1060 Repositories
Python zero-shot-video-captioning Libraries

MoCoPnet - Deformable 3D Convolution for Video Super-Resolution
Deformable 3D Convolution for Video Super-Resolution Pytorch implementation of l
 28 Dec 15, 2022
28 Dec 15, 2022
This is a TG Video Compress BoT. Product by BINARY Tech
🌀 Video Compressor Bot Product by BINARY Tech Deploy to Heroku The Hard Way virtualenv -p python3 VENV . ./VENV/bin/activate pip install -r requireme
 1 Jan 4, 2022
1 Jan 4, 2022

Referring Video Object Segmentation
Awesome-Referring-Video-Object-Segmentation Welcome to starts ⭐ & comments 💹 & sharing 😀 !! - 2021.12.12: Recent papers (from 2021) - welcome to ad
 57 Dec 11, 2022
57 Dec 11, 2022

Meteor scan - Scan through video for meteor
meteor_scan Scan through video for meteor Installation Install python packages b
 2 Jun 4, 2022
2 Jun 4, 2022

Zsseg.baseline - Zero-Shot Semantic Segmentation
This repo is for our paper A Simple Baseline for Zero-shot Semantic Segmentation
 98 Dec 20, 2022
98 Dec 20, 2022

ReferFormer - Official Implementation of ReferFormer
The official implementation of the paper: Language as Queries for Referring Vide
 232 Dec 29, 2022
232 Dec 29, 2022
VideocompBot - This is TG Video Compress BoT. Prouduct By BINARY Tech 💫
VideocompBot - This is TG Video Compress BoT. Prouduct By BINARY Tech 💫
 1 Jan 4, 2022
1 Jan 4, 2022

Pytorch implementation for ACMMM2021 paper "I2V-GAN: Unpaired Infrared-to-Visible Video Translation".
I2V-GAN This repository is the official Pytorch implementation for ACMMM2021 paper "I2V-GAN: Unpaired Infrared-to-Visible Video Translation". Traffic
 69 Dec 31, 2022
69 Dec 31, 2022

ZUNIT - Toward Zero-Shot Unsupervised Image-to-Image Translation
ZUNIT Dependencies you can install all the dependencies by pip install -r requirements.txt Datasets Download CUB dataset. Unzip the birds.zip at ./da
 9 Jun 24, 2022
9 Jun 24, 2022
![[CVPR 2021] Scan2Cap: Context-aware Dense Captioning in RGB-D Scans](https://github.com/daveredrum/Scan2Cap/raw/main/demo/Scan2Cap.gif)
[CVPR 2021] Scan2Cap: Context-aware Dense Captioning in RGB-D Scans
Scan2Cap: Context-aware Dense Captioning in RGB-D Scans Introduction We introduce the task of dense captioning in 3D scans from commodity RGB-D sensor
 79 Nov 7, 2022
79 Nov 7, 2022
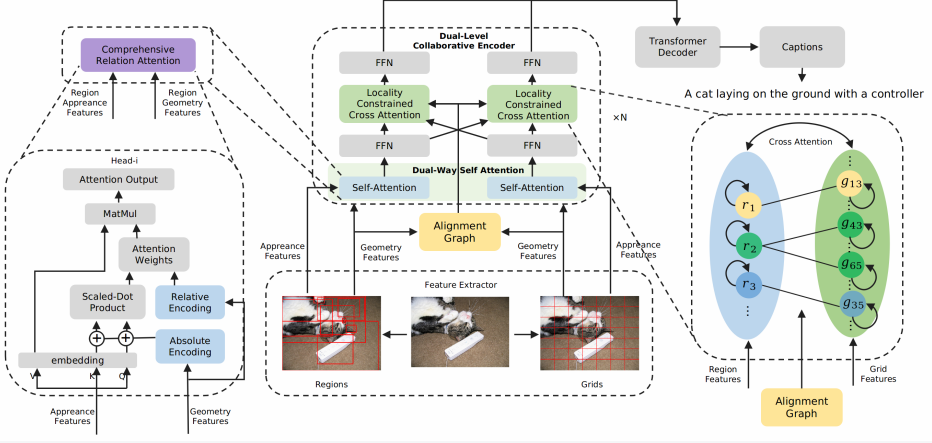
Official pytorch implementation of paper Dual-Level Collaborative Transformer for Image Captioning (AAAI 2021).
Dual-Level Collaborative Transformer for Image Captioning This repository contains the reference code for the paper Dual-Level Collaborative Transform
 160 Dec 11, 2022
160 Dec 11, 2022
Official pytorch implementation of the AAAI 2021 paper Semantic Grouping Network for Video Captioning
Semantic Grouping Network for Video Captioning Hobin Ryu, Sunghun Kang, Haeyong Kang, and Chang D. Yoo. AAAI 2021. [arxiv] Environment Ubuntu 16.04 CU
 43 Nov 25, 2022
43 Nov 25, 2022
LaBERT - A length-controllable and non-autoregressive image captioning model.
Length-Controllable Image Captioning (ECCV2020) This repo provides the implemetation of the paper Length-Controllable Image Captioning. Install conda
 53 Nov 13, 2022
53 Nov 13, 2022
PyTorch code for: Learning to Generate Grounded Visual Captions without Localization Supervision
Learning to Generate Grounded Visual Captions without Localization Supervision This is the PyTorch implementation of our paper: Learning to Generate G
 41 Nov 17, 2022
41 Nov 17, 2022
ECCV2020 paper: Fashion Captioning: Towards Generating Accurate Descriptions with Semantic Rewards. Code and Data.
This repo contains some of the codes for the following paper Fashion Captioning: Towards Generating Accurate Descriptions with Semantic Rewards. Code
 56 Dec 8, 2022
56 Dec 8, 2022
Moer Grounded Image Captioning by Distilling Image-Text Matching Model
Moer Grounded Image Captioning by Distilling Image-Text Matching Model Requirements Python 3.7 Pytorch 1.2 Prepare data Please use git clone --recurse
 60 Dec 16, 2022
60 Dec 16, 2022

