2660 Repositories
Python data-pipeline Libraries

pipeline for migrating lichess data into postgresql
How Long Does It Take Ordinary People To "Get Good" At Chess? TL;DR: According to 5.5 years of data from 2.3 million players and 450 million games, mo
 182 Nov 11, 2022
182 Nov 11, 2022
This is a practice on Airflow, which is building virtual env, installing Airflow and constructing data pipeline (DAGs)
airflow-test This is a practice on Airflow, which is Builing virtualbox env and setting Airflow on that env Installing Airflow using python virtual en
 1 Nov 1, 2021
1 Nov 1, 2021

This app finds duplicate to near duplicate images by generating a hash value for each image stored with a specialized data structure called VP-Tree which makes searching an image on a dataset of 100Ks almost instantanious
Offline Reverse Image Search Overview This app finds duplicate to near duplicate images by generating a hash value for each image stored with a specia
 53 Nov 15, 2022
53 Nov 15, 2022
Python script for transferring data between three drives in two separate stages
Waterlock Waterlock is a Python script meant for incrementally transferring data between three folder locations in two separate stages. It performs ha
 13 Nov 10, 2021
13 Nov 10, 2021
Parses data out of your Google Takeout (History, Activity, Youtube, Locations, etc...)
google_takeout_parser parses both the Historical HTML and new JSON format for Google Takeouts caches individual takeout results behind cachew merge mu
 27 Dec 28, 2022
27 Dec 28, 2022

This is a python table of data implementation with styles, colors
Table This is a python table of data implementation with styles, colors Example Table adapts to the lack of data Lambda color features Full power of l
 5 Nov 9, 2021
5 Nov 9, 2021

Tools for binary data on cassette
Micro Manchester Tape Storage Tools for storing binary data on cassette Includes: Python script for encoding Arduino sketch for decoding Eagle CAD fil
 28 Dec 25, 2022
28 Dec 25, 2022

Facilitates implementing deep neural-network backbones, data augmentations
Introduction Nowadays, the training of Deep Learning models is fragmented and unified. When AI engineers face up with one specific task, the common wa
 40 Dec 29, 2022
40 Dec 29, 2022
Lightweight Scheduled Blocks Checker for Current Epoch. No cardano-node Required, data is taken from blockfrost.io
ReLeaderLogs For Cardano Stakepool Operators: Lightweight Scheduled Blocks Checker for Current Epoch. No cardano-node Required, data is taken from blo
 2 Oct 19, 2021
2 Oct 19, 2021

Official and maintained implementation of the paper "OSS-Net: Memory Efficient High Resolution Semantic Segmentation of 3D Medical Data" [BMVC 2021].
OSS-Net: Memory Efficient High Resolution Semantic Segmentation of 3D Medical Data Christoph Reich, Tim Prangemeier, Özdemir Cetin & Heinz Koeppl | Pr
 23 Sep 21, 2022
23 Sep 21, 2022
CRUD database for python discord bot developers that stores data on discord text channels
Discord Database A CRUD (Create Read Update Delete) database for python Discord bot developers. All data is stored in key-value pairs directly on disc
 7 Oct 22, 2022
7 Oct 22, 2022

Complete portable pipeline for masking of Aadhaar Number adhering to Govt. Privacy Guidelines.
Aadhaar Number Masking Pipeline Implementation of a complete pipeline that masks the Aadhaar Number in given images to adhere to Govt. of India's Priv
 1 Nov 6, 2021
1 Nov 6, 2021
How to access and display MyEnergi data
MyEnergi-Python-Example How to access and display MyEnergi data Windows PC Install a version of Python typically 3.10 The Python code here needs addit
 8 Nov 28, 2022
8 Nov 28, 2022
HTTP API for FGO game data. Transform the raw game data into something a bit more manageable.
FGO game data API HTTP API for FGO game data. Transform the raw game data into something a bit more manageable. View the API documentation here: https
 51 Dec 26, 2022
51 Dec 26, 2022

