95 Repositories
Python apache-iceberg Libraries

Yet another Airflow plugin using CLI command as RESTful api, supports Airflow v2.X.
中文版文档 Airflow Extended API Plugin Airflow Extended API, which export airflow CLI command as REST-ful API to extend the ability of airflow official API
 106 Nov 9, 2022
106 Nov 9, 2022
Containerized Demo of Apache Spark MLlib on a Data Lakehouse (2022)
Spark-DeltaLake-Demo Reliable, Scalable Machine Learning (2022) This project was completed in an attempt to become better acquainted with the latest b
 8 Mar 21, 2022
8 Mar 21, 2022
We’re releasing an open-source tool you can use now, which we developed as a homemade Just-In-Time database access control tool for our sensitive database. This tool syncs with our directory service, slack, SIEM, and finally, our Apache Cassandra database.
Cassandra Access Control By Aner Izraeli - Intezer Security Manager ([email protected]) We’re releasing an open-source tool you can use now, which
 6 Mar 31, 2022
6 Mar 31, 2022
DAMPP (gui) is a Python based program to run simple webservers using MySQL, Php, Apache and PhpMyAdmin inside of Docker containers.
DAMPP (gui) is a Python based program to run simple webservers using MySQL, Php, Apache and PhpMyAdmin inside of Docker containers.
 1 Feb 19, 2022
1 Feb 19, 2022

Jupyter notebooks and AWS CloudFormation template to show how Hudi, Iceberg, and Delta Lake work
Modern Data Lake Storage Layers This repository contains supporting assets for my research in modern Data Lake storage layers like Apache Hudi, Apache
 25 Oct 31, 2022
25 Oct 31, 2022

PySpark Structured Streaming ROS Kafka ApacheSpark Cassandra
PySpark-Structured-Streaming-ROS-Kafka-ApacheSpark-Cassandra The purpose of this project is to demonstrate a structured streaming pipeline with Apache
 5 Nov 13, 2022
5 Nov 13, 2022
Python-geoarrow - Storing geometry data in Apache Arrow format
geoarrow Storing geometry data in Apache Arrow format Installation $ pip install
 11 Mar 3, 2022
11 Mar 3, 2022
Simple Python Script to Parse Apache Log, Get all Unique IPs and Urls visited by that IP
Parse_Apache_Log Simple Python Script to Parse Apache Log, Get all Unique IPs and Urls visited by that IP. It will create 3 different files. allIP.txt
 2 Mar 29, 2022
2 Mar 29, 2022
Event-driven-model-serving - Unified API of Apache Kafka and Google PubSub
event-driven-model-serving Unified API of Apache Kafka and Google PubSub 1. Proj
 4 Sep 23, 2022
4 Sep 23, 2022
SynapseML - an open source library to simplify the creation of scalable machine learning pipelines
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
A Time Series Library for Apache Spark
Flint: A Time Series Library for Apache Spark The ability to analyze time series data at scale is critical for the success of finance and IoT applicat
 970 Jan 4, 2023
970 Jan 4, 2023
Apache Spark & Python (pySpark) tutorials for Big Data Analysis and Machine Learning as IPython / Jupyter notebooks
Spark Python Notebooks This is a collection of IPython notebook/Jupyter notebooks intended to train the reader on different Apache Spark concepts, fro
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

BigDL - Evaluate the performance of BigDL (Distributed Deep Learning on Apache Spark) in big data analysis problems
Evaluate the performance of BigDL (Distributed Deep Learning on Apache Spark) in big data analysis problems.
 1 Jan 6, 2022
1 Jan 6, 2022

Powering up Apache JMeter with Streamlit and opening the door for machine learning.
Powering up Apache JMeter with Streamlit Overview Apache JMeter is an open source load testing tool written in 100% pure Java. JMeter supports umpteen
 16 Aug 24, 2022
16 Aug 24, 2022

Stream-Kafka-ELK-Stack - Weather data streaming using Apache Kafka and Elastic Stack.
Streaming Data Pipeline - Kafka + ELK Stack Streaming weather data using Apache Kafka and Elastic Stack. Data source: https://openweathermap.org/api O
 2 Jan 20, 2022
2 Jan 20, 2022

