Filter By
7418 Repositories
Python Deep Learning

Text2Art is an AI art generator powered with VQGAN + CLIP and CLIPDrawer models
Text2Art is an AI art generator powered with VQGAN + CLIP and CLIPDrawer models. You can easily generate all kind of art from drawing, painting, sketch, or even a specific artist style just using a text input. You can also specify the dimensions of the image. The process can take 3-20 mins and the results will be emailed to you.
 643 Dec 30, 2022
643 Dec 30, 2022
A research toolkit for particle swarm optimization in Python
PySwarms is an extensible research toolkit for particle swarm optimization (PSO) in Python. It is intended for swarm intelligence researchers, practit
 1k Dec 30, 2022
1k Dec 30, 2022
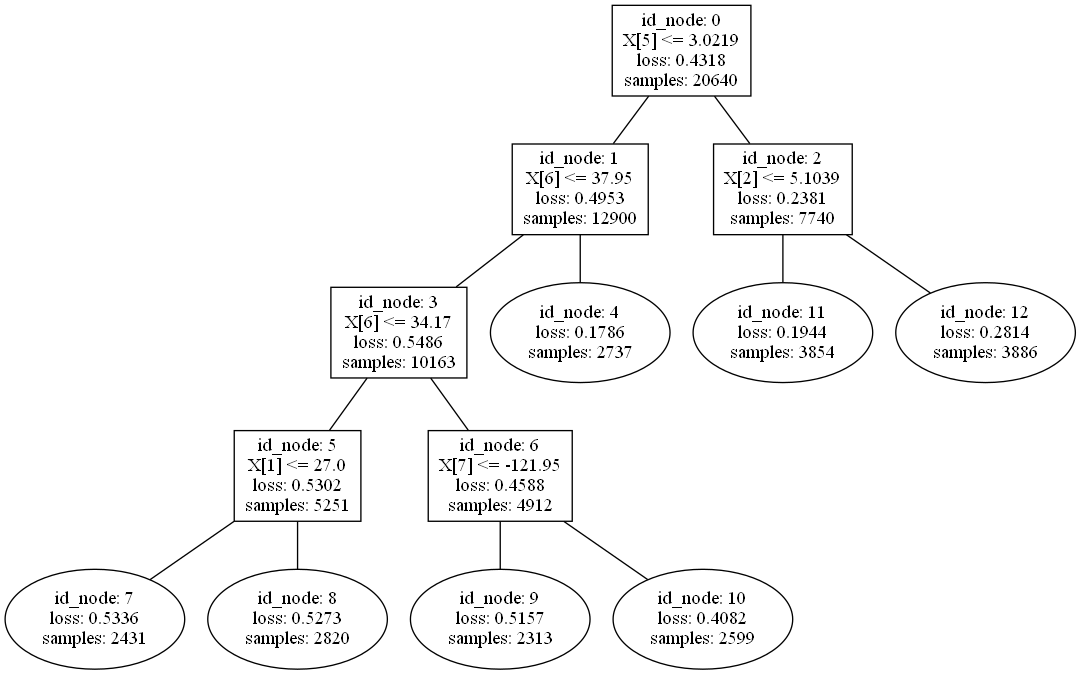
A python library to build Model Trees with Linear Models at the leaves.
A python library to build Model Trees with Linear Models at the leaves.
 212 Dec 30, 2022
212 Dec 30, 2022

This repository contains various models targetting multimodal representation learning, multimodal fusion for downstream tasks such as multimodal sentiment analysis.
Multimodal Deep Learning 🎆 🎆 🎆 Announcing the multimodal deep learning repository that contains implementation of various deep learning-based model
 398 Dec 30, 2022
398 Dec 30, 2022
![[CVPR'22] Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast](https://user-images.githubusercontent.com/83934424/157233454-9a0fbae6-2e05-4285-9042-70af1449ad96.png)
[CVPR'22] Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast
wseg Overview The Pytorch implementation of Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast. [arXiv] Though image-level weakly
 96 Dec 30, 2022
96 Dec 30, 2022