Source code of our BMVC 2021 paper: AniFormer: Data-driven 3D Animation with Transformer
AniFormer This is the PyTorch implementation of our BMVC 2021 paper AniFormer: Data-driven 3D Animation with Transformer. Haoyu Chen, Hao Tang, Nicu S
 7 Oct 22, 2021
7 Oct 22, 2021
Official and maintained implementation of the paper "OSS-Net: Memory Efficient High Resolution Semantic Segmentation of 3D Medical Data" [BMVC 2021].
OSS-Net: Memory Efficient High Resolution Semantic Segmentation of 3D Medical Data Christoph Reich, Tim Prangemeier, Özdemir Cetin & Heinz Koeppl | Pr
23 Sep 21, 2022

Plotting data from the landroid and a raspberry pi zero to a influx-db
landroid-pi-influx Plotting data from the landroid and a raspberry pi zero to a influx-db Dependancies Hardware: Landroid WR130E Raspberry Pi Zero Wif
 2 Oct 22, 2021
2 Oct 22, 2021
Python Project on Pro Data Analysis Track
Udacity-BikeShare-Project: Python Project on Pro Data Analysis Track Basic Data Exploration with pandas on Bikeshare Data Basic Udacity project using
 0 Nov 10, 2021
0 Nov 10, 2021
Repository for the paper "Exploring the Sensory Spaces of English Perceptual Verbs in Natural Language Data"
Sensory Spaces of English Perceptual Verbs This repository contains the code and collocational data described in the paper "Exploring the Sensory Spac
 0 Sep 7, 2021
0 Sep 7, 2021

Code/data of the paper "Hand-Object Contact Prediction via Motion-Based Pseudo-Labeling and Guided Progressive Label Correction" (BMVC2021)
Hand-Object Contact Prediction (BMVC2021) This repository contains the code and data for the paper "Hand-Object Contact Prediction via Motion-Based Ps
 13 Nov 7, 2022
13 Nov 7, 2022

PyTorch code of my WACV 2022 paper Improving Model Generalization by Agreement of Learned Representations from Data Augmentation
Improving Model Generalization by Agreement of Learned Representations from Data Augmentation (WACV 2022) Paper ArXiv Why it matters? When data augmen
 5 Mar 4, 2022
5 Mar 4, 2022
Source code of our BMVC 2021 paper: AniFormer: Data-driven 3D Animation with Transformer
AniFormer This is the PyTorch implementation of our BMVC 2021 paper AniFormer: Data-driven 3D Animation with Transformer. Haoyu Chen, Hao Tang, Nicu S
24 Nov 2, 2022
Codebase for BMVC 2021 paper "Text Based Person Search with Limited Data"
Text Based Person Search with Limited Data This is the codebase for our BMVC 2021 paper. Please bear with me refactoring this codebase after CVPR dead
 33 Nov 24, 2022
33 Nov 24, 2022
Data for "Driving the Herd: Search Engines as Content Influencers" paper
herding_data Data for "Driving the Herd: Search Engines as Content Influencers" paper Dataset description The collection contains 2250 documents, 30 i
 0 Aug 17, 2021
0 Aug 17, 2021
This is a tool to help people to make a bot for labelling images for machine learning projects.
labeller_images_python_telegramBOT This is a bot to help collect data for any machine learning project. It was developed using the python-telegram-bot
 2 Nov 13, 2021
2 Nov 13, 2021

Modify version of impacket wmiexec.py, get output(data,response) from registry, don't need SMB connection, also bypassing antivirus-software in lateral movement like WMIHACKER.
wmiexec-RegOut Modify version of impacket wmiexec.py,wmipersist.py. Got output(data,response) from registry, don't need SMB connection, but I'm in the
 228 Jan 4, 2023
228 Jan 4, 2023

Github scraper app is used to scrape data for a specific user profile created using streamlit and BeautifulSoup python packages
Github Scraper Github scraper app is used to scrape data for a specific user profile. Github scraper app gets a github profile name and check whether
 6 Apr 5, 2022
6 Apr 5, 2022
Council Data Project is an open-source project dedicated to providing journalists, activists, researchers, and all members of each community we serve with the tools they need to stay informed and hold their Council Members accountable.
CDP - Self Council Data Project Council Data Project is an open-source project dedicated to providing journalists, activists, researchers, and all mem
 1 May 12, 2022
1 May 12, 2022

Analysis of ROM image for Norsk Data VDU 301 S
This repository is meant to analyze the ROM images from Norsk Data VDU 301 S as provided at by Torfinn. To combine the two ROM image halves and extrac
 1 Oct 21, 2021
1 Oct 21, 2021