Use Jupyter Notebooks to demonstrate how to build a Recommender with Apache Spark & Elasticsearch
Recommendation engines are one of the most well known, widely used and highest value use cases for applying machine learning. Despite this, while there are many resources available for the basics of training a recommendation model, there are relatively few that explain how to actually deploy these models to create a large-scale recommender system.
 793 Dec 18, 2022
793 Dec 18, 2022

This mini project showcase how to build and debug Apache Spark application using Python
Spark app can't be debugged using normal procedure. This mini project showcase how to build and debug Apache Spark application using Python programming language. There are also options to run Spark application on Spark container
 1 Dec 29, 2021
1 Dec 29, 2021
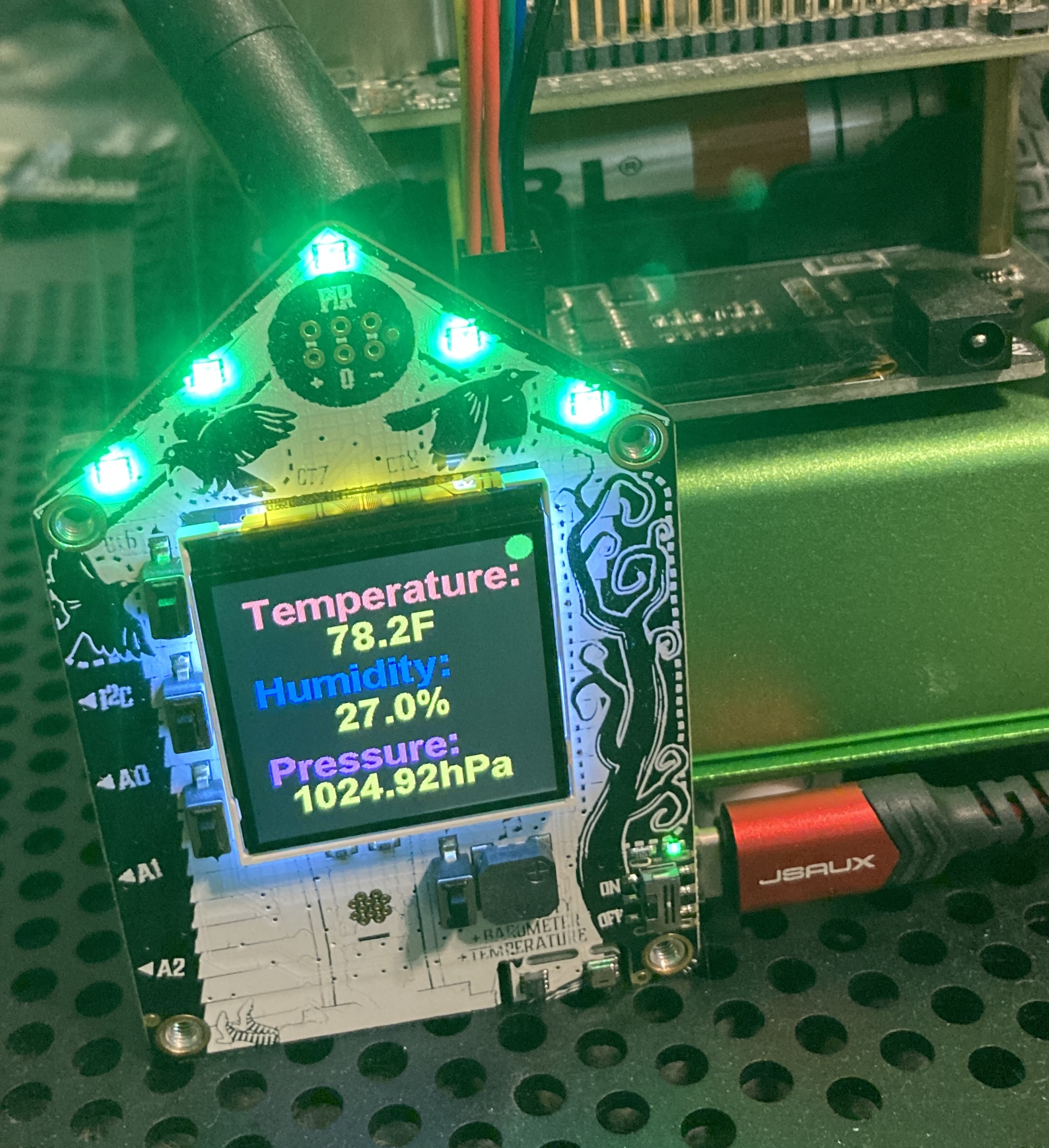
AdaFruit Funhouse publishing Temperature, Humidity and Pressure to MQTT / Apache Pulsar
pulsar-adafruit-funhouse AdaFruit Funhouse publishing Temperature, Humidity and Pressure to MQTT / Apache Pulsar Device Get your own from adafruit Ada
 1 Dec 30, 2021
1 Dec 30, 2021
A script to search, scrape and scan for Apache Log4j CVE-2021-44228 affected files using Google dorks
Log4j dork scanner This is an auto script to search, scrape and scan for Apache Log4j CVE-2021-44228 affected files using Google dorks. Installation:
 5 Dec 27, 2022
5 Dec 27, 2022

