2002 Repositories
Python NLP-Natural-Language-Processing Libraries
Knock your images before these make you painful.
image-knocker Knock your images before these make you painful. Background One day, I had run my deep learning model training program and got off work
 9 Jul 25, 2022
9 Jul 25, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022
This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation". It is intended to be used for normalizing / cleaning Bengali and English text.
normalizer This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch
 23 Nov 30, 2022
23 Nov 30, 2022
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022
📷 Python package and CLI utility to create photo mosaics.
📷 Python package and CLI utility to create photo mosaics.
 7 Oct 29, 2022
7 Oct 29, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Reading list for research topics in sound event detection
Sound event detection aims at processing the continuous acoustic signal and converting it into symbolic descriptions of the corresponding sound events present at the auditory scene.
 64 Jan 5, 2023
64 Jan 5, 2023
Bridging Vision and Language Model
BriVL BriVL (Bridging Vision and Language Model) 是首个中文通用图文多模态大规模预训练模型。BriVL模型在图文检索任务上有着优异的效果,超过了同期其他常见的多模态预训练模型(例如UNITER、CLIP)。 BriVL论文:WenLan: Bridgi
 235 Dec 27, 2022
235 Dec 27, 2022

Data augmentation for NLP, accepted at EMNLP 2021 Findings
AEDA: An Easier Data Augmentation Technique for Text Classification This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Techni
 81 Dec 9, 2022
81 Dec 9, 2022
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks A Transformer-based library for SocialNLP classification tasks. Currently
 298 Jan 7, 2023
298 Jan 7, 2023
tagls is a language server based on gtags.
tagls tagls is a language server based on gtags. Why I wrote it? Almost all modern editors have great support to LSP, but language servers based on se
 31 Dec 1, 2022
31 Dec 1, 2022

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022

TorchIO is a Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
 1.6k Jan 6, 2023
1.6k Jan 6, 2023

🎴 LearnQuick is a flashcard application that you can study with decks and cards.
🎴 LearnQuick is a flashcard application that you can study with decks and cards. The main function of the application is to show the front sides of the created cards to the user and ask them to guess the back of the card. As a result of self-assessment of user's ability to guess the back sides of the displayed cards, the cards that user weak against are shown more often, and the cards that user strong against are shown less frequently.
 7 Aug 21, 2022
7 Aug 21, 2022

Application for shadowing Chinese.
chinese-shadowing Simple APP for shadowing chinese. With this application, it is very easy to record yourself, play the sound recorded and listen to s
 5 Sep 6, 2022
5 Sep 6, 2022

MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving.
MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving. It is a comprehensive framework for research purpose that integrates popular MWP benchmark datasets and typical deep learning-based MWP algorithms.
 119 Jan 4, 2023
119 Jan 4, 2023
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
297 Dec 29, 2022

pedalboard is a Python library for adding effects to audio.
pedalboard is a Python library for adding effects to audio. It supports a number of common audio effects out of the box, and also allows the use of VST3® and Audio Unit plugin formats for third-party effects.
 3.9k Jan 2, 2023
3.9k Jan 2, 2023

