2773 Repositories
Python Data-Science-Intern-Challenge Libraries
Python script that extract data via YouTube Api and manipulates it.
UNLIMITED README for the Unlimited game [Mining game] Explore the docs » View Demo · Report Bug · Request Feature Table of Contents About The Project
 1 Dec 12, 2021
1 Dec 12, 2021

This script has been created in order to find what are the most common demanded technologies in Data Engineering field.
This is a Python script that given a whole corpus of job descriptions and a file with keywords it extracts the number of number of ocurrences of these keywords and write it to a file. This script it is easy to extend to accept more functionalities
 0 Jul 17, 2022
0 Jul 17, 2022
Kodi script for proper Australian weather data
Kodi Oz Weather weather.ozweather Script for Kodi for high quality Australian weather data sourced directly from the BOM. Available from the Kodi offi
 5 Nov 24, 2022
5 Nov 24, 2022
A Python package for Misty II development
Misty2py Misty2py is a Python 3 package for Misty II development using Misty's REST API. Read the full documentation here! Installation Poetry To inst
 1 Mar 7, 2022
1 Mar 7, 2022
Code for the AAAI-2022 paper: Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification
Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification (AAAI 2022) Prerequisite PyTorch = 1.2.0 P
 16 Dec 14, 2022
16 Dec 14, 2022
Codes and pretrained weights for winning submission of 2021 Brain Tumor Segmentation (BraTS) Challenge
Winning submission to the 2021 Brain Tumor Segmentation Challenge This repo contains the codes and pretrained weights for the winning submission to th
 94 Dec 28, 2022
94 Dec 28, 2022
Evaluating saliency methods on artificial data with different background types
Evaluating saliency methods on artificial data with different background types This repository contains the relevant code for the MedNeurips 2021 subm
 2 Jul 5, 2022
2 Jul 5, 2022

Music Source Separation; Train & Eval & Inference piplines and pretrained models we used for 2021 ISMIR MDX Challenge.
Introduction 1. Usage (For MSS) 1.1 Prepare running environment 1.2 Use pretrained model 1.3 Train new MSS models from scratch 1.3.1 How to train 1.3.
 100 Dec 25, 2022
100 Dec 25, 2022
ScisorWiz: Differential Isoform Visualizer for Long-Read RNA Sequencing Data
ScisorWiz: Vizualizer for Differential Isoform Expression README ScisorWiz is a linux-based R-package for visualizing differential isoform expression
 6 Oct 4, 2022
6 Oct 4, 2022
Deep Learning Datasets Maker is a QGIS plugin to make datasets creation easier for raster and vector data.
Deep Learning Dataset Maker Deep Learning Datasets Maker is a QGIS plugin to make datasets creation easier for raster and vector data. How to use Down
 25 Dec 15, 2022
25 Dec 15, 2022
The test data, code and detailed description of the AW t-SNE algorithm
AW-t-SNE The test data, code and result of the AW t-SNE algorithm Structure of the folder Datasets: This folder contains two datasets, the MNIST datas
 1 Mar 9, 2022
1 Mar 9, 2022
Validation and inference over LinkML instance data using souffle
Translates LinkML schemas into Datalog programs and executes them using Souffle, enabling advanced validation and inference over instance data
 7 Aug 7, 2022
7 Aug 7, 2022
Capsule endoscopy detection DACON challenge
capsule_endoscopy_detection (DACON Challenge) Overview Yolov5, Yolor, mmdetection기반의 모델을 사용 (총 11개 모델 앙상블) 모든 모델은 학습 시 Pretrained Weight을 yolov5, yolo
 11 Nov 25, 2022
11 Nov 25, 2022
Python Data Structures and Algorithms
No non-sense and no BS repo for how data structure code should be in Python - simple and elegant.
 1.9k Jan 8, 2023
1.9k Jan 8, 2023

 9.3k Jan 7, 2023
9.3k Jan 7, 2023
Haphazard scripts for scraping bitcoin/bitcoin data from GitHub
This is a quick-and-dirty tool used to scrape bitcoin/bitcoin pull request and commentary data. Each output/pr number folder contains comments.json:
 8 Oct 12, 2022
8 Oct 12, 2022

