566 Repositories
Python awesome-public-datasets Libraries

Papers, Datasets, Algorithms, SOTA for STR. Long-time Maintaining
Scene Text Recognition Recommendations Everythin about Scene Text Recognition SOTA • Papers • Datasets • Code Contents 1. Papers 2. Datasets 2.1 Synth
 197 Jan 5, 2023
197 Jan 5, 2023
Download and preprocess popular sequential recommendation datasets
Sequential Recommendation Datasets This repository collects some commonly used sequential recommendation datasets in recent research papers and provid
 125 Dec 6, 2022
125 Dec 6, 2022
Public repository of the 3DV 2021 paper "Generative Zero-Shot Learning for Semantic Segmentation of 3D Point Clouds"
Generative Zero-Shot Learning for Semantic Segmentation of 3D Point Clouds Björn Michele1), Alexandre Boulch1), Gilles Puy1), Maxime Bucher1) and Rena
 15 Dec 22, 2022
15 Dec 22, 2022
EMNLP 2021 paper Models and Datasets for Cross-Lingual Summarisation.
This repository contains data and code for our EMNLP 2021 paper Models and Datasets for Cross-Lingual Summarisation. Please contact me at [email protected]
 9 Oct 28, 2022
9 Oct 28, 2022
Event Coding for the HV Protocol MEG datasets
Scripts for QA and trigger preprocessing of NIMH HV Protocol Install pip install git+https://github.com/nih-megcore/hv_proc Usage hv_process.py will
 2 Nov 14, 2022
2 Nov 14, 2022
This script aims to make the dynamic public ip of your local server, public.
EZ DDNS CLOUDFLARE This script aims to make the dynamic ip of your local server, public. It does this by regularly updating cloudflare's dns record. B
 3 Feb 13, 2022
3 Feb 13, 2022

A curated list of awesome deep long-tailed learning resources.
A curated list of awesome deep long-tailed learning resources.
 210 Dec 25, 2022
210 Dec 25, 2022

Useful guides, tutorials, and FAQs related to LEGO Universe and Darkflame Universe.
Awesome Lego Universe A curated list of awesome things related to LEGO Universe. LEGO Universe was a kid-friendly massively-multiplayer online role pl
 33 Dec 12, 2022
33 Dec 12, 2022

Implementation of the ivis algorithm as described in the paper Structure-preserving visualisation of high dimensional single-cell datasets.
Implementation of the ivis algorithm as described in the paper Structure-preserving visualisation of high dimensional single-cell datasets.
 285 Jan 4, 2023
285 Jan 4, 2023