fishington.io bot with OpenCV and NumPy
fishington.io-bot fishington.io bot with using OpenCV and NumPy bot can continue to fishing fully automatically how to use Open cmd in fishington.io-b
 77 Jan 2, 2023
77 Jan 2, 2023
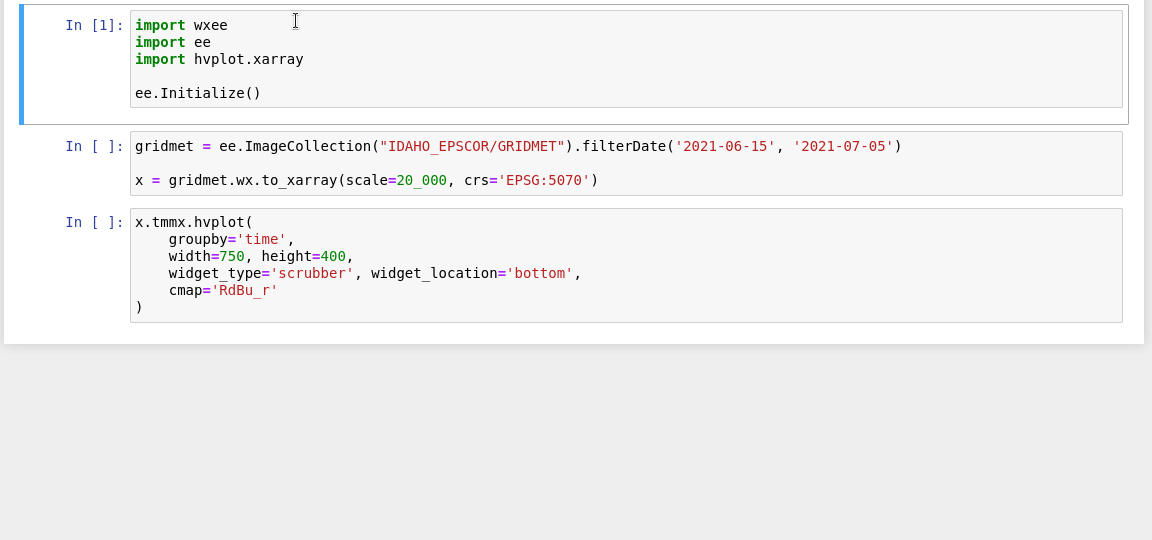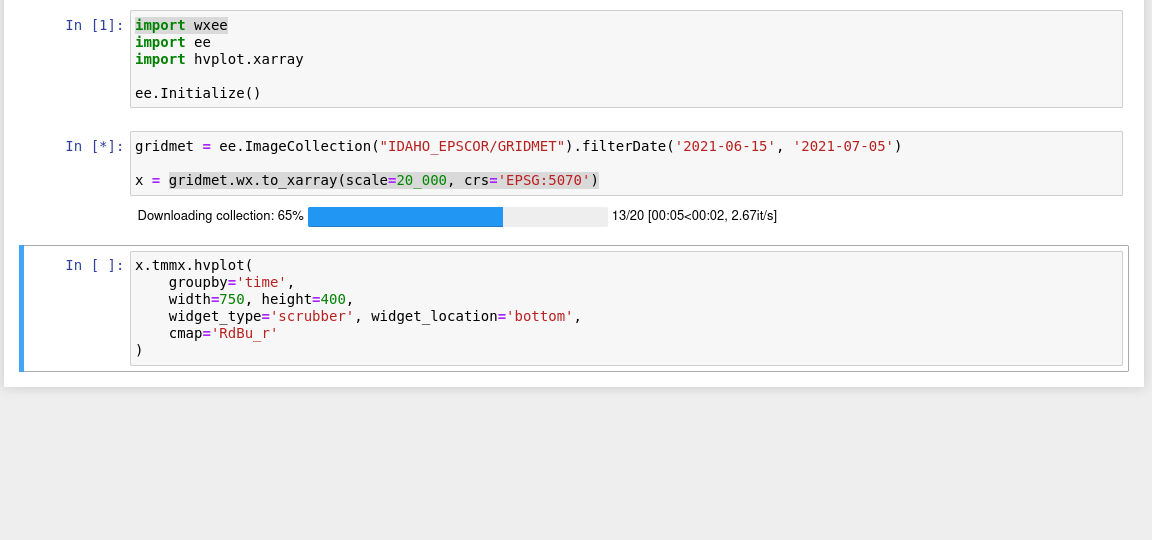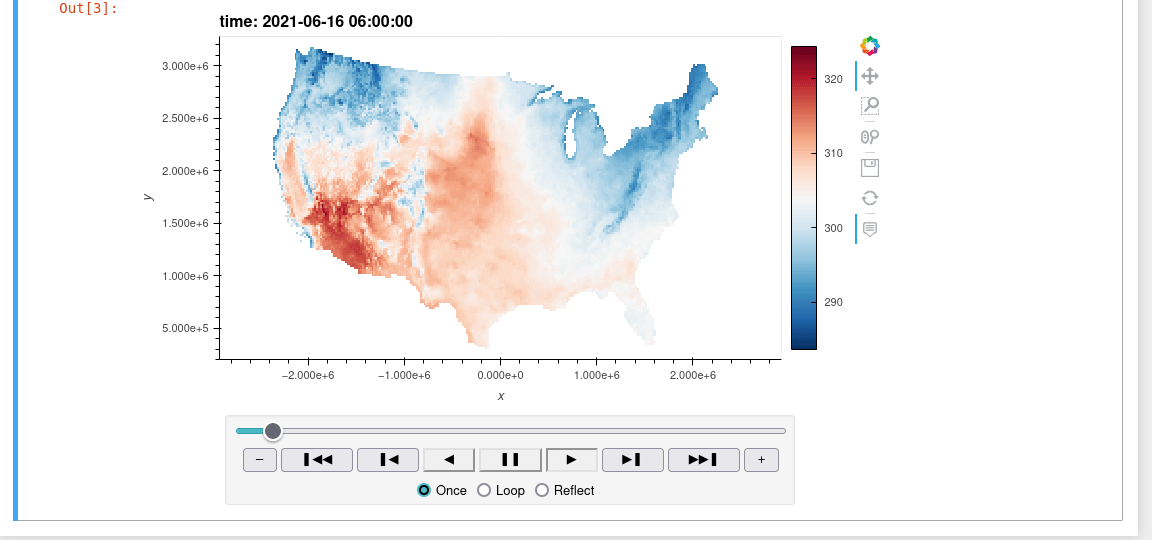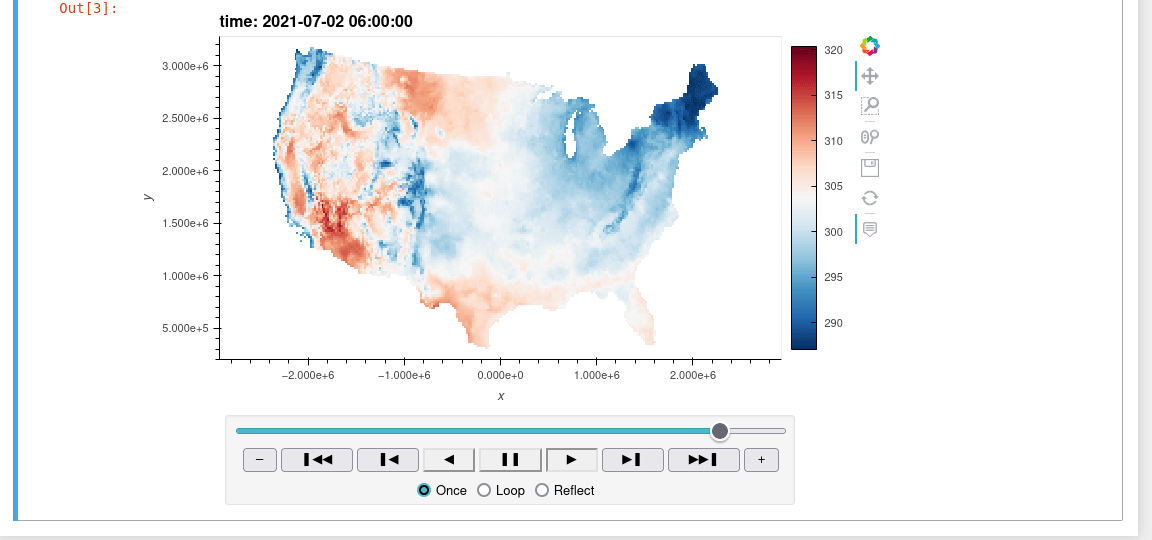
A Python interface between Earth Engine and xarray for processing weather and climate data
wxee What is wxee? wxee was built to make processing gridded, mesoscale time series weather and climate data quick and easy by integrating the data ca
 160 Dec 31, 2022
160 Dec 31, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
Ray-based parallel data preprocessing for NLP and ML.
Wrangl Ray-based parallel data preprocessing for NLP and ML. pip install wrangl # for latest pip install git+https://github.com/vzhong/wrangl See exa
 33 Dec 27, 2022
33 Dec 27, 2022
Framework for creating efficient data processing pipelines