Meshed-Memory Transformer for Image Captioning. CVPR 2020
M²: Meshed-Memory Transformer This repository contains the reference code for the paper Meshed-Memory Transformer for Image Captioning (CVPR 2020). Pl
 422 Dec 28, 2022
422 Dec 28, 2022
![Implementation of 'X-Linear Attention Networks for Image Captioning' [CVPR 2020]](https://github.com/JDAI-CV/image-captioning/raw/master/images/framework.jpg)
Implementation of 'X-Linear Attention Networks for Image Captioning' [CVPR 2020]
Introduction This repository is for X-Linear Attention Networks for Image Captioning (CVPR 2020). The original paper can be found here. Please cite wi
 240 Dec 17, 2022
240 Dec 17, 2022
![[CVPR 2020] Transform and Tell: Entity-Aware News Image Captioning](https://github.com/alasdairtran/transform-and-tell/raw/master/figures/teaser.png)
[CVPR 2020] Transform and Tell: Entity-Aware News Image Captioning
Transform and Tell: Entity-Aware News Image Captioning This repository contains the code to reproduce the results in our CVPR 2020 paper Transform and
 85 Dec 13, 2022
85 Dec 13, 2022
WeakVRD-Captioning - Implementation of paper Improving Image Captioning with Better Use of Caption
WeakVRD-Captioning - Implementation of paper Improving Image Captioning with Better Use of Caption
 30 Oct 28, 2022
30 Oct 28, 2022
PyTorch code for MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning
MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning PyTorch code for our ACL 2020 paper "MART: Memory-Augmented Recur
 151 Jan 6, 2023
151 Jan 6, 2023
Code for paper Adaptively Aligned Image Captioning via Adaptive Attention Time
Adaptively Aligned Image Captioning via Adaptive Attention Time This repository includes the implementation for Adaptively Aligned Image Captioning vi
 45 Aug 27, 2022
45 Aug 27, 2022
Implementation of the Object Relation Transformer for Image Captioning
Object Relation Transformer This is a PyTorch implementation of the Object Relation Transformer published in NeurIPS 2019. You can find the paper here
 158 Dec 24, 2022
158 Dec 24, 2022
Unsupervised captioning - Code for Unsupervised Image Captioning
Unsupervised Image Captioning by Yang Feng, Lin Ma, Wei Liu, and Jiebo Luo Introduction Most image captioning models are trained using paired image-se
 207 Dec 24, 2022
207 Dec 24, 2022
This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detection', CVPR 2019.
Code-and-Dataset-for-CapSal This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detec
 48 Aug 19, 2022
48 Aug 19, 2022

GoodNews Everyone! Context driven entity aware captioning for news images
This is the code for a CVPR 2019 paper, called GoodNews Everyone! Context driven entity aware captioning for news images. Enjoy! Model preview: Huge T
 117 Dec 19, 2022
117 Dec 19, 2022
This repository focus on Image Captioning & Video Captioning & Seq-to-Seq Learning & NLP
Awesome-Visual-Captioning Table of Contents ACL-2021 CVPR-2021 AAAI-2021 ACMMM-2020 NeurIPS-2020 ECCV-2020 CVPR-2020 ACL-2020 AAAI-2020 ACL-2019 NeurI
 362 Jan 3, 2023
362 Jan 3, 2023
Stinky ID - A stable pluggable Telegram userbot + Voice & Video Call music bot, based on Telethon
Ultroid - UserBot A stable pluggable Telegram userbot + Voice & Video Call music
 1 Jan 3, 2022
1 Jan 3, 2022

Tensorflow implementation of soft-attention mechanism for video caption generation.
SA-tensorflow Tensorflow implementation of soft-attention mechanism for video caption generation. An example of soft-attention mechanism. The attentio
 153 Nov 14, 2022
153 Nov 14, 2022
Code release for Convolutional Two-Stream Network Fusion for Video Action Recognition
Convolutional Two-Stream Network Fusion for Video Action Recognition
 676 Dec 31, 2022
676 Dec 31, 2022

Show-attend-and-tell - TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
 902 Nov 29, 2022
902 Nov 29, 2022

