1326 Repositories
Python text-extraction Libraries
Arabic-Phonetic-Output - You can input the phonetic version of any Arabic text here. This software will show you output in Arabic (with vowels)
Arabic-Phonetic-Output You can input the phonetic version of any Arabic text her
 1 Dec 30, 2021
1 Dec 30, 2021

Using the provided dataset which includes various book features, in order to predict the price of books, using various proposed methods and models.
Using the provided dataset which includes various book features, in order to predict the price of books, using various proposed methods and models.
 1 Jan 13, 2022
1 Jan 13, 2022
2021 AI CUP Competition on Traditional Chinese Scene Text Recognition - Intermediate Contest
繁體中文場景文字辨識 程式碼說明 組別:這就是我 成員:蔣明憲 唐碩謙 黃玥菱 林冠霆 蕭靖騰 目錄 環境套件 安裝方式 資料夾布局 前處理-製作偵測訓練註解檔 前處理-製作分類訓練樣本 part.py : 從 json 裁切出分類訓練樣本 Class.py : 將切出來的樣本按照文字分類到各資料夾
 3 Jan 14, 2022
3 Jan 14, 2022
Text mining project; Using distilBERT to predict authors in the classification task authorship attribution.
DistilBERT-Text-mining-authorship-attribution Dataset used: https://www.kaggle.com/azimulh/tweets-data-for-authorship-attribution-modelling/version/2
 1 Jan 13, 2022
1 Jan 13, 2022
Image-generation-baseline - MUGE Text To Image Generation Baseline
MUGE Text To Image Generation Baseline Requirements and Installation More detail
 23 Oct 17, 2022
23 Oct 17, 2022
BERN2: an advanced neural biomedical namedentity recognition and normalization tool
BERN2 We present BERN2 (Advanced Biomedical Entity Recognition and Normalization), a tool that improves the previous neural network-based NER tool by
 20 Jan 13, 2022
20 Jan 13, 2022
PyTorch code for JEREX: Joint Entity-Level Relation Extractor
JEREX: "Joint Entity-Level Relation Extractor" PyTorch code for JEREX: "Joint Entity-Level Relation Extractor". For a description of the model and exp
 50 Dec 1, 2022
50 Dec 1, 2022

Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021)
TDEER 🦌 🦒 Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021) Overview TDEE
 33 Dec 23, 2022
33 Dec 23, 2022

Vector Quantized Diffusion Model for Text-to-Image Synthesis
Vector Quantized Diffusion Model for Text-to-Image Synthesis Due to company policy, I have to set microsoft/VQ-Diffusion to private for now, so I prov
 294 Jan 5, 2023
294 Jan 5, 2023

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
A menu for pygame. Simple, and easy to use
pygame-menu Source repo on GitHub, and run it on Repl.it Introduction Pygame-menu is a python-pygame library for creating menus and GUIs. It supports
 411 Dec 27, 2022
411 Dec 27, 2022
👄 The most accurate natural language detection library for Python, suitable for long and short text alike
1. What does this library do? Its task is simple: It tells you which language some provided textual data is written in. This is very useful as a prepr
 334 Dec 30, 2022
334 Dec 30, 2022
A Telegram bot written in python.
telegram_bot This bot is currently a beta project. Features A telegram bot which can: Send current COVID-19 cases/stats of Germany Send current worth
 1 Jan 11, 2022
1 Jan 11, 2022
Multi-Stage Episodic Control for Strategic Exploration in Text Games
XTX: eXploit - Then - eXplore Requirements First clone this repo using git clone https://github.com/princeton-nlp/XTX.git Please create two conda envi
 9 May 24, 2022
9 May 24, 2022

