771 Repositories
Python COVID-19-Deaths-Dataset Libraries
The Malware Open-source Threat Intelligence Family dataset contains 3,095 disarmed PE malware samples from 454 families
MOTIF Dataset The Malware Open-source Threat Intelligence Family (MOTIF) dataset contains 3,095 disarmed PE malware samples from 454 families, labeled
 112 Dec 13, 2022
112 Dec 13, 2022

Artstation-Artistic-face-HQ Dataset (AAHQ)
Artstation-Artistic-face-HQ Dataset (AAHQ) Artstation-Artistic-face-HQ (AAHQ) is a high-quality image dataset of artistic-face images. It is proposed
 105 Dec 16, 2022
105 Dec 16, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022

Cooperative Driving Dataset: a dataset for multi-agent driving scenarios
Cooperative Driving Dataset (CODD) The Cooperative Driving dataset is a synthetic dataset generated using CARLA that contains lidar data from multiple
 124 Dec 28, 2022
124 Dec 28, 2022

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023

Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
 8 Oct 6, 2022
8 Oct 6, 2022
A set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI.
Overview This is a set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI. Make TFRecords To run t
 8 Nov 1, 2022
8 Nov 1, 2022
The official homepage of the COCO-Stuff dataset.
The COCO-Stuff dataset Holger Caesar, Jasper Uijlings, Vittorio Ferrari Welcome to official homepage of the COCO-Stuff [1] dataset. COCO-Stuff augment
 715 Dec 31, 2022
715 Dec 31, 2022
Python script to download the celebA-HQ dataset from google drive
download-celebA-HQ Python script to download and create the celebA-HQ dataset. WARNING from the author. I believe this script is broken since a few mo
 133 Dec 21, 2022
133 Dec 21, 2022
[3DV 2021] A Dataset-Dispersion Perspective on Reconstruction Versus Recognition in Single-View 3D Reconstruction Networks
dispersion-score Official implementation of 3DV 2021 Paper A Dataset-dispersion Perspective on Reconstruction versus Recognition in Single-view 3D Rec
 7 May 28, 2022
7 May 28, 2022

Dataset for the Research2Clinics @ NeurIPS 2021 Paper: What Do You See in this Patient? Behavioral Testing of Clinical NLP Models
Behavioral Testing of Clinical NLP Models This repository contains code for testing the behavior of clinical prediction models based on patient letter
 2 Sep 20, 2022
2 Sep 20, 2022
Dataset and codebase for NeurIPS 2021 paper: Exploring Forensic Dental Identification with Deep Learning
Repository under construction. Example dataset, checkpoints, and training/testing scripts will be avaible soon! 💡 Collated best practices from most p
 4 Jun 26, 2022
4 Jun 26, 2022
Info and sample codes for "NTU RGB+D Action Recognition Dataset"
"NTU RGB+D" Action Recognition Dataset "NTU RGB+D 120" Action Recognition Dataset "NTU RGB+D" is a large-scale dataset for human action recognition. I
 578 Dec 30, 2022
578 Dec 30, 2022

DALLE-tools provided useful dataset utilities to improve you workflow with WebDatasets.
DALLE tools DALLE-tools is a github repository with useful tools to categorize, annotate or check the sanity of your datasets. Installation Just clone
 11 Dec 25, 2022
11 Dec 25, 2022
CCPD: a diverse and well-annotated dataset for license plate detection and recognition
CCPD (Chinese City Parking Dataset, ECCV) UPdate on 10/03/2019. CCPD Dataset is now updated. We are confident that images in subsets of CCPD is much m
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
Cluttered MNIST Dataset
Cluttered MNIST Dataset A setup script will download MNIST and produce mnist/*.t7 files: luajit download_mnist.lua Example usage: local mnist_clutter
 50 Jul 12, 2022
50 Jul 12, 2022
A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset
xwrf A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset. The primary objective of
 43 Nov 29, 2022
43 Nov 29, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022
Long Expressive Memory (LEM)
Long Expressive Memory for Sequence Modeling This repository contains the implementation to reproduce the numerical experiments of the paper Long Expr
 47 Dec 17, 2022
47 Dec 17, 2022