CloakifyFactory & the Cloakify Toolset - Data Exfiltration & Infiltration In Plain Sight;
CloakifyFactory CloakifyFactory & the Cloakify Toolset - Data Exfiltration & Infiltration In Plain Sight; Evade DLP/MLS Devices; Social Engineering of
 3 Oct 18, 2022
3 Oct 18, 2022
Deep learning library for solving differential equations and more
DeepXDE Voting on whether we should have a Slack channel for discussion. DeepXDE is a library for scientific machine learning. Use DeepXDE if you need
 1.4k Dec 29, 2022
1.4k Dec 29, 2022

QuakeLabeler is a Python package to create and manage your seismic training data, processes, and visualization in a single place — so you can focus on building the next big thing.
QuakeLabeler Quake Labeler was born from the need for seismologists and developers who are not AI specialists to easily, quickly, and independently bu
 15 Nov 4, 2022
15 Nov 4, 2022
Retentioneering: product analytics, data-driven customer journey map optimization, marketing analytics, web analytics, transaction analytics, graph visualization, and behavioral segmentation with customer segments in Python.
What is Retentioneering? Retentioneering is a Python framework and library to assist product analysts and marketing analysts as it makes it easier to
 581 Jan 7, 2023
581 Jan 7, 2023

🔥🔥High-Performance Face Recognition Library on PaddlePaddle & PyTorch🔥🔥
face.evoLVe: High-Performance Face Recognition Library based on PaddlePaddle & PyTorch Evolve to be more comprehensive, effective and efficient for fa
 3.1k Jan 4, 2023
3.1k Jan 4, 2023

Towards Nonlinear Disentanglement in Natural Data with Temporal Sparse Coding
Towards Nonlinear Disentanglement in Natural Data with Temporal Sparse Coding
 61 Dec 21, 2022
61 Dec 21, 2022

Project code for weakly supervised 3D object detectors using wide-baseline multi-view traffic camera data: WIBAM.
WIBAM (Work in progress) Weakly Supervised Training of Monocular 3D Object Detectors Using Wide Baseline Multi-view Traffic Camera Data 3D object dete
 10 Aug 24, 2022
10 Aug 24, 2022
Data Structures and algorithms package implementation
Documentation Simple and Easy Package --This is package for enabling basic linear and non-linear data structures and algos-- Data Structures Array Sta
 1 Oct 30, 2021
1 Oct 30, 2021
CLI utility for updating the EVE Online static data export in a postgres database
EVE SDE Postgres updater CLI utility for updating the EVE Online static data export postgres database. This has been tested with the Fuzzwork postgres
 1 Oct 29, 2021
1 Oct 29, 2021
A CLI for streaming, downloading anime shows. The shows data is indexed through GogoAnime.
Anime-cli A CLI for streaming, downloading anime shows. The shows data is indexed through GogoAnime. Please install mpv video-player for better experi
 31 Oct 23, 2022
31 Oct 23, 2022
PyEmits, a python package for easy manipulation in time-series data.
PyEmits, a python package for easy manipulation in time-series data. Time-series data is very common in real life. Engineering FSI industry (Financial
 5 Sep 23, 2022
5 Sep 23, 2022
![[NeurIPS 2021] “Improving Contrastive Learning on Imbalanced Data via Open-World Sampling”,](https://github.com/VITA-Group/MAK/raw/main/imgs/pipeline.png)
[NeurIPS 2021] “Improving Contrastive Learning on Imbalanced Data via Open-World Sampling”,
Improving Contrastive Learning on Imbalanced Data via Open-World Sampling Introduction Contrastive learning approaches have achieved great success in
 24 Dec 17, 2022
24 Dec 17, 2022

Pytorch implementation of paper "Learning Co-segmentation by Segment Swapping for Retrieval and Discovery"
SegSwap Pytorch implementation of paper "Learning Co-segmentation by Segment Swapping for Retrieval and Discovery" [PDF] [Project page] If our project
 41 Dec 10, 2022
41 Dec 10, 2022
One package to access multiple different data sources through their respective API platforms.
BESTLab Platform One package to access multiple different data sources through their respective API platforms. Usage HOBO Platform See hobo_example.py
 1 Nov 16, 2021
1 Nov 16, 2021

