k Jan 4, 2023
2.3k Jan 4, 2023

Command Line Text-To-Speech using Google TTS
cli-tts Thanks to gTTS by @pndurette! This is an interactive command line text-to-speech tool using Google TTS. Just type text and the voice will be p
 3 Nov 11, 2022
3 Nov 11, 2022

This machine-learning algorithm takes in data from the last 60 days and tries to predict tomorrow's price of any crypto you ask it.
Crypto-Currency-Predictor This machine-learning algorithm takes in data from the last 60 days and tries to predict tomorrow's price of any crypto you
 6 Dec 4, 2022
6 Dec 4, 2022

Check the basic quality of any dataset
Data Quality Checker in Python Check the basic quality of any dataset. Sneak Peek Read full tutorial at Medium. Explore the app Requirements python 3.
 8 Feb 23, 2022
8 Feb 23, 2022
Data derived from the OpenType specification
This package currently provides the opentypespec.tags module, which exports FEATURE_TAGS, SCRIPT_TAGS, LANGUAGE_TAGS and BASELINE_TAGS dictionaries, representing data from the Layout Tag Registry
 4 Dec 1, 2022
4 Dec 1, 2022

Yata is a fast, simple and easy Data Visulaization tool, running on python dash
Yata is a fast, simple and easy Data Visulaization tool, running on python dash. The main goal of Yata is to provide a easy way for persons with little programming knowledge to visualize their data easily.
 3 Jun 28, 2021
3 Jun 28, 2021
Datargsing is a data management and manipulation Python library
Datargsing What is It? Datargsing is a data management and manipulation Python library which is currently in deving Why this library is good? This Pyt
 10 Oct 24, 2022
10 Oct 24, 2022
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
 564 Jan 3, 2023
564 Jan 3, 2023

mlscraper: Scrape data from HTML pages automatically with Machine Learning
🤖 Scrape data from HTML websites automatically with Machine Learning
 798 Dec 29, 2022
798 Dec 29, 2022
A toolbox of scene text detection and recognition
FudanOCR This toolbox contains the implementations of the following papers: Scene Text Telescope: Text-Focused Scene Image Super-Resolution [Chen et a
 170 Dec 26, 2022
170 Dec 26, 2022

Distributed DataLoader For Pytorch Based On Ray
Dpex——用户无感知分布式数据预处理组件 一、前言 随着GPU与CPU的算力差距越来越大以及模型训练时的预处理Pipeline变得越来越复杂,CPU部分的数据预处理已经逐渐成为了模型训练的瓶颈所在,这导致单机的GPU配置的提升并不能带来期望的线性加速。预处理性能瓶颈的本质在于每个GPU能够使用的C
 23 Nov 2, 2022
23 Nov 2, 2022

Azure Cloud Advocates at Microsoft are pleased to offer a 12-week, 24-lesson curriculum all about Machine Learning
Azure Cloud Advocates at Microsoft are pleased to offer a 12-week, 24-lesson curriculum all about Machine Learning
 43.4k Jan 4, 2023
43.4k Jan 4, 2023
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
 152 Oct 29, 2022
152 Oct 29, 2022
This is a simple backtesting framework to help you test your crypto currency trading. It includes a way to download and store historical crypto data and to execute a trading strategy.
You can use this simple crypto backtesting script to ensure your trading strategy is successful Minimal setup required and works well with static TP a
 154 Sep 12, 2022
154 Sep 12, 2022

Code implementation of Data Efficient Stagewise Knowledge Distillation paper.
Data Efficient Stagewise Knowledge Distillation Table of Contents Data Efficient Stagewise Knowledge Distillation Table of Contents Requirements Image
 112 Dec 2, 2022
112 Dec 2, 2022

BARTScore: Evaluating Generated Text as Text Generation
This is the Repo for the paper: BARTScore: Evaluating Generated Text as Text Generation Updates 2021.06.28 Release online evaluation Demo 2021.06.25 R
 196 Dec 17, 2022
196 Dec 17, 2022
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
 93 Dec 17, 2022
93 Dec 17, 2022

PyTorch Implementation of NCSOFT's FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
FastPitchFormant - PyTorch Implementation PyTorch Implementation of FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis. Qu
63 Jan 2, 2023
Source code for models described in the paper "AudioCLIP: Extending CLIP to Image, Text and Audio" (https://arxiv.org/abs/2106.13043)
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
 458 Jan 2, 2023
458 Jan 2, 2023