An implementation of the methods presented in Causal-BALD: Deep Bayesian Active Learning of Outcomes to Infer Treatment-Effects from Observational Data.
An implementation of the methods presented in Causal-BALD: Deep Bayesian Active Learning of Outcomes to Infer Treatment-Effects from Observational Data.
 9 Apr 4, 2022
9 Apr 4, 2022

Code for CVPR2019 paper《Unequal Training for Deep Face Recognition with Long Tailed Noisy Data》
Unequal-Training-for-Deep-Face-Recognition-with-Long-Tailed-Noisy-Data. This is the code of CVPR 2019 paper《Unequal Training for Deep Face Recognition
 68 Jan 7, 2023
68 Jan 7, 2023
![[NeurIPS 2020] Semi-Supervision (Unlabeled Data) & Self-Supervision Improve Class-Imbalanced / Long-Tailed Learning](https://github.com/YyzHarry/imbalanced-semi-self/raw/master/assets/tsne_semi.png)
[NeurIPS 2020] Semi-Supervision (Unlabeled Data) & Self-Supervision Improve Class-Imbalanced / Long-Tailed Learning
Rethinking the Value of Labels for Improving Class-Imbalanced Learning This repository contains the implementation code for paper: Rethinking the Valu
 656 Dec 28, 2022
656 Dec 28, 2022

Supercharging Imbalanced Data Learning WithCausal Representation Transfer
ECRT: Energy-based Causal Representation Transfer Code for Supercharging Imbalanced Data Learning With Energy-basedContrastive Representation Transfer
 11 May 2, 2022
11 May 2, 2022
Machine Learning automation and tracking
The Open-Source MLOps Orchestration Framework MLRun is an open-source MLOps framework that offers an integrative approach to managing your machine-lea
 873 Jan 4, 2023
873 Jan 4, 2023
ZenML 🙏: MLOps framework to create reproducible ML pipelines for production machine learning.
ZenML is an extensible, open-source MLOps framework to create production-ready machine learning pipelines. It has a simple, flexible syntax, is cloud and tool agnostic, and has interfaces/abstractions that are catered towards ML workflows.
 2.6k Dec 27, 2022
2.6k Dec 27, 2022

Kubernetes-native workflow automation platform for complex, mission-critical data and ML processes at scale. It has been battle-tested at Lyft, Spotify, Freenome, and others and is truly open-source.
Flyte Flyte is a workflow automation platform for complex, mission-critical data, and ML processes at scale Home Page · Quick Start · Documentation ·
 3k Jan 1, 2023
3k Jan 1, 2023

Reproducible Data Science at Scale!
Pachyderm: The Data Foundation for Machine Learning Pachyderm provides the data layer that allows machine learning teams to productionize and scale th
 5.7k Dec 29, 2022
5.7k Dec 29, 2022
A high-performance Python-based I/O system for large (and small) deep learning problems, with strong support for PyTorch.
WebDataset WebDataset is a PyTorch Dataset (IterableDataset) implementation providing efficient access to datasets stored in POSIX tar archives and us
 1.1k Jan 8, 2023
1.1k Jan 8, 2023
Existing Literature about Machine Unlearning
Machine Unlearning Papers 2021 Brophy and Lowd. Machine Unlearning for Random Forests. In ICML 2021. Bourtoule et al. Machine Unlearning. In IEEE Symp
 213 Jan 8, 2023
213 Jan 8, 2023

Pytorch Implementations of large number classical backbone CNNs, data enhancement, torch loss, attention, visualization and some common algorithms.
Torch-template-for-deep-learning Pytorch implementations of some **classical backbone CNNs, data enhancement, torch loss, attention, visualization and
 270 Dec 31, 2022
270 Dec 31, 2022
Garbage classification using structure data.
垃圾分类模型使用说明 1.包含以下数据文件 文件 描述 data/MaterialMapping.csv 物体以及其归类的信息 data/TestRecords 光谱原始测试数据 CSV 文件 data/TestRecordDesc.zip CSV 文件描述文件 data/Boundaries.cs
 1 Dec 10, 2021
1 Dec 10, 2021
Discord bot ( discord.py ), uses pandas library from python for data-management.
Discord_bot A Best and the most easy-to-use Discord bot !! Some simple basic auto moderations, Chat functions. It includes a game similar to Casino, g
 4 Aug 30, 2022
4 Aug 30, 2022

