1049 Repositories
Python video-face-extractor Libraries
Brief idea about our project is mentioned in project presentation file.
Brief idea about our project is mentioned in project presentation file. You just have to run attendance.py file in your suitable IDE but we prefer jupyter lab.
 3 Mar 20, 2022
3 Mar 20, 2022

Vignette is a face tracking software for characters using osu!framework.
Vignette is a face tracking software for characters using osu!framework. Unlike most solutions, Vignette is: Made with osu!framework, the game framewo
 412 Dec 28, 2022
412 Dec 28, 2022

MoViNets PyTorch implementation: Mobile Video Networks for Efficient Video Recognition;
MoViNet-pytorch Pytorch unofficial implementation of MoViNets: Mobile Video Networks for Efficient Video Recognition. Authors: Dan Kondratyuk, Liangzh
 189 Dec 20, 2022
189 Dec 20, 2022
4D Human Body Capture from Egocentric Video via 3D Scene Grounding
4D Human Body Capture from Egocentric Video via 3D Scene Grounding [Project] [Paper] Installation: Our method requires the same dependencies as SMPLif
 37 Nov 8, 2022
37 Nov 8, 2022

A Python script that creates subtitles of a given length from text paragraphs that can be easily imported into any Video Editing software such as FinalCut Pro for further adjustments.
Text to Subtitles - Python This python file creates subtitles of a given length from text paragraphs that can be easily imported into any Video Editin
 9 Dec 24, 2022
9 Dec 24, 2022
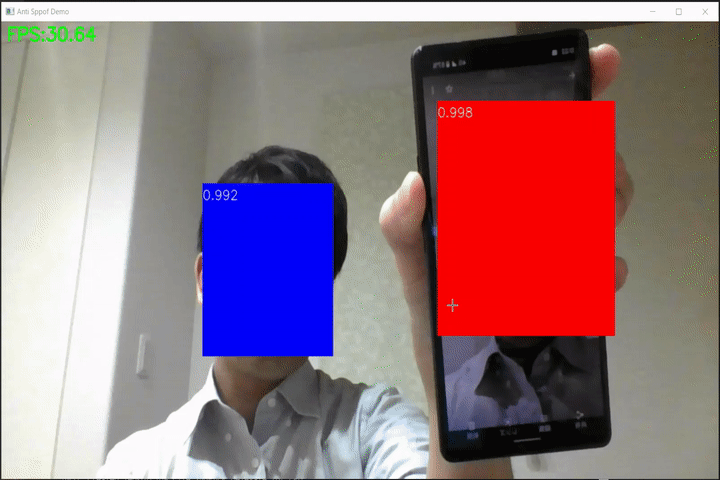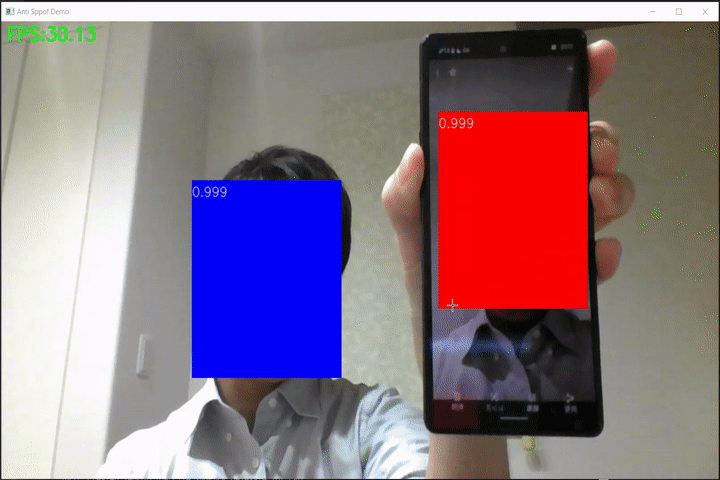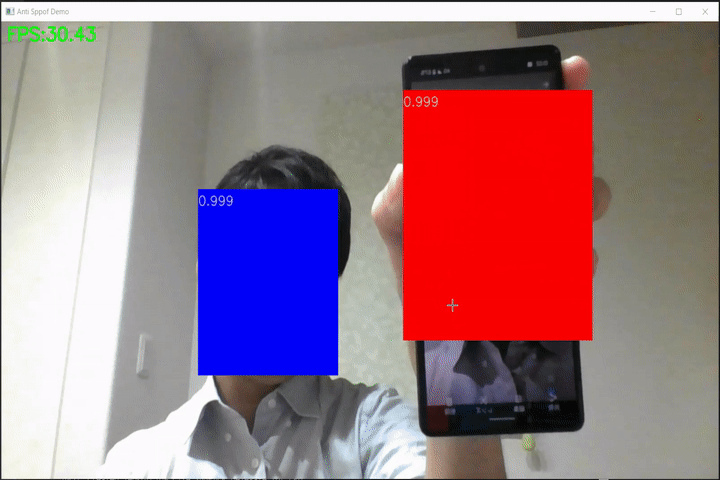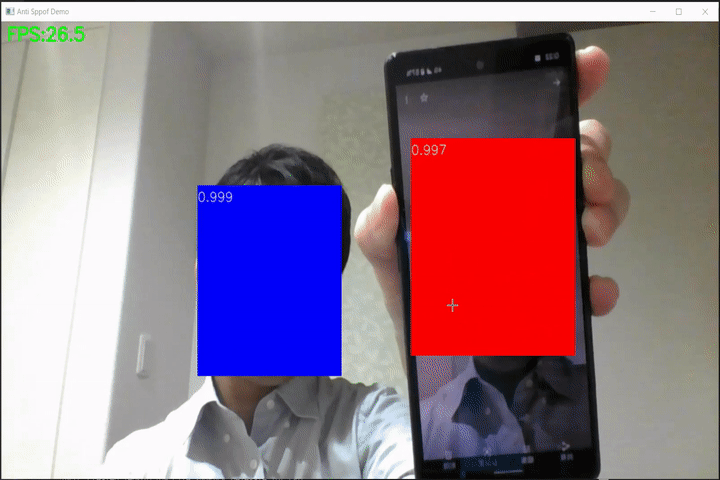
なりすまし検出(anti-spoof-mn3)のWebカメラ向けデモ
FaceDetection-Anti-Spoof-Demo なりすまし検出(anti-spoof-mn3)のWebカメラ向けデモです。 モデルはPINTO_model_zoo/191_anti-spoof-mn3からONNX形式のモデルを使用しています。 Requirement mediapipe
 8 Nov 18, 2022
8 Nov 18, 2022
Flappy Bird clone utilizing facial recognition to move the
Flappy Face Flappy Bird clone utilizing facial recognition to move the "bird" How it works Flappy Face uses Facial Recognition to detect your face's p
 1 Jan 11, 2022
1 Jan 11, 2022
Video Frame Interpolation without Temporal Priors (a general method for blurry video interpolation)
Video Frame Interpolation without Temporal Priors (NeurIPS2020) [Paper] [video] How to run Prerequisites NVIDIA GPU + CUDA 9.0 + CuDNN 7.6.5 Pytorch 1
 31 Sep 4, 2022
31 Sep 4, 2022

