2525 Repositories
Python data-lakehouse Libraries
Advanced Pandas Vault — Utilities, Functions and Snippets (by @firmai).
PandasVault — Advanced Pandas Functions and Code Snippets The only Pandas utility package you would ever need. It has no exotic external dependencies
 374 Jan 7, 2023
374 Jan 7, 2023

PandaPy has the speed of NumPy and the usability of Pandas 10x to 50x faster (by @firmai)
PandaPy "I came across PandaPy last week and have already used it in my current project. It is a fascinating Python library with a lot of potential to
527 Jan 2, 2023
Automatically visualize your pandas dataframe via a single print! 📊 💡
A Python API for Intelligent Visual Discovery Lux is a Python library that facilitate fast and easy data exploration by automating the visualization a
 4.3k Dec 28, 2022
4.3k Dec 28, 2022
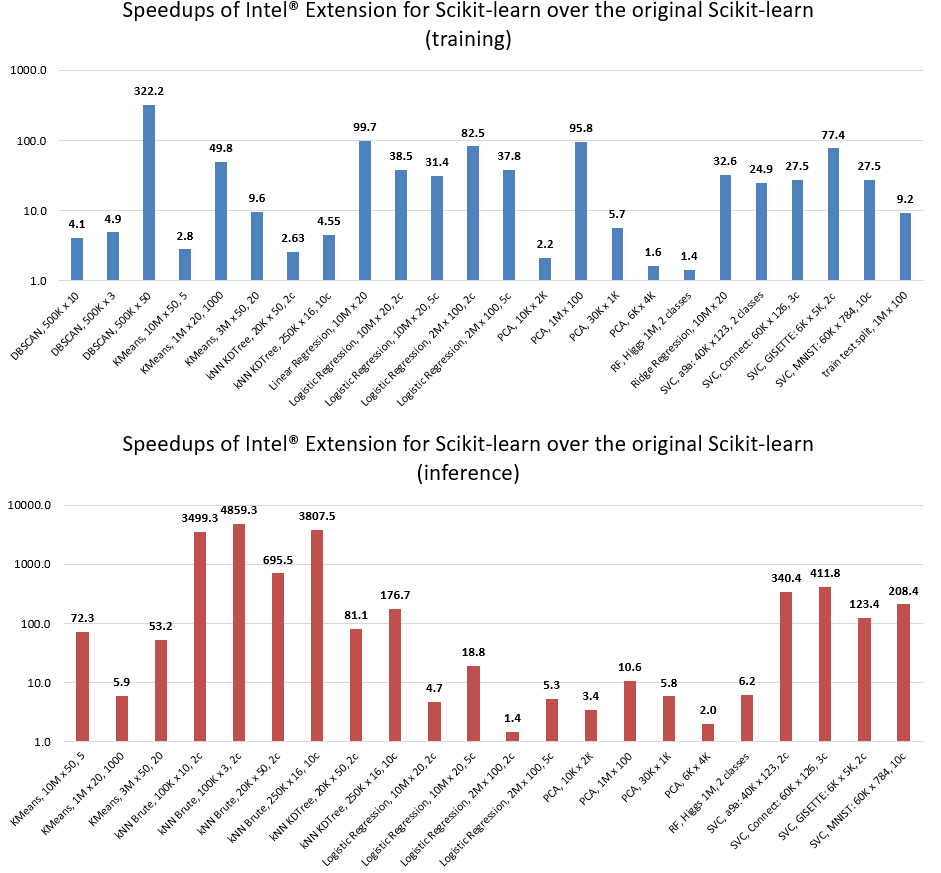
Intel(R) Extension for Scikit-learn is a seamless way to speed up your Scikit-learn application
Intel(R) Extension for Scikit-learn* Installation | Documentation | Examples | Support | FAQ With Intel(R) Extension for Scikit-learn you can accelera
 858 Dec 25, 2022
858 Dec 25, 2022
Finding project directories in Python (data science) projects, just like there R rprojroot and here packages
Find relative paths from a project root directory Finding project directories in Python (data science) projects, just like there R here and rprojroot
 102 Nov 16, 2022
102 Nov 16, 2022
Intake is a lightweight package for finding, investigating, loading and disseminating data.
Intake: A general interface for loading data Intake is a lightweight set of tools for loading and sharing data in data science projects. Intake helps
 851 Jan 1, 2023
851 Jan 1, 2023
Mars is a tensor-based unified framework for large-scale data computation which scales numpy, pandas, scikit-learn and Python functions.
Mars is a tensor-based unified framework for large-scale data computation which scales numpy, pandas, scikit-learn and many other libraries. Documenta
 2.5k Jan 7, 2023
2.5k Jan 7, 2023