Project to deploy a machine learning model based on Titanic dataset from Kaggle
kaggle_titanic_deploy Project to deploy a machine learning model based on Titanic dataset from Kaggle In this project we used the Titanic dataset from
 8 May 23, 2022
8 May 23, 2022
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset This repository contains links to data and code to fetch and reproduce
 19 Dec 16, 2022
19 Dec 16, 2022
Minimal API for the COVID Booking System of the Offices at the UniPD Math Dep
Simple and easy to use python BOT for the COVID registration booking system of the math department @ unipd (torre archimede). This API creates an interface with the official website, with more useful functionalities.
 4 Dec 24, 2021
4 Dec 24, 2021
An analysis of the efficiency of the COVID-19 vaccine
VaccineEfficiency 💉 An analysis of the efficiency of the COVID-19 vaccine 3 Methods 1️⃣ Compare country's vaccination data to number of day- to-day c
 1 Dec 10, 2021
1 Dec 10, 2021
COIN the currently largest dataset for comprehensive instruction video analysis.
COIN Dataset COIN is the currently largest dataset for comprehensive instruction video analysis. It contains 11,827 videos of 180 different tasks (i.e
 86 Dec 28, 2022
86 Dec 28, 2022
Dataset and Source code of paper 'Enhancing Keyphrase Extraction from Academic Articles with their Reference Information'.
Enhancing Keyphrase Extraction from Academic Articles with their Reference Information Overview Dataset and code for paper "Enhancing Keyphrase Extrac
 15 Nov 24, 2022
15 Nov 24, 2022