Implementations of orthogonal and semi-orthogonal convolutions in the Fourier domain with applications to adversarial robustness
Orthogonalizing Convolutional Layers with the Cayley Transform This repository contains implementations and source code to reproduce experiments for t
 36 Dec 30, 2022
36 Dec 30, 2022
![[CVPRW 21]](https://github.com/VITA-Group/BNN_NoBN/raw/main/Figs/res.png)
[CVPRW 21] "BNN - BN = ? Training Binary Neural Networks without Batch Normalization", Tianlong Chen, Zhenyu Zhang, Xu Ouyang, Zechun Liu, Zhiqiang Shen, Zhangyang Wang
BNN - BN = ? Training Binary Neural Networks without Batch Normalization Codes for this paper BNN - BN = ? Training Binary Neural Networks without Bat
 40 Dec 30, 2022
40 Dec 30, 2022
Codes for our paper "SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge" (EMNLP 2020)
SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge Introduction SentiLARE is a sentiment-aware pre-trained language
 74 Dec 30, 2022
74 Dec 30, 2022
Multi-layer convolutional LSTM with Pytorch
Convolution_LSTM_pytorch Thanks for your attention. I haven't got time to maintain this repo for a long time. I recommend this repo which provides an
 733 Dec 30, 2022
733 Dec 30, 2022

Official MegEngine implementation of CREStereo(CVPR 2022 Oral).
[CVPR 2022] Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation This repository contains MegEngine implementation of ou
 309 Dec 30, 2022
309 Dec 30, 2022
🏎️ Accelerate training and inference of 🤗 Transformers with easy to use hardware optimization tools
Hugging Face Optimum 🤗 Optimum is an extension of 🤗 Transformers, providing a set of performance optimization tools enabling maximum efficiency to t
 842 Dec 30, 2022
842 Dec 30, 2022
Official code of our work, Unified Pre-training for Program Understanding and Generation [NAACL 2021].
PLBART Code pre-release of our work, Unified Pre-training for Program Understanding and Generation accepted at NAACL 2021. Note. A detailed documentat
 138 Dec 30, 2022
138 Dec 30, 2022

 578 Dec 30, 2022
578 Dec 30, 2022
Official repository for "Restormer: Efficient Transformer for High-Resolution Image Restoration". SOTA for motion deblurring, image deraining, denoising (Gaussian/real data), and defocus deblurring.
Restormer: Efficient Transformer for High-Resolution Image Restoration Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan,
 906 Dec 30, 2022
906 Dec 30, 2022
A PyTorch implementation of the architecture of Mask RCNN
EDIT (AS OF 4th NOVEMBER 2019): This implementation has multiple errors and as of the date 4th, November 2019 is insufficient to be utilized as a reso
 975 Dec 30, 2022
975 Dec 30, 2022

ManipulaTHOR, a framework that facilitates visual manipulation of objects using a robotic arm
ManipulaTHOR: A Framework for Visual Object Manipulation Kiana Ehsani, Winson Han, Alvaro Herrasti, Eli VanderBilt, Luca Weihs, Eric Kolve, Aniruddha
 65 Dec 30, 2022
65 Dec 30, 2022

CMT: Convolutional Neural Networks Meet Vision Transformers
CMT: Convolutional Neural Networks Meet Vision Transformers [arxiv] 1. Introduction This repo is the CMT model which impelement with pytorch, no refer
 83 Dec 30, 2022
83 Dec 30, 2022

Code for "NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video", CVPR 2021 oral
NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video Project Page | Paper NeuralRecon: Real-Time Coherent 3D Reconstruction from Mon
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

PyMatting: A Python Library for Alpha Matting
Given an input image and a hand-drawn trimap (top row), alpha matting estimates the alpha channel of a foreground object which can then be composed onto a different background (bottom row).
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

SMPLpix: Neural Avatars from 3D Human Models
subject0_validation_poses.mp4 Left: SMPL-X human mesh registered with SMPLify-X, middle: SMPLpix render, right: ground truth video. SMPLpix: Neural Av
 292 Dec 30, 2022
292 Dec 30, 2022
Bonnet: An Open-Source Training and Deployment Framework for Semantic Segmentation in Robotics.
Bonnet: An Open-Source Training and Deployment Framework for Semantic Segmentation in Robotics. By Andres Milioto @ University of Bonn. (for the new P
 314 Dec 30, 2022
314 Dec 30, 2022