PyTorch implementation of Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Simple PyTorch Implementation of "Grokking" Implementation of Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets Usage Running
 15 Sep 29, 2022
15 Sep 29, 2022
A comprehensive set of fairness metrics for datasets and machine learning models, explanations for these metrics, and algorithms to mitigate bias in datasets and models.
AI Fairness 360 (AIF360) The AI Fairness 360 toolkit is an extensible open-source library containg techniques developed by the research community to h
 1.9k Jan 6, 2023
1.9k Jan 6, 2023
The implementation for paper Joint t-SNE for Comparable Projections of Multiple High-Dimensional Datasets.
Joint t-sne This is the implementation for paper Joint t-SNE for Comparable Projections of Multiple High-Dimensional Datasets. abstract: We present Jo
 7 Dec 18, 2022
7 Dec 18, 2022
The first public repository that provides free BUBT website scraping API script on Github.
BUBT WEBSITE SCRAPPING SCRIPT I think this is the first public repository that provides free BUBT website scraping API script on github. When I was do
 3 Feb 10, 2022
3 Feb 10, 2022
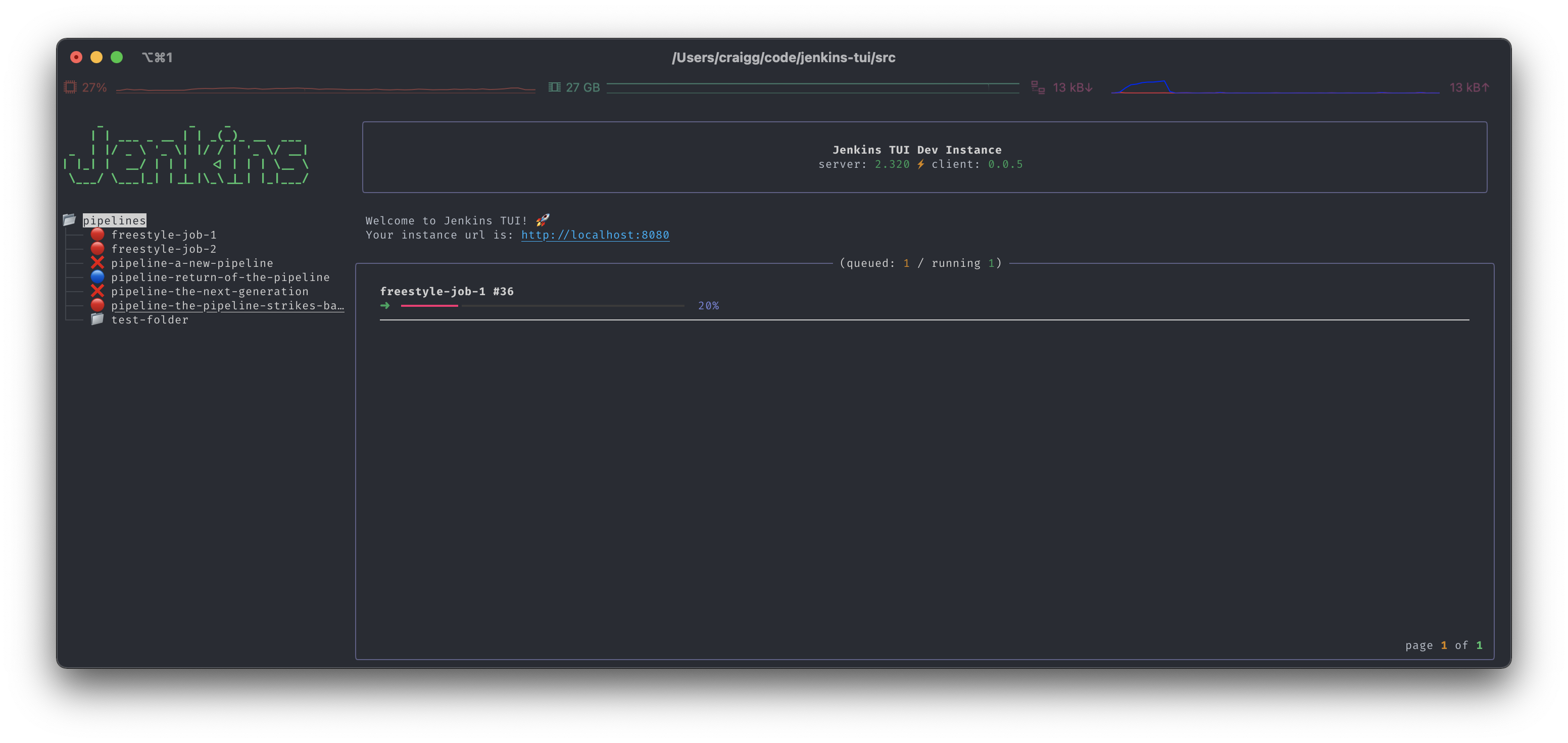
A curated list of awesome things related to Textual
Awesome Textual | A curated list of awesome things related to Textual. Textual is a TUI (Text User Interface) framework for Python inspired by modern
 5 May 8, 2022
5 May 8, 2022
PyTorch toolkit for biomedical imaging
farabio is a minimal PyTorch toolkit for out-of-the-box deep learning support in biomedical imaging. For further information, see Wikis and Docs.
 47 Dec 28, 2022
47 Dec 28, 2022
public repo for ESTER dataset and modeling (EMNLP'21)
Project / Paper Introduction This is the project repo for our EMNLP'21 paper: https://arxiv.org/abs/2104.08350 Here, we provide brief descriptions of
 19 Oct 27, 2022
19 Oct 27, 2022
A prototype COG-based tile server for sparse Mars datasets
Mars tiler Mars Tiler is a prototype web application that serves tiles from cloud-optimized GeoTIFFs, with an emphasis on supporting planetary dataset
 3 Mar 23, 2022
3 Mar 23, 2022
Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph",
K-BERT Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph", which is implemented based on the UER framework. R
 834 Jan 9, 2023
834 Jan 9, 2023
PLUR is a collection of source code datasets suitable for graph-based machine learning.
PLUR (Programming-Language Understanding and Repair) is a collection of source code datasets suitable for graph-based machine learning. We provide scripts for downloading, processing, and loading the datasets. This is done by offering a unified API and data structures for all datasets.
 76 Nov 25, 2022
76 Nov 25, 2022
Re-implementation of 'Grokking: Generalization beyond overfitting on small algorithmic datasets'
Re-implementation of the paper 'Grokking: Generalization beyond overfitting on small algorithmic datasets' Paper Original paper can be found here Data
 38 Aug 9, 2022
38 Aug 9, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
Optimizing Deeper Transformers on Small Datasets
DT-Fixup Optimizing Deeper Transformers on Small Datasets Paper published in ACL 2021: arXiv Detailed instructions to replicate our results in the pap
 16 Nov 14, 2022
16 Nov 14, 2022