Aqueduct Framework for creating efficient data processing pipelines. Contact Feel free to ask questions in telegram t.me/avito-ml Key Features Increas
 137 Dec 29, 2022
137 Dec 29, 2022
Add filters (background blur, etc) to your webcam on Linux.
webcam-filters Add filters (background blur, etc) to your webcam on Linux. Video conferencing applications tend to either lack video effects altogethe
 480 Dec 14, 2022
480 Dec 14, 2022
超轻量级bert的pytorch版本,大量中文注释,容易修改结构,持续更新
bert4pytorch 2021年8月27更新: 感谢大家的star,最近有小伙伴反映了一些小的bug,我也注意到了,奈何这个月工作上实在太忙,更新不及时,大约会在9月中旬集中更新一个只需要pip一下就完全可用的版本,然后会新添加一些关键注释。 再增加对抗训练的内容,更新一个完整的finetune
 317 Dec 18, 2022
317 Dec 18, 2022
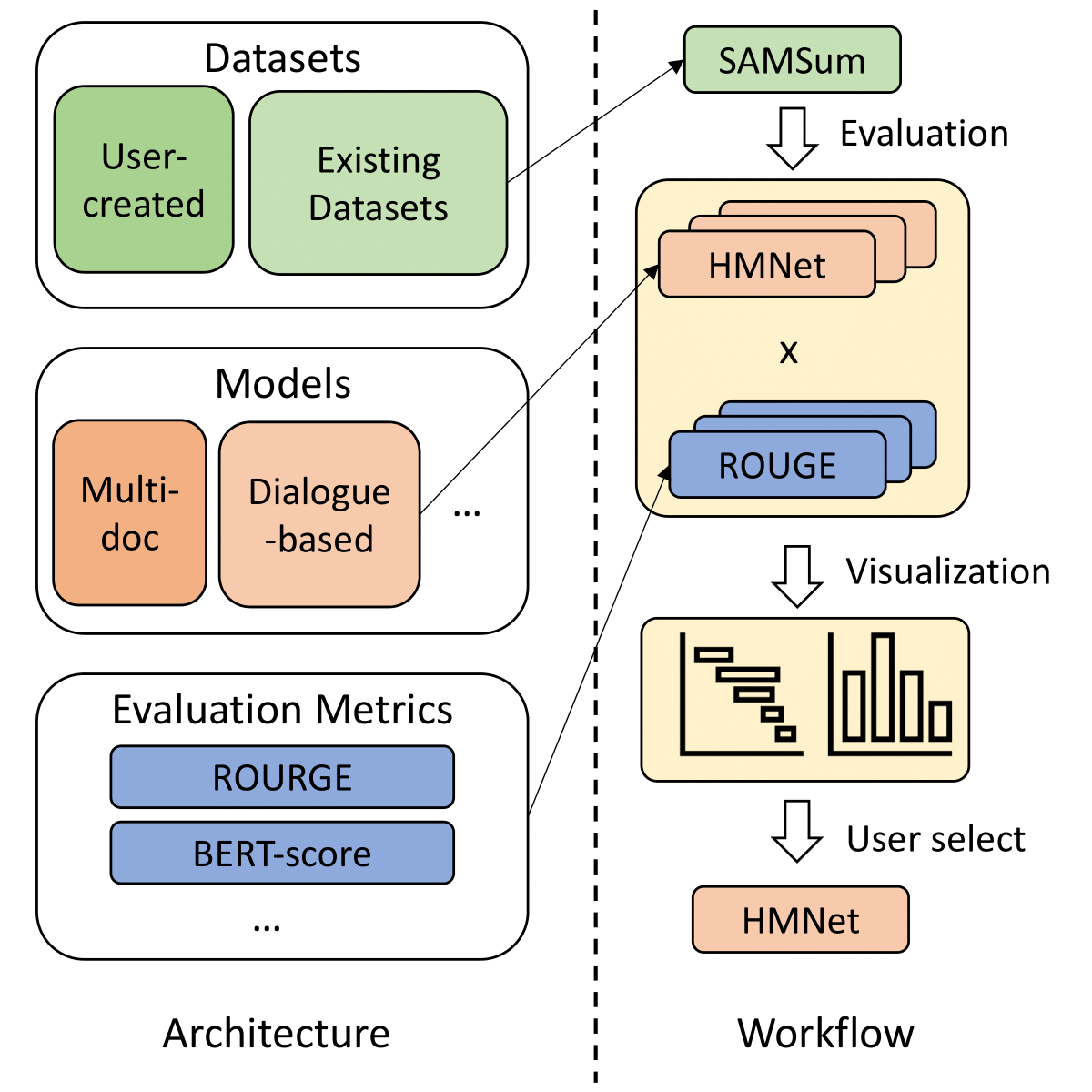
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023
EMNLP 2021 - Frustratingly Simple Pretraining Alternatives to Masked Language Modeling
Frustratingly Simple Pretraining Alternatives to Masked Language Modeling This is the official implementation for "Frustratingly Simple Pretraining Al
 31 Nov 18, 2022
31 Nov 18, 2022

