379 Repositories
Python audio-compression Libraries

Text Classification in Turkish Texts with Bert
You can watch the details of the project on my youtube channel Project Interface Project Second Interface Goal= Correctly guessing the classification
 42 Dec 31, 2022
42 Dec 31, 2022

Let's you download entire YT-playlists.
Youtube MP3 Playlist Downloader Let's you download entire youtube playlists as mp3 files. This application is basically a script that makes it easier
 11 Dec 18, 2022
11 Dec 18, 2022
Official Pytorch implementation for Deep Contextual Video Compression, NeurIPS 2021
Introduction Official Pytorch implementation for Deep Contextual Video Compression, NeurIPS 2021 Prerequisites Python 3.8 and conda, get Conda CUDA 11
 51 Dec 3, 2022
51 Dec 3, 2022
A Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities
MPT A Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities. Implementation for our AAAI 2022 paper: Multi-
 4 May 8, 2022
4 May 8, 2022
Network Compression via Central Filter
Network Compression via Central Filter Environments The code has been tested in the following environments: Python 3.8 PyTorch 1.8.1 cuda 10.2 torchsu
 2 May 12, 2022
2 May 12, 2022
A PyTorch library and evaluation platform for end-to-end compression research
CompressAI CompressAI (compress-ay) is a PyTorch library and evaluation platform for end-to-end compression research. CompressAI currently provides: c
 680 Jan 6, 2023
680 Jan 6, 2023
A GUI-based audio player with support for a large variety of formats
Miza-Player A GUI-based audio player with support for a large variety of formats, able to play from web-hosted media platforms such as YouTube, includ
 3 Dec 14, 2022
3 Dec 14, 2022
A library for researching neural networks compression and acceleration methods.
A library for researching neural networks compression and acceleration methods.
 100 Dec 29, 2022
100 Dec 29, 2022
MelGAN test on audio decoding
Official repository for the paper MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis The original work URL: https://github.com
 1 Apr 29, 2022
1 Apr 29, 2022
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022

Real-Time Spherical Microphone Renderer for binaural reproduction in Python
ReTiSAR Implementation of the Real-Time Spherical Microphone Renderer for binaural reproduction in Python [1][2]. Contents: | Requirements | Setup | Q
 51 Dec 17, 2022
51 Dec 17, 2022

An Image compression simulator that uses Source Extractor and Monte Carlo methods to examine the post compressive effects different compression algorithms have.
ImageCompressionSimulation An Image compression simulator that uses Source Extractor and Monte Carlo methods to examine the post compressive effects o
 1 Dec 11, 2021
1 Dec 11, 2021
Visualizer using audio and semantic analysis to explore BigGAN (Brock et al., 2018) latent space.
BigGAN Audio Visualizer Description This visualizer explores BigGAN (Brock et al., 2018) latent space by using pitch/tempo of an audio file to generat
 2 Nov 21, 2022
2 Nov 21, 2022
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks - Official Project Page This repository contains the code develope
 1.7k Dec 18, 2022
1.7k Dec 18, 2022