Deep-Learning-Image-Captioning - Implementing convolutional and recurrent neural networks in Keras to generate sentence descriptions of images
Deep Learning - Image Captioning with Convolutional and Recurrent Neural Nets ========================================================================
 23 Apr 6, 2022
23 Apr 6, 2022

Image captioning - Tensorflow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Introduction This neural system for image captioning is roughly based on the paper "Show, Attend and Tell: Neural Image Caption Generation with Visual
 749 Dec 28, 2022
749 Dec 28, 2022
Telegram Music/ Video Streaming Bot Using Pytgcalls
Video Player 🔥 ᴢᴀɪᴅ ᴠᴄ ᴘʟᴀyᴇʀ ɪꜱ ᴀ ᴛᴇʟᴇɢʀᴀᴍ ᴘʀᴏᴊᴇᴄᴛ ʙᴀꜱᴇᴅ ᴏɴ ᴘʏʀᴏɢʀᴀᴍ ꜰᴏʀ ᴘʟᴀʏ ᴍᴜꜱɪᴄꜱ ɪɴ ᴠᴄ ᴄʜᴀᴛꜱ... 🅡🅔🅟🅞 🅢🅣🅐🅣🅢 ʀᴇQᴜɪʀᴇᴍᴇɴᴛꜱ 📝 FFmpeg NodeJ
 16 Nov 30, 2022
16 Nov 30, 2022
LightningFSL: Pytorch-Lightning implementations of Few-Shot Learning models.
LightningFSL: Few-Shot Learning with Pytorch-Lightning In this repo, a number of pytorch-lightning implementations of FSL algorithms are provided, inc
 76 Dec 11, 2022
76 Dec 11, 2022
A video scene detection algorithm is designed to detect a variety of different scenes within a video
Scene-Change-Detection - A video scene detection algorithm is designed to detect a variety of different scenes within a video. There is a very simple definition for a scene: It is a series of logically and chronologically related shots taken in a specific order to depict an over-arching concept or story.
 1 Jan 4, 2022
1 Jan 4, 2022

DIP-football - A football video analyse system based on Yolov5, alphapose, Qt6
足球视频分析系统 作者 陆徐东 [email protected] 方天宬 [email protected] 简介 本项目是SJTU 21-22学年CS386 数字图像处理课程的大作业,本文是足球视频分析系统的参考文档。我们主要实现了以下功能: 基于Yolo v5和PastaNet搭建了足球视频的
 2 Jun 4, 2022
2 Jun 4, 2022
Doods2 - API for detecting objects in images and video streams using Tensorflow
DOODS2 - Return of DOODS Dedicated Open Object Detection Service - Yes, it's a b
 101 Jan 4, 2023
101 Jan 4, 2023
Video-Player - Telegram Music/ Video Streaming Bot Using Pytgcalls
Video Player 🔥 ᴢᴀɪᴅ ᴠᴄ ᴘʟᴀyᴇʀ ɪꜱ ᴀ ᴛᴇʟᴇɢʀᴀᴍ ᴘʀᴏᴊᴇᴄᴛ ʙᴀꜱᴇᴅ ᴏɴ ᴘʏʀᴏɢʀᴀᴍ ꜰᴏʀ ᴘʟᴀʏ
 16 Nov 30, 2022
16 Nov 30, 2022
Ffmpeg videostream - High speed video frame access in Python, using FFmpeg and FFshow
FFmpeg VideoStream High speed video frame access in Python, using FFmpeg and FFshow This script requires: Karl Kroening's 'ffmpeg-python' library. (ht
 3 Sep 29, 2022
3 Sep 29, 2022
Video stream image stacking -- live version
video stream image stacking v2 -- live version A very simple streamed video image stacking code! Version 2.1 left mouse click to select a small region
 1 Jan 3, 2022
1 Jan 3, 2022
𝐴 𝑡𝑒𝑙𝑒𝑔𝑟𝑎𝑚 𝑏𝑜𝑡 𝑡ℎ𝑎𝑡 𝑐𝑎𝑛 𝑑𝑜𝑤𝑛𝑙𝑜𝑎𝑑 𝑣𝑖𝑑𝑒𝑜 𝑎𝑛𝑑 𝑎𝑢𝑑𝑖𝑜 𝑓𝑟𝑜𝑚 𝑦𝑜𝑢𝑡𝑢𝑏𝑒 𝑎𝑛𝑑 𝑣𝑖𝑑𝑒𝑜 𝑤𝑒𝑏𝑠𝑖𝑡𝑒𝑠 𝑞𝑢𝑖𝑐𝑘𝑙𝑦
𝐴 𝑡𝑒𝑙𝑒𝑔𝑟𝑎𝑚 𝑏𝑜𝑡 𝑡ℎ𝑎𝑡 𝑐𝑎𝑛 𝑑𝑜𝑤𝑛𝑙𝑜𝑎𝑑 𝑣𝑖𝑑𝑒𝑜 𝑎𝑛𝑑 𝑎𝑢𝑑𝑖𝑜 𝑓𝑟𝑜𝑚 𝑦𝑜𝑢𝑡𝑢𝑏𝑒 𝑎𝑛𝑑 𝑣𝑖𝑑𝑒𝑜 𝑤𝑒𝑏𝑠𝑖𝑡𝑒𝑠 𝑞𝑢𝑖𝑐𝑘𝑙𝑦
 2 Aug 4, 2022
2 Aug 4, 2022

