91 Repositories
Python big-endian Libraries
A Python package develop for transportation spatio-temporal big data processing, analysis and visualization.
English 中文版 TransBigData Introduction TransBigData is a Python package developed for transportation spatio-temporal big data processing, analysis and
 251 Jan 3, 2023
251 Jan 3, 2023

Face recognition system using MTCNN, FACENET, SVM and FAST API to track participants of Big Brother Brasil in real time.
BBB Face Recognizer Face recognition system using MTCNN, FACENET, SVM and FAST API to track participants of Big Brother Brasil in real time. Instalati
 232 Dec 24, 2022
232 Dec 24, 2022

CVE-2022-1388 F5 BIG-IP iControl REST Auth Bypass RCE
CVE-2022-1388 CVE-2022-1388 F5 BIG-IP iControl REST Auth Bypass RCE. POST /mgmt/tm/util/bash HTTP/1.1 Host: Accept-Encoding: gzip, deflate Accept: */
 81 Dec 12, 2022
81 Dec 12, 2022

Using Machine Learning to Create High-Res Fine Art
BIG.art: Using Machine Learning to Create High-Res Fine Art How to use GLIDE and BSRGAN to create ultra-high-resolution paintings with fine details By
 13 Nov 27, 2022
13 Nov 27, 2022
Vaex library for Big Data Analytics of an Airline dataset
Vaex-Big-Data-Analytics-for-Airline-data A Python notebook (ipynb) created in Jupyter Notebook, which utilizes the Vaex library for Big Data Analytics
 1 Feb 13, 2022
1 Feb 13, 2022

PATC: Introduction to Big Data Analytics. Practical Data Analytics for Solving Real World Problems
PATC: Introduction to Big Data Analytics. Practical Data Analytics for Solving Real World Problems
 1 Feb 7, 2022
1 Feb 7, 2022
Proyecto - Análisis de texto de eventos históricos
Acceder al código desde Google Colab para poder ver de manera adecuada todas las visualizaciones y poder interactuar con ellas. Link de acceso: https:
 1 Jan 31, 2022
1 Jan 31, 2022
A small script to export all AWAF policies from a BIG-IP device
This script leverages BIG-IP iControl REST API to export ALL AWAF policies in the system and saves them locally. The policies can be exported in the following formats: xml, plc and json.
 3 Feb 3, 2022
3 Feb 3, 2022
Pyspark sam - Analyze Big Sequence Alignments with PySpark in AWS EMR
pyspark_sam This repo hosts my code for the article "Analyze Big Sequence Alignm
 4 Dec 9, 2022
4 Dec 9, 2022
INFO-H515 - Big Data Scalable Analytics
INFO-H515 - Big Data Scalable Analytics Jacopo De Stefani, Giovanni Buroni, Théo Verhelst and Gianluca Bontempi - Machine Learning Group Exercise clas
 58 Dec 11, 2022
58 Dec 11, 2022
SynapseML - an open source library to simplify the creation of scalable machine learning pipelines
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022

DeepAmandine is an artificial intelligence that allows you to talk to it for hours, you won't know the difference.
DeepAmandine This is an artificial intelligence based on GPT-3 that you can chat with, it is very nice and makes a lot of jokes. We wish you a good ex
 3 Apr 19, 2022
3 Apr 19, 2022
Classic algorithms including Fizz Buzz, Bubble Sort, the Fibonacci Sequence, a Sudoku solver, and more.
Algorithms Classic algorithms including Fizz Buzz, Bubble Sort, the Fibonacci Sequence, a Sudoku solver, and more. Algorithm Complexity Time and Space
 1 Jan 14, 2022
1 Jan 14, 2022
Download and process GOES-16 and GOES-17 data from NOAA's archive on AWS using Python.
Download and display GOES-East and GOES-West data GOES-East and GOES-West satellite data are made available on Amazon Web Services through NOAA's Big
 88 Dec 16, 2022
88 Dec 16, 2022
Big Data & Cloud Computing for Oceanography
DS2 Class 2022, Big Data & Cloud Computing for Oceanography Home of the 2022 ISblue Big Data & Cloud Computing for Oceanography class (IMT-A, ENSTA, I
 5 Mar 19, 2022
5 Mar 19, 2022

Python for downloading model data (HRRR, RAP, GFS, NBM, etc.) from NOMADS, NOAA's Big Data Program partners (Amazon, Google, Microsoft), and the University of Utah Pando Archive System.
Python for downloading model data (HRRR, RAP, GFS, NBM, etc.) from NOMADS, NOAA's Big Data Program partners (Amazon, Google, Microsoft), and the University of Utah Pando Archive System.
194 Jan 2, 2023
GDIT: Geometry Dash Info Tool
GDIT: Geometry Dash Info Tool This is the first large script that allows you to quickly get information from the Geometry Dash server
 2 Jan 9, 2022
2 Jan 9, 2022
Apache Spark & Python (pySpark) tutorials for Big Data Analysis and Machine Learning as IPython / Jupyter notebooks
Spark Python Notebooks This is a collection of IPython notebook/Jupyter notebooks intended to train the reader on different Apache Spark concepts, fro
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