Make dbt docs and Apache Superset talk to one another
dbt-superset-lineage Make dbt docs and Apache Superset talk to one another Why do I need something like this? Odds are rather high that you use dbt to
 81 Jan 6, 2023
81 Jan 6, 2023
A simple and lightweight genetic algorithm for optimization of any machine learning model
geneticml This package contains a simple and lightweight genetic algorithm for optimization of any machine learning model. Installation Use pip to ins
 8 Aug 10, 2022
8 Aug 10, 2022
KIDA: Knowledge Inheritance in Data Aggregation
KIDA: Knowledge Inheritance in Data Aggregation This project releases our 1st place solution on NeurIPS2021 ML4CO Dual Task. Slide and model weights a
 24 Sep 8, 2022
24 Sep 8, 2022
Model Validation Toolkit is a collection of tools to assist with validating machine learning models prior to deploying them to production and monitoring them after deployment to production.
Model Validation Toolkit is a collection of tools to assist with validating machine learning models prior to deploying them to production and monitoring them after deployment to production.
 25 Dec 28, 2022
25 Dec 28, 2022
Does MAML Only Work via Feature Re-use? A Data Set Centric Perspective
Does-MAML-Only-Work-via-Feature-Re-use-A-Data-Set-Centric-Perspective Does MAML Only Work via Feature Re-use? A Data Set Centric Perspective Installin
 2 Nov 7, 2022
2 Nov 7, 2022

Python scripts for plotting audiograms and related data from Interacoustics Equinox audiometer and Otoaccess software.
audiometry Python scripts for plotting audiograms and related data from Interacoustics Equinox 2.0 audiometer and Otoaccess software. Maybe similar sc
 2 Jun 15, 2022
2 Jun 15, 2022

Data Analysis for First Year Laboratory at Imperial College, London.
Data Analysis for First Year Laboratory at Imperial College, London. For personal reference only, and to reference in lab reports and lab books.
 0 Aug 29, 2022
0 Aug 29, 2022
This is a project of data parallel that running on NLP tasks.
This is a project of data parallel that running on NLP tasks.
 2 Dec 12, 2021
2 Dec 12, 2021
Applied Machine Learning for Graduate Program in Computer Science (PPGCC)
Applied Machine Learning for Graduate Program in Computer Science (PPGCC) - Federal University of Santa Catarina
 1 Dec 22, 2021
1 Dec 22, 2021
Rapid experimentation and scaling of deep learning models on molecular and crystal graphs.
LitMatter A template for rapid experimentation and scaling deep learning models on molecular and crystal graphs. How to use Clone this repository and
 32 Dec 6, 2022
32 Dec 6, 2022
DANet for Tabular data classification/ regression.
Deep Abstract Networks A PyTorch code implemented for the submission DANets: Deep Abstract Networks for Tabular Data Classification and Regression. Do
 55 Sep 14, 2022
55 Sep 14, 2022

The best solution of the Weather Prediction track in the Yandex Shifts challenge
yandex-shifts-weather The repository contains information about my solution for the Weather Prediction track in the Yandex Shifts challenge https://re
 15 Dec 18, 2022
15 Dec 18, 2022

Package for extracting emotions from social media text. Tailored for financial data.
EmTract: Extracting Emotions from Social Media Text Tailored for Financial Contexts EmTract is a tool that extracts emotions from social media text. I
 13 Nov 17, 2022
13 Nov 17, 2022
BrainGNN - A deep learning model for data-driven discovery of functional connectivity
A deep learning model for data-driven discovery of functional connectivity https://doi.org/10.3390/a14030075 Usman Mahmood, Zengin Fu, Vince D. Calhou
 3 Aug 28, 2022
3 Aug 28, 2022