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023
GE2340 project source code without credentials.
GE2340-Project-Public GE2340 project source code without credentials. Run the bot.py to start the bot Telegram: @jasperwong_ge2340_bot If the bot does
 0 Feb 10, 2022
0 Feb 10, 2022

Neighborhood Reconstructing Autoencoders
Neighborhood Reconstructing Autoencoders The official repository for Neighborhood Reconstructing Autoencoders (Lee, Kwon, and Park, NeurIPS 2021). T
 24 Dec 14, 2022
24 Dec 14, 2022
Public Code for NIPS submission SimiGrad: Fine-Grained Adaptive Batching for Large ScaleTraining using Gradient Similarity Measurement
Public code for NIPS submission "SimiGrad: Fine-Grained Adaptive Batching for Large Scale Training using Gradient Similarity Measurement" This repo co
 0 Oct 13, 2021
0 Oct 13, 2021
Code for "Solving Graph-based Public Good Games with Tree Search and Imitation Learning"
Code for "Solving Graph-based Public Good Games with Tree Search and Imitation Learning" This is the code for the paper Solving Graph-based Public Goo
 3 Dec 5, 2022
3 Dec 5, 2022
Aerial Ace is a helper bot for poketwo which provide various functionalities on top of being a pokedex.
Aerial Ace is a helper bot for poketwo which provide various functionalities on top of being a pokedex.
 1 Dec 1, 2021
1 Dec 1, 2021
✨✨✨An awesome open source toolbox for stereo matching.
OpenStereo This is an awesome open source toolbox for stereo matching. Supported Methods: BM SGM(T-PAMI'07) GCNet(ICCV'17) PSMNet(CVPR'18) StereoNet(E
 6 Nov 4, 2022
6 Nov 4, 2022

DALLE-tools provided useful dataset utilities to improve you workflow with WebDatasets.
DALLE tools DALLE-tools is a github repository with useful tools to categorize, annotate or check the sanity of your datasets. Installation Just clone
 11 Dec 25, 2022
11 Dec 25, 2022
Awesome Django Blog App
Awesome-Django-Blog-App Made with love django as the backend and Bootstrap as the frontend ! i hope that can help !! Project Title Django provides mul
 2 Feb 8, 2022
2 Feb 8, 2022
Datasets, Transforms and Models specific to Computer Vision
vision Datasets, Transforms and Models specific to Computer Vision Installation First install the nightly version of OneFlow python3 -m pip install on
 68 Dec 7, 2022
68 Dec 7, 2022
GradAttack is a Python library for easy evaluation of privacy risks in public gradients in Federated Learning
GradAttack is a Python library for easy evaluation of privacy risks in public gradients in Federated Learning, as well as corresponding mitigation strategies.
 129 Dec 30, 2022
129 Dec 30, 2022

A benchmark dataset for emulating atmospheric radiative transfer in weather and climate models with machine learning (NeurIPS 2021 Datasets and Benchmarks Track)
ClimART - A Benchmark Dataset for Emulating Atmospheric Radiative Transfer in Weather and Climate Models Official PyTorch Implementation Using deep le
 21 Dec 31, 2022
21 Dec 31, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022

Lite version of my Gatekeeper backdoor for public use.
Gatekeeper Lite Backdoor Fully functioning bind-type backdoor This backdoor is a fully functioning bind shell and lite version of my full functioning
 56 Mar 25, 2022
56 Mar 25, 2022
Experimenting with computer vision techniques to generate annotated image datasets from gameplay recordings automatically.
Experimenting with computer vision techniques to generate annotated image datasets from gameplay recordings automatically. The collected data will then be used to train a deep neural network that can detect enemy player models in real time, during gameplay. Finally, a virtual input device will adjust the player's crosshair based on live detections for greater accuracy.
 3 Apr 24, 2022
3 Apr 24, 2022