A benchmark dataset for emulating atmospheric radiative transfer in weather and climate models with machine learning (NeurIPS 2021 Datasets and Benchmarks Track)
ClimART - A Benchmark Dataset for Emulating Atmospheric Radiative Transfer in Weather and Climate Models Official PyTorch Implementation Using deep le
 21 Dec 31, 2022
21 Dec 31, 2022
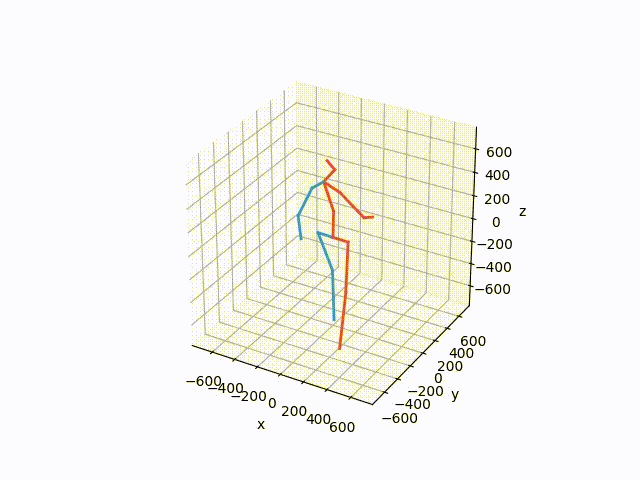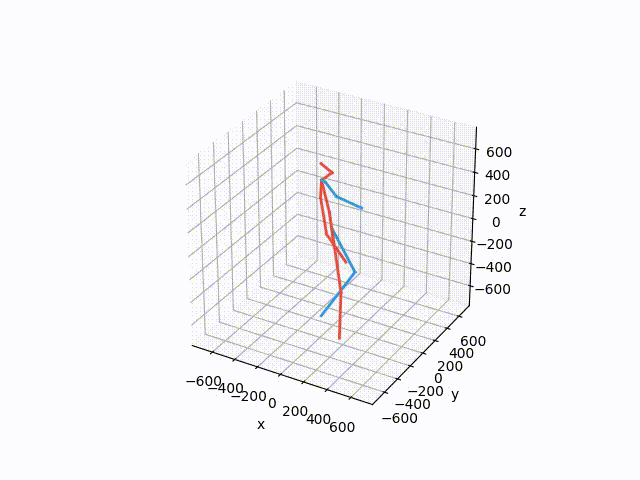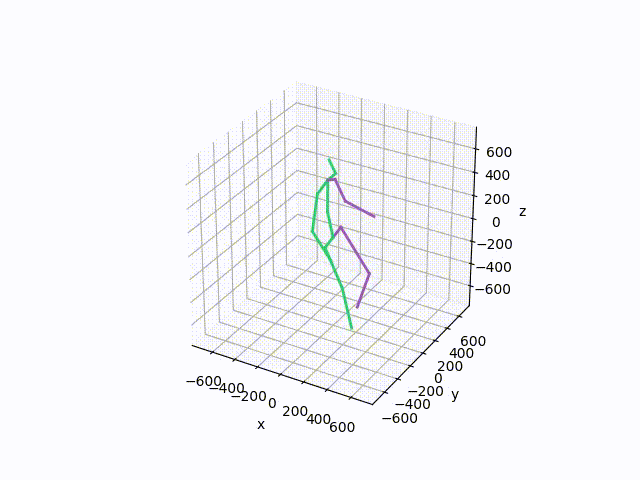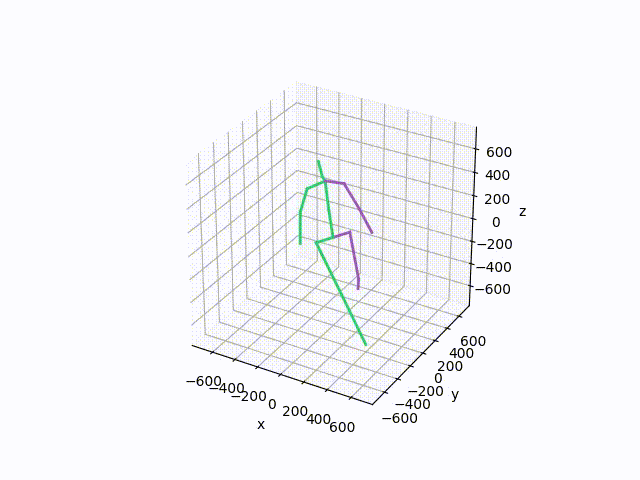
Plot and save the ground truth and predicted results of human 3.6 M and CMU mocap dataset.
Visualization-of-Human3.6M-Dataset Plot and save the ground truth and predicted results of human 3.6 M and CMU mocap dataset. human-motion-prediction
 5 Nov 18, 2022
5 Nov 18, 2022
A benchmark dataset for mesh multi-label-classification based on cube engravings introduced in MeshCNN
Double Cube Engravings This script creates a dataset for multi-label mesh clasification, with an intentionally difficult setup for point cloud classif
 1 Nov 30, 2021
1 Nov 30, 2021
A fast, dataset-agnostic, deep visual search engine for digital art history
imgs.ai imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings. It utilizes modern
 5 Dec 14, 2022
5 Dec 14, 2022
Predicting diabetes over a five year period using logistic regression and the Pima First-Nation dataset
Diabetes This script uses the Pima First Nations dataset to create a model to predict whether or not an individual will develop Diabetes Mellitus Type
 1 Mar 28, 2022
1 Mar 28, 2022
Train an imgs.ai model on your own dataset
imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings.
5 Dec 21, 2021

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

This repository contains the source code of our work on designing efficient CNNs for computer vision
Efficient networks for Computer Vision This repo contains source code of our work on designing efficient networks for different computer vision tasks:
 386 Nov 26, 2022
386 Nov 26, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
An open-source Kazakh named entity recognition dataset (KazNERD), annotation guidelines, and baseline NER models.
Kazakh Named Entity Recognition This repository contains an open-source Kazakh named entity recognition dataset (KazNERD), named entity annotation gui
 9 Dec 23, 2022
9 Dec 23, 2022
Python NZ COVID Pass Verifier/Generator
Python NZ COVID Pass Verifier/Generator This is quick proof of concept verifier I coded up in a few hours using various libraries to parse and generat
 12 Jan 3, 2023
12 Jan 3, 2023
Scraping script for stats on covid19 pandemic status in Chiba prefecture, Japan
About 千葉県の地域別の詳細感染者統計(Excelファイル) をCSVに変換し、かつ地域別の日時感染者集計値を出力するスクリプトです。 Requirement POSIX互換なシェル, e.g. GNU Bash (1) curl (1) python = 3.8 pandas = 1.1.
 1 Nov 29, 2021
1 Nov 29, 2021
LSUN Dataset Documentation and Demo Code
LSUN Please check LSUN webpage for more information about the dataset. Data Release All the images in one category are stored in one lmdb database fil
 426 Jan 2, 2023
426 Jan 2, 2023
A new test set for ImageNet
ImageNetV2 The ImageNetV2 dataset contains new test data for the ImageNet benchmark. This repository provides associated code for assembling and worki
 186 Dec 18, 2022
186 Dec 18, 2022
Qlib is an AI-oriented quantitative investment platform
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment.
 10.1k Dec 30, 2022
10.1k Dec 30, 2022

