Filter By
389 Repositories
Python Data Analysis
Udacity-api-reporting-pipeline - Udacity api reporting pipeline
udacity-api-reporting-pipeline In this exercise, you'll use portions of each of
 1 Feb 15, 2022
1 Feb 15, 2022
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
 2 Feb 14, 2022
2 Feb 14, 2022

Airflow ETL With EKS EFS Sagemaker
Airflow ETL With EKS EFS & Sagemaker (en desarrollo) Diagrama de la solución Imp
 1 Feb 14, 2022
1 Feb 14, 2022
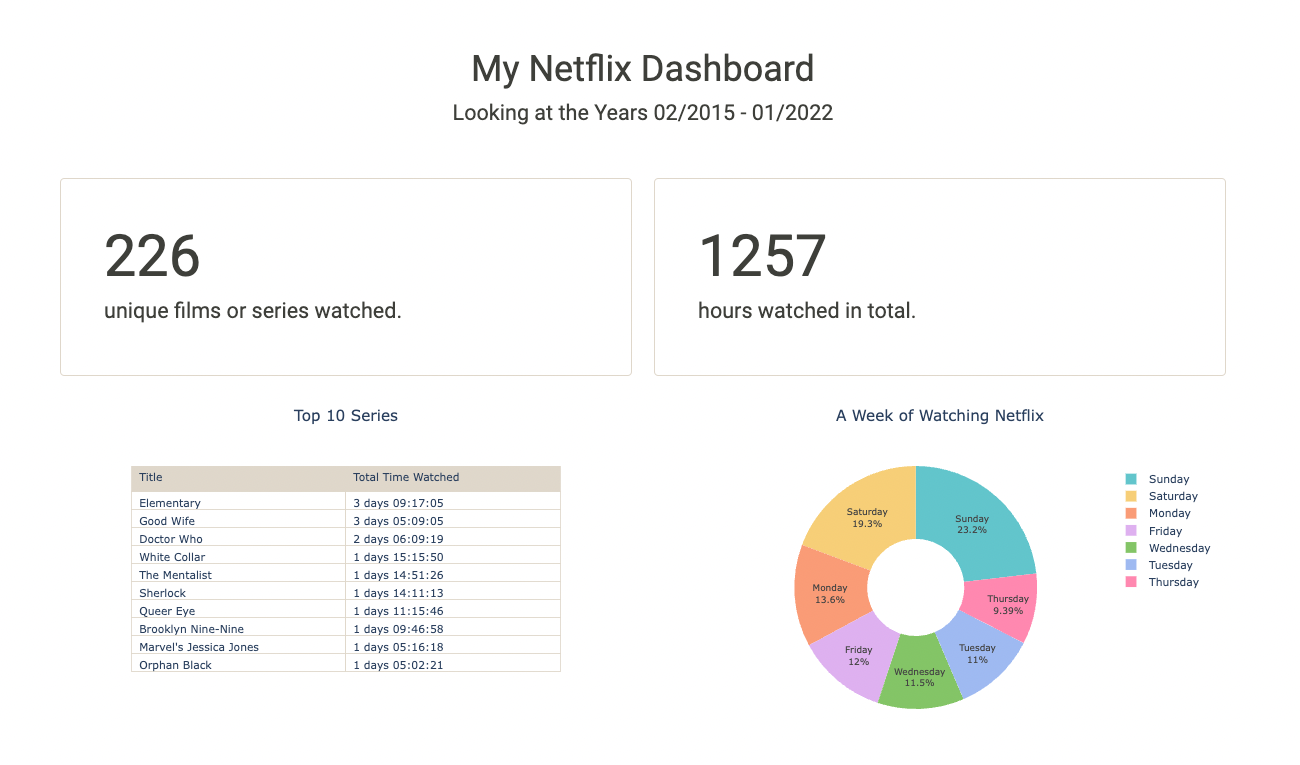
Project: Netflix Data Analysis and Visualization with Python
Project: Netflix Data Analysis and Visualization with Python Table of Contents General Info Installation Demo Usage and Main Functionalities Contribut
 2 Feb 13, 2022
2 Feb 13, 2022
OpenARB is an open source program aiming to emulate a free market while encouraging players to participate in arbitrage in order to increase working capital.
Overview OpenARB is an open source program aiming to emulate a free market while encouraging players to participate in arbitrage in order to increase
 3 Feb 12, 2022
3 Feb 12, 2022
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify.
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify. The ETL process flows from AWS's S3 into staging tables in AWS Redshift.
 1 Feb 11, 2022
1 Feb 11, 2022

Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
 1 Feb 11, 2022
1 Feb 11, 2022
Python Package for DataHerb: create, search, and load datasets.
The Python Package for DataHerb A DataHerb Core Service to Create and Load Datasets.
 4 Feb 11, 2022
4 Feb 11, 2022

Data Scientist in Simple Stock Analysis of PT Bukalapak.com Tbk for Long Term Investment
Data Scientist in Simple Stock Analysis of PT Bukalapak.com Tbk for Long Term Investment Brief explanation of PT Bukalapak.com Tbk Bukalapak was found
 2 Feb 10, 2022
2 Feb 10, 2022
.npy, .npz, .mtx converter.
npy-converter Matrix Data Converter. Expand matrix for multi-thread, multi-process Divid matrix for multi-thread, multi-process Support: .mtx, .npy, .
 1 Feb 7, 2022
1 Feb 7, 2022
Weather Image Recognition - Python weather application using series of data
Weather Image Recognition - Python weather application using series of data
 1 Feb 4, 2022
1 Feb 4, 2022
Project under the certification "Data Analysis with Python" on FreeCodeCamp
Sea Level Predictor Assignment You will anaylize a dataset of the global average sea level change since 1880. You will use the data to predict the sea
 3 Jan 31, 2022
3 Jan 31, 2022
InDels analysis of CRISPR lines by NGS amplicon sequencing technology for a multicopy gene family.
CRISPRanalysis InDels analysis of CRISPR lines by NGS amplicon sequencing technology for a multicopy gene family. In this work, we present a workflow
 2 Jan 31, 2022
2 Jan 31, 2022
Data-sets from the survey and analysis
bachelor-thesis "Umfragewerte.xlsx" contains the orginal survey results. "umfrage_alle.csv" contains the survey results but one participant is cancele
 1 Jan 26, 2022
1 Jan 26, 2022
simple way to build the declarative and destributed data pipelines with python
unipipeline simple way to build the declarative and distributed data pipelines. Why you should use it Declarative strict config Scaffolding Fully type
 0 Jan 26, 2022
0 Jan 26, 2022

Desafio proposto pela IGTI em seu bootcamp de Cloud Data Engineer
Desafio Modulo 4 - Cloud Data Engineer Bootcamp - IGTI Objetivos Criar infraestrutura como código Utuilizando um cluster Kubernetes na Azure Ingestão
 4 Jan 23, 2022
4 Jan 23, 2022
Ejercicios Panda usando Pandas
Readme Below we add configuration details to locally test your application To co
 1 Jan 22, 2022
1 Jan 22, 2022

Full ELT process on GCP environment.
Rent Houses Germany - GCP Pipeline Project: The goal of the project is to extract data about house rentals in Germany, store, process and analyze it u
 2 Jan 20, 2022
2 Jan 20, 2022

Stream-Kafka-ELK-Stack - Weather data streaming using Apache Kafka and Elastic Stack.
Streaming Data Pipeline - Kafka + ELK Stack Streaming weather data using Apache Kafka and Elastic Stack. Data source: https://openweathermap.org/api O
2 Jan 20, 2022
Import, connect and transform data into Excel
xlwings_query Import, connect and transform data into Excel. Description The concept is to apply data transformations to a main query object. When the
 1 Jan 19, 2022
1 Jan 19, 2022

