3466 Repositories
Python data-pre-processing Libraries

MoCap-Solver: A Neural Solver for Optical Motion Capture Data
MoCap-Solver is a data-driven-based robust marker denoising method, which takes raw mocap markers as input and outputs corresponding clean markers and skeleton motions.
 55 Dec 28, 2022
55 Dec 28, 2022

Image-to-image regression with uncertainty quantification in PyTorch
Image-to-image regression with uncertainty quantification in PyTorch. Take any dataset and train a model to regress images to images with rigorous, distribution-free uncertainty quantification.
 25 Dec 26, 2022
25 Dec 26, 2022
Crowd-Kit is a powerful Python library that implements commonly-used aggregation methods for crowdsourced annotation and offers the relevant metrics and datasets
Crowd-Kit: Computational Quality Control for Crowdsourcing Documentation Crowd-Kit is a powerful Python library that implements commonly-used aggregat
 125 Dec 30, 2022
125 Dec 30, 2022
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
BROS (BERT Relying On Spatiality) is a pre-trained language model focusing on text and layout for better key information extraction from documents. Given the OCR results of the document image, which are text and bounding box pairs, it can perform various key information extraction tasks, such as extracting an ordered item list from receipts
 94 Dec 30, 2022
94 Dec 30, 2022
Supplementary Data for Evolving Reinforcement Learning Algorithms
evolvingrl Supplementary Data for Evolving Reinforcement Learning Algorithms This dataset contains 1000 loss graphs from two experiments: 500 unique g
 42 Sep 21, 2022
42 Sep 21, 2022
A framework for GPU based high-performance medical image processing and visualization
FAST is an open-source cross-platform framework with the main goal of making it easier to do high-performance processing and visualization of medical images on heterogeneous systems utilizing both multi-core CPUs and GPUs. To achieve this, FAST use modern C++, OpenCL and OpenGL.
 315 Dec 30, 2022
315 Dec 30, 2022
Course materials for Fall 2021 "CIS6930 Topics in Computing for Data Science" at New College of Florida
Fall 2021 CIS6930 Topics in Computing for Data Science This repository hosts course materials used for a 13-week course "CIS6930 Topics in Computing f
 101 Nov 30, 2022
101 Nov 30, 2022
Customizing Visual Styles in Plotly
Customizing Visual Styles in Plotly Code for a workshop originally developed for an Unconference session during the Outlier Conference hosted by Data
 9 Aug 3, 2022
9 Aug 3, 2022

Geospatial data-science analysis on reasons behind delay in Grab ride-share services
Grab x Pulis Detailed analysis done to investigate possible reasons for delay in Grab services for NUS Data Analytics Competition 2022, to be found in
 6 Jun 7, 2022
6 Jun 7, 2022

metedraw is a project mainly for data visualization projects of Atmospheric Science, Marine Science, Environmental Science or other majors
It is mainly for data visualization projects of Atmospheric Science, Marine Science, Environmental Science or other majors.
 11 Jul 5, 2022
11 Jul 5, 2022

OpenStats is a library built on top of streamlit that extracts data from the Github API and shows the main KPIs
Open Stats Discover and share the KPIs of your OpenSource project. OpenStats is a library built on top of streamlit that extracts data from the Github
 4 Apr 3, 2022
4 Apr 3, 2022

A research of IT labor market based especially on hh.ru. Salaries, rate of technologies and etc.
hh_ru_research Проект реализован в учебных целях анализа рынка труда, в особенности по hh.ru Input data В качестве входных данных используются сериали
 3 Sep 7, 2022
3 Sep 7, 2022

To build a regression model to predict the concrete compressive strength based on the different features in the training data.
Cement-Strength-Prediction Problem Statement To build a regression model to predict the concrete compressive strength based on the different features
 4 Jun 11, 2022
4 Jun 11, 2022
A Python implementation of red-black trees
Python red-black trees A Python implementation of red-black trees. This code was originally copied from programiz.com, but I have made a few tweaks to
 7 Oct 20, 2022
7 Oct 20, 2022
Contains a Jupyter Notebook for calculating remaining plants required based on field/lathhouse data.
Davis-Sunflowers-Su21 Project goals: Plants influence their reproduction and mating system in many ways. Various factors such as time of flowering, ab
 1 Feb 10, 2022
1 Feb 10, 2022
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify.
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify. The ETL process flows from AWS's S3 into staging tables in AWS Redshift.
 1 Feb 11, 2022
1 Feb 11, 2022