Türkçe küfürlü içerikleri bulan bir yapay zeka kütüphanesi / An ML library for profanity detection in Turkish sentences
"Kötü söz sahibine aittir." -Anonim Nedir? sinkaf uygunsuz yorumların bulunmasını sağlayan bir python kütüphanesidir. Farkı nedir? Diğer algoritmalard
 4 Feb 18, 2022
4 Feb 18, 2022
Dataloader tools for language modelling
Installation: pip install lm_dataloader Design Philosophy A library to unify lm dataloading at large scale Simple interface, any tokenizer can be inte
 5 Mar 25, 2022
5 Mar 25, 2022
Ask for weather information like a human
weather-nlp About Ask for weather information like a human. Goals Understand typical questions like: Hourly temperatures in Potsdam on 2020-09-15. Rai
 5 Oct 29, 2022
5 Oct 29, 2022

🌈 PyTorch Implementation for EMNLP'21 Findings "Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer"
SGLKT-VisDial Pytorch Implementation for the paper: Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer Gi-Cheon Kang, Junseok P
 9 Jul 5, 2022
9 Jul 5, 2022
Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs
Perceiver IO Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs Usage import torch from src.perceiver.
 111 Nov 15, 2022
111 Nov 15, 2022
EMNLP 2021 Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections
Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections Ruiqi Zhong, Kristy Lee*, Zheng Zhang*, Dan Klein EMN
 42 Nov 3, 2022
42 Nov 3, 2022