Official Implementation of CoSMo: Content-Style Modulation for Image Retrieval with Text Feedback
CoSMo.pytorch Official Implementation of CoSMo: Content-Style Modulation for Image Retrieval with Text Feedback, Seungmin Lee*, Dongwan Kim*, Bohyung
 54 Dec 8, 2022
54 Dec 8, 2022
![[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach](https://github.com/SHI-Labs/Rethinking-Text-Segmentation/raw/main/.figure/image_only.jpg)
[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach
Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach This is the repo to host the dataset TextSeg and code for TexRNe
 174 Dec 19, 2022
174 Dec 19, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
 190 Jan 3, 2023
190 Jan 3, 2023
Tuplex is a parallel big data processing framework that runs data science pipelines written in Python at the speed of compiled code
Tuplex is a parallel big data processing framework that runs data science pipelines written in Python at the speed of compiled code. Tuplex has similar Python APIs to Apache Spark or Dask, but rather than invoking the Python interpreter, Tuplex generates optimized LLVM bytecode for the given pipeline and input data set.
 791 Jan 4, 2023
791 Jan 4, 2023

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
A Bot To Get Info Of Telegram messages , Media , Channel id Group ID etc.
Info-Bot A Bot To Get Info Of Telegram messages , Media , Channel id Group ID etc. Get Info Of Your And Messages , Channels , Groups ETC... How to mak
 23 Nov 12, 2022
23 Nov 12, 2022
An advanced real time threat intelligence framework to identify threats and malicious web traffic on the basis of IP reputation and historical data.
ARTIF is a new advanced real time threat intelligence framework built that adds another abstraction layer on the top of MISP to identify threats and malicious web traffic on the basis of IP reputation and historical data. It also performs automatic enrichment and threat scoring by collecting, processing and correlating observables based on different factors.
 225 Dec 31, 2022
225 Dec 31, 2022
The source codes for ACL 2021 paper 'BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data'
BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data This repository provides the implementation details for
 124 Dec 27, 2022
124 Dec 27, 2022

PyTorch implementation of ARM-Net: Adaptive Relation Modeling Network for Structured Data.
A ready-to-use framework of latest models for structured (tabular) data learning with PyTorch. Applications include recommendation, CRT prediction, healthcare analytics, and etc.
 48 Nov 30, 2022
48 Nov 30, 2022
A data preprocessing package for time series data. Design for machine learning and deep learning.
A data preprocessing package for time series data. Design for machine learning and deep learning.
 152 Jan 7, 2023
152 Jan 7, 2023
This is a template for the Non-autoregressive Deep Learning-Based TTS model (in PyTorch).
Non-autoregressive Deep Learning-Based TTS Template This is a template for the Non-autoregressive TTS model. It contains Data Preprocessing Pipeline D
13 Dec 5, 2022

This is the antenna performance plotted from tinyGS reception data.
tinyGS-antenna-map This is the antenna performance plotted from tinyGS reception data. See their repository. The code produces a plot that provides Az
 14 Aug 21, 2022
14 Aug 21, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
189 Jan 2, 2023
nnDetection is a self-configuring framework for 3D (volumetric) medical object detection which can be applied to new data sets without manual intervention. It includes guides for 12 data sets that were used to develop and evaluate the performance of the proposed method.
What is nnDetection? Simultaneous localisation and categorization of objects in medical images, also referred to as medical object detection, is of hi
 365 Jan 9, 2023
365 Jan 9, 2023

Meerkat provides fast and flexible data structures for working with complex machine learning datasets.
Meerkat makes it easier for ML practitioners to interact with high-dimensional, multi-modal data. It provides simple abstractions for data inspection, model evaluation and model training supported by efficient and robust IO under the hood.
 115 Dec 12, 2022
115 Dec 12, 2022

A scanpy extension to analyse single-cell TCR and BCR data.
Scirpy: A Scanpy extension for analyzing single-cell immune-cell receptor sequencing data Scirpy is a scalable python-toolkit to analyse T cell recept
 145 Jan 3, 2023
145 Jan 3, 2023

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023

Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
SEDE SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description
 83 Nov 11, 2022
83 Nov 11, 2022
Cross-Modal Contrastive Learning for Text-to-Image Generation
Cross-Modal Contrastive Learning for Text-to-Image Generation This repository hosts the open source JAX implementation of XMC-GAN. Setup instructions
94 Nov 12, 2022

Blender Python - Node-based multi-line text and image flowchart
MindMapper v0.8 Node-based text and image flowchart for Blender Mindmap with shortcuts visible: Mindmap with shortcuts hidden: Notes This was requeste
 58 Oct 8, 2022
58 Oct 8, 2022
AudioCLIP Extending CLIP to Image, Text and Audio
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
458 Jan 2, 2023