Code for the paper "Controllable Video Captioning with an Exemplar Sentence"
SMCG Code for the paper "Controllable Video Captioning with an Exemplar Sentence" Introduction We investigate a novel and challenging task, namely con
 10 Dec 4, 2022
10 Dec 4, 2022
A PyTorch Implementation of PGL-SUM from "Combining Global and Local Attention with Positional Encoding for Video Summarization", Proc. IEEE ISM 2021
PGL-SUM: Combining Global and Local Attention with Positional Encoding for Video Summarization PyTorch Implementation of PGL-SUM From "PGL-SUM: Combin
 35 Dec 22, 2022
35 Dec 22, 2022
A PyTorch Toolbox for Face Recognition
FaceX-Zoo FaceX-Zoo is a PyTorch toolbox for face recognition. It provides a training module with various supervisory heads and backbones towards stat
 1.1k Dec 3, 2021
1.1k Dec 3, 2021
A Telegram Video Watermark Adder Bot
Watermark-Bot A Telegram Video Watermark Adder Bot by @VideosWaterMarkRobot Features: Save Custom Watermark Image. Auto Resize Watermark According to
 5 Jun 17, 2022
5 Jun 17, 2022

Artstation-Artistic-face-HQ Dataset (AAHQ)
Artstation-Artistic-face-HQ Dataset (AAHQ) Artstation-Artistic-face-HQ (AAHQ) is a high-quality image dataset of artistic-face images. It is proposed
 105 Dec 16, 2022
105 Dec 16, 2022
A Light CNN for Deep Face Representation with Noisy Labels
A Light CNN for Deep Face Representation with Noisy Labels Citation If you use our models, please cite the following paper: @article{wulight, title=
 715 Nov 5, 2022
715 Nov 5, 2022
Code & Models for Temporal Segment Networks (TSN) in ECCV 2016
Temporal Segment Networks (TSN) We have released MMAction, a full-fledged action understanding toolbox based on PyTorch. It includes implementation fo
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