Video2x - A lossless video/GIF/image upscaler achieved with waifu2x, Anime4K, SRMD and RealSR.
Official Discussion Group (Telegram): https://t.me/video2x A Discord server is also available. Please note that most developers are only on Telegram.
 5.9k Dec 31, 2022
5.9k Dec 31, 2022
Autosub - Command-line utility for auto-generating subtitles for any video file
Auto-generated subtitles for any video Autosub is a utility for automatic speech recognition and subtitle generation. It takes a video or an a
 3.9k Jan 5, 2023
3.9k Jan 5, 2023

Repositório criado para abrigar os notebooks com a listas de exercícios propostos pelo professor Gustavo Guanabara do canal Curso em Vídeo do YouTube durante o Curso de Python 3
Curso em Vídeo - Exercícios de Python 3 Sobre o repositório Este repositório contém os notebooks com a listas de exercícios propostos pelo professor G
 9 Oct 15, 2022
9 Oct 15, 2022
Videocaptioning.pytorch - A simple implementation of video captioning
pytorch implementation of video captioning recommend installing pytorch and pyth
 2 Jan 1, 2022
2 Jan 1, 2022

VQMIVC - Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion (Interspeech
 262 Dec 31, 2022
262 Dec 31, 2022

Unet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning
Unet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning English | 中文 ❗ Now we provide inferencing code and pre-training models
 164 Jan 2, 2023
164 Jan 2, 2023
YouTube-Video-Downloader - Download Youtube Videos for free.
YouTube-Video-Downloader Download Youtube Videos for free. Installing Dependencies:- Windows pip install pytube Mac/Linux pip3 install pytube Clonin
 1 Jan 1, 2022
1 Jan 1, 2022

Face_mosaic - Mosaic blur processing is applied to multiple faces appearing in the video
動機 face_recognitionを使用して得られる顔座標は長方形であり、この座標をそのまま用いてぼかし処理を行った場合得られる画像は醜い。 それに対してモ
 6 Feb 3, 2022
6 Feb 3, 2022

A Survey on Deep Learning Technique for Video Segmentation
A Survey on Deep Learning Technique for Video Segmentation A Survey on Deep Learning Technique for Video Segmentation Wenguan Wang, Tianfei Zhou, Fati
 112 Dec 12, 2022
112 Dec 12, 2022

TransPrompt - Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification
TransPrompt This code is implement for our EMNLP 2021's paper 《TransPrompt:Towards an Automatic Transferable Prompting Framework for Few-shot Text Cla
 23 Dec 21, 2022
23 Dec 21, 2022

Learning Dynamic Network Using a Reuse Gate Function in Semi-supervised Video Object Segmentation.
Training Script for Reuse-VOS This code implementation of CVPR 2021 paper : Learning Dynamic Network Using a Reuse Gate Function in Semi-supervised Vi
 22 Jan 1, 2023
22 Jan 1, 2023
CapsuleVOS: Semi-Supervised Video Object Segmentation Using Capsule Routing
CapsuleVOS This is the code for the ICCV 2019 paper CapsuleVOS: Semi-Supervised Video Object Segmentation Using Capsule Routing. Arxiv Link: https://a
 53 Oct 27, 2022
53 Oct 27, 2022

PyTorch implementation of Neural View Synthesis and Matching for Semi-Supervised Few-Shot Learning of 3D Pose
Neural View Synthesis and Matching for Semi-Supervised Few-Shot Learning of 3D Pose Release Notes The official PyTorch implementation of Neural View S
 20 Oct 9, 2022
20 Oct 9, 2022

Image to Image translation, image generataton, few shot learning
Semi-supervised Learning for Few-shot Image-to-Image Translation [paper] Abstract: In the last few years, unpaired image-to-image translation has witn
 49 Nov 18, 2022
49 Nov 18, 2022
Learning to Self-Train for Semi-Supervised Few-Shot
Learning to Self-Train for Semi-Supervised Few-Shot Classification This repository contains the TensorFlow implementation for NeurIPS 2019 Paper "Lear
 86 Dec 29, 2022
86 Dec 29, 2022
Meta Learning for Semi-Supervised Few-Shot Classification
few-shot-ssl-public Code for paper Meta-Learning for Semi-Supervised Few-Shot Classification. [arxiv] Dependencies cv2 numpy pandas python 2.7 / 3.5+
 501 Jan 8, 2023
501 Jan 8, 2023

