231 Repositories
Python LARGE Libraries

Code Generation using a large neural network called GPT-J
CodeGenX is a Code Generation system powered by Artificial Intelligence! It is delivered to you in the form of a Visual Studio Code Extension and is Free and Open-source!
 389 Dec 31, 2022
389 Dec 31, 2022
eBay's TSV Utilities: Command line tools for large, tabular data files. Filtering, statistics, sampling, joins and more.
Command line utilities for tabular data files This is a set of command line utilities for manipulating large tabular data files. Files of numeric and
 1.4k Jan 9, 2023
1.4k Jan 9, 2023
Official Implementation of "Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras"
Multi Camera Pig Tracking Official Implementation of Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras CVPR2021 CV4Animals Workshop P
 44 Jan 6, 2023
44 Jan 6, 2023

PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition, CVPR 2018
PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place
 294 Dec 12, 2022
294 Dec 12, 2022

TriMap: Large-scale Dimensionality Reduction Using Triplets
TriMap TriMap is a dimensionality reduction method that uses triplet constraints to form a low-dimensional embedding of a set of points. The triplet c
 235 Dec 24, 2022
235 Dec 24, 2022

An implementation of the largeVis algorithm for visualizing large, high-dimensional datasets, for R
largeVis This is an implementation of the largeVis algorithm described in (https://arxiv.org/abs/1602.00370). It also incorporates: A very fast algori
 336 May 25, 2022
336 May 25, 2022
Datashader is a data rasterization pipeline for automating the process of creating meaningful representations of large amounts of data.
Datashader is a data rasterization pipeline for automating the process of creating meaningful representations of large amounts of data.
 2.9k Jan 6, 2023
2.9k Jan 6, 2023
A Large Scale Benchmark for Individual Treatment Effect Prediction and Uplift Modeling
large-scale-ITE-UM-benchmark This repository contains code and data to reproduce the results of the paper "A Large Scale Benchmark for Individual Trea
 10 Nov 19, 2022
10 Nov 19, 2022

A large-image collection explorer and fast classification tool
IMAX: Interactive Multi-image Analysis eXplorer This is an interactive tool for visualize and classify multiple images at a time. It written in Python
 23 Dec 16, 2022
23 Dec 16, 2022
Bio-Computing Platform Featuring Large-Scale Representation Learning and Multi-Task Deep Learning “螺旋桨”生物计算工具集
English | 简体中文 Latest News 2021.10.25 Paper "Docking-based Virtual Screening with Multi-Task Learning" is accepted by BIBM 2021. 2021.07.29 PaddleHeli
 633 Jan 4, 2023
633 Jan 4, 2023

SHIFT15M: multiobjective large-scale fashion dataset with distributional shifts
[arXiv] The main motivation of the SHIFT15M project is to provide a dataset that contains natural dataset shifts collected from a web service IQON, wh
 138 Nov 24, 2022
138 Nov 24, 2022
Code for text augmentation method leveraging large-scale language models
HyperMix Code for our paper GPT3Mix and conducting classification experiments using GPT-3 prompt-based data augmentation. Getting Started Installing P
 47 Dec 20, 2022
47 Dec 20, 2022

Learning to Map Large-scale Sparse Graphs on Memristive Crossbar
Release of AutoGMap:Learning to Map Large-scale Sparse Graphs on Memristive Crossbar For reproduction of our searched model, the Ubuntu OS is recommen
 2 Aug 23, 2022
2 Aug 23, 2022
Large-scale Hyperspectral Image Clustering Using Contrastive Learning, CIKM 21 Workshop
Spectral-spatial contrastive clustering (SSCC) Yaoming Cai, Yan Liu, Zijia Zhang, Zhihua Cai, and Xiaobo Liu, Large-scale Hyperspectral Image Clusteri
 4 Nov 2, 2022
4 Nov 2, 2022
Source code for our EMNLP'21 paper 《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》
Child-Tuning Source code for EMNLP 2021 Long paper: Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning. 1. Environ
 46 Dec 12, 2022
46 Dec 12, 2022
Create large-scale ML-driven multiscale simulation ensembles to study the interactions
MuMMI RAS v0.1 Released: Nov 16, 2021 MuMMI RAS is the application component of the MuMMI framework developed to create large-scale ML-driven multisca
 4 Feb 16, 2022
4 Feb 16, 2022
PyTorch-LIT is the Lite Inference Toolkit (LIT) for PyTorch which focuses on easy and fast inference of large models on end-devices.
PyTorch-LIT PyTorch-LIT is the Lite Inference Toolkit (LIT) for PyTorch which focuses on easy and fast inference of large models on end-devices. With
 157 Dec 11, 2022
157 Dec 11, 2022
![[NeurIPS 2021] Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods](https://user-images.githubusercontent.com/58995473/120717799-27fd9200-c496-11eb-940f-b16d4d528e0f.png)
[NeurIPS 2021] Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods
Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods Large Scale Learning on Non-Homophilous Graphs: New Benchmark
 16 Nov 12, 2021
16 Nov 12, 2021

ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning. In ICCV, 2021.
ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning This repository contains the code for our ICCV 202
 28 Nov 8, 2022
28 Nov 8, 2022
Code for "FPS-Net: A convolutional fusion network for large-scale LiDAR point cloud segmentation".
FPS-Net Code for "FPS-Net: A convolutional fusion network for large-scale LiDAR point cloud segmentation", accepted by ISPRS journal of Photogrammetry
 15 Nov 30, 2022
15 Nov 30, 2022
This is an example of how to automate Ridit Analysis for a dataset with large amount of questions and many item attributes
This is an example of how to automate Ridit Analysis for a dataset with large amount of questions and many item attributes
 1 Nov 17, 2021
1 Nov 17, 2021
Source code, data, and evaluation details for “Cross-Lingual Citations in English Papers: A Large-Scale Analysis of Prevalence, Formation, and Ramifications”
Analysis of cross-lingual citations in English papers Contents initial_analysis Source code, data, and evaluation details as published at ICADL2020 ci
 1 Oct 27, 2022
1 Oct 27, 2022

NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework
NLP From Scratch Without Large-Scale Pretraining This repository contains the code, pre-trained model checkpoints and curated datasets for our paper:
 224 Dec 8, 2022
224 Dec 8, 2022
![[ICCV 2021] HRegNet: A Hierarchical Network for Large-scale Outdoor LiDAR Point Cloud Registration](https://github.com/ispc-lab/HRegNet/raw/main/assets/overall.png)
[ICCV 2021] HRegNet: A Hierarchical Network for Large-scale Outdoor LiDAR Point Cloud Registration
HRegNet: A Hierarchical Network for Large-scale Outdoor LiDAR Point Cloud Registration Introduction The repository contains the source code and pre-tr
 55 Dec 14, 2022
55 Dec 14, 2022

O2O-Afford: Annotation-Free Large-Scale Object-Object Affordance Learning (CoRL 2021)
O2O-Afford: Annotation-Free Large-Scale Object-Object Affordance Learning Object-object Interaction Affordance Learning. For a given object-object int
 26 Nov 4, 2022
26 Nov 4, 2022
Implementation of "Scaled-YOLOv4: Scaling Cross Stage Partial Network" using PyTorch framwork.
YOLOv4-large This is the implementation of "Scaled-YOLOv4: Scaling Cross Stage Partial Network" using PyTorch framwork. YOLOv4-CSP YOLOv4-tiny YOLOv4-
 2k Jan 2, 2023
2k Jan 2, 2023
A tool for batch processing large fasta files and accompanying metadata table to upload to repositories via API
Fasta Uploader A tool for batch processing large fasta files and accompanying metadata table to repositories via API The python fasta_uploader.py scri
 1 Dec 9, 2021
1 Dec 9, 2021
Code for EMNLP2021 paper "Allocating Large Vocabulary Capacity for Cross-lingual Language Model Pre-training"
VoCapXLM Code for EMNLP2021 paper Allocating Large Vocabulary Capacity for Cross-lingual Language Model Pre-training Environment DockerFile: dancingso
 15 Jul 28, 2022
15 Jul 28, 2022