Unofficial PyTorch Implementation for HifiFace (https://arxiv.org/abs/2106.09965)
HifiFace — Unofficial Pytorch Implementation Image source: HifiFace: 3D Shape and Semantic Prior Guided High Fidelity Face Swapping (figure 1, pg. 1)
 218 Jan 4, 2023
218 Jan 4, 2023
Media Replay Engine (MRE) is a framework to build automated video clipping and replay (highlight) generation pipelines for live and video-on-demand content.
Media Replay Engine (MRE) is a framework for building automated video clipping and replay (highlight) generation pipelines using AWS services for live
 30 Nov 29, 2022
30 Nov 29, 2022
Revisiting Temporal Alignment for Video Restoration
Revisiting Temporal Alignment for Video Restoration [arXiv] Kun Zhou, Wenbo Li, Liying Lu, Xiaoguang Han, Jiangbo Lu We provide our results at Google
 52 Dec 25, 2022
52 Dec 25, 2022
Camera Distortion-aware 3D Human Pose Estimation in Video with Optimization-based Meta-Learning
Camera Distortion-aware 3D Human Pose Estimation in Video with Optimization-based Meta-Learning This is the official repository of "Camera Distortion-
 12 Oct 6, 2022
12 Oct 6, 2022

PySlowFast: video understanding codebase from FAIR for reproducing state-of-the-art video models.
PySlowFast PySlowFast is an open source video understanding codebase from FAIR that provides state-of-the-art video classification models with efficie
 5.3k Jan 3, 2023
5.3k Jan 3, 2023

Face Recognition Attendance Project
Face-Recognition-Attendance-Project In This Project You will learn how to mark attendance using face recognition, Hello Guys This is Gautam Kumar, Thi
 1 Dec 3, 2022
1 Dec 3, 2022

SFD implement with pytorch
S³FD: Single Shot Scale-invariant Face Detector A PyTorch Implementation of Single Shot Scale-invariant Face Detector Description Meanwhile train hand
 251 Dec 22, 2022
251 Dec 22, 2022

Official implementation of Pixel-Level Bijective Matching for Video Object Segmentation
BMVOS This is the official implementation of Pixel-Level Bijective Matching for Video Object Segmentation, to appear in WACV 2022. @article{cho2021pix
 13 Dec 14, 2022
13 Dec 14, 2022
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats
TG-MusicPlayer A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Py
 4 Dec 14, 2022
4 Dec 14, 2022
Official repository of "Investigating Tradeoffs in Real-World Video Super-Resolution"
RealBasicVSR [Paper] This is the official repository of "Investigating Tradeoffs in Real-World Video Super-Resolution, arXiv". This repository contain
 566 Dec 28, 2022
566 Dec 28, 2022