This Python program generates a random email address and password from a 2 big lists and checks the generated email.
This Python program generates a random email address and password from a 2 big lists and checks the generated email.
 13 Dec 4, 2022
13 Dec 4, 2022

Uproot is a library for reading and writing ROOT files in pure Python and NumPy.
Uproot is a library for reading and writing ROOT files in pure Python and NumPy. Unlike the standard C++ ROOT implementation, Uproot is only an I/O li
 164 Dec 31, 2022
164 Dec 31, 2022

BigDL - Evaluate the performance of BigDL (Distributed Deep Learning on Apache Spark) in big data analysis problems
Evaluate the performance of BigDL (Distributed Deep Learning on Apache Spark) in big data analysis problems.
 1 Jan 6, 2022
1 Jan 6, 2022
A big endian Gentoo port developed on a Pine64.org RockPro64
Gentoo-aarch64_be A big endian Gentoo port developed on a Pine64.org RockPro64 The endian wars are over... little endian won. As a result, it is incre
 6 Dec 7, 2022
6 Dec 7, 2022

BigbrotherBENL - Face recognition on the Big Brother episodes in Belgium and the Netherlands.
BigbrotherBENL - Face recognition on the Big Brother episodes in Belgium and the Netherlands. Keeping statistics of whom are most visible and recognisable in the series and wether or not it has an impact on who wins.
 2 Jan 4, 2022
2 Jan 4, 2022
ML-PersonalWork - Big assignment PersonalWork in Machine Learning, 2021 autumn BUAA.
ML-PersonalWork - Big assignment PersonalWork in Machine Learning, 2021 autumn BUAA.
 2 Dec 16, 2022
2 Dec 16, 2022
Spark-movie-lens - An on-line movie recommender using Spark, Python Flask, and the MovieLens dataset
A scalable on-line movie recommender using Spark and Flask This Apache Spark tutorial will guide you step-by-step into how to use the MovieLens datase
794 Dec 23, 2022
Utilize data analytics skills to solve real-world business problems using Humana’s big data
Humana-Mays-2021-HealthCare-Analytics-Case-Competition- The goal of the project is to utilize data analytics skills to solve real-world business probl
 1 Dec 27, 2021
1 Dec 27, 2021
Feature Store for Machine Learning
Overview Feast is an open source feature store for machine learning. Feast is the fastest path to productionizing analytic data for model training and
 3.8k Dec 30, 2022
3.8k Dec 30, 2022

A distributed block-based data storage and compute engine
Nebula is an extremely-fast end-to-end interactive big data analytics solution. Nebula is designed as a high-performance columnar data storage and tabular OLAP engine.
 131 Dec 26, 2022
131 Dec 26, 2022
Functions for easily making publication-quality figures with matplotlib.
Data-viz utils 📈 Functions for data visualization in matplotlib 📚 API Can be installed using pip install dvu and then imported with import dvu. You
 16 Sep 15, 2022
16 Sep 15, 2022
The official repository for ROOT: analyzing, storing and visualizing big data, scientifically
About The ROOT system provides a set of OO frameworks with all the functionality needed to handle and analyze large amounts of data in a very efficien
 2k Dec 29, 2022
2k Dec 29, 2022
Big data on k8s
# microsoft azure # https://docs.microsoft.com/en-us/cli/azure/install-azure-cli az account set --subscription [] az aks get-credentials --resource-g
 22 Dec 24, 2022
22 Dec 24, 2022

Delta Sharing: An Open Protocol for Secure Data Sharing
Delta Sharing: An Open Protocol for Secure Data Sharing Delta Sharing is an open protocol for secure real-time exchange of large datasets, which enabl
 497 Jan 2, 2023
497 Jan 2, 2023
Convert long numbers into a human-readable format in Python
Convert long numbers into a human-readable format in Python
 73 Dec 28, 2022
73 Dec 28, 2022
This enforces signatures for CVE-2021-44228 across all policies on a BIG-IP ASM device
f5-waf-enforce-sigs-CVE-2021-44228 This enforces signatures for CVE-2021-44228 across all policies on a BIG-IP ASM device Overview This script enforce
 5 Mar 31, 2022
5 Mar 31, 2022

Reproducible Data Science at Scale!
Pachyderm: The Data Foundation for Machine Learning Pachyderm provides the data layer that allows machine learning teams to productionize and scale th
 5.7k Dec 29, 2022
5.7k Dec 29, 2022
Minimal pure Python library for working with little-endian list representation of bit strings.
bitlist Minimal Python library for working with bit vectors natively. Purpose This library allows programmers to work with a native representation of
 0 Jul 25, 2022
0 Jul 25, 2022