Steerable discovery of neural audio effects
Steerable discovery of neural audio effects Christian J. Steinmetz and Joshua D. Reiss Abstract Applications of deep learning for audio effects often
 182 Dec 29, 2022
182 Dec 29, 2022
Code for csig audio deepfake detection
FMFCC Audio Deepfake Detection Solution This repo provides an solution for the 多媒体伪造取证大赛. Our solution achieve the 1st in the Audio Deepfake Detection
 9 Jun 4, 2022
9 Jun 4, 2022
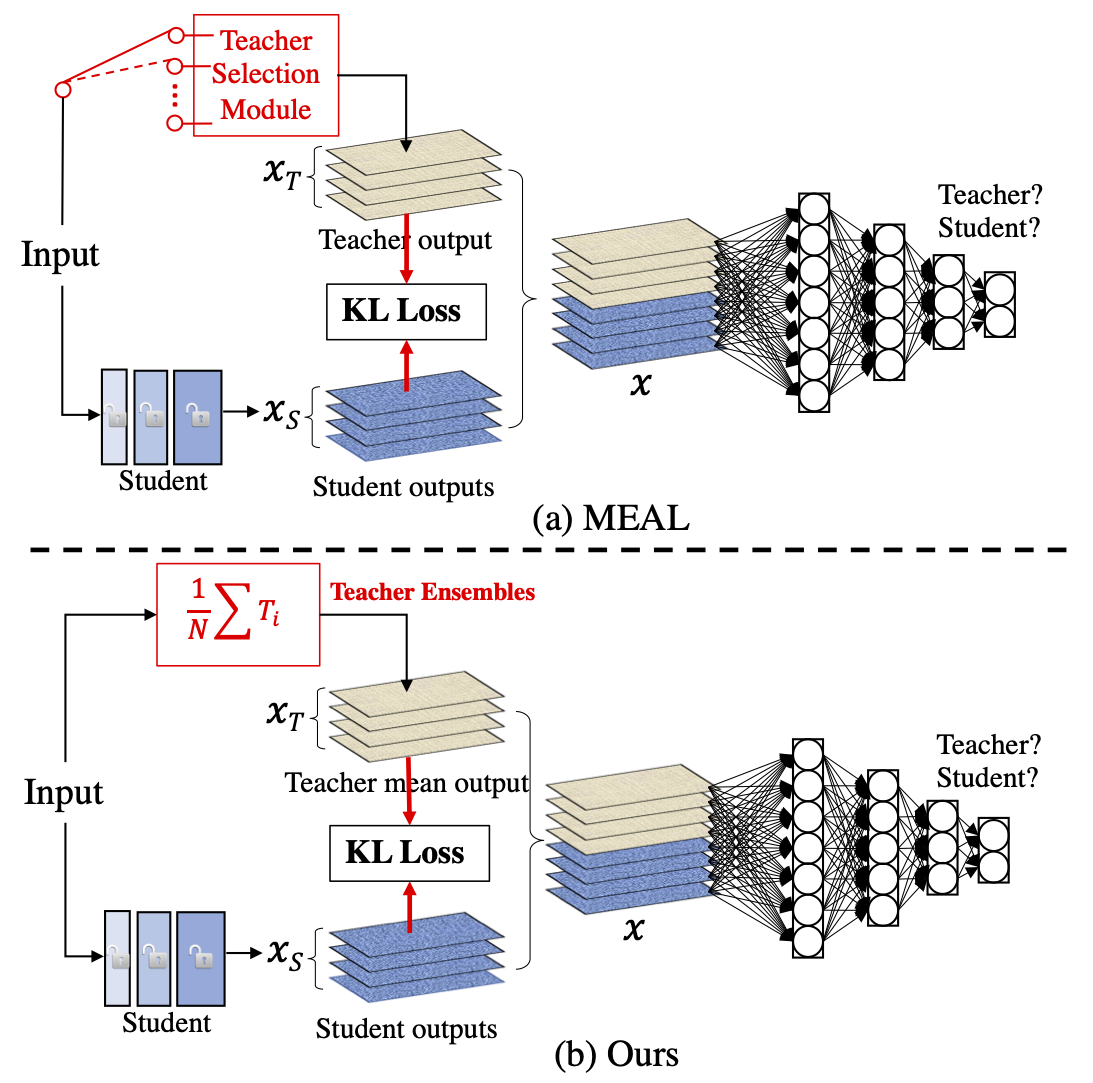
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
MEAL-V2 This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tric
 653 Dec 19, 2022
653 Dec 19, 2022
Userscript qutebrowser for downloading audio / video from youtube using aria2
Yt-Downloader Userscript qutebrowser for downloading video / audio from youtube using aria2 by hint links. Requirements Rofi youtube-dl aria2 dunst In
 0 Dec 11, 2021
0 Dec 11, 2021
[NeurIPS'21 Spotlight] PyTorch code for our paper "Aligned Structured Sparsity Learning for Efficient Image Super-Resolution"
ASSL This repository is for a new network pruning method (Aligned Structured Sparsity Learning, ASSL) for efficient single image super-resolution (SR)
 47 Nov 28, 2022
47 Nov 28, 2022

The official repository for Audio ALBERT
AALBERT Here is also the official repository of AALBERT, which is Pytorch lightning reimplementation of the paper, Audio ALBERT: A Lite Bert for Self-
 55 Dec 11, 2022
55 Dec 11, 2022