Veri Setinizi Yolov5 Formatına Dönüştürün
Veri Setinizi Yolov5 Formatına Dönüştürün! Bu Repo da Neler Var? Xml Formatındaki Veri Setini .Txt Formatına Çevirme Xml Formatındaki Dosyaları Silme
 4 Aug 22, 2022
4 Aug 22, 2022
An index of algorithms for learning causality with data
awesome-causality-algorithms An index of algorithms for learning causality with data. Please cite our survey paper if this index is helpful. @article{
 2.3k Jan 8, 2023
2.3k Jan 8, 2023
A Discord token grabber written in Python3, with awesome obfuscation and anti-debug protection.
☣️ Plague ☣️ Plague is a Discord token grabber written in Python3, obfuscated with Kramer, protected from traffic analysers with Scarecrow and using t
 125 Dec 20, 2022
125 Dec 20, 2022
Finds, downloads, parses, and standardizes public bikeshare data into a standard pandas dataframe format
Finds, downloads, parses, and standardizes public bikeshare data into a standard pandas dataframe format.
 2 Dec 1, 2021
2 Dec 1, 2021

A curated list of awesome papers for Semantic Retrieval (TOIS Accepted: Semantic Models for the First-stage Retrieval: A Comprehensive Review).
A curated list of awesome papers for Semantic Retrieval (TOIS Accepted: Semantic Models for the First-stage Retrieval: A Comprehensive Review).
 189 Dec 28, 2022
189 Dec 28, 2022

MobileNetV1-V2,MobileNeXt,GhostNet,AdderNet,ShuffleNetV1-V2,Mobile+ViT etc.
MobileNetV1-V2,MobileNeXt,GhostNet,AdderNet,ShuffleNetV1-V2,Mobile+ViT etc. ⭐⭐⭐⭐⭐
 568 Jan 4, 2023
568 Jan 4, 2023
Metrics to evaluate quality and efficacy of synthetic datasets.
An Open Source Project from the Data to AI Lab, at MIT Metrics for Synthetic Data Generation Projects Website: https://sdv.dev Documentation: https://
 129 Jan 3, 2023
129 Jan 3, 2023
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems.
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems.
 880 Jan 7, 2023
880 Jan 7, 2023
Awesome Deep Graph Clustering is a collection of SOTA, novel deep graph clustering methods
ADGC: Awesome Deep Graph Clustering ADGC is a collection of state-of-the-art (SOTA), novel deep graph clustering methods (papers, codes and datasets).
 297 Dec 27, 2022
297 Dec 27, 2022
The public repository about our joint FINN research project
FInite volume Neural Network (FINN) This repository contains the PyTorch code for models, training, and testing, and Python code for data generation t
 1 Nov 24, 2021
1 Nov 24, 2021
VGGVox models for Speaker Identification and Verification trained on the VoxCeleb (1 & 2) datasets
VGGVox models for speaker identification and verification This directory contains code to import and evaluate the speaker identification and verificat
 338 Dec 27, 2022
338 Dec 27, 2022
Public Management System for ACP's 24H TT Fronteira 2021
CROWD MANAGEMENT SYSTEM 24H TT Vila de Froteira 2021 This python script creates a dashboard with realtime updates regarding the capacity of spectactor
 1 Nov 24, 2021
1 Nov 24, 2021
A curated list of awesome projects and resources related fastai
A curated list of awesome projects and resources related fastai
 138 Dec 22, 2022
138 Dec 22, 2022
Data imputations library to preprocess datasets with missing data
Impyute is a library of missing data imputation algorithms. This library was designed to be super lightweight, here's a sneak peak at what impyute can do.
 329 Dec 5, 2022
329 Dec 5, 2022
Centralized whale instance using github actions, sourcing metadata from bigquery-public-data.
Whale Demo Instance: Bigquery Public Data This is a fully-functioning demo instance of the whale data catalog, actively scraping data from Bigquery's
 17 Dec 14, 2022
17 Dec 14, 2022

Current state of supervised and unsupervised depth completion methods
Awesome Depth Completion Table of Contents About Sparse-to-Dense Depth Completion Current State of Depth Completion Unsupervised VOID Benchmark Superv
 224 Dec 28, 2022
224 Dec 28, 2022