Python bilgilerimi eğlenceli bir şekilde hatırlamak ve daha da geliştirmek için The Big Book of Small Python Projects isimli bir kitap almıştım.
Python bilgilerimi eğlenceli bir şekilde hatırlamak ve daha da geliştirmek için The Big Book of Small Python Projects isimli bir kitap almıştım. Bu repo kitaptaki örnek programları çalıştığım oyun alanım.
 22 Oct 26, 2022
22 Oct 26, 2022
Think Big, Teach Small: Do Language Models Distil Occam’s Razor?
Think Big, Teach Small: Do Language Models Distil Occam’s Razor? Software related to the paper "Think Big, Teach Small: Do Language Models Distil Occa
 0 Dec 7, 2021
0 Dec 7, 2021
Simple and Distributed Machine Learning
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
3.9k Dec 30, 2022
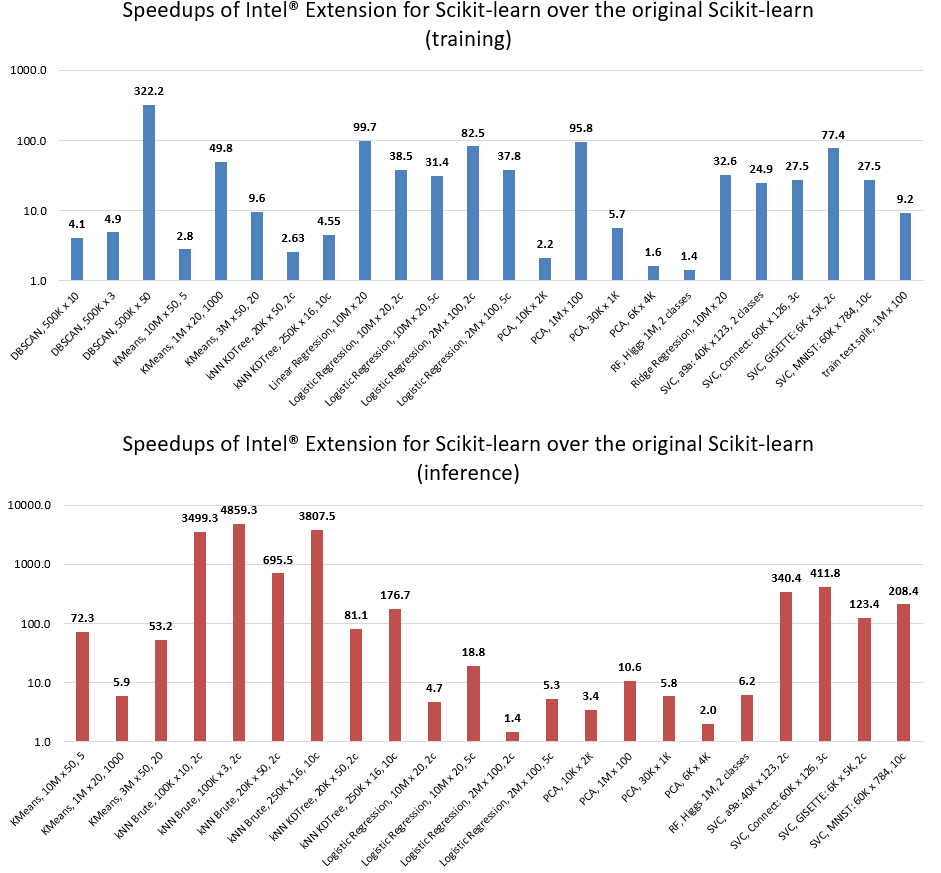
Intel(R) Extension for Scikit-learn is a seamless way to speed up your Scikit-learn application
Intel(R) Extension for Scikit-learn* Installation | Documentation | Examples | Support | FAQ With Intel(R) Extension for Scikit-learn you can accelera
 858 Dec 25, 2022
858 Dec 25, 2022
Fast Fourier Transform-accelerated Interpolation-based t-SNE (FIt-SNE)
FFT-accelerated Interpolation-based t-SNE (FIt-SNE) Introduction t-Stochastic Neighborhood Embedding (t-SNE) is a highly successful method for dimensi
 547 Dec 21, 2022
547 Dec 21, 2022
Falcon: Interactive Visual Analysis for Big Data
Falcon: Interactive Visual Analysis for Big Data Crossfilter millions of records without latencies. This project is work in progress and not documente
 803 Dec 27, 2022
803 Dec 27, 2022

