2753 Repositories
Python Real-time-sign-language-recognition Libraries
Pyccel stands for Python extension language using accelerators.
Pyccel stands for Python extension language using accelerators.
 242 Jan 2, 2023
242 Jan 2, 2023
Merlion: A Machine Learning Framework for Time Series Intelligence
Merlion is a Python library for time series intelligence. It provides an end-to-end machine learning framework that includes loading and transforming data, building and training models, post-processing model outputs, and evaluating model performance. I
 2.8k Jan 5, 2023
2.8k Jan 5, 2023

Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation, available for both PyTorch and Tensorflow.
 730 Jan 9, 2023
730 Jan 9, 2023

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Discretized Integrated Gradients for Explaining Language Models (EMNLP 2021)
Discretized Integrated Gradients for Explaining Language Models (EMNLP 2021) Overview of paths used in DIG and IG. w is the word being attributed. The
 17 Oct 27, 2022
17 Oct 27, 2022
The GitHub repository for the paper: “Time Series is a Special Sequence: Forecasting with Sample Convolution and Interaction“.
SCINet This is the original PyTorch implementation of the following work: Time Series is a Special Sequence: Forecasting with Sample Convolution and I
 386 Jan 1, 2023
386 Jan 1, 2023

Labelling platform for text using distant supervision
With DataQA, you can label unstructured text documents using rule-based distant supervision.
 245 Aug 5, 2022
245 Aug 5, 2022
text-to-speach bot - You really do NOT have time for read a newsletter? Now you can listen to it
NewsletterReader You really do NOT have time for read a newsletter? Now you can listen to it The Newsletter of Filipe Deschamps is a great place to re
 8 Sep 18, 2021
8 Sep 18, 2021
A Tensorflow based library for Time Series Modelling with Gaussian Processes
Markovflow Documentation | Tutorials | API reference | Slack What does Markovflow do? Markovflow is a Python library for time-series analysis via prob
 24 Dec 12, 2022
24 Dec 12, 2022
Tevatron is a simple and efficient toolkit for training and running dense retrievers with deep language models.
Tevatron Tevatron is a simple and efficient toolkit for training and running dense retrievers with deep language models. The toolkit has a modularized
 193 Jan 4, 2023
193 Jan 4, 2023
Simple embedding based text classifier inspired by fastText, implemented in tensorflow
FastText in Tensorflow This project is based on the ideas in Facebook's FastText but implemented in Tensorflow. However, it is not an exact replica of
 306 Dec 2, 2022
306 Dec 2, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 4, 2023
7.1k Jan 4, 2023

Neural Style and MSG-Net
PyTorch-Style-Transfer This repo provides PyTorch Implementation of MSG-Net (ours) and Neural Style (Gatys et al. CVPR 2016), which has been included
 904 Dec 21, 2022
904 Dec 21, 2022

A PyTorch implementation of Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks
SVHNClassifier-PyTorch A PyTorch implementation of Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks If
 182 Jan 3, 2023
182 Jan 3, 2023
Speech Recognition using DeepSpeech2.
deepspeech.pytorch Implementation of DeepSpeech2 for PyTorch using PyTorch Lightning. The repo supports training/testing and inference using the DeepS
 2k Jan 4, 2023
2k Jan 4, 2023

A PyTorch Implementation of Single Shot MultiBox Detector
SSD: Single Shot MultiBox Object Detector, in PyTorch A PyTorch implementation of Single Shot MultiBox Detector from the 2016 paper by Wei Liu, Dragom
 4.8k Jan 7, 2023
4.8k Jan 7, 2023

Time Delayed NN implemented in pytorch
Pytorch Time Delayed NN Time Delayed NN implemented in PyTorch. Usage kernels = [(1, 25), (2, 50), (3, 75), (4, 100), (5, 125), (6, 150)] tdnn = TDNN
 79 Aug 4, 2022
79 Aug 4, 2022
PICARD - Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models
This is the official implementation of the following paper: Torsten Scholak, Nathan Schucher, Dzmitry Bahdanau. PICARD - Parsing Incrementally for Con
 217 Jan 1, 2023
217 Jan 1, 2023
A Domain Specific Language (DSL) for building language patterns. These can be later compiled into spaCy patterns, pure regex, or any other format
RITA DSL This is a language, loosely based on language Apache UIMA RUTA, focused on writing manual language rules, which compiles into either spaCy co
 60 Sep 26, 2022
60 Sep 26, 2022
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.9k Dec 31, 2022
2.9k Dec 31, 2022
A Multilingual Latent Dirichlet Allocation (LDA) Pipeline with Stop Words Removal, n-gram features, and Inverse Stemming, in Python.
Multilingual Latent Dirichlet Allocation (LDA) Pipeline This project is for text clustering using the Latent Dirichlet Allocation (LDA) algorithm. It
 74 Oct 7, 2022
74 Oct 7, 2022
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022

The tool to make NLP datasets ready to use
chazutsu photo from Kaikado, traditional Japanese chazutsu maker chazutsu is the dataset downloader for NLP. import chazutsu r = chazutsu.data
 243 Dec 29, 2022
243 Dec 29, 2022