Real-time VIBE: Frame by Frame Inference of VIBE (Video Inference for Human Body Pose and Shape Estimation)
Real-time VIBE Inference VIBE frame-by-frame. Overview This is a frame-by-frame inference fork of VIBE at [https://github.com/mkocabas/VIBE]. Usage: i
 23 Jul 2, 2022
23 Jul 2, 2022
This is the face keypoint train code of project face-detection-project
face-key-point-pytorch 1. Data structure The structure of landmarks_jpg is like below: |--landmarks_jpg |----AFW |------AFW_134212_1_0.jpg |------AFW_
 3 Nov 27, 2022
3 Nov 27, 2022
Code from the 2021 Signal Video Superclass
Twilio Video Demo This is the code written during the live Twilio Video demo during Twilio's Signal 2021 Superclass. It creates a simple Video applica
 2 Oct 21, 2021
2 Oct 21, 2021
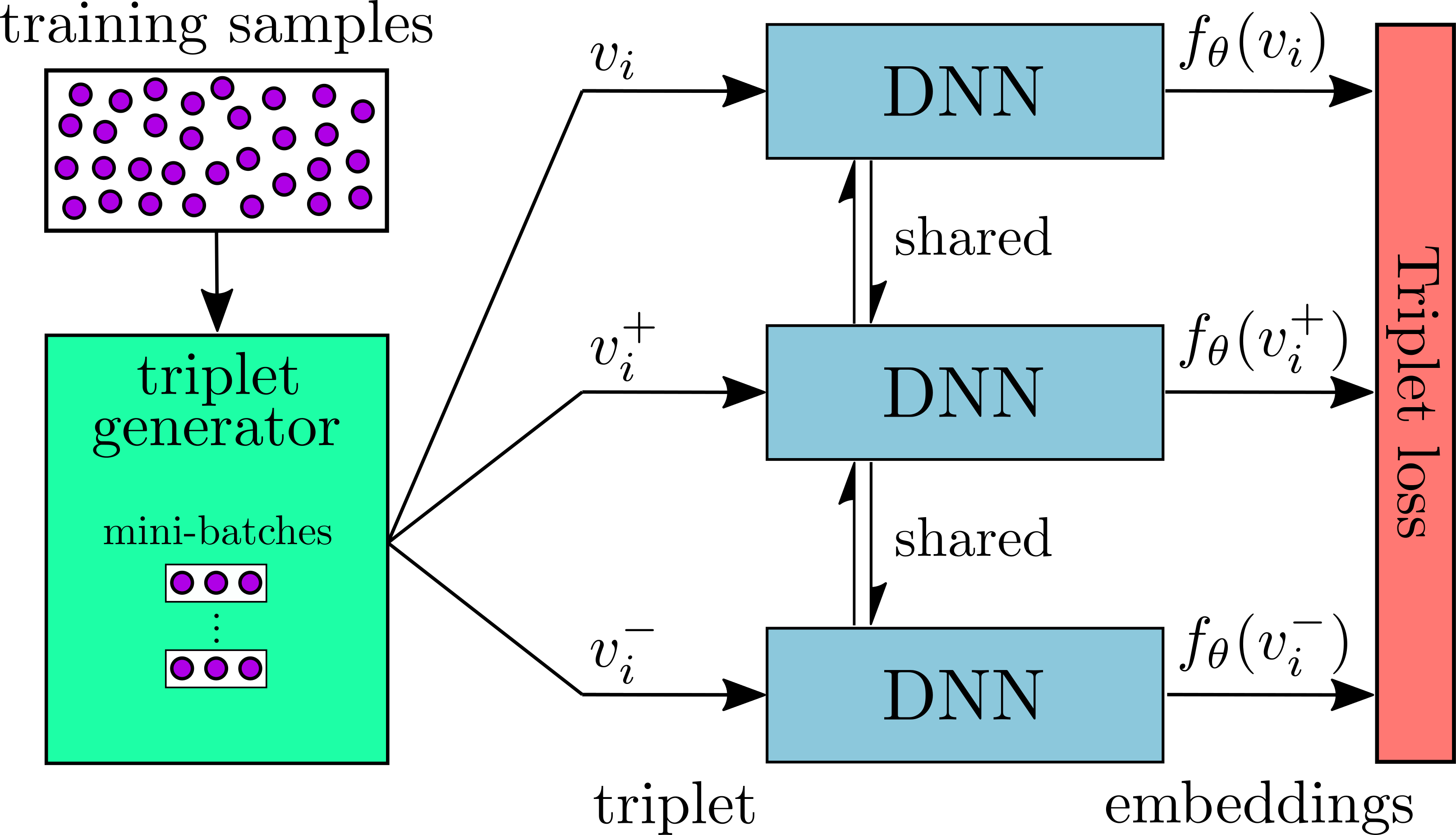
Near-Duplicate Video Retrieval with Deep Metric Learning
Near-Duplicate Video Retrieval with Deep Metric Learning This repository contains the Tensorflow implementation of the paper Near-Duplicate Video Retr
 2 Jan 24, 2022
2 Jan 24, 2022
This plugin generates json files used by deovr allowing you to play 2d and 3d video's using the player
deovr-plugin This plugin generates json files used by deovr allowing you to play 2d and 3d video's using the player. Deovr looks for an index file /de
 10 Sep 29, 2022
10 Sep 29, 2022
COIN the currently largest dataset for comprehensive instruction video analysis.
COIN Dataset COIN is the currently largest dataset for comprehensive instruction video analysis. It contains 11,827 videos of 180 different tasks (i.e
 86 Dec 28, 2022
86 Dec 28, 2022
End-to-End Referring Video Object Segmentation with Multimodal Transformers
End-to-End Referring Video Object Segmentation with Multimodal Transformers This repo contains the official implementation of the paper: End-to-End Re
 608 Dec 30, 2022
608 Dec 30, 2022

PyTorch code of paper "LiVLR: A Lightweight Visual-Linguistic Reasoning Framework for Video Question Answering"
LiVLR-VideoQA We propose a Lightweight Visual-Linguistic Reasoning framework (LiVLR) for VideoQA. The overview of LiVLR: Evaluation on MSRVTT-QA Datas
 7 Dec 30, 2022
7 Dec 30, 2022

A simple rest api serving a deep learning model that classifies human gender based on their faces. (vgg16 transfare learning)
this is a simple rest api serving a deep learning model that classifies human gender based on their faces. (vgg16 transfare learning)
 5 Dec 9, 2021
5 Dec 9, 2021