Large scale PTM - PPI relation extraction
Large-scale protein-protein post-translational modification extraction with distant supervision and confidence calibrated BioBERT The silver standard
 1 Feb 25, 2022
1 Feb 25, 2022
HuSpaCy: industrial-strength Hungarian natural language processing
HuSpaCy: Industrial-strength Hungarian NLP HuSpaCy is a spaCy model and a library providing industrial-strength Hungarian language processing faciliti
 120 Dec 14, 2022
120 Dec 14, 2022
BERN2: an advanced neural biomedical namedentity recognition and normalization tool
BERN2 We present BERN2 (Advanced Biomedical Entity Recognition and Normalization), a tool that improves the previous neural network-based NER tool by
13 Jan 11, 2022
This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents".
Introduction This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents". If
 0 Jan 11, 2022
0 Jan 11, 2022
Source code for the plant extraction workflow introduced in the paper “Agricultural Plant Cataloging and Establishment of a Data Framework from UAV-based Crop Images by Computer Vision”
Plant extraction workflow Source code for the plant extraction workflow introduced in the paper "Agricultural Plant Cataloging and Establishment of a
 0 Apr 22, 2022
0 Apr 22, 2022
Towards Boosting the Accuracy of Non-Latin Scene Text Recognition
Convolutional Recurrent Neural Network + CTCLoss | STAR-Net Code for paper "Towards Boosting the Accuracy of Non-Latin Scene Text Recognition" Depende
 7 Aug 7, 2022
7 Aug 7, 2022
Creating a python chatbot that Starbucks users can text to place an order + help cut wait time of a normal coffee.
Creating a python chatbot that Starbucks users can text to place an order + help cut wait time of a normal coffee.
 2 Jan 20, 2022
2 Jan 20, 2022
This is an AI that is supposed to say you if your text is formal or not
This is an AI that is supposed to say you if your text is formal or not. It's written in Python 3 and has some german examples (because I'm german yk) in the text.json file. This file contains the text which the AI. The TXT-file isn't important but necessary.
 1 Jan 12, 2022
1 Jan 12, 2022
Send SMS text messages via email with as many accounts as you want :)
SMS-Spammer Send SMS text messages via email with as many accounts as you want :) Example Set Up Guide! To start log into the gmail account you would
 10 Oct 25, 2022
10 Oct 25, 2022

Text classification on IMDB dataset using Keras and Bi-LSTM network
Text classification on IMDB dataset using Keras and Bi-LSTM Text classification on IMDB dataset using Keras and Bi-LSTM network. Usage python3 main.py
 2 Sep 27, 2022
2 Sep 27, 2022
A text file containing 479k English words for all your dictionary/word-based projects e.g: auto-completion / autosuggestion
List Of English Words A text file containing over 466k English words. While searching for a list of english words (for an auto-complete tutorial) I fo
 8.5k Jan 3, 2023
8.5k Jan 3, 2023
Natural Language Processing Best Practices & Examples
NLP Best Practices In recent years, natural language processing (NLP) has seen quick growth in quality and usability, and this has helped to drive bus
 6.1k Dec 31, 2022
6.1k Dec 31, 2022

macOS development environment setup: Setting up a new developer machine can be an ad-hoc, manual, and time-consuming process.
dev-setup Motivation Setting up a new developer machine can be an ad-hoc, manual, and time-consuming process. dev-setup aims to simplify the process w
 5.9k Jan 2, 2023
5.9k Jan 2, 2023

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022

Moji sends text and fun facts from different APIs wit da use of a notification deamon
Moji sends text and fun facts from different APIs wit da use of a notification deamon. Can be runned via dmenu or rofi.
 2 Jan 12, 2022
2 Jan 12, 2022

Text editor on python to convert english text to malayalam(Romanization/Transiteration).
Manglish Text Editor This is a simple transiteration (romanization ) program which is used to convert manglish to malayalam (converts njaan to ഞാൻ ).
 1 May 11, 2022
1 May 11, 2022
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022

DeltaPy - Tabular Data Augmentation (by @firmai)
DeltaPy — Tabular Data Augmentation & Feature Engineering Finance Quant Machine Learning ML-Quant.com - Automated Research Repository Introduction T
 470 Dec 28, 2022
470 Dec 28, 2022
Algorithms for outlier, adversarial and drift detection
Alibi Detect is an open source Python library focused on outlier, adversarial and drift detection. The package aims to cover both online and offline d
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
An intuitive library to extract features from time series
Time Series Feature Extraction Library Intuitive time series feature extraction This repository hosts the TSFEL - Time Series Feature Extraction Libra
 589 Jan 4, 2023
589 Jan 4, 2023
Highly comparative time-series analysis
〰️ hctsa 〰️ : highly comparative time-series analysis hctsa is a software package for running highly comparative time-series analysis using Matlab (fu
 569 Dec 21, 2022
569 Dec 21, 2022