A columnar data container that can be compressed.
Unmaintained Package Notice Unfortunately, and due to lack of resources, the Blosc Development Team is unable to maintain this package anymore. During
 944 Dec 9, 2022
944 Dec 9, 2022
Metrics to evaluate quality and efficacy of synthetic datasets.
An Open Source Project from the Data to AI Lab, at MIT Metrics for Synthetic Data Generation Projects Website: https://sdv.dev Documentation: https://
 129 Jan 3, 2023
129 Jan 3, 2023
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems.
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems.
 880 Jan 7, 2023
880 Jan 7, 2023

A DSL for data-driven computational pipelines
"Dataflow variables are spectacularly expressive in concurrent programming" Henri E. Bal , Jennifer G. Steiner , Andrew S. Tanenbaum Quick overview Ne
 1.9k Jan 3, 2023
1.9k Jan 3, 2023

Integrate bus data from a variety of sources (batch processing and real time processing).
Purpose: This is integrate bus data from a variety of sources such as: csv, json api, sensor data ... into Relational Database (batch processing and r
 1 Nov 25, 2021
1 Nov 25, 2021
Python script for diving image data to train test and val
dataset-division-to-train-val-test-python python script for dividing image data to train test and val If you have an image dataset in the following st
 1 Nov 14, 2022
1 Nov 14, 2022
Data repo for one-among.us
Our Data Data repo for one-among.us File Structure Directory /people/userid/: Data for a specific person info.json5: Profile information page.md: Pr
 55 Dec 30, 2022
55 Dec 30, 2022
Pydantic based mock data generation
This library offers powerful mock data generation capabilities for pydantic based models. It can also be used with other libraries that use pydantic as a foundation, for example SQLModel, Beanie and ormar.
 396 Dec 28, 2022
396 Dec 28, 2022

Maze generator and solver with python
Procedural-Maze-Generator-Algorithms Check out my youtube channel : Auctux Ressources Thanks to Jamis Buck Book : Mazes for programmers Requirements P
 19 Dec 7, 2022
19 Dec 7, 2022

Helping you manage your data science projects sanely.
PyDS CLI Helping you manage your data science projects sanely. Requirements Anaconda/Miniconda/Miniforge/Mambaforge (Mambaforge recommended!) git on y
 16 Apr 25, 2022
16 Apr 25, 2022

Source files for the data lake demo video using the AWS TICKIT database
Data Lake Demo Source code for video demonstration detailed in the post, Building a Simple Data Lake on AWS . Build a simple data lake on AWS using a
 97 Dec 23, 2022
97 Dec 23, 2022

The official PyTorch code for NeurIPS 2021 ML4AD Paper, "Does Thermal data make the detection systems more reliable?"
MultiModal-Collaborative (MMC) Learning Framework for integrating RGB and Thermal spectral modalities This is the official code for NeurIPS 2021 Machi
 5 Nov 25, 2021
5 Nov 25, 2021

This repository contains part of the code used to make the images visible in the article "How does an AI Imagine the Universe?" published on Towards Data Science.
Generative Adversarial Network - Generating Universe This repository contains part of the code used to make the images visible in the article "How doe
 9 Dec 18, 2022
9 Dec 18, 2022
eBay's TSV Utilities: Command line tools for large, tabular data files. Filtering, statistics, sampling, joins and more.
Command line utilities for tabular data files This is a set of command line utilities for manipulating large tabular data files. Files of numeric and
 1.4k Jan 9, 2023
1.4k Jan 9, 2023