Lint game data metafiles against GTA5.xsd for Rockstar's game engine (RAGE)
rage-lint Lint RAGE (only GTA5 at the moment) meta/XML files for validity based off of the GTA5.xsd generated from game code. This script accepts a se
 11 Sep 18, 2022
11 Sep 18, 2022
Social Media Network Focuses On Data Security And Being Community Driven Web App
privalise Social Media Network Focuses On Data Security And Being Community Driven Web App The Main Idea: We`ve seen social media web apps that focuse
 8 Jun 25, 2021
8 Jun 25, 2021
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my thesis if you're curious or if you're looking for info I haven't documented. Mostly I would recommend giving a quick look to the figures beyond the introduction.
 38.5k Jan 3, 2023
38.5k Jan 3, 2023
Craxk is a SINGLE AND NON-REPLICABLE Hash that uses data from the hardware where it is executed to form a hash that can only be reproduced by a single machine.
What is Craxk ? Craxk is a UNIQUE AND NON-REPLICABLE Hash that uses data from the hardware where it is executed to form a hash that can only be reprod
 5 Jun 19, 2021
5 Jun 19, 2021
Sublime Text 2/3 style auto completion for ST4
Hippie Autocompletion Sublime Text 2/3 style auto completion for ST4: cycle through words, do not show popup. Simply hit Tab to insert completion, hit
 20 May 19, 2022
20 May 19, 2022
Rayvens makes it possible for data scientists to access hundreds of data services within Ray with little effort.
Rayvens augments Ray with events. With Rayvens, Ray applications can subscribe to event streams, process and produce events. Rayvens leverages Apache
 32 Dec 25, 2022
32 Dec 25, 2022

Official Pytorch Implementation of: "Semantic Diversity Learning for Zero-Shot Multi-label Classification"(2021) paper
Semantic Diversity Learning for Zero-Shot Multi-label Classification Paper Official PyTorch Implementation Avi Ben-Cohen, Nadav Zamir, Emanuel Ben Bar
 28 Aug 29, 2022
28 Aug 29, 2022
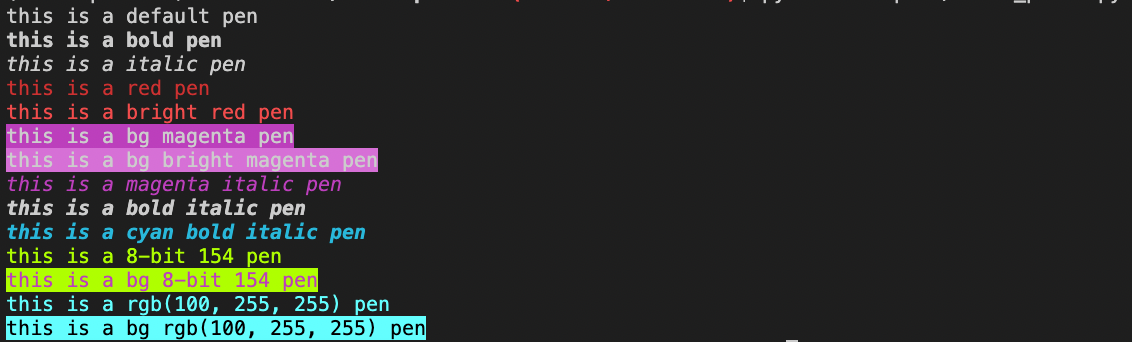
Print 'text color' and 'text format' on Term with Python
term-printer Print 'text color' and 'text format' on Term with Python ※ It may not work depending on the OS and shell used. PIP $ pip install term-pri
 10 Nov 12, 2022
10 Nov 12, 2022
A python to scratch API connector. Can fetch data from the API and send it back in cloud variables.
Scratch2py Scratch2py or S2py is a easy to use, versatile tool to communicate with the Scratch API Based of scratchclient by Raihan142857 Installation
 20 Jun 18, 2022
20 Jun 18, 2022

BRepNet: A topological message passing system for solid models
BRepNet: A topological message passing system for solid models This repository contains the an implementation of BRepNet: A topological message passin
 42 Dec 30, 2022
42 Dec 30, 2022
Migrate data from SQL to NoSQL easily
Migrate data from SQL to NoSQL easily Installation 💯 pip install sql2nosql --upgrade Dependencies 📢 For the package to work, it first needs "clients
 43 Mar 26, 2022
43 Mar 26, 2022

Pytorch implementation for "Implicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter".
Implicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter This is a pytorch-based implementation for paper Implicit Feature Alignme
 61 Nov 12, 2022
61 Nov 12, 2022

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
59 Dec 6, 2022
![[ICML 2021] Break-It-Fix-It: Learning to Repair Programs from Unlabeled Data](https://github.com/michiyasunaga/BIFI/raw/main/figs/task.png)
[ICML 2021] Break-It-Fix-It: Learning to Repair Programs from Unlabeled Data
Break-It-Fix-It: Learning to Repair Programs from Unlabeled Data This repo provides the source code & data of our paper: Break-It-Fix-It: Unsupervised
 86 Nov 30, 2022
86 Nov 30, 2022