Library extending Jupyter notebooks to integrate with Apache TinkerPop and RDF SPARQL.
Graph Notebook: easily query and visualize graphs The graph notebook provides an easy way to interact with graph databases using Jupyter notebooks. Us
 501 Dec 28, 2022
501 Dec 28, 2022
Provides script to download and format public IP lists related to the Log4j exploit.
Provides script to download and format public IP lists related to the Log4j exploit. Current format includes: plain list, Cisco ASA Network Group.
 1 Jan 2, 2022
1 Jan 2, 2022

Travis CI testing a Dockerfile based on Palantir's remix of Apache Cassandra, testing IaC, and testing integration health of Debian
Testing Palantir's remix of Apache Cassandra with Snyk & Travis CI This repository is to show Travis CI testing a Dockerfile based on Palantir's remix
 1 Dec 20, 2021
1 Dec 20, 2021
Log4j minecraft with python
Apache-Log4j Apache Log4j 远程代码执行 攻击者可直接构造恶意请求,触发远程代码执行漏洞。漏洞利用无需特殊配置,经阿里云安全团队验证,Apache Struts2、Apache Solr、Apache Druid、Apache Flink等均受影响 Steps 【Import
 57 Oct 3, 2022
57 Oct 3, 2022
Apache (Py)Spark type annotations (stub files).
PySpark Stubs A collection of the Apache Spark stub files. These files were generated by stubgen and manually edited to include accurate type hints. T
 114 Nov 22, 2022
114 Nov 22, 2022

A real-time financial data streaming pipeline and visualization platform using Apache Kafka, Cassandra, and Bokeh.
Realtime Financial Market Data Visualization and Analysis Introduction This repo shows my project about real-time stock data pipeline. All the code is
 6 Sep 7, 2022
6 Sep 7, 2022

Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Apache Airflow Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are define
 28.6k Dec 28, 2022
28.6k Dec 28, 2022