Code for the upcoming CVPR 2021 paper
The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth Jamie Watson, Oisin Mac Aodha, Victor Prisacariu, Gabriel J. Brostow and Michael
 496 Dec 30, 2022
496 Dec 30, 2022

An official implementation of "SFNet: Learning Object-aware Semantic Correspondence" (CVPR 2019, TPAMI 2020) in PyTorch.
PyTorch implementation of SFNet This is the implementation of the paper "SFNet: Learning Object-aware Semantic Correspondence". For more information,
 87 Dec 30, 2022
87 Dec 30, 2022

Bayesian optimisation library developped by Huawei Noah's Ark Library
Bayesian Optimisation Research This directory contains official implementations for Bayesian optimisation works developped by Huawei R&D, Noah's Ark L
 395 Dec 30, 2022
395 Dec 30, 2022

Merlion: A Machine Learning Framework for Time Series Intelligence
Merlion: A Machine Learning Library for Time Series Table of Contents Introduction Installation Documentation Getting Started Anomaly Detection Foreca
 2.8k Dec 30, 2022
2.8k Dec 30, 2022

Official implementation of the ICCV 2021 paper "Conditional DETR for Fast Training Convergence".
The DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings and that the spatial embeddings make minor contributions, increasing the need for high-quality content embeddings and thus increasing the training difficulty.
 281 Dec 30, 2022
281 Dec 30, 2022
This is an official implementation of CvT: Introducing Convolutions to Vision Transformers.
Introduction This is an official implementation of CvT: Introducing Convolutions to Vision Transformers. We present a new architecture, named Convolut
 408 Dec 30, 2022
408 Dec 30, 2022

Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding
Vision Longformer This project provides the source code for the vision longformer paper. Multi-Scale Vision Longformer: A New Vision Transformer for H
209 Dec 30, 2022
[CIKM 2019] Code and dataset for "Fi-GNN: Modeling Feature Interactions via Graph Neural Networks for CTR Prediction"
FiGNN for CTR prediction The code and data for our paper in CIKM2019: Fi-GNN: Modeling Feature Interactions via Graph Neural Networks for CTR Predicti
 75 Dec 30, 2022
75 Dec 30, 2022

Multi-Task Temporal Shift Attention Networks for On-Device Contactless Vitals Measurement (NeurIPS 2020)
MTTS-CAN: Multi-Task Temporal Shift Attention Networks for On-Device Contactless Vitals Measurement Paper Xin Liu, Josh Fromm, Shwetak Patel, Daniel M
 106 Dec 30, 2022
106 Dec 30, 2022

Learning Dense Representations of Phrases at Scale (Lee et al., 2020)
DensePhrases DensePhrases provides answers to your natural language questions from the entire Wikipedia in real-time. While it efficiently searches th
 540 Dec 30, 2022
540 Dec 30, 2022
Few-NERD: Not Only a Few-shot NER Dataset
Few-NERD: Not Only a Few-shot NER Dataset This is the source code of the ACL-IJCNLP 2021 paper: Few-NERD: A Few-shot Named Entity Recognition Dataset.
 319 Dec 30, 2022
319 Dec 30, 2022
A python library for face detection and features extraction based on mediapipe library
FaceAnalyzer A python library for face detection and features extraction based on mediapipe library Introduction FaceAnalyzer is a library based on me
 14 Dec 30, 2022
14 Dec 30, 2022

Source code for "OmniPhotos: Casual 360° VR Photography"
OmniPhotos: Casual 360° VR Photography Project Page | Video | Paper | Demo | Data This repository contains the source code for creating and viewing Om
 144 Dec 30, 2022
144 Dec 30, 2022

StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation
StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation Demo video: CVPR 2021 Oral: Single Channel Manipulation: Localized or attribu
 267 Dec 30, 2022
267 Dec 30, 2022

Code for "Neural 3D Scene Reconstruction with the Manhattan-world Assumption" CVPR 2022 Oral
News 05/10/2022 To make the comparison on ScanNet easier, we provide all quantitative and qualitative results of baselines here, including COLMAP, COL
365 Dec 30, 2022