Multiview 3D object detection on MultiviewC dataset through moft3d.
Voxelized 3D Feature Aggregation for Multiview Detection [arXiv] Multiview 3D object detection on MultiviewC dataset through VFA. Introduction We prop
 20 Dec 21, 2022
20 Dec 21, 2022
The 1st Place Solution of the Facebook AI Image Similarity Challenge (ISC21) : Descriptor Track.
ISC21-Descriptor-Track-1st The 1st Place Solution of the Facebook AI Image Similarity Challenge (ISC21) : Descriptor Track. You can check our solution
 75 Jan 8, 2023
75 Jan 8, 2023
Official PyTorch implementation of the ICRA 2021 paper: Adversarial Differentiable Data Augmentation for Autonomous Systems.
Adversarial Differentiable Data Augmentation This repository provides the official PyTorch implementation of the ICRA 2021 paper: Adversarial Differen
 3 Oct 15, 2022
3 Oct 15, 2022
Projeto job insights - Projeto avaliativo da Trybe do Bloco 32: Introdução à Python
Termos e acordos Ao iniciar este projeto, você concorda com as diretrizes do Código de Ética e Conduta e do Manual da Pessoa Estudante da Trybe. Boas
 1 Dec 9, 2021
1 Dec 9, 2021
A data driven app for bicycle hiring in London(UK)
bicycle_hiring_app_deployed A data driven app for bicycle hiring in London(UK). It predicts expected number of bicycle hire in London. It asks users t
 1 Dec 10, 2021
1 Dec 10, 2021

Script to create an animated data visualisation for categorical timeseries data - GIF choropleth map with annotations.
choropleth_ldn Simple script to create a chloropleth map of London with categorical timeseries data. The script in main.py creates a gif of the most f
 1 Oct 7, 2021
1 Oct 7, 2021
Simple Python project using Opencv and datetime package to recognise faces and log attendance data in a csv file.
Attendance-System-based-on-Facial-recognition-Attendance-data-stored-in-csv-file- Simple Python project using Opencv and datetime package to recognise
 3 Aug 9, 2022
3 Aug 9, 2022
Extracts data from the database for a graph-node and stores it in parquet files
subgraph-extractor Extracts data from the database for a graph-node and stores it in parquet files Installation For developing, it's recommended to us
 0 Jan 10, 2022
0 Jan 10, 2022
Downloads data from OSM API and uploads it to the mapping sandbox.
OpenStreetMap To Sandbox This is a script to download data from OSM API and upload it to the mapping sandbox. Note that it clears all data in the sand
 5 Nov 27, 2022
5 Nov 27, 2022
A simple and lightweight genetic algorithm for optimization of any machine learning model
geneticml This package contains a simple and lightweight genetic algorithm for optimization of any machine learning model. Installation Use pip to ins
8 Aug 10, 2022
Functions to analyze Cell-ID single-cell cytometry data using python language.
PyCellID (building...) Functions to analyze Cell-ID single-cell cytometry data using python language. Dependecies for this project. attrs(=21.1.0) fo
 0 Dec 22, 2021
0 Dec 22, 2021
Cash in on Expressed Barcode Tags (EBTs) from NGS Sequencing Data with Python
Cash in on Expressed Barcode Tags (EBTs) from NGS Sequencing Data with Python Cashier is a tool developed by Russell Durrett for the analysis and extr
 3 Sep 11, 2022
3 Sep 11, 2022
Modular analysis tools for neurophysiology data
Neuroanalysis Modular and interactive tools for analysis of neurophysiology data, with emphasis on patch-clamp electrophysiology. Functions for runnin
 5 Dec 22, 2021
5 Dec 22, 2021
Data pipelines for both TensorFlow and PyTorch!
rapidnlp-datasets Data pipelines for both TensorFlow and PyTorch ! If you want to load public datasets, try: tensorflow/datasets huggingface/datasets
 1 Dec 8, 2021
1 Dec 8, 2021