An original implementation of "Noisy Channel Language Model Prompting for Few-Shot Text Classification"
Channel LM Prompting (and beyond) This includes an original implementation of Sewon Min, Mike Lewis, Hannaneh Hajishirzi, Luke Zettlemoyer. "Noisy Cha
 92 Jan 7, 2023
92 Jan 7, 2023

Ongoing research training transformer language models at scale, including: BERT & GPT-2
Megatron (1 and 2) is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA.
 3.5k Dec 30, 2022
3.5k Dec 30, 2022
This repo is to provide a list of literature regarding Deep Learning on Graphs for NLP
This repo is to provide a list of literature regarding Deep Learning on Graphs for NLP
 230 Nov 22, 2022
230 Nov 22, 2022
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022

The source code of CVPR 2019 paper "Deep Exemplar-based Video Colorization".
Deep Exemplar-based Video Colorization (Pytorch Implementation) Paper | Pretrained Model | Youtube video 🔥 | Colab demo Deep Exemplar-based Video Col
 253 Dec 27, 2022
253 Dec 27, 2022

Code for our ALiBi method for transformer language models.
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation This repository contains the code and models for our paper Tra
 211 Dec 31, 2022
211 Dec 31, 2022

CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
100 Dec 28, 2022
⚖️ A Statutory Article Retrieval Dataset in French.
A Statutory Article Retrieval Dataset in French This repository contains the Belgian Statutory Article Retrieval Dataset (BSARD), as well as the code
 19 Nov 17, 2022
19 Nov 17, 2022
CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
100 Dec 28, 2022
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion Yinghao Aaron Li, Ali Zare, Nima Mesgarani We pres
 282 Jan 1, 2023
282 Jan 1, 2023
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 5, 2023
7.1k Jan 5, 2023
Python library for the DeepL language translation API.
The DeepL API is a language translation API that allows other computer programs to send texts and documents to DeepL's servers and receive high-quality translations. This opens a whole universe of opportunities for developers: any translation product you can imagine can now be built on top of DeepL's best-in-class translation technology.
 535 Jan 4, 2023
535 Jan 4, 2023
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023

Using a raspberry pi, we listen to the coffee machine and count the number of coffee consumption
A typical datarootsian consumes high-quality fresh coffee in their office environment. The board of dataroots had a very critical decision by the end of 2021-Q2 regarding coffee consumption.
 51 Nov 21, 2022
51 Nov 21, 2022
This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab.
Speech-Backbones This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab. Grad-TTS Official implementation of the Grad-
 295 Jan 7, 2023
295 Jan 7, 2023
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022

Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions
Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions To learn more about this project: medium blog post The goal of this proje
 60 Dec 17, 2022
60 Dec 17, 2022

A Survey of Natural Language Generation in Task-Oriented Dialogue System (TOD): Recent Advances and New Frontiers
A Survey of Natural Language Generation in Task-Oriented Dialogue System (TOD): Recent Advances and New Frontiers
 132 Nov 25, 2022
132 Nov 25, 2022