Deep Learning Interviews book: Hundreds of fully solved job interview questions from a wide range of key topics in AI.
This book was written for you: an aspiring data scientist with a quantitative background, facing down the gauntlet of the interview process in an increasingly competitive field. For most of you, the interview process is the most significant hurdle between you and a dream job.
 4.1k Dec 28, 2022
4.1k Dec 28, 2022

DaCeML - Machine learning powered by data-centric parallel programming.
Data-centric machine learning powered by DaCe
 48 Dec 12, 2022
48 Dec 12, 2022

This python project contains a class FileProcessor which allows one to grab a file and get some meta data and header information from it
This python project contains a class FileProcessor which allows one to grab a file and get some meta data and header information from it. In the current state, it outputs a PrettyTable to txt file as well as the raw data from that table into a csv.
 1 Nov 9, 2021
1 Nov 9, 2021
CPSPEC is an astrophysical data reduction software for timing
CPSPEC manual Introduction CPSPEC is an astrophysical data reduction software for timing. Various timing properties, such as power spectra and cross s
 1 Oct 20, 2021
1 Oct 20, 2021
A Big Data ETL project in PySpark on the historical NYC Taxi Rides data
Processing NYC Taxi Data using PySpark ETL pipeline Description This is an project to extract, transform, and load large amount of data from NYC Taxi
 2 Dec 12, 2021
2 Dec 12, 2021
Example of scraping a paginated API endpoint and dumping the data into a DB
Provider API Scraper Example Example of scraping a paginated API endpoint and dumping the data into a DB. Pre-requisits Python = 3.9 Pipenv Setup # i
 1 Oct 20, 2021
1 Oct 20, 2021
Vector AI — A platform for building vector based applications. Encode, query and analyse data using vectors.
Vector AI is a framework designed to make the process of building production grade vector based applications as quickly and easily as possible. Create
 267 Dec 23, 2022
267 Dec 23, 2022

TagLab: an image segmentation tool oriented to marine data analysis
TagLab: an image segmentation tool oriented to marine data analysis TagLab was created to support the activity of annotation and extraction of statist
 49 Dec 29, 2022
49 Dec 29, 2022

10x faster matrix and vector operations
Bolt is an algorithm for compressing vectors of real-valued data and running mathematical operations directly on the compressed representations. If yo
 2.3k Jan 9, 2023
2.3k Jan 9, 2023
Synthetic structured data generators
Join us on What is Synthetic Data? Synthetic data is artificially generated data that is not collected from real world events. It replicates the stati
 850 Jan 7, 2023
850 Jan 7, 2023
High-quality implementations of standard and SOTA methods on a variety of tasks.
Uncertainty Baselines The goal of Uncertainty Baselines is to provide a template for researchers to build on. The baselines can be a starting point fo
 1.1k Dec 30, 2022
1.1k Dec 30, 2022
Open source Python implementation of the HDR+ photography pipeline
hdrplus-python Open source Python implementation of the HDR+ photography pipeline, originally developped by Google and presented in a 2016 article. Th
 77 Jan 5, 2023
77 Jan 5, 2023
A rule learning algorithm for the deduction of syndrome definitions from time series data.
README This project provides a rule learning algorithm for the deduction of syndrome definitions from time series data. Large parts of the algorithm a
 0 Sep 24, 2021
0 Sep 24, 2021

Scalable implementation of Lee / Mykland (2012) and Ait-Sahalia / Jacod (2012) Jump tests for noisy high frequency data
JumpDetectR Name of QuantLet : JumpDetectR Published in : 'To be published as "Jump dynamics in high frequency crypto markets"' Description : 'Scala
 12 Jan 1, 2023
12 Jan 1, 2023
abess: Fast Best-Subset Selection in Python and R
abess: Fast Best-Subset Selection in Python and R Overview abess (Adaptive BEst Subset Selection) library aims to solve general best subset selection,
 297 Dec 21, 2022
297 Dec 21, 2022
SPRING is a seq2seq model for Text-to-AMR and AMR-to-Text (AAAI2021).
SPRING This is the repo for SPRING (Symmetric ParsIng aNd Generation), a novel approach to semantic parsing and generation, presented at AAAI 2021. Wi
 98 Dec 21, 2022
98 Dec 21, 2022
EODAG is a command line tool and a plugin-oriented Python framework for searching, aggregating results and downloading remote sensed images while offering a unified API for data access regardless of the data provider
EODAG (Earth Observation Data Access Gateway) is a command line tool and a plugin-oriented Python framework for searching, aggregating results and downloading remote sensed images while offering a unified API for data access regardless of the data provider
 205 Jan 3, 2023
205 Jan 3, 2023
NudeNet: Neural Nets for Nudity Classification, Detection and selective censoring
NudeNet: Neural Nets for Nudity Classification, Detection and selective censoring Uncensored version of the following image can be found at https://i.
 1.1k Dec 29, 2022
1.1k Dec 29, 2022