Speech to text streamlit app
Speech to text Streamlit-app! 👄 This speech to text recognition is powered by t
 9 Jan 1, 2023
9 Jan 1, 2023
Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi.
Spchcat Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi. Description spchcat is a command-line tool that read
 279 Jan 3, 2023
279 Jan 3, 2023
A Practitioner's Guide to Natural Language Processing
Learn how to process, classify, cluster, summarize, understand syntax, semantics and sentiment of text data with the power of Python! This repository contains code and datasets used in my book, Text Analytics with Python published by Apress/Springer.
 1.5k Jan 3, 2023
1.5k Jan 3, 2023
A list of NLP(Natural Language Processing) tutorials
NLP Tutorial A list of NLP(Natural Language Processing) tutorials built on PyTorch. Table of Contents A step-by-step tutorial on how to implement and
 1.3k Dec 25, 2022
1.3k Dec 25, 2022
Beancount: Double-Entry Accounting from Text Files.
beancount: Double-Entry Accounting from Text Files Contents Description Documentation Download & Installation Versions Filing Bugs Copyright and Licen
 2.3k Dec 28, 2022
2.3k Dec 28, 2022
Free and open source qualitative research tool
Taguette A spin on the phrase "tag it!", Taguette is a free and open source qualitative research tool that allows users to: Import PDFs, Word Docs (.d
 48 Jan 2, 2023
48 Jan 2, 2023

Graphical Password Authentication System.
Graphical Password Authentication System. This is used to increase the protection/security of a website. Our system is divided into further 4 layers of protection. Each layer is totally different and diverse than the others. This not only increases protection, but also makes sure that no non-human can log in to your account using different activities such as Brute Force Algorithm and so on.
 12 Dec 16, 2022
12 Dec 16, 2022
BERN2: an advanced neural biomedical namedentity recognition and normalization tool
BERN2 We present BERN2 (Advanced Biomedical Entity Recognition and Normalization
99 Jan 6, 2023
Text and code for the forthcoming second edition of Think Bayes, by Allen Downey.
Think Bayes 2 by Allen B. Downey The HTML version of this book is here. Think Bayes is an introduction to Bayesian statistics using computational meth
 1.5k Jan 8, 2023
1.5k Jan 8, 2023
Diff Match Patch is a high-performance library in multiple languages that manipulates plain text.
The Diff Match and Patch libraries offer robust algorithms to perform the operations required for synchronizing plain text. Diff: Compare two blocks o
 5.9k Dec 30, 2022
5.9k Dec 30, 2022

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023
NLP techniques such as named entity recognition, sentiment analysis, topic modeling, text classification with Python to predict sentiment and rating of drug from user reviews.
This file contains the following documents sumbited for Baruch CIS9665 group 9 fall 2021. 1. Dataset: drug_reviews.csv 2. python codes for text classi
 2 Jan 4, 2023
2 Jan 4, 2023

Textual: a TUI (Text User Interface) framework for Python inspired by modern web development
Textual Textual is a TUI (Text User Interface) framework for Python inspired by
 17.1k Jan 4, 2023
17.1k Jan 4, 2023

End-to-End text sumarization, QAs generation using flask.
Help-Me-Read A web application created with Flask + BootStrap + HuggingFace 🤗 to generate summary and question-answer from given input text. It uses
 12 Nov 13, 2022
12 Nov 13, 2022

👑 spaCy building blocks and visualizers for Streamlit apps
spacy-streamlit: spaCy building blocks for Streamlit apps This package contains utilities for visualizing spaCy models and building interactive spaCy-
 620 Dec 29, 2022
620 Dec 29, 2022

A simple component to display annotated text in Streamlit apps.
Annotated Text Component for Streamlit A simple component to display annotated text in Streamlit apps. For example: Installation First install Streaml
 312 Dec 30, 2022
312 Dec 30, 2022

Understand Text Summarization and create your own summarizer in python
Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document. Technologies that can make a coherent summary take into account variables such as length, writing style and syntax.
 1 Oct 18, 2022
1 Oct 18, 2022