SW components and demos for visual kinship recognition. An emphasis is put on the FIW dataset-- data loaders, benchmarks, results in summary.
FIW Data Development Kit Table of Contents Introduction Families In the Wild Database Publications Organization To Do License Getting Involved Introdu
 12 Jun 4, 2022
12 Jun 4, 2022
RM Operation can equivalently convert ResNet to VGG, which is better for pruning; and can help RepVGG perform better when the depth is large.
RMNet: Equivalently Removing Residual Connection from Networks This repository is the official implementation of "RMNet: Equivalently Removing Residua
 184 Jan 4, 2023
184 Jan 4, 2023

A large-scale database for graph representation learning
A large-scale database for graph representation learning
 29 Nov 25, 2022
29 Nov 25, 2022
Paper Code:A Self-adaptive Weighted Differential Evolution Approach for Large-scale Feature Selection
1. SaWDE.m is the main function 2. DataPartition.m is used to randomly partition the original data into training sets and test sets with a ratio of 7
 14 Dec 8, 2022
14 Dec 8, 2022
[NeurIPS 2021] Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods
Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods Large Scale Learning on Non-Homophilous Graphs: New Benchmark
60 Jan 3, 2023
![[v1 (ISBI'21) + v2] MedMNIST: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification](https://github.com/MedMNIST/MedMNIST/raw/main/assets/medmnistv2.jpg)
[v1 (ISBI'21) + v2] MedMNIST: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification
MedMNIST Project (Website) | Dataset (Zenodo) | Paper (arXiv) | MedMNIST v1 (ISBI'21) Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bili
 683 Dec 28, 2022
683 Dec 28, 2022
Colossal-AI: A Unified Deep Learning System for Large-Scale Parallel Training
ColossalAI An integrated large-scale model training system with efficient parallelization techniques. arXiv: Colossal-AI: A Unified Deep Learning Syst
 7.9k Jan 8, 2023
7.9k Jan 8, 2023
Colossal-AI: A Unified Deep Learning System for Large-Scale Parallel Training
ColossalAI An integrated large-scale model training system with efficient parallelization techniques Installation PyPI pip install colossalai Install
7.1k Jan 3, 2023

A new benchmark for Icon Question Answering (IconQA) and a large-scale icon dataset Icon645.
IconQA About IconQA is a new diverse abstract visual question answering dataset that highlights the importance of abstract diagram understanding and c
 24 Dec 30, 2022
24 Dec 30, 2022

Can we visualize a large scientific data set with a surrogate model? We're building a GAN for the Earth's Mantle Convection data set to see if we can!
EarthGAN - Earth Mantle Surrogate Modeling Can a surrogate model of the Earth’s Mantle Convection data set be built such that it can be readily run in
 0 Dec 9, 2021
0 Dec 9, 2021
Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking
Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking We revisit and address issues with Oxford 5k and Paris 6k image retrieval benchm
 188 Dec 17, 2022
188 Dec 17, 2022

Official PyTorch implementation of "Improving Face Recognition with Large AgeGaps by Learning to Distinguish Children" (BMVC 2021)
Inter-Prototype (BMVC 2021): Official Project Webpage This repository provides the official PyTorch implementation of the following paper: Improving F
 16 Jun 30, 2022
16 Jun 30, 2022
Very Deep Convolutional Networks for Large-Scale Image Recognition
pytorch-vgg Some scripts to convert the VGG-16 and VGG-19 models [1] from Caffe to PyTorch. The converted models can be used with the PyTorch model zo
 217 Dec 5, 2022
217 Dec 5, 2022
Official PyTorch implementation of "Improving Face Recognition with Large AgeGaps by Learning to Distinguish Children" (BMVC 2021)
Inter-Prototype (BMVC 2021): Official Project Webpage This repository provides the official PyTorch implementation of the following paper: Improving F
16 Jun 30, 2022
A bot for Large Fry Larrys
GroupMe Bot Driver This driver is written entirely in Python, and with easy configuration in mind. Using this driver, you'll be able to monitor multip
 1 Oct 25, 2021
1 Oct 25, 2021

Open-source Laplacian Eigenmaps for dimensionality reduction of large data in python.
Fast Laplacian Eigenmaps in python Open-source Laplacian Eigenmaps for dimensionality reduction of large data in python. Comes with an wrapper for NMS
 17 Jul 9, 2022
17 Jul 9, 2022