Desafio proposto pela IGTI em seu bootcamp de Cloud Data Engineer
Desafio Modulo 4 - Cloud Data Engineer Bootcamp - IGTI Objetivos Criar infraestrutura como código Utuilizando um cluster Kubernetes na Azure Ingestão
 4 Jan 23, 2022
4 Jan 23, 2022

Web scraped S&P 500 Data from Wikipedia using Pandas and performed Exploratory Data Analysis on the data.
Web scraped S&P 500 Data from Wikipedia using Pandas and performed Exploratory Data Analysis on the data. Then used Yahoo Finance to get the related stock data and displayed them in the form of charts.
 3 Sep 9, 2022
3 Sep 9, 2022
The fastai book, published as Jupyter Notebooks
English / Spanish / Korean / Chinese / Bengali / Indonesian The fastai book These notebooks cover an introduction to deep learning, fastai, and PyTorc
 17k Jan 7, 2023
17k Jan 7, 2023

Extension to fastai for volumetric medical data
FAIMED 3D use fastai to quickly train fully three-dimensional models on radiological data Classification from faimed3d.all import * Load data in vari
 26 Aug 22, 2022
26 Aug 22, 2022

Compare MLOps Platforms. Breakdowns of SageMaker, VertexAI, AzureML, Dataiku, Databricks, h2o, kubeflow, mlflow...
Compare MLOps Platforms. Breakdowns of SageMaker, VertexAI, AzureML, Dataiku, Databricks, h2o, kubeflow, mlflow...
 318 Jan 2, 2023
318 Jan 2, 2023

Graph Convolutional Neural Networks with Data-driven Graph Filter (GCNN-DDGF)
Graph Convolutional Gated Recurrent Neural Network (GCGRNN) Improved from Graph Convolutional Neural Networks with Data-driven Graph Filter (GCNN-DDGF
 21 Dec 18, 2022
21 Dec 18, 2022
Project5 Data processing system
Project5-Data-processing-system User just needed to copy both these file to a folder and open Project5.py using cmd or using any python ide. It is to
 1 Nov 23, 2021
1 Nov 23, 2021
Epidemiology analysis package
zEpid zEpid is an epidemiology analysis package, providing easy to use tools for epidemiologists coding in Python 3.5+. The purpose of this library is
 111 Jan 8, 2023
111 Jan 8, 2023
Explorative Data Analysis Guidelines
Explorative Data Analysis Get data into a usable format! Find out if the following predictive modeling phase will be successful! Combine everything in
 18 Dec 26, 2022
18 Dec 26, 2022
cleanlab is the data-centric ML ops package for machine learning with noisy labels.
cleanlab is the data-centric ML ops package for machine learning with noisy labels. cleanlab cleans labels and supports finding, quantifying, and lear
 51 Nov 28, 2022
51 Nov 28, 2022
Data imputations library to preprocess datasets with missing data
Impyute is a library of missing data imputation algorithms. This library was designed to be super lightweight, here's a sneak peak at what impyute can do.
 329 Dec 5, 2022
329 Dec 5, 2022
Kaggler is a Python package for lightweight online machine learning algorithms and utility functions for ETL and data analysis.
Kaggler is a Python package for lightweight online machine learning algorithms and utility functions for ETL and data analysis. It is distributed under the MIT License.
 720 Dec 25, 2022
720 Dec 25, 2022
Skoot is a lightweight python library of machine learning transformer classes that interact with scikit-learn and pandas.
Skoot is a lightweight python library of machine learning transformer classes that interact with scikit-learn and pandas. Its objective is to ex
 54 Aug 20, 2022
54 Aug 20, 2022
dirty_cat is a Python module for machine-learning on dirty categorical variables.
dirty_cat dirty_cat is a Python module for machine-learning on dirty categorical variables.
 637 Dec 29, 2022
637 Dec 29, 2022

Pypeln is a simple yet powerful Python library for creating concurrent data pipelines.
Pypeln Pypeln (pronounced as "pypeline") is a simple yet powerful Python library for creating concurrent data pipelines. Main Features Simple: Pypeln
 1.4k Dec 31, 2022
1.4k Dec 31, 2022