Code for the paper "Offline Reinforcement Learning as One Big Sequence Modeling Problem"
Trajectory Transformer Code release for Offline Reinforcement Learning as One Big Sequence Modeling Problem. Installation All python dependencies are
 266 Dec 27, 2022
266 Dec 27, 2022
Urban Big Data Centre Housing Sensor Project
Housing Sensor Project The Urban Big Data Centre is conducting a study of indoor environmental data in Scottish houses. We are using Raspberry Pi devi
 2 Dec 13, 2021
2 Dec 13, 2021
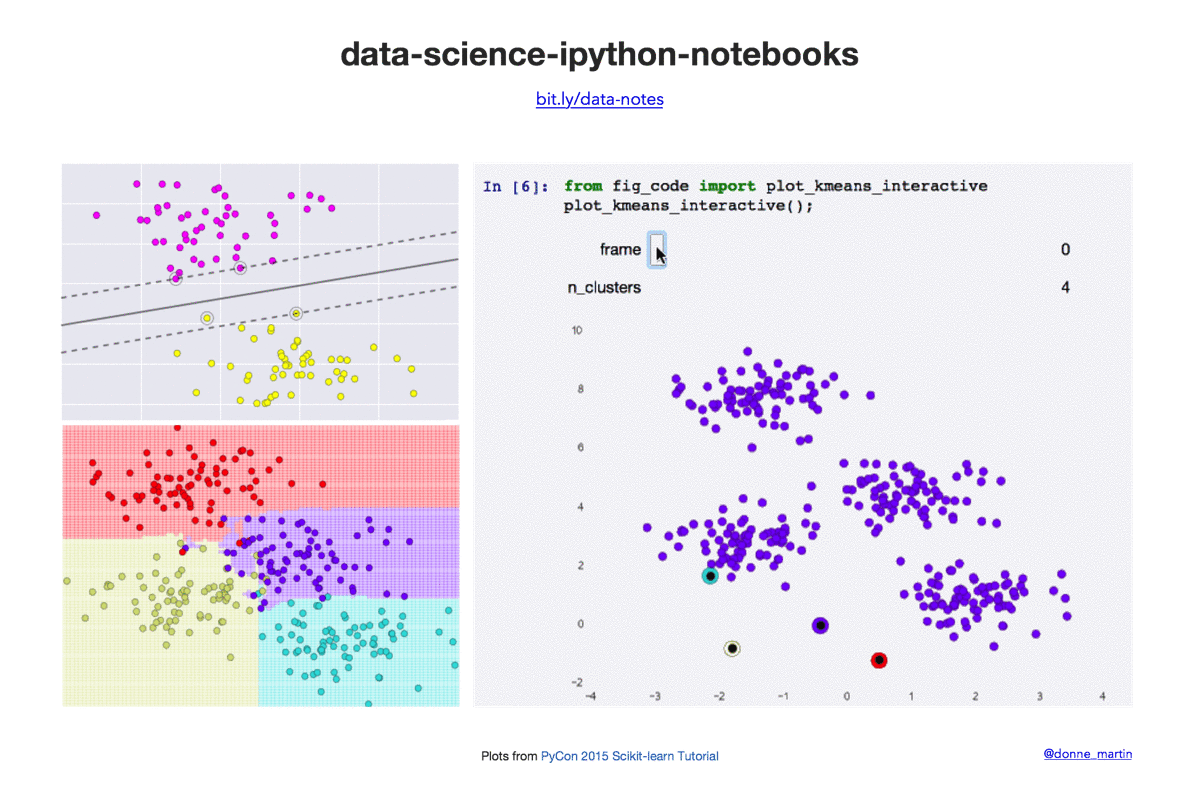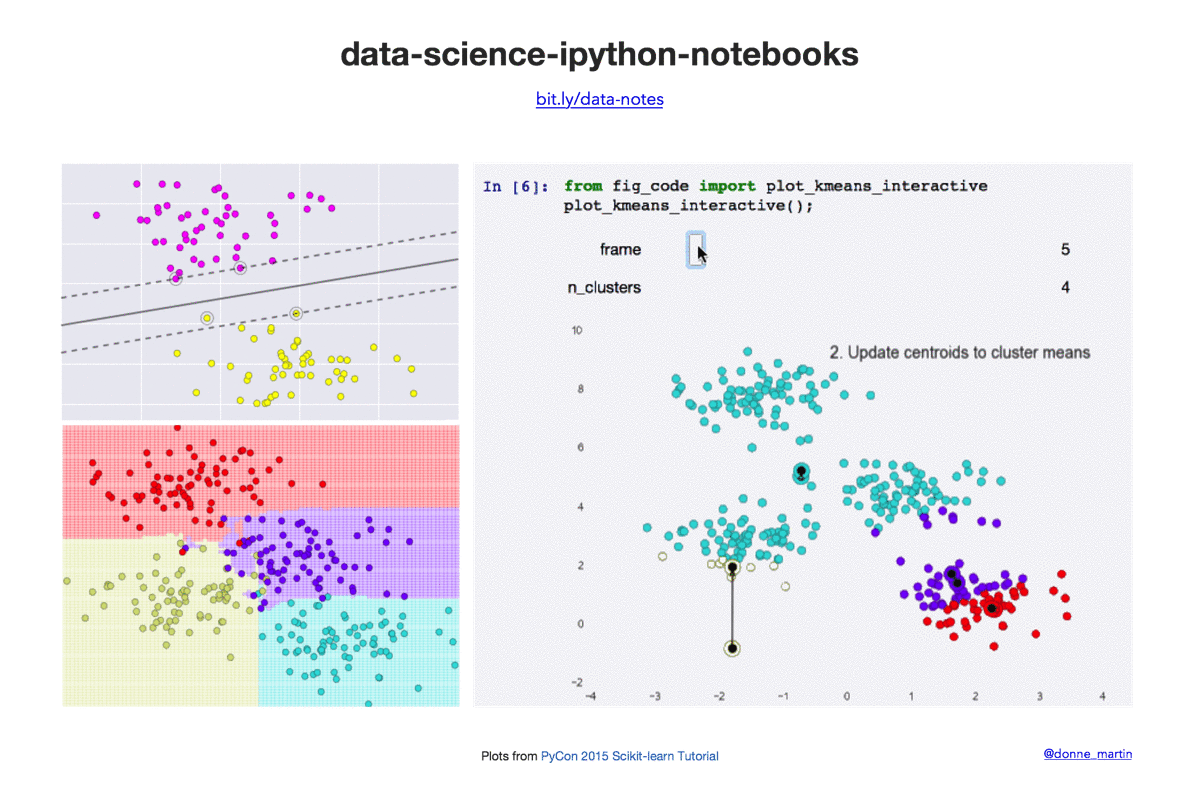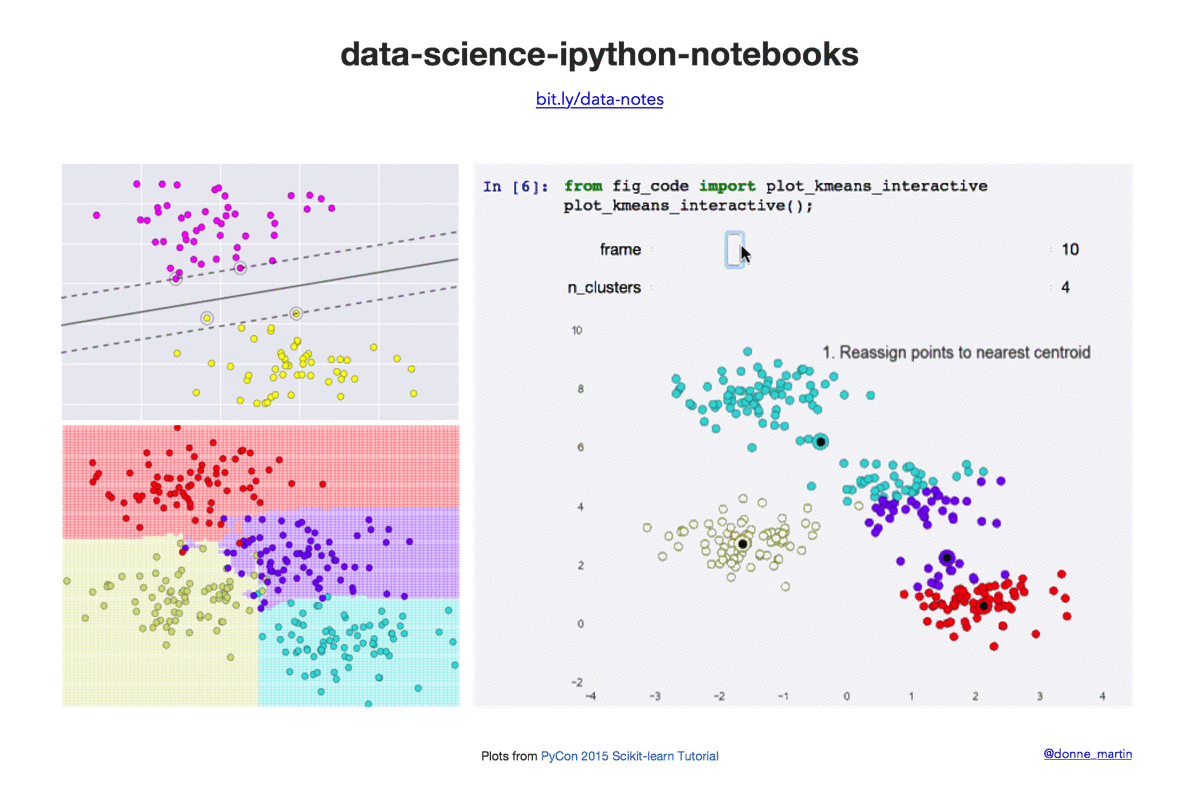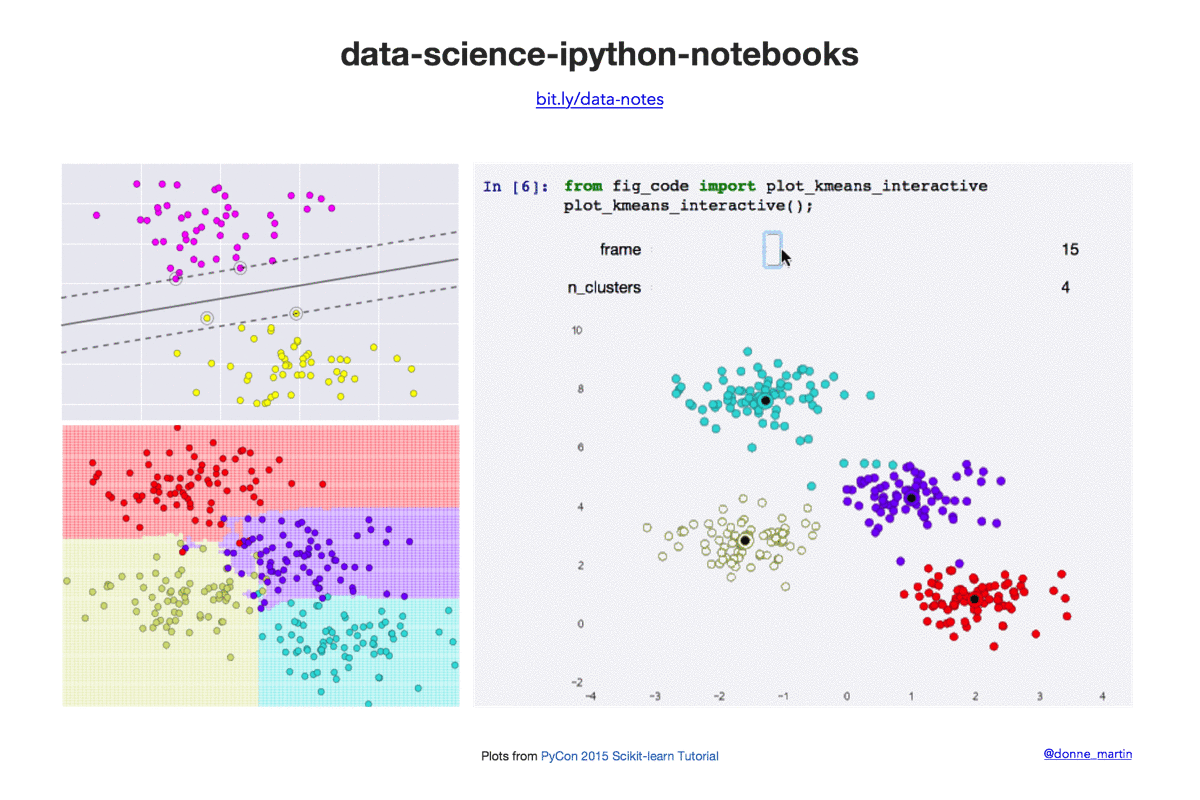
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.
 24.5k Jan 9, 2023
24.5k Jan 9, 2023