Repo for EMNLP 2021 paper "Beyond Preserved Accuracy: Evaluating Loyalty and Robustness of BERT Compression"
beyond-preserved-accuracy Repo for EMNLP 2021 paper "Beyond Preserved Accuracy: Evaluating Loyalty and Robustness of BERT Compression" How to implemen
 10 Dec 23, 2022
10 Dec 23, 2022
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization (ACL 2021)
Structured Super Lottery Tickets in BERT This repo contains our codes for the paper "Super Tickets in Pre-Trained Language Models: From Model Compress
 16 Dec 11, 2022
16 Dec 11, 2022
Pretrained language model and its related optimization techniques developed by Huawei Noah's Ark Lab.
Pretrained Language Model This repository provides the latest pretrained language models and its related optimization techniques developed by Huawei N
 2.6k Jan 1, 2023
2.6k Jan 1, 2023

Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators This is our Pytorch implementation for t
 12 Jul 22, 2022
12 Jul 22, 2022
Implementation of the algorithm shown in the article "Modelo de Predicción de Éxito de Canciones Basado en Descriptores de Audio"
Success Predictor Implementation of the algorithm shown in the article "Modelo de Predicción de Éxito de Canciones Basado en Descriptores de Audio". B
 4 Mar 17, 2022
4 Mar 17, 2022
A code implementation of AC-GC: Activation Compression with Guaranteed Convergence, in NeurIPS 2021.
Code For AC-GC: Lossy Activation Compression with Guaranteed Convergence This code is intended to be used as a supplemental material for submission to
 2 Nov 1, 2022
2 Nov 1, 2022
OpenL3: Open-source deep audio and image embeddings
OpenL3 OpenL3 is an open-source Python library for computing deep audio and image embeddings. Please refer to the documentation for detailed instructi
 326 Jan 2, 2023
326 Jan 2, 2023
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats
TG-MusicPlayer A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Py
 4 Dec 14, 2022
4 Dec 14, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022
Code for unmixing audio signals in four different stems "drums, bass, vocals, others". The code is adapted from "Jukebox: A Generative Model for Music"
Status: Archive (code is provided as-is, no updates expected) Disclaimer This code is a based on "Jukebox: A Generative Model for Music" Paper We adju
 24 Dec 29, 2022
24 Dec 29, 2022
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats.
VC UserBot A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Python
 1 Nov 29, 2021
1 Nov 29, 2021
Pytorch implementation for Patient Knowledge Distillation for BERT Model Compression
Patient Knowledge Distillation for BERT Model Compression Knowledge distillation for BERT model Installation Run command below to install the environm
 180 Dec 19, 2022
180 Dec 19, 2022

SwinIR: Image Restoration Using Swin Transformer
SwinIR: Image Restoration Using Swin Transformer This repository is the official PyTorch implementation of SwinIR: Image Restoration Using Shifted Win
 2.4k Jan 5, 2023
2.4k Jan 5, 2023
Convert Video Files To Text And Audio
Video-To-Text Convert Video Files To Text And Audio Convert To Audio 1: open dvtt folder in cmd 2: run this command in cmd = main.py Audio Convert To
 2 Dec 5, 2021
2 Dec 5, 2021

R interface to fast.ai
R interface to fastai The fastai package provides R wrappers to fastai. The fastai library simplifies training fast and accurate neural nets using mod
 113 Dec 20, 2022
113 Dec 20, 2022
FasterAI: A library to make smaller and faster models with FastAI.
Fasterai fasterai is a library created to make neural network smaller and faster. It essentially relies on common compression techniques for networks
 193 Jan 1, 2023
193 Jan 1, 2023
🔊 Audio and fastai v2
Fastaudio An audio module for fastai v2. We want to help you build audio machine learning applications while minimizing the need for audio domain expe
 152 Dec 28, 2022
152 Dec 28, 2022