This repository contains datasets and baselines for benchmarking Chinese text recognition.
Benchmarking-Chinese-Text-Recognition This repository contains datasets and baselines for benchmarking Chinese text recognition. Please see the corres
 254 Dec 30, 2022
254 Dec 30, 2022
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss This repository implements the SAFL in pytorch. Installation conda env create -f environm
 6 Aug 24, 2022
6 Aug 24, 2022

RodoSol-ALPR Dataset
RodoSol-ALPR Dataset This dataset, called RodoSol-ALPR dataset, contains 20,000 images captured by static cameras located at pay tolls owned by the Ro
 45 Dec 15, 2022
45 Dec 15, 2022

Two-stage text summarization with BERT and BART
Two-Stage Text Summarization Description We experiment with a 2-stage summarization model on CNN/DailyMail dataset that combines the ability to filter
 6 Oct 22, 2022
6 Oct 22, 2022
STEFANN: Scene Text Editor using Font Adaptive Neural Network
STEFANN: Scene Text Editor using Font Adaptive Neural Network @ The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2020.
 208 Dec 11, 2022
208 Dec 11, 2022

A unified framework to jointly model images, text, and human attention traces.
connect-caption-and-trace This repository contains the reference code for our paper Connecting What to Say With Where to Look by Modeling Human Attent
 73 Oct 24, 2022
73 Oct 24, 2022
Character Grounding and Re-Identification in Story of Videos and Text Descriptions
Character in Story Identification Network (CiSIN) This project hosts the code for our paper. Youngjae Yu, Jongseok Kim, Heeseung Yun, Jiwan Chung and
 8 Dec 9, 2022
8 Dec 9, 2022
Moer Grounded Image Captioning by Distilling Image-Text Matching Model
Moer Grounded Image Captioning by Distilling Image-Text Matching Model Requirements Python 3.7 Pytorch 1.2 Prepare data Please use git clone --recurse
 60 Dec 16, 2022
60 Dec 16, 2022
Python-Text-editor: a simple text editor on Python and Tkinter
Python-Text-editor This is a simple text editor on Python and Tkinter. The proje
 1 Jan 3, 2022
1 Jan 3, 2022
Text Summarization - WCN — Weighted Contextual N-gram method for evaluation of Text Summarization
Text Summarization WCN — Weighted Contextual N-gram method for evaluation of Text Summarization In this project, I fine tune T5 model on Extreme Summa
 1 Jan 3, 2022
1 Jan 3, 2022
Boamp-extractor - Script d'extraction des AOs publiés au BOAMP
BOAMP Extractor BOAMP-Extractor permet d'extraire les offres de marchés publics publiées au bulletin officiel des annonces des marchés publics (BOAMP)
 3 Dec 9, 2022
3 Dec 9, 2022
DeepSpeech - Easy-to-use Speech Toolkit including SOTA ASR pipeline, influential TTS with text frontend and End-to-End Speech Simultaneous Translation.
(简体中文|English) Quick Start | Documents | Models List PaddleSpeech is an open-source toolkit on PaddlePaddle platform for a variety of critical tasks i
 5.6k Jan 3, 2023
5.6k Jan 3, 2023
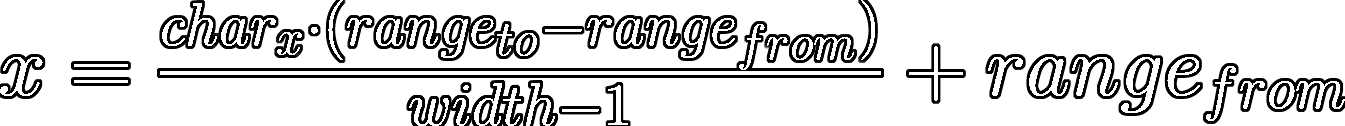
Glyph-graph - A simple, yet versatile, package for graphing equations on a 2-dimensional text canvas
Glyth Graph Revision for 0.01 A simple, yet versatile, package for graphing equations on a 2-dimensional text canvas List of contents: Brief Introduct
 2 Oct 21, 2022
2 Oct 21, 2022
NFT-Price-Prediction-CNN - Using visual feature extraction, prices of NFTs are predicted via CNN (Alexnet and Resnet) architectures.
NFT-Price-Prediction-CNN - Using visual feature extraction, prices of NFTs are predicted via CNN (Alexnet and Resnet) architectures.
 5 Nov 3, 2022
5 Nov 3, 2022
Skype export archive to text converter for python
Skype export archive to text converter This software utility extracts chat logs
 2 Jun 30, 2022
2 Jun 30, 2022