PrimaryBid - Transform application Lifecycle Data and Design and ETL pipeline architecture for ingesting data from multiple sources to redshift
Transform application Lifecycle Data and Design and ETL pipeline architecture for ingesting data from multiple sources to redshift This project is composed of two parts: Part1 and Part2
 1 Jan 19, 2022
1 Jan 19, 2022
Python data processing, analysis, visualization, and data operations
Python This is a Python data processing, analysis, visualization and data operations of the source code warehouse, book ISBN: 9787115527592 Descriptio
 1 Jan 16, 2022
1 Jan 16, 2022
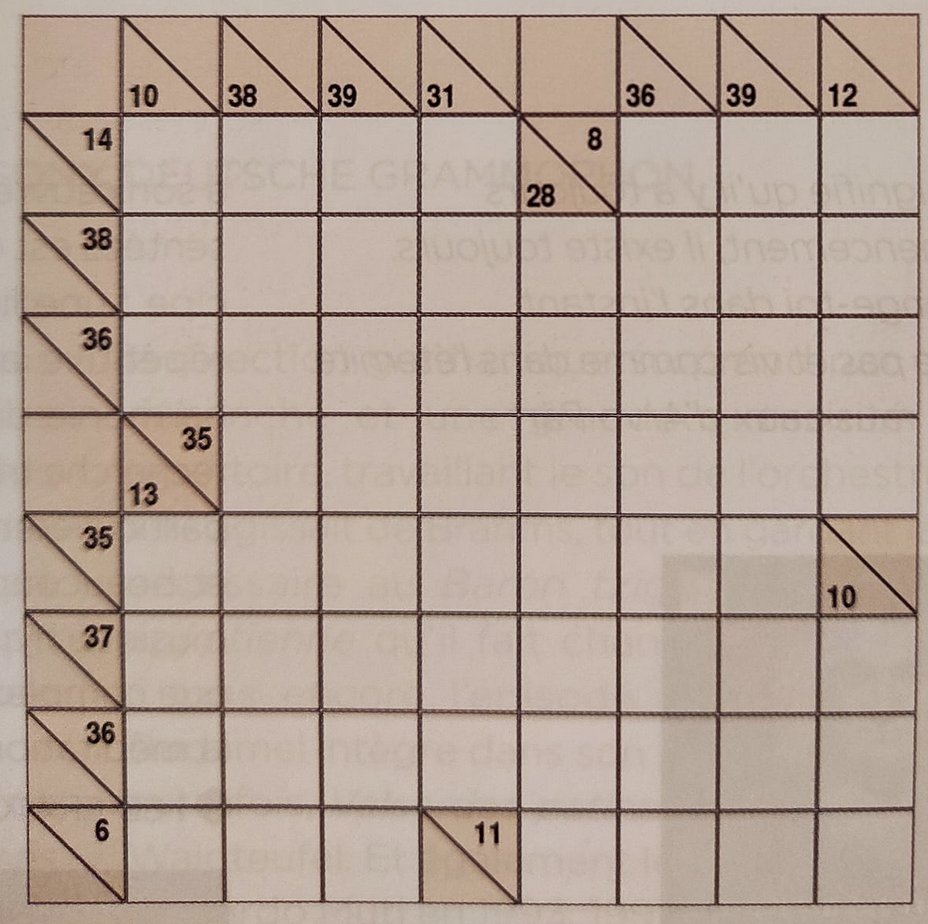
Very basic but functional Kakuro solver written in Python.
kakuro.py Very basic but functional Kakuro solver written in Python. It uses a reduction to exact set cover and Ali Assaf's elegant implementation of
 4 Jan 15, 2022
4 Jan 15, 2022
Shot notebooks resuming the main functions of GeoPandas
Shot notebooks resuming the main functions of GeoPandas, 2 notebooks written as Exercises to apply these functions.
 1 Jan 12, 2022
1 Jan 12, 2022
Python scripts aim to use a Random Forest machine learning algorithm to predict the water affinity of Metal-Organic Frameworks
The following Python scripts aim to use a Random Forest machine learning algorithm to predict the water affinity of Metal-Organic Frameworks (MOFs). The training set is extracted from the Cambridge Structural Database and the CoRE_MOF 2019 dataset.
 1 Jan 9, 2022
1 Jan 9, 2022
INF42 - Topological Data Analysis
TDA INF421(Conception et analyse d'algorithmes) Projet : Topological Data Analysis SphereMin Etant donné un nuage des points, ce programme contient de
 2 Jan 7, 2022
2 Jan 7, 2022