A python program with an Objective-C GUI for building and booting OpenCore on both legacy and modern Macs
A python program with an Objective-C GUI for building and booting OpenCore on both legacy and modern Macs, see our in-depth Guide for more information.
 4.7k Jan 2, 2023
4.7k Jan 2, 2023

QuakeLabeler is a Python package to create and manage your seismic training data, processes, and visualization in a single place — so you can focus on building the next big thing.
QuakeLabeler Quake Labeler was born from the need for seismologists and developers who are not AI specialists to easily, quickly, and independently bu
 15 Nov 4, 2022
15 Nov 4, 2022
A Big Data ETL project in PySpark on the historical NYC Taxi Rides data
Processing NYC Taxi Data using PySpark ETL pipeline Description This is an project to extract, transform, and load large amount of data from NYC Taxi
 2 Dec 12, 2021
2 Dec 12, 2021
useful files for the Freenove Big Hexapod
FreenoveBigHexapod useful files for the Freenove Big Hexapod HexaDogPos is a utility for converting the Freenove xyz co-ordinate system to servo angle
 2 May 28, 2022
2 May 28, 2022
The little-endian version of MessagePack
MessagePackEL This is the little-endian version of MessagePack, except the endianness is different, the rest is exactly the same as MessagePack. C lib
 9 May 13, 2022
9 May 13, 2022
CPC-big and k-means clustering for zero-resource speech processing
The CPC-big model and k-means checkpoints used in Analyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing.
 5 Nov 23, 2022
5 Nov 23, 2022
AI Flow is an open source framework that bridges big data and artificial intelligence.
Flink AI Flow Introduction Flink AI Flow is an open source framework that bridges big data and artificial intelligence. It manages the entire machine
 144 Dec 30, 2022
144 Dec 30, 2022
Python code to divide big numbers
divide-big-num Python code to divide big numbers
 1 Oct 15, 2021
1 Oct 15, 2021
Script that organizes the Google Takeout archive into one big chronological folder
Script that organizes the Google Takeout archive into one big chronological folder
 1.6k Jan 9, 2023
1.6k Jan 9, 2023