Quantization library for PyTorch. Support low-precision and mixed-precision quantization, with hardware implementation through TVM.
HAWQ: Hessian AWare Quantization HAWQ is an advanced quantization library written for PyTorch. HAWQ enables low-precision and mixed-precision uniform
 293 Dec 30, 2022
293 Dec 30, 2022
A GPU-optional modular synthesizer in pytorch, 16200x faster than realtime, for audio ML researchers.
torchsynth The fastest synth in the universe. Introduction torchsynth is based upon traditional modular synthesis written in pytorch. It is GPU-option
 229 Jan 2, 2023
229 Jan 2, 2023
DA2Lite is an automated model compression toolkit for PyTorch.
DA2Lite (Deep Architecture to Lite) is a toolkit to compress and accelerate deep network models. ⭐ Star us on GitHub — it helps!! Frameworks & Librari
 7 Mar 22, 2022
7 Mar 22, 2022
A desktop GUI providing an audio interface for GPT3.
Jabberwocky neil_degrasse_tyson_with_audio.mp4 Project Description This GUI provides an audio interface to GPT-3. My main goal was to provide a conven
 16 Nov 27, 2022
16 Nov 27, 2022
This bot can stream audio or video files and urls in telegram voice chats
Voice Chat Streamer This bot can stream audio or video files and urls in telegram voice chats :) 🎯 Follow me and star this repo for more telegram bot
 4 Oct 9, 2022
4 Oct 9, 2022
This is a Client-Server-System which can send audio from a microphone from the server to client and in the other direction.
Audio-Streaming-Python This is a Client-Server-System which can send audio from a microphone from the server to client and in the other direction. You
 0 Jan 5, 2023
0 Jan 5, 2023
ZipFly is a zip archive generator based on zipfile.py
ZipFly is a zip archive generator based on zipfile.py. It was created by Buzon.io to generate very large ZIP archives for immediate sending out to clients, or for writing large ZIP archives without memory inflation.
 506 Jan 4, 2023
506 Jan 4, 2023
IntraQ: Learning Synthetic Images with Intra-Class Heterogeneity for Zero-Shot Network Quantization
IntraQ: Learning Synthetic Images with Intra-Class Heterogeneity for Zero-Shot Network Quantization paper Requirements Python = 3.7.10 Pytorch == 1.7
 1 Nov 19, 2021
1 Nov 19, 2021
Reference PyTorch implementation of "End-to-end optimized image compression with competition of prior distributions"
PyTorch reference implementation of "End-to-end optimized image compression with competition of prior distributions" by Benoit Brummer and Christophe
 6 Jun 16, 2022
6 Jun 16, 2022
Code for IntraQ, PyTorch implementation of our paper under review
IntraQ: Learning Synthetic Images with Intra-Class Heterogeneity for Zero-Shot Network Quantization paper Requirements Python = 3.7.10 Pytorch == 1.7
1 Nov 19, 2021
Python based Telegram bot. Search and download YouTube video or audio.
Python-Telegram-Youtube-Media-Bot Python based Telegram bot. Search and download YouTube video or audio. Just change settings.py and start TelegramBot
 2 Oct 2, 2022
2 Oct 2, 2022

Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
 589 Jan 2, 2023
589 Jan 2, 2023

🛠️ Tools for Transformers compression using Lightning ⚡
Bert-squeeze is a repository aiming to provide code to reduce the size of Transformer-based models or decrease their latency at inference time.
 66 Dec 11, 2022
66 Dec 11, 2022

The audio-video synchronization of MKV Container Format is exploited to achieve data hiding
The audio-video synchronization of MKV Container Format is exploited to achieve data hiding, where the hidden data can be utilized for various management purposes, including hyper-linking, annotation, and authentication
 1 Nov 17, 2021
1 Nov 17, 2021