Implementation of SOMs (Self-Organizing Maps) with neighborhood-based map topologies.
py-self-organizing-maps Simple implementation of self-organizing maps (SOMs) A SOM is an unsupervised method for learning a mapping from a discrete ne
 6 Nov 22, 2022
6 Nov 22, 2022

Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
 1 Feb 11, 2022
1 Feb 11, 2022
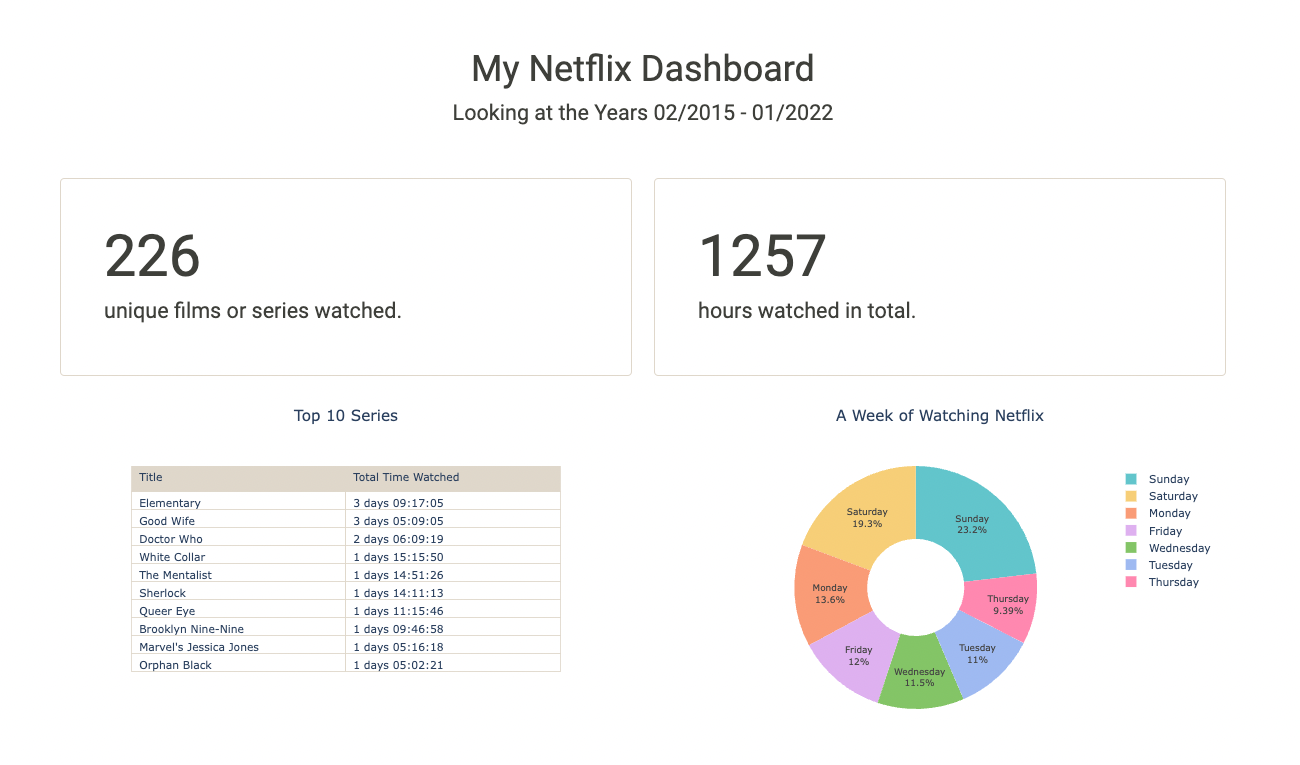
Project: Netflix Data Analysis and Visualization with Python
Project: Netflix Data Analysis and Visualization with Python Table of Contents General Info Installation Demo Usage and Main Functionalities Contribut
 2 Feb 13, 2022
2 Feb 13, 2022
PLStream: A Framework for Fast Polarity Labelling of Massive Data Streams
PLStream: A Framework for Fast Polarity Labelling of Massive Data Streams Motivation When dataset freshness is critical, the annotating of high speed
 4 Aug 2, 2022
4 Aug 2, 2022