The code of Zero-shot learning for low-light image enhancement based on dual iteration
Zero-shot-dual-iter-LLE The code of Zero-shot learning for low-light image enhancement based on dual iteration. You can get the real night image tests
 1 Mar 18, 2022
1 Mar 18, 2022
Pytorch implementation of the paper "COAD: Contrastive Pre-training with Adversarial Fine-tuning for Zero-shot Expert Linking."
Expert-Linking Pytorch implementation of the paper "COAD: Contrastive Pre-training with Adversarial Fine-tuning for Zero-shot Expert Linking." This is
 12 Jan 1, 2023
12 Jan 1, 2023
Multilingual Image Captioning
Multilingual Image Captioning Authors: Bhavitvya Malik, Gunjan Chhablani Demo Link: https://huggingface.co/spaces/flax-community/multilingual-image-ca
 32 Nov 25, 2022
32 Nov 25, 2022
Rocks vc Userbot: A Telegram Bot Project That's Allow You To Play Audio And Video Music On Telegram Voice Chat Group
⭐️ Rocks VC Userbot ⭐️ Telegram Userbot To Play Audio And Video Song On VC Chat
 10 Jul 18, 2022
10 Jul 18, 2022
Youtube video downloader and info extractor for python.
tube_dl Tube_dl is a Simple Youtube video downloader for Python. A Modular approach to bypass and download Youtube Videos and Playlist from Youtube us
 16 Jul 9, 2022
16 Jul 9, 2022
Telegram music & video bot direct play music
⚡ NOINOI MUSIC PLAYER 🎵 SUPERFAST MUSIC BOT WHO CAN DIRECT PLAY SONG ON TELEGRAM VOICE CHAT ALSO CAN PLAY VIDEO ON VOICE CHATS ✨ Heroku Deploy YOU CA
 3 Dec 29, 2021
3 Dec 29, 2021
Reproduce results and replicate training fo T0 (Multitask Prompted Training Enables Zero-Shot Task Generalization)
T-Zero This repository serves primarily as codebase and instructions for training, evaluation and inference of T0. T0 is the model developed in Multit
 253 Dec 27, 2022
253 Dec 27, 2022

A stable and Fast telegram video convertor bot which can compress, convert(video into audio and other video formats), rename with permanent thumbnail and trim.
ᴠɪᴅᴇᴏ ᴄᴏɴᴠᴇʀᴛᴏʀ A stable and Fast telegram video convertor bot which can compress, convert(video into audio and other video formats), rename and trim.
 183 Jan 4, 2023
183 Jan 4, 2023

Align and Prompt: Video-and-Language Pre-training with Entity Prompts
ALPRO Align and Prompt: Video-and-Language Pre-training with Entity Prompts [Paper] Dongxu Li, Junnan Li, Hongdong Li, Juan Carlos Niebles, Steven C.H
 127 Dec 21, 2022
127 Dec 21, 2022

Intelligent Video Analytics toolkit based on different inference backends.
English | 中文 OpenIVA OpenIVA is an end-to-end intelligent video analytics development toolkit based on different inference backends, designed to help
 15 Oct 27, 2022
15 Oct 27, 2022

N-Omniglot is a large neuromorphic few-shot learning dataset
N-Omniglot [Paper] || [Dataset] N-Omniglot is a large neuromorphic few-shot learning dataset. It reconstructs strokes of Omniglot as videos and uses D
 11 Dec 5, 2022
11 Dec 5, 2022

Official Pytorch Implementation of 3DV2021 paper: SAFA: Structure Aware Face Animation.
SAFA: Structure Aware Face Animation (3DV2021) Official Pytorch Implementation of 3DV2021 paper: SAFA: Structure Aware Face Animation. Getting Started
 122 Dec 23, 2022
122 Dec 23, 2022

Official code for the paper "Self-Supervised Prototypical Transfer Learning for Few-Shot Classification"
Self-Supervised Prototypical Transfer Learning for Few-Shot Classification This repository contains the reference source code and pre-trained models (
 44 Nov 4, 2022
44 Nov 4, 2022

Unsupervised Learning of Video Representations using LSTMs
Unsupervised Learning of Video Representations using LSTMs Code for paper Unsupervised Learning of Video Representations using LSTMs by Nitish Srivast
 341 Dec 20, 2022
341 Dec 20, 2022

Official implementation of ACMMM'20 paper 'Self-supervised Video Representation Learning Using Inter-intra Contrastive Framework'
Self-supervised Video Representation Learning Using Inter-intra Contrastive Framework Official code for paper, Self-supervised Video Representation Le
 103 Dec 21, 2022
103 Dec 21, 2022

Implementation of our paper "Video Playback Rate Perception for Self-supervised Spatio-Temporal Representation Learning".
PRP Introduction This is the implementation of our paper "Video Playback Rate Perception for Self-supervised Spatio-Temporal Representation Learning".
 39 Dec 29, 2022
39 Dec 29, 2022