TextAttack 🐙 is a Python framework for adversarial attacks, data augmentation, and model training in NLP
TextAttack 🐙 Generating adversarial examples for NLP models [TextAttack Documentation on ReadTheDocs] About • Setup • Usage • Design About TextAttack
 2.2k Jan 3, 2023
2.2k Jan 3, 2023
Unofficial Pytorch Lightning implementation of Contrastive Syn-to-Real Generalization (ICLR, 2021)
Unofficial Pytorch Lightning implementation of Contrastive Syn-to-Real Generalization (ICLR, 2021)
 17 Sep 23, 2021
17 Sep 23, 2021
A facial recognition doorbell system using a Raspberry Pi
Facial Recognition Doorbell This project expands on the person-detecting doorbell system to allow it to identify faces, and announce names accordingly
 22 Apr 15, 2022
22 Apr 15, 2022

EMNLP'2021: Can Language Models be Biomedical Knowledge Bases?
BioLAMA BioLAMA is biomedical factual knowledge triples for probing biomedical LMs. The triples are collected and pre-processed from three sources: CT
 41 Nov 18, 2022
41 Nov 18, 2022
This repo in the implementation of EMNLP'21 paper "SPARQLing Database Queries from Intermediate Question Decompositions" by Irina Saparina, Anton Osokin
SPARQLing Database Queries from Intermediate Question Decompositions This repo is the implementation of the following paper: SPARQLing Database Querie
 20 Dec 19, 2022
20 Dec 19, 2022
Incorporating KenLM language model with HuggingFace implementation of Wav2Vec2CTC Model using beam search decoding
Wav2Vec2CTC With KenLM Using KenLM ARPA language model with beam search to decode audio files and show the most probable transcription. Assuming you'v
 65 Sep 21, 2022
65 Sep 21, 2022
This project converts your human voice input to its text transcript and to an automated voice too.
Human Voice to Automated Voice & Text Introduction: In this project, whenever you'll speak, it will turn your voice into a robot voice and furthermore
 3 Oct 15, 2021
3 Oct 15, 2021
The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models
Graformer The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models Graformer (also named BridgeTransformer in t
 22 Dec 14, 2022
22 Dec 14, 2022
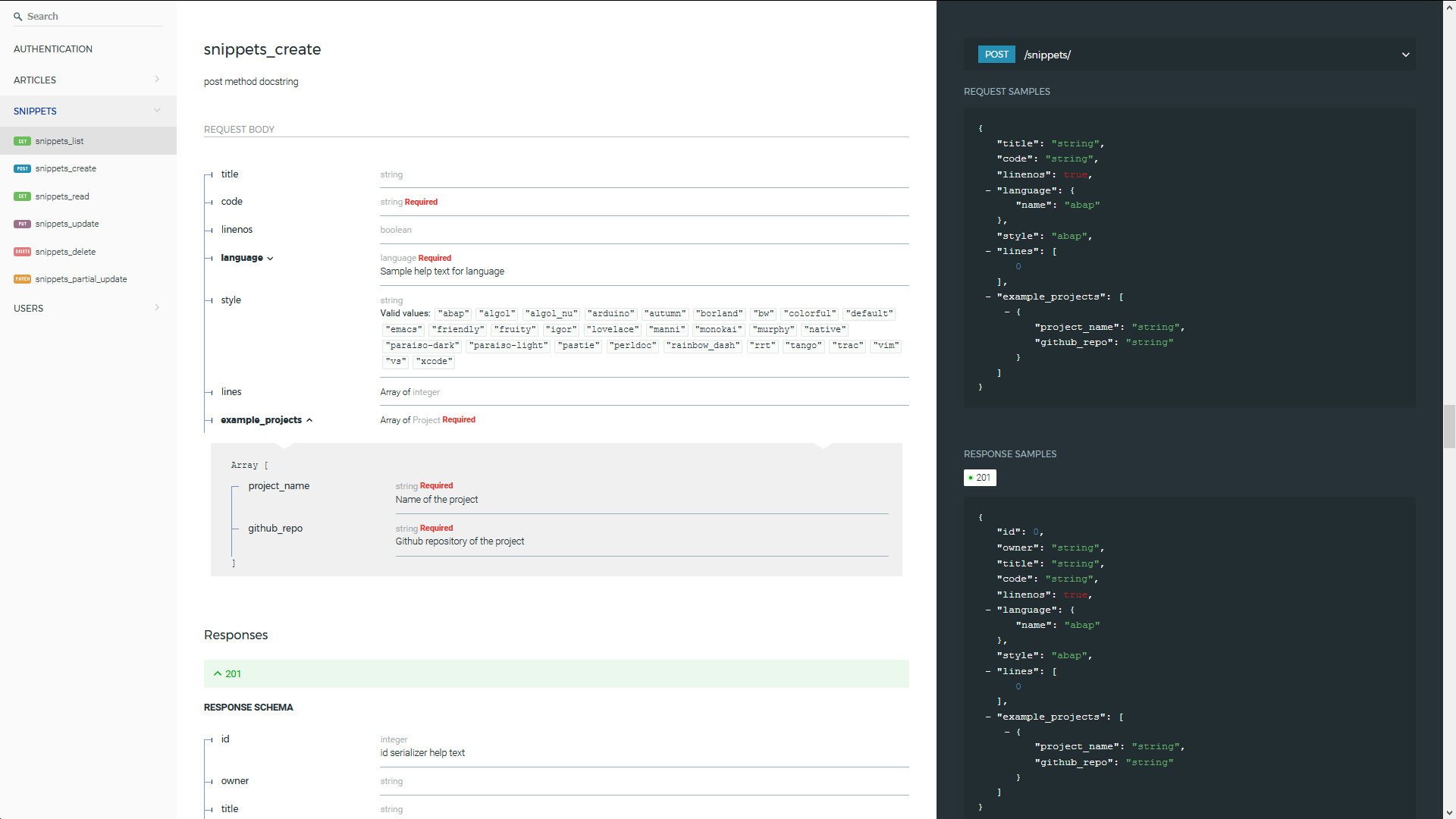
Automated generation of real Swagger/OpenAPI 2.0 schemas from Django REST Framework code.
drf-yasg - Yet another Swagger generator Generate real Swagger/OpenAPI 2.0 specifications from a Django Rest Framework API. Compatible with Django Res
 3k Dec 31, 2022
3k Dec 31, 2022
![[ICCV 2021] FaPN: Feature-aligned Pyramid Network for Dense Image Prediction](https://github.com/ShihuaHuang95/FaPN-full/raw/main/assert/fpn_vs_fapn.png)
[ICCV 2021] FaPN: Feature-aligned Pyramid Network for Dense Image Prediction
FaPN: Feature-aligned Pyramid Network for Dense Image Prediction [arXiv] [Project Page] @inproceedings{ huang2021fapn, title={{FaPN}: Feature-alig
 23 Jul 22, 2022
23 Jul 22, 2022
Natural Language Processing with transformers
we want to create a repo to illustrate usage of transformers in chinese
 763 Dec 27, 2022
763 Dec 27, 2022