A python scripts that uses 3 different feature extraction methods such as SIFT, SURF and ORB to find a book in a video clip and project trailer of a movie based on that book, on to it.
A python scripts that uses 3 different feature extraction methods such as SIFT, SURF and ORB to find a book in a video clip and project trailer of a movie based on that book, on to it.
 3 Feb 10, 2022
3 Feb 10, 2022

This project uses ViT to perform image classification tasks on DATA set CIFAR10.
Vision-Transformer-Multiprocess-DistributedDataParallel-Apex Introduction This project uses ViT to perform image classification tasks on DATA set CIFA
 3 Jun 3, 2022
3 Jun 3, 2022

CLASSIX is a fast and explainable clustering algorithm based on sorting
CLASSIX Fast and explainable clustering based on sorting CLASSIX is a fast and explainable clustering algorithm based on sorting. Here are a few highl
 69 Jan 6, 2023
69 Jan 6, 2023
PyTorch implementation of the ExORL: Exploratory Data for Offline Reinforcement Learning
ExORL: Exploratory Data for Offline Reinforcement Learning This is an original PyTorch implementation of the ExORL framework from Don't Change the Alg
 52 Jan 1, 2023
52 Jan 1, 2023
Geowifi 📡 💘 🌎 Search WiFi geolocation data by BSSID and SSID on different public databases.
Geowifi 📡 💘 🌎 Search WiFi geolocation data by BSSID and SSID on different public databases.
 441 Dec 23, 2022
441 Dec 23, 2022

Python code to fuse multiple RGB-D images into a TSDF voxel volume.
Volumetric TSDF Fusion of RGB-D Images in Python This is a lightweight python script that fuses multiple registered color and depth images into a proj
 845 Jan 3, 2023
845 Jan 3, 2023

The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding.
SuperGen The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. Requirements Before running, you
 38 Dec 12, 2022
38 Dec 12, 2022
Explore extreme compression for pre-trained language models
Code for paper "Exploring extreme parameter compression for pre-trained language models ICLR2022"
 16 Nov 14, 2022
16 Nov 14, 2022

Interactive Dashboard for Visualizing OSM Data Change
Dashboard and intuitive data downloader for more interactive experience with interpreting osm change data.
 1 Feb 20, 2022
1 Feb 20, 2022
Data Analysis: Data Visualization of Airlines
Data Analysis: Data Visualization of Airlines Anderson Cruz | London-UK | Linkedin | Nowa Capital Project: Traffic Airlines Airline Reporting Carrier
 1 Feb 10, 2022
1 Feb 10, 2022
This program will help you to properly scrape all data from a specific website
This program will help you to properly scrape all data from a specific website
 0 May 15, 2022
0 May 15, 2022

Extract GoPro highlights and GPMF data.
Python script that parses the gpmd stream for GOPRO moov track (MP4) and extract the GPS info into a GPX (and kml) file.
 2 May 13, 2022
2 May 13, 2022
SubOmiEmbed: Self-supervised Representation Learning of Multi-omics Data for Cancer Type Classification
SubOmiEmbed: Self-supervised Representation Learning of Multi-omics Data for Cancer Type Classification
 3 Nov 15, 2022
3 Nov 15, 2022
L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources.
L3Cube-MahaCorpus L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources. We expand the existing Marathi monolingual
 21 Dec 17, 2022
21 Dec 17, 2022
Python package for concise, transparent, and accurate predictive modeling
Python package for concise, transparent, and accurate predictive modeling. All sklearn-compatible and easy to use. 📚 docs • 📖 demo notebooks Modern
 983 Jan 1, 2023
983 Jan 1, 2023
Nested cross-validation is necessary to avoid biased model performance in embedded feature selection in high-dimensional data with tiny sample sizes
Pruner for nested cross-validation - Sphinx-Doc Nested cross-validation is necessary to avoid biased model performance in embedded feature selection i
 1 Dec 15, 2021
1 Dec 15, 2021
Data and code accompanying the paper Politics and Virality in the Time of Twitter
Politics and Virality in the Time of Twitter Data and code accompanying the paper Politics and Virality in the Time of Twitter. In specific: the code
 3 Jul 2, 2022
3 Jul 2, 2022