OpenABC-D: A Large-Scale Dataset For Machine Learning Guided Integrated Circuit Synthesis
OpenABC-D: A Large-Scale Dataset For Machine Learning Guided Integrated Circuit Synthesis Overview OpenABC-D is a large-scale labeled dataset generate
 31 Nov 22, 2022
31 Nov 22, 2022

Recommendation algorithms for large graphs
Fast recommendation algorithms for large graphs based on link analysis. License: Apache Software License Author: Emmanouil (Manios) Krasanakis Depende
 27 Jan 7, 2023
27 Jan 7, 2023

🦙 LaMa Image Inpainting, Resolution-robust Large Mask Inpainting with Fourier Convolutions, WACV 2022
🦙 LaMa Image Inpainting, Resolution-robust Large Mask Inpainting with Fourier Convolutions, WACV 2022
 4.7k Dec 31, 2022
4.7k Dec 31, 2022
Solver for Large-Scale Rank-One Semidefinite Relaxations
STRIDE: spectrahedral proximal gradient descent along vertices A Solver for Large-Scale Rank-One Semidefinite Relaxations About STRIDE is designed for
 48 Dec 20, 2022
48 Dec 20, 2022
Code to reproduce the experiments from our NeurIPS 2021 paper " The Limitations of Large Width in Neural Networks: A Deep Gaussian Process Perspective"
Code To run: python runner.py new --save SAVE_NAME --data PATH_TO_DATA_DIR --dataset DATASET --model model_name [options] --n 1000 - train - t
 5 Dec 12, 2022
5 Dec 12, 2022
An implementation of the [Hierarchical (Sig-Wasserstein) GAN] algorithm for large dimensional Time Series Generation
Hierarchical GAN for large dimensional financial market data Implementation This repository is an implementation of the [Hierarchical (Sig-Wasserstein
 11 Nov 29, 2022
11 Nov 29, 2022
A utility for quickly cropping large collections of images.
Crop Tool A utility for quickly cropping large collections of images. Inspired by Derrick Schultz's dataset-tools. Setup It's suggested that you use A
 6 Nov 14, 2021
6 Nov 14, 2021
Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks
Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks This repository contains a TensorFlow implementation of "
 5 Jan 8, 2023
5 Jan 8, 2023

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: UniSpeech (ICML 2021): Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR UniSpeech-
 33 Oct 14, 2021
33 Oct 14, 2021

Current Antarctic large iceberg positions derived from ASCAT and OSCAT-2
Iceberg Locations Antarctic large iceberg positions derived from ASCAT and OSCAT-2. All data collected here are from the NASA SCP website Overview Thi
 5 Jul 27, 2022
5 Jul 27, 2022
LIVECell - A large-scale dataset for label-free live cell segmentation
LIVECell dataset This document contains instructions of how to access the data associated with the submitted manuscript "LIVECell - A large-scale data
 112 Jan 7, 2023
112 Jan 7, 2023

Large Scale Multi-Illuminant (LSMI) Dataset for Developing White Balance Algorithm under Mixed Illumination
Large Scale Multi-Illuminant (LSMI) Dataset for Developing White Balance Algorithm under Mixed Illumination (ICCV 2021) Dataset License This work is l
 33 Jan 4, 2023
33 Jan 4, 2023
dotsend is a web application which helps you to upload your large files and share file via link
dotsend is a web application which helps you to upload your large files and share file via link
 0 Dec 3, 2022
0 Dec 3, 2022
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
 37 Sep 5, 2022
37 Sep 5, 2022
MEDS: Enhancing Memory Error Detection for Large-Scale Applications
MEDS: Enhancing Memory Error Detection for Large-Scale Applications Prerequisites cmake and clang Build MEDS supporting compiler $ make Build Using Do
 34 Dec 14, 2022
34 Dec 14, 2022

A framework for large scale recommendation algorithms.
A framework for large scale recommendation algorithms.
 880 Jan 3, 2023
880 Jan 3, 2023

Pytorch implementation for "Large-Scale Long-Tailed Recognition in an Open World" (CVPR 2019 ORAL)
Large-Scale Long-Tailed Recognition in an Open World [Project] [Paper] [Blog] Overview Open Long-Tailed Recognition (OLTR) is the author's re-implemen
 761 Dec 26, 2022
761 Dec 26, 2022

SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification
SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification
 24 May 20, 2022
24 May 20, 2022
Large-scale open domain KNOwledge grounded conVERsation system based on PaddlePaddle
Knover Knover is a toolkit for knowledge grounded dialogue generation based on PaddlePaddle. Knover allows researchers and developers to carry out eff
607 Dec 31, 2022

BMInf (Big Model Inference) is a low-resource inference package for large-scale pretrained language models (PLMs).
BMInf (Big Model Inference) is a low-resource inference package for large-scale pretrained language models (PLMs).
 377 Jan 2, 2023
377 Jan 2, 2023

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022
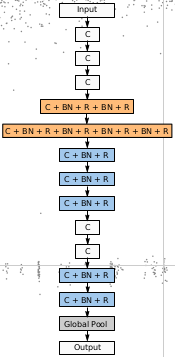
This implements one of result networks from Large-scale evolution of image classifiers
Exotic structured image classifier This implements one of result networks from Large-scale evolution of image classifiers by Esteban Real, et. al. Req
 54 Nov 25, 2022
54 Nov 25, 2022

Django helper application to easily and non-destructively crop arbitrarily large images in admin and frontend.
django-image-cropping django-image-cropping is an app for cropping uploaded images via Django's admin backend using Jcrop. Screenshot: django-image-cr
 546 Jan 3, 2023
546 Jan 3, 2023
IndoBERTweet is the first large-scale pretrained model for Indonesian Twitter. Published at EMNLP 2021 (main conference)
IndoBERTweet 🐦 🇮🇩 1. Paper Fajri Koto, Jey Han Lau, and Timothy Baldwin. IndoBERTweet: A Pretrained Language Model for Indonesian Twitter with Effe
 40 Nov 30, 2022
40 Nov 30, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
7.6k Jan 1, 2023
Galileo library for large scale graph training by JD
近年来,图计算在搜索、推荐和风控等场景中获得显著的效果,但也面临超大规模异构图训练,与现有的深度学习框架Tensorflow和PyTorch结合等难题。 Galileo(伽利略)是一个图深度学习框架,具备超大规模、易使用、易扩展、高性能、双后端等优点,旨在解决超大规模图算法在工业级场景的落地难题,提
 128 Nov 29, 2022
128 Nov 29, 2022

Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine.
img2dataset Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine. Also supports
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
This software's intent is to automate all activities related to manage Axie Infinity Scholars. It is specially aimed to mangers with large scholar roasters.
Axie Scholars Utilities This software's intent is to automate all activities related to manage Scholars. It is specially aimed to mangers with large s
 153 Nov 16, 2022
153 Nov 16, 2022
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022
Code used to generate the results appearing in "Train longer, generalize better: closing the generalization gap in large batch training of neural networks"
Train longer, generalize better - Big batch training This is a code repository used to generate the results appearing in "Train longer, generalize bet
 145 Sep 16, 2022
145 Sep 16, 2022
Evaluation suite for large-scale language models.
This repo contains code for running the evaluations and reproducing the results from the Jurassic-1 Technical Paper (see blog post), with current support for running the tasks through both the AI21 Studio API and OpenAI's GPT3 API.
 71 Dec 17, 2022
71 Dec 17, 2022
A pytorch implementation of the CVPR2021 paper "VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild"
VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild A pytorch implementation of the CVPR2021 paper "VSPW: A Large-scale Dataset for Video
 45 Nov 29, 2022
45 Nov 29, 2022
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023
Large scale embeddings on a single machine.
Marius Marius is a system under active development for training embeddings for large-scale graphs on a single machine. Training on large scale graphs
 107 Jan 3, 2023
107 Jan 3, 2023
ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge (ManiSkill Challenge), a large-scale learning-from-demonstrations benchmark for object manipulation.
ManiSkill-Learn ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge, a large-scale learning-from-dem
 48 Dec 30, 2022
48 Dec 30, 2022
Run Effective Large Batch Contrastive Learning on Limited Memory GPU
Gradient Cache Gradient Cache is a simple technique for unlimitedly scaling contrastive learning batch far beyond GPU memory constraint. This means tr
 198 Dec 29, 2022
198 Dec 29, 2022

A central task in drug discovery is searching, screening, and organizing large chemical databases
A central task in drug discovery is searching, screening, and organizing large chemical databases. Here, we implement clustering on molecular similarity. We support multiple methods to provide a interactive exploration of chemical space.
 124 Jan 7, 2023
124 Jan 7, 2023