code for our ECCV-2020 paper: Self-supervised Video Representation Learning by Pace Prediction
Video_Pace This repository contains the code for the following paper: Jiangliu Wang, Jianbo Jiao and Yunhui Liu, "Self-Supervised Video Representation
 95 Dec 14, 2022
95 Dec 14, 2022
Video Representation Learning by Recognizing Temporal Transformations. In ECCV, 2020.
Video Representation Learning by Recognizing Temporal Transformations [Project Page] Simon Jenni, Givi Meishvili, and Paolo Favaro. In ECCV, 2020. Thi
 46 Nov 14, 2022
46 Nov 14, 2022
![[NeurIPS'20] Self-supervised Co-Training for Video Representation Learning. Tengda Han, Weidi Xie, Andrew Zisserman.](https://github.com/TengdaHan/CoCLR/raw/main/asset/teaser.png)
[NeurIPS'20] Self-supervised Co-Training for Video Representation Learning. Tengda Han, Weidi Xie, Andrew Zisserman.
CoCLR: Self-supervised Co-Training for Video Representation Learning This repository contains the implementation of: InfoNCE (MoCo on videos) UberNCE
 271 Jan 2, 2023
271 Jan 2, 2023
![[arXiv 2020] Video Representation Learning with Visual Tempo Consistency](https://github.com/decisionforce/VTHCL/raw/master/docs/figures/pipeline.png)
[arXiv 2020] Video Representation Learning with Visual Tempo Consistency
Video Representation Learning with Visual Tempo Consistency [Paper] [Project Page] News Full codebae is coming soon Pretained Models For now, we provi
 24 Nov 23, 2022
24 Nov 23, 2022

Official Pytorch implementation for AAAI2021 paper (RSPNet: Relative Speed Perception for Unsupervised Video Representation Learning)
RSPNet Official Pytorch implementation for AAAI2021 paper "RSPNet: Relative Speed Perception for Unsupervised Video Representation Learning" [Suppleme
 35 Jun 24, 2022
35 Jun 24, 2022

AdaFocus V2: End-to-End Training of Spatial Dynamic Networks for Video Recognition
AdaFocusV2 This repo contains the official code and pre-trained models for AdaFo
 79 Dec 26, 2022
79 Dec 26, 2022