Python tools for 3D face: 3DMM, Mesh processing(transform, camera, light, render), 3D face representations.
face3d: Python tools for processing 3D face Introduction This project implements some basic functions related to 3D faces. You can use this to process
 2.3k Dec 30, 2022
2.3k Dec 30, 2022
🤖 Telegram UserBot Untuk Memutar Lagu Dan Video Di Obrolan Suara Telegram.
🤖 Telegram UserBot Untuk Memutar Lagu Dan Video Di Obrolan Suara Telegram.
 2 Nov 13, 2021
2 Nov 13, 2021
Facial detection, landmark tracking and expression transfer library for Windows, Linux and Mac
Welcome to the CSIRO Face Analysis SDK. Documentation for the SDK can be found in doc/documentation.html. All code in this SDK is provided according t
 7 Jul 16, 2020
7 Jul 16, 2020
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats.
VC UserBot A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Python
 1 Nov 29, 2021
1 Nov 29, 2021

Fake videos detection by tracing the source using video hashing retrieval.
Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake Videos 🎉️ 📜 Directory Introduction VTL Trace Samples and Acc of Hash
 56 Dec 22, 2022
56 Dec 22, 2022

✂️ EyeLipCropper is a Python tool to crop eyes and mouth ROIs of the given video.
EyeLipCropper EyeLipCropper is a Python tool to crop eyes and mouth ROIs of the given video. The whole process consists of three parts: frame extracti
 9 Oct 25, 2022
9 Oct 25, 2022
Telegram bot to stream videos in telegram voicechat for both groups and channels.
Telegram bot to stream videos in telegram voicechat for both groups and channels. Supports live streams, YouTube videos and telegram media. With record stream support, Schedule streams, and many more.
 4 Nov 13, 2022
4 Nov 13, 2022
Making a music video with Wav2CLIP and VQGAN-CLIP
music2video Overview A repo for making a music video with Wav2CLIP and VQGAN-CLIP. The base code was derived from VQGAN-CLIP The CLIP embedding for au
 163 Dec 26, 2022
163 Dec 26, 2022
Play Video & Music on Telegram Group Video Chat
🖤 DEMONGIRL 🖤 ʜᴇʟʟᴏ ❤️ 🇱🇰 Join us ᴠɪᴅᴇᴏ sᴛʀᴇᴀᴍ ɪs ᴀɴ ᴀᴅᴠᴀɴᴄᴇᴅ ᴛᴇʟᴇʀᴀᴍ ʙᴏᴛ ᴛʜᴀᴛ's ᴀʟʟᴏᴡ ʏᴏᴜ ᴛᴏ ᴘʟᴀʏ ᴠɪᴅᴇᴏ & ᴍᴜsɪᴄ ᴏɴ ᴛᴇʟᴇɢʀᴀᴍ ɢʀᴏᴜᴘ ᴠɪᴅᴇᴏ ᴄʜᴀᴛ 🧪 ɢ
 5 Dec 31, 2021
5 Dec 31, 2021

PFLD pytorch Implementation
PFLD-pytorch Implementation of PFLD A Practical Facial Landmark Detector by pytorch. 1. install requirements pip3 install -r requirements.txt 2. Datas
 669 Jan 2, 2023
669 Jan 2, 2023
alfred-py: A deep learning utility library for **human**
Alfred Alfred is command line tool for deep-learning usage. if you want split an video into image frames or combine frames into a single video, then a
 800 Jan 3, 2023
800 Jan 3, 2023

SMPL-X: A new joint 3D model of the human body, face and hands together
SMPL-X: A new joint 3D model of the human body, face and hands together [Paper Page] [Paper] [Supp. Mat.] Table of Contents License Description News I
 1k Jan 9, 2023
1k Jan 9, 2023

Deep Sketch-guided Cartoon Video Inbetweening
Cartoon Video Inbetweening Paper | DOI | Video The source code of Deep Sketch-guided Cartoon Video Inbetweening by Xiaoyu Li, Bo Zhang, Jing Liao, Ped
 37 Dec 22, 2022
37 Dec 22, 2022
A light and fast one class detection framework for edge devices. We provide face detector, head detector, pedestrian detector, vehicle detector......
A Light and Fast Face Detector for Edge Devices Big News: LFD, which is a big update of LFFD, now is released (2021.03.09). It is strongly recommended
 1.3k Dec 25, 2022
1.3k Dec 25, 2022
![Deep Video Matting via Spatio-Temporal Alignment and Aggregation [CVPR2021]](https://github.com/nowsyn/DVM/raw/master/figures/framework.png)
Deep Video Matting via Spatio-Temporal Alignment and Aggregation [CVPR2021]
Deep Video Matting via Spatio-Temporal Alignment and Aggregation [CVPR2021] Paper: https://arxiv.org/abs/2104.11208 Introduction Despite the significa
 76 Dec 7, 2022
76 Dec 7, 2022