Image Data Augmentation in Keras
Image data augmentation is a technique that can be used to artificially expand the size of a training dataset by creating modified versions of images in the dataset.
 3 Feb 15, 2022
3 Feb 15, 2022

Data Augmentation Using Keras and Python
Data-Augmentation-Using-Keras-and-Python Data augmentation is the process of increasing the number of training dataset. Keras library offers a simple
 3 Feb 15, 2022
3 Feb 15, 2022
Definitive Guide to Creating a SQL Database on Cloud with AWS and Python
Definitive Guide to Creating a SQL Database on Cloud with AWS and Python An easy-to-follow comprehensive guide on integrating Amazon RDS, MySQL Workbe
 6 Aug 17, 2022
6 Aug 17, 2022
Structured Data Gradient Pruning (SDGP)
Structured Data Gradient Pruning (SDGP) Weight pruning is a technique to make Deep Neural Network (DNN) inference more computationally efficient by re
 10 Nov 11, 2022
10 Nov 11, 2022
Pytorch Implementation for Dilated Continuous Random Field
DilatedCRF Pytorch implementation for fully-learnable DilatedCRF. If you find my work helpful, please consider our paper: @article{Mo2022dilatedcrf,
 3 Nov 13, 2022
3 Nov 13, 2022

LinkScope allows you to perform online investigations by representing information as discrete pieces of data, called Entities.
LinkScope Client Description This is the repository for the LinkScope Client Online Investigation software. LinkScope allows you to perform online inv
 108 Jan 4, 2023
108 Jan 4, 2023
IADS 2021-22 Algorithm and Data structure collection
A collection of algorithms and datastructures introduced during UoE's Introduction to Datastructures and Algorithms class.
 20 Nov 7, 2022
20 Nov 7, 2022
Prometheus exporter for chess.com player data
chess-exporter Prometheus exporter for chess.com player data implemented via chess.com's published data API and Prometheus Python Client Example use c
 7 Feb 28, 2022
7 Feb 28, 2022
Kartothek - a Python library to manage large amounts of tabular data in a blob store
Kartothek - a Python library to manage (create, read, update, delete) large amounts of tabular data in a blob store
 15 Dec 25, 2022
15 Dec 25, 2022

Generate database table diagram from SQL data definition.
sql2diagram Generate database table diagram from SQL data definition. e.g. "CREATE TABLE ..." See Example below How does it works? Analyze the SQL to
 1 Feb 8, 2022
1 Feb 8, 2022

PATC: Introduction to Big Data Analytics. Practical Data Analytics for Solving Real World Problems
PATC: Introduction to Big Data Analytics. Practical Data Analytics for Solving Real World Problems
 1 Feb 7, 2022
1 Feb 7, 2022
MidTerm Project for the Data Analysis FT Bootcamp, Adam Tycner and Florent ZAHOUI
MidTerm Project for the Data Analysis FT Bootcamp, Adam Tycner and Florent ZAHOUI Hallo
 1 Feb 7, 2022
1 Feb 7, 2022

CT Based COVID 19 Diagnose by Image Processing and Deep Learning
This project proposed the deep learning and image processing method to undertake the diagnosis on 2D CT image and 3D CT volume.
 1 Feb 8, 2022
1 Feb 8, 2022