Code for the TASLP paper "PSLA: Improving Audio Tagging With Pretraining, Sampling, Labeling, and Aggregation".
PSLA: Improving Audio Tagging with Pretraining, Sampling, Labeling, and Aggregation Introduction Getting Started FSD50K Recipe AudioSet Recipe Label E
 84 Dec 27, 2022
84 Dec 27, 2022
Iterative Training: Finding Binary Weight Deep Neural Networks with Layer Binarization
Iterative Training: Finding Binary Weight Deep Neural Networks with Layer Binarization This repository contains the source code for the paper (link wi
 0 Nov 19, 2021
0 Nov 19, 2021
SomaFM Plugin for Kodi
SomaFM XBMC Plugin This description is a bit outdated. You can simply install this addon by browsing the official repositories from within Kodi. Insta
 7 Jan 21, 2022
7 Jan 21, 2022
Audio/Video downloader
youtubeDownloader Audio/Video downloader • The project downloads audio/video/both after link is entered • It also shows total size of the file, time l
 1 Nov 16, 2021
1 Nov 16, 2021
An implementation of Group Fisher Pruning for Practical Network Compression based on pytorch and mmcv
FisherPruning-Pytorch An implementation of Group Fisher Pruning for Practical Network Compression based on pytorch and mmcv Main Functions Pruning f
 15 Dec 17, 2022
15 Dec 17, 2022
STBP is a way to train SNN with datasets by Backward propagation.
Spiking neural network (SNN), compared with depth neural network (DNN), has faster processing speed, lower energy consumption and more biological interpretability, which is expected to approach Strong AI.
 18 Dec 9, 2022
18 Dec 9, 2022
An open source AutoML toolkit for automate machine learning lifecycle, including feature engineering, neural architecture search, model compression and hyper-parameter tuning.
NNI Doc | 简体中文 NNI (Neural Network Intelligence) is a lightweight but powerful toolkit to help users automate Feature Engineering, Neural Architecture
 12.4k Dec 31, 2022
12.4k Dec 31, 2022
YOLOX_AUDIO is an audio event detection model based on YOLOX
YOLOX_AUDIO is an audio event detection model based on YOLOX, an anchor-free version of YOLO. This repo is an implementated by PyTorch. Main goal of YOLOX_AUDIO is to detect and classify pre-defined audio events in multi-spectrogram domain using image object detection frameworks.
 77 Dec 19, 2022
77 Dec 19, 2022
A discord bot for downloading youtube video and audio files
disctube disctube is a discord bot for downloading video and audio files from youtube using python pytube. disclaimer i am not the best python program
 3 Feb 3, 2022
3 Feb 3, 2022

ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning. In ICCV, 2021.
ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning This repository contains the code for our ICCV 202
 28 Nov 8, 2022
28 Nov 8, 2022
A script that downloads YouTube videos/audio
YouTube-Downloader A script that downloads YouTube videos/audio from youtube. Usage Download the script by executing the following in your terminal :
 2 Jan 4, 2022
2 Jan 4, 2022

The repository for our EMNLP 2021 paper "Finnish Dialect Identification: The Effect of Audio and Text"
Finnish Dialect Identification The repository for our EMNLP 2021 paper "Finnish Dialect Identification: The Effect of Audio and Text". We present a te
 2 Dec 25, 2021
2 Dec 25, 2021
Generating a structured library of .wav samples with Python.
sample-library Scripts for generating a structured sample library with Python Requires Docker about Samples are written to wave files in lib/. Differe
 1 Nov 11, 2021
1 Nov 11, 2021

Efficient Training of Audio Transformers with Patchout
PaSST: Efficient Training of Audio Transformers with Patchout This is the implementation for Efficient Training of Audio Transformers with Patchout Pa
 165 Dec 26, 2022
165 Dec 26, 2022

WaveFake: A Data Set to Facilitate Audio DeepFake Detection
WaveFake: A Data Set to Facilitate Audio DeepFake Detection This is the code repository for our NeurIPS 2021 (Track on Datasets and Benchmarks) paper
 27 Dec 22, 2022
27 Dec 22, 2022
Carnatic Notes Predictor for audio files
Carnatic Notes Predictor for audio files Link for live application: https://share.streamlit.io/pradeepak1/carnatic-notes-predictor-for-audio-files/mai
 1 Nov 6, 2021
1 Nov 6, 2021
WaveFake: A Data Set to Facilitate Audio DeepFake Detection
WaveFake: A Data Set to Facilitate Audio DeepFake Detection This is the code repository for our NeurIPS 2021 (Track on Datasets and Benchmarks) paper
27 Dec 22, 2022
On-device speech-to-index engine powered by deep learning.
On-device speech-to-index engine powered by deep learning.
 30 Nov 24, 2022
30 Nov 24, 2022

A rofi-blocks script that searches youtube and plays the selected audio on mpv.
rofi-ytm A rofi-blocks script that searches youtube and plays the selected audio on mpv. To use the script, run the following command rofi -modi block
 26 Dec 21, 2022
26 Dec 21, 2022