A collection of SOTA Image Classification Models in PyTorch
A collection of SOTA Image Classification Models in PyTorch
 85 Dec 30, 2022
85 Dec 30, 2022
Django package to log request values such as device, IP address, user CPU time, system CPU time, No of queries, SQL time, no of cache calls, missing, setting data cache calls for a particular URL with a basic UI.
django-web-profiler's documentation: Introduction: django-web-profiler is a django profiling tool which logs, stores debug toolbar statistics and also
 77 Oct 29, 2022
77 Oct 29, 2022

Search Git commits in natural language
NaLCoS - NAtural Language COmmit Search Search commit messages in your repository in natural language. NaLCoS (NAtural Language COmmit Search) is a co
 50 Mar 22, 2022
50 Mar 22, 2022
Analyzes crypto candles over a set time period and then trades based on winning patterns found
patternstrade Analyzes crypto candles over a set time period and then trades based on winning patterns found. Heavily customizable. Warning: This was
 14 May 29, 2022
14 May 29, 2022

Abstractive opinion summarization system (SelSum) and the largest dataset of Amazon product summaries (AmaSum). EMNLP 2021 conference paper.
Learning Opinion Summarizers by Selecting Informative Reviews This repository contains the codebase and the dataset for the corresponding EMNLP 2021
 39 Jan 1, 2023
39 Jan 1, 2023
A minimalistic wrapper around PyOpenGL to save development time
glpy glpy is pyOpenGl wrapper which lets you work with pyOpenGl easily.It is not meant to be a replacement for pyOpenGl but runs on top of pyOpenGl to
 9 Apr 2, 2022
9 Apr 2, 2022
IndoBERTweet is the first large-scale pretrained model for Indonesian Twitter. Published at EMNLP 2021 (main conference)
IndoBERTweet 🐦 🇮🇩 1. Paper Fajri Koto, Jey Han Lau, and Timothy Baldwin. IndoBERTweet: A Pretrained Language Model for Indonesian Twitter with Effe
 40 Nov 30, 2022
40 Nov 30, 2022
![[EMNLP 2021] LM-Critic: Language Models for Unsupervised Grammatical Error Correction](https://github.com/michiyasunaga/LM-Critic/raw/main/figs/local_optimality.png)
[EMNLP 2021] LM-Critic: Language Models for Unsupervised Grammatical Error Correction
LM-Critic: Language Models for Unsupervised Grammatical Error Correction This repo provides the source code & data of our paper: LM-Critic: Language M
 98 Nov 24, 2022
98 Nov 24, 2022
Code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition"
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
Code for the paper "Flexible Generation of Natural Language Deductions"
Code for the paper "Flexible Generation of Natural Language Deductions"
 12 Nov 11, 2022
12 Nov 11, 2022
Code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
This repository contains the code for the paper in Findings of EMNLP 2021: "EfficientBERT: Progressively Searching Multilayer Perceptron via Warm-up Knowledge Distillation".
 28 Nov 10, 2022
28 Nov 10, 2022
OnTime is a small python that you set a time and on that time, app will send you notification and also play an alarm.
OnTime Always be OnTime! What is OnTime? OnTime is a small python that you set a time and on that time, app will send you notification and also play a
 11 Jan 16, 2022
11 Jan 16, 2022