Official Implementation of LARGE: Latent-Based Regression through GAN Semantics
LARGE: Latent-Based Regression through GAN Semantics [Project Website] [Google Colab] [Paper] LARGE: Latent-Based Regression through GAN Semantics Yot
 83 Dec 6, 2022
83 Dec 6, 2022
A Python library to utilize AWS API Gateway's large IP pool as a proxy to generate pseudo-infinite IPs for web scraping and brute forcing.
A Python library to utilize AWS API Gateway's large IP pool as a proxy to generate pseudo-infinite IPs for web scraping and brute forcing.
 929 Jan 1, 2023
929 Jan 1, 2023

FactSeg: Foreground Activation Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery (TGRS)
FactSeg: Foreground Activation Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery by Ailong Ma, Junjue Wang*, Yanfei Zhon
 43 Jan 5, 2023
43 Jan 5, 2023

A PyTorch implementation of "Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks" (KDD 2019).
ClusterGCN ⠀⠀ A PyTorch implementation of "Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks" (KDD 2019). A
 697 Dec 27, 2022
697 Dec 27, 2022

Official repository for the paper, MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding.
MidiBERT-Piano Authors: Yi-Hui (Sophia) Chou, I-Chun (Bronwin) Chen Introduction This is the official repository for the paper, MidiBERT-Piano: Large-
 137 Dec 15, 2022
137 Dec 15, 2022

A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
 75 Dec 26, 2022
75 Dec 26, 2022

An algorithm that handles large-scale aerial photo co-registration, based on SURF, RANSAC and PyTorch autograd.
An algorithm that handles large-scale aerial photo co-registration, based on SURF, RANSAC and PyTorch autograd.
 41 Oct 29, 2022
41 Oct 29, 2022
Large dataset storage format for Pytorch
H5Record Large dataset ( 100G, = 1T) storage format for Pytorch (wip) Support python 3 pip install h5record Why? Writing large dataset is still a
 43 Oct 22, 2022
43 Oct 22, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
 190 Jan 3, 2023
190 Jan 3, 2023

A large dataset of 100k Google Satellite and matching Map images, resembling pix2pix's Google Maps dataset.
Larger Google Sat2Map dataset This dataset extends the aerial ⟷ Maps dataset used in pix2pix (Isola et al., CVPR17). The provide script download_sat2m
 34 Dec 28, 2022
34 Dec 28, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
189 Jan 2, 2023

Square Root Bundle Adjustment for Large-Scale Reconstruction
RootBA: Square Root Bundle Adjustment Project Page | Paper | Poster | Video | Code Table of Contents Citation Dependencies Installing dependencies on
 205 Dec 20, 2022
205 Dec 20, 2022

Official Implement of CVPR 2021 paper “Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting”
RGBT Crowd Counting Lingbo Liu, Jiaqi Chen, Hefeng Wu, Guanbin Li, Chenglong Li, Liang Lin. "Cross-Modal Collaborative Representation Learning and a L
 37 Dec 8, 2022
37 Dec 8, 2022
Compositional and Parameter-Efficient Representations for Large Knowledge Graphs
NodePiece - Compositional and Parameter-Efficient Representations for Large Knowledge Graphs NodePiece is a "tokenizer" for reducing entity vocabulary
 107 Jan 4, 2023
107 Jan 4, 2023

Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020)
GraspNet Baseline Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020). [paper] [dataset] [API] [do
 209 Dec 29, 2022
209 Dec 29, 2022

Human POSEitioning System (HPS): 3D Human Pose Estimation and Self-localization in Large Scenes from Body-Mounted Sensors, CVPR 2021
Human POSEitioning System (HPS): 3D Human Pose Estimation and Self-localization in Large Scenes from Body-Mounted Sensors Human POSEitioning System (H
 66 Dec 21, 2022
66 Dec 21, 2022
DistML is a Ray extension library to support large-scale distributed ML training on heterogeneous multi-node multi-GPU clusters
DistML is a Ray extension library to support large-scale distributed ML training on heterogeneous multi-node multi-GPU clusters
 27 Aug 19, 2022
27 Aug 19, 2022

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021