Implementation of the ivis algorithm as described in the paper Structure-preserving visualisation of high dimensional single-cell datasets.
Implementation of the ivis algorithm as described in the paper Structure-preserving visualisation of high dimensional single-cell datasets.
 285 Jan 4, 2023
285 Jan 4, 2023
Tugas kelompok Struktur Data
Binary-Tree Tugas kelompok Struktur Data Silahkan jika ingin mengubah tipe data pada operasi binary tree *Boleh juga semua program kelompok bisa disat
 2 Nov 28, 2022
2 Nov 28, 2022
This contains timezone mapping information for when preprocessed from the geonames data
when-data This contains timezone mapping information for when preprocessed from the geonames data. It exists in a separate repository so that one does
 2 Dec 7, 2021
2 Dec 7, 2021
A variant caller for the GBA gene using WGS data
Gauchian: WGS-based GBA variant caller Gauchian is a targeted variant caller for the GBA gene based on a whole-genome sequencing (WGS) BAM file. Gauch
 16 Oct 13, 2022
16 Oct 13, 2022
A python script for extracting/removing exif data from images by @AbirHasan2005
Image-Exif A Python script for extracting exif metadata from images. How to use? Using this script you can extract exif data from image and save in .c
 13 Dec 16, 2022
13 Dec 16, 2022
The Spark Challenge Student Check-In/Out Tracking Script
The Spark Challenge Student Check-In/Out Tracking Script This Python Script uses the Student ID Database to match the entries with the ID Card Swipe a
 1 Dec 9, 2021
1 Dec 9, 2021
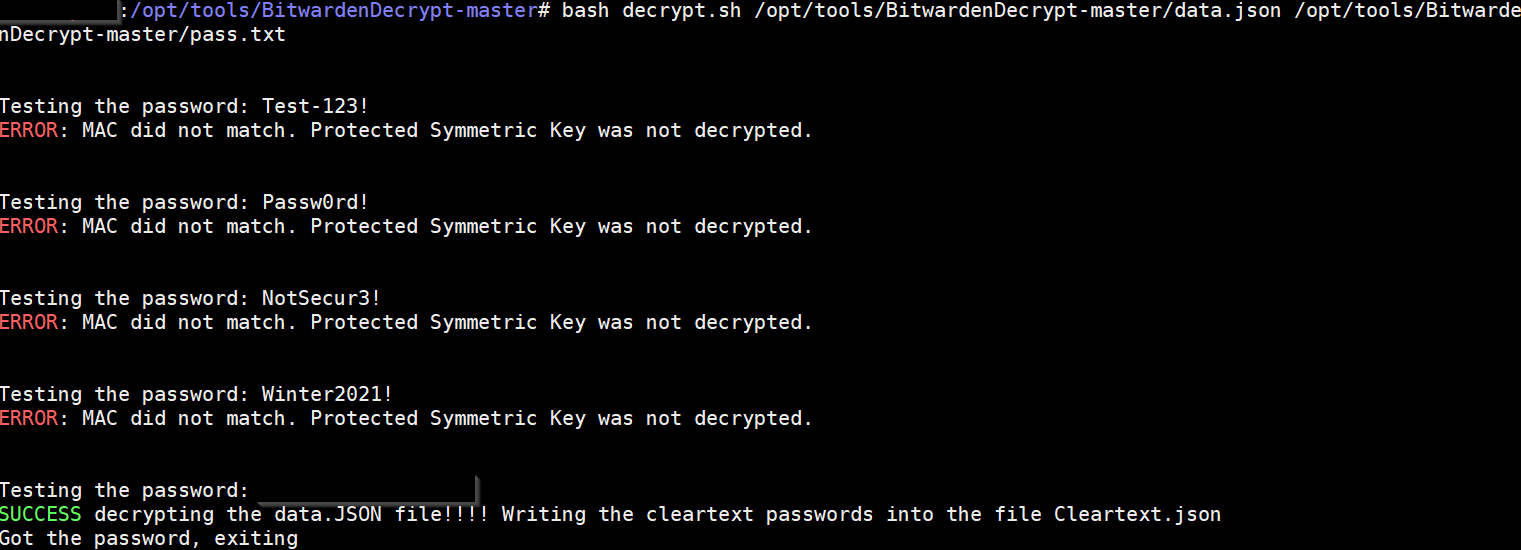
Wordlist attacks on Bitwarden data.json files
BitwardenDecryptBrute This is a slightly modified version of BitwardenDecrypt. In addition to the decryption this version can do wordlist attacks for
 42 Nov 9, 2022
42 Nov 9, 2022
Codebase for the solution that won first place and was awarded the most human-like agent in the 2021 NeurIPS Competition MineRL BASALT Challenge.
KAIROS MineRL BASALT Codebase for the solution that won first place and was awarded the most human-like agent in the 2021 NeurIPS Competition MineRL B
 37 Oct 30, 2022
37 Oct 30, 2022
RoadMap and preparation material for Machine Learning and Data Science - From beginner to expert.
ML-and-DataScience-preparation This repository has the goal to create a learning and preparation roadMap for Machine Learning Engineers and Data Scien
 33 Dec 29, 2022
33 Dec 29, 2022
Data Visualizer Web-Application
Viz-It Data Visualizer Web-Application If I ask you where most of the data wrangler looses their time ? It is Data Overview and EDA. Presenting "Viz-I
 17 Nov 20, 2022
17 Nov 20, 2022