Mathics is a general-purpose computer algebra system (CAS). It is an open-source alternative to Mathematica
Mathics is a general-purpose computer algebra system (CAS). It is an open-source alternative to Mathematica. It is free both as in "free beer" and as in "freedom".
 535 Jan 4, 2023
535 Jan 4, 2023
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 341 Dec 29, 2022
341 Dec 29, 2022
Must-read papers on improving efficiency for pre-trained language models.
Must-read papers on improving efficiency for pre-trained language models.
 89 Jan 3, 2023
89 Jan 3, 2023
Shape Matching of Real 3D Object Data to Synthetic 3D CADs (3DV project @ ETHZ)
Real2CAD-3DV Shape Matching of Real 3D Object Data to Synthetic 3D CADs (3DV project @ ETHZ) Group Member: Yue Pan, Yuanwen Yue, Bingxin Ke, Yujie He
 24 Jun 22, 2022
24 Jun 22, 2022
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022
Learn how to responsibly deliver value with ML.
Made With ML Applied ML · MLOps · Production Join 30K+ developers in learning how to responsibly deliver value with ML. 🔥 Among the top MLOps reposit
 32k Dec 30, 2022
32k Dec 30, 2022
![[ICCV2021] Official code for](https://github.com/Uason-Chen/CTR-GCN/raw/main/src/framework.jpg)
[ICCV2021] Official code for "Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition"
CTR-GCN This repo is the official implementation for Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition. The pap
 148 Dec 16, 2022
148 Dec 16, 2022
Augmenty is an augmentation library based on spaCy for augmenting texts.
Augmenty: The cherry on top of your NLP pipeline Augmenty is an augmentation library based on spaCy for augmenting texts. Besides a wide array of high
 124 Dec 29, 2022
124 Dec 29, 2022
An unofficial python API for trading on the DeGiro platform, with the ability to get real time data and historical data.
DegiroAPI An unofficial API for the trading platform Degiro written in Python with the ability to get real time data and historical data for products.
 5 Dec 16, 2022
5 Dec 16, 2022

Tool to add main subject to items on Wikidata using a WMFs CirrusSearch for named entity recognition or a manually supplied list of QIDs
ItemSubjector Tool made to add main subject statements to items based on the title using a home-brewed CirrusSearch-based Named Entity Recognition alg
 9 Nov 17, 2022
9 Nov 17, 2022
Channel Pruning for Accelerating Very Deep Neural Networks (ICCV'17)
Channel Pruning for Accelerating Very Deep Neural Networks (ICCV'17)
 1k Jan 3, 2023
1k Jan 3, 2023
Stor is a community-driven green cryptocurrency based on a proof of space and time consensus algorithm.
Stor Blockchain Stor is a community-driven green cryptocurrency based on a proof of space and time consensus algorithm. For more information, see our
 15 May 18, 2022
15 May 18, 2022

“Data Augmentation for Cross-Domain Named Entity Recognition” (EMNLP 2021)
Data Augmentation for Cross-Domain Named Entity Recognition Authors: Shuguang Chen, Gustavo Aguilar, Leonardo Neves and Thamar Solorio This repository
 18 Sep 10, 2022
18 Sep 10, 2022
Calculates carbon footprint based on fuel mix and discharge profile at the utility selected. Can create graphs and tabular output for fuel mix based on input file of series of power drawn over a period of time.
carbon-footprint-calculator Conda distribution ~/anaconda3/bin/conda install anaconda-client conda-build ~/anaconda3/bin/conda config --set anaconda_u
 7 Sep 26, 2022
7 Sep 26, 2022

Advance Image Downloader/Extractor (Job) is a Python-Flask web-based app, which will help the user download the any kind of Images at any date and time over the internet. These images will get downloaded as a job and then let user know that the images have been downloaded by sending them a link over an email.
Advance Image Downloader/Extractor(Job) Advance Image Downloader/Extractor (Job) is a Python-Flask web-based app, which will help the user download th
 13 Aug 27, 2022
13 Aug 27, 2022

This repository contains the PyTorch implementation of the paper STaCK: Sentence Ordering with Temporal Commonsense Knowledge appearing at EMNLP 2021.
STaCK: Sentence Ordering with Temporal Commonsense Knowledge This repository contains the pytorch implementation of the paper STaCK: Sentence Ordering
 23 Dec 16, 2022
23 Dec 16, 2022

