1060 Repositories
Python zero-shot-video-captioning Libraries

VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training [Arxiv] VideoMAE: Masked Autoencoders are Data-Efficient Learne
 697 Jan 7, 2023
697 Jan 7, 2023

Temporally Efficient Vision Transformer for Video Instance Segmentation, CVPR 2022, Oral
Temporally Efficient Vision Transformer for Video Instance Segmentation Temporally Efficient Vision Transformer for Video Instance Segmentation (CVPR
 203 Dec 31, 2022
203 Dec 31, 2022

Official code for CVPR2022 paper: Depth-Aware Generative Adversarial Network for Talking Head Video Generation
📖 Depth-Aware Generative Adversarial Network for Talking Head Video Generation (CVPR 2022) 🔥 If DaGAN is helpful in your photos/projects, please hel
 503 Jan 4, 2023
503 Jan 4, 2023

The official repo for OC-SORT: Observation-Centric SORT on video Multi-Object Tracking. OC-SORT is simple, online and robust to occlusion/non-linear motion.
OC-SORT Observation-Centric SORT (OC-SORT) is a pure motion-model-based multi-object tracker. It aims to improve tracking robustness in crowded scenes
 325 Jan 5, 2023
325 Jan 5, 2023

Official code for "Towards An End-to-End Framework for Flow-Guided Video Inpainting" (CVPR2022)
E2FGVI (CVPR 2022) English | 简体中文 This repository contains the official implementation of the following paper: Towards An End-to-End Framework for Flo
 537 Jan 7, 2023
537 Jan 7, 2023
Official repository of "BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment"
BasicVSR_PlusPlus (CVPR 2022) [Paper] [Project Page] [Code] This is the official repository for BasicVSR++. Please feel free to raise issue related to
 227 Jan 1, 2023
227 Jan 1, 2023
The Pytorch code of "Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification", CVPR 2022 (Oral).
DeepBDC for few-shot learning Introduction In this repo, we provide the implementation of the following paper: "Joint Distribution Matters: Dee
 116 Dec 19, 2022
116 Dec 19, 2022

BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training By Likun Cai, Zhi Zhang, Yi Zhu, Li Zhang, Mu Li, Xiangyang Xue. This
 290 Dec 29, 2022
290 Dec 29, 2022
![[SIGGRAPH 2022 Journal Track] AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars](https://github.com/hongfz16/AvatarCLIP/raw/main/assets/tallandskinny_femalesoldier_arguing.gif)
[SIGGRAPH 2022 Journal Track] AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars Fangzhou Hong1* Mingyuan Zhang1* Liang Pan1 Zhongang Cai1,2,3 Lei Yang2
 749 Jan 4, 2023
749 Jan 4, 2023
Code for T-Few from "Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning"
T-Few This repository contains the official code for the paper: "Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learni
 220 Dec 31, 2022
220 Dec 31, 2022
Video Frame Interpolation with Transformer (CVPR2022)
VFIformer Official PyTorch implementation of our CVPR2022 paper Video Frame Interpolation with Transformer Dependencies python = 3.8 pytorch = 1.8.0
 63 Dec 16, 2022
63 Dec 16, 2022
csv2ir is a script to convert ir .csv files to .ir files for the flipper.
csv2ir csv2ir is a script to convert ir .csv files to .ir files for the flipper. For a repo of .ir files, please see https://github.com/logickworkshop
 38 Dec 31, 2022
38 Dec 31, 2022

Python library for tracking human heads with FLAME (a 3D morphable head model)
Video Head Tracker 3D tracking library for human heads based on FLAME (a 3D morphable head model). The tracking algorithm is inspired by face2face. It
 61 Dec 25, 2022
61 Dec 25, 2022
[CVPR 2022] Official PyTorch Implementation for "Reference-based Video Super-Resolution Using Multi-Camera Video Triplets"
Reference-based Video Super-Resolution (RefVSR) Official PyTorch Implementation of the CVPR 2022 Paper Project | arXiv | RealMCVSR Dataset This repo c
 151 Dec 30, 2022
151 Dec 30, 2022

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022
Official implementation of "CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding" (CVPR, 2022)
CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding (CVPR'22) Paper Link | Project Page Abstract : Manual an
 152 Dec 23, 2022
152 Dec 23, 2022