PyTorch implementation of SimSiam: Exploring Simple Siamese Representation Learning
SimSiam: Exploring Simple Siamese Representation Learning This is a PyTorch implementation of the SimSiam paper: @Article{chen2020simsiam, author =
 834 Dec 30, 2022
834 Dec 30, 2022
A machine learning package for streaming data in Python. The other ancestor of River.
scikit-multiflow is a machine learning package for streaming data in Python. creme and scikit-multiflow are merging into a new project called River. W
 670 Dec 30, 2022
670 Dec 30, 2022
Toolbox of models, callbacks, and datasets for AI/ML researchers.
Pretrained SOTA Deep Learning models, callbacks and more for research and production with PyTorch Lightning and PyTorch Website • Installation • Main
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

Builds a LoRa radio frequency fingerprint identification (RFFI) system based on deep learning techiniques
This project builds a LoRa radio frequency fingerprint identification (RFFI) system based on deep learning techiniques.
 20 Dec 30, 2022
20 Dec 30, 2022

ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection
ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection This repository contains implementation of the
 190 Dec 30, 2022
190 Dec 30, 2022

pytorch implementation for PointNet
PointNet.pytorch This repo is implementation for PointNet in pytorch. The model is in pointnet/model.py. It is teste
 1.7k Dec 30, 2022
1.7k Dec 30, 2022

A PyTorch implementation of "Predict then Propagate: Graph Neural Networks meet Personalized PageRank" (ICLR 2019).
APPNP ⠀ A PyTorch implementation of Predict then Propagate: Graph Neural Networks meet Personalized PageRank (ICLR 2019). Abstract Neural message pass
 329 Dec 30, 2022
329 Dec 30, 2022

ICLR2021 (Under Review)
Self-Supervised Time Series Representation Learning by Inter-Intra Relational Reasoning This repository contains the official PyTorch implementation o
 58 Dec 30, 2022
58 Dec 30, 2022
This is the official implementation of TrivialAugment and a mini-library for the application of multiple image augmentation strategies including RandAugment and TrivialAugment.
Trivial Augment This is the official implementation of TrivialAugment (https://arxiv.org/abs/2103.10158), as was used for the paper. TrivialAugment is
 94 Dec 30, 2022
94 Dec 30, 2022
Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening
Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening Introduction This is an implementation of the model used for breast
 757 Dec 30, 2022
757 Dec 30, 2022
CS583: Deep Learning
CS583: Deep Learning
 2.6k Dec 30, 2022
2.6k Dec 30, 2022
The Multi-Mission Maximum Likelihood framework (3ML)
PyPi Conda The Multi-Mission Maximum Likelihood framework (3ML) A framework for multi-wavelength/multi-messenger analysis for astronomy/astrophysics.
 62 Dec 30, 2022
62 Dec 30, 2022

This is the code for the paper "Contrastive Clustering" (AAAI 2021)
Contrastive Clustering (CC) This is the code for the paper "Contrastive Clustering" (AAAI 2021) Dependency python=3.7 pytorch=1.6.0 torchvision=0.8
 210 Dec 30, 2022
210 Dec 30, 2022

Keyword spotting on Arm Cortex-M Microcontrollers
Keyword spotting for Microcontrollers This repository consists of the tensorflow models and training scripts used in the paper: Hello Edge: Keyword sp
 1k Dec 30, 2022
1k Dec 30, 2022

Official PyTorch implementation of the paper "Deep Constrained Least Squares for Blind Image Super-Resolution", CVPR 2022.
Deep Constrained Least Squares for Blind Image Super-Resolution [Paper] This is the official implementation of 'Deep Constrained Least Squares for Bli
141 Dec 30, 2022

A collection of SOTA Image Classification Models in PyTorch
A collection of SOTA Image Classification Models in PyTorch
 85 Dec 30, 2022
85 Dec 30, 2022
DiffQ performs differentiable quantization using pseudo quantization noise. It can automatically tune the number of bits used per weight or group of weights, in order to achieve a given trade-off between model size and accuracy.
Differentiable Model Compression via Pseudo Quantization Noise DiffQ performs differentiable quantization using pseudo quantization noise. It can auto
145 Dec 30, 2022
ROS support for Velodyne 3D LIDARs
Overview Velodyne1 is a collection of ROS2 packages supporting Velodyne high definition 3D LIDARs3. Warning: The master branch normally contains code
 543 Dec 30, 2022
543 Dec 30, 2022