322 Repositories
Python visual-interestingness Libraries
Official repository of PanoAVQA: Grounded Audio-Visual Question Answering in 360° Videos (ICCV 2021)
Pano-AVQA Official repository of PanoAVQA: Grounded Audio-Visual Question Answering in 360° Videos (ICCV 2021) [Paper] [Poster] [Video] Getting Starte
 9 Dec 23, 2022
9 Dec 23, 2022
Repo for EchoVPR: Echo State Networks for Visual Place Recognition
EchoVPR Repo for EchoVPR: Echo State Networks for Visual Place Recognition Currently under development Dirs: data: pre-collected hidden representation
 4 Oct 4, 2022
4 Oct 4, 2022

Revitalizing CNN Attention via Transformers in Self-Supervised Visual Representation Learning
Revitalizing CNN Attention via Transformers in Self-Supervised Visual Representation Learning
 89 Dec 2, 2022
89 Dec 2, 2022

Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation
Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation The code repository for "Audio-Visual Generalized Few-Shot Learning with
 3 Jun 27, 2022
3 Jun 27, 2022
COVINS -- A Framework for Collaborative Visual-Inertial SLAM and Multi-Agent 3D Mapping
COVINS -- A Framework for Collaborative Visual-Inertial SLAM and Multi-Agent 3D Mapping Version 1.0 COVINS is an accurate, scalable, and versatile vis
 183 Dec 27, 2022
183 Dec 27, 2022

This is the official pytorch implementation for our ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visual Question Answering" on VQA Task
🌈 ERASOR (RA-L'21 with ICRA Option) Official page of "ERASOR: Egocentric Ratio of Pseudo Occupancy-based Dynamic Object Removal for Static 3D Point C
 225 Dec 29, 2022
225 Dec 29, 2022

Pytorch implementation for our ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visual Question Answering".
TRAnsformer Routing Networks (TRAR) This is an official implementation for ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visu
 49 Nov 10, 2022
49 Nov 10, 2022

A PyTorch implementation of "From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network" (ICCV2021)
From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network The official code of VisionLAN (ICCV2021). VisionLAN successfully a
 81 Dec 12, 2022
81 Dec 12, 2022
Official implementation of Influence-balanced Loss for Imbalanced Visual Classification in PyTorch.
Official implementation of Influence-balanced Loss for Imbalanced Visual Classification in PyTorch.
 70 Jan 3, 2023
70 Jan 3, 2023

We utilize deep reinforcement learning to obtain favorable trajectories for visual-inertial system calibration.
Unified Data Collection for Visual-Inertial Calibration via Deep Reinforcement Learning Update: The lastest code will be updated in this branch. Pleas
 27 Dec 29, 2022
27 Dec 29, 2022
AryaBota: An app to teach Python coding via gradual programming and visual output
AryaBota An app to teach Python coding, that gradually allows students to transition from using commands similar to natural language, to more Pythonic
 5 Feb 8, 2022
5 Feb 8, 2022
A Fast and Accurate One-Stage Approach to Visual Grounding, ICCV 2019 (Oral)
One-Stage Visual Grounding ***** New: Our recent work on One-stage VG is available at ReSC.***** A Fast and Accurate One-Stage Approach to Visual Grou
 118 Dec 5, 2022
118 Dec 5, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
 166 Dec 11, 2022
166 Dec 11, 2022

DSAC* for Visual Camera Re-Localization (RGB or RGB-D)
DSAC* for Visual Camera Re-Localization (RGB or RGB-D) Introduction Installation Data Structure Supported Datasets 7Scenes 12Scenes Cambridge Landmark
 143 Dec 22, 2022
143 Dec 22, 2022