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022

Empower Sequence Labeling with Task-Aware Language Model
LM-LSTM-CRF Check Our New NER Toolkit 🚀 🚀 🚀 Inference: LightNER: inference w. models pre-trained / trained w. any following tools, efficiently. Tra
 838 Jan 5, 2023
838 Jan 5, 2023

PyTorch implementation of Advantage Actor Critic (A2C), Proximal Policy Optimization (PPO), Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation (ACKTR) and Generative Adversarial Imitation Learning (GAIL).
pytorch-a2c-ppo-acktr Update (April 12th, 2021) PPO is great, but Soft Actor Critic can be better for many continuous control tasks. Please check out
 3k Jan 9, 2023
3k Jan 9, 2023

An almost fully customizable language made in python!
Whython is a project language, the idea of it is that anyone can download and edit the language to make it suitable to what they want.
 47 Nov 5, 2022
47 Nov 5, 2022
DEMix Layers for Modular Language Modeling
DEMix This repository contains modeling utilities for "DEMix Layers: Disentangling Domains for Modular Language Modeling" (Gururangan et. al, 2021). T
 43 Nov 11, 2022
43 Nov 11, 2022
Evaluation suite for large-scale language models.
This repo contains code for running the evaluations and reproducing the results from the Jurassic-1 Technical Paper (see blog post), with current support for running the tasks through both the AI21 Studio API and OpenAI's GPT3 API.
 71 Dec 17, 2022
71 Dec 17, 2022

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 5, 2023
247 Jan 5, 2023

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

Composed Image Retrieval using Pretrained LANguage Transformers (CIRPLANT)
CIRPLANT This repository contains the code and pre-trained models for Composed Image Retrieval using Pretrained LANguage Transformers (CIRPLANT) For d
 29 Nov 17, 2022
29 Nov 17, 2022

Guesslang detects the programming language of a given source code
Detect the programming language of a source code
 618 Dec 29, 2022
618 Dec 29, 2022

Data Preparation, Processing, and Visualization for MoVi Data
MoVi-Toolbox Data Preparation, Processing, and Visualization for MoVi Data, https://www.biomotionlab.ca/movi/ MoVi is a large multipurpose dataset of
 51 Nov 27, 2022
51 Nov 27, 2022
The official code for paper "R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Modeling".
R2D2 This is the official code for paper titled "R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Mode
 49 Dec 17, 2022
49 Dec 17, 2022

Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision. ICCV 2021.
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision Download links and PyTorch implementation of "Towers of Ba
 40 Dec 14, 2022
40 Dec 14, 2022
Library for processing molecules and reactions in python way
Chython [ˈkʌɪθ(ə)n] Library for processing molecules and reactions in python way. Features: Read/write/convert formats: MDL .RDF (.RXN) and .SDF (.MOL
 16 Dec 1, 2022
16 Dec 1, 2022

3D position tracking for soccer players with multi-camera videos
This repo contains a full pipeline to support 3D position tracking of soccer players, with multi-view calibrated moving/fixed video sequences as inputs.
 72 Dec 27, 2022
72 Dec 27, 2022
Vision-Language Transformer and Query Generation for Referring Segmentation (ICCV 2021)
Vision-Language Transformer and Query Generation for Referring Segmentation Please consider citing our paper in your publications if the project helps
 143 Dec 23, 2022
143 Dec 23, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022
😇A pyTorch implementation of the DeepMoji model: state-of-the-art deep learning model for analyzing sentiment, emotion, sarcasm etc
------ Update September 2018 ------ It's been a year since TorchMoji and DeepMoji were released. We're trying to understand how it's being used such t
 865 Dec 24, 2022
865 Dec 24, 2022
Ongoing research training transformer language models at scale, including: BERT & GPT-2
What is this fork of Megatron-LM and Megatron-DeepSpeed This is a detached fork of https://github.com/microsoft/Megatron-DeepSpeed, which in itself is
 316 Jan 3, 2023
316 Jan 3, 2023
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023