A Guide for Feature Engineering and Feature Selection, with implementations and examples in Python.
Feature Engineering & Feature Selection A comprehensive guide [pdf] [markdown] for Feature Engineering and Feature Selection, with implementations and
 968 Dec 29, 2022
968 Dec 29, 2022
apricot implements submodular optimization for the purpose of selecting subsets of massive data sets to train machine learning models quickly.
Please consider citing the manuscript if you use apricot in your academic work! You can find more thorough documentation here. apricot implements subm
 457 Dec 20, 2022
457 Dec 20, 2022
MCML is a toolkit for semi-supervised dimensionality reduction and quantitative analysis of Multi-Class, Multi-Label data
MCML is a toolkit for semi-supervised dimensionality reduction and quantitative analysis of Multi-Class, Multi-Label data. We demonstrate its use
 26 Nov 29, 2022
26 Nov 29, 2022
Dump Data from FTDI Serial Port to Binary File on MacOS
Dump Data from FTDI Serial Port to Binary File on MacOS
 1 Nov 24, 2021
1 Nov 24, 2021
Crypto Stats and Tweets Data Pipeline using Airflow
Crypto Stats and Tweets Data Pipeline using Airflow Introduction Project Overview This project was brought upon through Udacity's nanodegree program.
 1 Nov 24, 2021
1 Nov 24, 2021
A package to predict protein inter-residue geometries from sequence data
trRosetta This package is a part of trRosetta protein structure prediction protocol developed in: Improved protein structure prediction using predicte
 185 Jan 7, 2023
185 Jan 7, 2023
An optimization and data collection toolbox for convenient and fast prototyping of computationally expensive models.
An optimization and data collection toolbox for convenient and fast prototyping of computationally expensive models. Hyperactive: is very easy to lear
 422 Jan 4, 2023
422 Jan 4, 2023
68 keypoint annotations for COFW test data
68 keypoint annotations for COFW test data This repository contains manually annotated 68 keypoints for COFW test data (original annotation of CFOW da
 31 Dec 6, 2022
31 Dec 6, 2022
Centralized whale instance using github actions, sourcing metadata from bigquery-public-data.
Whale Demo Instance: Bigquery Public Data This is a fully-functioning demo instance of the whale data catalog, actively scraping data from Bigquery's
 17 Dec 14, 2022
17 Dec 14, 2022
Fast Fourier Transform-accelerated Interpolation-based t-SNE (FIt-SNE)
FFT-accelerated Interpolation-based t-SNE (FIt-SNE) Introduction t-Stochastic Neighborhood Embedding (t-SNE) is a highly successful method for dimensi
 547 Dec 21, 2022
547 Dec 21, 2022
An interactive UMAP visualization of the MNIST data set.
Code for an interactive UMAP visualization of the MNIST data set. Demo at https://grantcuster.github.io/umap-explorer/. You can read more about the de
 70 Dec 27, 2022
70 Dec 27, 2022
A high-performance topological machine learning toolbox in Python
giotto-tda is a high-performance topological machine learning toolbox in Python built on top of scikit-learn and is distributed under the G
 632 Dec 29, 2022
632 Dec 29, 2022
Single-Cell Analysis in Python. Scales to 1M cells.
Scanpy – Single-Cell Analysis in Python Scanpy is a scalable toolkit for analyzing single-cell gene expression data built jointly with anndata. It inc
 1.4k Jan 5, 2023
1.4k Jan 5, 2023

3D rendered visualization of the austrian monuments registry
Visualization of the Austrian Monuments Visualization of the monument landscape of the austrian monuments registry (Bundesdenkmalamt Denkmalverzeichni
 3 Oct 24, 2019
3 Oct 24, 2019
Falcon: Interactive Visual Analysis for Big Data
Falcon: Interactive Visual Analysis for Big Data Crossfilter millions of records without latencies. This project is work in progress and not documente
 803 Dec 27, 2022
803 Dec 27, 2022