Line as a Visual Sentence: Context-aware Line Descriptor for Visual Localization
Line as a Visual Sentence with LineTR This repository contains the inference code, pretrained model, and demo scripts of the following paper. It suppo
 158 Dec 27, 2022
158 Dec 27, 2022
This reporistory contains the test-dev data of the paper "xGQA: Cross-lingual Visual Question Answering".
This reporistory contains the test-dev data of the paper "xGQA: Cross-lingual Visual Question Answering".
 18 Dec 9, 2022
18 Dec 9, 2022
![[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification](https://github.com/raoyongming/CAL/raw/master/figs/intro.png)
[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Counterfactual Attention Learning Created by Yongming Rao*, Guangyi Chen*, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for ICCV
 90 Dec 31, 2022
90 Dec 31, 2022

Code and data for "Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning" (EMNLP 2021).
GD-VCR Code for Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning (EMNLP 2021). Research Questions and Aims: How well can a model perform o
 24 Oct 13, 2022
24 Oct 13, 2022
Official Implementation of Few-shot Visual Relationship Co-localization
VRC Official implementation of the Few-shot Visual Relationship Co-localization (ICCV 2021) paper project page | paper Requirements Use python = 3.8.
 22 Oct 13, 2022
22 Oct 13, 2022
[ICCV 2021] Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
Counterfactual Attention Learning Created by Yongming Rao*, Guangyi Chen*, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for ICCV
89 Dec 18, 2022
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
PyTorch implementation of SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
 1.7k Dec 28, 2022
1.7k Dec 28, 2022

Cockpit is a visual and statistical debugger specifically designed for deep learning.
Cockpit: A Practical Debugging Tool for Training Deep Neural Networks
 421 Dec 29, 2022
421 Dec 29, 2022
[ICCV 2021] Released code for Causal Attention for Unbiased Visual Recognition
CaaM This repo contains the codes of training our CaaM on NICO/ImageNet9 dataset. Due to my recent limited bandwidth, this codebase is still messy, wh
 66 Dec 31, 2022
66 Dec 31, 2022

This repo implements a Topological SLAM: Deep Visual Odometry with Long Term Place Recognition (Loop Closure Detection)
This repo implements a topological SLAM system. Deep Visual Odometry (DF-VO) and Visual Place Recognition are combined to form the topological SLAM system.
 32 Jun 23, 2022
32 Jun 23, 2022

🌈 PyTorch Implementation for EMNLP'21 Findings "Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer"
SGLKT-VisDial Pytorch Implementation for the paper: Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer Gi-Cheon Kang, Junseok P
 9 Jul 5, 2022
9 Jul 5, 2022

PaddleViT: State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 2.0+
PaddlePaddle Vision Transformers State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 🤖 PaddlePaddle Visual Transformers (PaddleViT or
 1k Dec 28, 2022
1k Dec 28, 2022