Python package to display video in GUI using OpenCV-Python and PySide6
Python package to display video in GUI using OpenCV-Python and PySide6. Introduction cv2PySide6 is a package which provides utility classes and functi
 3 Jun 6, 2022
3 Jun 6, 2022
Asad Alexa VC Bot Is A Telegram Bot Project That's Allow You To Play Audio And Video Music On Telegram Voice Chat Group.
Asad Alexa VC Bot Is A Telegram Bot Project That's Allow You To Play Audio And Video Music On Telegram Voice Chat Group.
6 Jun 20, 2022
Telegram music & video bot direct play music
Telegram music & video bot direct play music
1 Dec 28, 2021
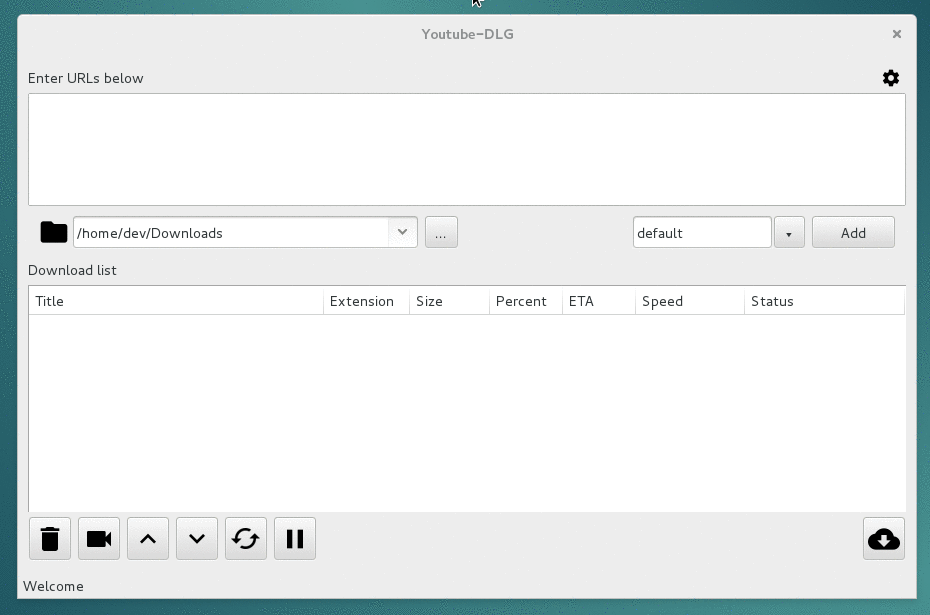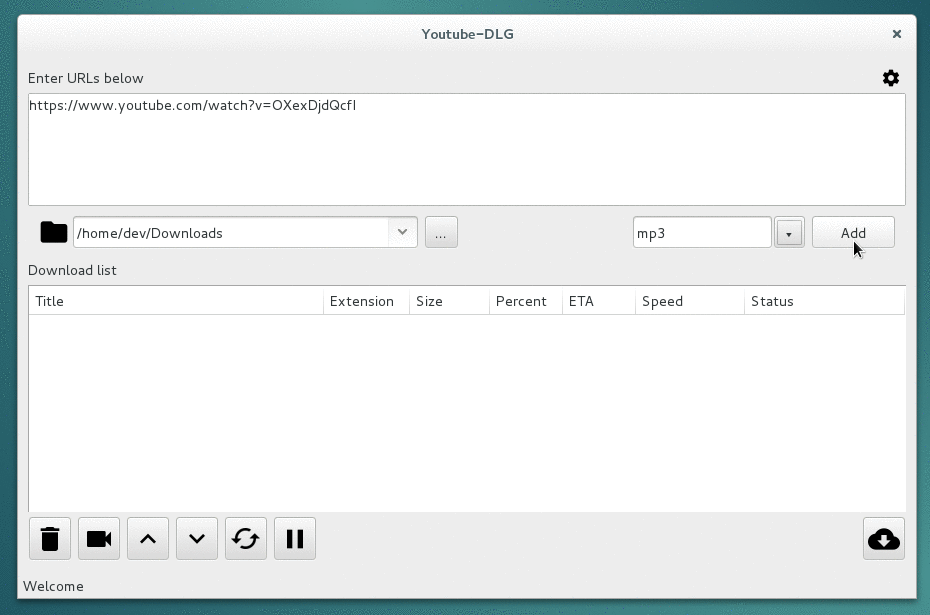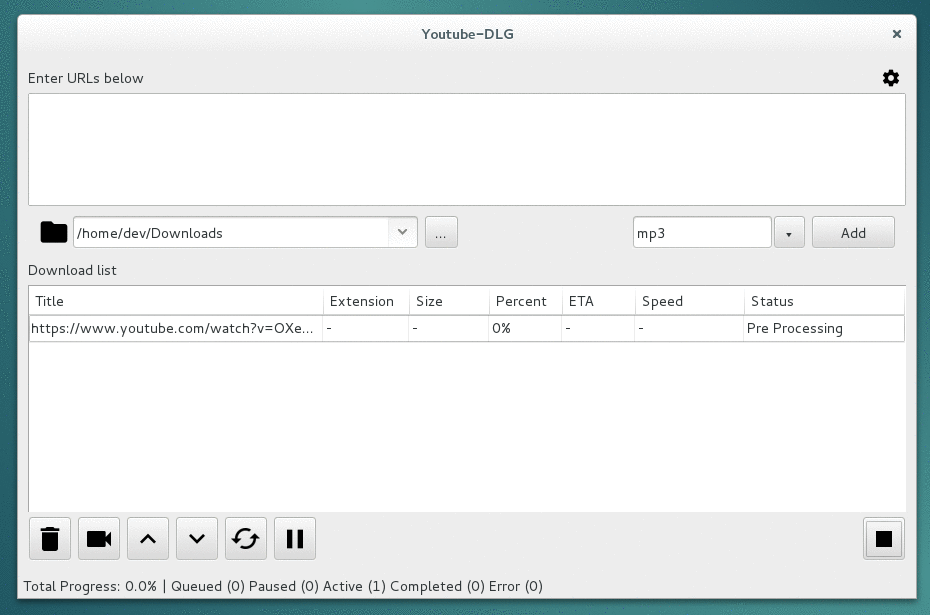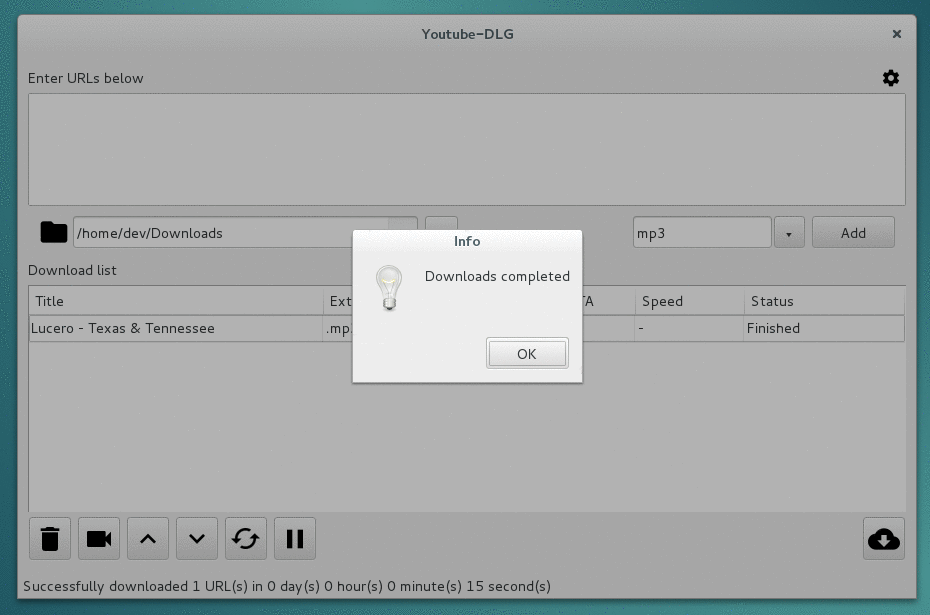
A cross platform front-end GUI of the popular youtube-dl written in wxPython.
youtube-dlG A cross platform front-end GUI of the popular youtube-dl media downloader written in wxPython. Supported sites Screenshots Requirements Py
 8.7k Dec 31, 2022
8.7k Dec 31, 2022