Augmented CLIP - Training simple models to predict CLIP image embeddings from text embeddings, and vice versa.
Train aug_clip against laion400m-embeddings found here: https://laion.ai/laion-400-open-dataset/ - note that this used the base ViT-B/32 CLIP model. S
 55 Sep 13, 2022
55 Sep 13, 2022

Ascify-Art - An easy to use, GUI based and user-friendly colored ASCII art generator from images!
Ascify-Art This is a python based colored ASCII art generator for free! How to Install? You can download and use the python version if you want, modul
 14 Dec 31, 2022
14 Dec 31, 2022
Png-to-stl - Converts PNG and text to SVG, and then extrudes that based on parameters
have ansible installed locally run ansible-playbook setup_application.yml this sets up directories, installs system packages, and sets up python envir
 1 Jan 3, 2022
1 Jan 3, 2022

AutoGluon: AutoML for Text, Image, and Tabular Data
AutoML for Text, Image, and Tabular Data AutoGluon automates machine learning tasks enabling you to easily achieve strong predictive performance in yo
 5.2k Dec 29, 2022
5.2k Dec 29, 2022

A supercharged version of paperless: scan, index and archive all your physical documents
Paperless-ng Paperless (click me) is an application by Daniel Quinn and contributors that indexes your scanned documents and allows you to easily sear
 5.3k Jan 9, 2023
5.3k Jan 9, 2023

50-days-of-Statistics-for-Data-Science - This repository consist of a 50-day program
50-days-of-Statistics-for-Data-Science - This repository consist of a 50-day program. All the statistics required for the complete understanding of data science will be uploaded in this repository.
 22 Dec 9, 2022
22 Dec 9, 2022
Vector space based Information Retrieval System for Text Processing - Information retrieval
Information Retrieval: Text Processing Group 13 Sequence of operations Install Requirements Add given wikipedia files to the corpus directory. Downloa
 1 Jan 1, 2022
1 Jan 1, 2022

Siamese-nn-semantic-text-similarity - A repository containing comprehensive Neural Networks based PyTorch implementations for the semantic text similarity task
Siamese Deep Neural Networks for Semantic Text Similarity PyTorch A repository c
 32 Dec 15, 2022
32 Dec 15, 2022
This can be use to convert text in a file to handwritten text.
TextToHandwriting This can be used to convert text to handwriting. Clone this project or download the code. Run TextToImage.py give the filename of th
 2 Feb 6, 2022
2 Feb 6, 2022

TransPrompt - Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification
TransPrompt This code is implement for our EMNLP 2021's paper 《TransPrompt:Towards an Automatic Transferable Prompting Framework for Few-shot Text Cla
 23 Dec 21, 2022
23 Dec 21, 2022
MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
MixText This repo contains codes for the following paper: Jiaao Chen, Zichao Yang, Diyi Yang: MixText: Linguistically-Informed Interpolation of Hidden
 309 Dec 12, 2022
309 Dec 12, 2022
Implementation of ICLR 2020 paper "Revisiting Self-Training for Neural Sequence Generation"
Self-Training for Neural Sequence Generation This repo includes instructions for running noisy self-training algorithms from the following paper: Revi
 45 Dec 31, 2022
45 Dec 31, 2022
Personal implementation of paper "Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval"
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval This repo provides personal implementation of paper Approximate Ne
 8 Oct 7, 2022
8 Oct 7, 2022

A minimal and ridiculously good looking command-line-interface toolkit
Proper CLI Proper CLI is a Python package for creating beautiful, composable, and ridiculously good looking command-line-user-interfaces without havin
 2 Dec 22, 2022
2 Dec 22, 2022
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. ocrmypdf
 8k Jan 8, 2023
8k Jan 8, 2023