A Persian Image Captioning model based on Vision Encoder Decoder Models of the transformers🤗.
Persian-Image-Captioning We fine-tuning the Vision Encoder Decoder Model for the task of image captioning on the coco-flickr-farsi dataset. The implem
 15 Aug 25, 2022
15 Aug 25, 2022
Telegram Group Calls Streaming bot with some useful features, written in Python with Pyrogram and Py-Tgcalls. Supporting platforms like Youtube, Spotify, Resso, AppleMusic, Soundcloud and M3u8 Links.
Yukki Music Bot Yukki Music Bot is a Powerful Telegram Music+Video Bot written in Python using Pyrogram and Py-Tgcalls by which you can stream songs,
 996 Dec 28, 2022
996 Dec 28, 2022
Free course that takes you from zero to Reinforcement Learning PRO 🦸🏻🦸🏽
The Hands-on Reinforcement Learning course 🚀 From zero to HERO 🦸🏻🦸🏽 Out of intense complexities, intense simplicities emerge. -- Winston Churchi
 260 Dec 28, 2022
260 Dec 28, 2022

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023
An ever-growing playground of notebooks showcasing CLIP's impressive zero-shot capabilities.
Playground for CLIP-like models Demo Colab Link GradCAM Visualization Naive Zero-shot Detection Smarter Zero-shot Detection Captcha Solver Changelog 2
 101 Dec 30, 2022
101 Dec 30, 2022

Implements VQGAN+CLIP for image and video generation, and style transfers, based on text and image prompts. Emphasis on ease-of-use, documentation, and smooth video creation.
VQGAN-CLIP-GENERATOR Overview This is a package (with available notebook) for running VQGAN+CLIP locally, with a focus on ease of use, good documentat
 98 Dec 30, 2022
98 Dec 30, 2022

Official Implementation of "Third Time's the Charm? Image and Video Editing with StyleGAN3" https://arxiv.org/abs/2201.13433
Third Time's the Charm? Image and Video Editing with StyleGAN3 Yuval Alaluf*, Or Patashnik*, Zongze Wu, Asif Zamir, Eli Shechtman, Dani Lischinski, Da
 531 Dec 20, 2022
531 Dec 20, 2022

CLIPfa: Connecting Farsi Text and Images
CLIPfa: Connecting Farsi Text and Images OpenAI released the paper Learning Transferable Visual Models From Natural Language Supervision in which they
 66 Dec 14, 2022
66 Dec 14, 2022
Ego4d dataset repository. Download the dataset, visualize, extract features & example usage of the dataset
Ego4D EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated v
 118 Jan 7, 2023
118 Jan 7, 2023

Near Zero-Overhead Python Code Coverage
Slipcover: Near Zero-Overhead Python Code Coverage by Juan Altmayer Pizzorno and Emery Berger at UMass Amherst's PLASMA lab. About Slipcover Slipcover
 325 Dec 28, 2022
325 Dec 28, 2022
[CVPR 2022 Oral] TubeDETR: Spatio-Temporal Video Grounding with Transformers
TubeDETR: Spatio-Temporal Video Grounding with Transformers Website • STVG Demo • Paper This repository provides the code for our paper. This includes
 108 Dec 27, 2022
108 Dec 27, 2022

PromptDet: Expand Your Detector Vocabulary with Uncurated Images
PromptDet: Expand Your Detector Vocabulary with Uncurated Images Paper Website Introduction The goal of this work is to establish a scalable pipeline
 103 Dec 20, 2022
103 Dec 20, 2022

PyTorch implementations of the paper: "DR.VIC: Decomposition and Reasoning for Video Individual Counting, CVPR, 2022"
DRNet for Video Indvidual Counting (CVPR 2022) Introduction This is the official PyTorch implementation of paper: DR.VIC: Decomposition and Reasoning
 35 Nov 22, 2022
35 Nov 22, 2022

Official code for "Bridging Video-text Retrieval with Multiple Choice Questions", CVPR 2022 (Oral).
Bridging Video-text Retrieval with Multiple Choice Questions, CVPR 2022 (Oral) Paper | Project Page | Pre-trained Model | CLIP-Initialized Pre-trained
 99 Jan 6, 2023
99 Jan 6, 2023
UMT is a unified and flexible framework which can handle different input modality combinations, and output video moment retrieval and/or highlight detection results.
Unified Multi-modal Transformers This repository maintains the official implementation of the paper UMT: Unified Multi-modal Transformers for Joint Vi
84 Jan 4, 2023