An implementation of the largeVis algorithm for visualizing large, high-dimensional datasets, for R
largeVis This is an implementation of the largeVis algorithm described in (https://arxiv.org/abs/1602.00370). It also incorporates: A very fast algori
 336 May 25, 2022
336 May 25, 2022
The purpose of this project is to share knowledge on how awesome Streamlit is and can be
Awesome Streamlit The fastest way to build Awesome Tools and Apps! Powered by Python! The purpose of this project is to share knowledge on how Awesome
 1.5k Jan 7, 2023
1.5k Jan 7, 2023
A curated list of awesome Dash (plotly) resources
Awesome Dash A curated list of awesome Dash (plotly) resources Dash is a productive Python framework for building web applications. Written on top of
 1.7k Jan 7, 2023
1.7k Jan 7, 2023
Use Flask API to wrap Facebook data. Grab the wapper of Facebook public pages without an API key.
Facebook Scraper Use Flask API to wrap Facebook data. Grab the wapper of Facebook public pages without an API key. (Currently working 2021) Setup Befo
 2 Dec 27, 2021
2 Dec 27, 2021
This toolkit provides codes to download and pre-process the SLUE datasets, train the baseline models, and evaluate SLUE tasks.
slue-toolkit We introduce Spoken Language Understanding Evaluation (SLUE) benchmark. This toolkit provides codes to download and pre-process the SLUE
 39 Sep 21, 2022
39 Sep 21, 2022
Deep Learning with PyTorch made easy 🚀 !
Deep Learning with PyTorch made easy 🚀 ! Carefree? carefree-learn aims to provide CAREFREE usages for both users and developers. It also provides a c
 381 Dec 22, 2022
381 Dec 22, 2022

NeurIPS 2021 Datasets and Benchmarks Track
AP-10K: A Benchmark for Animal Pose Estimation in the Wild Introduction | Updates | Overview | Download | Training Code | Key Questions | License Intr
 82 Dec 11, 2022
82 Dec 11, 2022
Python: Wrangled and unpivoted gaming datasets. Tableau: created dashboards - Market Beacon and Player’s Shopping Guide.
Created two information products for GameStop. Using Python, wrangled and unpivoted datasets, and created Tableau dashboards.
 2 Jan 29, 2022
2 Jan 29, 2022

Neurons Dataset API - The official dataloader and visualization tools for Neurons Datasets.
Neurons Dataset API - The official dataloader and visualization tools for Neurons Datasets. Introduction We propose our dataloader API for loading and
 1 Nov 19, 2021
1 Nov 19, 2021

Serverless Public Key Infrastructure Framework
Ottr: Serverless Public Key Infrastructure Framework Ottr is a serverless framework for Public Key Infrastructure (PKI) that aims to provide a robust
 259 Dec 28, 2022
259 Dec 28, 2022

SHIFT15M: multiobjective large-scale fashion dataset with distributional shifts
[arXiv] The main motivation of the SHIFT15M project is to provide a dataset that contains natural dataset shifts collected from a web service IQON, wh
 138 Nov 24, 2022
138 Nov 24, 2022

Learning infinite-resolution image processing with GAN and RL from unpaired image datasets, using a differentiable photo editing model.
Exposure: A White-Box Photo Post-Processing Framework ACM Transactions on Graphics (presented at SIGGRAPH 2018) Yuanming Hu1,2, Hao He1,2, Chenxi Xu1,
 719 Dec 29, 2022
719 Dec 29, 2022

Curated list of awesome GAN applications and demo
gans-awesome-applications Curated list of awesome GAN applications and demonstrations. Note: General GAN papers targeting simple image generation such
 4.5k Jan 7, 2023
4.5k Jan 7, 2023

 1.2k Dec 26, 2022
1.2k Dec 26, 2022

Summary of related papers on visual attention
This repo is built for paper: Attention Mechanisms in Computer Vision: A Survey paper Vision-Attention-Papers Channel attention Spatial attention Temp
 2.1k Dec 30, 2022
2.1k Dec 30, 2022

Code-free deep segmentation for computational pathology
NoCodeSeg: Deep segmentation made easy! This is the official repository for the manuscript "Code-free development and deployment of deep segmentation
 26 Nov 23, 2022
26 Nov 23, 2022