Desktop music recognition application for windows
MusicRecognizer Music recognition application for windows You can choose from which of the devices the recording will be made. If you choose speakers,
 28 Dec 13, 2022
28 Dec 13, 2022
Natural language computational chemistry command line interface.
nlcc Install pip install nlcc Must have Open-AI Codex key: export OPENAI_API_KEY=your key here then nlcc key bindings ctrl-w copy to clipboard (Note
 37 Dec 14, 2022
37 Dec 14, 2022
[EMNLP 2021] Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training
RoSTER The source code used for Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training, p
 60 Dec 30, 2022
60 Dec 30, 2022

Official Pytorch implementation of Test-Agnostic Long-Tailed Recognition by Test-Time Aggregating Diverse Experts with Self-Supervision.
This repository is the official Pytorch implementation of Test-Agnostic Long-Tailed Recognition by Test-Time Aggregating Diverse Experts with Self-Supervision.
 101 Dec 30, 2022
101 Dec 30, 2022
Finds snippets in iambic pentameter in English-language text and tries to combine them to a rhyming sonnet.
Sonnet finder Finds snippets in iambic pentameter in English-language text and tries to combine them to a rhyming sonnet. Usage This is a Python scrip
 11 Sep 25, 2022
11 Sep 25, 2022
Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
Real-ESRGAN Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data Ported from https://github.com/xinntao/Real-ESRGAN Depend
 44 Dec 27, 2022
44 Dec 27, 2022

Fully reproducible, Dockerized, step-by-step, tutorial on how to mock a "real-time" Kafka data stream from a timestamped csv file. Detailed blog post published on Towards Data Science.
time-series-kafka-demo Mock stream producer for time series data using Kafka. I walk through this tutorial and others here on GitHub and on my Medium
 26 Nov 15, 2022
26 Nov 15, 2022

Asynchronous and also synchronous non-official QvaPay client for asyncio and Python language.
Asynchronous and also synchronous non-official QvaPay client for asyncio and Python language. This library is still under development, the interface could be changed.
 8 Sep 18, 2021
8 Sep 18, 2021
Simple integer-valued time series bit packing
Smahat allows to encode a sequence of integer values using a fixed (for all values) number of bits but minimal with regards to the data range. For example: for a series of boolean values only one bit is needed, for a series of integer percentages 7 bits are needed, etc.
 7 Aug 27, 2021
7 Aug 27, 2021
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
 7.6k Jan 1, 2023
7.6k Jan 1, 2023

Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition
Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition Official implementation of the Efficient Conforme
 145 Dec 30, 2022
145 Dec 30, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
PhysCap: Physically Plausible Monocular 3D Motion Capture in Real Time
PhysCap: Physically Plausible Monocular 3D Motion Capture in Real Time The implementation is based on SIGGRAPH Aisa'20. Dependencies Python 3.7 Ubuntu
 124 Dec 8, 2022
124 Dec 8, 2022
SinglepassTextCluster, an TextCluster tools based on Singlepass cluster algorithm that use tfidf vector and doc2vec,which can be used for individual real-time corpus cluster task。基于single-pass算法思想的自动文本聚类小组件,内置tfidf和doc2vec两种文本向量方法,可自动输出聚类数目、类簇文档集合和簇类大小,用于自有实时数据的聚类任务。
项目的背景 SinglepassTextCluster, an TextCluster tool based on Singlepass cluster algorithm that use tfidf vector and doc2vec,which can be used for individ
 34 Dec 18, 2022
34 Dec 18, 2022

Example of animated maps in matplotlib + geopandas using entire time series of congressional district maps from UCLA archive. rendered, interactive version below
Example of animated maps in matplotlib + geopandas using entire time series of congressional district maps from UCLA archive. rendered, interactive version below
 5 May 18, 2022
5 May 18, 2022

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022

Face Mask Detection is a project to determine whether someone is wearing mask or not, using deep neural network.
face-mask-detection Face Mask Detection is a project to determine whether someone is wearing mask or not, using deep neural network. It contains 3 scr
 13 Jan 18, 2022
13 Jan 18, 2022

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022
This is a project to detect gestures to zoom in or out, using the real-time distance between the index finger and the thumb. It's based on OpenCV and Mediapipe.
Pinch-zoom This is a python project based on real-time hand-gesture detection, to zoom in or out, using the distance between the index finger and the
 6 Jul 11, 2022
6 Jul 11, 2022

Realtime Face Anti Spoofing with Face Detector based on Deep Learning using Tensorflow/Keras and OpenCV
Realtime Face Anti-Spoofing Detection 🤖 Realtime Face Anti Spoofing Detection with Face Detector to detect real and fake faces Please star this repo
 86 Aug 3, 2022
86 Aug 3, 2022
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Bridging Vision and Language Model
BriVL BriVL (Bridging Vision and Language Model) 是首个中文通用图文多模态大规模预训练模型。BriVL模型在图文检索任务上有着优异的效果,超过了同期其他常见的多模态预训练模型(例如UNITER、CLIP)。 BriVL论文:WenLan: Bridgi
 235 Dec 27, 2022
235 Dec 27, 2022