Natural language processing summarizer using 3 state of the art Transformer models: BERT, GPT2, and T5
NLP-Summarizer Natural language processing summarizer using 3 state of the art Transformer models: BERT, GPT2, and T5 This project aimed to provide in
 1 Feb 7, 2022
1 Feb 7, 2022
This repo has the source code for the crawler and data crawled from auto-data.net
This repo contains the source code for crawler and crawled data of cars specifications from autodata. The data has roughly 45k cars
 5 Nov 22, 2022
5 Nov 22, 2022
Python command line tool and python engine to label table fields and fields in data files.
Python command line tool and python engine to label table fields and fields in data files. It could help to find meaningful data in your tables and data files or to find Personal identifable information (PII).
 22 Dec 5, 2022
22 Dec 5, 2022
Sequence-tagging using deep learning
Classification using Deep Learning Requirements PyTorch version = 1.9.1+cu111 Python version = 3.8.10 PyTorch-Lightning version = 1.4.9 Huggingface
 2 Dec 20, 2022
2 Dec 20, 2022

Scraping and visualising India's real-time COVID-19 data from the MOHFW dataset.
COVID19-WEB-SCRAPER Open Source Tech Lab - Project [SEMESTER IV] OSTL Assignments OSTL Assignments - 1 OSTL Assignments - 2 Project COVID19 India Data
 8 Apr 28, 2022
8 Apr 28, 2022

Create artistic visualisations with your exercise data (Python version)
strava_py Create artistic visualisations with your exercise data (Python version). This is a port of the R strava package to Python. Examples Facets A
 53 Dec 28, 2022
53 Dec 28, 2022
Conducted ANOVA and Logistic regression analysis using matplot library to visualize the result.
Intro-to-Data-Science Conducted ANOVA and Logistic regression analysis. Project ANOVA The main aim of this project is to perform One-Way ANOVA analysi
 1 Feb 6, 2022
1 Feb 6, 2022
1900-2016 Olympic Data Analysis in Python by plotting different graphs
🔥 Olympics Data Analysis 🔥 In Data Science field, there is a big topic before creating a model for future prediction is Data Analysis. We can find o
 1 Feb 6, 2022
1 Feb 6, 2022