A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Torch and Numpy.
Visdom A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Python. Overview Concepts Setup Usage API To
 9.4k Jan 7, 2023
9.4k Jan 7, 2023
Complex heatmaps are efficient to visualize associations between different sources of data sets and reveal potential patterns.
Make Complex Heatmaps Complex heatmaps are efficient to visualize associations between different sources of data sets and reveal potential patterns. H
 973 Jan 9, 2023
973 Jan 9, 2023
A set of useful perceptually uniform colormaps for plotting scientific data
Colorcet: Collection of perceptually uniform colormaps Build Status Coverage Latest dev release Latest release Docs What is it? Colorcet is a collecti
 590 Dec 31, 2022
590 Dec 31, 2022

Streamlit — The fastest way to build data apps in Python
Welcome to Streamlit 👋 The fastest way to build and share data apps. Streamlit lets you turn data scripts into sharable web apps in minutes, not week
 22k Jan 6, 2023
22k Jan 6, 2023
The purpose of this project is to share knowledge on how awesome Streamlit is and can be
Awesome Streamlit The fastest way to build Awesome Tools and Apps! Powered by Python! The purpose of this project is to share knowledge on how Awesome
 1.5k Jan 7, 2023
1.5k Jan 7, 2023
A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Torch and Numpy.
Visdom A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Python. Overview Concepts Setup Usage API To
9.4k Jan 7, 2023
Select, weight and analyze complex sample data
Sample Analytics In large-scale surveys, often complex random mechanisms are used to select samples. Estimates derived from such samples must reflect
 37 Dec 15, 2022
37 Dec 15, 2022
Datashader is a data rasterization pipeline for automating the process of creating meaningful representations of large amounts of data.
Datashader is a data rasterization pipeline for automating the process of creating meaningful representations of large amounts of data.
2.9k Jan 6, 2023
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows.
An open-source, low-code machine learning library in Python 🚀 Version 2.3.5 out now! Check out the release notes here. Official • Docs • Install • Tu
 6.7k Jan 8, 2023
6.7k Jan 8, 2023

Visualization ideas for data science
Nuance I use Nuance to curate varied visualization thoughts during my data scientist career. It is not yet a package but a list of small ideas. Welcom
 16 Nov 3, 2022
16 Nov 3, 2022

🌲 Implementation of the Robust Random Cut Forest algorithm for anomaly detection on streams
🌲 Implementation of the Robust Random Cut Forest algorithm for anomaly detection on streams
 416 Jan 6, 2023
416 Jan 6, 2023
Approximate Nearest Neighbor Search for Sparse Data in Python!
Approximate Nearest Neighbor Search for Sparse Data in Python! This library is well suited to finding nearest neighbors in sparse, high dimensional spaces (like text documents).
 906 Jan 1, 2023
906 Jan 1, 2023
Project looking into use of autoencoder for semi-supervised learning and comparing data requirements compared to supervised learning.
Project looking into use of autoencoder for semi-supervised learning and comparing data requirements compared to supervised learning.
 2 Dec 17, 2021
2 Dec 17, 2021

A program that analyzes data from inertia measurement units installeed in aircraft and generates g-exceedance curves
A program that analyzes data from inertia measurement units installeed in aircraft and generates g-exceedance curves
 1 Nov 23, 2021
1 Nov 23, 2021
What if home automation was homoiconic? Just transformations of data? No more YAML!
radiale what if home-automation was also homoiconic? The upper or proximal row contains three bones, to which Gegenbaur has applied the terms radiale,
 21 Mar 26, 2022
21 Mar 26, 2022
Steganography Image/Data Injector.
Byte Steganography Image/Data Injector. For artists or people to inject their own print/data into their images. TODO Add more file formats to support.
 4 Nov 16, 2022
4 Nov 16, 2022
Python module for data science and machine learning users.
dsnk-distributions package dsnk distribution is a Python module for data science and machine learning that was created with the goal of reducing calcu
 1 Nov 23, 2021
1 Nov 23, 2021
Use Flask API to wrap Facebook data. Grab the wapper of Facebook public pages without an API key.
Facebook Scraper Use Flask API to wrap Facebook data. Grab the wapper of Facebook public pages without an API key. (Currently working 2021) Setup Befo
 2 Dec 27, 2021
2 Dec 27, 2021
Python beta calculator that retrieves stock and market data and provides linear regressions.
Stock and Index Beta Calculator Python script that calculates the beta (β) of a stock against the chosen index. The script retrieves the data and resa
 4 Jul 29, 2022
4 Jul 29, 2022
Lightweight library for accessing data and configuration
accsr This lightweight library contains utilities for managing, loading, uploading, opening and generally wrangling data and configurations. It was ba
 7 Mar 9, 2022
7 Mar 9, 2022