Raid ToolBox (RTB) is a big toolkit of Spamming/Raiding/Token management tools for discord.
This code is very out of date and not very good, feel free to make it into something better. (we check the github page every 5 years to pulls your PRs
 2 Oct 3, 2021
2 Oct 3, 2021
Eland is a Python Elasticsearch client for exploring and analyzing data in Elasticsearch with a familiar Pandas-compatible API.
Python Client and Toolkit for DataFrames, Big Data, Machine Learning and ETL in Elasticsearch
 463 Dec 30, 2022
463 Dec 30, 2022

BMInf (Big Model Inference) is a low-resource inference package for large-scale pretrained language models (PLMs).
BMInf (Big Model Inference) is a low-resource inference package for large-scale pretrained language models (PLMs).
 377 Jan 2, 2023
377 Jan 2, 2023

PySpark Cheat Sheet - learn PySpark and develop apps faster
This cheat sheet will help you learn PySpark and write PySpark apps faster. Everything in here is fully functional PySpark code you can run or adapt to your programs.
 168 Jan 1, 2023
168 Jan 1, 2023

Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine.
img2dataset Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine. Also supports
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
Code for the paper "Reinforcement Learning as One Big Sequence Modeling Problem"
Trajectory Transformer Code release for Reinforcement Learning as One Big Sequence Modeling Problem. Installation All python dependencies are in envir
269 Jan 5, 2023
A Pythonic Data Catalog powered by Ray that brings exabyte-level scalability and fast, ACID-compliant, change-data-capture to your big data workloads.
DeltaCAT DeltaCAT is a Pythonic Data Catalog powered by Ray. Its data storage model allows you to define and manage fast, scalable, ACID-compliant dat
 45 Oct 15, 2022
45 Oct 15, 2022
Tuplex is a parallel big data processing framework that runs data science pipelines written in Python at the speed of compiled code
Tuplex is a parallel big data processing framework that runs data science pipelines written in Python at the speed of compiled code. Tuplex has similar Python APIs to Apache Spark or Dask, but rather than invoking the Python interpreter, Tuplex generates optimized LLVM bytecode for the given pipeline and input data set.
 791 Jan 4, 2023
791 Jan 4, 2023

Source codes of CenterTrack++ in 2021 ICME Workshop on Big Surveillance Data Processing and Analysis
MOT Tracked object bounding box association (CenterTrack++) New association method based on CenterTrack. Two new branches (Tracked Size and IOU) are a
 36 Oct 4, 2022
36 Oct 4, 2022
Apache Liminal is an end-to-end platform for data engineers & scientists, allowing them to build, train and deploy machine learning models in a robust and agile way
Apache Liminals goal is to operationalise the machine learning process, allowing data scientists to quickly transition from a successful experiment to an automated pipeline of model training, validation, deployment and inference in production. Liminal provides a Domain Specific Language to build ML workflows on top of Apache Airflow.
 121 Dec 28, 2022
121 Dec 28, 2022
Python utility function to communicate with a subprocess using iterables: for when data is too big to fit in memory and has to be streamed
iterable-subprocess Python utility function to communicate with a subprocess using iterables: for when data is too big to fit in memory and has to be
 5 Jul 10, 2022
5 Jul 10, 2022
Stream Framework is a Python library, which allows you to build news feed, activity streams and notification systems using Cassandra and/or Redis. The authors of Stream-Framework also provide a cloud service for feed technology:
Stream Framework Activity Streams & Newsfeeds Stream Framework is a Python library which allows you to build activity streams & newsfeeds using Cassan
 4.7k Jan 2, 2023
4.7k Jan 2, 2023
![[Preprint] Escaping the Big Data Paradigm with Compact Transformers, 2021](https://github.com/SHI-Labs/Compact-Transformers/raw/main/images/model_sym.png)
[Preprint] Escaping the Big Data Paradigm with Compact Transformers, 2021
Compact Transformers Preprint Link: Escaping the Big Data Paradigm with Compact Transformers By Ali Hassani[1]*, Steven Walton[1]*, Nikhil Shah[1], Ab
 367 Dec 31, 2022
367 Dec 31, 2022
The most widely used Python to C compiler
Welcome to Cython! Cython is a language that makes writing C extensions for Python as easy as Python itself. Cython is based on Pyrex, but supports mo
 7.6k Jan 3, 2023
7.6k Jan 3, 2023
BigDL: Distributed Deep Learning Framework for Apache Spark
BigDL: Distributed Deep Learning on Apache Spark What is BigDL? BigDL is a distributed deep learning library for Apache Spark; with BigDL, users can w
 4.1k Jan 9, 2023
4.1k Jan 9, 2023
Find big moving stocks before they move using machine learning and anomaly detection
Surpriver - Find High Moving Stocks before they Move Find high moving stocks before they move using anomaly detection and machine learning. Surpriver
 1.5k Dec 31, 2022
1.5k Dec 31, 2022
Apache Flink
Apache Flink Apache Flink is an open source stream processing framework with powerful stream- and batch-processing capabilities. Learn more about Flin
20.4k Dec 30, 2022