Reading streams of Twitter data, save them to Kafka, then process with Kafka Stream API and Spark Streaming
Using Streaming Twitter Data with Kafka and Spark Reading streams of Twitter data, publishing them to Kafka topic, process message using Kafka Stream
 1 Dec 6, 2021
1 Dec 6, 2021

A little but useful tool to explore OCR data extracted with `pytesseract` and `opencv`
Screenshot OCR Tool Extracting data from screen time screenshots in iOS and Android. We are exploring 3 options: Simple OCR with no text position usin
 1 Dec 7, 2021
1 Dec 7, 2021

This collection of tools that makes it easy to secure and/or obfuscate messages, files, and data.
Scrambler App This collection of tools that makes it easy to secure and/or obfuscate messages, files, and data. It leverages encryption tools such as
 2 Aug 31, 2022
2 Aug 31, 2022
A set of Python scripts and notebooks to help administer and configure Workforce projects.
Workforce Scripts A set of Python scripts and notebooks to help administer and configure Workforce projects. Notebooks Several example Jupyter noteboo
 75 Sep 9, 2022
75 Sep 9, 2022
UF3: a python library for generating ultra-fast interatomic potentials
Ultra-Fast Force Fields (UF3) S. R. Xie, M. Rupp, and R. G. Hennig, "Ultra-fast interpretable machine-learning potentials", preprint arXiv:2110.00624
 24 Nov 13, 2022
24 Nov 13, 2022
Repo with data from local elections in Portugal from 2009 to 2013
autarquicas - local elections in Portugal Repo with data from local elections in Portugal from 2009 to 2013 Objective To provide, to all, raw data fro
 6 Apr 6, 2022
6 Apr 6, 2022
Deep Learning applied to Integral data analysis
DeepIntegralCompton Deep Learning applied to Integral data analysis Module installation Move to the root directory of the project and execute : pip in
 1 Dec 10, 2021
1 Dec 10, 2021
Binance Kline Data With Python
Binance Kline Data by seunghan(gingerthorp) reference https://github.com/binance/binance-public-data/ All intervals are supported: 1m, 3m, 5m, 15m, 30
 5 Jul 13, 2022
5 Jul 13, 2022
A website for courses of Major Computer Science, NKU
A website for courses of Major Computer Science, NKU
 0 Oct 6, 2022
0 Oct 6, 2022
HTSeq is a Python library to facilitate processing and analysis of data from high-throughput sequencing (HTS) experiments.
HTSeq DEVS: https://github.com/htseq/htseq DOCS: https://htseq.readthedocs.io A Python library to facilitate programmatic analysis of data from high-t
 57 Dec 20, 2022
57 Dec 20, 2022

Sacred is a tool to help you configure, organize, log and reproduce experiments developed at IDSIA.
Sacred Every experiment is sacred Every experiment is great If an experiment is wasted God gets quite irate Sacred is a tool to help you configure, or
 4k Jan 2, 2023
4k Jan 2, 2023

Machine learning model evaluation made easy: plots, tables, HTML reports, experiment tracking and Jupyter notebook analysis.
sklearn-evaluation Machine learning model evaluation made easy: plots, tables, HTML reports, experiment tracking, and Jupyter notebook analysis. Suppo
 354 Dec 31, 2022
354 Dec 31, 2022
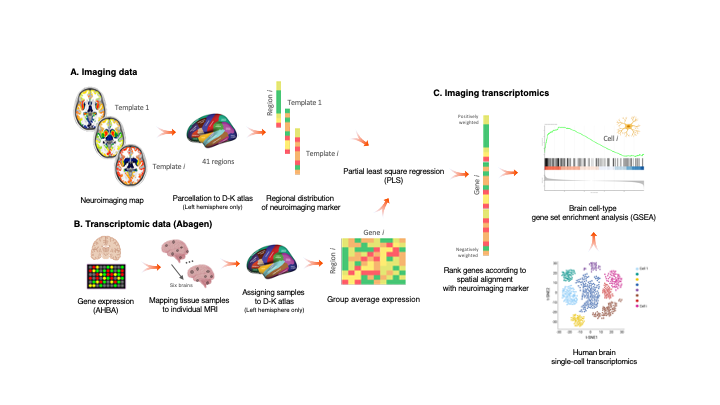
A package, and script, to perform imaging transcriptomics on a neuroimaging scan.
Imaging Transcriptomics Imaging transcriptomics is a methodology that allows to identify patterns of correlation between gene expression and some prop
 10 Dec 27, 2022
10 Dec 27, 2022
Script to generate a massive volume of data in sql, csv, json or xml format
DataGenerator Made with Python Open for pull requests 1. Dependencies To install required dependencies run pip install -r requirements.txt 2. Executi
 3 Sep 20, 2022
3 Sep 20, 2022
This is collection of Managementsystem programs: Hospital Management, Student Managemen, etc
Contribute in this repository and help other students with their assignment by adding python scripts for various management system programs.
 3 Mar 20, 2022
3 Mar 20, 2022