An efficient and easy-to-use deep learning model compression framework
TinyNeuralNetwork 简体中文 TinyNeuralNetwork is an efficient and easy-to-use deep learning model compression framework, which contains features like neura
 441 Dec 25, 2022
441 Dec 25, 2022
Back to Basics: Efficient Network Compression via IMP
Back to Basics: Efficient Network Compression via IMP Authors: Max Zimmer, Christoph Spiegel, Sebastian Pokutta This repository contains the code to r
 1 Nov 19, 2021
1 Nov 19, 2021
convert-to-opus-cli is a Python CLI program for converting audio files to opus audio format.
convert-to-opus-cli convert-to-opus-cli is a Python CLI program for converting audio files to opus audio format. Installation Must have installed ffmp
 4 Dec 21, 2022
4 Dec 21, 2022

SEC'21: Sparse Bitmap Compression for Memory-Efficient Training onthe Edge
Training Deep Learning Models on The Edge Training on the Edge enables continuous learning from new data for deployed neural networks on memory-constr
 4 Nov 18, 2022
4 Nov 18, 2022
An implementation of the Contrast Predictive Coding (CPC) method to train audio features in an unsupervised fashion.
CPC_audio This code implements the Contrast Predictive Coding algorithm on audio data, as described in the paper Unsupervised Pretraining Transfers we
 8 Nov 14, 2022
8 Nov 14, 2022
Terminal-based audio-to-text converter
att Terminal-based audio-to-text converter Project description A terminal-based audio-to-text converter written in python, enabling you to convert .wa
 4 Dec 15, 2022
4 Dec 15, 2022
This is a story bot, that will scrape stories from r/stories subreddit and convert it into an Audio File.
Introduction This is a story bot, that will scrape stories from r/stories subreddit and convert it into an Audio File. Installation pip install -r req
 11 Jun 30, 2022
11 Jun 30, 2022

Generic image compressor for machine learning. Pytorch code for our paper "Lossy compression for lossless prediction".
Lossy Compression for Lossless Prediction Using: Training: This repostiory contains our implementation of the paper: Lossy Compression for Lossless Pr
 84 Jan 2, 2023
84 Jan 2, 2023

digital audio workstation, instrument and effect plugins, wave editor
digital audio workstation, instrument and effect plugins, wave editor
 306 Jan 5, 2023
306 Jan 5, 2023
An 8D music player made to enjoy Halloween this year!🤘
HAPPY HALLOWEEN buddy! Split Player Hello There! Welcome to SplitPlayer... Supposed To Be A 8DPlayer.... You Decide.... It can play the ordinary audio
 1 Nov 4, 2021
1 Nov 4, 2021

Pytorch implementation of our paper accepted by NeurIPS 2021 -- Revisiting Discriminator in GAN Compression: A Generator-discriminator Cooperative Compression Scheme
Revisiting Discriminator in GAN Compression: A Generator-discriminator Cooperative Compression Scheme (NeurIPS2021) (Link) Overview Prerequisites Linu
 34 Mar 31, 2022
34 Mar 31, 2022
Using python to generate a bat script of repetitive lines of code that differ in some way but can sort out a group of audio files according to their common names
Batch Sorting Using python to generate a bat script of repetitive lines of code that differ in some way but can sort out a group of audio files accord
 1 Oct 29, 2021
1 Oct 29, 2021
Python script for extracting audio from video files and creating Mel spectrograms
video2spectrogram About This package is meant to automate the process of extracting audio files from videos and saving the plots computed from these a
 1 Oct 28, 2021
1 Oct 28, 2021
A Python 3 script for capturing and recording a SDR stream to a WAV file (or serving it to a HTTP audio stream).
rfsoapyfile A Python 3 script for capturing and recording a SDR stream to a WAV file (or serving it to a HTTP audio stream). The script is threaded fo
 4 Dec 19, 2022
4 Dec 19, 2022
Code Release for the paper "TriBERT: Full-body Human-centric Audio-visual Representation Learning for Visual Sound Separation"
TriBERT This repository contains the code for the NeurIPS 2021 paper titled "TriBERT: Full-body Human-centric Audio-visual Representation Learning for
 8 Aug 31, 2022
8 Aug 31, 2022
Audio Domain Adaptation for Acoustic Scene Classification using Disentanglement Learning
Audio Domain Adaptation for Acoustic Scene Classification using Disentanglement Learning Reference Abeßer, J. & Müller, M. Towards Audio Domain Adapt
 2 Jul 6, 2022
2 Jul 6, 2022
Audio Visual Emotion Recognition using TDA
Audio Visual Emotion Recognition using TDA RAVDESS database with two datasets analyzed: Video and Audio dataset: Audio-Dataset: https://www.kaggle.com
 3 May 11, 2022
3 May 11, 2022
SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch.
The SpeechBrain Toolkit SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch. The goal is to create a single, flexible, and us
 5.1k Jan 2, 2023
5.1k Jan 2, 2023
Revisiting Discriminator in GAN Compression: A Generator-discriminator Cooperative Compression Scheme (NeurIPS2021)
Revisiting Discriminator in GAN Compression: A Generator-discriminator Cooperative Compression Scheme (NeurIPS2021) Overview Prerequisites Linux Pytho
34 Mar 31, 2022
YOLOv5 Series Multi-backbone, Pruning and quantization Compression Tool Box.
YOLOv5-Compression Update News Requirements 环境安装 pip install -r requirements.txt Evaluation metric Visdrone Model mAP mAP@50 Parameters(M) GFLOPs FPS@
 719 Jan 2, 2023
719 Jan 2, 2023