Interactive Web App with Streamlit and Scikit-learn that applies different Classification algorithms to popular datasets
Interactive Web App with Streamlit and Scikit-learn that applies different Classification algorithms to popular datasets Datasets Used: Iris dataset,
 2 Nov 18, 2021
2 Nov 18, 2021
STBP is a way to train SNN with datasets by Backward propagation.
Spiking neural network (SNN), compared with depth neural network (DNN), has faster processing speed, lower energy consumption and more biological interpretability, which is expected to approach Strong AI.
 18 Dec 9, 2022
18 Dec 9, 2022

Semantic segmentation models, datasets and losses implemented in PyTorch.
Semantic Segmentation in PyTorch Semantic Segmentation in PyTorch Requirements Main Features Models Datasets Losses Learning rate schedulers Data augm
 1.3k Jan 7, 2023
1.3k Jan 7, 2023
Python dataset creator to construct datasets composed of OpenFace extracted features and Shimmer3 GSR+ Sensor datas
Python dataset creator to construct datasets composed of OpenFace extracted features and Shimmer3 GSR+ Sensor datas
 3 Jul 5, 2022
3 Jul 5, 2022

Infoga is a tool gathering email accounts informations (ip,hostname,country,...) from different public source
Infoga - Email OSINT Infoga is a tool gathering email accounts informations (ip,hostname,country,...) from different public source (search engines, pg
 1.8k Jan 4, 2023
1.8k Jan 4, 2023
WildHack 2021 solution by Nuclear Foxes team (public version).
WildHack 2021 Nuclear Foxes Team This repo contains our project for the Wildberries Hackathon 2021. Task 2: Searching tags Implement an algorithm of r
 1 Apr 18, 2022
1 Apr 18, 2022
Code and datasets for TPAMI 2021
SkeletonNet This repository constains the codes and ShapeNetV1-Surface-Skeleton,ShapNetV1-SkeletalVolume and 2d image datasets ShapeNetRendering. Plea
 34 Aug 15, 2022
34 Aug 15, 2022

ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning. In ICCV, 2021.
ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning This repository contains the code for our ICCV 202
 28 Nov 8, 2022
28 Nov 8, 2022
The world's first public V2ray manager Telegram bot
📌 DarkV2ray-Manager-Bot 0.1 UPDATE 11/11/2021 Telegram bot v2ray Test user expired date data limit paylode && sni usage user on/off heroku bot hostin
 1 Nov 11, 2021
1 Nov 11, 2021
ObjTables: Tools for creating and reusing high-quality spreadsheets
ObjTables: Tools for creating and reusing high-quality spreadsheets ObjTables is a toolkit which makes it easy to use spreadsheets (e.g., XLSX workboo
 7 Jun 14, 2021
7 Jun 14, 2021
Replication Package for "An Empirical Study of the Effectiveness of an Ensemble of Stand-alone Sentiment Detection Tools for Software Engineering Datasets"
Replication Package for "An Empirical Study of the Effectiveness of an Ensemble of Stand-alone Sentiment Detection Tools for Software Engineering Data
 2 Oct 6, 2022
2 Oct 6, 2022
Source code for the paper: Variance-Aware Machine Translation Test Sets (NeurIPS 2021 Datasets and Benchmarks Track)
Variance-Aware-MT-Test-Sets Variance-Aware Machine Translation Test Sets License See LICENSE. We follow the data licensing plan as the same as the WMT
 5 Dec 21, 2021
5 Dec 21, 2021
Understanding the Effects of Datasets Characteristics on Offline Reinforcement Learning
Understanding the Effects of Datasets Characteristics on Offline Reinforcement Learning Kajetan Schweighofer1, Markus Hofmarcher1, Marius-Constantin D
 17 Dec 28, 2022
17 Dec 28, 2022

Leaderboard, taxonomy, and curated list of few-shot object detection papers.
Leaderboard, taxonomy, and curated list of few-shot object detection papers.
 70 Jan 7, 2023
70 Jan 7, 2023

An implementation of a discriminant function over a normal distribution to help classify datasets.
CS4044D Machine Learning Assignment 1 By Dev Sony, B180297CS The question, report and source code can be found here. Github Repo Solution 1 Based on t
 6 Nov 9, 2021
6 Nov 9, 2021

face2comics by Sxela (Alex Spirin) - face2comics datasets
This is a paired face to comics dataset, which can be used to train pix2pix or similar networks.
 164 Nov 13, 2022
164 Nov 13, 2022