Official Pytorch implementation for 2021 ICCV paper "Learning Motion Priors for 4D Human Body Capture in 3D Scenes" and trained models / data
Learning Motion Priors for 4D Human Body Capture in 3D Scenes (LEMO) Official Pytorch implementation for 2021 ICCV (oral) paper "Learning Motion Prior
 165 Dec 19, 2022
165 Dec 19, 2022
This directory gathers the tools developed by the Data Sourcing Working Group
BigScience Data Sourcing Code This directory gathers the tools developed by the Data Sourcing Working Group First Sourcing Sprint: October 2021 The co
 27 Nov 4, 2022
27 Nov 4, 2022
An audnexus client, providing rich author and audiobook data to Plex via it's legacy plugin agent system.
Audnexus.bundle An audnex.us client, providing rich author and audiobook data to Plex via it's legacy plugin agent system. 📝 Table of Contents About
 248 Jan 2, 2023
248 Jan 2, 2023
An assignment from my grad-level data mining course demonstrating some experience with NLP/neural networks/Pytorch
NLP-Pytorch-Assignment An assignment from my grad-level data mining course (before I started personal projects) demonstrating some experience with NLP
 0 Feb 6, 2022
0 Feb 6, 2022
Demonstrate a Dataflow pipeline that saves data from an API into BigQuery table
Overview dataflow-mvp provides a basic example pipeline that pulls data from an API and writes it to a BigQuery table using GCP's Dataflow (i.e., Apac
 1 Dec 3, 2021
1 Dec 3, 2021
A Python library for loading data from a SpaceX Starlink satellite.
Starlink Python A Python library for loading data from a SpaceX Starlink satellite. The goal is to be a simple interface for Starlink. It builds upon
 2 Jan 16, 2022
2 Jan 16, 2022
Visualize large time-series data in plotly
plotly_resampler enables visualizing large sequential data by adding resampling functionality to Plotly figures. In this Plotly-Resampler demo over 11
 604 Dec 28, 2022
604 Dec 28, 2022
Rainbow DQN implementation accompanying the paper "Fast and Data-Efficient Training of Rainbow" which reaches 205.7 median HNS after 10M frames. 🌈
Rainbow 🌈 An implementation of Rainbow DQN which reaches a median HNS of 205.7 after only 10M frames (the original Rainbow from Hessel et al. 2017 re
 15 Dec 3, 2021
15 Dec 3, 2021
Randomisation-based inference in Python based on data resampling and permutation.
Randomisation-based inference in Python based on data resampling and permutation.
 67 Dec 27, 2022
67 Dec 27, 2022
Python code for working with NFL play by play data.
nfl_data_py nfl_data_py is a Python library for interacting with NFL data sourced from nflfastR, nfldata, dynastyprocess, and Draft Scout. Includes im
 82 Jan 5, 2023
82 Jan 5, 2023
voice assistant made with python that search for covid19 data(like total cases, deaths and etc) in a specific country
covid19-voice-assistant voice assistant made with python that search for covid19 data(like total cases, deaths and etc) in a specific country installi
 2 Dec 5, 2021
2 Dec 5, 2021