BErt-like Neurophysiological Data Representation
BENDR BErt-like Neurophysiological Data Representation This repository contains the source code for reproducing, or extending the BERT-like self-super
 114 Dec 23, 2022
114 Dec 23, 2022

SnapMix: Semantically Proportional Mixing for Augmenting Fine-grained Data (AAAI 2021)
SnapMix: Semantically Proportional Mixing for Augmenting Fine-grained Data (AAAI 2021) PyTorch implementation of SnapMix | paper Method Overview Cite
 126 Dec 30, 2022
126 Dec 30, 2022

ClearML - Auto-Magical Suite of tools to streamline your ML workflow. Experiment Manager, MLOps and Data-Management
ClearML - Auto-Magical Suite of tools to streamline your ML workflow Experiment Manager, MLOps and Data-Management ClearML Formerly known as Allegro T
 4k Jan 9, 2023
4k Jan 9, 2023
Rainbow DQN implementation that outperforms the paper's results on 40% of games using 20x less data 🌈
Rainbow 🌈 An implementation of Rainbow DQN which outperforms the paper's (Hessel et al. 2017) results on 40% of tested games while using 20x less dat
 31 Dec 21, 2022
31 Dec 21, 2022
Deep Learning with PyTorch made easy 🚀 !
Deep Learning with PyTorch made easy 🚀 ! Carefree? carefree-learn aims to provide CAREFREE usages for both users and developers. It also provides a c
 381 Dec 22, 2022
381 Dec 22, 2022
Python package for missing-data imputation with deep learning
MIDASpy Overview MIDASpy is a Python package for multiply imputing missing data using deep learning methods. The MIDASpy algorithm offers significant
 77 Dec 3, 2022
77 Dec 3, 2022

Create a database, insert data and easily select it with Sqlite
sqliteBasics create a database, insert data and easily select it with Sqlite Watch on YouTube a step by step tutorial explaining this code: https://yo
 27 Dec 27, 2022
27 Dec 27, 2022
A Python package to process & model ChEMBL data.
insilico: A Python package to process & model ChEMBL data. ChEMBL is a manually curated chemical database of bioactive molecules with drug-like proper
 0 Dec 9, 2021
0 Dec 9, 2021
An open source utility for creating publication quality LaTex figures generated from OpenFOAM data files.
foamTEX An open source utility for creating publication quality LaTex figures generated from OpenFOAM data files. Explore the docs » Report Bug · Requ
 1 Dec 19, 2021
1 Dec 19, 2021
Data Applications Project
DBMS project- Hotel Franchise Data and application project By TEAM Kurukunda Bhargavi Pamulapati Pallavi Greeshma Amaraneni What is this project about
 1 Nov 28, 2021
1 Nov 28, 2021
Sheet Data Image/PDF-to-CSV Converter
Sheet Data Image/PDF-to-CSV Converter
 5 Nov 22, 2021
5 Nov 22, 2021
Official repository for "Restormer: Efficient Transformer for High-Resolution Image Restoration". SOTA for motion deblurring, image deraining, denoising (Gaussian/real data), and defocus deblurring.
Restormer: Efficient Transformer for High-Resolution Image Restoration Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan,
 906 Dec 30, 2022
906 Dec 30, 2022
A single model for shaping, creating, accessing, storing data within a Database
'db' within pydantic - A single model for shaping, creating, accessing, storing data within a Database Key Features Integrated Redis Caching Support A
 178 Dec 16, 2022
178 Dec 16, 2022
Image classification for projects and researches
This is a tool to help you quickly solve classification problems including: data analysis, training, report results and model explanation.
 2 Dec 27, 2021
2 Dec 27, 2021
MinHash, LSH, LSH Forest, Weighted MinHash, HyperLogLog, HyperLogLog++, LSH Ensemble
datasketch: Big Data Looks Small datasketch gives you probabilistic data structures that can process and search very large amount of data super fast,
 1.9k Jan 7, 2023
1.9k Jan 7, 2023

AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty
AugMix Introduction We propose AugMix, a data processing technique that mixes augmented images and enforces consistent embeddings of the augmented ima
 876 Dec 17, 2022
876 Dec 17, 2022
How to use TensorLayer
How to use TensorLayer While research in Deep Learning continues to improve the world, we use a bunch of tricks to implement algorithms with TensorLay
 349 Dec 7, 2022
349 Dec 7, 2022
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate.
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate. Website • Key Features • How To Use • Docs •
 21.1k Dec 29, 2022
21.1k Dec 29, 2022
This project uses Youtube data API's to do youtube tags analysis based on viewCount, comments etc.
Youtube video details analyser Steps to run this project Please set the AuthKey which you can fetch from google developer console and paste it in the
 1 Nov 21, 2021
1 Nov 21, 2021
zeus is a Python implementation of the Ensemble Slice Sampling method.
zeus is a Python implementation of the Ensemble Slice Sampling method. Fast & Robust Bayesian Inference, Efficient Markov Chain Monte Carlo (MCMC), Bl
 197 Dec 4, 2022
197 Dec 4, 2022
Source code and notebooks to reproduce experiments and benchmarks on Bias Faces in the Wild (BFW).
Face Recognition: Too Bias, or Not Too Bias? Robinson, Joseph P., Gennady Livitz, Yann Henon, Can Qin, Yun Fu, and Samson Timoner. "Face recognition:
 41 Dec 12, 2022
41 Dec 12, 2022

Python module for performing linear regression for data with measurement errors and intrinsic scatter
Linear regression for data with measurement errors and intrinsic scatter (BCES) Python module for performing robust linear regression on (X,Y) data po
 56 Sep 27, 2022
56 Sep 27, 2022

Projeto: Machine Learning: Linguagens de Programacao 2004-2001
Projeto: Machine Learning: Linguagens de Programacao 2004-2001 Projeto de Data Science e Machine Learning de análise de linguagens de programação de 2
 0 Jun 29, 2021
0 Jun 29, 2021

Predicting the usefulness of reviews given the review text and metadata surrounding the reviews.
Predicting Yelp Review Quality Table of Contents Introduction Motivation Goal and Central Questions The Data Data Storage and ETL EDA Data Pipeline Da
 3 Nov 27, 2022
3 Nov 27, 2022
Tutorials, assignments, and competitions for MIT Deep Learning related courses.
MIT Deep Learning This repository is a collection of tutorials for MIT Deep Learning courses. More added as courses progress. Tutorial: Deep Learning
 9.5k Jan 7, 2023
9.5k Jan 7, 2023
Python solutions to solve practical business problems.
Python Business Analytics Also instead of "watching" you can join the link-letter, it's already being sent out to about 90 people and you are free to
357 Dec 26, 2022

Python Data Science Handbook: full text in Jupyter Notebooks
Python Data Science Handbook This repository contains the entire Python Data Science Handbook, in the form of (free!) Jupyter notebooks. How to Use th
 36.9k Dec 28, 2022
36.9k Dec 28, 2022
Design and build a wrapper for the Open Weather API current weather data service
Design and build a wrapper for the Open Weather API current weather data service that returns a city's temperature, with caching, also allowing for the temperature of the latest queried cities that are still validly cached to be retrieved.
 1 Jun 27, 2022
1 Jun 27, 2022

Empyrial is a Python-based open-source quantitative investment library dedicated to financial institutions and retail investors
By Investors, For Investors. Want to read this in Chinese? Click here Empyrial is a Python-based open-source quantitative investment library dedicated
 640 Dec 31, 2022
640 Dec 31, 2022