The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation
PointNav-VO The Surprising Effectiveness of Visual Odometry Techniques for Embodied PointGoal Navigation Project Page | Paper Table of Contents Setup
 41 Dec 15, 2022
41 Dec 15, 2022
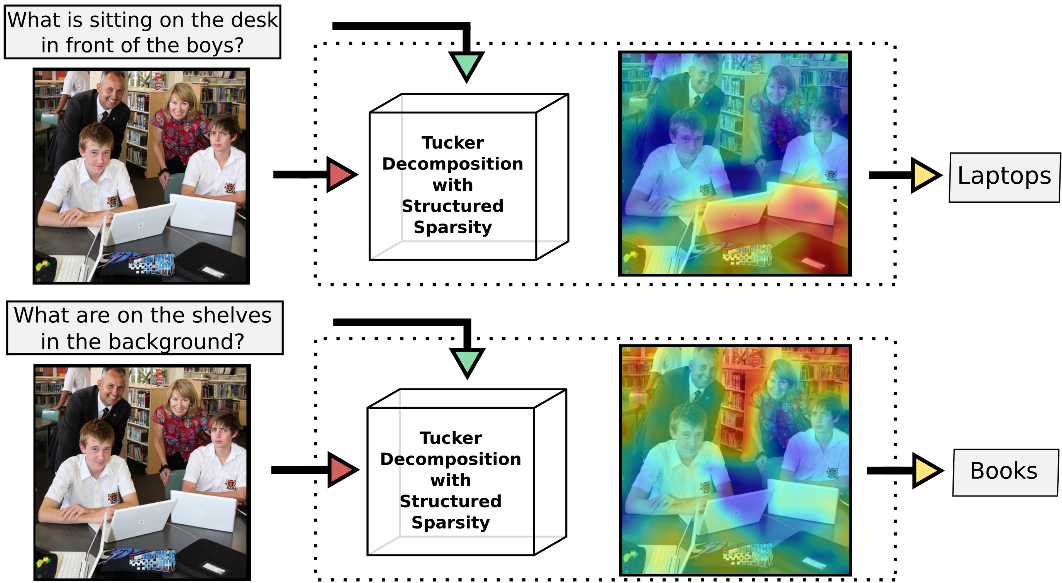
Visual Question Answering in Pytorch
Visual Question Answering in pytorch /!\ New version of pytorch for VQA available here: https://github.com/Cadene/block.bootstrap.pytorch This repo wa
 672 Jan 1, 2023
672 Jan 1, 2023
PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
Improving Visual-Semantic Embeddings with Hard Negatives Code for the image-caption retrieval methods from VSE++: Improving Visual-Semantic Embeddings
 441 Dec 5, 2022
441 Dec 5, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
166 Dec 11, 2022

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022
A management system designed for the employees of MIRAS (Art Gallery). It is used to sell/cancel tickets, book/cancel events and keeps track of all upcoming events.
Art-Galleria-Management-System Its a management system designed for the employees of MIRAS (Art Gallery). Backend : Python Frontend : Django Database
 8 Nov 30, 2022
8 Nov 30, 2022

A weakly-supervised scene graph generation codebase. The implementation of our CVPR2021 paper ``Linguistic Structures as Weak Supervision for Visual Scene Graph Generation''
README.md shall be finished soon. WSSGG 0 Overview 1 Installation 1.1 Faster-RCNN 1.2 Language Parser 1.3 GloVe Embeddings 2 Settings 2.1 VG-GT-Graph
 35 Nov 20, 2022
35 Nov 20, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
 41 Jan 3, 2023
41 Jan 3, 2023

Code release for The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification (TIP 2020)
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification Code release for The Devil is in the Channels: Mutual-Channel
 230 Dec 31, 2022
230 Dec 31, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023
Video Visual Relation Detection (VidVRD) tracklets generation. also for ACM MM Visual Relation Understanding Grand Challenge
VidVRD-tracklets This repository contains codes for Video Visual Relation Detection (VidVRD) tracklets generation based on MEGA and deepSORT. These tr
 25 Dec 21, 2022
25 Dec 21, 2022

Official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers
Visual Parser (ViP) This is the official implementation of the paper Visual Parser: Representing Part-whole Hierarchies with Transformers. Key Feature
 117 Dec 11, 2022
117 Dec 11, 2022
DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021)
DPT This repo is the official implementation of DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021). We provide code and model
 111 Dec 21, 2022
111 Dec 21, 2022
This is the code for CVPR 2021 oral paper: Jigsaw Clustering for Unsupervised Visual Representation Learning
JigsawClustering Jigsaw Clustering for Unsupervised Visual Representation Learning Pengguang Chen, Shu Liu, Jiaya Jia Introduction This project provid
 73 Sep 18, 2022
73 Sep 18, 2022

Dataset used in "PlantDoc: A Dataset for Visual Plant Disease Detection" accepted in CODS-COMAD 2020
PlantDoc: A Dataset for Visual Plant Disease Detection This repository contains the Cropped-PlantDoc dataset used for benchmarking classification mode
 109 Dec 29, 2022
109 Dec 29, 2022

This's an implementation of deepmind Visual Interaction Networks paper using pytorch
Visual-Interaction-Networks An implementation of Deepmind visual interaction networks in Pytorch. Introduction For the purpose of understanding the ch
 166 Dec 6, 2022
166 Dec 6, 2022

PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs
PyTorch implementation of VAGAN: Visual Feature Attribution Using Wasserstein GANs This code aims to reproduce results obtained in the paper "Visual F
 93 Aug 17, 2022
93 Aug 17, 2022

Bilinear attention networks for visual question answering
Bilinear Attention Networks This repository is the implementation of Bilinear Attention Networks for the visual question answering and Flickr30k Entit
 506 Nov 29, 2022
506 Nov 29, 2022

source code of “Visual Saliency Transformer” (ICCV2021)
Visual Saliency Transformer (VST) source code for our ICCV 2021 paper “Visual Saliency Transformer” by Nian Liu, Ni Zhang, Kaiyuan Wan, Junwei Han, an
 89 Dec 21, 2022
89 Dec 21, 2022

🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
 7.7k Jan 5, 2023
7.7k Jan 5, 2023

PyTorch implementation of "Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning"
Transparency-by-Design networks (TbD-nets) This repository contains code for replicating the experiments and visualizations from the paper Transparenc
 351 Nov 18, 2022
351 Nov 18, 2022

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022

URIE: Universal Image Enhancementfor Visual Recognition in the Wild
URIE: Universal Image Enhancementfor Visual Recognition in the Wild This is the implementation of the paper "URIE: Universal Image Enhancement for Vis
 43 Sep 12, 2022
43 Sep 12, 2022
improvement of CLIP features over the traditional resnet features on the visual question answering, image captioning, navigation and visual entailment tasks.
CLIP-ViL In our paper "How Much Can CLIP Benefit Vision-and-Language Tasks?", we show the improvement of CLIP features over the traditional resnet fea
 310 Dec 28, 2022
310 Dec 28, 2022
STMTrack: Template-free Visual Tracking with Space-time Memory Networks
STMTrack This is the official implementation of the paper: STMTrack: Template-free Visual Tracking with Space-time Memory Networks. Setup Prepare Anac
 62 Dec 21, 2022
62 Dec 21, 2022
![[CVPR 2021] A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts](https://github.com/gyhandy/Visual-Reasoning-eXplanation/raw/main/docs/Fig-1.png)
[CVPR 2021] A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts
Visual-Reasoning-eXplanation [CVPR 2021 A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts] Project Page | Vid
 54 Dec 21, 2022
54 Dec 21, 2022

box is a text-based visual programming language inspired by Unreal Engine Blueprint function graphs.
Box is a text-based visual programming language inspired by Unreal Engine blueprint function graphs. $ cat factorial.box ┌─ƒ(Factorial)───┐
 104 Dec 24, 2022
104 Dec 24, 2022
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
 564 Jan 3, 2023
564 Jan 3, 2023

Code for "Learning Canonical Representations for Scene Graph to Image Generation", Herzig & Bar et al., ECCV2020
Learning Canonical Representations for Scene Graph to Image Generation (ECCV 2020) Roei Herzig*, Amir Bar*, Huijuan Xu, Gal Chechik, Trevor Darrell, A
 24 Jul 7, 2022
24 Jul 7, 2022
![[CVPR2021] Look before you leap: learning landmark features for one-stage visual grounding.](https://github.com/svip-lab/LBYLNet/raw/main/imgs/landmarks.png)
[CVPR2021] Look before you leap: learning landmark features for one-stage visual grounding.
LBYL-Net This repo implements paper Look Before You Leap: Learning Landmark Features For One-Stage Visual Grounding CVPR 2021. Getting Started Prerequ
 45 Dec 12, 2022
45 Dec 12, 2022