Average time per match by division
HW_02 Unzip matches.rar to access .json files for matches. Get an API key to access their data at: https://developer.riotgames.com/ Average time per m
 11 Jan 7, 2022
11 Jan 7, 2022
CSV database for chihuahua (HUAHUA) blockchain transactions
super-fiesta Shamelessly ripped components from https://github.com/hodgerpodger/staketaxcsv - Thanks for doing all the hard work. This code does only
 1 Jan 7, 2022
1 Jan 7, 2022
An ETL framework + Monitoring UI/API (experimental project for learning purposes)
Fastlane An ETL framework for building pipelines, and Flask based web API/UI for monitoring pipelines. Project structure fastlane |- fastlane: (ETL fr
 2 Jan 6, 2022
2 Jan 6, 2022

BigDL - Evaluate the performance of BigDL (Distributed Deep Learning on Apache Spark) in big data analysis problems
Evaluate the performance of BigDL (Distributed Deep Learning on Apache Spark) in big data analysis problems.
 1 Jan 6, 2022
1 Jan 6, 2022
Analyse the limit order book in seconds. Zoom to tick level or get yourself an overview of the trading day.
Analyse the limit order book in seconds. Zoom to tick level or get yourself an overview of the trading day. Correlate the market activity with the Apple Keynote presentations.
 2 Jan 4, 2022
2 Jan 4, 2022
Py-price-monitoring - A Python price monitor
A Python price monitor This project was focused on Brazil, so the monitoring is
 1 Jan 4, 2022
1 Jan 4, 2022
Common bioinformatics database construction
biodb Common bioinformatics database construction 1.taxonomy (Substance classification database) Download the database wget -c https://ftp.ncbi.nlm.ni
 2 Jan 4, 2022
2 Jan 4, 2022
A project consists in a set of assignements corresponding to a BI process: data integration, construction of an OLAP cube, qurying of a OPLAP cube and reporting.
TennisBusinessIntelligenceProject - A project consists in a set of assignements corresponding to a BI process: data integration, construction of an OLAP cube, qurying of a OPLAP cube and reporting.
 1 Jan 2, 2022
1 Jan 2, 2022

2019 Data Science Bowl
Kaggle-2019-Data-Science-Bowl-Solution - Here i present my solution to kaggle 2019 data science bowl and how i improved it to win a silver medal in that competition.
 1 Jan 1, 2022
1 Jan 1, 2022

This mini project showcase how to build and debug Apache Spark application using Python
Spark app can't be debugged using normal procedure. This mini project showcase how to build and debug Apache Spark application using Python programming language. There are also options to run Spark application on Spark container
 1 Dec 29, 2021
1 Dec 29, 2021
This program analyzes a DNA sequence and outputs snippets of DNA that are likely to be protein-coding genes.
This program analyzes a DNA sequence and outputs snippets of DNA that are likely to be protein-coding genes.
 1 Dec 28, 2021
1 Dec 28, 2021
For making Tagtog annotation into csv dataset
tagtog_relation_extraction for making Tagtog annotation into csv dataset How to Use On Tagtog 1. Go to Project Downloads 2. Download all documents,
 4 Dec 28, 2021
4 Dec 28, 2021
Utilize data analytics skills to solve real-world business problems using Humana’s big data
Humana-Mays-2021-HealthCare-Analytics-Case-Competition- The goal of the project is to utilize data analytics skills to solve real-world business probl
 1 Dec 27, 2021
1 Dec 27, 2021
Mortgage-loan-prediction - Show how to perform advanced Analytics and Machine Learning in Python using a full complement of PyData utilities
Mortgage-loan-prediction - Show how to perform advanced Analytics and Machine Learning in Python using a full complement of PyData utilities. This is aimed at those looking to get into the field of Data Science or those who are already in the field and looking to solve a real-world project with python.
 1 Dec 26, 2021
1 Dec 26, 2021
Titanic data analysis for python
Titanic-data-analysis This Repo is an analysis on Titanic_mod.csv This csv file contains some assumed data of the Titanic ship after sinking This full
 1 Dec 26, 2021
1 Dec 26, 2021