A Pytorch Implementation of a continuously rate adjustable learned image compression framework.
GainedVAE A Pytorch Implementation of a continuously rate adjustable learned image compression framework, Gained Variational Autoencoder(GainedVAE). N
 39 Dec 24, 2022
39 Dec 24, 2022
This repository contains code and data for "On the Multimodal Person Verification Using Audio-Visual-Thermal Data"
trimodal_person_verification This repository contains the code, and preprocessed dataset featured in "A Study of Multimodal Person Verification Using
 7 Aug 31, 2022
7 Aug 31, 2022
Official implementation of the paper WAV2CLIP: LEARNING ROBUST AUDIO REPRESENTATIONS FROM CLIP
Wav2CLIP 🚧 WIP 🚧 Official implementation of the paper WAV2CLIP: LEARNING ROBUST AUDIO REPRESENTATIONS FROM CLIP 📄 🔗 Ho-Hsiang Wu, Prem Seetharaman
 240 Dec 13, 2022
240 Dec 13, 2022
An app made in Python using the PyTube and Tkinter libraries to download videos and MP3 audio.
yt-dl (GUI Edition) An app made in Python using the PyTube and Tkinter libraries to download videos and MP3 audio. How do I download this? Windows: Fi
 1 Oct 23, 2021
1 Oct 23, 2021
Who calls the shots? Rethinking Few-Shot Learning for Audio (WASPAA 2021)
rethink-audio-fsl This repo contains the source code for the paper "Who calls the shots? Rethinking Few-Shot Learning for Audio." (WASPAA 2021) Table
 34 Dec 24, 2022
34 Dec 24, 2022

OpenClubhouse - A third-part web application based on flask to play Clubhouse audio.
OpenClubhouse - A third-part web application based on flask to play Clubhouse audio.
 1.1k Jan 5, 2023
1.1k Jan 5, 2023
Script simples para baixar vídeos/áudios/playlist do YouTube
🔗 VilelaTube ▶️ Script simples para baixar vídeos/áudios/playlist do YouTube Requisitos • Como usar • Melhorias futuras ⚠️ Atenção! ⚠️ Lembre-se de a
 2 Nov 3, 2021
2 Nov 3, 2021
A Telegram Userbot to play or streaming Audio and Video songs / files in Telegram Voice Chats.
Vcmusic-Userbot A Telegram Userbot to play or streaming Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram R
 3 Oct 23, 2021
3 Oct 23, 2021
a dnn ai project to classify which food people are eating on audio recordings
Deep Learning - EAT Challenge About This project is part of an AI challenge of the DeepLearning course 2021 at the University of Augsburg. The objecti
 1 Oct 24, 2021
1 Oct 24, 2021
Official implementation of the paper Chunked Autoregressive GAN for Conditional Waveform Synthesis
Chunked Autoregressive GAN (CARGAN) Official implementation of the paper Chunked Autoregressive GAN for Conditional Waveform Synthesis [paper] [compan
150 Dec 6, 2022