VID-Fusion: Robust Visual-Inertial-Dynamics Odometry for Accurate External Force Estimation
VID-Fusion VID-Fusion: Robust Visual-Inertial-Dynamics Odometry for Accurate External Force Estimation Authors: Ziming Ding , Tiankai Yang, Kunyi Zhan
 86 Nov 18, 2022
86 Nov 18, 2022
Localizing Visual Sounds the Hard Way
Localizing-Visual-Sounds-the-Hard-Way Code and Dataset for "Localizing Visual Sounds the Hard Way". The repo contains code and our pre-trained model.
 58 Dec 7, 2022
58 Dec 7, 2022

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023

Orthogonal Over-Parameterized Training
The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is of great importance. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. See our previous work -- MHE for an in-depth introduction.
 11 Apr 18, 2022
11 Apr 18, 2022

Visual Weather api. Returns beautiful pictures with the current weather.
VWapi Visual Weather api. Returns beautiful pictures with the current weather. Installation: sudo apt update -y && sudo apt upgrade -y sudo apt instal
 33 Nov 13, 2022
33 Nov 13, 2022

MLP-Like Vision Permutator for Visual Recognition (PyTorch)
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition (arxiv) This is a Pytorch implementation of our paper. We present Vision
 162 Nov 28, 2022
162 Nov 28, 2022
PyTorch implementation code for the paper MixCo: Mix-up Contrastive Learning for Visual Representation
How to Reproduce our Results This repository contains PyTorch implementation code for the paper MixCo: Mix-up Contrastive Learning for Visual Represen
 46 Dec 15, 2022
46 Dec 15, 2022

VOLO: Vision Outlooker for Visual Recognition
VOLO: Vision Outlooker for Visual Recognition, arxiv This is a PyTorch implementation of our paper. We present Vision Outlooker (VOLO). We show that o
 876 Dec 9, 2022
876 Dec 9, 2022

Code for the RA-L (ICRA) 2021 paper "SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition"
SeqNet: Learning Descriptors for Sequence-Based Hierarchical Place Recognition [ArXiv+Supplementary] [IEEE Xplore RA-L 2021] [ICRA 2021 YouTube Video]
 63 Dec 12, 2022
63 Dec 12, 2022

JittorVis - Visual understanding of deep learning model.
JittorVis is a deep neural network computational graph visualization library based on Jittor.
 182 Jan 6, 2023
182 Jan 6, 2023

Episodic Transformer (E.T.) is a novel attention-based architecture for vision-and-language navigation. E.T. is based on a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions.
Episodic Transformers (E.T.) Episodic Transformer for Vision-and-Language Navigation Alexander Pashevich, Cordelia Schmid, Chen Sun Episodic Transform
 62 Dec 24, 2022
62 Dec 24, 2022
![Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations. [2021]](https://github.com/wvangansbeke/Revisiting-Contrastive-SSL/raw/main/images/teaser.jpg)
Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations. [2021]
Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations This repo contains the Pytorch implementation of our paper: Revisit
 80 Nov 20, 2022
80 Nov 20, 2022

Keep CALM and Improve Visual Feature Attribution
Keep CALM and Improve Visual Feature Attribution Jae Myung Kim1*, Junsuk Choe1*, Zeynep Akata2, Seong Joon Oh1† * Equal contribution † Corresponding a
 90 Dec 7, 2022
90 Dec 7, 2022

Code for paper: Group-CAM: Group Score-Weighted Visual Explanations for Deep Convolutional Networks
Group-CAM By Zhang, Qinglong and Rao, Lu and Yang, Yubin [State Key Laboratory for Novel Software Technology at Nanjing University] This repo is the o
 98 Nov 16, 2022
98 Nov 16, 2022

An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C.
vizh An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C. Overview Her
 228 Dec 17, 2022
228 Dec 17, 2022
PyTorch implementation for ACL 2021 paper "Maria: A Visual Experience Powered Conversational Agent".
Maria: A Visual Experience Powered Conversational Agent This repository is the Pytorch implementation of our paper "Maria: A Visual Experience Powered
 22 Dec 12, 2022
22 Dec 12, 2022