XViT - Space-time Mixing Attention for Video Transformer
XViT - Space-time Mixing Attention for Video Transformer This is the official implementation of the XViT paper: @inproceedings{bulat2021space, title
 33 Dec 23, 2022
33 Dec 23, 2022
A curated list of the latest breakthroughs in AI (in 2021) by release date with a clear video explanation, link to a more in-depth article, and code.
2021: A Year Full of Amazing AI papers- A Review 📌 A curated list of the latest breakthroughs in AI by release date with a clear video explanation, l
 2.9k Dec 31, 2022
2.9k Dec 31, 2022
Tkinter based YouTube video downloader works on pytube 11.0.2. Can download YouTube videos in 720p(HD), 144p and even only audio.
YouTube-Downloader Tkinter based YouTube video downloader works on pytube 11.0.2. Can download YouTube videos in 720p(HD), 144p and even only audio. G
 2 Dec 27, 2021
2 Dec 27, 2021

FingerPy is a algorithm to measure, analyse and monitor heart-beat using only a video of the user's finger on a mobile cellphone camera.
FingerPy is a algorithm using python, scipy and fft to measure, analyse and monitor heart-beat using only a video of the user's finger on a m
 37 Oct 21, 2022
37 Oct 21, 2022
python based bot Sends notification to your telegram whenever a new video is released on a youtube channel!
YTnotifier python based bot Sends notification to your telegram whenever a new video is released on a youtube channel! REQUIREMENTS telethon python-de
 6 Jul 23, 2022
6 Jul 23, 2022
Breaking Shortcut: Exploring Fully Convolutional Cycle-Consistency for Video Correspondence Learning
Breaking Shortcut: Exploring Fully Convolutional Cycle-Consistency for Video Correspondence Learning Yansong Tang *, Zhenyu Jiang *, Zhenda Xie *, Yue
 12 Nov 16, 2022
12 Nov 16, 2022
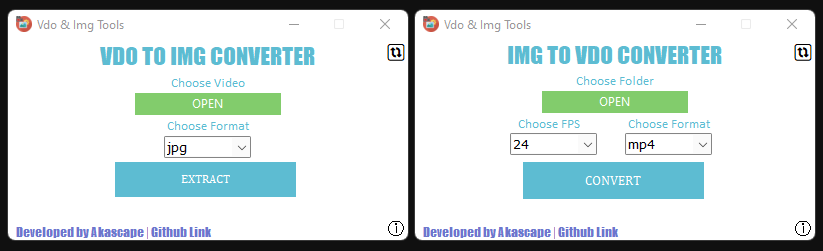
An easy to use GUI based video to image sequence converter (and vice versa).
Vdo & Img Conversion Tools This is a quick conversion tool made with python that can save you a lot of time. With this tool you can extract image sequ
 3 Sep 18, 2022
3 Sep 18, 2022

Traditional deepdream with VQGAN+CLIP and optical flow. Ready to use in Google Colab
VQGAN-CLIP-Video cat.mp4 policeman.mp4 schoolboy.mp4 forsenBOG.mp4
 23 Oct 26, 2022
23 Oct 26, 2022
Telegram bot for stream music or video on telegram
KYURA MUSIC Telegram bot for stream music or video on telegram, powered by PyTgCalls and Pyrogram Help Need Help me to translate this repo, click the
 0 Dec 8, 2022
0 Dec 8, 2022
Lightweight, zero-dependency proxy and storage RTSP server
python-rtsp-server Python-rtsp-server is a lightweight, zero-dependency proxy and storage server for several IP-cameras and multiple clients. Features
 39 Nov 23, 2022
39 Nov 23, 2022

Codes for the paper Contrast and Mix: Temporal Contrastive Video Domain Adaptation with Background Mixing
Contrast and Mix (CoMix) The repository contains the codes for the paper Contrast and Mix: Temporal Contrastive Video Domain Adaptation with Backgroun
 13 Dec 10, 2022
13 Dec 10, 2022
Automatically segment in-video YouTube sponsorships.
SponsorBlock Auto Segment [Model Download] Automatically segment in-video YouTube sponsorships. Trained on a large dataset of YouTube sponsor transcri
 7 Aug 22, 2022
7 Aug 22, 2022
🐥Flappy Birds🐤 Video game. With your help I can go through🚀 the pipes. All UI is made with 🐍Pygame🐍
🐠 Flappy Fish 🐢 I am Flappy Fish 🐟 . With your help I can jump through the pipes and experience an interesting and exciting flight deep into the fi
 2 Jan 14, 2022
2 Jan 14, 2022

Official Implementation of VAT
Semantic correspondence Few-shot segmentation Cost Aggregation Is All You Need for Few-Shot Segmentation For more information, check out project [Proj
 114 Dec 27, 2022
114 Dec 27, 2022
Create a Video Membership app using FastAPI & NoSQL
Video Membership Create a Video Membership app using FastAPI & NoSQL. In this series, we're going to explore building a membership application using F
 69 Dec 25, 2022
69 Dec 25, 2022

Turn any live video stream or locally stored video into a dataset of interesting samples for ML training, or any other type of analysis.
Sieve Video Data Collection Example Find samples that are interesting within hours of raw video, for free and completely automatically using Sieve API
 72 Aug 1, 2022
72 Aug 1, 2022