This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on table detection and table structure recognition.
WTW-Dataset This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on ICCV 2021. Here, you can download the
 109 Dec 29, 2022
109 Dec 29, 2022
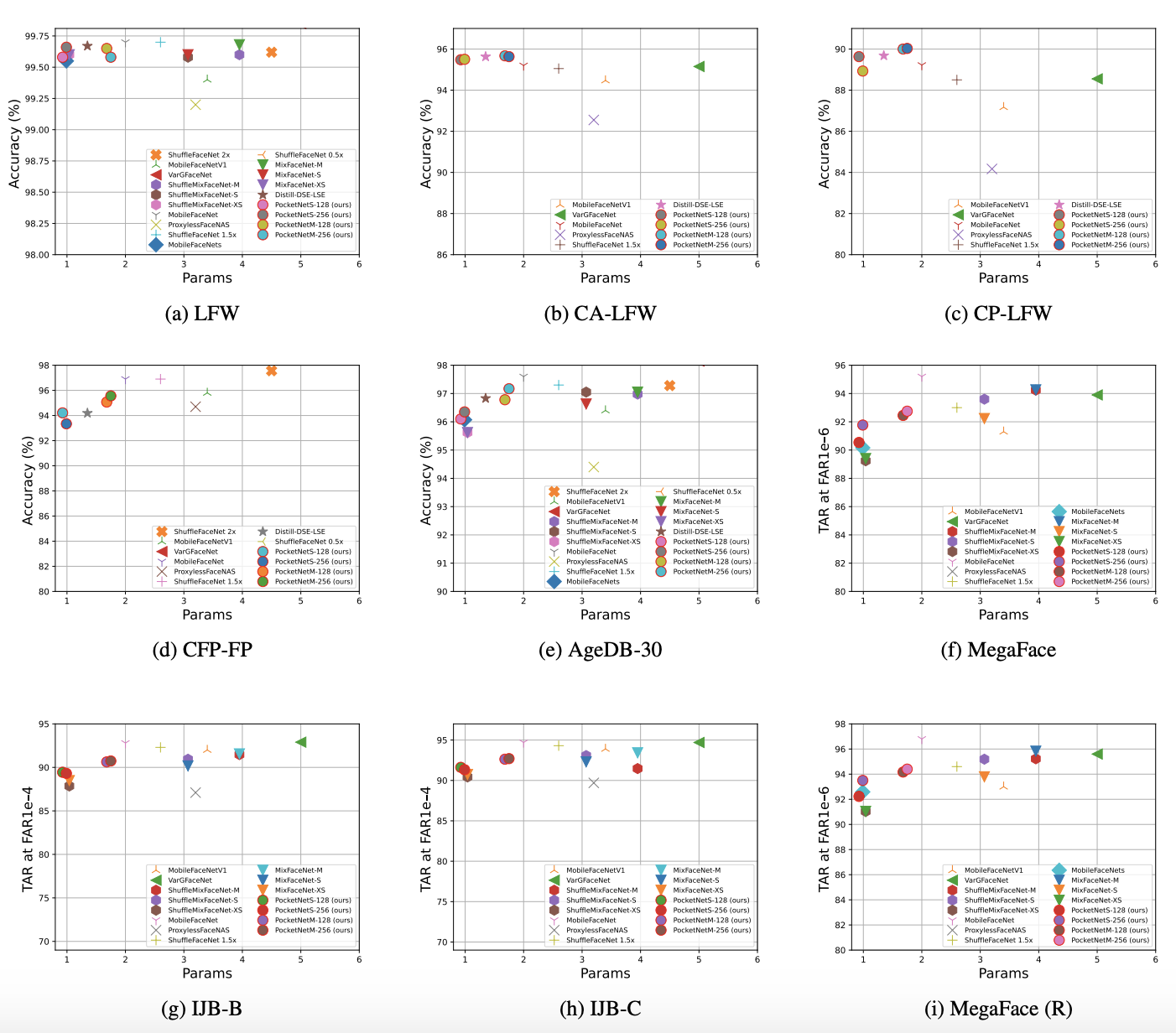
PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and Multi-Step Knowledge Distillation
PocketNet This is the official repository of the paper: PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and M
 40 Dec 22, 2022
40 Dec 22, 2022
Uses the Duke Energy Gateway to import near real time energy usage into Home Assistant
Duke Energy Gateway This is a custom integration for Home Assistant. It pulls near-real-time energy usage from Duke Energy via the Duke Energy Gateway
 28 Dec 23, 2022
28 Dec 23, 2022
tagls is a language server based on gtags.
tagls tagls is a language server based on gtags. Why I wrote it? Almost all modern editors have great support to LSP, but language servers based on se
 31 Dec 1, 2022
31 Dec 1, 2022

🎴 LearnQuick is a flashcard application that you can study with decks and cards.
🎴 LearnQuick is a flashcard application that you can study with decks and cards. The main function of the application is to show the front sides of the created cards to the user and ask them to guess the back of the card. As a result of self-assessment of user's ability to guess the back sides of the displayed cards, the cards that user weak against are shown more often, and the cards that user strong against are shown less frequently.
 7 Aug 21, 2022
7 Aug 21, 2022