Amazon Forest Computer Vision: Satellite Image tagging code using PyTorch / Keras with lots of PyTorch tricks
Amazon Forest Computer Vision Satellite Image tagging code using PyTorch / Keras Here is a sample of images we had to work with Source: https://www.ka
 359 Jan 5, 2023
359 Jan 5, 2023

A Web API for automatic background removal using Deep Learning. App is made using Flask and deployed on Heroku.
Automatic_Background_Remover A Web API for automatic background removal using Deep Learning. App is made using Flask and deployed on Heroku. 👉 https:
 16 Oct 29, 2022
16 Oct 29, 2022

missing-pixel-filler is a python package that, given images that may contain missing data regions (like satellite imagery with swath gaps), returns these images with the regions filled.
Missing Pixel Filler This is the official code repository for the Missing Pixel Filler by SpaceML. missing-pixel-filler is a python package that, give
 11 Jul 19, 2022
11 Jul 19, 2022
Techdegree Data Analysis Project 2
Basketball Team Stats Tool In this project you will be writing a program that reads from the "constants" data (PLAYERS and TEAMS) in constants.py. Thi
 2 Oct 23, 2021
2 Oct 23, 2021
This repository requires you to solve a problem by writing some basic python code.
Can You Solve a Problem? A beginner friendly repository that requires you to solve familiar problems with python. This could be as simple as implement
 11 Nov 30, 2022
11 Nov 30, 2022
[ICCV 2021] A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
[ICCV 2021] A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
 45 Dec 12, 2022
45 Dec 12, 2022

The implementation of the submitted paper "Deep Multi-Behaviors Graph Network for Voucher Redemption Rate Prediction" in SIGKDD 2021 Applied Data Science Track.
DMBGN: Deep Multi-Behaviors Graph Networks for Voucher Redemption Rate Prediction The implementation of the accepted paper "Deep Multi-Behaviors Graph
 10 Jul 12, 2022
10 Jul 12, 2022
Multiparametric Image Analysis
Documentation The documentation is available on populse_mia's website here Installation From PyPI, for users By cloning the package, for developers Fr
 9 Dec 14, 2022
9 Dec 14, 2022
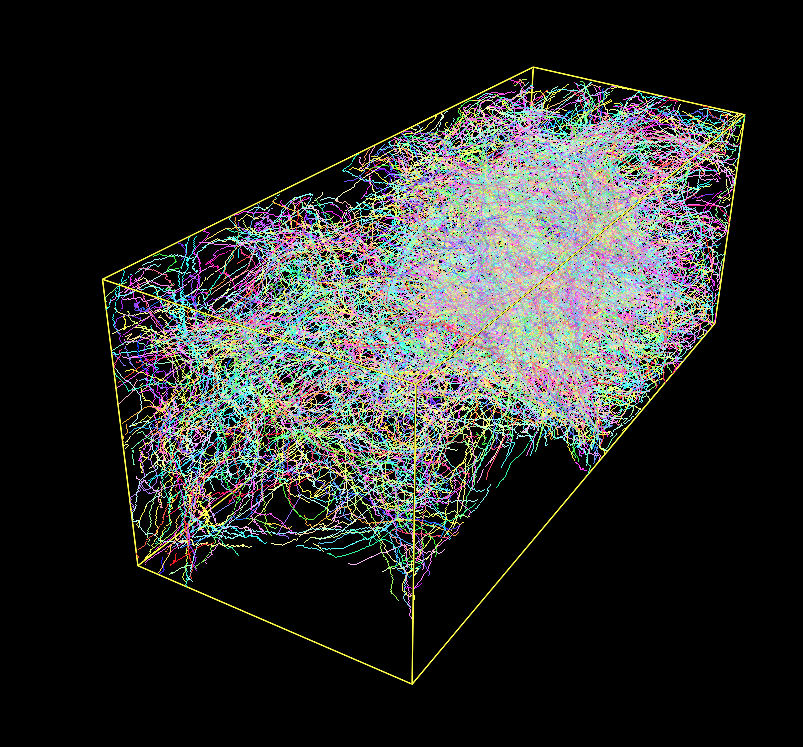
Kimimaro: Skeletonize Densely Labeled Images
Kimimaro: Skeletonize Densely Labeled Images # Produce SWC files from volumetric images. kimimaro forge labels.npy --progress # writes to ./kimimaro_o
 92 Dec 17, 2022
92 Dec 17, 2022
Lale is a Python library for semi-automated data science.
Lale is a Python library for semi-automated data science. Lale makes it easy to automatically select algorithms and tune hyperparameters of pipelines that are compatible with scikit-learn, in a type-safe fashion.
 293 Dec 29, 2022
293 Dec 29, 2022