Simple API for UCI Machine Learning Dataset Repository (search, download, analyze)
A simple API for working with University of California, Irvine (UCI) Machine Learning (ML) repository Table of Contents Introduction About Page of the
 223 Dec 5, 2022
223 Dec 5, 2022
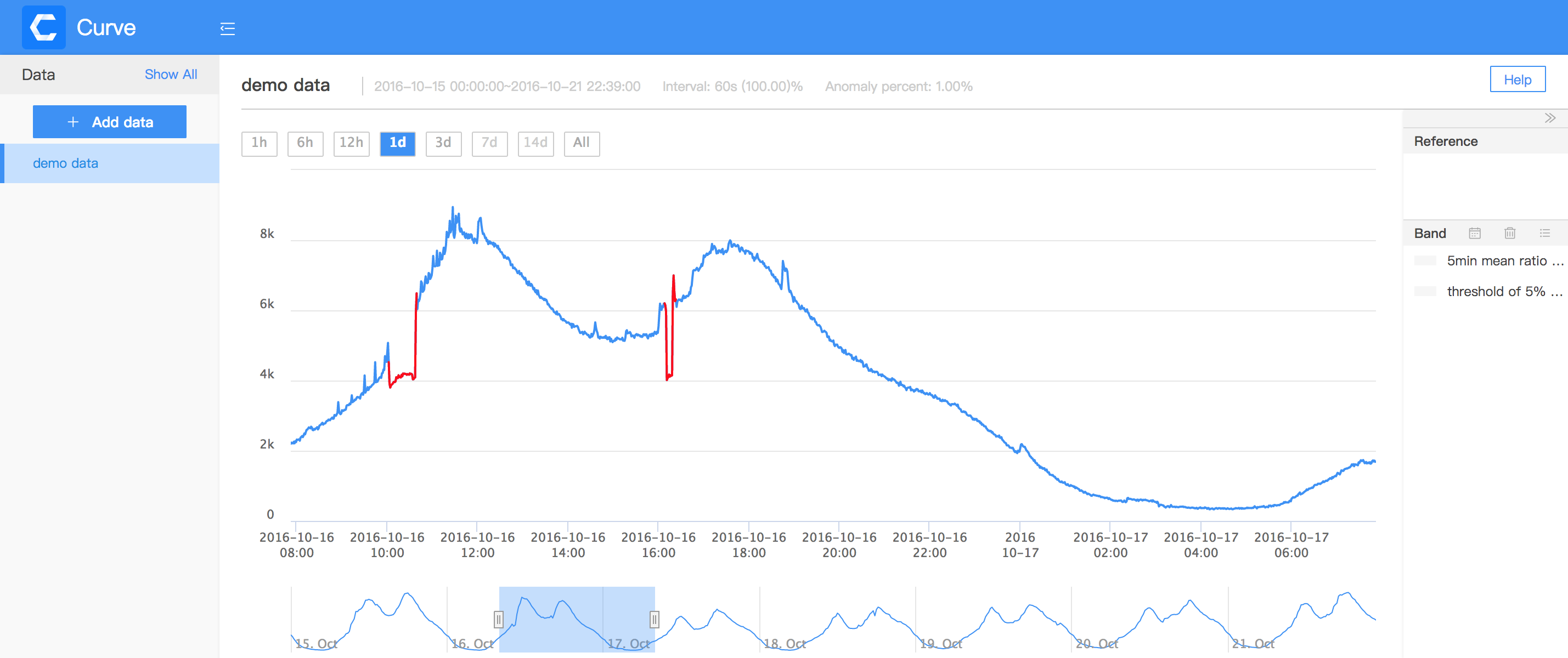
An Integrated Experimental Platform for time series data anomaly detection.
Curve Sorry to tell contributors and users. We decided to archive the project temporarily due to the employee work plan of collaborators. There are no
 486 Dec 21, 2022
486 Dec 21, 2022
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022
Python script to tabulate data formats like json, csv, html, etc
pyT PyT is a a command line tool and as well a library for visualising various data formats like: JSON HTML Table CSV XML, etc. Features Print table o
 1 Dec 30, 2021
1 Dec 30, 2021

MS in Data Science capstone project. Studying attacks on autonomous vehicles.
Surveying Attack Models for CAVs Guide to Installing CARLA and Collecting Data Our project focuses on surveying attack models for Connveced Autonomous
 1 Dec 9, 2021
1 Dec 9, 2021
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022
GDSC UIET KUK 📍 , welcomes you all to this amazing event where you will be introduced to the world of coding 💻 .
GDSC UIET KUK 📍 , welcomes you all to this amazing event where you will be introduced to the world of coding 💻 .
 9 Mar 24, 2022
9 Mar 24, 2022