Make dbt docs and Apache Superset talk to one another
dbt-superset-lineage Make dbt docs and Apache Superset talk to one another Why do I need something like this? Odds are rather high that you use dbt to
 81 Jan 6, 2023
81 Jan 6, 2023
Keeper for Ricochet Protocol, implemented with Apache Airflow
Ricochet Keeper This repository contains Apache Airflow DAGs for executing keeper operations for Ricochet Exchange. Usage You will need to run this us
 5 May 24, 2022
5 May 24, 2022
Proof of concept to check if hosts are vulnerable to CVE-2021-41773
CVE-2021-41773 PoC Proof of concept to check if hosts are vulnerable to CVE-2021-41773. Description (https://cve.mitre.org/cgi-bin/cvename.cgi?name=CV
 43 Nov 9, 2022
43 Nov 9, 2022
E-Commerce recommender demo with real-time data and a graph database
🔍 E-Commerce recommender demo 🔍 This is a simple stream setup that uses Memgraph to ingest real-time data from a simulated online store. Data is str
 3 Feb 23, 2022
3 Feb 23, 2022
Pythonic Lucene - A simplified python impelementaiton of Apache Lucene
A simplified python impelementaiton of Apache Lucene, mabye helps to understand how an enterprise search engine really works.
 2 Sep 12, 2022
2 Sep 12, 2022
Simple and Distributed Machine Learning
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
3.9k Dec 30, 2022
Deep Learning Pipelines for Apache Spark
Deep Learning Pipelines for Apache Spark The repo only contains HorovodRunner code for local CI and API docs. To use HorovodRunner for distributed tra
 2k Jan 8, 2023
2k Jan 8, 2023
AWS Glue PySpark - Apache Hudi Quick Start Guide
AWS Glue PySpark - Apache Hudi Quick Start Guide Disclaimer: This is a quick start guide for the Apache Hudi Python Spark connector, running on AWS Gl
 8 Nov 14, 2022
8 Nov 14, 2022
Building house price data pipelines with Apache Beam and Spark on GCP
This project contains the process from building a web crawler to extract the raw data of house price to create ETL pipelines using Google Could Platform services.
 1 Nov 22, 2021
1 Nov 22, 2021
The Python agent for Apache SkyWalking
SkyWalking Python Agent SkyWalking-Python: The Python Agent for Apache SkyWalking, which provides the native tracing abilities for Python project. Sky
149 Dec 12, 2022
On the 11/11/21 the apache 2.4.49-2.4.50 remote command execution POC has been published online and this is a loader so that you can mass exploit servers using this.
ApacheRCE ApacheRCE is a small little python script that will allow you to input the apache version 2.4.49-2.4.50 and then input a list of ip addresse
 3 Dec 4, 2022
3 Dec 4, 2022
Log processor for nginx or apache that extracts user and user sessions and calculates other types of useful data for bot detection or traffic analysis
Log processor for nginx or apache that extracts user and user sessions and calculates other types of useful data for bot detection or traffic analysis
 1 Nov 11, 2021
1 Nov 11, 2021

 3 Dec 16, 2022
3 Dec 16, 2022
Fast python tool to test apache path traversal CVE-2021-41773 in a List of url
CVE-2021-41773 Fast python tool to test apache path traversal CVE-2021-41773 in a List of url Usage :- create a live urls file and use the flag "-l" p
 12 Nov 9, 2022
12 Nov 9, 2022
Apache Superset out of box version(Windows 64-bit)
superset_app Apache Superset out of box version (Windows 64bit) prepare job download 3 files python-3.8.10-embed-amd64.zip get-pip.py python_geohash‑0
 9 Oct 2, 2022
9 Oct 2, 2022
A minimal configuration for a dockerized kafka project.
Docker Kafka Quickstart A minimal configuration for a dockerized kafka project. Usage: Run this command to build kafka and zookeeper containers, and c
 5 Jan 12, 2022
5 Jan 12, 2022

It's a simple tool for test vulnerability Apache Path Traversal
SimplesApachePathTraversal Simples Apache Path Traversal It's a simple tool for test vulnerability Apache Path Traversal https://blog.mrcl0wn.com/2021
 56 Dec 27, 2022
56 Dec 27, 2022
A tutorial presents several practical examples of how to build DAGs in Apache Airflow
Apache Airflow - Python Brasil 2021 Este tutorial apresenta vários exemplos práticos de como construir DAGs no Apache Airflow. Background Apache Airfl
 14 Jun 3, 2022
14 Jun 3, 2022

Current Antarctic large iceberg positions derived from ASCAT and OSCAT-2
Iceberg Locations Antarctic large iceberg positions derived from ASCAT and OSCAT-2. All data collected here are from the NASA SCP website Overview Thi
 5 Jul 27, 2022
5 Jul 27, 2022

CVE-2021-41773 Path Traversal for Apache 2.4.49
CVE-2021-41773 Path Traversal for Apache 2.4.49
 3 Oct 20, 2021
3 Oct 20, 2021
Know your customer pipeline in apache air flow
KYC_pipline Know your customer pipeline in apache air flow For a successful pipeline run take these steps: Run you Airflow server Admin - connection
 4 Aug 1, 2022
4 Aug 1, 2022
TensorFlowOnSpark brings TensorFlow programs to Apache Spark clusters.
TensorFlowOnSpark TensorFlowOnSpark brings scalable deep learning to Apache Hadoop and Apache Spark clusters. By combining salient features from the T
 3.8k Jan 4, 2023
3.8k Jan 4, 2023