Implementation of 🦩 Flamingo, state-of-the-art few-shot visual question answering attention net out of Deepmind, in Pytorch
🦩 Flamingo - Pytorch Implementation of Flamingo, state-of-the-art few-shot visual question answering attention net, in Pytorch. It will include the p
 630 Dec 28, 2022
630 Dec 28, 2022
Direct application of DALLE-2 to video synthesis, using factored space-time Unet and Transformers
DALLE2 Video (wip) ** only to be built after DALLE2 image is done and replicated, and the importance of the prior network is validated ** Direct appli
105 May 15, 2022
Python/Rust implementations and notes from Proofs Arguments and Zero Knowledge
What is this? This is where I'll be collecting resources related to the Study Group on Dr. Justin Thaler's Proofs Arguments And Zero Knowledge Book. T
 66 Jan 4, 2023
66 Jan 4, 2023
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022

The code is for the paper "A Self-Distillation Embedded Supervised Affinity Attention Model for Few-Shot Segmentation"
SD-AANet The code is for the paper "A Self-Distillation Embedded Supervised Affinity Attention Model for Few-Shot Segmentation" [arxiv] Overview confi
 9 Nov 7, 2022
9 Nov 7, 2022
An open souce video/music streamer based on MPV and piped.
🎶 Harmony Music An easy way to stream videos or music from Youtube from the command line while regaining your privacy. 📖 Table Of Contents ❔ What's
 16 Nov 15, 2022
16 Nov 15, 2022
Fast TikTok NO Watermark Video Downloader (username or url)
💎 TD [ TikDown v4 ] Star ⭐ if you want more Discord Server * discord.gg/onlp | Waxor#9999 Why not open source anymore ? * BECAUSE PEOPLE SKID, STEA
 26 Dec 1, 2022
26 Dec 1, 2022

Learning to compose soft prompts for compositional zero-shot learning.
Compositional Soft Prompting (CSP) Compositional soft prompting (CSP), a parameter-efficient learning technique to improve the zero-shot compositional
 32 Jan 2, 2023
32 Jan 2, 2023
![[arXiv22] Disentangled Representation Learning for Text-Video Retrieval](https://github.com/foolwood/DRL/raw/main/demo/pipeline.png)
[arXiv22] Disentangled Representation Learning for Text-Video Retrieval
Disentangled Representation Learning for Text-Video Retrieval This is a PyTorch implementation of the paper Disentangled Representation Learning for T
 49 Dec 18, 2022
49 Dec 18, 2022
"Video Moment Retrieval from Text Queries via Single Frame Annotation" in SIGIR 2022.
ViGA: Video moment retrieval via Glance Annotation This is the official repository of the paper "Video Moment Retrieval from Text Queries via Single F
 38 Dec 31, 2022
38 Dec 31, 2022

YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Created using Python, PyTube and PySimpleGUI.
YouTube Downloader YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Disclaimer It's
 3 Dec 14, 2022
3 Dec 14, 2022
vit for few-shot classification
Few-Shot ViT Requirements PyTorch (= 1.9) TorchVision timm (latest) einops tqdm numpy scikit-learn scipy argparse tensorboardx Pretrained Checkpoints
 26 Nov 30, 2022
26 Nov 30, 2022
scrape tiktok/douyin video list from specific user or keyword
get-tiktok-user-video-list scrape tiktok/douyin video list from specific user or keyword 以**https://www.douyin.com/user/MS4wLjABAAAAUpIowEL3ygUAahQB47
 4 Jul 6, 2022
4 Jul 6, 2022
Codes for "Template-free Prompt Tuning for Few-shot NER".
EntLM The source codes for EntLM. Dependencies: Cuda 10.1, python 3.6.5 To install the required packages by following commands: $ pip3 install -r requ
 77 Dec 27, 2022
77 Dec 27, 2022
Code for One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022)
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022) Paper | Demo Requirements Python = 3.6 , Pytorch
 84 Jan 3, 2023
84 Jan 3, 2023
MAU: A Motion-Aware Unit for Video Prediction and Beyond, NeurIPS2021
MAU (NeurIPS2021) Zheng Chang, Xinfeng Zhang, Shanshe Wang, Siwei Ma, Yan Ye, Xinguang Xiang, Wen GAo. Official PyTorch Code for "MAU: A Motion-Aware
 20 Nov 25, 2022
20 Nov 25, 2022
2022-bridge - Example code belonging to the Bridge pattern video
Let's Take The Bridge Pattern To The Next Level This video covers how the bridge
 11 Jun 14, 2022
11 Jun 14, 2022