Collection of data visualizing projects through Tableau, Data Wrapper, and Power BI
Data-Visualization-Projects Collection of data visualizing projects through Tableau, Data Wrapper, and Power BI Indigenous-Brands-Social-Movements Pyt
 1 Feb 5, 2022
1 Feb 5, 2022
/samples.jpg)
A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution.
Awesome Pretrained StyleGAN2 A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution. Note the readme is a
 1.1k Dec 24, 2022
1.1k Dec 24, 2022
Pokehandy - Data web app sobre Pokémon TCG que desarrollo durante transmisiones de Twitch, 2022
⚡️ Pokéhandy – Pokémon Hand Simulator [WIP 🚧 ] This application aims to simulat
 5 Feb 23, 2022
5 Feb 23, 2022
Helperpod - A CLI tool to run a Kubernetes utility pod with pre-installed tools that can be used for debugging/testing purposes inside a Kubernetes cluster
Helperpod is a CLI tool to run a Kubernetes utility pod with pre-installed tools that can be used for debugging/testing purposes inside a Kubernetes cluster.
 2 Feb 5, 2022
2 Feb 5, 2022
InverterApi - This project has been designed to take monitoring data from Voltronic, Axpert, Mppsolar PIP, Voltacon, Effekta
InverterApi - This project has been designed to take monitoring data from Voltronic, Axpert, Mppsolar PIP, Voltacon, Effekta
 2 Sep 3, 2022
2 Sep 3, 2022
Weather Image Recognition - Python weather application using series of data
Weather Image Recognition - Python weather application using series of data
 1 Feb 4, 2022
1 Feb 4, 2022
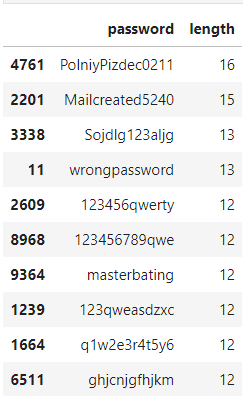
Analysis of a dataset of 10000 passwords to find common trends and mistakes people generally make while setting up a password.
Analysis of a dataset of 10000 passwords to find common trends and mistakes people generally make while setting up a password.
 7 Sep 4, 2022
7 Sep 4, 2022
Geospatial Data Visualization using PyGMT
Example script to visualize topographic data, earthquake data, and tomographic data on a map
 2 Jul 30, 2022
2 Jul 30, 2022
Evaluate on three different ML model for feature selection using Breast cancer data.
Anomaly-detection-Feature-Selection Evaluate on three different ML model for feature selection using Breast cancer data. ML models: SVM, KNN and MLP.
 1 Mar 17, 2022
1 Mar 17, 2022
Natural Language Processing at EDHEC, 2022
Natural Language Processing Here you will find the teaching materials for the "Natural Language Processing" course at EDHEC Business School, 2022 What
 1 Feb 4, 2022
1 Feb 4, 2022
A solution designed to extract, transform and load Chicago crime data from an RDS instance to other services in AWS.
This project is intended to implement a solution designed to extract, transform and load Chicago crime data from an RDS instance to other services in AWS.
 1 Feb 4, 2022
1 Feb 4, 2022
ADB-IP-ROTATION - Use your mobile phone to gain a temporary IP address using ADB and data tethering
ADB IP ROTATE This an Python script based on Android Debug Bridge (adb) shell sc
 2 Jul 12, 2022
2 Jul 12, 2022
A data structure that extends pyspark.sql.DataFrame with metadata information.
MetaFrame A data structure that extends pyspark.sql.DataFrame with metadata info
 8 Feb 15, 2022
8 Feb 15, 2022
sfgp is a package that aggregates individual scripts and notebooks, primarily written for the basic analysis tasks of genetics and pharmacogenomics data.
sfgp is a package that aggregates individual scripts and notebooks, primarily written for the basic analysis tasks of genetics and pharmacogenomics data.
 1 Mar 31, 2022
1 Mar 31, 2022
🌍 Create 3d-printable STLs from satellite elevation data 🌏
mapa 🌍 Create 3d-printable STLs from satellite elevation data Installation pip install mapa Usage mapa uses numpy and numba under the hood to crunch
 13 Dec 15, 2022
13 Dec 15, 2022
This project proposes a camera vision based cursor control system, using hand moment captured from a webcam through a landmarks of hand by using Mideapipe module
This project proposes a camera vision based cursor control system, using hand moment captured from a webcam through a landmarks of hand by using Mideapipe module
 2 Feb 20, 2022
2 Feb 20, 2022
Soccerdata - Efficiently scrape soccer data from various sources
SoccerData is a collection of wrappers over soccer data from Club Elo, ESPN, FBr
 195 Jan 4, 2023
195 Jan 4, 2023
Data from "Datamodels: Predicting Predictions with Training Data"
Data from "Datamodels: Predicting Predictions with Training Data" Here we provid
 51 Dec 9, 2022
51 Dec 9, 2022

Data-depth-inference - Data depth inference with python
Welcome! This readme will guide you through the use of the code in this reposito
 3 Feb 8, 2022
3 Feb 8, 2022
Catalogue data - A Python Scripts to prepare catalogue data
catalogue_data Scripts to prepare catalogue data. Setup Clone this repo. Install
 3 Mar 3, 2022
3 Mar 3, 2022
Python/Selenium script to scrape data about university courses
university-courses Python/Selenium script to scrape data about university courses. Script first extracts URLs of each courses homepage, then trawls ea
 1 Feb 2, 2022
1 Feb 2, 2022
Download Web-10K data by querying Bing Image Search
gpv2-web10k This repository contains the script to download images from the Web-10K dataset. The script takes in a list of queries, queries Bing Image
 8 Sep 6, 2022
8 Sep 6, 2022
The aim is to extract timeseries water level 2D information for any designed boundaries within the EasyGSH model domain
bct_file_generator_for_EasyGSH The aim is to extract timeseries water level 2D information for any designed boundaries within the EasyGSH model domain
 1 Jul 8, 2022
1 Jul 8, 2022