PySpark Cheat Sheet - learn PySpark and develop apps faster
This cheat sheet will help you learn PySpark and write PySpark apps faster. Everything in here is fully functional PySpark code you can run or adapt to your programs.
 168 Jan 1, 2023
168 Jan 1, 2023
Project repository of Apache Airflow, deployed on Docker in Amazon EC2 via GitLab.
Airflow on Docker in EC2 + GitLab's CI/CD Personal project for simple data pipeline using Airflow. Airflow will be installed inside Docker container,
 13 Nov 29, 2022
13 Nov 29, 2022
This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, reading data from PubSub.
Sample streaming Dataflow pipeline written in Python This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, readin
 9 Mar 18, 2022
9 Mar 18, 2022
Apache Liminal is an end-to-end platform for data engineers & scientists, allowing them to build, train and deploy machine learning models in a robust and agile way
Apache Liminals goal is to operationalise the machine learning process, allowing data scientists to quickly transition from a successful experiment to an automated pipeline of model training, validation, deployment and inference in production. Liminal provides a Domain Specific Language to build ML workflows on top of Apache Airflow.
121 Dec 28, 2022
Apache Solr SSRF(CVE-2021-27905)
Solr-SSRF Apache Solr SSRF #Use [-] Apache Solr SSRF漏洞 (CVE-2021-27905) [-] Options: -h or --help : 方法说明 -u or --url
 70 Nov 9, 2022
70 Nov 9, 2022
Apache OFBiz rmi反序列化EXP(CVE-2021-26295)
Apache OFBiz rmi反序列化EXP(CVE-2021-26295) 目前仅支持nc弹shell 将ysoserial.jar放置在同目录下,py3运行,根据提示输入漏洞url,你的vps地址和端口 第二次使用建议删除exp.ot 本工具仅用于安全测试,禁止未授权非法攻击站点,否则后果自负
 15 Nov 9, 2022
15 Nov 9, 2022
Sequence-to-sequence framework with a focus on Neural Machine Translation based on Apache MXNet
Sequence-to-sequence framework with a focus on Neural Machine Translation based on Apache MXNet
 1000 Apr 19, 2021
1000 Apr 19, 2021
geobeam - adds GIS capabilities to your Apache Beam and Dataflow pipelines.
geobeam adds GIS capabilities to your Apache Beam pipelines. What does geobeam do? geobeam enables you to ingest and analyze massive amounts of geospa
 61 Nov 8, 2022
61 Nov 8, 2022

Apache Superset is a Data Visualization and Data Exploration Platform
Apache Superset is a Data Visualization and Data Exploration Platform
49.9k Jan 2, 2023
Retrying is an Apache 2.0 licensed general-purpose retrying library, written in Python, to simplify the task of adding retry behavior to just about anything.
Retrying Retrying is an Apache 2.0 licensed general-purpose retrying library, written in Python, to simplify the task of adding retry behavior to just
 1.9k Dec 29, 2022
1.9k Dec 29, 2022

Viewflow is an Airflow-based framework that allows data scientists to create data models without writing Airflow code.
Viewflow Viewflow is a framework built on the top of Airflow that enables data scientists to create materialized views. It allows data scientists to f
 114 Oct 12, 2022
114 Oct 12, 2022
[DEPRECATED] Tensorflow wrapper for DataFrames on Apache Spark
TensorFrames (Deprecated) Note: TensorFrames is deprecated. You can use pandas UDF instead. Experimental TensorFlow binding for Scala and Apache Spark
757 Dec 31, 2022
Distributed Tensorflow, Keras and PyTorch on Apache Spark/Flink & Ray
A unified Data Analytics and AI platform for distributed TensorFlow, Keras and PyTorch on Apache Spark/Flink & Ray What is Analytics Zoo? Analytics Zo
 2.5k Dec 28, 2022
2.5k Dec 28, 2022
Microsoft Machine Learning for Apache Spark
Microsoft Machine Learning for Apache Spark MMLSpark is an ecosystem of tools aimed towards expanding the distributed computing framework Apache Spark
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
TensorFlowOnSpark brings TensorFlow programs to Apache Spark clusters.
TensorFlowOnSpark TensorFlowOnSpark brings scalable deep learning to Apache Hadoop and Apache Spark clusters. By combining salient features from the T
3.8k Jan 4, 2023
Petastorm library enables single machine or distributed training and evaluation of deep learning models from datasets in Apache Parquet format. It supports ML frameworks such as Tensorflow, Pytorch, and PySpark and can be used from pure Python code.
Petastorm Contents Petastorm Installation Generating a dataset Plain Python API Tensorflow API Pytorch API Spark Dataset Converter API Analyzing petas
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
BigDL: Distributed Deep Learning Framework for Apache Spark
BigDL: Distributed Deep Learning on Apache Spark What is BigDL? BigDL is a distributed deep learning library for Apache Spark; with BigDL, users can w
4.1k Jan 9, 2023

Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet.
Horovod Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make dis
 12.9k Jan 7, 2023
12.9k Jan 7, 2023
Objax Apache-2Objax (🥉19 · ⭐ 580) - Objax is a machine learning framework that provides an Object.. Apache-2 jax
Objax Tutorials | Install | Documentation | Philosophy This is not an officially supported Google product. Objax is an open source machine learning fr
 729 Jan 2, 2023
729 Jan 2, 2023
Apache Flink
Apache Flink Apache Flink is an open source stream processing framework with powerful stream- and batch-processing capabilities. Learn more about Flin
20.4k Dec 30, 2022
This repository lets you train neural networks models for performing end-to-end full-page handwriting recognition using the Apache MXNet deep learning frameworks on the IAM Dataset.
Handwritten Text Recognition (OCR) with MXNet Gluon These notebooks have been created by Jonathan Chung, as part of his internship as Applied Scientis
422 Jan 3, 2023

Apache Airflow - A platform to programmatically author, schedule, and monitor workflows
Apache Airflow Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are define
28.6k Jan 1, 2023
Mirror of Apache Allura
Apache Allura Allura is an open source implementation of a software "forge", a web site that manages source code repositories, bug reports, discussion
106 Dec 21, 2022
Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet.
Horovod Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make dis
12.9k Dec 29, 2022
Koalas: pandas API on Apache Spark
pandas API on Apache Spark Explore Koalas docs » Live notebook · Issues · Mailing list Help Thirsty Koalas Devastated by Recent Fires The Koalas proje
3.2k Jan 4, 2023
A pure Python implementation of Apache Spark's RDD and DStream interfaces.
pysparkling Pysparkling provides a faster, more responsive way to develop programs for PySpark. It enables code intended for Spark applications to exe
 254 Dec 6, 2022
254 Dec 6, 2022
PySpark + Scikit-learn = Sparkit-learn
Sparkit-learn PySpark + Scikit-learn = Sparkit-learn GitHub: https://github.com/lensacom/sparkit-learn About Sparkit-learn aims to provide scikit-lear
 1.1k Jan 4, 2023
1.1k Jan 4, 2023
Zulip server and webapp - powerful open source team chat
Zulip overview Zulip is a powerful, open source group chat application that combines the immediacy of real-time chat with the productivity benefits of
 17k Jan 7, 2023
17k Jan 7, 2023
Open source platform for the machine learning lifecycle
MLflow: A Machine Learning Lifecycle Platform MLflow is a platform to streamline machine learning development, including tracking experiments, packagi
 13.3k Jan 4, 2023
13.3k Jan 4, 2023
Retrying is an Apache 2.0 licensed general-purpose retrying library, written in Python, to simplify the task of adding retry behavior to just about anything.
Retrying Retrying is an Apache 2.0 licensed general-purpose retrying library, written in Python, to simplify the task of adding retry behavior to just
1.9k Dec 29, 2022
Sequence-to-sequence framework with a focus on Neural Machine Translation based on Apache MXNet
Sockeye This package contains the Sockeye project, an open-source sequence-to-sequence framework for Neural Machine Translation based on Apache MXNet
986 Feb 17, 2021
Sequence-to-sequence framework with a focus on Neural Machine Translation based on Apache MXNet
Sockeye This package contains the Sockeye project, an open-source sequence-to-sequence framework for Neural Machine Translation based on Apache MXNet
1.1k Dec 27, 2022
Apache Spark - A unified analytics engine for large-scale data processing
Apache Spark Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an op
34.7k Jan 4, 2023