ZeroGen: Efficient Zero-shot Learning via Dataset Generation
ZEROGEN This repository contains the code for our paper “ZeroGen: Efficient Zero
 31 Dec 30, 2022
31 Dec 30, 2022
Alpha-Zero - Telegram Group Manager Bot Written In Python Using Pyrogram
✨ Alpha Zero Bot ✨ Telegram Group Manager Bot + Userbot Written In Python Using
 1 Feb 17, 2022
1 Feb 17, 2022
Programmers-quest - Programmer's Quest! An open source MMO built on top of the Panda3D game engine and Astron server
Programmer's Quest! Programmer's Quest! The open source Python 3 2D MMORPG showc
 5 Oct 7, 2022
5 Oct 7, 2022

Digan - Official PyTorch implementation of Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
DIGAN (ICLR 2022) Official PyTorch implementation of "Generating Videos with Dyn
 147 Dec 31, 2022
147 Dec 31, 2022
Source code to accompany Defunctland's video "FASTPASS: A Complicated Legacy"
Shapeland Simulator Source code to accompany Defunctland's video "FASTPASS: A Complicated Legacy" Download the video at https://www.youtube.com/watch?
 70 Dec 14, 2022
70 Dec 14, 2022

RIFE - Real-Time Intermediate Flow Estimation for Video Frame Interpolation
RIFE - Real-Time Intermediate Flow Estimation for Video Frame Interpolation YouTube | BiliBili 16X interpolation results from two input images: Introd
 28 Dec 9, 2022
28 Dec 9, 2022
Code To Tune or Not To Tune? Zero-shot Models for Legal Case Entailment.
COLIEE 2021 - task 2: Legal Case Entailment This repository contains the code to reproduce NeuralMind's submissions to COLIEE 2021 presented in the pa
 13 Dec 16, 2022
13 Dec 16, 2022

HCQ: Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval
HCQ: Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval [toc] 1. Introduction This repository provides the code for our paper at
 13 Dec 8, 2022
13 Dec 8, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
1.4k Jan 8, 2023
Vitrix is an open-source FPS video game coded in python
Vitrix is an open-source FPS video game coded in python Table of contents Usage Game Server Installing Requirements Hardware Requirements Software Req
 1 Feb 13, 2022
1 Feb 13, 2022
The zero player Darwinism simulation game as described by Conway (demonstrates Turing Completeness)
Conway's Game of Life The zero player Darwinism simulation game as described by Conway (demonstrates Turing Completeness). I created this script after
 1 Feb 13, 2022
1 Feb 13, 2022

Tensorflow 2 implementation of our high quality frame interpolation neural network
FILM: Frame Interpolation for Large Scene Motion Project | Paper | YouTube | Benchmark Scores Tensorflow 2 implementation of our high quality frame in
 1.6k Dec 28, 2022
1.6k Dec 28, 2022

Zero-Cost Proxies for Lightweight NAS
Zero-Cost-NAS Companion code for the ICLR2021 paper: Zero-Cost Proxies for Lightweight NAS tl;dr A single minibatch of data is used to score neural ne
 108 Dec 20, 2022
108 Dec 20, 2022
One-Shot Neural Ensemble Architecture Search by Diversity-Guided Search Space Shrinking
One-Shot Neural Ensemble Architecture Search by Diversity-Guided Search Space Shrinking This is an official implementation for NEAS presented in CVPR
 19 Sep 8, 2022
19 Sep 8, 2022

A python scripts that uses 3 different feature extraction methods such as SIFT, SURF and ORB to find a book in a video clip and project trailer of a movie based on that book, on to it.
A python scripts that uses 3 different feature extraction methods such as SIFT, SURF and ORB to find a book in a video clip and project trailer of a movie based on that book, on to it.
 3 Feb 10, 2022
3 Feb 10, 2022
Official repository for GCR rerank, a GCN-based reranking method for both image and video re-ID
Official repository for GCR rerank, a GCN-based reranking method for both image and video re-ID
 53 Nov 22, 2022
53 Nov 22, 2022

Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
 58 Dec 24, 2022
58 Dec 24, 2022
End-to-end image captioning with EfficientNet-b3 + LSTM with Attention
Image captioning End-to-end image captioning with EfficientNet-b3 + LSTM with Attention Model is seq2seq model. In the encoder pretrained EfficientNet
 2 Feb 10, 2022
2 Feb 10, 2022

SCI-AIDE : High-fidelity Few-shot Histopathology Image Synthesis for Rare Cancer Diagnosis
SCI-AIDE : High-fidelity Few-shot Histopathology Image Synthesis for Rare Cancer Diagnosis Pretrained Models In this work, we created synthetic tissue
 1 Feb 7, 2022
1 Feb 7, 2022
This bot plays the most recent video from the Daily Silksong News Youtube Channel whenever a specific user enters voice chat once a day.
Do you have that one friend that really likes Hollow Knight. Are they waiting for Silksong to come out? Heckle them with this Discord bot.
 2 Feb 9, 2022
2 Feb 9, 2022

The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding.
SuperGen The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. Requirements Before running, you
 38 Dec 12, 2022
38 Dec 12, 2022

Youtube Downloader is a simple but highly efficient Youtube Video Downloader, made completly using Python
Youtube Downloader is a simple but highly efficient Youtube Video Downloader, made completly using Python
 2 Nov 26, 2022
2 Nov 26, 2022
A motion tracking system for any arbitaray points in a video frame.
PointTracking This code is written by Majid Masoumi @ [email protected] I have used lucas kanade optical flow technique to track the points b
 1 Feb 9, 2022
1 Feb 9, 2022

Official implementation for paper Render In-between: Motion Guided Video Synthesis for Action Interpolation
Render In-between: Motion Guided Video Synthesis for Action Interpolation [Paper] [Supp] [arXiv] [4min Video] This is the official Pytorch implementat
 8 Oct 27, 2022
8 Oct 27, 2022

Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
 7 Nov 9, 2022
7 Nov 9, 2022
Cascaded Deep Video Deblurring Using Temporal Sharpness Prior and Non-local Spatial-Temporal Similarity
This repository is the official PyTorch implementation of Cascaded Deep Video Deblurring Using Temporal Sharpness Prior and Non-local Spatial-Temporal Similarity
 4 Dec 11, 2022
4 Dec 11, 2022
 15 Apr 12, 2022
15 Apr 12, 2022
Temporal Alignment Prediction for Supervised Representation Learning and Few-Shot Sequence Classification
Temporal Alignment Prediction for Supervised Representation Learning and Few-Shot Sequence Classification Introduction. This package includes the pyth
 5 Dec 6, 2022
5 Dec 6, 2022
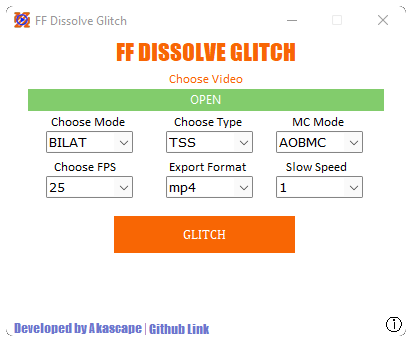
A GUI based glitch tool that uses FFMPEG to create motion interpolated glitches in your videos.
FF Dissolve Glitch This is a GUI based glitch tool that uses FFmpeg to create awesome and wierd motion interpolated glitches in videos. I call it FF d
 19 Nov 10, 2022
19 Nov 10, 2022
VideoMergeDcBot1 - Video Merge Dc Bot for telegram
VIDEO MERGE BOT An Telegram Bot Demo 👉 @VideoMergeDcBot To Merge multiple Video
 2 Feb 4, 2022
2 Feb 4, 2022

Splat a video into a mosaic by sampling a frame at regular intervals
Splat a video into a mosaic by sampling a frame at regular intervals. Useful for seeing the changes over time of an entire video or movie.
 4 Oct 16, 2022
4 Oct 16, 2022