3D AffordanceNet is a 3D point cloud benchmark consisting of 23k shapes from 23 semantic object categories, annotated with 56k affordance annotations and covering 18 visual affordance categories.
3D AffordanceNet This repository is the official experiment implementation of 3D AffordanceNet benchmark. 3D AffordanceNet is a 3D point cloud benchma
 49 Dec 1, 2022
49 Dec 1, 2022
![A 2D Visual Localization Framework based on Essential Matrices [ICRA2020]](https://github.com/GrumpyZhou/visloc-relapose/raw/master/pipeline/pipeline.jpg)
A 2D Visual Localization Framework based on Essential Matrices [ICRA2020]
A 2D Visual Localization Framework based on Essential Matrices This repository provides implementation of our paper accepted at ICRA: To Learn or Not
 27 Nov 7, 2022
27 Nov 7, 2022
FLVIS: Feedback Loop Based Visual Initial SLAM
FLVIS Feedback Loop Based Visual Inertial SLAM 1-Video EuRoC DataSet MH_05 Handheld Test in Lab FlVIS on UAV Platform 2-Relevent Publication: Under Re
 182 Dec 4, 2022
182 Dec 4, 2022

Exploring Visual Engagement Signals for Representation Learning
Exploring Visual Engagement Signals for Representation Learning Menglin Jia, Zuxuan Wu, Austin Reiter, Claire Cardie, Serge Belongie and Ser-Nam Lim C
 9 Jul 23, 2022
9 Jul 23, 2022

A new kind of Progress Bar, with real time throughput, eta and very cool animations!
A new kind of Progress Bar, with real time throughput, eta and very cool animations!
 4.1k Jan 8, 2023
4.1k Jan 8, 2023
This is an official implementation for "ResT: An Efficient Transformer for Visual Recognition".
ResT By Qing-Long Zhang and Yu-Bin Yang [State Key Laboratory for Novel Software Technology at Nanjing University] This repo is the official implement
222 Dec 13, 2022

Lumen provides a framework for visual analytics, which allows users to build data-driven dashboards from a simple yaml specification
Lumen project provides a framework for visual analytics, which allows users to build data-driven dashboards from a simple yaml specification
 120 Jan 4, 2023
120 Jan 4, 2023
Conformer: Local Features Coupling Global Representations for Visual Recognition
Conformer: Local Features Coupling Global Representations for Visual Recognition (arxiv) This repository is built upon DeiT and timm Usage First, inst
 378 Jan 8, 2023
378 Jan 8, 2023

TrTr: Visual Tracking with Transformer
TrTr: Visual Tracking with Transformer We propose a novel tracker network based on a powerful attention mechanism called Transformer encoder-decoder a
 66 Dec 27, 2022
66 Dec 27, 2022

Code release for paper: The Boombox: Visual Reconstruction from Acoustic Vibrations
The Boombox: Visual Reconstruction from Acoustic Vibrations Boyuan Chen, Mia Chiquier, Hod Lipson, Carl Vondrick Columbia University Project Website |
 12 Nov 30, 2022
12 Nov 30, 2022
Python codes for Lite Audio-Visual Speech Enhancement.
Lite Audio-Visual Speech Enhancement (Interspeech 2020) Introduction This is the PyTorch implementation of Lite Audio-Visual Speech Enhancement (LAVSE
 85 Dec 1, 2022
85 Dec 1, 2022
Visual DSL framework for django
Preface Processes change more often than technic. Domain Rules are situational and may differ from customer to customer. With diverse code and frequen
 165 Jan 8, 2023
165 Jan 8, 2023

Visual Tracking by TridenAlign and Context Embedding
Visual Tracking by TridentAlign and Context Embedding (TACT) Test code for "Visual Tracking by TridentAlign and Context Embedding" Janghoon Choi, Juns
 32 Aug 25, 2021
32 Aug 25, 2021