We are building an open database of COVID-19 cases with chest X-ray or CT images.
🛑 Note: please do not claim diagnostic performance of a model without a clinical study! This is not a kaggle competition dataset. Please read this pa
 2.9k Dec 30, 2022
2.9k Dec 30, 2022
COVID-19 Chatbot with Rasa 2.0: open source conversational AI
COVID-19 chatbot implementation with Rasa open source 2.0, conversational AI framework.
 1 Dec 23, 2022
1 Dec 23, 2022
Simple and easy to use python API for the COVID registration booking system of the math department @ unipd (torre archimede)
Simple and easy to use python API for the COVID registration booking system of the math department @ unipd (torre archimede). This API creates an interface with the official browser, with more useful functionalities.
4 Dec 24, 2021
Python code for loading the Aschaffenburg Pose Dataset.
Aschaffenburg Pose Dataset (APD) This repository contains Python code for loading and filtering the Aschaffenburg Pose Dataset. The dataset itself and
 1 Nov 26, 2021
1 Nov 26, 2021

Unofficial PyTorch implementation of "RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving" (ECCV 2020)
RTM3D-PyTorch The PyTorch Implementation of the paper: RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving (ECCV 2020
 271 Nov 29, 2022
271 Nov 29, 2022

Benchmarks for the Optimal Power Flow Problem
Power Grid Lib - Optimal Power Flow This benchmark library is curated and maintained by the IEEE PES Task Force on Benchmarks for Validation of Emergi
 207 Dec 8, 2022
207 Dec 8, 2022
The devkit of the nuScenes dataset.
nuScenes devkit Welcome to the devkit of the nuScenes and nuImages datasets. Overview Changelog Devkit setup nuImages nuImages setup Getting started w
 1.6k Jan 5, 2023
1.6k Jan 5, 2023

A large-scale face dataset for face parsing, recognition, generation and editing.
CelebAMask-HQ [Paper] [Demo] CelebAMask-HQ is a large-scale face image dataset that has 30,000 high-resolution face images selected from the CelebA da
 1.7k Dec 26, 2022
1.7k Dec 26, 2022
Python script for diving image data to train test and val
dataset-division-to-train-val-test-python python script for dividing image data to train test and val If you have an image dataset in the following st
 1 Nov 14, 2022
1 Nov 14, 2022
An open source algorithm and dataset for finding poop in pictures.
The shitspotter module is where I will be work on the "shitspotter" poop-detection algorithm and dataset. The primary goal of this work is to allow for the creation of a phone app that finds where your dog pooped, because you ran to grab the doggy-bags you forgot, and now you can't find the damn thing.
 29 Nov 29, 2022
29 Nov 29, 2022
A colab notebook for training Stylegan2-ada on colab, transfer learning onto your own dataset.
Stylegan2-Ada-Google-Colab-Starter-Notebook A no thrills colab notebook for training Stylegan2-ada on colab. transfer learning onto your own dataset h
 66 Dec 16, 2022
66 Dec 16, 2022
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
An Agnostic Object Detection Framework IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-q
 790 Jan 5, 2023
790 Jan 5, 2023
Command-line tool for downloading and extending the RedCaps dataset.
RedCaps Downloader This repository provides the official command-line tool for downloading and extending the RedCaps dataset. Users can seamlessly dow
 33 Dec 14, 2022
33 Dec 14, 2022
Official Implementation of "Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras"
Multi Camera Pig Tracking Official Implementation of Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras CVPR2021 CV4Animals Workshop P
 44 Jan 6, 2023
44 Jan 6, 2023