Cleaning and analysing aggregated UK political polling data.
Analysing aggregated UK polling data The tweet collection & storage pipeline used in email-service is used to also collect tweets from @britainelects.
 0 Dec 22, 2021
0 Dec 22, 2021
A model checker for verifying properties in epistemic models
Epistemic Model Checker This is a model checker for verifying properties in epistemic models. The goal of the model checker is to check for Pluralisti
 2 Dec 22, 2021
2 Dec 22, 2021

Uses MIT/MEDSL, New York Times, and US Census datasources to analyze per-county COVID-19 deaths.
Covid County Executive summary Setup Install miniconda, then in the command line, run conda create -n covid-county conda activate covid-county conda i
 1 Dec 22, 2021
1 Dec 22, 2021
Important dataframe statistics with a single command
quick_eda Receiving dataframe statistics with one command Project description A python package for Data Scientists, Students, ML Engineers and anyone
 2 Dec 19, 2021
2 Dec 19, 2021
A Streamlit web-app for a data-science project that aims to evaluate if the answer to a question is helpful.
How useful is the aswer? A Streamlit web-app for a data-science project that aims to evaluate if the answer to a question is helpful. If you want to l
 1 Dec 17, 2021
1 Dec 17, 2021

A program that uses an API and a AI model to get info of sotcks
Stock-Market-AI-Analysis I dont mind anyone using this code but please give me credit A program that uses an API and a AI model to get info of stocks
 1 Dec 17, 2021
1 Dec 17, 2021
Snakemake workflow for converting FASTQ files to self-contained CRAM files with maximum lossless compression.
Snakemake workflow: name A Snakemake workflow for description Usage The usage of this workflow is described in the Snakemake Workflow Catalog. If
 1 Dec 16, 2021
1 Dec 16, 2021
Pyspark project that able to do joins on the spark data frames.
SPARK JOINS This project is to perform inner, all outer joins and semi joins. create_df.py: load_data.py : helps to put data into Spark data frames. d
 1 Dec 14, 2021
1 Dec 14, 2021
A Big Data ETL project in PySpark on the historical NYC Taxi Rides data
Processing NYC Taxi Data using PySpark ETL pipeline Description This is an project to extract, transform, and load large amount of data from NYC Taxi
 2 Dec 12, 2021
2 Dec 12, 2021

My first Python project is a simple Mad Libs program.
Python CLI Mad Libs Game My first Python project is a simple Mad Libs program. Mad Libs is a phrasal template word game created by Leonard Stern and R
 1 Dec 10, 2021
1 Dec 10, 2021
The Spark Challenge Student Check-In/Out Tracking Script
The Spark Challenge Student Check-In/Out Tracking Script This Python Script uses the Student ID Database to match the entries with the ID Card Swipe a
 1 Dec 9, 2021
1 Dec 9, 2021

MS in Data Science capstone project. Studying attacks on autonomous vehicles.
Surveying Attack Models for CAVs Guide to Installing CARLA and Collecting Data Our project focuses on surveying attack models for Connveced Autonomous
 1 Dec 9, 2021
1 Dec 9, 2021
Developed for analyzing the covariance for OrcVIO
about This repo is developed for analyzing the covariance for OrcVIO environment setup platform ubuntu 18.04 using conda conda env create --file envir
 1 Dec 8, 2021
1 Dec 8, 2021