A non-linear, non-parametric Machine Learning method capable of modeling complex datasets
Fast Symbolic Regression Symbolic Regression is a non-linear, non-parametric Machine Learning method capable of modeling complex data sets. fastsr aim
 3 Jun 22, 2022
3 Jun 22, 2022

Datasets and source code for our paper Webly Supervised Fine-Grained Recognition: Benchmark Datasets and An Approach
Introduction Datasets and source code for our paper Webly Supervised Fine-Grained Recognition: Benchmark Datasets and An Approach Datasets: WebFG-496
 21 Sep 30, 2022
21 Sep 30, 2022

An open source recipe book from the awesome staff of Clinical Genomics
meatballs An open source recipe book from the awesome staff of Clinical Genomics.
 2 Dec 7, 2021
2 Dec 7, 2021
A program will generate a eth key pair that has the public key that starts with a defined amount of 0
ETHAdressGenerator This short program will generate a eth key pair that has the public key that starts with a defined amount of 0 Requirements Python
 3 Nov 19, 2021
3 Nov 19, 2021
An unofficial personal implementation of UM-Adapt, specifically to tackle joint estimation of panoptic segmentation and depth prediction for autonomous driving datasets.
Semisupervised Multitask Learning This repository is an unofficial and slightly modified implementation of UM-Adapt[1] using PyTorch. This code primar
 11 Nov 25, 2022
11 Nov 25, 2022
Gets instagram public username and returns usefull informations like profilepic(b64), video_urls etc.
InstaSucker Gets instagram public username and returns usefull informations like profilepic(b64), video_urls etc. Information this project contains a
 5 Apr 30, 2022
5 Apr 30, 2022
Open-source linguistic ethnography tool for framing public opinion in mediatized groups.
Open-source linguistic ethnography tool for framing public opinion in mediatized groups. Table of Contents Installing Quickstart Links Installing Pyth
 7 Jun 2, 2022
7 Jun 2, 2022
Python tools for querying and manipulating BIDS datasets.
PyBIDS is a Python library to centralize interactions with datasets conforming BIDS (Brain Imaging Data Structure) format.
 180 Dec 18, 2022
180 Dec 18, 2022

An awesome tool to save articles from RSS feed to Pocket automatically.
RSS2Pocket An awesome tool to save articles from RSS feed to Pocket automatically. About the Project I used to use IFTTT to save articles from RSS fee
 10 Nov 12, 2022
10 Nov 12, 2022

RLDS stands for Reinforcement Learning Datasets
RLDS RLDS stands for Reinforcement Learning Datasets and it is an ecosystem of tools to store, retrieve and manipulate episodic data in the context of
135 Jan 1, 2023
![[NeurIPS 2021] Well-tuned Simple Nets Excel on Tabular Datasets](https://github.com/releaunifreiburg/WellTunedSimpleNets/raw/main/figures/all_baselines_diagram.png)
[NeurIPS 2021] Well-tuned Simple Nets Excel on Tabular Datasets
[NeurIPS 2021] Well-tuned Simple Nets Excel on Tabular Datasets Introduction This repo contains the source code accompanying the paper: Well-tuned Sim
 52 Jan 4, 2023
52 Jan 4, 2023
Public implementation of the Convolutional Motif Kernel Network (CMKN) architecture
CMKN Implementation of the convolutional motif kernel network (CMKN) introduced in Ditz et al., "Convolutional Motif Kernel Network", 2021. Testing Yo
 1 Nov 17, 2021
1 Nov 17, 2021
Python with braces. Because Python is awesome, but whitespace is awful.
Bython Python with braces. Because Python is awesome, but whitespace is awful. Bython is a Python preprosessor which translates curly brackets into in
 1 Nov 4, 2021
1 Nov 4, 2021
This repository has datasets containing information of Uber pickups in NYC from April 2014 to September 2014 and January to June 2015. data Analysis , virtualization and some insights are gathered here
uber-pickups-analysis Data Source: https://www.kaggle.com/fivethirtyeight/uber-pickups-in-new-york-city Information about data set The dataset contain
 1 Nov 3, 2021
1 Nov 3, 2021

Public repo for automation scripts
Script_Quickies Public repo for automation scripts Dependencies Chrome webdriver .exe (make sure it matches the version of chrome you are using) Selen
 1 Nov 4, 2021
1 Nov 4, 2021