Curating a dataset for bioimage transfer learning
CytoImageNet A large-scale pretraining dataset for bioimage transfer learning. Motivation In past few decades, the increase in speed of data collectio
 9 Jun 20, 2022
9 Jun 20, 2022
COVID-19 case tracker in Dash
covid_dashy_personal This is a personal project to build a simple COVID-19 tracker for Australia with Dash. Key functions of this dashy will be to Dis
 1 Nov 30, 2021
1 Nov 30, 2021
The source code and dataset for the RecGURU paper (WSDM 2022)
RecGURU About The Project Source code and baselines for the RecGURU paper "RecGURU: Adversarial Learning of Generalized User Representations for Cross
 17 Jan 7, 2023
17 Jan 7, 2023

A tutorial on training a DarkNet YOLOv4 model for the CrowdHuman dataset
YOLOv4 CrowdHuman Tutorial This is a tutorial demonstrating how to train a YOLOv4 people detector using Darknet and the CrowdHuman dataset. Table of c
 118 Nov 10, 2022
118 Nov 10, 2022
Lacmus is a cross-platform application that helps to find people who are lost in the forest using computer vision and neural networks.
lacmus The program for searching through photos from the air of lost people in the forest using Retina Net neural nwtwork. The project is being develo
 168 Dec 27, 2022
168 Dec 27, 2022
Txt2Xml tool will help you convert from txt COCO format to VOC xml format in Object Detection Problem.
TXT 2 XML All codes assume running from root directory. Please update the sys path at the beginning of the codes before running. Over View Txt2Xml too
 4 Nov 24, 2022
4 Nov 24, 2022
Source code and notebooks to reproduce experiments and benchmarks on Bias Faces in the Wild (BFW).
Face Recognition: Too Bias, or Not Too Bias? Robinson, Joseph P., Gennady Livitz, Yann Henon, Can Qin, Yun Fu, and Samson Timoner. "Face recognition:
 41 Dec 12, 2022
41 Dec 12, 2022

Predicting the usefulness of reviews given the review text and metadata surrounding the reviews.
Predicting Yelp Review Quality Table of Contents Introduction Motivation Goal and Central Questions The Data Data Storage and ETL EDA Data Pipeline Da
 3 Nov 27, 2022
3 Nov 27, 2022
AI-powered literature discovery and review engine for medical/scientific papers
AI-powered literature discovery and review engine for medical/scientific papers paperai is an AI-powered literature discovery and review engine for me
 819 Dec 30, 2022
819 Dec 30, 2022

This repository will help you get label for images in Stanford Cars Dataset.
STANFORD CARS DATASET stanford-cars "The Cars dataset contains 16,185 images of 196 classes of cars. The data is split into 8,144 training images and
3 Sep 20, 2022
Json2Xml tool will help you convert from json COCO format to VOC xml format in Object Detection Problem.
JSON 2 XML All codes assume running from root directory. Please update the sys path at the beginning of the codes before running. Over View Json2Xml t
6 Aug 22, 2022

This project uses unsupervised machine learning to identify correlations between daily inoculation rates in the USA and twitter sentiment in regards to COVID-19.
Twitter COVID-19 Sentiment Analysis Members: Christopher Bach | Khalid Hamid Fallous | Jay Hirpara | Jing Tang | Graham Thomas | David Wetherhold Pro
 4 Oct 15, 2022
4 Oct 15, 2022

iAWE is a wonderful dataset for those of us who work on Non-Intrusive Load Monitoring (NILM) algorithms.
iAWE is a wonderful dataset for those of us who work on Non-Intrusive Load Monitoring (NILM) algorithms. You can find its main page and description via this link. If you are familiar with NILM-TK API, you probably know that you can work with iAWE hdf5 data file in NILM-TK.
 3 Mar 19, 2022
3 Mar 19, 2022

Neurons Dataset API - The official dataloader and visualization tools for Neurons Datasets.
Neurons Dataset API - The official dataloader and visualization tools for Neurons Datasets. Introduction We propose our dataloader API for loading and
 1 Nov 19, 2021
1 Nov 19, 2021