Location-Sensitive Visual Recognition with Cross-IOU Loss
The trained models are temporarily unavailable, but you can train the code using reasonable computational resource. Location-Sensitive Visual Recognit
 146 Dec 25, 2022
146 Dec 25, 2022
A simple visual front end to the Maya UE4 RBF plugin delivered with MetaHumans
poseWrangler Overview PoseWrangler is a simple UI to create and edit pose-driven relationships in Maya using the MayaUE4RBF plugin. This plugin is dis
 105 Dec 18, 2022
105 Dec 18, 2022
So-ViT: Mind Visual Tokens for Vision Transformer
So-ViT: Mind Visual Tokens for Vision Transformer Introduction This repository contains the source code under PyTorch framework and models trai
 44 Nov 24, 2022
44 Nov 24, 2022

ManipulaTHOR, a framework that facilitates visual manipulation of objects using a robotic arm
ManipulaTHOR: A Framework for Visual Object Manipulation Kiana Ehsani, Winson Han, Alvaro Herrasti, Eli VanderBilt, Luca Weihs, Eric Kolve, Aniruddha
 65 Dec 30, 2022
65 Dec 30, 2022

LVI-SAM: Tightly-coupled Lidar-Visual-Inertial Odometry via Smoothing and Mapping
LVI-SAM This repository contains code for a lidar-visual-inertial odometry and mapping system, which combines the advantages of LIO-SAM and Vins-Mono
 1.1k Dec 27, 2022
1.1k Dec 27, 2022
Code for "Learning the Best Pooling Strategy for Visual Semantic Embedding", CVPR 2021
Learning the Best Pooling Strategy for Visual Semantic Embedding Official PyTorch implementation of the paper Learning the Best Pooling Strategy for V
 106 Jan 6, 2023
106 Jan 6, 2023

Implementation of "Distribution Alignment: A Unified Framework for Long-tail Visual Recognition"(CVPR 2021)
Implementation of "Distribution Alignment: A Unified Framework for Long-tail Visual Recognition"(CVPR 2021)
 105 Nov 7, 2022
105 Nov 7, 2022

Code for Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021)
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021) Hang Zhou, Yasheng Sun, Wayne Wu, Chen Cha
 628 Dec 28, 2022
628 Dec 28, 2022
PyTorch reimplementation of the paper Involution: Inverting the Inherence of Convolution for Visual Recognition [CVPR 2021].
Involution: Inverting the Inherence of Convolution for Visual Recognition Unofficial PyTorch reimplementation of the paper Involution: Inverting the I
 100 Dec 1, 2022
100 Dec 1, 2022

Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation
Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation This is the official repository for our paper Neural Reprojection Error
 78 Dec 1, 2022
78 Dec 1, 2022

A Collection of Conference & School Notes in Machine Learning 🦄📝🎉
Machine Learning Conference & Summer School Notes. 🦄📝🎉
 558 Dec 28, 2022
558 Dec 28, 2022

UniMoCo: Unsupervised, Semi-Supervised and Full-Supervised Visual Representation Learning
UniMoCo: Unsupervised, Semi-Supervised and Full-Supervised Visual Representation Learning This is the official PyTorch implementation for UniMoCo pape
 49 Jan 2, 2023
49 Jan 2, 2023

Learning Spatio-Temporal Transformer for Visual Tracking
STARK The official implementation of the paper Learning Spatio-Temporal Transformer for Visual Tracking Hiring research interns for visual transformer
 484 Dec 29, 2022
484 Dec 29, 2022
Learning Spatio-Temporal Transformer for Visual Tracking
STARK The official implementation of the paper Learning Spatio-Temporal Transformer for Visual Tracking Highlights The strongest performances Tracker
485 Jan 4, 2023
git git《Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking》(CVPR 2021) GitHub:git2] 《Masksembles for Uncertainty Estimation》(CVPR 2021) GitHub:git3]
Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking Ning Wang, Wengang Zhou, Jie Wang, and Houqiang Li Accepted by CVPR
 236 Dec 22, 2022
236 Dec 22, 2022