Glue is a python project to link visualizations of scientific datasets across many files.
Glue Glue is a python project to link visualizations of scientific datasets across many files. Click on the image for a quick demo: Features Interacti
 675 Dec 9, 2022
675 Dec 9, 2022
Transform-Invariant Non-Negative Matrix Factorization
Transform-Invariant Non-Negative Matrix Factorization A comprehensive Python package for Non-Negative Matrix Factorization (NMF) with a focus on learn
 6 Jul 1, 2022
6 Jul 1, 2022

A collection of neat and practical data science and machine learning projects
Data Science A collection of neat and practical data science and machine learning projects Explore the docs » Report Bug · Request Feature Table of Co
 2 Dec 10, 2021
2 Dec 10, 2021
A logical, reasonably standardized, but flexible project structure for doing and sharing data science work.
Cookiecutter Data Science A logical, reasonably standardized, but flexible project structure for doing and sharing data science work. Project homepage
 0 Sep 5, 2021
0 Sep 5, 2021

eyes is a Public Opinion Mining System focusing on taiwanese forums such as PTT, Dcard.
eyes is a Public Opinion Mining System focusing on taiwanese forums such as PTT, Dcard. Features 🔥 Article monitor: helps you capture the trend at a
 116 Dec 29, 2022
116 Dec 29, 2022

🌌 Economics Observatory Visualisation Repository
Economics Observatory Visualisation Repository Website | Visualisations | Data | Here you will find all the data visualisations and infographics attac
 3 Dec 14, 2022
3 Dec 14, 2022
Framework for the Complete Gaze Tracking Pipeline
Framework for the Complete Gaze Tracking Pipeline The figure below shows a general representation of the camera-to-screen gaze tracking pipeline [1].
 20 Jan 6, 2023
20 Jan 6, 2023

A Discord bot to easily and quickly format your JSON data
Invite PrettyJSON to your Discord server Table of contents About the project What is JSON? What is pretty printing? How to use Input options Command I
 4 Jan 24, 2022
4 Jan 24, 2022
Code associated with the paper "Towards Understanding the Data Dependency of Mixup-style Training".
Mixup-Data-Dependency Code associated with the paper "Towards Understanding the Data Dependency of Mixup-style Training". Running Alternating Line Exp
 0 Nov 11, 2021
0 Nov 11, 2021
The official repository for our paper "The Neural Data Router: Adaptive Control Flow in Transformers Improves Systematic Generalization".
Codebase for learning control flow in transformers The official repository for our paper "The Neural Data Router: Adaptive Control Flow in Transformer
 24 Oct 15, 2022
24 Oct 15, 2022
Tools for working with MARC data in Catalogue Bridge.
catbridge_tools Tools for working with MARC data in Catalogue Bridge. Borrows heavily from PyMarc
 1 Nov 11, 2021
1 Nov 11, 2021

collect training and calibration data for gaze tracking
Collect Training and Calibration Data for Gaze Tracking This tool allows collecting gaze data necessary for personal calibration or training of eye-tr
5 Dec 17, 2022

Data and code for ICCV 2021 paper Distant Supervision for Scene Graph Generation.
Distant Supervision for Scene Graph Generation Data and code for ICCV 2021 paper Distant Supervision for Scene Graph Generation. Introduction The pape
 23 Dec 31, 2022
23 Dec 31, 2022