Convert monolithic Jupyter notebooks into Ploomber pipelines.
Soorgeon Join our community | Newsletter | Contact us | Blog | Website | YouTube Convert monolithic Jupyter notebooks into Ploomber pipelines. soorgeo
 65 Dec 16, 2022
65 Dec 16, 2022
This repository collects together basic linguistic processing data for using dataset dumps from the Common Voice project
Common Voice Utils This repository collects together basic linguistic processing data for using dataset dumps from the Common Voice project. It aims t
 40 Dec 20, 2022
40 Dec 20, 2022
Hatchet is a Python-based library that allows Pandas dataframes to be indexed by structured tree and graph data.
Hatchet Hatchet is a Python-based library that allows Pandas dataframes to be indexed by structured tree and graph data. It is intended for analyzing
 14 Aug 19, 2022
14 Aug 19, 2022
Upload comma-delimited files to biglocalnews.org in your GitHub Action
Upload comma-delimited files to biglocalnews.org in your GitHub Action Inputs api-key: Your biglocalnews.org API token. project-id: The identifier of
 1 Apr 20, 2022
1 Apr 20, 2022
Used for data processing in machine learning, and help us to construct ML model more easily from scratch
Used for data processing in machine learning, and help us to construct ML model more easily from scratch. Can be used in linear model, logistic regression model, and decision tree.
 0 Jul 5, 2022
0 Jul 5, 2022
A Login/Registration GUI Application with SQLite database for manipulating data.
Login-Register_Tk A Login/Registration GUI Application with SQLite database for manipulating data. What is this program? This program is a GUI applica
 1 Feb 1, 2022
1 Feb 1, 2022
Generates, filters, parses, and cleans data regarding the financial disclosures of judges in the American Judicial System
This repository contains code that gets data regarding financial disclosures from the Court Listener API main.py: contains driver code that interacts
 2 Aug 6, 2022
2 Aug 6, 2022

Enable geospatial data mining through Google Earth Engine in Grasshopper 3D, via its most recent Hops component.
AALU_Geo Mining This repository is produced for a masterclass at the Architectural Association Landscape Urbanism programme. Requirements Rhinoceros (
 4 Nov 16, 2022
4 Nov 16, 2022
MoRecon - A tool for reconstructing missing frames in motion capture data.
MoRecon - A tool for reconstructing missing frames in motion capture data.
 38 Dec 3, 2022
38 Dec 3, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
NFCDS Workshop Beginners Guide Bioinformatics Data Analysis
Genomics Workshop FIXME: overview of workshop Code of Conduct All participants s
 2 Jun 13, 2022
2 Jun 13, 2022
Mednlp - Medical natural language parsing and utility library
Medical natural language parsing and utility library A natural language medical
 3 Aug 24, 2022
3 Aug 24, 2022

Code for You Only Cut Once: Boosting Data Augmentation with a Single Cut
You Only Cut Once (YOCO) YOCO is a simple method/strategy of performing augmenta
 88 Dec 28, 2022
88 Dec 28, 2022

DUCKSPLOIT - Windows Hacking FrameWork using Reverse Shell
Ducksploit Install Ducksploit Hacker setup raspberry pico Download https://githu
 2 Jan 31, 2022
2 Jan 31, 2022

Reverse engineering the dengue virus (under development construction)
Reverse engineering the dengue virus (under development 🚧 ) What is dengue? Dengue is a viral infection transmitted to humans through the bite of inf
 4 Feb 9, 2022
4 Feb 9, 2022
Proyecto - Análisis de texto de eventos históricos
Acceder al código desde Google Colab para poder ver de manera adecuada todas las visualizaciones y poder interactuar con ellas. Link de acceso: https:
 1 Jan 31, 2022
1 Jan 31, 2022
Proyecto - Desgaste y rendimiento de empleados de IBM HR Analytics
Acceder al código desde Google Colab para poder ver de manera adecuada todas las visualizaciones y poder interactuar con ellas. Links de acceso: Noteb
1 Jan 31, 2022

A command line tool that can convert Day One data into markdown files.
Introduction Features Before Start Export data from Day One Check Integrity Special Cases for Photo Extension Name Audio Extension Name Usage Known Is
 26 Dec 31, 2022
26 Dec 31, 2022

A simple app to scrap data from Twitter.
Twitter-Scraping-App A simple app to scrap data from Twitter. Available Features Search query. Select number of data you want to fetch from twitter. C
 2 Oct 31, 2022
2 Oct 31, 2022