Simple Python script that lets you upload image/video to imgur
Pymgur 🐍 Simple Python script that lets you upload image/video to imgur! Usage 🔨 Git Clone this repository install the requirements (pip install -r
 3 Feb 20, 2022
3 Feb 20, 2022
Video-face-extractor - Video face extractor with Python
Python face extractor Setup Create the srcvideos and faces directories Put your
 2 Feb 3, 2022
2 Feb 3, 2022
Terminal-Video-Player - A program that can display video in the terminal using ascii characters
Terminal-Video-Player - A program that can display video in the terminal using ascii characters
 15 Nov 10, 2022
15 Nov 10, 2022
Constrained Language Models Yield Few-Shot Semantic Parsers
Constrained Language Models Yield Few-Shot Semantic Parsers This repository contains tools and instructions for reproducing the experiments in the pap
 43 Nov 23, 2022
43 Nov 23, 2022
traiNNer is an open source image and video restoration (super-resolution, denoising, deblurring and others) and image to image translation toolbox based on PyTorch.
traiNNer traiNNer is an open source image and video restoration (super-resolution, denoising, deblurring and others) and image to image translation to
 202 Jan 4, 2023
202 Jan 4, 2023

camKapture is an open source application that allows users to access their webcam device and take pictures or create videos.
camKapture is an open source application that allows users to access their webcam device and take pictures or create videos.
 1 Jun 21, 2022
1 Jun 21, 2022
Video-stream - A telegram video stream bot repo
This is a Telegram Video stream Bot. Binary Tech 💫 Features stream videos downl
 1 Feb 2, 2022
1 Feb 2, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
Supervised Sliding Window Smoothing Loss Function Based on MS-TCN for Video Segmentation
SSWS-loss_function_based_on_MS-TCN Supervised Sliding Window Smoothing Loss Function Based on MS-TCN for Video Segmentation Supervised Sliding Window
 3 Aug 3, 2022
3 Aug 3, 2022

PyTorch implementation of "VRT: A Video Restoration Transformer"
VRT: A Video Restoration Transformer Jingyun Liang, Jiezhang Cao, Yuchen Fan, Kai Zhang, Rakesh Ranjan, Yawei Li, Radu Timofte, Luc Van Gool Computer
 837 Jan 9, 2023
837 Jan 9, 2023
Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners
DART Implementation for ICLR2022 paper Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners. Environment [email protected] Use pi
 83 Dec 27, 2022
83 Dec 27, 2022
Self-Supervised Deep Blind Video Super-Resolution
Self-Blind-VSR Paper | Discussion Self-Supervised Deep Blind Video Super-Resolution By Haoran Bai and Jinshan Pan Abstract Existing deep learning-base
 35 Dec 9, 2022
35 Dec 9, 2022

Distance-Ratio-Based Formulation for Metric Learning
Distance-Ratio-Based Formulation for Metric Learning Environment Python3 Pytorch (http://pytorch.org/) (version 1.6.0+cu101) json tqdm Preparing datas
 1 Dec 7, 2022
1 Dec 7, 2022

PyTorch implementation for the paper Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime
Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime Created by Prarthana Bhattacharyya. Disclaimer: This is n
 5 Nov 8, 2022
5 Nov 8, 2022
EASY - Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients.
EASY - Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients. This repository is the official im
 57 Dec 26, 2022
57 Dec 26, 2022

PyTorch implementation of our paper How robust are discriminatively trained zero-shot learning models?
How robust are discriminatively trained zero-shot learning models? This repository contains the PyTorch implementation of our paper How robust are dis
 5 Feb 4, 2022
5 Feb 4, 2022
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques This repository is derived from the NMTGMinor
 1 Sep 7, 2022
1 Sep 7, 2022
Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation
Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation Prerequisites This repo is built upon a local copy of transfo
 10 Sep 28, 2022
10 Sep 28, 2022

Blind Video Temporal Consistency via Deep Video Prior
deep-video-prior (DVP) Code for NeurIPS 2020 paper: Blind Video Temporal Consistency via Deep Video Prior PyTorch implementation | paper | project web
 272 Dec 21, 2022
272 Dec 21, 2022

Labelme is a graphical image annotation tool, It is written in Python and uses Qt for its graphical interface
Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).
 9.6k Jan 9, 2023
9.6k Jan 9, 2023

Human Dynamics from Monocular Video with Dynamic Camera Movements
Human Dynamics from Monocular Video with Dynamic Camera Movements Ri Yu, Hwangpil Park and Jehee Lee Seoul National University ACM Transactions on Gra
 215 Jan 1, 2023
215 Jan 1, 2023