Automatically align face images 🙃→🙂. Can also do windowing and warping.
Automatic Face Alignment (AFA) Carl M. Gaspar & Oliver G.B. Garrod You have lots of photos of faces like this: But you want to line up all of the face
 15 Dec 12, 2022
15 Dec 12, 2022
Simple nightcore song+video maker
nighty nighty is a simple nightcore song maker (+ video) Installation clone the repo wherever you want git clone https://www.github.com/DanyB0/nighty
 2 Oct 2, 2022
2 Oct 2, 2022
Convert Video Files To Text And Audio
Video-To-Text Convert Video Files To Text And Audio Convert To Audio 1: open dvtt folder in cmd 2: run this command in cmd = main.py Audio Convert To
 2 Dec 5, 2021
2 Dec 5, 2021

Attendance Monitoring with Face Recognition using Python
Attendance Monitoring with Face Recognition using Python A python GUI integrated attendance system using face recognition to take attendance. In this
 2 Jun 21, 2022
2 Jun 21, 2022

720p FPGA Media Player (RISC-V + Motion JPEG + SD + HDMI on an Artix 7)
FPGA Media Player This project is a FPGA based media player which is capable of playing Motion JPEG encoded video over HDMI or VGA on commonly availab
 179 Dec 2, 2022
179 Dec 2, 2022

A large-scale face dataset for face parsing, recognition, generation and editing.
CelebAMask-HQ [Paper] [Demo] CelebAMask-HQ is a large-scale face image dataset that has 30,000 high-resolution face images selected from the CelebA da
 1.7k Dec 26, 2022
1.7k Dec 26, 2022
Revisiting Video Saliency: A Large-scale Benchmark and a New Model (CVPR18, PAMI19)
DHF1K =========================================================================== Wenguan Wang, J. Shen, M.-M Cheng and A. Borji, Revisiting Video Sal
 126 Dec 3, 2022
126 Dec 3, 2022

CenterFace(size of 7.3MB) is a practical anchor-free face detection and alignment method for edge devices.
CenterFace Introduce CenterFace(size of 7.3MB) is a practical anchor-free face detection and alignment method for edge devices. Recent Update 2019.09.
 1.2k Dec 21, 2022
1.2k Dec 21, 2022

Source files for the data lake demo video using the AWS TICKIT database
Data Lake Demo Source code for video demonstration detailed in the post, Building a Simple Data Lake on AWS . Build a simple data lake on AWS using a
 97 Dec 23, 2022
97 Dec 23, 2022
Self-Regulated Learning for Egocentric Video Activity Anticipation
Self-Regulated Learning for Egocentric Video Activity Anticipation Introduction This is a Pytorch implementation of the model described in our paper:
 13 Sep 23, 2022
13 Sep 23, 2022
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis This is a PyTorch implementation of the model described in our pape
6 Jul 8, 2021
Official repository of "Investigating Tradeoffs in Real-World Video Super-Resolution"
RealBasicVSR [Paper] This is the official repository of "Investigating Tradeoffs in Real-World Video Super-Resolution, arXiv". This repository contain
566 Dec 28, 2022
A Telegram bot to convert videos into x265/x264 format via ffmpeg.
Video Encoder Bot A Telegram bot to convert videos into x265/x264 format via ffmpeg. Configuration Add values in environment variables or add them in
 1 Mar 8, 2022
1 Mar 8, 2022
Malicious Document IoC Extractor is a collection of scripts that helps extracting IoCs from various maldoc families.
MDIExtractor Malicious Document IoC Extractor (MDIExtractor) is a collection of scripts that helps extracting IoCs from various maldoc families. Prere
 14 Nov 25, 2022
14 Nov 25, 2022
OpenMMLab Video Perception Toolbox. It supports Video Object Detection (VID), Multiple Object Tracking (MOT), Single Object Tracking (SOT), Video Instance Segmentation (VIS) with a unified framework.
English | 简体中文 Documentation: https://mmtracking.readthedocs.io/ Introduction MMTracking is an open source video perception toolbox based on PyTorch.
 2.7k Jan 8, 2023
2.7k Jan 8, 2023
Apply AnimeGAN-v2 across frames of a video clip
title emoji colorFrom colorTo sdk app_file pinned AnimeGAN-v2 For Videos 🔥 blue red gradio app.py false AnimeGAN-v2 For Videos Apply AnimeGAN-v2 acro
 36 Oct 18, 2022
36 Oct 18, 2022
Face Recognition and Emotion Detector Device
Face Recognition and Emotion Detector Device Orange PI 1 Python 3.10.0 + Django 3.2.9 Project's file explanation Django manage.py Django commands hand
 2 Dec 21, 2021
2 Dec 21, 2021

Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
Expressive Body Capture: 3D Hands, Face, and Body from a Single Image [Project Page] [Paper] [Supp. Mat.] Table of Contents License Description Fittin
1.3k Jan 7, 2023

Weakly Supervised Dense Event Captioning in Videos, i.e. generating multiple sentence descriptions for a video in a weakly-supervised manner.
WSDEC This is the official repo for our NeurIPS paper Weakly Supervised Dense Event Captioning in Videos. Description Repo directories ./: global conf
 96 Nov 1, 2022
96 Nov 1, 2022
Tesla App Update Differences Extractor
Tesla App Update Differences Extractor Python program that finds the differences between two versions of the Tesla App. When Tesla updates the app a l
 5 Apr 11, 2022
5 Apr 11, 2022
Telegram Video Chat Video Streaming bot 🇱🇰
🧪 Get SESSION_NAME from below: Pyrogram 🎭 Preview ✨ Features Music & Video stream support MultiChat support Playlist & Queue support Skip, Pause, Re
 5 Jun 26, 2022
5 Jun 26, 2022
Pytorch implementation of "Geometrically Adaptive Dictionary Attack on Face Recognition" (WACV 2022)
Geometrically Adaptive Dictionary Attack on Face Recognition This is the Pytorch code of our paper "Geometrically Adaptive Dictionary Attack on Face R
 6 Nov 21, 2022
6 Nov 21, 2022
![Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency[ECCV 2020]](https://github.com/jiaxiangshang/MGCNet/raw/master/githubVisual/ECCV2020_Github.gif)
Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency[ECCV 2020]
Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency(ECCV 2020) This is an official python implementati
 304 Jan 3, 2023
304 Jan 3, 2023
![[AAAI2021] The source code for our paper 《Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion》.](https://github.com/FingerRec/DSM-decoupling-scene-motion/raw/main/figures/ppl.png)
[AAAI2021] The source code for our paper 《Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion》.
DSM The source code for paper Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion Project Website; Datasets li
 114 Oct 16, 2022
114 Oct 16, 2022
Posts locally saved videos to the desired subreddit
redditvideoposter posts locally saved videos to the desired subreddit ================================================================= STEPS: pip ins
 2 Dec 1, 2021
2 Dec 1, 2021

Face Recognition plus identification simply and fast | Python
PyFaceDetection Face Recognition plus identification simply and fast Ubuntu Setup sudo pip3 install numpy sudo pip3 install cmake sudo pip3 install dl
 16 Sep 22, 2022
16 Sep 22, 2022
A telegram bot for compressing/encoding videos in h264 format.
Video-Encoder-Bot a telegram bot for compressing/encoding videos in h264 format. Configuration Add values in environment variables or add them in conf
 61 Dec 29, 2022
61 Dec 29, 2022
Twitter bot to know the number of dislikes of a YouTube video
YT_dislikes is a twitter bot that allows you to know the number of dislikes (and likes) of a YouTube video. Now it is not possible to see the number o
 1 Jan 8, 2022
1 Jan 8, 2022
Source code and notebooks to reproduce experiments and benchmarks on Bias Faces in the Wild (BFW).
Face Recognition: Too Bias, or Not Too Bias? Robinson, Joseph P., Gennady Livitz, Yann Henon, Can Qin, Yun Fu, and Samson Timoner. "Face recognition:
 41 Dec 12, 2022
41 Dec 12, 2022
A denoising autoencoder + adversarial losses and attention mechanisms for face swapping.
faceswap-GAN Adding Adversarial loss and perceptual loss (VGGface) to deepfakes'(reddit user) auto-encoder architecture. Updates Date Update 2018-08-2
 3.2k Dec 30, 2022
3.2k Dec 30, 2022
Yet another video caption
Yet another video caption
 5 May 26, 2022
5 May 26, 2022
This bot can stream audio or video files and urls in telegram voice chats
Voice Chat Streamer This bot can stream audio or video files and urls in telegram voice chats :) 🎯 Follow me and star this repo for more telegram bot
 4 Oct 9, 2022
4 Oct 9, 2022

Image and video quality assessment
CenseoQoE: 视觉感知画质评价框架 项目介绍 图像/视频在编解码、传输和显示等过程中难免引入不同类型/程度的失真导致图像质量下降。图像/视频质量评价(IVQA)的研究目标是希望模仿人类视觉感知系统, 通过算法评估图片/视频在终端用户的眼中画质主观体验的好坏,目前在视频编解码、画质增强、画质监。
 133 Dec 20, 2022
133 Dec 20, 2022