CVE-2021-22986 & F5 BIG-IP RCE
Vuln Impact This vulnerability allows for unauthenticated attackers with network access to the iControl REST interface, through the BIG-IP management
 85 Dec 2, 2022
85 Dec 2, 2022
Beyond the Imitation Game collaborative benchmark for enormous language models
BIG-bench 🪑 The Beyond the Imitation Game Benchmark (BIG-bench) will be a collaborative benchmark intended to probe large language models, and extrap
 1.3k Jan 1, 2023
1.3k Jan 1, 2023
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
 10k Jan 1, 2023
10k Jan 1, 2023

Out-of-Core DataFrames for Python, ML, visualize and explore big tabular data at a billion rows per second 🚀
What is Vaex? Vaex is a high performance Python library for lazy Out-of-Core DataFrames (similar to Pandas), to visualize and explore big tabular data
 7.7k Jan 1, 2023
7.7k Jan 1, 2023
Koalas: pandas API on Apache Spark
pandas API on Apache Spark Explore Koalas docs » Live notebook · Issues · Mailing list Help Thirsty Koalas Devastated by Recent Fires The Koalas proje
 3.2k Jan 4, 2023
3.2k Jan 4, 2023
NumPy and Pandas interface to Big Data
Blaze translates a subset of modified NumPy and Pandas-like syntax to databases and other computing systems. Blaze allows Python users a familiar inte
 3.1k Jan 1, 2023
3.1k Jan 1, 2023
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
10k Jan 1, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
6.8k Feb 18, 2021
Big-Papa Integrates Javascript and python for remote cookie stealing which then can be used for session hijacking
Big-Papa is a remote cookie stealer which can then be used for session hijacking and Bypassing 2 Factor Authentication
 77 Jan 3, 2023
77 Jan 3, 2023
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
10k Jan 1, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
5.7k Feb 12, 2021
Apache Spark - A unified analytics engine for large-scale data processing
Apache Spark Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an op
34.7k Jan 4, 2023
Big Bird: Transformers for Longer Sequences
BigBird, is a sparse-attention based transformer which extends Transformer based models, such as BERT to much longer sequences. Moreover, BigBird comes along with a theoretical understanding of the capabilities of a complete transformer that the sparse model can handle.
 457 Dec 23, 2022
457 Dec 23, 2022
NumPy and Pandas interface to Big Data
Blaze translates a subset of modified NumPy and Pandas-like syntax to databases and other computing systems. Blaze allows Python users a familiar inte
3.1k Jan 1, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
6.9k Jan 4, 2023
Serverless proxy for Spark cluster
Hydrosphere Mist Hydrosphere Mist is a serverless proxy for Spark cluster. Mist provides a new functional programming framework and deployment model f
 317 Dec 1, 2022
317 Dec 1, 2022
H2O is an Open Source, Distributed, Fast & Scalable Machine Learning Platform: Deep Learning, Gradient Boosting (GBM) & XGBoost, Random Forest, Generalized Linear Modeling (GLM with Elastic Net), K-Means, PCA, Generalized Additive Models (GAM), RuleFit, Support Vector Machine (SVM), Stacked Ensembles, Automatic Machine Learning (AutoML), etc.
H2O H2O is an in-memory platform for distributed, scalable machine learning. H2O uses familiar interfaces like R, Python, Scala, Java, JSON and the Fl
 6.1k Jan 5, 2023
6.1k Jan 5, 2023

:truck: Agile Data Preparation Workflows made easy with dask, cudf, dask_cudf and pyspark
To launch a live notebook server to test optimus using binder or Colab, click on one of the following badges: Optimus is the missing framework to prof
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
NumPy and Pandas interface to Big Data
Blaze translates a subset of modified NumPy and Pandas-like syntax to databases and other computing systems. Blaze allows Python users a familiar inte
3.1k Jan 5, 2023