Encode and decode text application
Text Encoder and Decoder Encode and decode text in many ways using this application! Encode in: ASCII85 Base85 Base64 Base32 Base16 Url MD5 Hash SHA-1
 1 Feb 12, 2022
1 Feb 12, 2022
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022

A Python parser that takes the content of a text file and then reads it into variables.
Text-File-Parser A Python parser that takes the content of a text file and then reads into variables. Input.text File 1. What is your ***? 1. 18 -
 0 Jul 26, 2021
0 Jul 26, 2021

Text to Binary Converter
Text to Binary Converter Programmed in Python | PySimpleGUI If you like it give it a star How it works Simple text to binary and binary to text conver
 11 Dec 6, 2022
11 Dec 6, 2022
A markdown extension for converting Leiden+ epigraphic text to TEI XML/HTML
LeidenMark $ pip install leidenmark A Python Markdown extension for converting Leiden+ epigraphic text to TEI XML/HTML. Inspired by the Brill plain te
 2 Aug 4, 2021
2 Aug 4, 2021

🇰🇷 Text to Image in Korean
KoDALLE Utilizing pretrained language model’s token embedding layer and position embedding layer as DALLE’s text encoder. Background Training DALLE mo
 74 Sep 22, 2022
74 Sep 22, 2022

Align and Prompt: Video-and-Language Pre-training with Entity Prompts
ALPRO Align and Prompt: Video-and-Language Pre-training with Entity Prompts [Paper] Dongxu Li, Junnan Li, Hongdong Li, Juan Carlos Niebles, Steven C.H
 127 Dec 21, 2022
127 Dec 21, 2022
Artificial intelligence technology inferring issues and logically supporting facts from raw text
개요 비정형 텍스트를 학습하여 쟁점별 사실과 논리적 근거 추론이 가능한 인공지능 원천기술 Artificial intelligence techno
 6 Dec 29, 2021
6 Dec 29, 2021

A tool combining EasyOCR and LaMa to automatically detect text and replace it with an inpainted background.
EasyLaMa (WIP) This is a tool combining EasyOCR and LaMa to automatically detect text and replace it with an inpainted background. Installation For GP
 3 Sep 17, 2022
3 Sep 17, 2022

Scene-Text-Detection-and-Recognition (Pytorch)
Scene-Text-Detection-and-Recognition (Pytorch) Competition URL: https://tbrain.t
 9 Jan 2, 2023
9 Jan 2, 2023
Transformation spoken text to written text
Transformation spoken text to written text This model is used for formatting raw asr text output from spoken text to written text (Eg. date, number, i
 16 Dec 28, 2022
16 Dec 28, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 1.1k Jan 2, 2023
1.1k Jan 2, 2023
nlpcommon is a python Open Source Toolkit for text classification.
nlpcommon nlpcommon, Python Text Tool. Guide Feature Install Usage Dataset Contact Cite Reference Feature nlpcommon is a python Open Source
 3 May 29, 2022
3 May 29, 2022
Extract city and country mentions from Text like GeoText without regex, but FlashText, a Aho-Corasick implementation.
flashgeotext ⚡ 🌍 Extract and count countries and cities (+their synonyms) from text, like GeoText on steroids using FlashText, a Aho-Corasick impleme
 57 Dec 16, 2022
57 Dec 16, 2022

OpenAI CLIP text encoders for multiple languages!
Multilingual-CLIP OpenAI CLIP text encoders for any language Colab Notebook · Pre-trained Models · Report Bug Overview OpenAI recently released the pa
 481 Dec 30, 2022
481 Dec 30, 2022
This is a telegram bot help you to get stylish fonts and text.
Stylish Font Bot 🐿 This is a telegram bot help you to get stylish fonts and text. Deploy to heroku 🗳 Press the button Deploy to heroku and give the
 0 Apr 8, 2022
0 Apr 8, 2022
Adventura is an open source Python Text Adventure Engine
Adventura Adventura is an open source Python Text Adventure Engine, Not yet uplo
 5 Oct 2, 2022
5 Oct 2, 2022
API to summarize input text
summaries API to summarize input text normal run $ docker-compose exec web python -m pytest disable warnings $ docker-compose exec web python -m pytes
 1 Sep 8, 2021
1 Sep 8, 2021