Pandas on AWS - Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretManager, PostgreSQL, MySQL, SQLServer and S3 (Parquet, CSV, JSON and EXCEL).
AWS Data Wrangler Pandas on AWS Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretMana
3.3k Dec 31, 2022
Apache Libcloud is a Python library which hides differences between different cloud provider APIs and allows you to manage different cloud resources through a unified and easy to use API
Apache Libcloud - a unified interface for the cloud Apache Libcloud is a Python library which hides differences between different cloud provider APIs
1.9k Dec 25, 2022
google-cloud-bigtable Apache-2google-cloud-bigtable (🥈31 · ⭐ 3.5K) - Google Cloud Bigtable API client library. Apache-2
Python Client for Google Cloud Bigtable Google Cloud Bigtable is Google's NoSQL Big Data database service. It's the same database that powers many cor
 39 Dec 3, 2022
39 Dec 3, 2022
python-bigquery Apache-2python-bigquery (🥈34 · ⭐ 3.5K · 📈) - Google BigQuery API client library. Apache-2
Python Client for Google BigQuery Querying massive datasets can be time consuming and expensive without the right hardware and infrastructure. Google
550 Jan 1, 2023
GoAccess is a real-time web log analyzer and interactive viewer that runs in a terminal in *nix systems or through your browser.
GoAccess What is it? GoAccess is an open source real-time web log analyzer and interactive viewer that runs in a terminal on *nix systems or through y
 15.6k Jan 2, 2023
15.6k Jan 2, 2023
google-resumable-media Apache-2google-resumable-media (🥉28 · ⭐ 27) - Utilities for Google Media Downloads and Resumable.. Apache-2
google-resumable-media Utilities for Google Media Downloads and Resumable Uploads See the docs for examples and usage. Experimental asyncio Support Wh
36 Nov 22, 2022
Apache Flink 目录遍历漏洞批量检测 (CVE-2020-17519)
使用方法&免责声明 该脚本为Apache Flink 目录遍历漏洞批量检测 (CVE-2020-17519)。 使用方法:Python CVE-2020-17519.py urls.txt urls.txt 中每个url为一行,漏洞地址输出在vul.txt中 影响版本: Apache Flink 1
 45 Sep 21, 2022
45 Sep 21, 2022
Apache Superset is a Data Visualization and Data Exploration Platform
Superset A modern, enterprise-ready business intelligence web application. Why Superset? | Supported Databases | Installation and Configuration | Rele
50k Jan 6, 2023
Serverless proxy for Spark cluster
Hydrosphere Mist Hydrosphere Mist is a serverless proxy for Spark cluster. Mist provides a new functional programming framework and deployment model f
 317 Dec 1, 2022
317 Dec 1, 2022
Unified Interface for Constructing and Managing Workflows on different workflow engines, such as Argo Workflows, Tekton Pipelines, and Apache Airflow.
Couler What is Couler? Couler aims to provide a unified interface for constructing and managing workflows on different workflow engines, such as Argo
 781 Jan 3, 2023
781 Jan 3, 2023
Run Python in Apache Storm topologies. Pythonic API, CLI tooling, and a topology DSL.
Streamparse lets you run Python code against real-time streams of data via Apache Storm. With streamparse you can create Storm bolts and spouts in Pyt
 1.5k Dec 22, 2022
1.5k Dec 22, 2022
Python client for Apache Kafka
Kafka Python client Python client for the Apache Kafka distributed stream processing system. kafka-python is designed to function much like the offici
 5.1k Jan 8, 2023
5.1k Jan 8, 2023
DataStax Python Driver for Apache Cassandra
DataStax Driver for Apache Cassandra A modern, feature-rich and highly-tunable Python client library for Apache Cassandra (2.1+) and DataStax Enterpri
 1.3k Dec 25, 2022
1.3k Dec 25, 2022
Pandas on AWS - Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretManager, PostgreSQL, MySQL, SQLServer and S3 (Parquet, CSV, JSON and EXCEL).
AWS Data Wrangler Pandas on AWS Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretMana
3.3k Jan 4, 2023