VGGFace2-HQ - A high resolution face dataset for face editing purpose
The first open source high resolution dataset for face swapping!!! A high resolution version of VGGFace2 for academic face editing purpose
 232 Dec 29, 2022
232 Dec 29, 2022
![[Nature Machine Intelligence' 21]](https://github.com/HUST-EIC-AI-LAB/UCADI/raw/master/pic/flow_chart.jpg)
[Nature Machine Intelligence' 21] "Advancing COVID-19 Diagnosis with Privacy-Preserving Collaboration in Artificial Intelligence"
[UCADI] COVID-19 Diagnosis With Federated Learning Intro We developed a Federated Learning (FL) Framework for global researchers to collaboratively tr
 30 Dec 12, 2022
30 Dec 12, 2022

SHIFT15M: multiobjective large-scale fashion dataset with distributional shifts
[arXiv] The main motivation of the SHIFT15M project is to provide a dataset that contains natural dataset shifts collected from a web service IQON, wh
 138 Nov 24, 2022
138 Nov 24, 2022
Reproduction process of BERT on SST2 dataset
BERT-SST2-Prod Reproduction process of BERT on SST2 dataset 安装说明 下载代码库 git clone https://github.com/JunnYu/BERT-SST2-Prod 进入文件夹,安装requirements pip ins
 1 Nov 18, 2021
1 Nov 18, 2021
PyTorch Kafka Dataset: A definition of a dataset to get training data from Kafka.
PyTorch Kafka Dataset: A definition of a dataset to get training data from Kafka.
 7 Aug 1, 2022
7 Aug 1, 2022

GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data
GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data By Shuchang Zhou, Taihong Xiao, Yi Yang, Dieqiao Feng, Qinyao He, W
 141 Apr 16, 2021
141 Apr 16, 2021

A DCGAN to generate anime faces using custom mined dataset
Anime-Face-GAN-Keras A DCGAN to generate anime faces using custom dataset in Keras. Dataset The dataset is created by crawling anime database websites
 190 Jan 3, 2023
190 Jan 3, 2023

Extract rooms type, door, neibour rooms, rooms corners nad bounding boxes, and generate graph from rplan dataset
Housegan-data-reader House-GAN++ (data-reader) Code and instructions for converting rplan dataset (raster images) to housegan++ data format. House-GAN
 13 Nov 24, 2022
13 Nov 24, 2022

Powerful and efficient Computer Vision Annotation Tool (CVAT)
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 1, 2023
8.6k Jan 1, 2023
For making Tagtog annotation into csv dataset
tagtog_relation_extraction for making Tagtog annotation into csv dataset How to Use On Tagtog 1. Go to Project Downloads 2. Download all documents,
 4 Dec 28, 2021
4 Dec 28, 2021
Simple Baselines for Human Pose Estimation and Tracking
Simple Baselines for Human Pose Estimation and Tracking News Our new work High-Resolution Representations for Labeling Pixels and Regions is available
2.7k Jan 5, 2023

 1.2k Dec 26, 2022
1.2k Dec 26, 2022
implementation of the KNN algorithm on crab biometrics dataset for CS16
crab-knn implementation of the KNN algorithm in Python applied to biometrics data of purple rock crabs (leptograpsus variegatus) to classify the sex o
 1 Nov 18, 2021
1 Nov 18, 2021
CCQA A New Web-Scale Question Answering Dataset for Model Pre-Training
CCQA: A New Web-Scale Question Answering Dataset for Model Pre-Training This is the official repository for the code and models of the paper CCQA: A N
 29 Nov 30, 2022
29 Nov 30, 2022
Simulation of early COVID-19 using SIR model and variants (SEIR ...).
COVID-19-simulation Simulation of early COVID-19 using SIR model and variants (SEIR ...). Made by the Laboratory of Sustainable Life Assessment (GYRO)
 1 Nov 17, 2021
1 Nov 17, 2021

This repository contains the needed resources to build the HIRID-ICU-Benchmark dataset
HiRID-ICU-Benchmark This repository contains the needed resources to build the HIRID-ICU-Benchmark dataset for which the manuscript can be found here.
 30 Dec 16, 2022
30 Dec 16, 2022
GiantMIDI-Piano is a classical piano MIDI dataset contains 10,854 MIDI files of 2,786 composers
GiantMIDI-Piano is a classical piano MIDI dataset contains 10,854 MIDI files of 2,786 composers
 1.3k Jan 4, 2023
1.3k Jan 4, 2023