Application for shadowing Chinese.
chinese-shadowing Simple APP for shadowing chinese. With this application, it is very easy to record yourself, play the sound recorded and listen to s
 5 Sep 6, 2022
5 Sep 6, 2022

MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving.
MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving. It is a comprehensive framework for research purpose that integrates popular MWP benchmark datasets and typical deep learning-based MWP algorithms.
 119 Jan 4, 2023
119 Jan 4, 2023
aws-lambda-scheduler lets you call any existing AWS Lambda Function you have in a future time.
aws-lambda-scheduler aws-lambda-scheduler lets you call any existing AWS Lambda Function you have in the future. This functionality is achieved by dyn
 57 Dec 17, 2022
57 Dec 17, 2022
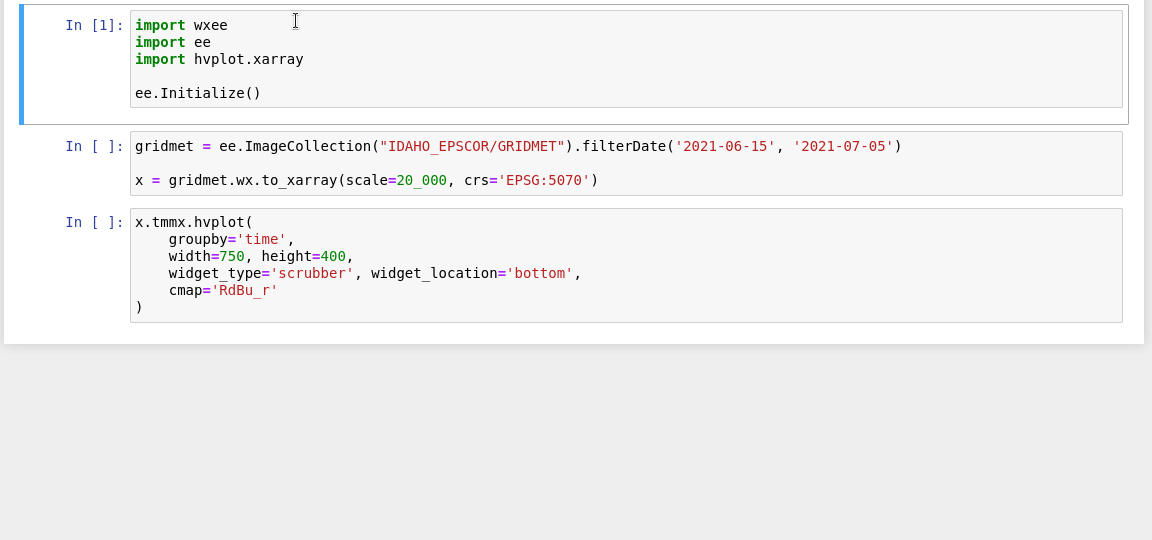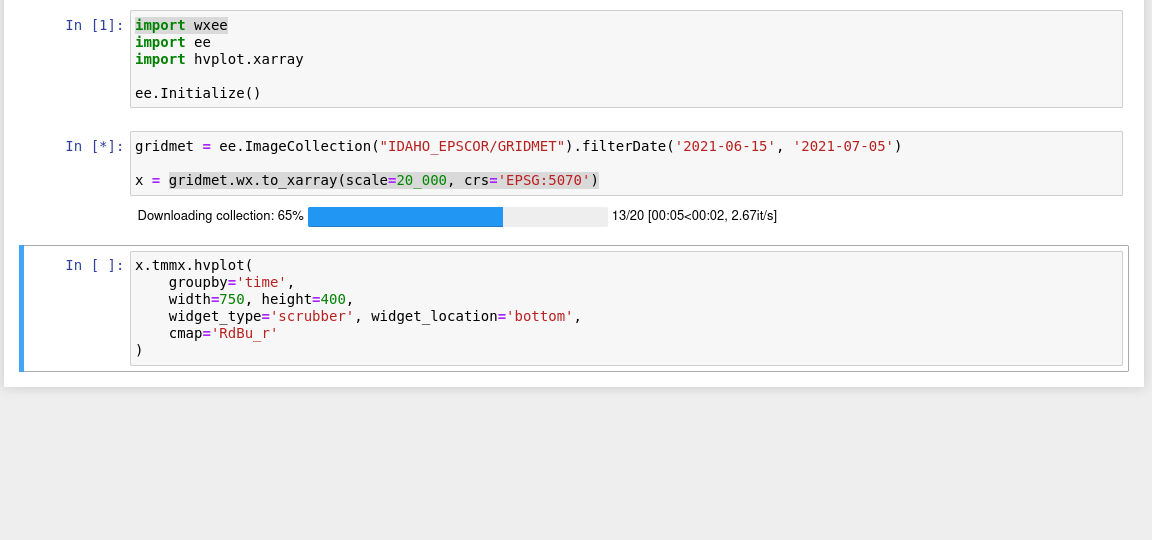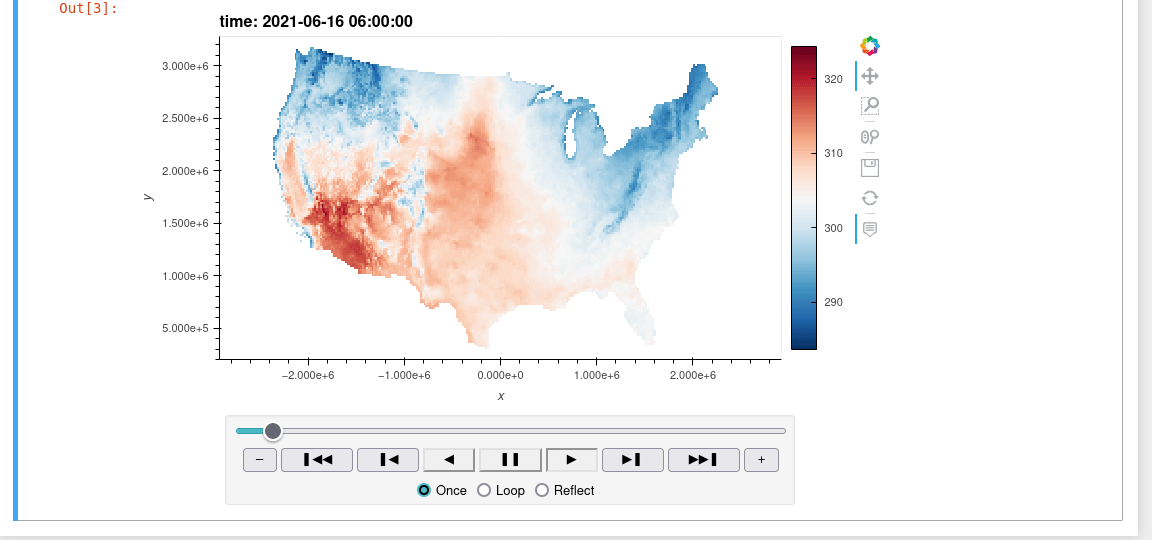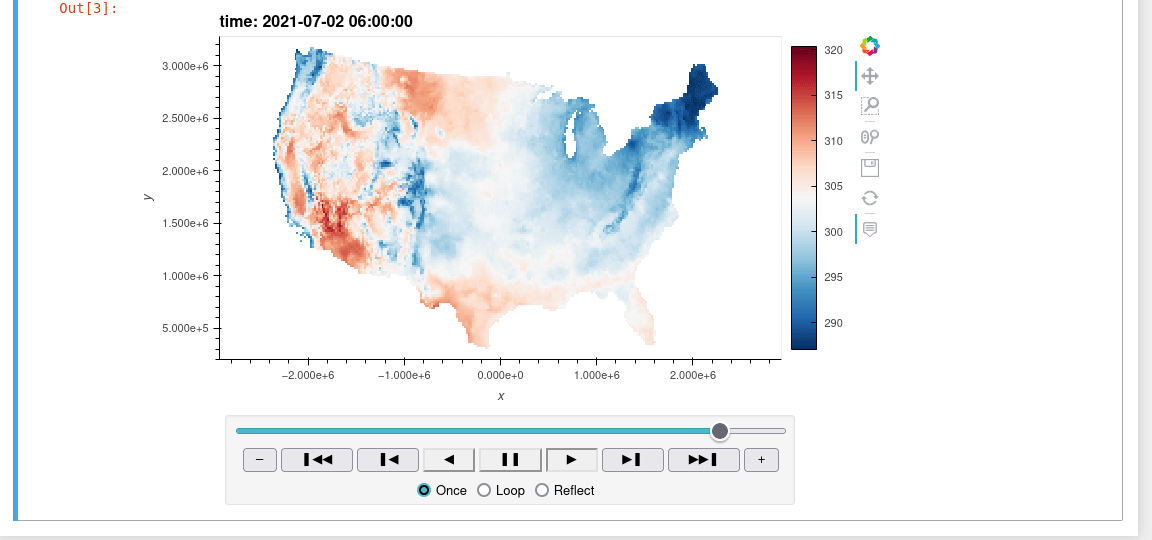
A Python interface between Earth Engine and xarray for processing weather and climate data
wxee What is wxee? wxee was built to make processing gridded, mesoscale time series weather and climate data quick and easy by integrating the data ca
 160 Dec 31, 2022
160 Dec 31, 2022

Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
 91 Nov 22, 2022
91 Nov 22, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022
ETNA is an easy-to-use time series forecasting framework.
ETNA is an easy-to-use time series forecasting framework. It includes built in toolkits for time series preprocessing, feature generation, a variety of predictive models with unified interface - from classic machine learning to SOTA neural networks, models combination methods and smart backtesting. ETNA is designed to make working with time series simple, productive, and fun.
 674 Jan 7, 2023
674 Jan 7, 2023
Cross Quality LFW: A database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Cross-Quality Labeled Faces in the Wild (XQLFW) Here, we release the database, evaluation protocol and code for the following paper: Cross Quality LFW
 10 Dec 12, 2022
10 Dec 12, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023