A complete NLP guideline for enthusiasts
NLP-NINJA A complete guide for Natural Language Processing in Python Table of Contents S.No. Topic Level Meaning 1 Tokenization 🤍 Beginner 2 Stemming
 22 Dec 27, 2022
22 Dec 27, 2022
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
65 Sep 13, 2022
PyTorch implementation for Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuous Sign Language Recognition.
Stochastic CSLR This is the PyTorch implementation for the ECCV 2020 paper: Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuou
 28 Dec 19, 2022
28 Dec 19, 2022
Source code for "Progressive Transformers for End-to-End Sign Language Production" (ECCV 2020)
Progressive Transformers for End-to-End Sign Language Production Source code for "Progressive Transformers for End-to-End Sign Language Production" (B
 58 Dec 21, 2022
58 Dec 21, 2022
Sign Language Translation with Transformers (COLING'2020, ECCV'20 SLRTP Workshop)
transformer-slt This repository gathers data and code supporting the experiments in the paper Better Sign Language Translation with STMC-Transformer.
 107 Dec 27, 2022
107 Dec 27, 2022
Sign Language Transformers (CVPR'20)
Sign Language Transformers (CVPR'20) This repo contains the training and evaluation code for the paper Sign Language Transformers: Sign Language Trans
 164 Dec 30, 2022
164 Dec 30, 2022

Pre-Trained Image Processing Transformer (IPT)
Pre-Trained Image Processing Transformer (IPT) By Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Cha
332 Dec 18, 2022
Code for the paper "VisualBERT: A Simple and Performant Baseline for Vision and Language"
This repository contains code for the following two papers: VisualBERT: A Simple and Performant Baseline for Vision and Language (arxiv) with a short
 463 Dec 9, 2022
463 Dec 9, 2022
Multi Task Vision and Language
12-in-1: Multi-Task Vision and Language Representation Learning Please cite the following if you use this code. Code and pre-trained models for 12-in-
 712 Dec 19, 2022
712 Dec 19, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023

VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
VisualGPT Our Paper VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning Main Architecture of Our VisualGPT Downloa
 140 Dec 28, 2022
140 Dec 28, 2022

The RWKV Language Model
RWKV-LM We propose the RWKV language model, with alternating time-mix and channel-mix layers: The R, K, V are generated by linear transforms of input,
 877 Jan 5, 2023
877 Jan 5, 2023
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023

FairyTailor: Multimodal Generative Framework for Storytelling
FairyTailor: Multimodal Generative Framework for Storytelling
 172 Dec 30, 2022
172 Dec 30, 2022
Code for ACL 21: Generating Query Focused Summaries from Query-Free Resources
marge This repository releases the code for Generating Query Focused Summaries from Query-Free Resources. Please cite the following paper [bib] if you
 28 Nov 10, 2022
28 Nov 10, 2022

Sum-Product Probabilistic Language
Sum-Product Probabilistic Language SPPL is a probabilistic programming language that delivers exact solutions to a broad range of probabilistic infere
 57 Nov 17, 2022
57 Nov 17, 2022
This repository contains the code for "Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based Bias in NLP".
Self-Diagnosis and Self-Debiasing This repository contains the source code for Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based
 62 Dec 12, 2022
62 Dec 12, 2022

Codes for processing meeting summarization datasets AMI and ICSI.
Meeting Summarization Dataset Meeting plays an essential part in our daily life, which allows us to share information and collaborate with others. Wit
 39 Dec 14, 2022
39 Dec 14, 2022

esguard provides a Python decorator that waits for processing while monitoring the load of Elasticsearch.
esguard esguard provides a Python decorator that waits for processing while monitoring the load of Elasticsearch. Quick Start You need to launch elast
 5 Dec 8, 2021
5 Dec 8, 2021

Implementation of the paper: "SinGAN: Learning a Generative Model from a Single Natural Image"
SinGAN This is an unofficial implementation of SinGAN from someone who's been sitting right next to SinGAN's creator for almost five years. Please ref
 35 Nov 10, 2022
35 Nov 10, 2022
open-information-extraction-system, build open-knowledge-graph(SPO, subject-predicate-object) by pyltp(version==3.4.0)
中文开放信息抽取系统, open-information-extraction-system, build open-knowledge-graph(SPO, subject-predicate-object) by pyltp(version==3.4.0)
 7 Nov 2, 2022
7 Nov 2, 2022
Code for "Finetuning Pretrained Transformers into Variational Autoencoders"
transformers-into-vaes Code for Finetuning Pretrained Transformers into Variational Autoencoders (our submission to NLP Insights Workshop 2021). Gathe
 22 Nov 26, 2022
22 Nov 26, 2022
Machine learning models from Singapore's NLP research community
SG-NLP Machine learning models from Singapore's natural language processing (NLP) research community. sgnlp is a Python package that allows you to eas
 21 Dec 17, 2022
21 Dec 17, 2022