Video Corpus Moment Retrieval with Contrastive Learning (SIGIR 2021)
Video Corpus Moment Retrieval with Contrastive Learning PyTorch implementation for the paper "Video Corpus Moment Retrieval with Contrastive Learning"
 42 Dec 29, 2022
42 Dec 29, 2022
TikTok downloader video without watermark from Telegram bot
⬇️ How to download video from Tik Tok via telegram bot? Send a link to the video from tik tok to our telegram bot and it will send you a video without
 1 Mar 4, 2022
1 Mar 4, 2022
Automatic video generator for local news
Automatic video generator for local news
 2 Jan 11, 2022
2 Jan 11, 2022
Opencv face recognition desktop application
Opencv-Face-Recognition Opencv face recognition desktop application Program developed by Gustavo Wydler Azuaga - 2021-11-19 Screenshots of the program
 1 Nov 19, 2021
1 Nov 19, 2021

VGGFace2-HQ - A high resolution face dataset for face editing purpose
The first open source high resolution dataset for face swapping!!! A high resolution version of VGGFace2 for academic face editing purpose
 232 Dec 29, 2022
232 Dec 29, 2022

You Can download any video/image in all social medias very easy and High Speed.
All-Downloader You Can download any video/image in all social medias very easy and High Speed. also you can easily download videos from web browsers s
 14 Dec 16, 2022
14 Dec 16, 2022
This is a repository of our model for weakly-supervised video dense anticipation.
Introduction This is a repository of our model for weakly-supervised video dense anticipation. More results on GTEA, Epic-Kitchens etc. will come soon
 2 Apr 9, 2022
2 Apr 9, 2022

Automatic Video Captioning Evaluation Metric --- EMScore
Automatic Video Captioning Evaluation Metric --- EMScore Overview For an illustration, EMScore can be computed as: Installation modify the encode_text
 17 Nov 28, 2022
17 Nov 28, 2022
TYolov5: A Temporal Yolov5 Detector Based on Quasi-Recurrent Neural Networks for Real-Time Handgun Detection in Video
TYolov5: A Temporal Yolov5 Detector Based on Quasi-Recurrent Neural Networks for Real-Time Handgun Detection in Video Timely handgun detection is a cr
 18 Dec 26, 2022
18 Dec 26, 2022

Blind visual quality assessment on 360° Video based on progressive learning
Blind visual quality assessment on omnidirectional or 360 video (ProVQA) Blind VQA for 360° Video via Progressively Learning from Pixels, Frames and V
 5 Jan 6, 2023
5 Jan 6, 2023
Video Chat Streamer With Python
Voice Chat Streamer This bot can stream audio or video files and urls in telegram voice chats :) 🎯 Follow me and star this repo for more telegram bot
4 Oct 9, 2022

Extracting frames from video and create video using frames
Extracting frames from video and create video using frames This program uses opencv library to extract the frames from video and create video from ext
 1 Nov 19, 2021
1 Nov 19, 2021

Official PyTorch implementation of "BlendGAN: Implicitly GAN Blending for Arbitrary Stylized Face Generation" (NeurIPS 2021)
BlendGAN: Implicitly GAN Blending for Arbitrary Stylized Face Generation Official PyTorch implementation of the NeurIPS 2021 paper Mingcong Liu, Qiang
462 Dec 29, 2022

PyTorch implementation for our NeurIPS 2021 Spotlight paper "Long Short-Term Transformer for Online Action Detection".
Long Short-Term Transformer for Online Action Detection Introduction This is a PyTorch implementation for our NeurIPS 2021 Spotlight paper "Long Short
 77 Dec 16, 2022
77 Dec 16, 2022
Lightweight Face Image Quality Assessment
LightQNet This is a demo code of training and testing [LightQNet] using Tensorflow. Uncertainty Losses: IDQ loss PCNet loss Uncertainty Networks: Mobi
 5 Nov 18, 2022
5 Nov 18, 2022
This is a project based on retinaface face detection, including ghostnet and mobilenetv3
English | 简体中文 RetinaFace in PyTorch Chinese detailed blog:https://zhuanlan.zhihu.com/p/379730820 Face recognition with masks is still robust---------
 59 Dec 21, 2022
59 Dec 21, 2022
Python based Telegram bot. Search and download YouTube video or audio.
Python-Telegram-Youtube-Media-Bot Python based Telegram bot. Search and download YouTube video or audio. Just change settings.py and start TelegramBot
 2 Oct 2, 2022
2 Oct 2, 2022
Generating Videos with Scene Dynamics
Generating Videos with Scene Dynamics This repository contains an implementation of Generating Videos with Scene Dynamics by Carl Vondrick, Hamed Pirs
 706 Jan 4, 2023
706 Jan 4, 2023