Using modified BiSeNet for face parsing in PyTorch
face-parsing.PyTorch Contents Training Demo References Training Prepare training data: -- download CelebAMask-HQ dataset -- change file path in the pr
 1.6k Jan 8, 2023
1.6k Jan 8, 2023
TensorFlow implementation of ENet, trained on the Cityscapes dataset.
segmentation TensorFlow implementation of ENet (https://arxiv.org/pdf/1606.02147.pdf) based on the official Torch implementation (https://github.com/e
 248 Dec 16, 2022
248 Dec 16, 2022

Semantic segmentation task for ADE20k & cityscapse dataset, based on several models.
semantic-segmentation-tensorflow This is a Tensorflow implementation of semantic segmentation models on MIT ADE20K scene parsing dataset and Cityscape
 83 Oct 13, 2022
83 Oct 13, 2022
Using fully convolutional networks for semantic segmentation with caffe for the cityscapes dataset
Using fully convolutional networks for semantic segmentation (Shelhamer et al.) with caffe for the cityscapes dataset How to get started Download the
 27 Jun 6, 2022
27 Jun 6, 2022
PyTorch Implementations for DeeplabV3 and PSPNet
Pytorch-segmentation-toolbox DOC Pytorch code for semantic segmentation. This is a minimal code to run PSPnet and Deeplabv3 on Cityscape dataset. Shor
 746 Dec 15, 2022
746 Dec 15, 2022

This is an (re-)implementation of DeepLab-ResNet in TensorFlow for semantic image segmentation on the PASCAL VOC dataset.
DeepLab-ResNet-TensorFlow This is an (re-)implementation of DeepLab-ResNet in TensorFlow for semantic image segmentation on the PASCAL VOC dataset. Up
 19 Jan 16, 2022
19 Jan 16, 2022
UNet model with VGG11 encoder pre-trained on Kaggle Carvana dataset
TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation By Vladimir Iglovikov and Alexey Shvets Introduction TernausNet is
 1k Dec 28, 2022
1k Dec 28, 2022
Identifies the faulty wafer before it can be used for the fabrication of integrated circuits and, in photovoltaics, to manufacture solar cells.
Identifies the faulty wafer before it can be used for the fabrication of integrated circuits and, in photovoltaics, to manufacture solar cells. The project retrains itself after every prediction, making it more robust and generalized over time.
 2 Jul 1, 2022
2 Jul 1, 2022
Recommendation System to recommend top books from the dataset
recommendersystem Recommendation System to recommend top books from the dataset Introduction The recom.py is the main program code. The dataset is als
 1 Nov 15, 2021
1 Nov 15, 2021
Python dataset creator to construct datasets composed of OpenFace extracted features and Shimmer3 GSR+ Sensor datas
Python dataset creator to construct datasets composed of OpenFace extracted features and Shimmer3 GSR+ Sensor datas
 3 Jul 5, 2022
3 Jul 5, 2022
FS-Mol: A Few-Shot Learning Dataset of Molecules
FS-Mol is A Few-Shot Learning Dataset of Molecules, containing molecular compounds with measurements of activity against a variety of protein targets. The dataset is presented with a model evaluation benchmark which aims to drive few-shot learning research in the domain of molecules and graph-structured data.
114 Dec 15, 2022

Automate UCheck COVID-19 self-assessment form submission
ucheck Automate UCheck COVID-19 self-assessment form submission. Disclaimer ucheck automatically completes the University of Tornto's UCheck COVID-19
 15 Nov 30, 2022
15 Nov 30, 2022

Created covid data pipeline using PySpark and MySQL that collected data stream from API and do some processing and store it into MYSQL database.
Created covid data pipeline using PySpark and MySQL that collected data stream from API and do some processing and store it into MYSQL database.
 2 Nov 20, 2021
2 Nov 20, 2021
A Python Covid-19 cases tracker that scrapes data off the web and presents the number of Cases, Recovered Cases, and Deaths that occurred because of the pandemic.
A Python Covid-19 cases tracker that scrapes data off the web and presents the number of Cases, Recovered Cases, and Deaths that occurred because of the pandemic.
 1 Nov 13, 2021
1 Nov 13, 2021