Unofficial Open Corporates CLI: OpenCorporates is a website that shares data on corporations under the copyleft Open Database License. This is an unofficial open corporates python command line tool.
Unofficial Open Corporates CLI OpenCorporates is a website that shares data on corporations under the copyleft Open Database License. This is an unoff
 30 Sep 8, 2022
30 Sep 8, 2022

Home Assistant custom integration to fetch data from Powerpal
Powerpal custom component for Home Assistant Component to integrate with powerpal. This repository and integration is not affiliated with Powerpal. Th
 32 Jan 7, 2023
32 Jan 7, 2023
Cryptocurrency Exchange Websocket Data Feed Handler
Cryptocurrency Exchange Websocket Data Feed Handler
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
Datashredder is a simple data corruption engine written in python. You can corrupt anything text, images and video.
Datashredder is a simple data corruption engine written in python. You can corrupt anything text, images and video. You can chose the cha
 2 Jul 22, 2022
2 Jul 22, 2022
An helper library to scrape data from TikTok in one line, using the Influencer Hunters APIs.
TikTok Scraper An utility library to scrape data from TikTok hassle-free Go to the website » View Demo · Report Bug · Request Feature About The Projec
 6 Jan 8, 2023
6 Jan 8, 2023
novel deep learning research works with PaddlePaddle
Research 发布基于飞桨的前沿研究工作,包括CV、NLP、KG、STDM等领域的顶会论文和比赛冠军模型。 目录 计算机视觉(Computer Vision) 自然语言处理(Natrual Language Processing) 知识图谱(Knowledge Graph) 时空数据挖掘(Spa
 1.5k Dec 29, 2022
1.5k Dec 29, 2022

Code and Data for NeurIPS2021 Paper "A Dataset for Answering Time-Sensitive Questions"
Time-Sensitive-QA The repo contains the dataset and code for NeurIPS2021 (dataset track) paper Time-Sensitive Question Answering dataset. The dataset
 35 Nov 14, 2022
35 Nov 14, 2022

Official Repository for our ICCV2021 paper: Continual Learning on Noisy Data Streams via Self-Purified Replay
Continual Learning on Noisy Data Streams via Self-Purified Replay This repository contains the official PyTorch implementation for our ICCV2021 paper.
 22 Nov 23, 2022
22 Nov 23, 2022
International Space Station data with Python research 🌎
International Space Station data with Python research 🌎 Plotting ISS trajectory, calculating the velocity over the earth and more. Plotting trajector
 41 Jun 16, 2022
41 Jun 16, 2022
Code and data for learning to search in local branching
Code and data for learning to search in local branching
 7 Dec 6, 2022
7 Dec 6, 2022
Python package for processing UC module spectral data.
UC Module Python Package How To Install clone repo. cd UC-module pip install . How to Use uc.module.UC(measurment=str, dark=str, reference=str, heade
 1 Oct 20, 2021
1 Oct 20, 2021
AI Flow is an open source framework that bridges big data and artificial intelligence.
Flink AI Flow Introduction Flink AI Flow is an open source framework that bridges big data and artificial intelligence. It manages the entire machine
 144 Dec 30, 2022
144 Dec 30, 2022
Script for scrape user data like "id,username,fullname,followers,tweets .. etc" by Twitter's search engine .
TwitterScraper Script for scrape user data like "id,username,fullname,followers,tweets .. etc" by Twitter's search engine . Screenshot Data Users Only
 19 Nov 17, 2022
19 Nov 17, 2022
A D3.js plugin that produces flame graphs from hierarchical data.
d3-flame-graph A D3.js plugin that produces flame graphs from hierarchical data. If you don't know what flame graphs are, check Brendan Gregg's post.
 740 Dec 29, 2022
740 Dec 29, 2022
wikirepo is a Python package that provides a framework to easily source and leverage standardized Wikidata information
Python based Wikidata framework for easy dataframe extraction wikirepo is a Python package that provides a framework to easily source and leverage sta
 35 Jan 4, 2023
35 Jan 4, 2023
Python-based Space Physics Environment Data Analysis Software
pySPEDAS pySPEDAS is an implementation of the SPEDAS framework for Python. The Space Physics Environment Data Analysis Software (SPEDAS) framework is
 98 Dec 22, 2022
98 Dec 22, 2022